- The paper introduces VoxServe, a unified serving system for streaming-centric SpeechLMs that abstracts model heterogeneity.
- It leverages asynchronous pipelining and dynamic scheduling to achieve 10–20× throughput improvements and lower Time-To-First-Audio.
- Evaluation on multiple models demonstrates near-linear multi-GPU scaling, robust streaming viability, and efficient resource utilization under high load.
VoxServe: A Unified Streaming-Centric Serving System for Diverse Speech LLMs
Introduction and Motivation
Scaling Speech LLMs (SpeechLMs) for real-time, streaming applications introduces acute challenges in system design, driven by the architectural diversity of models and the need for stringent low-latency, high-throughput guarantees. Current serving stacks for SpeechLMs are characterized by fragmented, architecture-specific solutions that lack holistic scheduling and optimization, rendering deployment costly, brittle, and inefficient. The paper "VoxServe: Streaming-Centric Serving System for Speech LLMs" (2602.00269) addresses these systemic gaps by introducing VoxServe—a unified serving framework architected to abstract over SpeechLM diversity, implement model-agnostic system optimizations, and deliver streaming-centric performance.
SpeechLM Inference and Architectural Diversity
Modern SpeechLMs couple LLM-based backbones with audio-specific modules such as neural audio detokenizers and, in some cases, audio encoders for conditioning. The inference workflow is inherently multi-stage: LLMs autoregressively produce audio tokens which are then detokenized to reconstruct waveforms, with many variants employing multi-codebook tokenization, high parameter-count detokenizers, or idiosyncratic data flows.
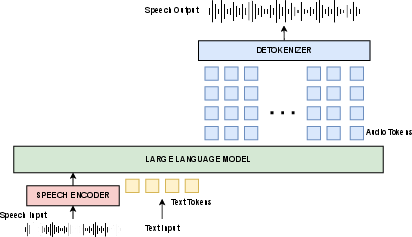
Figure 1: A typical workflow of SpeechLM inference, illustrating the multi-stage nature of token prediction and audio reconstruction.
Approaches differ in the number of codebooks, representation of feature values, and the depth/structure of underlying models, yielding a landscape where model-specific pipelines are the norm.
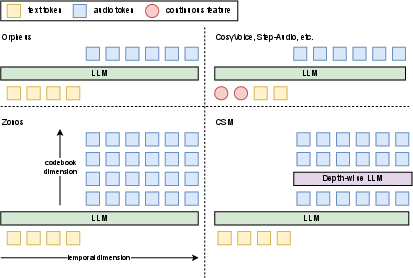
Figure 2: SpeechLM diversity in representing both audio and text data is evident in architectural choices across codebooks, feature value usage, and model granularity.
This diversity complicates integration, system-wide batching, scheduling, and the application of optimizations like CUDA graph capture. Existing stacks, being tightly coupled to specific model families, increase engineering cost and inhibit serving efficiency, particularly as models rapidly evolve.
Fragmentation of Deployment and System Implications
Direct deployment of SpeechLMs is currently hampered by the need for bespoke, tightly-coupled inference stacks. These fail to utilize cross-cutting batching or resource management and make model substitution or upgrade highly nontrivial.
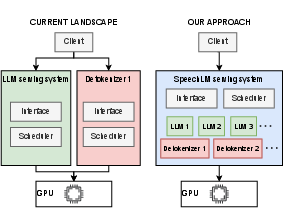
Figure 3: Left—fragmented bespoke inference stacks lead to suboptimal resource management. Right—a unified system allows holistic optimization and rapid integration of novel architectures.
Bespoke approaches also limit the scope for optimizing for streaming-specific metrics—such as minimized Time-To-First-Audio (TTFA) and high streaming viability—key to perceptually seamless and cost-effective deployment.
