- The paper introduces Divide-and-Conquer CoT, a framework that decomposes tasks for parallel reasoning, significantly reducing inference latency.
- It employs a staged RL pipeline using DAPO and CISPO with adaptive data filtering, which enhances both accuracy and efficiency.
- Empirical results show a 37.4% reduction in longest path length on AIME 2024 while maintaining or improving accuracy compared to sequential methods.
Divide-and-Conquer CoT: RL for Reducing Latency via Parallel Reasoning
Overview and Motivation
Long chain-of-thought (CoT) reasoning has become central to state-of-the-art LLM performance, especially in math domains. However, this approach introduces significant latency, as sequential token generation inevitably delays output. The "Divide-and-Conquer CoT" (DC-CoT) framework (2601.23027) addresses this bottleneck by training models to explicitly recognize and exploit opportunities for parallelization in reasoning processes. DC-CoT enables models to act as both a director, decomposing tasks into parallelizable subtasks, and as workers, executing those subtasks in parallel. The primary metric optimized is the longest path length (LPL)—defined as the maximal number of sequential tokens required across parallel branches—which serves as a latency proxy.
Methodological Framework
Architecture for Parallel Inference
DC-CoT formalizes inference as alternating between director-driven sequential reasoning and worker-level parallel reasoning. The algorithm proceeds as follows:
- The director generates an initial reasoning prefix, halting at a special
<spawn token.
- Multiple workers (typically three in experiments) are spawned, each assigned a subtask with the common context but different
<worker_i> tags, and perform their token generation in parallel.
- After all workers complete, their outputs re-enter the director’s context, which may terminate with an answer or recursively spawn further parallel workers if needed.
This mechanism enables hybrid sequential-parallel reasoning and is implemented via standard LM inference calls, leveraging unmodified vLLM serving.
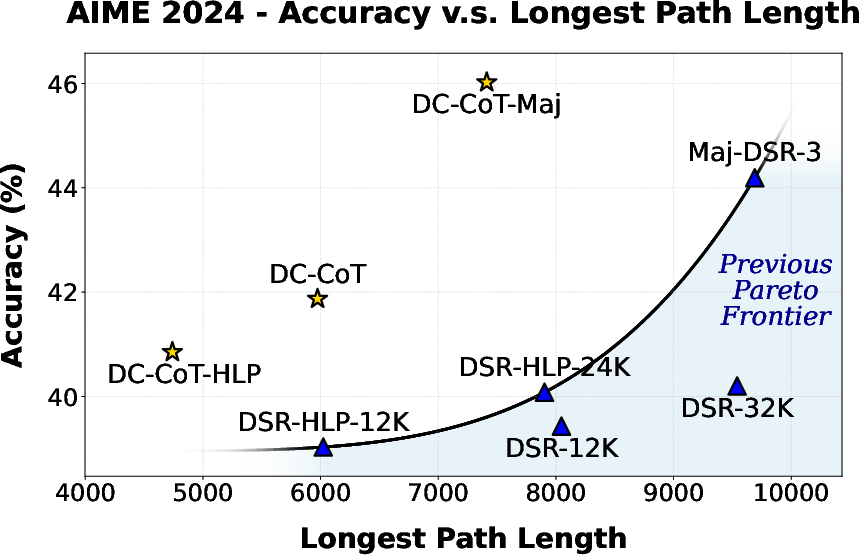
Figure 1: Accuracy (pass@1) and longest path length for DC-CoT and baselines on AIME 2024, demonstrating DC-CoT’s superior accuracy at lower LPL compared to sequential baselines.
Training Pipeline
Supervised Fine-Tuning (SFT)
The process begins by SFT on a curated demonstration set designed to initialize the ability to generate parallel reasoning structures in the required syntax. Sequential CoTs from DeepScaleR-1.5B-Preview are rewritten using an LLM to produce parallelizable CoTs, with strong constraints to ensure format consistency and correct decomposition.
Multi-Stage Reinforcement Learning
Given the substantial degradation from SFT (i.e., accuracy loss and insufficient parallelization), recovery is achieved via a carefully staged RL protocol:
- Stage 1: DAPO is used for policy optimization with a reward shaped by correctness and LPL. However, convergence plateaus, correlated with an observed monotonic increase in token entropy that inhibits deterministic token prediction.
