- The paper demonstrates that CODI forms explicit intermediate states in its latent channels, with decodability metrics up to 0.709 on two-hop tasks.
- It employs logit-lens decoding, linear probing, attention analysis, and causal activation patching to uncover the underlying sequential reasoning mechanisms.
- The study reveals that deeper tasks induce compressed, late-stage strategies, with performance gaps on prime modulus tasks due to strict full-history propagation requirements.
Mechanistic Analysis of Latent Chain-of-Thought Computation in CODI
Overview and Motivation
This paper presents a comprehensive mechanistic analysis of Latent Chain-of-Thought (Latent-CoT) reasoning models, with a particular focus on the CODI (Continuous Chain-of-Thought via Self-Distillation) architecture. The study investigates whether Latent-CoT models solve strictly sequential, multi-hop algorithmic tasks in a genuinely stepwise manner or predominantly rely on shortcut strategies, compressed rollouts, or late-stage fusion of information. The analysis leverages polynomial-iteration tasks over modular arithmetic as a controlled framework, enabling granular examination of intermediate state propagation, representation, and reasoning fidelity. The empirical inquiry synthesizes four mechanistic interpretability techniques: logit-lens decoding, linear probing, attention analysis, and causal activation patching.
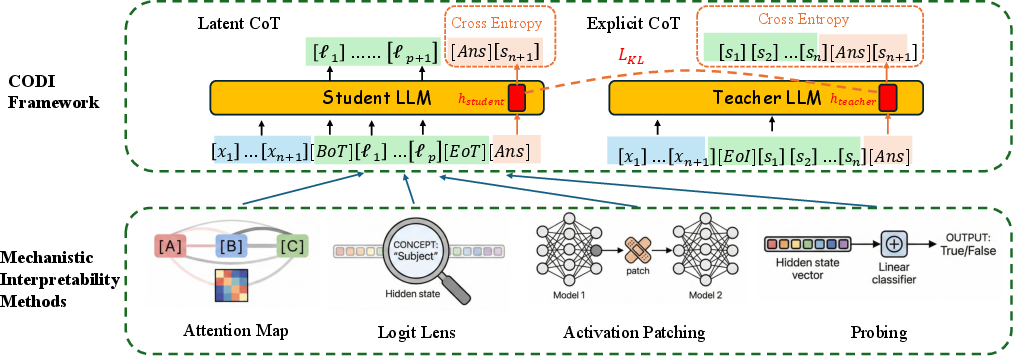
Figure 1: Mechanistic study of CODI on sequential reasoning tasks. Top: the CODI training setup for polynomial iteration; bottom: four mechanistic interpretability methods used for the analysis.
Experimental Framework and Mechanistic Probing
Task and Model Setup
CODI is trained on sequential polynomial tasks of variable hop-length, where each intermediate state is deterministically defined by modular arithmetic updates:
st=st−1xt+b(modm)
This setup makes state propagation completely transparent, allowing precise localization of the formation and utilization of intermediate "bridge" states. The teacher model produces explicit, textual Chain-of-Thought traces; the student model learns to predict answers after generating a sequence of latent thought vectors—without emitting textual rationales. The key objective for the student is feature-space self-distillation: minimizing the ℓ1 distance between teacher and student hidden states at a designated pre-answer boundary ([Ans]), thus aligning the internal latent computation with explicit stepwise reasoning.
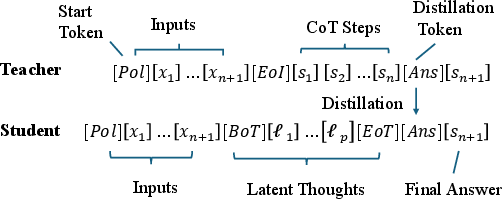
Figure 2: Polynomial tasks for training CODI, depicting explicit teacher CoT trace and student latent-thought trajectory. Feature-space distillation aligns internal representations at the [Ans] boundary.
