Scaling Multiagent Systems with Process Rewards
Abstract: While multiagent systems have shown promise for tackling complex tasks via specialization, finetuning multiple agents simultaneously faces two key challenges: (1) credit assignment across agents, and (2) sample efficiency of expensive multiagent rollouts. In this work, we propose finetuning multiagent systems with per-action process rewards from AI feedback (MAPPA) to address both. Through assigning credit to individual agent actions rather than only at task completion, MAPPA enables fine-grained supervision without ground truth labels while extracting maximal training signal from each rollout. We demonstrate our approach on competition math problems and tool-augmented data analysis tasks. On unseen math problems, MAPPA achieves +5.0--17.5pp on AIME and +7.8--17.2pp on AMC. For data analysis tasks, our method improves success rate by +12.5pp while quality metrics improve by up to 30%, validating that per-action supervision can lead to improvements across different multiagent system on various domains. By addressing these challenges, our work takes a first step toward scaling multiagent systems for complex, long-horizon tasks with minimal human supervision.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (big picture)
This paper shows a new way to train a team of AI helpers to work together better on long, hard tasks. Instead of only giving the team a single grade at the very end (pass/fail), the authors give small, helpful scores after each step the AIs take. They use another AI as a “coach” to watch what each teammate does and give fair, step-by-step feedback. This approach is called MAPPA: MultiAgent systems with Per-action Process rewards from AI feedback.
What questions the authors asked
The paper tackles two simple but important questions:
- In a team of AIs, how do you know which teammate helped or hurt the final result? (Who deserves credit or blame?)
- How can we teach these teams efficiently, when each full attempt takes a long time but normally gives only one final score?
Their idea: let a coach AI score each action as it happens, so every step becomes a learning opportunity and credit is given to the right teammate.
How they did it (methods in everyday language)
Think of a school group project with three students:
- One plans the solution,
- One writes code to test it,
- One checks the final answer and submits it.
Now add a coach (like a teacher’s aide) who watches every step, sees the code’s errors, and knows each student’s job. After each action, the coach gives a score from 0 to 10 and explains what went well or wrong. If the coder can’t find a file because the planner didn’t create it, the coach lowers the planner’s score, not the coder’s. That’s called “credit assignment.”
Here’s how the system works behind the scenes:
- Multiple AI agents with different roles work in a set order (a pipeline). They can also use tools, like running Python code in a safe “sandbox.”
- A separate “coach” AI reads the role, the action taken, and any tool results (including error messages). It gives a per-action score (process reward) on a 0–10 scale.
- The agents are trained with reinforcement learning (RL). In plain terms: they try, they get feedback, and they adjust to do better next time. The authors use a stable RL method (REINFORCE++) that helps the agents learn smoothly, even when each run looks a bit different.
- A gentle “stay close” nudge keeps each agent from changing too wildly at once, similar to practicing new skills without forgetting what already works.
- Training is distributed across many computers so lots of attempts and coach evaluations can happen in parallel.
They tested this on two kinds of teamwork:
- MathChat (competition math): three agents called Problem Solver, Code Executor, and Verifier solve AIME/AMC math problems, sometimes by writing and running code to check answers.
- DSBench (data science pipelines): three agents called Data Engineer, Modeler, and Analyst turn CSV files into a trained model and a final submission file, with real accuracy/error metrics available.
What they found and why it matters
The coach’s step-by-step scores helped the teams learn faster and more fairly than a single end-of-task grade. Key results:
- Competition math (AIME/AMC):
- Accuracy improved by about +5.0 to +17.5 percentage points on AIME and +7.8 to +17.2 points on AMC, depending on the base model size.
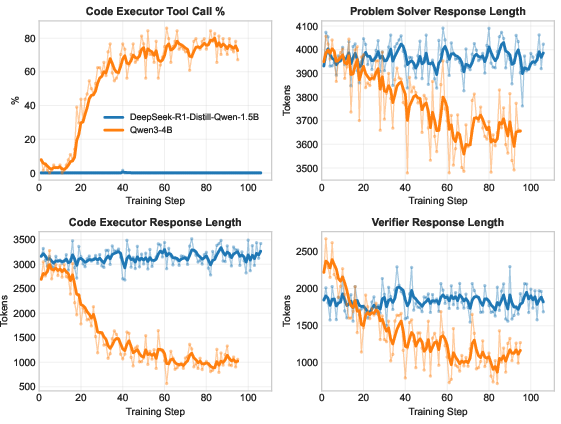
- The larger model learned stronger habits (like using tools more effectively and writing shorter, cleaner responses), showing the process rewards taught good behavior, not just final answers.
- Data science pipelines (DSBench):
- Overall success rate improved by +12.5 percentage points.
