vLLM-Omni: Fully Disaggregated Serving for Any-to-Any Multimodal Models
Abstract: Any-to-any multimodal models that jointly handle text, images, video, and audio represent a significant advance in multimodal AI. However, their complex architectures (typically combining multiple autoregressive LLMs, diffusion transformers, and other specialized components) pose substantial challenges for efficient model serving. Existing serving systems are mainly tailored to a single paradigm, such as autoregressive LLMs for text generation or diffusion transformers for visual generation. They lack support for any-to-any pipelines that involve multiple interconnected model components. As a result, developers must manually handle cross-stage interactions, leading to huge performance degradation. We present vLLM-Omni, a fully disaggregated serving system for any-to-any models. vLLM-Omni features a novel stage abstraction that enables users to decompose complex any-to-any architectures into interconnected stages represented as a graph, and a disaggregated stage execution backend that optimizes resource utilization and throughput across stages. Each stage is independently served by an LLM or diffusion engine with per-stage request batching, flexible GPU allocation, and unified inter-stage connectors for data routing. Experimental results demonstrate that vLLM-Omni reduces job completion time (JCT) by up to 91.4% compared to baseline methods. The code is public available at https://github.com/vllm-project/vllm-omni.
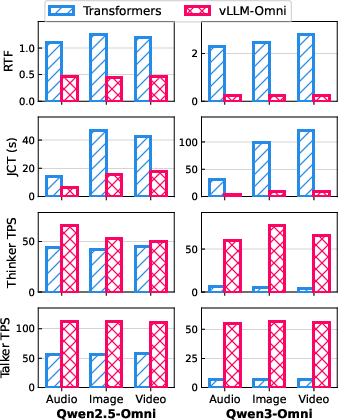
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (big picture)
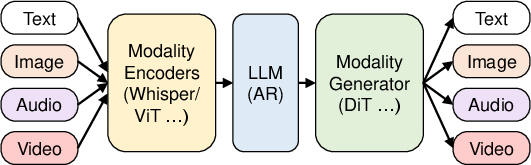
This paper introduces vLLM-Omni, a system that makes it much faster and easier to run fancy AI models that can take in different kinds of inputs (like text, pictures, video, or sound) and produce different kinds of outputs (like talking back, making an image, or creating a video). These are called “any-to-any multimodal models.” The core idea is to break these complex models into clear steps (called “stages”) and run each step efficiently, then connect the steps together smoothly.
What questions the authors wanted to answer
The authors focus on a simple problem:
- Today’s AI helpers that can read text, watch videos, listen to audio, and reply in voice or images are powerful—but hard to run efficiently because they’re made of many different parts (like a text generator and an image generator) glued together.
- Existing serving tools are usually good at only one kind of model (e.g., text-only chatbots or image generators), not a mix.
- So they ask: Can we build one serving system that handles all these different parts together, runs them efficiently, and makes the whole pipeline fast and flexible?
How vLLM-Omni works (in everyday terms)
Think of these AI models like a high-tech assembly line:
- Different stations do different jobs:
- One “writer” station (a text model) plans or generates words.
- One “artist” station (a diffusion model) turns a description into an image or video.
- One “speaker” station turns text into speech.
- In many modern assistants, more than one of these stations work in sequence. For example, a “Thinker” writes what to say, then a “Talker” turns that into audio, then a “Vocoder” turns that into waveforms (sound you can hear).
