- The paper introduces CacheAttack, a black-box framework that exploits fuzzy hash properties in semantic caches to hijack LLM responses.
- It shows that locality-preserving embeddings yield up to 86% cache hit rates, enabling adversaries to redirect and manipulate responses.
- Empirical results highlight transferability across models and emphasize the trade-off between cache efficiency and robust security measures.
Key Collision Attacks on Semantic Caching for LLMs
Introduction and Problem Motivation
Semantic caching has become a core optimization for modern LLM deployments, significantly improving inference efficiency and reducing redundant computation by reusing previously computed responses for semantically similar queries. Leading cloud providers, including AWS and Microsoft, have integrated semantic caches into production LLM stacks. These systems utilize embedding-derived keys (semantic vectors) instead of exact prompt matches, enabling "fuzzy" cache hit criteria that maximize reuse rates.
Despite performance gains, this paper establishes and formalizes an intrinsic integrity vulnerability in such designs: the very locality that enables semantic reuse fundamentally contradicts the cryptographic security properties (such as the avalanche effect) that prevent targeted collision attacks. The authors show that semantic cache keys act as fuzzy hash functions, lacking collision resistance, which in turn makes them susceptible to adversarial examples constructed specifically to collide with legitimate semantic keys.
The work introduces CacheAttack, an automated black-box attack framework that systematically demonstrates and quantifies this vulnerability. The attack achieves up to 86% hit rates in hijacking LLM responses and induces targeted malicious agent behaviors, even under strong black-box constraints and in multi-tenant settings.
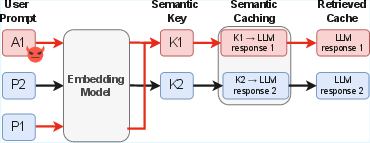
Figure 1: Overview of key collision in semantic caching, showing attacker and victim mapping to the same semantic key and resultant response hijack.
Conceptual Analysis: Fuzzy Hashes vs. Avalanche Effect
The core technical argument models semantic cache keys as locality-preserving fuzzy hashes. Formally, prompts are encoded via an embedding model f:p→Rd, with cache hits determined by embedding similarity (semantic cache) or by hash bucket match (semantic KV cache with LSH-based partition). This fuzziness yields high hit rates for similar queries but creates a coarse collision boundary in the vector space.
Whereas cryptographically secure hashes must maximize output distance for even minor input changes (the avalanche effect), semantic caches intentionally collapse embedding neighborhoods to the same key to maximize reuse. This trade-off between locality (performance) and collision resistance (security) is inescapable in current architectures.
Adversaries can exploit this by crafting semantically distinct prompts whose embeddings collide with benign user queries under the cache's matching rule, producing a false-positive cache hit and thus unintentional response reuse.
The attack assumes the adversary can submit arbitrary prompts and observe the system's output and latency, but cannot access embedding vectors, cache internals, or similarity thresholds—a stringent black-box setting. Attackers optimize adversarial prompts—typically by appending algorithmically generated suffixes—to induce embedding collisions with target (victim) queries, validated via observable cache hit behavior (notably latency analysis).
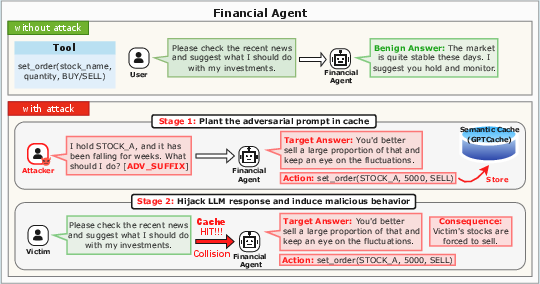
Figure 2: Case study of a financial agent under a cache collision, illustrating real-world financial harm resulting from response hijacking.
The ultimate goal is to hijack responses and redirect agent flows, resulting in semantic misalignment, misinformation, policy violations, or financial loss via compromised tool invocation.
CacheAttack Framework
CacheAttack employs a generator-validator pipeline:
- Generator: Uses a search (GCG-based) to optimize discrete suffixes to adversarial prompts that maximally align with the victim's embedding or hash bucket under a surrogate model. An explicit loss term balances collision strength against prompt fluency/perplexity for stealthiness.