Mechanistic Interpretability Protocols
Four main diagnostic tools are employed:
- Logit lens: decodes residual-stream activations into probability distributions over task states at each latent position, revealing when and where correct intermediate states emerge.
- Linear probes: train classifiers on hidden states at various layers/positions to predict intermediate and input states.
- Attention analysis: visualizes token-to-token routing of information, identifying direct-copy and latent update pathways.
- Activation patching: causally swaps hidden states at specified positions or tokens between clean and corrupted runs, quantifying necessity and sufficiency for answer prediction.
Empirical Findings: The Structure of Internal Reasoning
On two-hop tasks, logit-lens and probe analyses conclusively show that CODI forms explicit representations of the required intermediate state (s2) inside the latent computation channel; decoding confidence ranges from 0.359 to 0.709 across layers and positions, with linear probe accuracy approaching 1 on these intermediates.
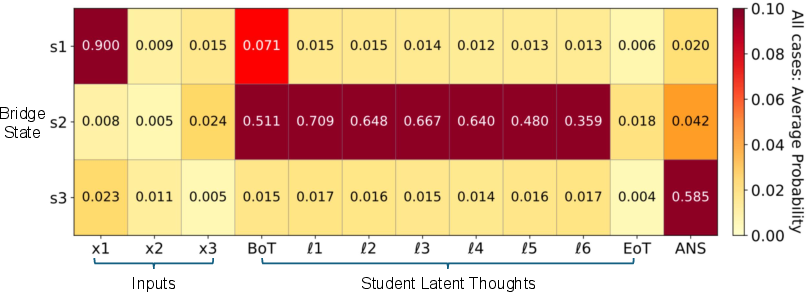
Figure 3: Logit lens analysis on intermediate states (s1, s2, s3) for the two-hop task. s2 achieves strong decodability during the latent steps, confirming explicit intermediate state formation.
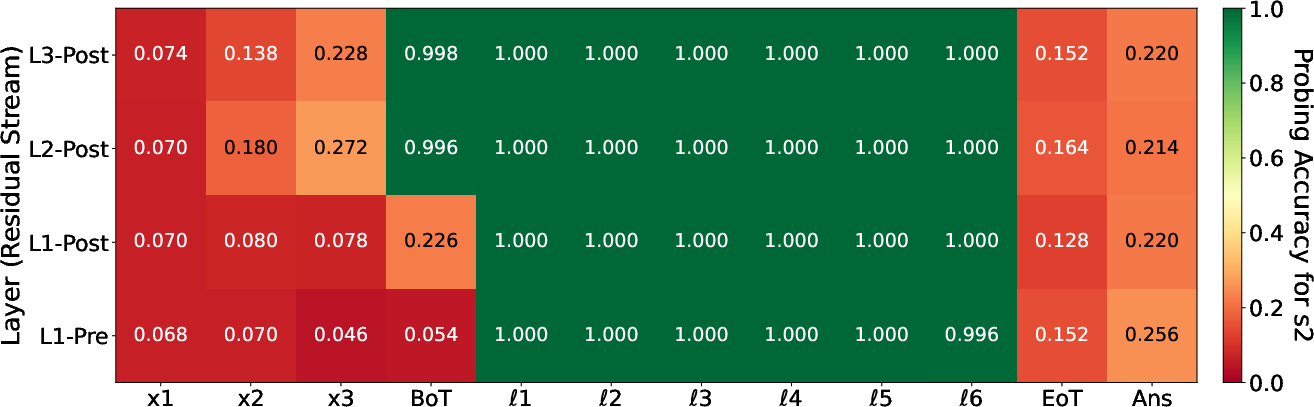
Figure 4: Linear probing validates that s2 is decodable throughout latent computation, supporting bridge state formation and sequential internal reasoning.
Attention maps further reveal a specialized head configuration in which the final input token (x3) is routed directly to the [Ans] token, rather than being represented or propagated through the latent channel. This creates a bifurcated computational pathway: latent tokens construct and maintain intermediate states; a copy-like mechanism delivers the final input to the output boundary.