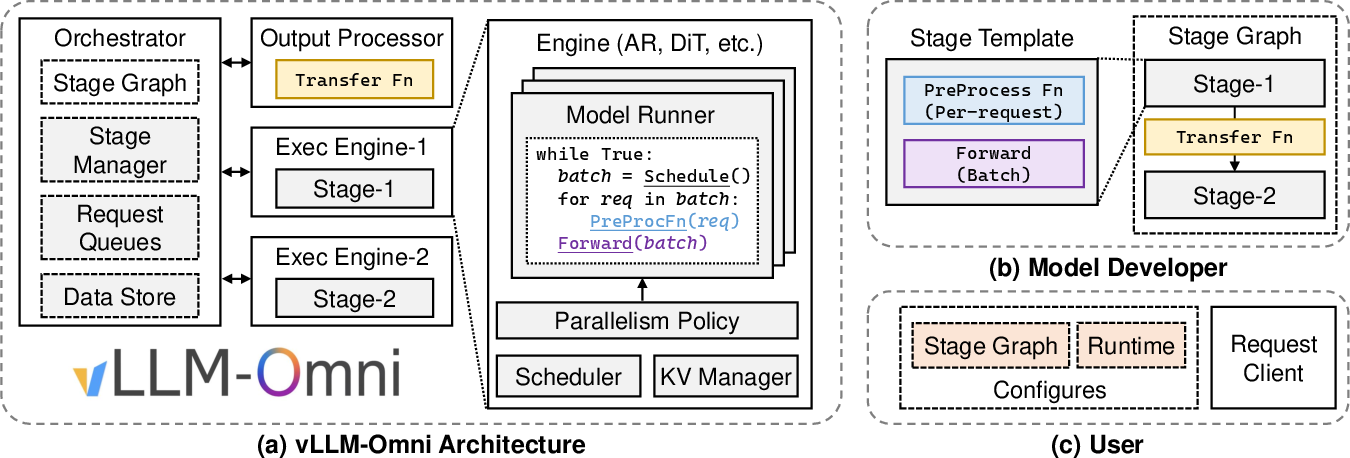
vLLM-Omni turns this assembly line into a clean “stage graph”:
- Each node (stage) is one station (e.g., the Thinker, the Talker, or the image/video generator).
- The edges are the “conveyor belts” that pass data (like text tokens, hidden states, or image features) from one stage to the next.
- An “orchestrator” directs traffic so each station gets the right inputs at the right time.
To make this fast and flexible:
- Each stage runs with its own specialized engine:
- Autoregressive LLM engine for text-style steps (the “writer” parts).
- Diffusion engine for image/video/audio-generation steps (the “artist” parts).
- Each stage can batch multiple requests on its own (so the GPUs stay busy).
- You can assign different GPUs and memory to different stages depending on how heavy they are.
- A “unified connector” moves data between stages efficiently (on the same machine or across multiple machines).
- “Streaming” lets downstream stages start early. For example, the “speaker” can begin producing sound while the “thinker” is still finishing the sentence—like a relay race where the next runner starts moving as the baton arrives.
In short: vLLM-Omni splits a complicated model into clear steps, optimizes each step with the right tools, and connects them with fast, flexible data pipes.
What they found (results) and why it matters
The authors tested vLLM-Omni on several real any-to-any models and compared it to standard implementations. Here are the highlights:
- For Qwen-Omni models (which generate both text and speech):
- Job Completion Time (how long it takes to finish a task) was reduced by up to 91.4%.
- Real-Time Factor (how fast speech is generated compared to its duration) improved a lot—meaning it can produce audio much faster than the audio length.
- Token throughput (how many tokens per second are produced) increased substantially for both the “Thinker” and the “Talker,” especially on larger models.
- For BAGEL (an image generation pipeline):
- Text-to-image jobs were about 2.4× faster.
- Image-to-image jobs were about 3.7× faster.
- For MiMo-Audio (text-to-speech with token-based audio):
- Speed improved up to about 11.6× with execution-graph compilation enabled.
- For diffusion-based image/video models (like Qwen-Image and Wan2.2):
- vLLM-Omni was about 1.26× faster than a popular baseline library.
Why it matters:
- Big speedups mean you can get voice replies, images, or videos more quickly—closer to real time.
- Developers don’t have to hand-build complicated pipelines for each model; the system handles the hard parts (batching, scheduling, data transfer) for them.