VoxServe Design: Unified Abstraction and Streaming-Aware Optimization
VoxServe introduces a three-pronged design addressing the above limitations:
- Unified Model Interface: Abstracts over model heterogeneity, exposing a standardized execution boundary (encompassing preprocess, LLM forward, sampling, and postprocess) that supports diverse token/mask/feature conventions and enables effective batched and pipelined execution.
- Scheduler for Streaming: Prioritizes requests dynamically depending on phase (startup vs. steady-state), exploiting slack where streaming viability is not at risk, and aggressively reducing TTFA for new requests.
- Asynchronous Pipeline: Decouples GPU-bound LLM and detokenizer steps from CPU-side state/control, utilizing device streams to overlap processing and further minimize scheduling bottlenecks.
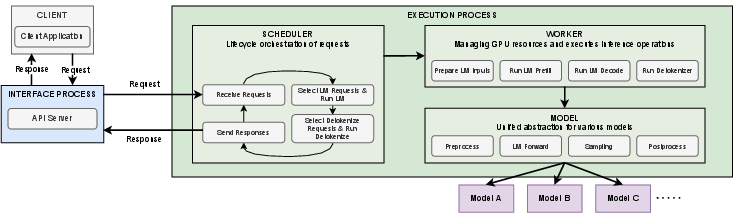
Figure 4: VoxServe architecture with modules for request orchestration, GPU management, and model abstraction enabling system-wide optimization.
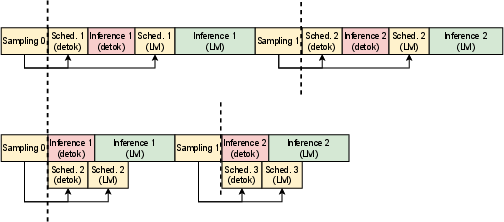
Figure 5: Asynchronous pipelining in VoxServe overlaps compute-intensive tasks, reducing end-to-end latency by exploiting independence between CPU and GPU stages.
VoxServe can therefore realize system-level optimizations—such as batching, streaming chunk management, cache consistency across heterogenous models, and CUDA graph-based execution—previously inaccessible in model-specific settings.
Evaluation: System Throughput, Latency, and Scalability
The paper presents extensive evaluation across multiple state-of-the-art SpeechLMs, including CosyVoice 2.0, Orpheus 3B, and Step-Audio 2, each with distinct detokenizer and tokenization strategies.
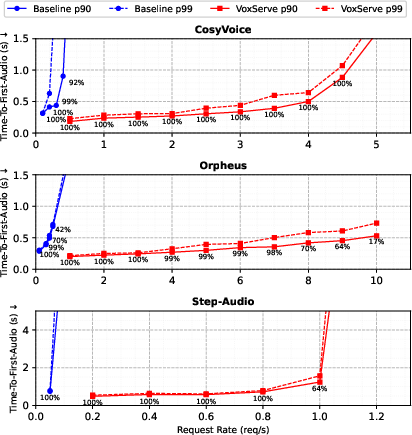
Figure 6: VoxServe achieves 10--20× higher serving throughput over baselines while maintaining comparable TTFA and streaming viability.
Key findings include:
- Throughput: VoxServe supports 10--20× higher request rates at constant p90 or p99 TTFA, relative to each model's official baseline implementation.
- Streaming Viability: Maintains high viability—the percentage of audio chunks enabling uninterrupted playback—well beyond the saturation points of baselines.
- Schedulability and Asynchrony: Ablations demonstrate the critical role of optimized scheduling and asynchronous pipelining, yielding substantial reductions in TTFA and improved resource utilization under high concurrency.
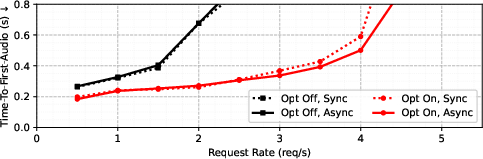
Figure 7: TTFA reductions realized through optimized scheduling and asynchronous pipelining, particularly under load.