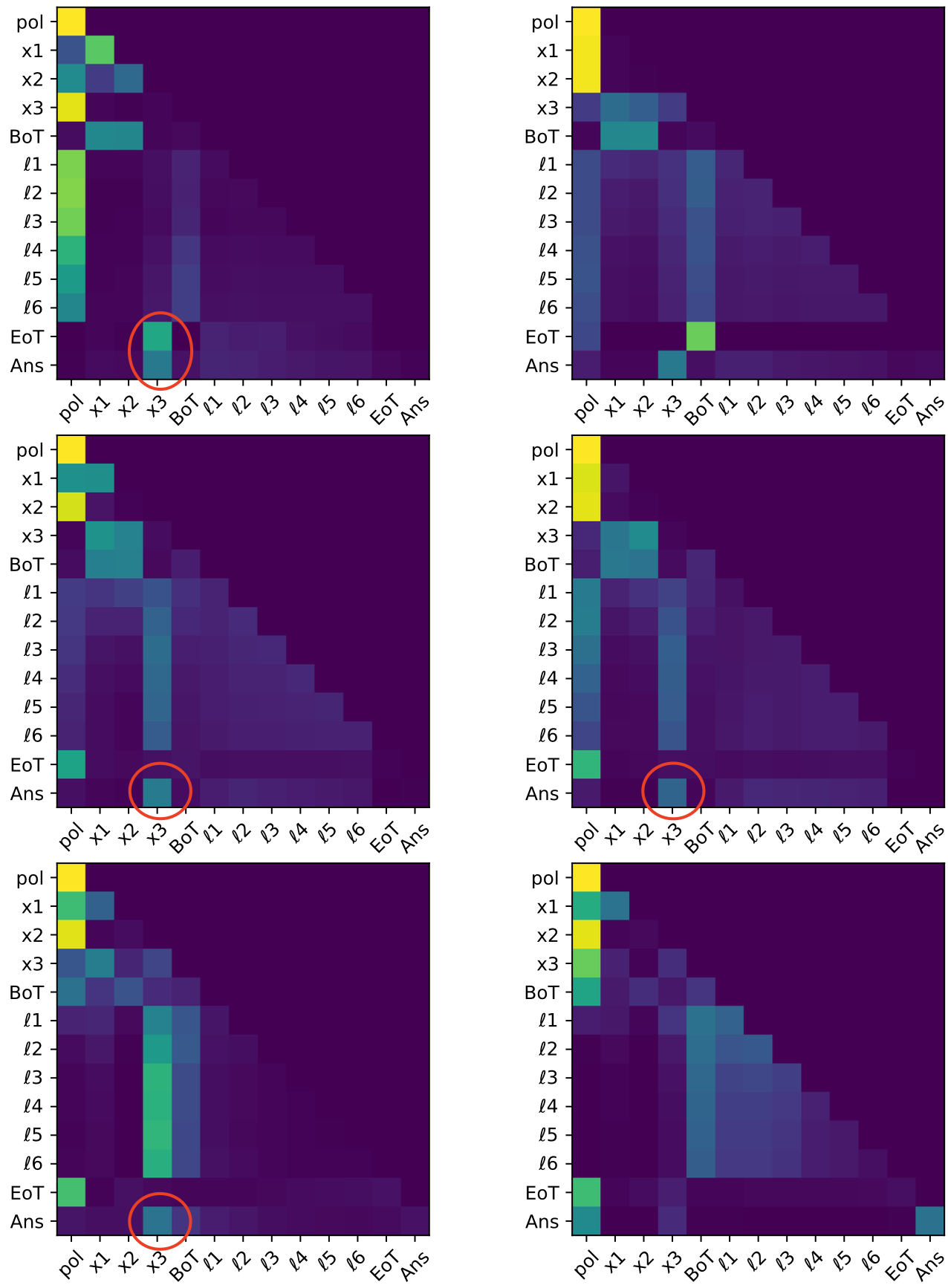
Figure 5: Attention maps for three-layer, two-head transformer on the two-hop polynomial task. [Ans] token attends strongly to x3, demonstrating a copy-like direct input routing strategy.