- It’s easier to scale across machines and mix different kinds of models in one pipeline.
What this could lead to (impact)
- Faster, smarter assistants that can listen, look, and speak—like talking to an AI that can watch a video, understand it, then explain it out loud or create an image in response.
- Simpler and more reliable deployment for companies and researchers building multimodal apps, because they can use one system for all parts instead of stitching different tools together.
- Better use of hardware (like GPUs), saving time and cost, and enabling larger, more complex models to run efficiently.
Overall, vLLM-Omni shows a practical way to serve next-generation AI models by treating them like a well-organized assembly line: break the job into stages, run each stage with the best tools, and keep the whole line moving smoothly and fast.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of the key gaps and unresolved questions that future researchers could address to strengthen and extend vLLM-Omni.
- Multi-tenant and online serving: The paper evaluates offline inference on single workloads; it lacks experiments and policies for multi-tenant, concurrent traffic with diverse request mixes, bursty arrivals, and streaming outputs. Develop and evaluate admission control, queuing, and scheduling under production-like load.
- Cross-stage scheduling algorithms: The “orchestrator” is described at a high level, but no formal scheduling strategy (e.g., pipeline-aware, SLO-aware, cost-aware, or fairness-aware) is presented. Design and compare cross-stage schedulers that optimize TTFT, JCT, throughput, and fairness across heterogeneous stages.
- Scalability across nodes: Although Ray/Mooncake connectors are mentioned, all experiments are on a single 2-GPU server. Validate scalability to multi-node clusters (tens to hundreds of GPUs), measure cross-node connector overheads with large payloads, and analyze throughput/latency scaling curves and bottlenecks.
- Connector robustness and semantics: The unified connector’s reliability (failure handling, retries, backpressure, ordering guarantees, exactly-once delivery) is not specified. Formalize connector semantics and evaluate robustness under failures and network partitions.
- Security and privacy: No discussion of data security for cross-stage and cross-node transfers (encryption, authentication, tenant isolation, access control). Implement and benchmark secure transport and isolation mechanisms without compromising performance.
- Quality preservation: Optimizations like TeaCache/cache-DiT and streaming outputs may affect generation quality. Provide quality metrics (e.g., audio MOS, image/video fidelity/consistency) and quantify any degradations versus baseline implementations.
- Baseline parity and fairness: Qwen-Omni baselines use Transformers implementations that “do not fully exploit modern LLM serving techniques.” Compare against best-optimized baselines (e.g., vLLM/SGLang where applicable, tuned Diffusers, or vendor-optimized runtimes) to ensure fair benchmarking.
- Auto-tuning and resource allocation: Per-stage GPU/memory allocation is manual. Develop auto-tuners that adapt parallelism, batching, and memory budgets to model characteristics and workload dynamics, and report time-to-stable configuration and gains.
- Memory management across stages: The work does not detail per-stage memory fragmentation, eviction policies (KV/MM cache), and cross-stage memory pressure interactions. Instrument and optimize memory reuse, spilling, and eviction to minimize OOM and maximize batching.
- Dynamic control flow: Stage graphs appear static; support for conditional branches, loops, or dynamically chosen paths (e.g., “route to image or audio decoder based on Thinker output”) is not demonstrated. Formalize and test dynamic control flow in the stage abstraction.
- Cyclic or iterative pipelines: It’s unclear if non-DAG stage graphs (feedback loops for planning/verification) are supported. Specify constraints, add loop/iteration primitives, and measure stability and performance under cyclic pipelines.
- Backpressure and flow control: Streaming outputs start downstream computation early, but mechanisms for controlling downstream backpressure or upstream slowdown are unspecified. Design and evaluate end-to-end flow control to avoid buffer bloat and thrashing.
- Heterogeneous hardware validation: The plugin architecture claims cross-platform support, but no experiments on diverse accelerators (e.g., NVIDIA generations, AMD, Ascend, TPUs), interconnects (NVLink/PCIe/InfiniBand), or mixed-precision capabilities. Conduct cross-hardware benchmarks and identify portability gaps.