- Quality metrics (like error rates) improved by up to 30%.
- Because the coach sees which files are created and what errors happen, it can assign credit or blame to the right agent (e.g., Data Engineer vs. Modeler vs. Analyst). That targeted feedback helps each role improve at what matters most.
They also discovered something interesting: over longer training, the team got better at regression tasks but slipped a bit on classification tasks. The authors traced this to a scoring bias: the coach tended to give slightly higher scores to regression work. This shows coach quality and fairness matter—a lot.
Why this matters:
- Per-action coaching turns every step into useful training data, which is more efficient and fair.
- Proper credit assignment helps specialized teammates improve without stepping on each other’s toes.
- Teams of smaller, specialized AIs—properly trained—can become both cheaper and better at complex, multi-step jobs.
What this could mean going forward
- Smarter team training: Using a coach AI to give step-by-step feedback can scale up multi-agent systems for hard, long tasks (like data science, research, or software) while reducing human supervision.
- Better specialization: Different teammates can safely get better at their unique roles without “forgetting” or interfering with each other.
- Caution about bias: If the coach has preferences (for example, favoring certain task types), the team may over-focus there. Future work could use multiple coaches, coach training, or history-aware coaching to reduce bias.
- Richer feedback: Beyond a single score, coaches could suggest fixes or show better examples, mixing RL with direct teaching.
- Larger teams: The same idea could scale to many agents working together on real-world, long projects—if we keep an eye on fairness, reliability, and “reward hacking” (optimizing the score without truly solving the task).
In short: Giving AIs a helpful coach that scores each step—not just the final outcome—makes multi-agent teams learn faster, specialize better, and solve complex tasks more reliably.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of what remains missing, uncertain, or unexplored in the paper, framed as actionable items for future research:
- Quantify the accuracy of coach-based credit assignment by constructing datasets with explicit causal labels for which agent’s action caused success/failure, and evaluate the coach’s attribution precision/recall against these labels.
- Systematically measure coach bias across task types (e.g., regression vs classification), verbosity, and style; develop calibration or debiasing methods (e.g., isotonic regression, score rescaling, or constrained scoring) and report their impact on training stability and final performance.
- Compare different coach models (frontier vs mid-tier vs small) in controlled ablations to characterize variance, reliability, and sample efficiency; include coach ensembles and aggregation schemes (majority vote, weighted averaging, disagreement-aware scoring).
- Clarify and ablate the reward scale: the text uses 0–10 ratings but the training section refers to ; specify the mapping, test alternative discretizations (e.g., {1–5, 0–100} or continuous), and study sensitivity to scaling and normalization.
- Establish robustness of process rewards when ground truth is absent for all steps: quantify failure modes where plausible-but-wrong actions accumulate positive coach scores, and evaluate guardrails to prevent “process-only” reward hacking.
- Evaluate the coach’s ability to interpret tool outputs and environment feedback at scale: measure how missing, noisy, or ambiguous tool logs affect reward accuracy, and develop resilient evaluation prompts or structured logging schemas.
- Benchmark MAPPA across diverse multiagent topologies beyond sequential pipelines (e.g., debate, hierarchical planners, mixture-of-agents, routing/gating) to validate generality and identify topology-specific reward designs.
- Scale to larger agent populations (dozens+) and measure how process rewards and global advantage normalization behave under high interdependence; study gradient interference, credit dilution, and compute/communication bottlenecks.
- Provide multi-seed runs, confidence intervals, and significance testing for reported gains (MathChat and DSBench) to assess statistical reliability, especially with small held-out sets.
- Explore discount factors and return shaping: ablate undiscounted return-to-go vs discounted returns (), reward baselines, and per-agent return aggregation to improve credit propagation across long horizons.
- Compare REINFORCE++ against alternatives (PPO variants, actor-critic, GRPO variants adapted to non-identical states, off-policy methods) under identical settings to validate algorithm choice and sample efficiency.
- Analyze KL penalty () sensitivity, per-token KL handling for think/tool code blocks, and length-normalization effects; ensure longer outputs aren’t disproportionately penalized or advantaged.
- Introduce richer coach outputs (rationales, suggested corrections, counterfactual actions) and integrate them via SFT/DPO+RL hybrids; quantify the exploration–exploitation trade-offs and sample efficiency gains.
- Implement and evaluate “reward backpropagation” (Appendix) where outcome blame/credit is systematically traced backward through the pipeline; measure improvements over independent per-step scoring.
- Prototype a trainable coach and study training signals (meta-evaluation, agreement with verifiers, human feedback), stability, and the risk of degenerate equilibria when coaches and agents co-evolve.
- Develop an “agent-as-a-coach” with memory, training-aware strategies, and curriculum (e.g., stabilize completion first, then optimize quality); quantify whether strategic scoring improves multi-objective performance and mitigates coach drift.