- Stage 2: CISPO replaces DAPO, stabilizing entropy and yielding further accuracy improvements, though eventually again plateauing due to training set filtering strategy.
- Stage 3-4: Data filtering strategy is refined; "Include-Easy" (initially) includes all-correct samples to provide LPL learning signals but is later switched to "Remove-Easy" to prevent RL from over-prioritizing LPL at the cost of accuracy. In the final stage, token budget and penalties are further increased to tighten latency without large accuracy regressions.
RL is performed with off-policy objectives (DAPO/GRPO/CISPO), and additional high length penalties (HLP) are introduced in late stages to further compress LPL.
Empirical Evaluation
Metrics and Baselines
DC-CoT and its HLP variant are evaluated across several mathematical reasoning benchmarks: AIME 2024, AMC 23, HMMT Feb 2025, MATH 500, Minerva Math, and Olympiad-Bench. Metrics are pass@1 and majority@3 accuracy, as well as longest path length. Baselines include DeepScaleR-1.5B-Preview (at various token limits), high length-penalized retrained DeepScaleR variants, and test-time aggregation via majority voting.
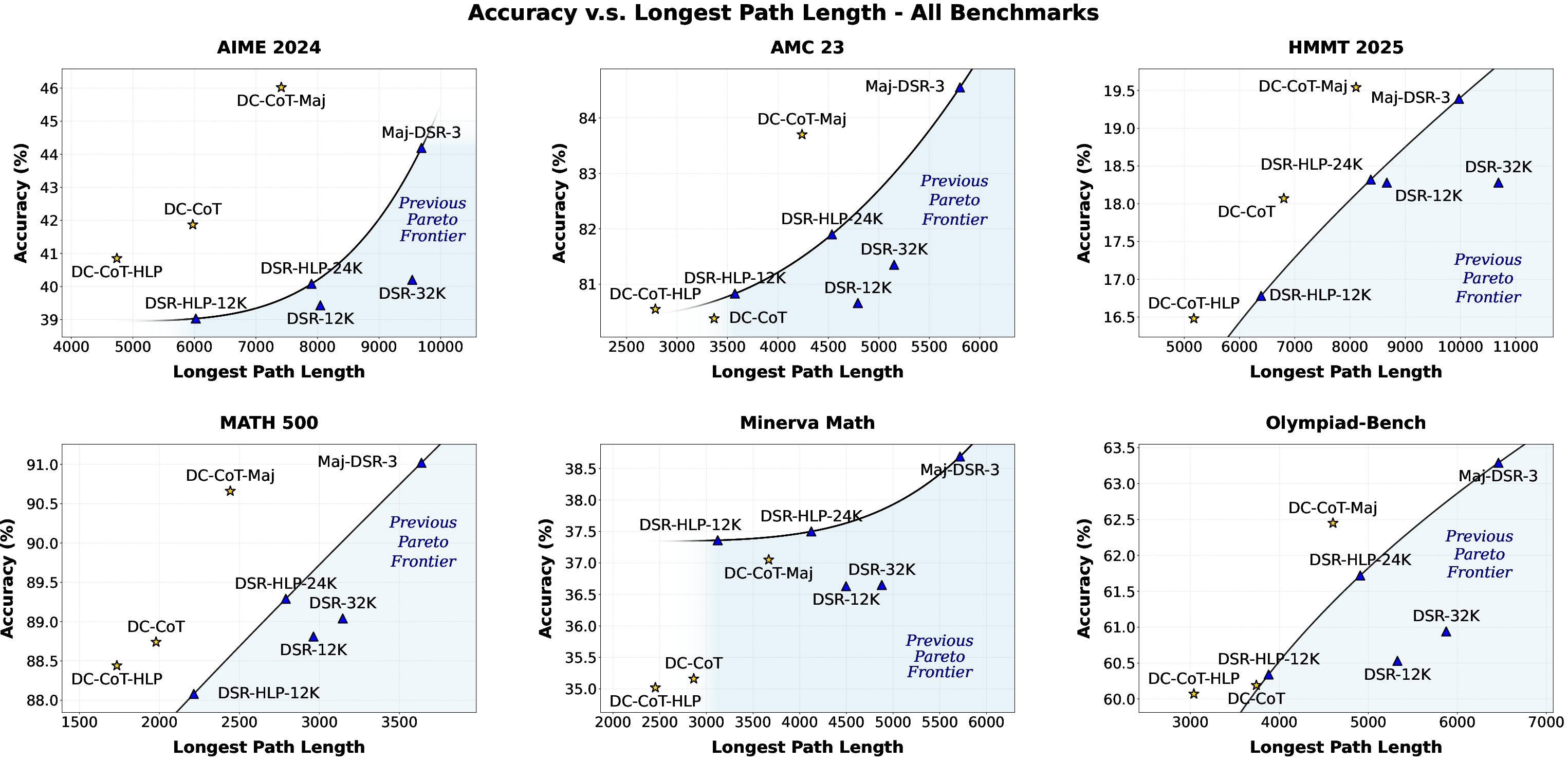
Figure 3: Accuracy (pass@1) and longest path length for all methods on all benchmarks, demonstrating the Pareto improvement of DC-CoT.