- Energy and cost efficiency: No power or cost-per-request analysis. Measure energy usage, cost models (GPU-hours, bandwidth), and propose policies (e.g., energy-aware scheduling, low-power modes) for sustainable serving.
- Encoder disaggregation: Encoders are sometimes fused into the Thinker stage. Quantify the benefits/costs of disaggregating encoders into separate stages (e.g., MM cache locality, reusability) and define best practices.
- Large-payload transfers: Connector overheads are reported only for modest payloads. Characterize performance for very large intermediate artifacts (e.g., long video embeddings, high-res latent tensors) and identify thresholds where transport dominates end-to-end latency.
- Observability and debugging: The system’s telemetry (per-stage traces, dataflow lineage, anomaly detection) is not described. Develop observability tooling for stage-level metrics, connector health, and performance regressions.
- QoS/SLO governance: No mechanism to enforce per-request SLOs (TTFT/JCT), prioritize interactive vs. batch jobs, or guarantee fairness across tenants. Design QoS policies and evaluate their impact on throughput and latency.
- Speculative and advanced decoding: Integration of speculative decoding, draft models, or E2E techniques across stages is not explored. Prototype cross-stage speculative execution and quantify speed/quality trade-offs.
- Quantization and compression: Support for per-stage quantization (LLM/DiT) and intermediate data compression is not evaluated. Explore precision/quantization strategies and connector-side compression codecs to reduce memory/transport costs.
- Stage graph API guarantees: The user-defined preprocess/transfer functions are flexible but lack formal API constraints (shape/type contracts, device placement). Define a type system and static checks to prevent costly data copies and runtime errors.
- Interplay with PD/EPD disaggregation: Compatibility is claimed, but there is no quantitative analysis of PD/EPD techniques within multi-stage pipelines. Measure benefits and edge cases when combining PD/EPD with the stage graph.
- Mixed workloads and modality skew: The system is evaluated on separate tasks; the impact of mixed modality workloads (e.g., concurrent T2I + TTS + VQA) on resource contention and scheduling remains unknown. Benchmark mixed scenarios and devise load shaping.
- Extreme sequence lengths and token-rate mismatch: The Talker often generates far more tokens than the Thinker. Study adaptive batching and pacing strategies to handle severe token-rate mismatches and long contexts (e.g., multi-minute audio, long videos).
- Fault tolerance and recovery: There is no description of checkpointing, in-flight request recovery, or stage hot-restart. Implement fault tolerance (per-stage checkpoints, replay) and quantify recovery time and lost work.
- Versioning and live updates: The paper does not address hot-swapping model stages (A/B testing, canary releases) in running pipelines. Develop mechanisms for safe stage replacement with minimal disruption and no connector incompatibilities.
- Interoperability with other pipeline systems: No comparison or integration with general-purpose workflow engines (e.g., Ray DAGs, Triton ensembles) or MLOps orchestrators. Evaluate interoperability benefits/limitations and migration paths.
- Reproducibility and workload diversity: Experiments use 100-query subsets and a single server. Expand to larger, diverse datasets, longer runs, statistical confidence intervals, and publish reproducible scripts/configs to validate robustness.
- End-to-end correctness under asynchrony: Streaming and asynchronous transfers can introduce nondeterminism. Define and test determinism guarantees (or controlled nondeterminism) and their impact on debugging and quality assurance.
Practical Applications
Immediate Applications
Below are practical use cases that can be deployed now by leveraging vLLM-Omni’s stage-graph abstraction, disaggregated execution, unified connector, diffusion engine, and streaming outputs. Each item notes sector alignment, potential tools/products/workflows, and key assumptions or dependencies.