- Multi-GPU Scaling: Data parallelism (up to 4×) yields near-linear throughput scaling. Disaggregated inference—partitioning LLM and detokenizer across GPUs—shows significant throughput and latency benefits versus conventional baselines, including effective inter-device cache/state management.
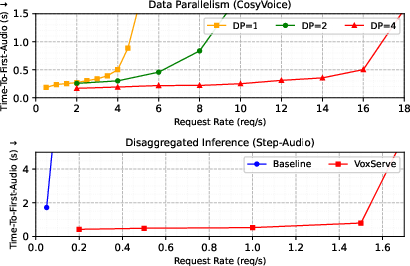
Figure 8: Multi-GPU scaling with near-linear improvements for both data parallel and disaggregated scenarios.
- Batch-Oriented Workloads: In throughput-oriented settings (e.g., audiobook or synthetic data generation), VoxServe with batch-maximizing schedulers achieves >10× acceleration over baseline systems.
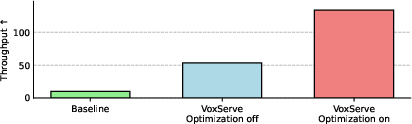
Figure 9: Throughput-oriented inference: maximizing total audio synthesized per latency reveals flexibility and sustained efficiency.
Robustness experiments confirm stable latency and throughput across varying datasets and input statistics, with consistent superiority over baseline systems.
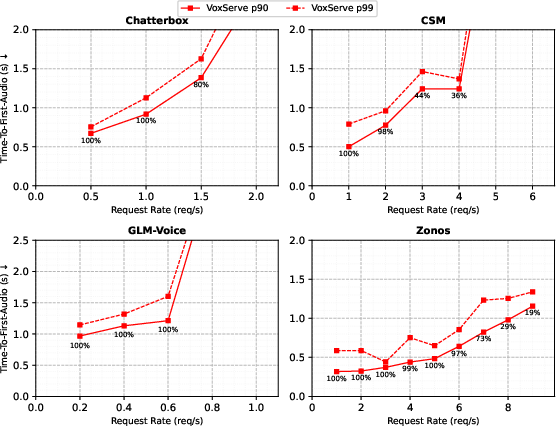
Figure 10: Serving performance is preserved across additional SpeechLM architectures integrated via VoxServe.
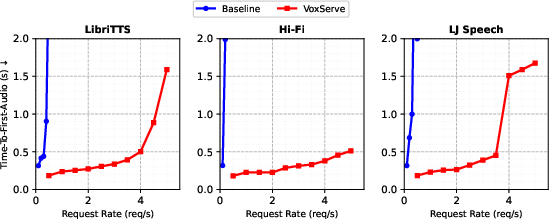
Figure 11: Consistent TTFA advantages for VoxServe across alternate input data sources.
Implications and Future Directions
Practically, VoxServe decouples model development and deployment engineering, enabling rapid adoption of new SpeechLMs while ensuring that optimizations—batching, scheduling, pipelining—generalize across architectural innovations. This unification is vital for the continued scale-up of speech-based AI services, reducing TCO and accelerating the pace of model iteration.
Theoretically, VoxServe demonstrates that system abstractions enabling execution pattern regularity—regardless of underlying model diversity—can unlock cross-cutting performance benefits. With the rise of heterogenous multi-modal models, similar design patterns may be applied to bridge serving gaps in vision, audio, and joint generative systems. Future work could extend these abstractions to incorporate adaptive scheduling based on per-request or per-user constraints, online system optimization via RL-based schedulers, and fine-grained quality-of-service management under mixed real-time and batch workloads.
Conclusion
VoxServe establishes a unified, streaming-centric framework for deploying diverse SpeechLMs at scale. By introducing model-agnostic abstractions and optimizing for streaming perceptual metrics, it achieves significant improvements in both system throughput and latency relative to model-specific baselines, without sacrificing flexibility or extensibility. These contributions both lower the operational barriers for real-time speech deployment and provide a blueprint for future multi-modal serving systems (2602.00269).