Main Results
DC-CoT achieves comparable or improved accuracy relative to DeepScaleR-1.5B-Preview at reduced LPL, particularly on math benchmarks with decomposable structure. Specifically, on AIME 2024, DC-CoT yields a 37.4% reduction in LPL compared to DSR-32K, with increased accuracy (Figure 1; Table 1 in the paper). Under HLP, LPL reductions approach 20–40% with minimal accuracy loss, showing strong tradeoff control. When combined with majority voting, DC-CoT also surpasses baseline aggregation in both accuracy and efficiency.
RL Training Dynamics
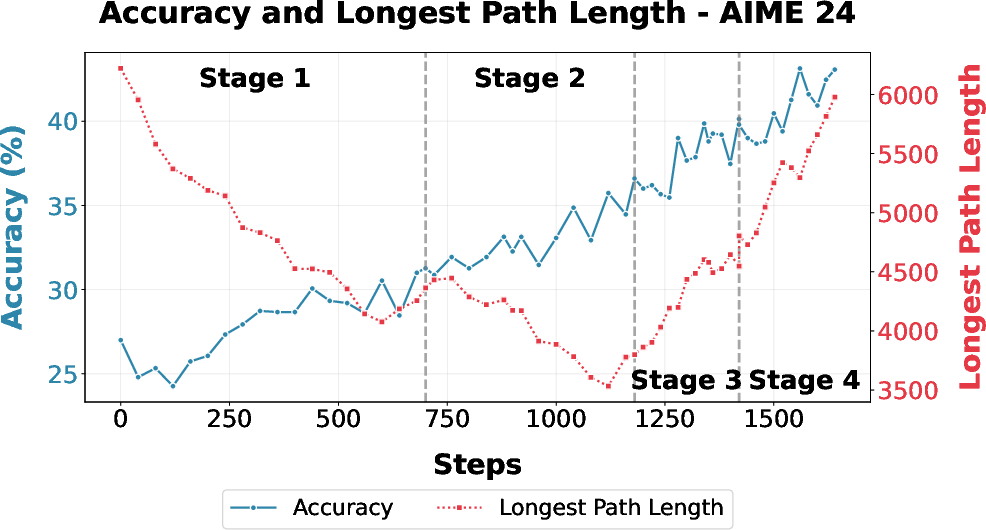
Figure 5: Accuracy and longest path length of DC-CoT on AIME 2024 over the RL curriculum, highlighting monotonic gains via staged RL and adaptive filtering.
- DAPO-based training increases the frequency of parallelization but encounters entropy-induced plateaus.
- CISPO stabilizes policy entropy and enables further accuracy gains, evidenced by the monotonic improvements in (Figure 5).
- Data filtering strategy shifts directly influence convergence behavior: removing "easy" (all-correct) samples helps overcome accuracy plateaus induced by over-optimizing for LPL.