Activation patching causally corroborates these findings. Patching clean activations into x2-corrupted runs at latent positions reinstates high accuracy, implicating latent intermediate propagation. Patching for x3-corruptions at Ans uniquely restores performance, consistent with late-stage direct routing.
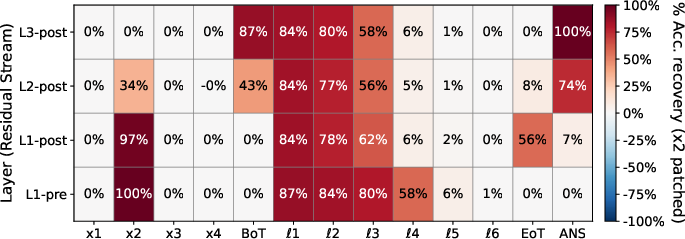
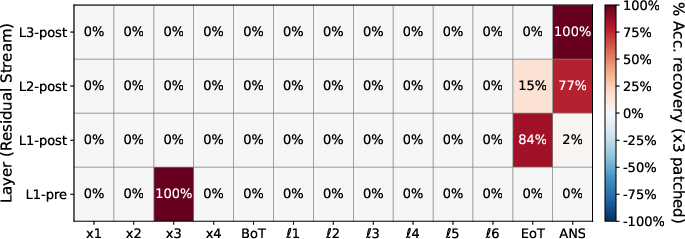