- Multimodal customer support voice assistants
- Sector: software, telecom, retail, banking
- What emerges: “Omni Voice Agent” that reasons (Thinker), speaks (Talker + Vocoder), and can generate/annotate visuals (DiT) in-session; streaming responses reduce time-to-first-word
- Dependencies: GPUs/accelerators; licenses and usage rights of any-to-any models (e.g., Qwen-Omni); reliable low-latency connectors; call recording and privacy compliance
- Media production pipelines for rapid image/video generation
- Sector: media/entertainment, advertising, gaming
- What emerges: “Creative Copilot” for T2I/I2I/T2V/I2V content with batch scheduling, stage-wise GPU allocation, and faster job completion times using the diffusion engine
- Dependencies: model safety filters; rights management; content moderation; accelerator memory budgets to support 1024x1024 and long-sequence video outputs
- Interactive educational tutors that speak and show visuals
- Sector: education/edtech
- What emerges: Multimodal teaching assistants that can explain topics verbally while generating and editing images or short videos; streaming stage output enables real-time classroom interaction
- Dependencies: age-appropriate content safeguards; device/network bandwidth for streaming; institutional data policies; compute budgeting per class/session
- Contact center analytics and real-time post-call summarization with voice playback
- Sector: finance, healthcare, logistics, insurance
- What emerges: Workflow where the Thinker generates structured summaries and the Talker/Vocoder deliver friendly audio recaps; stage disaggregation allows independent scaling for spikes in either text or audio workloads
- Dependencies: regulated data handling (HIPAA/PCI/GLBA); data retention policies; secure connectors across nodes; latency targets per SLA
- Developer tooling for any-to-any model prototyping and ablation
- Sector: academia, applied research, MLOps
- What emerges: “Omni Pipeline SDK” with stage graphs, per-stage preprocess/forward functions, and transfer functions; reproducible experiments across AR and DiT components
- Dependencies: access to public models and datasets; familiarity with vLLM APIs and Ray; benchmark harnesses for TPS/JCT/RTF metrics
- Multimodal product search and shopping assistants
- Sector: e-commerce
- What emerges: Assistants that understand voice and images of products, generate verbal recommendations, and produce edited visuals (colorways, styling) using DiT stages
- Dependencies: catalog integration and vector search; content policy; GPU allocation strategy to handle image-edit peaks
- Telehealth triage with multimodal inputs and human-friendly outputs
- Sector: healthcare
- What emerges: Voice-driven intake (audio/image/video) with structured text reasoning (Thinker) and patient-friendly audio explanations (Talker/Vocoder); image-edit for marking regions of interest
- Dependencies: medical device and privacy regulations; clinical validation; human-in-the-loop review; robustness to noisy inputs
- Stage-level autoscaling and cost optimization in cloud inference
- Sector: cloud, MLOps
- What emerges: “Omni Serving Orchestrator” that assigns accelerators per stage (Thinker/Talker/DiT), uses continuous batching, chunked prefill, and graph compilation to cut cost/latency
- Dependencies: autoscaling policies; observability/telemetry; heterogeneous accelerator fleets; connector tuning for single-node vs multi-node deployments
- Real-time accessibility tools (speech-enabled reading aids with visual augmentations)
- Sector: public sector, non-profit, daily life
- What emerges: Tools that read text aloud, generate illustrative images, and provide voice explanations; streaming reduces wait times for users with visual impairments
- Dependencies: device compute or reliable cloud connection; localized LLMs; safety checks for sensitive content
- Faster A/B testing of multimodal model architectures and serving strategies
- Sector: academia, enterprise R&D
- What emerges: Benchmarked experiments comparing Thinker/Talker/DiT variants, per-stage batching policies, and connector configurations; standardized metrics (JCT, TPS, RTF)
- Dependencies: experiment management; CI/CD; dataset licensing; competent GPU scheduling
Long-Term Applications
The following applications are promising but require further research, scaling, hardware evolution, or policy development to become robust and widely deployable.