- Formalize and test safeguards against reward hacking: define behavioral metrics (tool call rate, response length, error incidence) and anomaly detectors; evaluate whether elevated coach scores consistently co-occur with improved task outcomes.
- Extend DSBench evaluation with more tasks or synthetic variants to reduce variance; assess cross-dataset generalization (Kaggle-like benchmarks, AutoML datasets) and task complexity scaling.
- Examine partial-information training regimes more deeply: quantify how context visibility constraints per agent affect learning, credit assignment reliability, and emergent specialization.
- Study artifact management at scale (file passing, schema validation, serialization formats) and failure recovery (missing/corrupt files); design coach prompts and policies to handle artifact lifecycle robustly.
- Address sandbox security and reliability for code execution: evaluate defenses against harmful or resource-exhaustive code, and quantify the coach’s capacity to detect and penalize unsafe behaviors.
- Analyze truncation effects due to 4K token caps (including think tokens): measure how truncation impacts action quality and coach scoring, and propose adaptive limits or summarization mechanisms.
- Investigate dynamic turn budgeting and early termination policies (e.g., stop when confidence or quality thresholds are met); measure impacts on compute cost and success rate.
- Clarify reproducibility details (tokenization, sampling, reference model configurations, prompt variants, tool stack versions) and provide standardized evaluation harnesses to enable consistent replication.
- Explore cross-domain applicability (coding, scientific workflows, planning, knowledge-intensive QA) to validate domain agnosticism; identify domain-specific reward templates and coach competencies needed.
- Evaluate fairness metrics integration into training (not just selection), including multi-metric aggregation schemes that prevent per-metric reward hacking and align with downstream objectives.
- Quantify the coach’s causal reasoning limits: design counterfactual tests (e.g., perturbed logs, swapped artifacts) to evaluate whether the coach correctly assigns blame/credit under adversarial or ambiguous conditions.
- Examine information asymmetry effects: since the coach sees environment feedback agents cannot, test whether aligning agent-visible diagnostics (e.g., structured error surfaces) improves learning and reduces reliance on opaque coaching signals.
- Assess compute and throughput scaling of the distributed training stack (Ray, vLLM, ZeRO-3): provide profiling, cost models, and strategies (co-location, batching, asynchronous coaching) to reach practical deployment with larger systems.
- Validate that improvements transfer to single-pass evaluation (no resampling per problem) and to different temperatures; establish guidelines for inference-time settings that retain gains from process-based training.
- Provide ablations on prompt design for role specialization vs weight specialization: measure how much improvement comes from finetuning versus prompt engineering, and whether prompts remain robust post-training.
Practical Applications
Immediate Applications
The paper presents a novel method for improving multiagent systems using per-action process rewards from AI feedback. Here are some potential immediate applications across different sectors:
Industry
- Software Development
- Automated Code Review: Use the process reward framework to implement automated code reviewers that provide developers with specific feedback on code quality and improvements during the coding process.
- Continuous Integration Pipelines: Enhance CI/CD pipelines by integrating multiagent systems that dynamically allocate specialized agents to optimize various stages like testing, quality assurance, and deployment.
Academia
- Educational Tools
- Intelligent Tutoring Systems: Develop learning platforms where each topic or area of study can be tackled by specialized teaching agents, providing students with tailored feedback and guidance.
- Research Collaboration: Leverage this approach in collaborative research tools to distribute tasks dynamically among virtual research assistants based on specialization.
Policy
- AI Governance
- Policy Simulation: Use multiagent systems to simulate policy impacts across sectors, with individual agents representing different stakeholders (e.g., governmental bodies, businesses, citizens).
- Automated Regulatory Compliance: Implement systems that ensure new software or policies automatically comply with regulatory standards through specialized agents.
Long-Term Applications
While the paper provides a strong foundation, further research and development could enable broader applications:
Industry
- Large-Scale Manufacturing
- Industrial Robotics: Deploy multiagent systems for real-time coordination and adaptability in smart factories, where agents can allocate resources efficiently and handle complex manufacturing processes.
Academia
- Interdisciplinary Research
- Complex Systems Analysis: Long-term development of multiagent systems can lead to advanced models for analyzing and designing complex, interdisciplinary systems (e.g., urban planning, ecological models).
Policy
- Global Impact Analysis
- Climate Change Modeling: Extend this framework to create detailed simulations of climate change impacts and responses by governments, improving predictions and strategies through comprehensive analysis.
Daily Life
- Personal Assistants
- Smart Home Management: Implement multiagent systems in smart home ecosystems for efficient management of resources like energy consumption, security, and personal schedules.