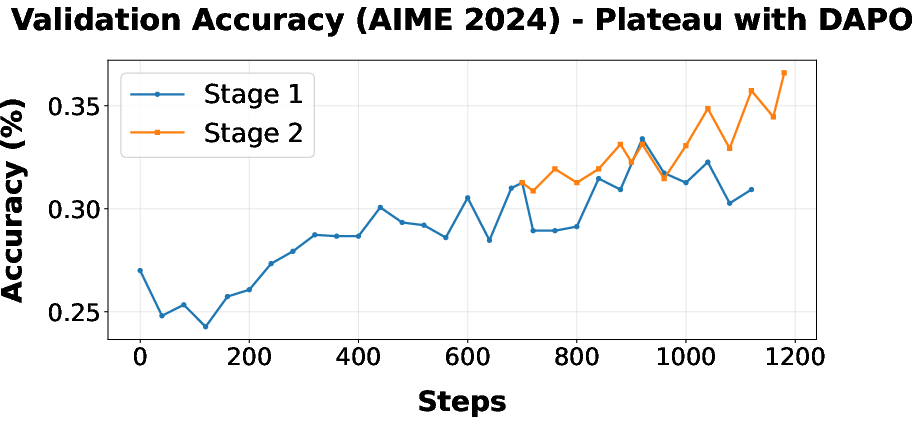
Figure 7: DAPO plateaus in accuracy during initial RL, but switching to CISPO resumes monotonic improvement.
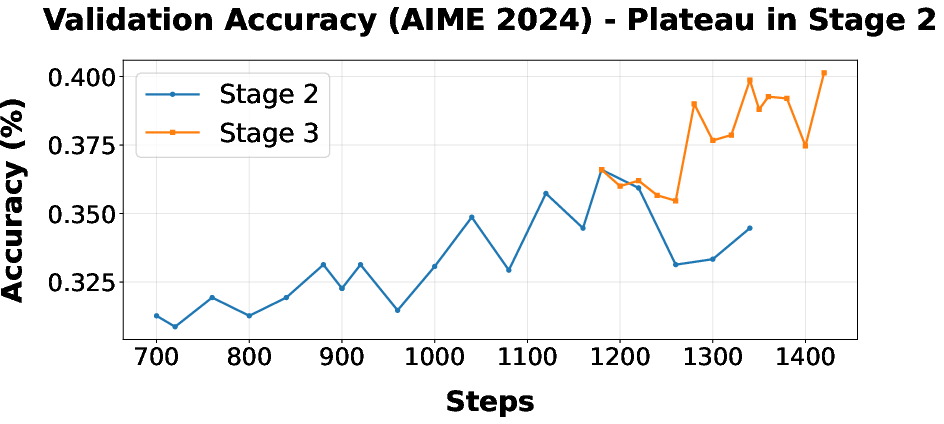
Figure 2: Plateauing in Stage 2 under "Include-Easy" filtering, resolved in Stage 3 by "Remove-Easy" strategy.
Entropy and Parallelism Analysis
The evolution of model entropy and degree of parallelism during training reveals that excessive entropy growth can degrade deterministic reasoning, and the overall reduction in sequential generation (as quantified by degree of parallelism metrics) correlates closely with LPL improvements.