- Edge–cloud split inference for multimodal assistants
- Sector: mobile, IoT, wearables
- What emerges: On-device encoders (audio/vision) and partial AR decoding, with cloud-based Talker/Vocoder or DiT for heavy generation; unified connector handles intermittent connectivity
- Dependencies: efficient hardware plugins (low-power accelerators); secure edge data handling; adaptive streaming; improved RDMA/TCP transport for low-latency cross-edge links
- Smart home and vehicle infotainment with any-to-any interaction
- Sector: consumer electronics, automotive
- What emerges: Voice+vision copilots that plan trips, describe scenes, and generate personalized audio or visuals on the fly; stage-level scheduling for varying compute envelopes
- Dependencies: OEM hardware support; robust far-field audio processing; in-cabin privacy and safety constraints; multi-user context management
- Multilingual public digital services with multimodal front-ends
- Sector: government/public sector
- What emerges: Voice-enabled portals that accept image/video evidence and return both textual and spoken responses; stage disaggregation supports scaling across regional datacenters
- Dependencies: procurement and compliance frameworks; accessibility standards; content moderation; sovereign hosting and data residency
- Real-time compliance monitoring for financial services
- Sector: finance
- What emerges: Systems that transcribe, reason over, and generate compliant audio summaries during live calls; connectors stream partial outputs to alerting systems
- Dependencies: stringent audit trails; model risk management; throughput guarantees under market spikes; domain-specific tuning and red-teaming
- Hospital diagnostics and clinical decision support with generative visuals
- Sector: healthcare
- What emerges: Assistants that reason over multimodal inputs and generate annotated images (e.g., highlighting suspected regions) plus spoken explanations for clinicians
- Dependencies: medical-grade validation; bias/fairness assessments; regulatory approvals; integration with EHR systems and PACS; certified hardware
- Robotics instruction engines with natural voice and visual planning feedback
- Sector: robotics, manufacturing, logistics
- What emerges: Pipelines where Thinker handles task planning and DiT generates visual plans or overlays; Talker/Vocoder provide natural voice instructions
- Dependencies: safety certification; tight real-time constraints; reliable edge inference; robust perception-to-language alignment
- Newsroom and content studios with fully automated multimodal workflows
- Sector: media/publishing
- What emerges: End-to-end flow from ingest (audio/video/image) to multimodal generation, editing, and voiced narration; stage-level autoscaling optimizes cost per story
- Dependencies: editorial oversight; copyright and rights clearance; quality controls; scalable storage and rendition pipelines
- Large-scale classroom platforms with multimodal curricula generation
- Sector: education
- What emerges: Systems that generate lesson visuals, simulations, and speak explanations per student level; streaming output for live feedback
- Dependencies: pedagogy alignment; safety filters; cost control across thousands of concurrent sessions; personalization data governance
- Multi-tenant cloud platforms offering “Any-to-Any Serving as a Service”
- Sector: cloud/SaaS
- What emerges: Managed service exposing stage-graph APIs, per-edge connector selection, autoscaling, and SLA-backed JCT/RTF targets
- Dependencies: multi-tenant isolation; usage metering and billing; model zoo with permissible licenses; robust DevSecOps and model monitoring
- Assistive technologies for vision/hearing with on-device generation
- Sector: healthcare, accessibility, daily life
- What emerges: Wearables that translate signs or scenes into audio, or generate visuals for hearing-impaired contexts; partial stages on-device to reduce latency
- Dependencies: energy-efficient accelerators; privacy-preserving on-device caches; durable edge–cloud fallback; safety testing across diverse user populations
Glossary
- Any-to-any multimodal models: Models that can accept and produce outputs across multiple modalities (text, image, video, audio) within a unified architecture. "Any-to-any multimodal models that jointly handle text, images, video, and audio represent a significant advance in multimodal AI."