- Health Management: Extend health monitoring to provide dynamic, personalized health recommendations or interventions by deploying specialized agents focused on different health aspects.
Assumptions and Dependencies
The feasibility of these applications depends on several factors:
- Assumptions
- The scalability of multiagent systems and their integration with existing technologies.
- Availability and accessibility of high-performance computing resources to support these systems during training and deployment.
- Dependencies
- Continuous development and refinement of AI models and reinforcement learning algorithms.
- Organizational willingness to adopt and invest in advanced AI-driven systems.
- Robust frameworks for AI ethics and governance to ensure these systems operate within acceptable societal norms.
Glossary
Agentic Systems: Refers to systems composed of agents that are capable of making independent decisions and taking actions towards achieving goals. "Building on these capabilities, multiagent systems---where multiple LLM-based agents interact to solve complex tasks---offer an intuitive path forward as specializations and the diversity of perspectives can tackle problems better than any single agent."
Catastrophic Forgetting: A phenomenon in machine learning where a model forgets previously acquired knowledge upon learning new information. "Multiagent architectures with separate weights enable specialization through end-to-end training, sidestepping catastrophic forgetting that limits single-model scaling just like mixture-of-experts (MoE) architecture."
Credit Assignment: The process of determining which components of a system are responsible for specific outcomes. "Recent work has begun exploring this direction of fine-tuning agents in multiagent systems simultaneously. However, two significant challenges remain: Credit assignment: How do we attribute the performance of the overall system to actions taken by individual agents?"
Distributed Training: A method of training machine learning models using multiple computing resources simultaneously to increase efficiency and manage large-scale data. "We leverage LLMs as coaches to assess the quality of each agent's action given its role, inputs, and environment feedback such as tool execution results."
LLMs: Extremely large neural networks trained on vast amounts of data, capable of performing a wide range of language processing tasks. "Recent evidence suggests such specialization naturally emerges through reinforcement learning: reasoning models trained solely for accuracy spontaneously develop diverse internal personas and expertise."
Mixture-of-Experts (MoE): A type of machine learning model that uses multiple expert components with different specializations to make predictions. "Multiagent architectures with separate weights enable specialization through end-to-end training, sidestepping catastrophic forgetting that limits single-model scaling just like mixture-of-experts (MoE) architecture."
Multiagent Systems: Systems composed of multiple interacting agents that work together to achieve their objectives. "While multiagent systems have shown promise for tackling complex tasks via specialization, finetuning multiple agents simultaneously faces two key challenges: credit assignment across agents, and sample efficiency of expensive multiagent rollouts."
Process Rewards: A technique in reinforcement learning where rewards are assigned during the process of an action rather than at the completion, providing more granular feedback. "In this work, we propose finetuning multiagent systems with per-action process rewards from AI feedback (MAPPA) to address both."
REINFORCE++: An algorithm for training policies using reinforcement learning that stabilizes policy optimization through global advantage normalization. "We then finetune each agent's underlying model with its actions' corresponding tuples via REINFORCE++."
Sample Efficiency: Refers to the effectiveness of an algorithm in learning from a limited number of samples. "Computational cost: Rollouts of the entire multiagent system can take minutes or even hours, yet yield only a single outcome reward signal."
Sequential Pipeline: A process structure where tasks are completed in a pre-determined order, one after another. "We implement a three-agent sequential pipeline designed to separate reasoning, computation, and verification."
Sparse Outcome Rewards: Rewards given based solely on the outcome of a task, without consideration for the processes leading to the outcome. "Rather than assigning a single sparse reward at trajectory's end according to fixed instructions in LLM-as-a-Judge, we leverage LLMs as coaches to assess the quality of each agent's action."
Tool-Augmented: Referring to systems enhanced by additional specialized tools beyond their basic capabilities. "Building on these capabilities, multiagent systems---where multiple LLM-based agents interact to solve complex tasks---offer an intuitive path forward as specializations and the diversity of perspectives can tackle problems better than any single agent."
Trajectory Tuples: Data structures consisting of ordered data representing the sequence of actions and states in the learning process of an agent. "As shown in Figure, each agent action generates a trajectory tuple $(\text{agent_id}, \text{input}, \text{action}, \text{reward})$ where the reward is provided by the coach evaluation."
Undiscounted Return-to-Go: The total expected future rewards an agent will receive, unadjusted for when the rewards are received. "The KL-penalized reward and advantage are: $r_t = r_t^{\text{coach} - \beta \cdot D_{\text{KL}(\pi_\theta \| \pi_{\text{ref}), \quad A_t = \sum_{\tau \geq t} r_\tau$, where and is the undiscounted return-to-go, propagating downstream rewards to earlier actions."
Collections
Sign up for free to add this paper to one or more collections.