- The paper presents TraceLLM, which achieves state-of-the-art requirements traceability using iterative prompt engineering and optimized demonstration selection strategies.
- It employs a detailed four-stage methodology including stratified dataset partitioning, empirical prompt design, prompt enrichment, and cross-domain robust evaluation.
- Empirical results show significant gains in precision and recall, validating the cost-effective, adaptable use of LLMs for semi-automated traceability in software engineering.
TraceLLM: Prompt Engineering with LLMs for Automated Requirements Traceability
Introduction
TraceLLM systematically investigates leveraging LLMs with prompt engineering for requirements traceability tasks. Traditional approaches—manual, IR, ML, and DL—struggle with precision and generalizability; transformers such as BERT and RoBERTa improve semantics but require fine-tuning and large labeled datasets. Recent LLMs (e.g., GPT-4, Claude, Gemini, LLaMA) support ICL, enabling flexible, low-setup adaptation to new tasks via prompt programming. However, optimal prompt construction and demonstration selection strategies (DSSs) for traceability link prediction remain largely unexplored. TraceLLM introduces and validates a comprehensive, iterative methodology optimizing prompt engineering and DSSs across multiple LLMs and software engineering domains.
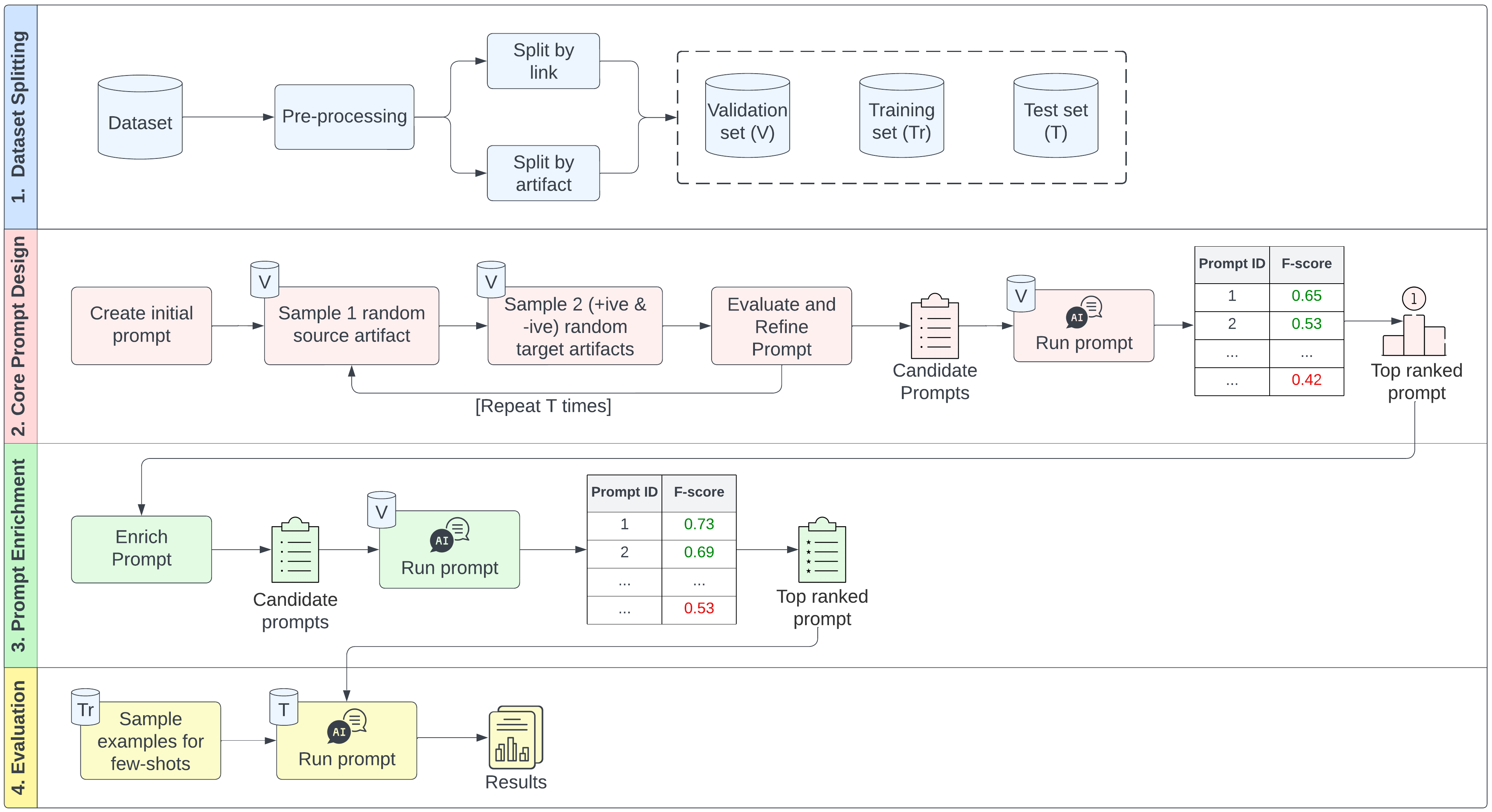
Figure 1: LLM-based traceability methodology (TraceLLM) illustrates the systematic, multi-stage process for prompt engineering and evaluation.