- Autoregressive (AR) LLMs: LLMs that generate output tokens sequentially, each conditioned on previously generated tokens. "adopt a ThinkerâTalker architecture that connects two autoregressive (AR) LLMs, one dedicated to generating text tokens and the other to generating audio tokens."
- cache-dit: A caching strategy to accelerate diffusion transformer inference by reusing intermediate states across denoising steps. "caching strategies for the iterative denoising process (TeaCache~\cite{teacache}, cache-dit~\cite{cache-dit})"
- Codec tokens: Discrete tokens representing compressed audio units used for autoregressive audio generation. "The Talker LLM then autoregressively generates codec tokens, repeatedly concatenating the Thinker hidden states at each decoding step."
- Continuous batching: A serving optimization that continuously forms batches of requests to improve throughput and resource utilization. "performance optimization techniques such as continuous batching~\cite{yu2022orca} for decoding and chunked prefill~\cite{Sarathi} processing cannot be applied."
- Data parallelism: A parallelization strategy that replicates the model across devices and splits input data among them. "support multiple parallelism strategies, such as data parallelism and tensor parallelism."
- Denoising: The iterative process in diffusion models of removing noise to reconstruct clean outputs. "diffusion serving frameworks~\cite{diffusers, fang2024xdit} are optimized for DiT denoising and designed for image and video generation."
- Diffusion engine: A specialized execution backend that serves diffusion models with optimizations for attention, caching, and parallelism. "vLLM-Omni integrates a dedicated diffusion engine seamlessly into its multi-stage pipeline architecture."
- Diffusion Transformer (DiT): A transformer-based architecture tailored for diffusion processes in image, audio, or video generation. "diffusion transformers (DiT)~\cite{DiT} for visual synthesis."
- Encode-Prefill-Decode (EPD) disaggregation: Decomposing the inference pipeline into separate encode, prefill, and decode stages for efficiency and flexibility. "This design remains compatible with existing EPD (encodeâprefillâdecode) disaggregation~\cite{epd}."
- Execution-graph compilation: A technique that compiles the model’s execution graph to optimize runtime performance. "the baseline implementation does not fully exploit modern LLLM serving techniques such as execution graph compilation."
- Flash Attention: An optimized attention algorithm that reduces memory usage and improves speed during transformer inference. "flash attention~\cite{dao2022flashattention}"
- Flow-matching: A method used in diffusion modeling to match probability flows, improving generation quality and speed. "DiT flow-matching for Mel-spectrograms and neural vocoding for waveforms."
- Job Completion Time (JCT): The total end-to-end latency for a request from submission to completion. "reduces job completion time (JCT) by up to 91.4\% compared to baseline methods."
- KV cache: A cache of attention key and value tensors used to avoid recomputation during autoregressive decoding. "These frameworks encapsulate iteration logic and attention key-value (KV) cache management within their runtime"
- Mixture-of-Experts (MoE): An architecture that routes inputs to specialized expert networks to improve efficiency and capacity. "LongCat-Flash-Omni~\cite{LongCat-Flash-Omni} uses a 560B-parameter MoE LLM backbone"
- Mixture-of-Transformers (MoT): An ensemble of transformer experts specialized for different tasks or modalities within a unified model. "its Mixture-of-Transformers (MoT) design separates multimodal semantic understanding from visual generation via different experts"
- Mooncake-based connector: A data-transfer mechanism enabling TCP or RDMA transport for cross-node stage communication. "A Mooncake-based connector~\cite{mooncake} complements this by enabling TCP- or RDMA-based transport"
- Multimodal embedding cache: A cache of embeddings from non-text modalities (e.g., image, audio) to avoid redundant computation. "multimodal embedding cache~\cite{wan2024look}"
- Orchestrator: A control component that schedules and coordinates execution across multiple model stages. "an orchestrator manages the execution of stages and schedules incoming requests."