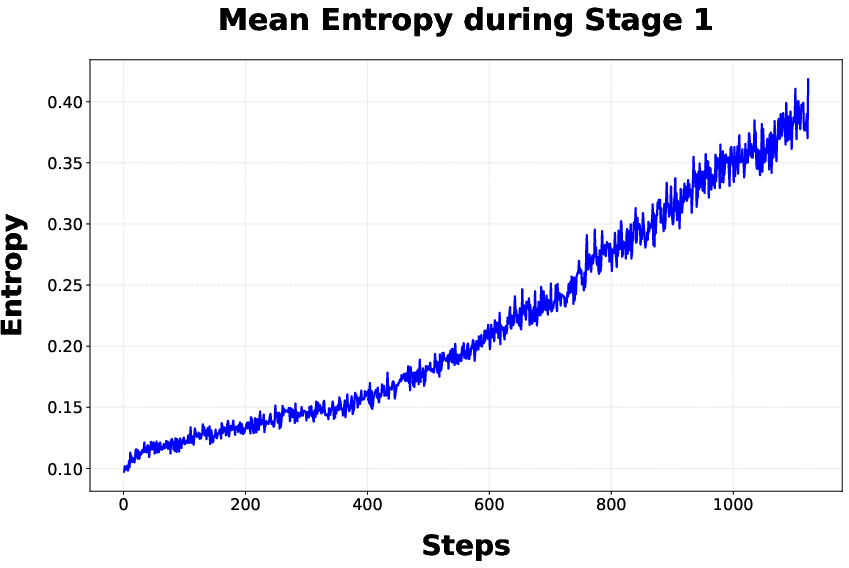
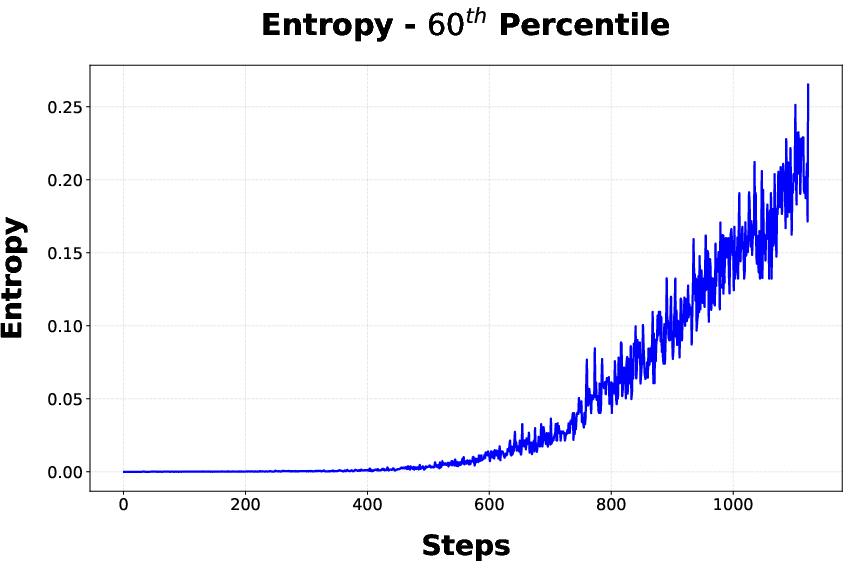
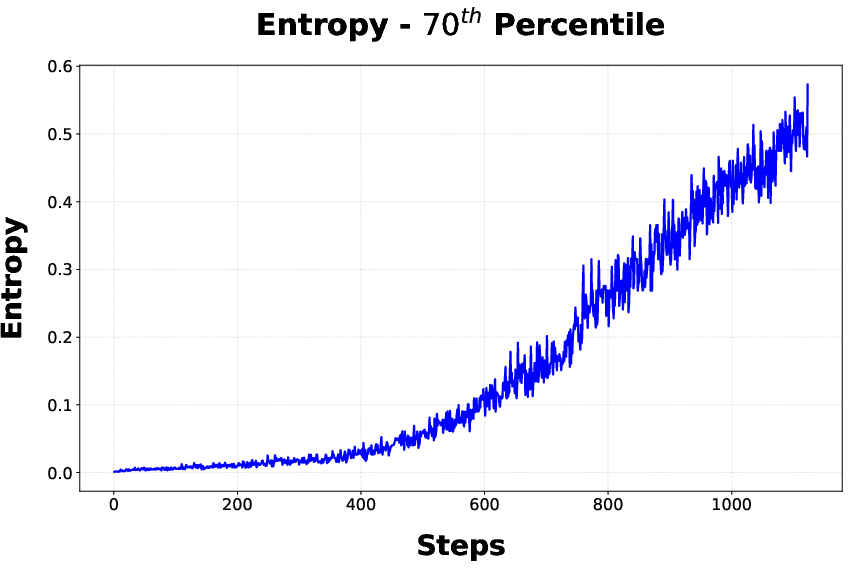
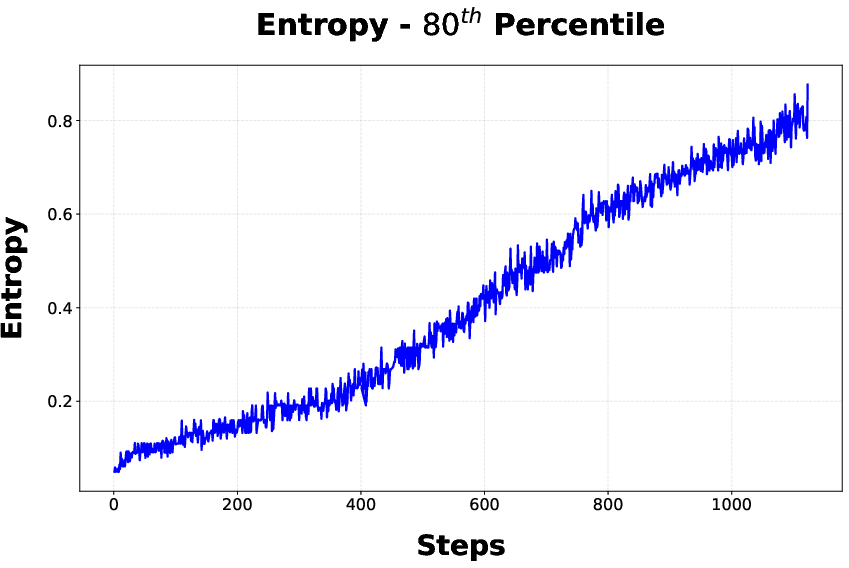
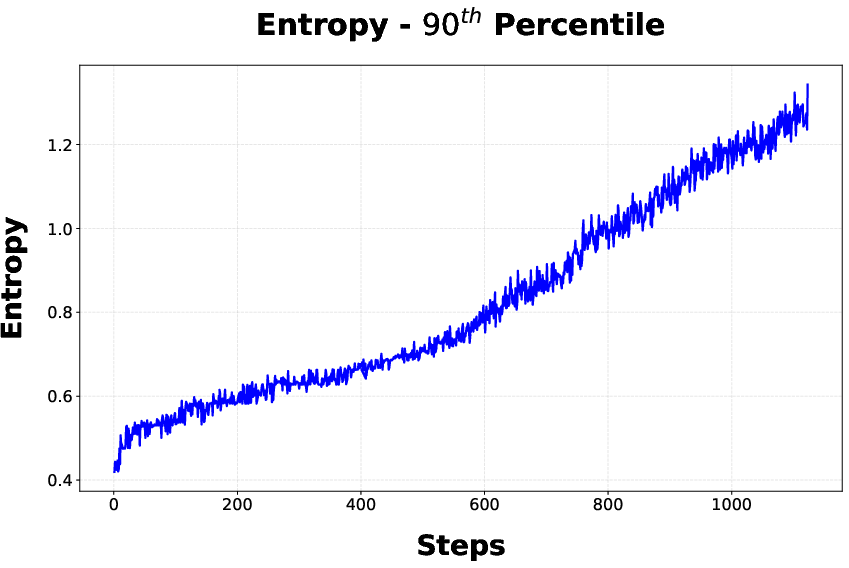
