What If We Allocate Test-Time Compute Adaptively?
Abstract: Test-time compute scaling allocates inference computation uniformly, uses fixed sampling strategies, and applies verification only for reranking. In contrast, we propose a verifier-guided adaptive framework treating reasoning as iterative trajectory generation and selection. For each problem, the agent runs multiple inference iterations. In each iteration, it optionally produces a high-level plan, selects a set of reasoning tools and a compute strategy together with an exploration parameter, and then generates a candidate reasoning trajectory. A process reward model (PRM) serves as a unified control signal: within each iteration, step-level PRM scores are aggregated to guide pruning and expansion during generation, and across iterations, aggregated trajectory rewards are used to select the final response. Across datasets, our dynamic, PRM-guided approach consistently outperforms direct test-time scaling, yielding large gains on MATH-500 and several-fold improvements on harder benchmarks such as AIME24 and AMO-Bench. We characterize efficiency using theoretical FLOPs and a compute intensity metric penalizing wasted generation and tool overhead, demonstrating that verification-guided allocation concentrates computation on high-utility reasoning paths.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper asks a simple question: instead of giving every problem the same amount of computer “thinking time,” what if we give easy problems less time and hard problems more time, and use a smart checker to guide that effort? The authors build a system that solves math problems by trying different reasoning paths, checking each step as it goes, and focusing its effort on the most promising paths.
Key Questions
The paper explores three main questions in easy-to-understand terms:
- How can we use extra compute (computer effort) at test time more wisely, instead of just using the same approach for every problem?
- Can a step-by-step checker help the model avoid bad reasoning early and steer it toward better solutions?
- Does this adaptive approach improve accuracy and use compute more efficiently compared to standard methods?
How Did They Do It?
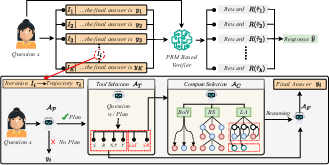
Think of solving a math problem like exploring different routes to a destination. The system doesn’t just pick one route and hope it works. It tries multiple routes (called “iterations”), checks the steps along the way, and chooses the best one.
What is a PRM (Process Reward Model)?
A PRM is like a careful coach or referee that looks at each reasoning step and gives it a score from 0 to 1. High scores mean the step looks correct and consistent. The system uses these scores to:
- Prune bad branches (stop wasting time on weak paths).
- Prefer strong branches (spend more effort where steps look solid).
- Pick the best final answer among several tries.
The agent repeats the following steps for each problem:
- Planning: Make a simple high-level plan before diving into details.
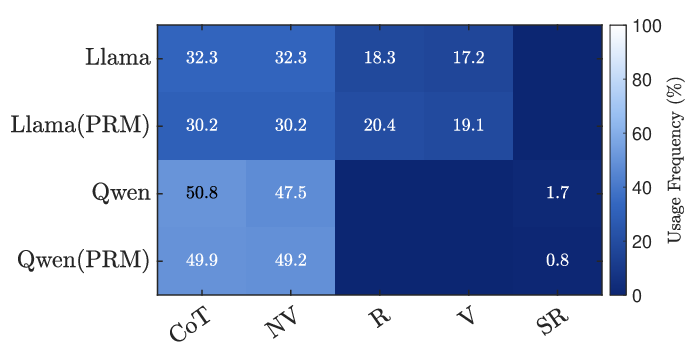
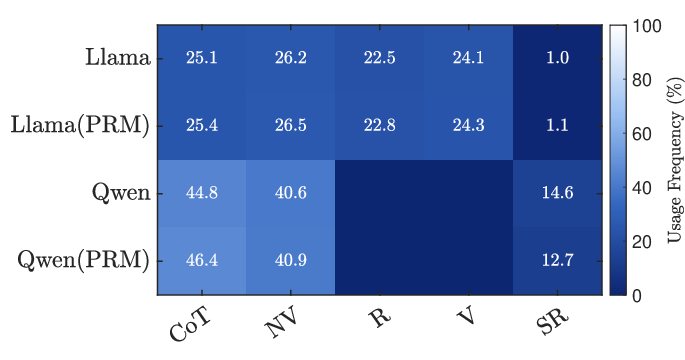
- Tool selection: Choose helpful “tools” like chain-of-thought (step-by-step reasoning), self-reflection (critique and fix), and numeric checks (verify calculations).
- Compute strategy selection: Decide how to explore solutions (for example, try many options or search deeper).
- Answer extraction: Present the final answer clearly from the chosen reasoning path.
Importantly, this adaptivity happens without retraining the model. The system uses structured prompts (instructions) to play different roles (planner, tool selector, strategy selector, checker), all powered by the same base LLM plus the PRM.