- Paged attention: An attention implementation that stores the KV cache in pages to improve memory locality and scalability. "attention implementations (e.g., paged attention~\cite{vllm}, flash attention~\cite{dao2022flashattention})"
- Prefix tree caching: Caching common prompt prefixes in a tree structure to reuse computation across similar requests. "prefix tree caching~\cite{sglang}."
- Prefill-Decode (PD) disaggregation: Splitting the prefill phase (processing the prompt) and the decode phase (token generation) into separate components. "Prefill-Decode (PD)~\cite{zhong2024distserve} disaggregation."
- Ray: A distributed execution framework for orchestrating multi-node computation and data movement. "we leverage Ray~\cite{ray} to orchestrate cross-node execution."
- RDMA: Remote Direct Memory Access; a networking technology for low-latency, high-throughput data transfer. "TCP- or RDMA-based transport"
- Real-Time Factor (RTF): The ratio of processing time to the duration of generated audio, indicating real-time performance. "We primarily evaluate Real-Time Factor (RTF) and Job Completion Time (JCT) as our performance metrics."
- RingAttention-based context parallelism: A parallelization technique that distributes attention context across devices in a ring topology. "parallelization approaches such as RingAttention-based context parallelism~\cite{ring} and Ulysses sequence parallelism."
- SAGE attention: An attention optimization tailored for efficient diffusion model inference. "SAGE attention~\cite{zhang2024sageattention}"
- Semantic-VQ: Vector quantization of semantic representations used to bridge high-level understanding and generative decoders. "it first employs semantic-VQ~\cite{geng2025x} with a VAE-based encoder~\cite{van2017neural} to extract visual features"
- Stage graph: A graph representation of model components (stages) and the data-flow edges between them. "introducing the concept of a stage graph."
- Stage-transfer functions: User-defined functions that transform and route intermediate data from one stage to the next. "users define stage-transfer functions that control how query states and intermediate data are transformed during transitions."
- Streaming stage output: Incrementally sending partial outputs to downstream stages to overlap computation and reduce latency. "vLLM-Omni implements streaming stage output, where intermediate results are transferred to downstream stages incrementally as they become available."
- TeaCache: A caching technique designed to accelerate iterative diffusion denoising. "caching strategies for the iterative denoising process (TeaCache~\cite{teacache}, cache-dit~\cite{cache-dit})"
- Tensor parallelism: Splitting large tensor operations across multiple accelerators to serve big models efficiently. "vLLM-Omni applies tensor parallelism to the Thinker across both accelerators"
- Thinker–Talker architecture: A two-LLM pipeline design where one LLM generates text (Thinker) and another generates audio tokens (Talker). "Qwen-Omni models adopt the Thinker-Talker architecture with three model components"
- Time-to-first-token (TTFT): The latency until the first token of the final response is produced. "By enabling overlapped execution across stages, streaming stage output reduces time-to-first-token (TTFT) for the final output"
- Tokens Per Second (TPS): A throughput metric measuring how many tokens a model generates per second. "we further report Tokens Per Second (TPS) for both the thinker and the talker components."
- TurboAttention: A quantized or optimized attention variant for faster inference in large models. "TurboAttention~\cite{kang2025turboattention}"
- Ulysses sequence parallelism: A sequence-level parallelization method to scale attention and sequence processing across devices. "Ulysses sequence parallelism."
- Unified connector: A generalized data-transfer interface that abstracts inter-stage transport across single-node and multi-node deployments. "vLLM-Omni supports disaggregated data transfer through a unified connector interface that decouples transport from model logic."
- VAE (Variational Autoencoder): A generative model that encodes inputs into a latent space and decodes them back, used here for visual feature extraction. "a VAE-based encoder~\cite{van2017neural}"
- Vocoder: A neural component that converts intermediate audio representations (e.g., codec tokens or spectrograms) into waveforms. "Finally, upon completion of the Talker stage, outputs are passed to the Vocoder stage for waveform reconstruction."
Collections
Sign up for free to add this paper to one or more collections.