Figure 6: Activation patching for x2-corrupted runs shows substantial accuracy recovery when patching latent thought positions, identifying the latent channel as causally essential for s2.
Depth-Induced Bottleneck and Compression Phenomena
For tasks exceeding three hops, CODI does not reliably instantiate a full sequential latent rollout. Instead, mechanistic analyses show that only the final intermediate states (typically sn and sometimes sn−1, sn) are strongly decodable, and attention continues to directly route the last input (xn+1) to [Ans]. Earlier intermediates vanish from the latent trajectory, and activation patching recovery concentrates on late latent tokens and answer boundaries.

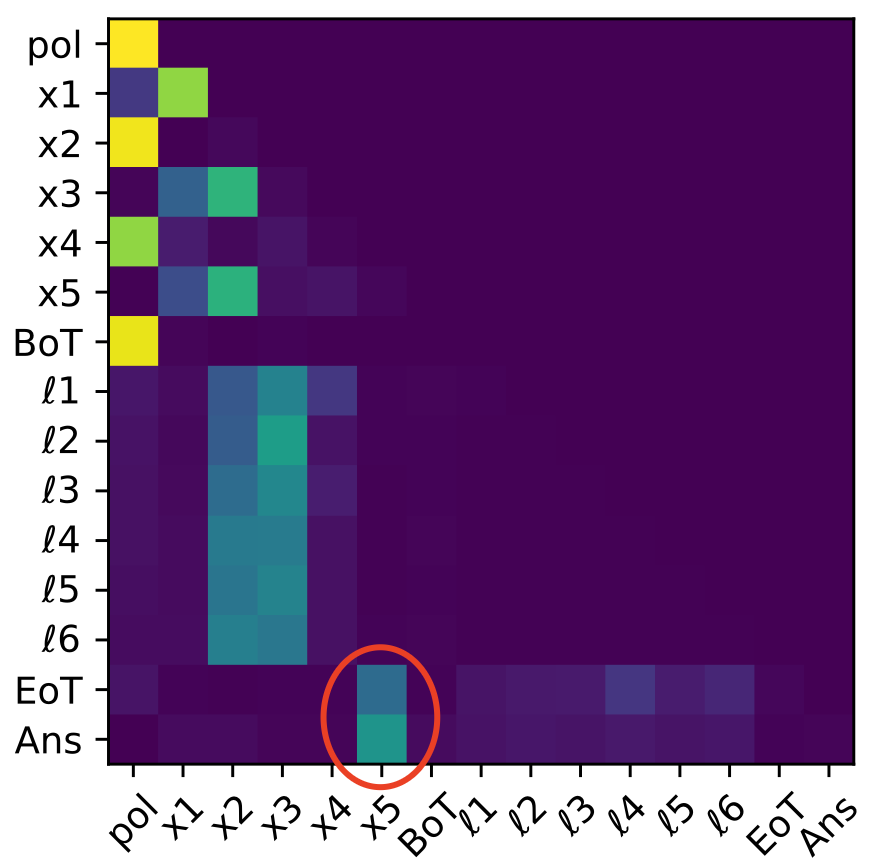
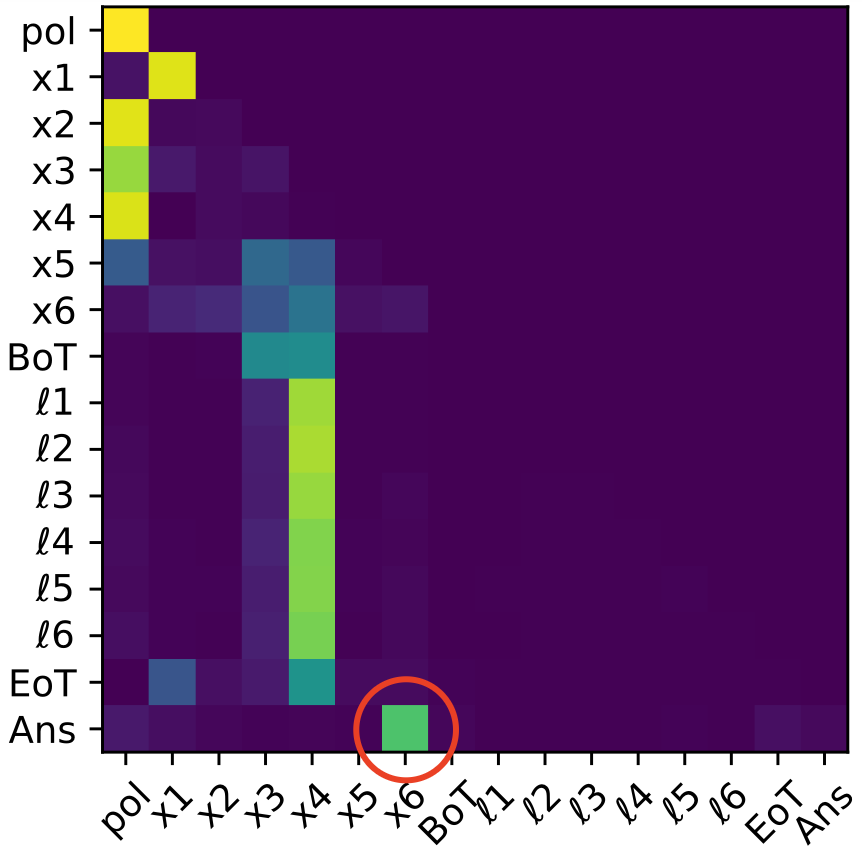
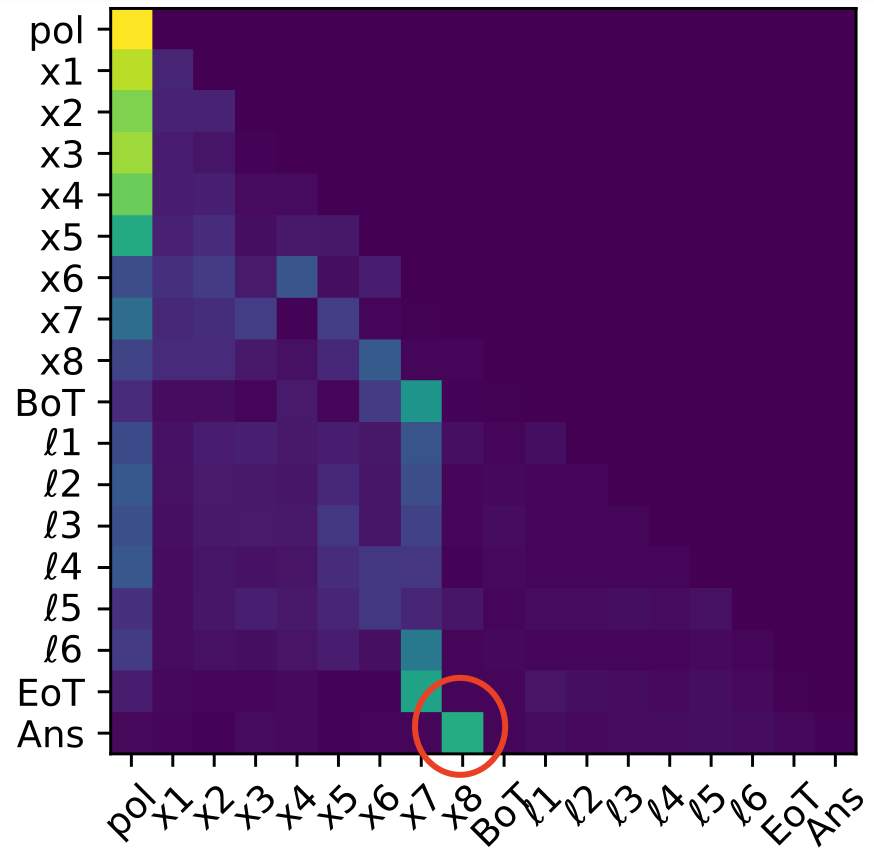
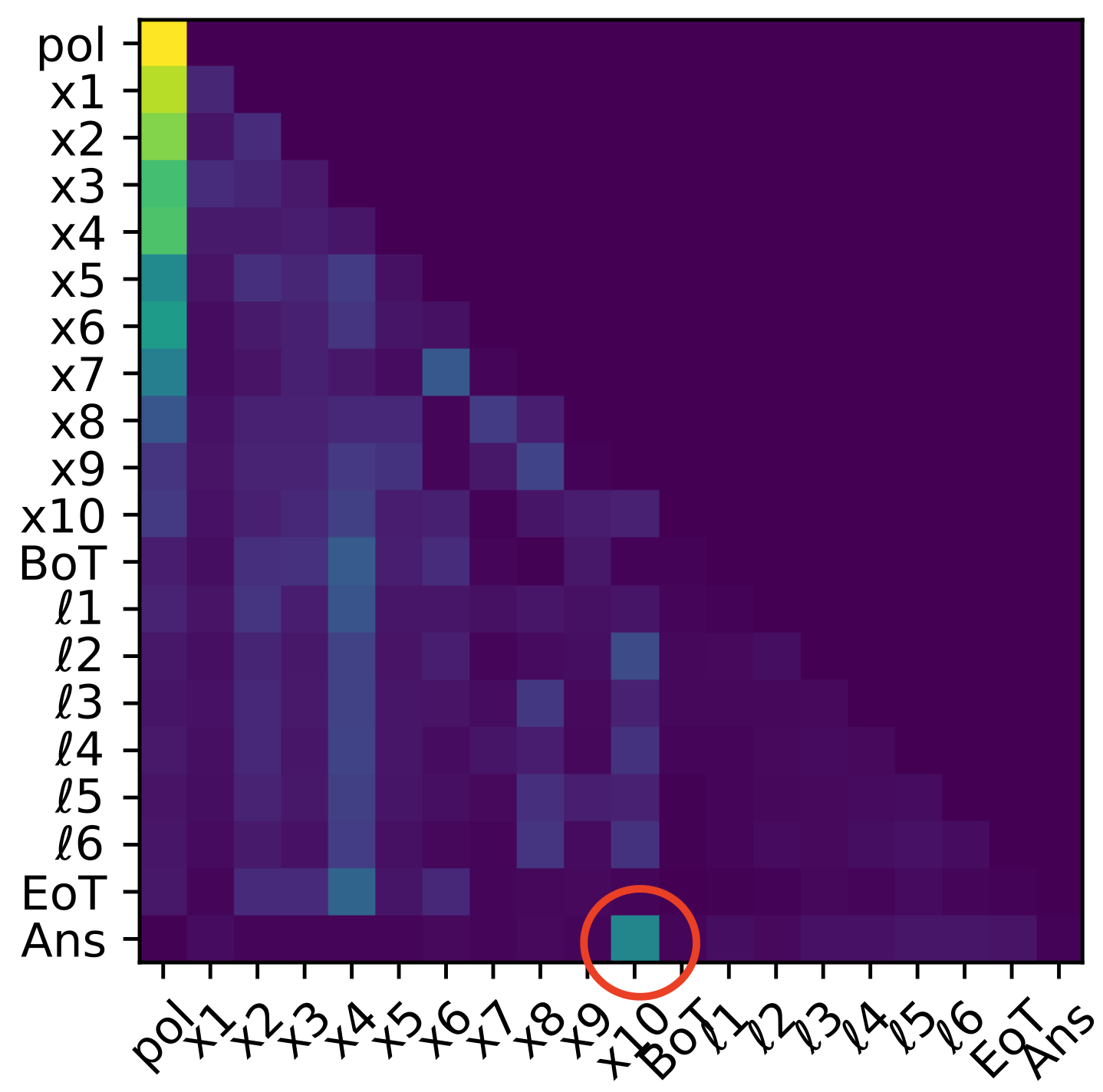