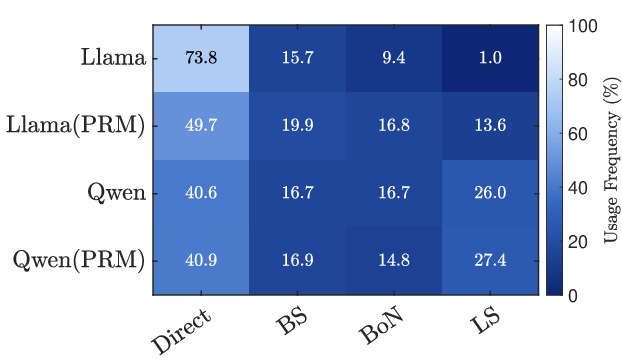
Search strategies (with everyday analogies)
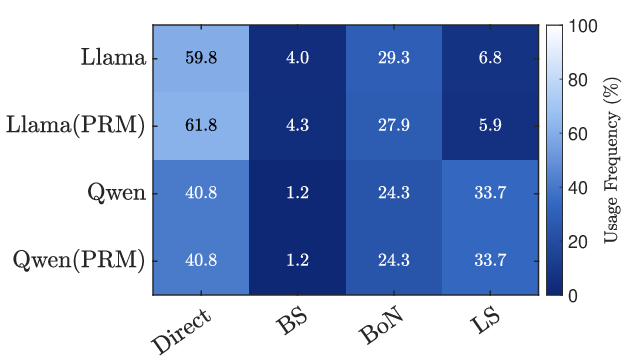
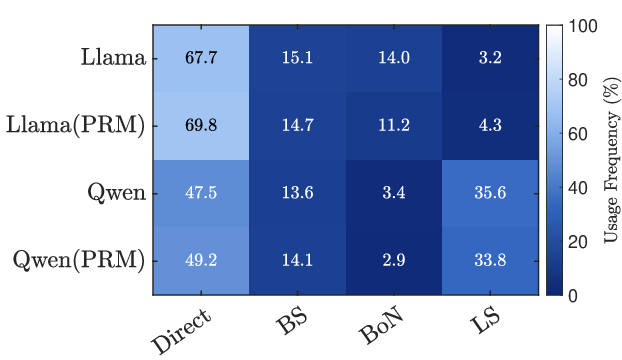
To make exploration smarter, the system uses different strategies:
- Best-of-N: Like taking N independent shots at the problem and picking the best one.
- Beam Search: Like following several promising routes at the same time and dropping weaker ones as you go.
- Lookahead: Like peeking a few steps ahead down each possible path to see which next step looks most promising, then committing to that single step and repeating.
Throughout generation, the PRM scores each step. Within one try (an iteration), these scores help keep only the best partial solutions. Across multiple tries, the system picks the overall best reasoning path.
Measuring compute in simple terms
- Theoretical FLOPs: Think of this as the total amount of tiny math operations the computer did—basically the total effort spent across all models (the problem solver, the controllers, and the checker).
- Compute Intensity: This score tries to capture “how much useful reasoning we did” after penalizing wasted tokens and extra checker/controller overhead. Lower is better: it means the system focused effort where it mattered.
Main Findings
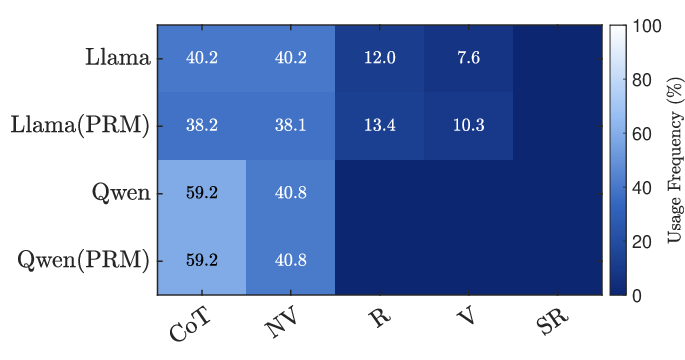
Here’s what the authors found when solving math problems across three datasets (MATH-500, AIME24, and AMO-Bench) using two models (Llama-3.1-8B-Instruct and Qwen-2.5-7B-Instruct):
- Adaptive beats static: Dynamically choosing tools and strategies, guided by PRM scores, outperforms using a fixed approach for every problem.
- Big accuracy gains:
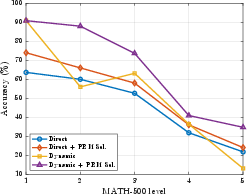
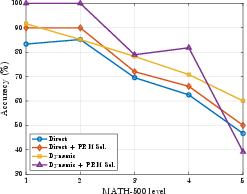
- On MATH-500, accuracy jumped from 43.8% to 65.4% for Llama-3.1-8B, and from 71.2% to 81.4% for Qwen-2.5-7B.
- On AIME24, it improved from 3.3% to 10.0% (Llama) and from 6.67% to 13.3% (Qwen).
- On AMO-Bench, it doubled from 2.0% to 4.0% for both models.
- Difficulty matters: The biggest improvements were on easier-to-medium problems (Levels 1–4 on MATH-500). On the very hardest problems (Level 5), the checker’s signals are less reliable, so gains are smaller.
- Better compute use: The system spends more effort on high-utility paths and less on obviously weak ones. Even when total compute goes up, it is used more effectively to deliver higher accuracy compared to simply “trying more” without guidance.
Implications and Impact
- Smarter effort allocation: Instead of treating all problems the same, the system adapts—quickly solving easy ones and investing more in hard ones. This saves time and improves reliability.
- Training-free and flexible: The approach doesn’t require retraining big models. It plugs in a step-checker (PRM) and uses role-based prompts, so it’s practical to deploy.
- Beyond math: The core idea—use intermediate verification to guide reasoning and compute—can be applied to other areas like coding (unit tests as verifiers), long-answer questions (consistency checks), or safety-critical decisions (domain-specific checks).
- Next steps: Stronger, difficulty-aware checkers could further improve results on very hard problems. Learned policies might also optimize when to stop, which tools to use, and how much to explore given strict compute or time budgets.
In short, the paper shows that “think smarter, not just more” is a winning strategy: using a step-by-step checker to adapt how much and where the model thinks leads to more accurate answers and better use of compute.
Collections
Sign up for free to add this paper to one or more collections.