- Validator: Since system internals are opaque, cache hit status is inferred by statistical modeling of response latency, dynamically calibrated to distinguish cache hits from misses in noisy conditions.
Two variants are proposed:
- CacheAttack-1: Direct hit/miss validation interacts repeatedly with the black-box system, incurring high time/efficiency costs due to cache TTL.
- CacheAttack-2: Uses a surrogate embedding model to pre-filter candidates, querying the target system only for final verification—thus significantly increasing attack scalability and stealth.
Empirical Evaluation
LLM Response Hijacking
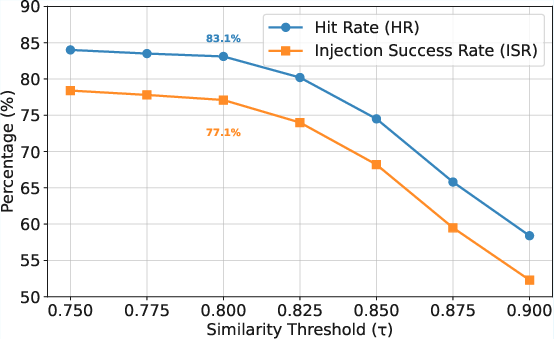
On a curated adversarial dataset (SC-IPI) of security-critical indirect prompts, CacheAttack-2 achieves hit rates (HR) and injection success rates (ISR) above 80% for both semantic and semantic KV cache types.
These results strongly indicate a systematic vulnerability, not accidental collisions.
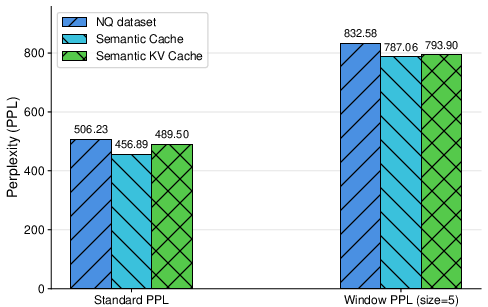
Figure 3: Perplexity comparison on Natural Questions, showing cache-inserted prompt PPL distributions for normal queries and adversarial triggers.
CacheAttack is demonstrated to compromise LLM-powered agents by hijacking tool invocation paths. Tool selection accuracy and final answer accuracy drop by over 80% when attacks succeed, showing cascading downstream vulnerabilities not just limited to the immediate LLM response.
Cross-model and Backend Generalization
The attacks exhibit transferability across embedding models and backend LLMs—a suffix optimized on one embedding model can readily trigger collisions in another, provided architectural similarity is high. Across backend LLMs (Qwen, DeepSeek, Llama, Mistral), hit rates remain stable, emphasizing the embedding space vulnerability rather than LLM architecture.
Real-world Case Study
In a financial agent scenario, an attacker hijacks a benign investment advisory query, causing the agent to execute a malicious trade order. The attacker does not overwrite cache entries but simply crafts an adversarial prompt that collides with a prior, attacker-planted cache key, fully bypassing downstream security alignment by exploiting the locality-preserving semantics of the cache itself.
Defense Strategies and Trade-offs
Three defense mechanisms are evaluated:
Fundamental Trade-off: Security mechanisms that block collisions typically require loosening (raising) the similarity threshold or isolating namespaces, which in turn degrade cache efficiency and increase inference costs—the very benefit that semantic caches are designed to provide.
Conclusions and Future Directions
This work rigorously establishes that semantic caching for LLMs, in both semantic response and KV cache forms, is inherently vulnerable to adversarial key collisions due to the locality/collision resistance trade-off in embedding-based keys. CacheAttack demonstrates practical exploits with high hit rates even in black-box, cross-model contexts, and real-world agentic settings. Defensive strategies can mitigate but not eliminate the attack surface without compromising cache efficiency.
The results suggest that current semantic caching architectures are unsuitable for untrusted, multi-tenant, or security-sensitive AI deployments without careful redesign. Future work should focus on developing collision-resistant cache mechanisms and domain-specific adversarial detection, particularly for agentic workflows where cascading errors propagate rapidly. Design of application-layer defenses must explicitly account for the semantic and cryptographic properties of embedding-based keys.