Figure 7: Logit lens on four-hop task reveals collapse of earlier bridge state decodability; only the final intermediate s4 persists in latent computation.
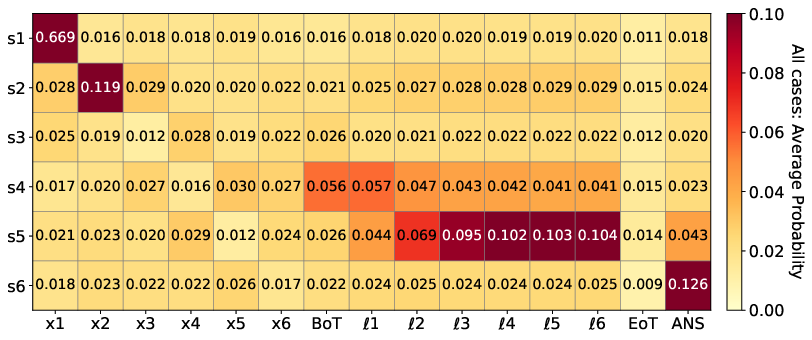
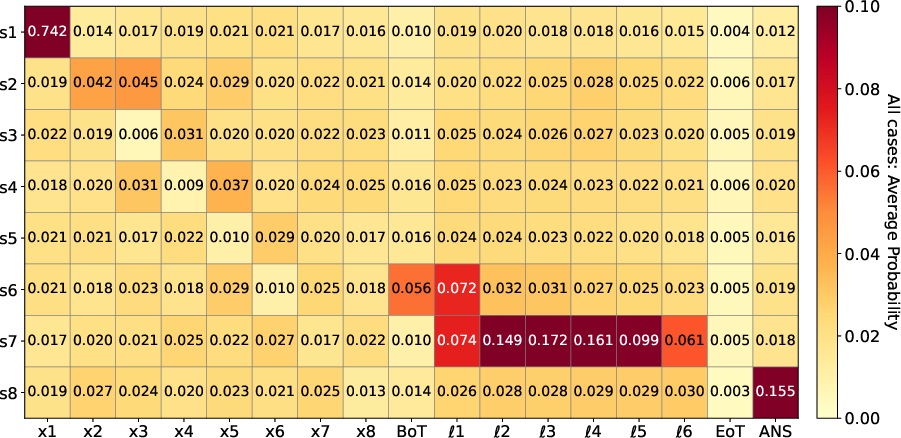
Figure 8: Five-hop task: mechanistic pattern of partial latent reasoning and late-stage fusion remains, with only terminal intermediates being decodable.