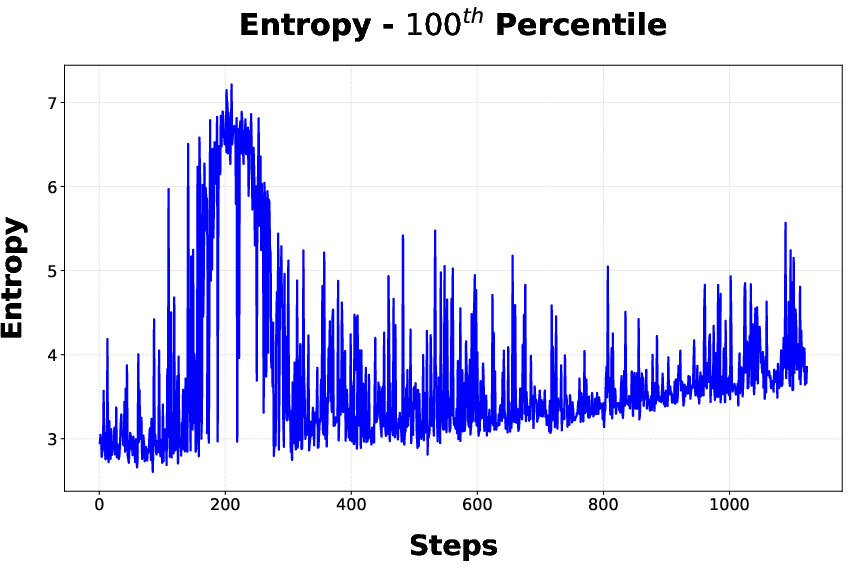
Figure 4: Entropy statistics during stage 1, with DAPO driving up mean entropy across tokens—correlated with the observed accuracy plateau.
