- The paper proposes ReGuLaR, a novel latent reasoning method that leverages a VAE framework with rendered Chain-of-Thought for efficient reasoning.
- It integrates visual-semantic guidance through rendered reasoning chains and frozen encoders to optimize latent state sampling and compress information.
- Experimental results show state-of-the-art performance and robust scalability across diverse datasets and model sizes in both text and multi-modal tasks.
ReGuLaR: Variational Latent Reasoning Guided by Rendered Chain-of-Thought
Introduction
The paper "ReGuLaR: Variational Latent Reasoning Guided by Rendered Chain-of-Thought" (2601.23184) introduces an innovative approach to improving the computational efficiency and reasoning effectiveness of LLMs. While Chain-of-Thought (CoT) techniques enhance LLMs through explicit reasoning chains, this leads to substantial computational redundancy. The paper proposes a novel latent reasoning paradigm, ReGuLaR, leveraging a variational auto-encoding framework that uses rendered reasoning chains as visual-semantic guides for compression, thereby providing efficient and insightful latent reasoning.
The core challenge addressed is the inefficiency inherent in explicit token-by-token generation in CoT, which results in prohibitive computational overhead. Recent latent reasoning approaches compress reasoning processes into continuous latent spaces but suffer from performance degradation due to inadequate compression guidance. ReGuLaR formulates latent reasoning within a VAE framework, sampling reasoning states from a posterior distribution conditioned on prior ones and regulated by visual-semantic representations obtained from rendered reasoning chains.
Methodology
ReGuLaR extends latent reasoning by integrating visual modalities, rendering reasoning chains as images to extract dense representations that guide latent state sampling. The process begins by segmenting the reasoning chain into smaller parts, which are then visualized and encoded. These visual embeddings serve as anchors for modeling the prior distribution of latent reasoning states, ensuring efficient compression and minimizing information loss.
In practice, ReGuLaR achieves this by employing a combination of rendering functions and frozen visual encoders, maximizing semantic density while minimizing computational overhead. The latent reasoning model is optimized by balancing the Evidence Lower Bound (ELBO) of the reasoning process, including both reasoning and answer generation losses. A critical component of the approach is the KL divergence term, which regularizes the posterior distribution to align it closely with the semantically rich and information-preserving prior derived from visual representations.
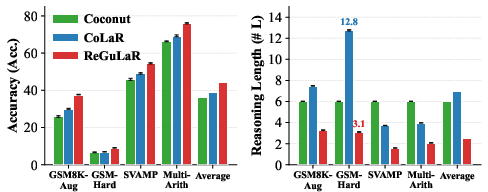
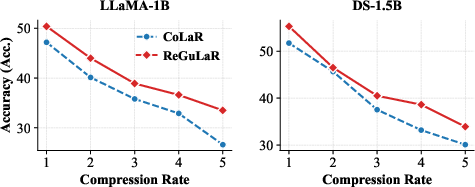
Figure 1: Generalizability analysis demonstrates robust performance across different model sizes and datasets.
Experimental Results
Extensive experiments validate the superiority of ReGuLaR over existing latent reasoning methods. ReGuLaR achieves state-of-the-art performance across multiple datasets, including GSM8K-Hard and AQUA-RAT, while demonstrating substantial gains in computational efficiency by reducing reasoning lengths significantly.
Additionally, an ablation study reveals the model's robustness across various rendering configurations and encoder modes, confirming the dense information compression capability of visual modality compared to text-based variants. The scalability analysis further illustrates ReGuLaR's positive scaling behavior across different model sizes, from LLaMA-3.2 1B to 8B Instruct variants, establishing its potential for broader application in large-scale foundation models.

Figure 2: Scalability analysis across varying model sizes highlights ReGuLaR's ability to maintain performance across scales.
Multi-modal Reasoning
A notable advantage of ReGuLaR is its native support for multi-modal reasoning. By incorporating non-textual elements alongside text in the reasoning process, ReGuLaR not only mitigates textual information loss but also surpasses explicit CoT techniques in complex scenarios. This capability is exemplified in molecular captioning tasks, where ReGuLaR integrates 2D molecular graphs with textual reasoning chains, achieving superior performance in comprehensive reasoning tasks.
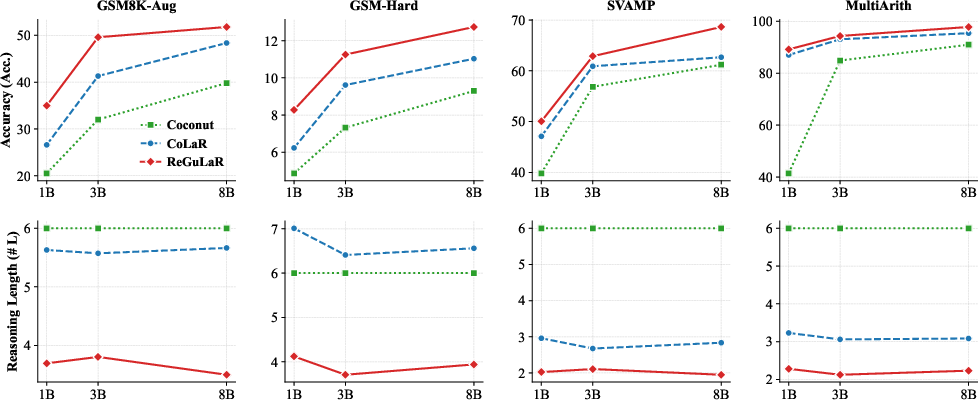
Figure 3: Rendered reasoning chains with 2D demonstrate the multi-modal integration for complex reasoning tasks.
Conclusion
ReGuLaR provides an insightful solution to latent reasoning by effectively balancing computational efficiency and reasoning effectiveness. Through its novel integration of visual-text modalities, it surpasses existing methods in compression capability and generalizability while offering broad scalability potential for larger models. Future work aims to expand upon ReGuLaR's capabilities by developing more challenging evaluation benchmarks, further exploring the theoretical foundations of latent reasoning, and enhancing multi-modal integration.