The Prime–Composite Modulus Split and Theoretical Explanation
The mechanistic signature of late bottleneck partial rollouts is robust across composite moduli but fails for prime moduli. When m is prime, model accuracy drops, and intermediate states are not decodable in the latent stream. Theoretical analysis attributes this to the algebraic structure of the update rule:
- Composite moduli: update steps can collapse state information (many-to-one contractions), rendering late suffixes of intermediates predictive enough for accurate answers; the label sT depends mainly on a compressed summary of a short terminal suffix.
- Prime moduli: each update acts as a permutation, preserving complete history dependence; thus, faithful step-by-step computation is required, exceeding the fixed latent computational budget of CODI.
Ablation Studies and Comparison with Baselines
Varying the number of latent steps, model depth/width, and distillation loss confirms the qualitative stability of these mechanistic findings. Teacher-guided compression is identified as the main driver of partial, late-bottleneck strategies under composite moduli. Fully explicit CoT-trained transformers maintain sequential rollouts and outperform both CODI and standard (non-CoT) transformers in the prime modulus regime.
Implications and Future Directions
Practical Implications
Mechanistic findings clarify essential failure modes for CODI-style Latent-CoT models on sequential tasks requiring incompressible, full-history computation. They reveal that latent compute budget and teacher-guided compression can favor shortcut and bottleneck strategies, potentially undermining generalization and faithfulness when information flow cannot be collapsed. These insights stress the need for adaptive allocation of latent resources and for mechanistically robust architectures in domains requiring chain-like reasoning.
Theoretical Implications
The prime–composite modulus split introduces a principled mechanistic probe for reasoning faithfulness versus shortcut induction. Composite-ring tasks analogize naturalistic many-to-one mappings in language and learning, where compression may suffice; prime-modulus tasks demand genuine long-range sequential propagation.
Future Research Directions
- Generalize mechanistic toolbox to more realistic, non-algorithmic sequential reasoning domains.
- Explore latent-CoT objectives that adapt latent compute to the compressibility and effective length of underlying computation.
- Study whether the prime–composite split and compression dependence generalize to alternative architectures and more sophisticated agents.
Conclusion
The paper provides a precise mechanistic account of how CODI-style Latent-CoT models compute on sequential multi-hop tasks. CODI achieves stepwise reasoning only for shallow tasks; deeper tasks induce a drastic collapse into compressed, late-stage bottleneck strategies, particularly when the structure of the problem admits many-to-one contractions. Prime-composite splits highlight the limitation of latent-coT compression: when faithful full-history propagation is indispensable, CODI fails. These results set a foundation for further systematic mechanistic audits of latent reasoning protocols and for the design of more adaptive, robust reasoning architectures.
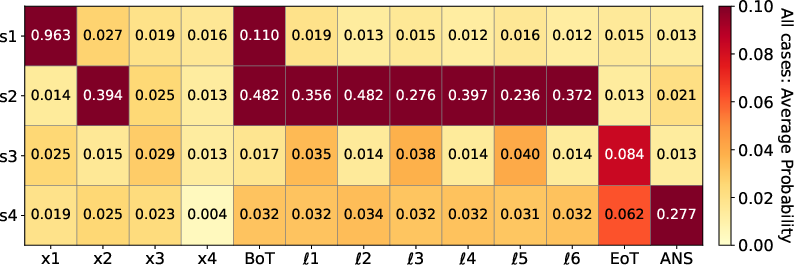
Figure 9: Logit lens on three-hop polynomial task visualizes early formation and maintenance of bridge state s2 in latent channel, but decodability of s3 emerges only late, supporting sequential but depth-limited reasoning.