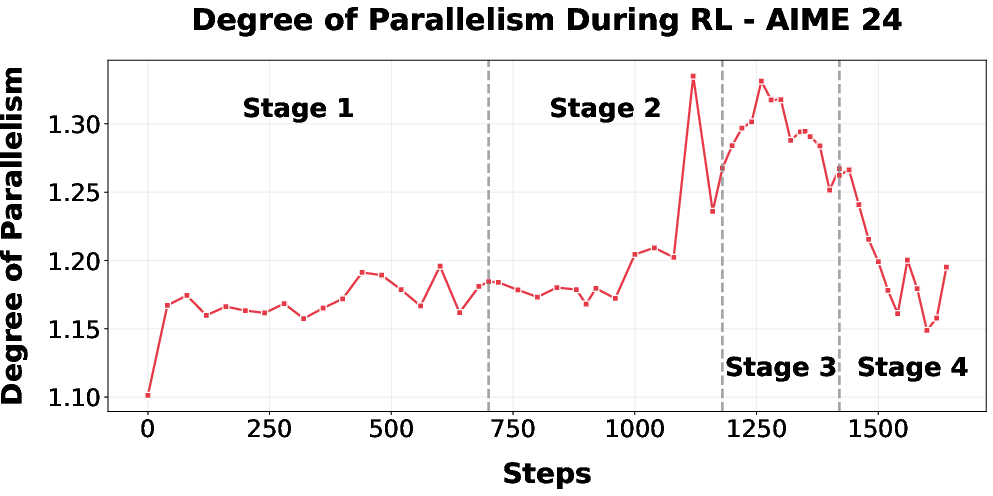
Figure 11: Degree of parallelism of DC-CoT on AIME 2024, rising during early RL and modulated by filtering strategy adaptations.
Implications, Limitations, and Future Directions
DC-CoT demonstrates that explicit training for parallel reasoning outperforms inference-time-only approaches (e.g., independent sampling, aggregation) in optimizing both accuracy and latency. Notably, DC-CoT can be stacked atop strong sequential RL reasoning models, unlike many prior parallelization approaches that start from instruction-tuned LLMs or non-reasoning models.
While DC-CoT achieves substantial LPL reductions without severe accuracy costs in decomposable domains, its gains are limited in datasets with inherently sequential structure (e.g., Minerva Math), suggesting that the effectiveness of parallel reasoning is task-dependent and warrants flexible orchestration modules capable of adaptively identifying parallelization opportunities.
Future research should consider integrating DC-CoT with advanced task decomposition planners, continual RL curriculum shaping (e.g., entropy scheduling based on RL dynamics), and compositional self-refinement during aggregation. Extending DC-CoT to larger models and multimodal reasoning settings could further stress-test its generalizability and influence practical deployment for latency-sensitive reasoning applications.
Conclusion
"Divide-and-Conquer CoT: RL for Reducing Latency via Parallel Reasoning" (2601.23027) establishes a robust framework for leveraging agentic parallel reasoning in LLMs. By innovatively combining SFT with staged RL and reward shaping, DC-CoT matches or surpasses state-of-the-art sequential approaches while substantially reducing inferential latency. The methodology provides a foundation for future advances in efficient, scalable, and adaptive LLM reasoning, with core insights applicable across multi-agent, agentic orchestration, and parallel-inference research themes.