Methodology: TraceLLM Framework
TraceLLM consists of four principal stages: (1) stratified dataset partitioning (by link or artifact, addressing TLC, TLG, TLX); (2) core prompt design via empirical, iterative human-in-the-loop refinement; (3) prompt enrichment (role/context/reasoning integration); and (4) robust evaluation on diverse benchmarks and LLMs. Demonstration selection (few-shot setting) is systematically varied by random, diversity-based, similarity-based, and uncertainty-based (label-aware) methods.
Prompt engineering follows best practices for clarity, explicit IO mapping, and minimal, controlled edits per iteration. Enrichment explores model role priming, explicit artifact type/context, and task orientation (e.g., fulfillment vs. implementation). Comprehensive ablation studies confirm sensitivity to both prompt phraseology and enrichment dimensions.
Demonstration Selection and Effects
TraceLLM investigates four DSSs, with rigorous balancing of positive/negative demonstrations:
- Diversity-based: maximizes inter-example semantic dissimilarity; encourages broader latent task coverage.
- Similarity-based: selects samples most semantically near the test instance; enhances local adaptation.
- Uncertainty-based: prioritizes low-confidence/misclassified examples; exposes model to challenging cases.
- Label-aware: maintains class distribution equilibrium in few-shot prompt context, mitigating label bias.
Demonstration selection is visualized via t-SNE projection, isolating submodular/greedy selection benefits (semantic spread vs. cluster-centric).
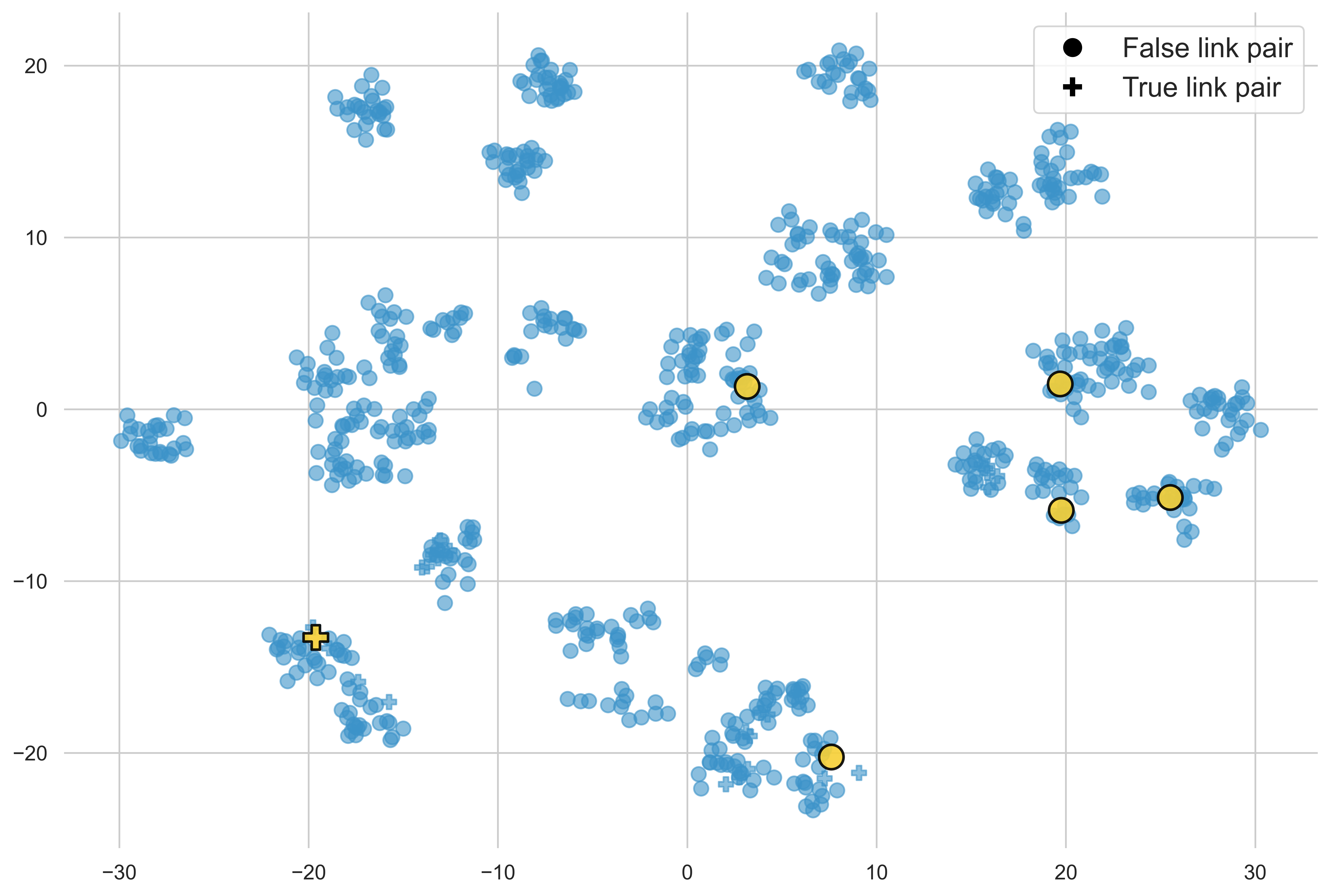
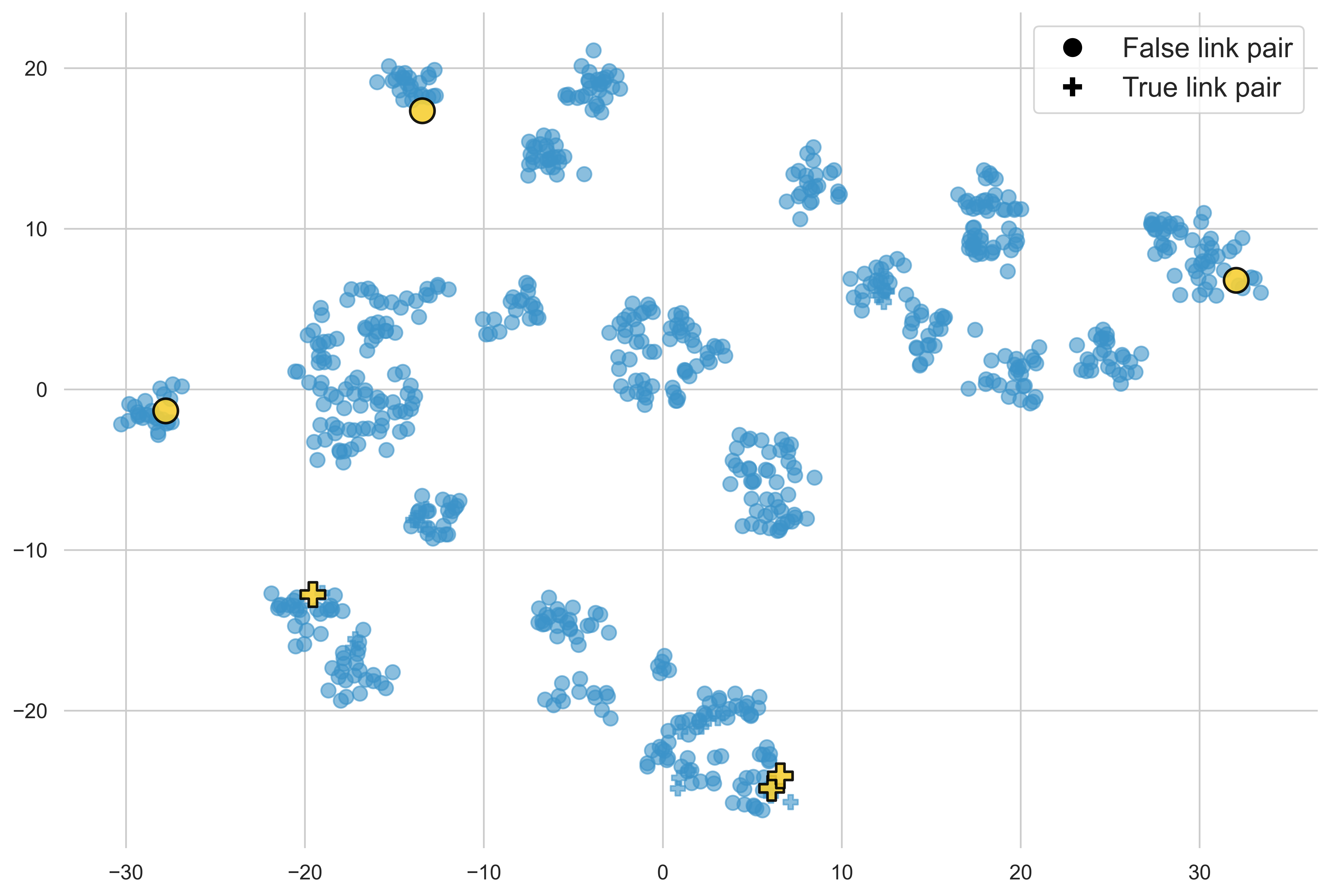
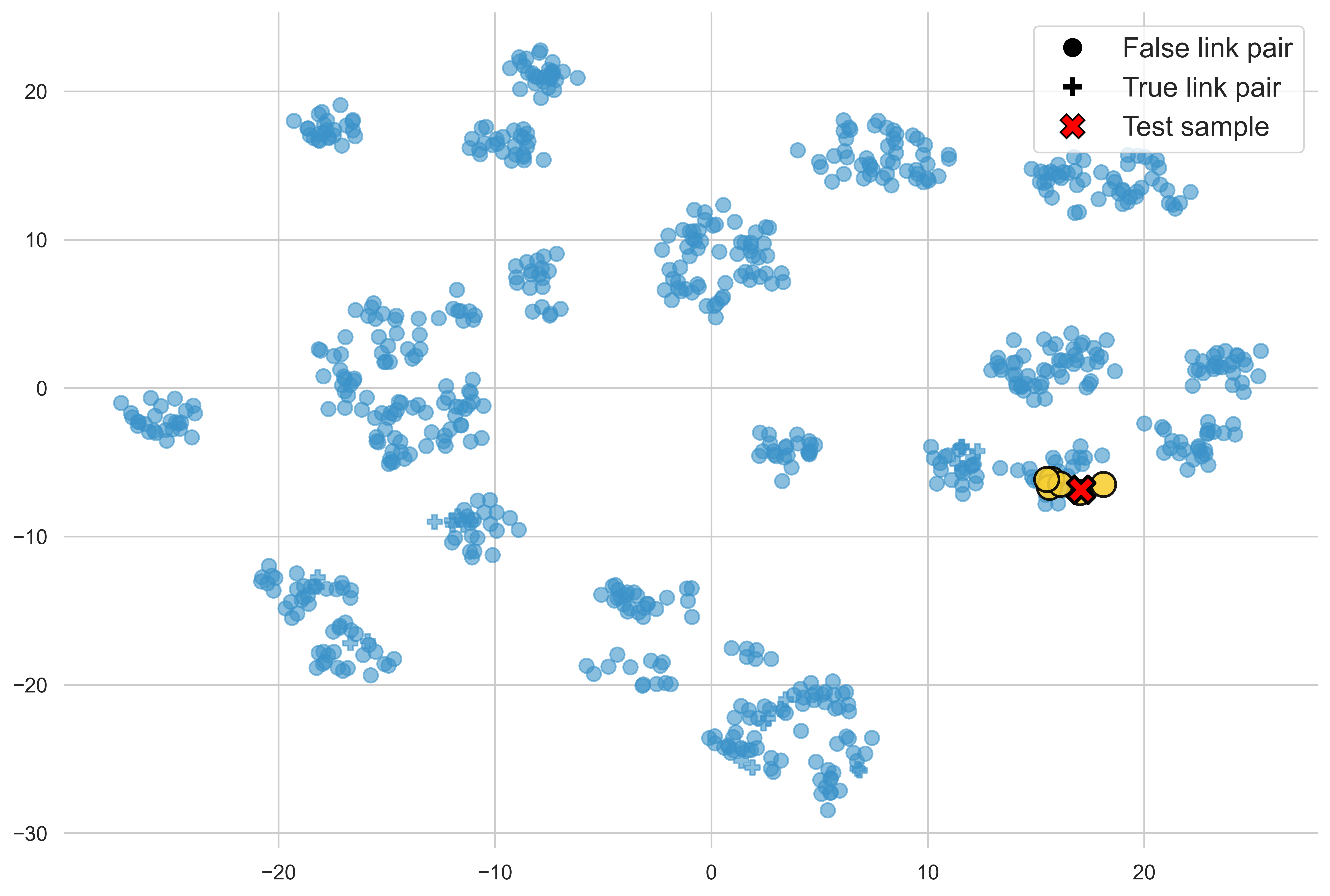
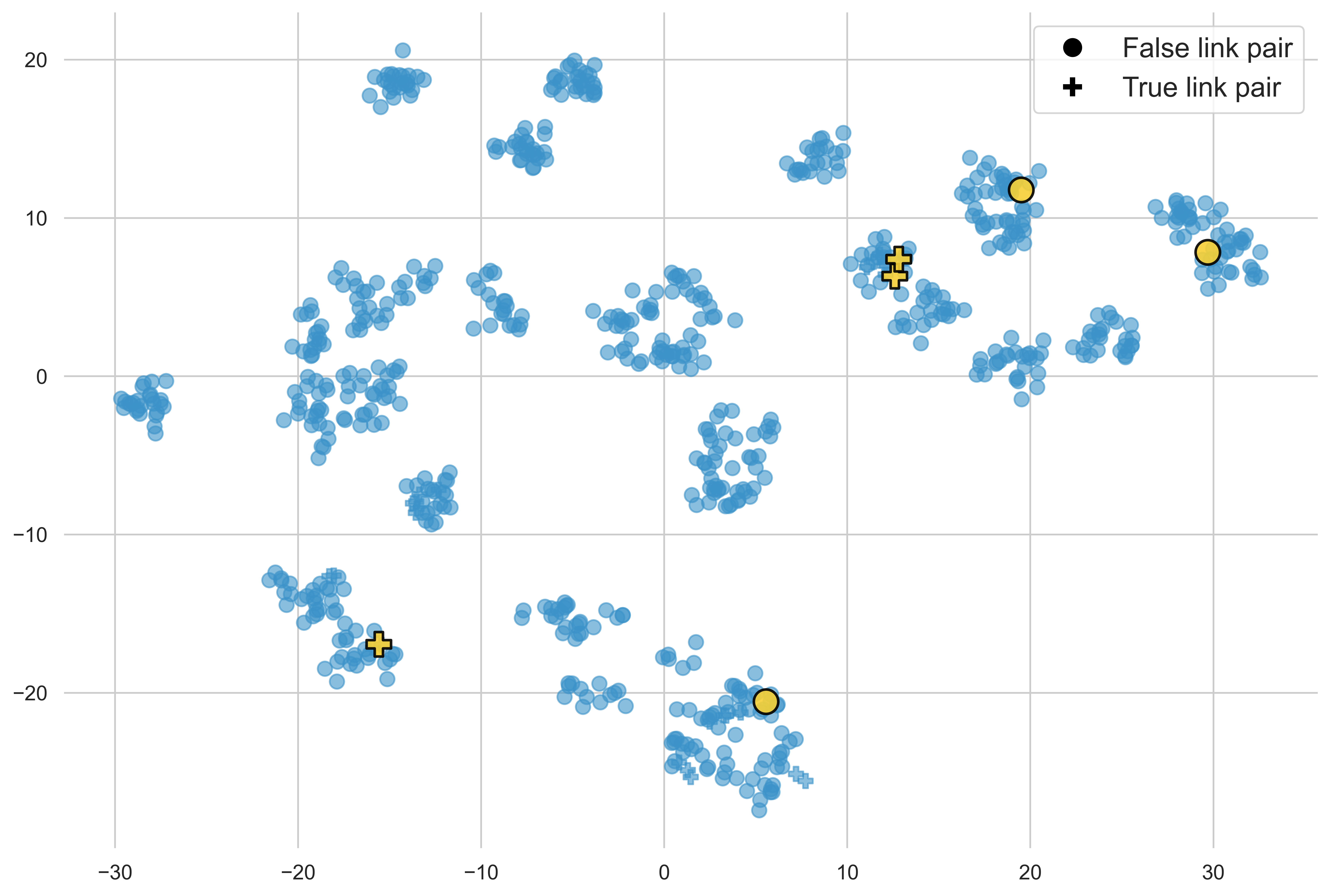
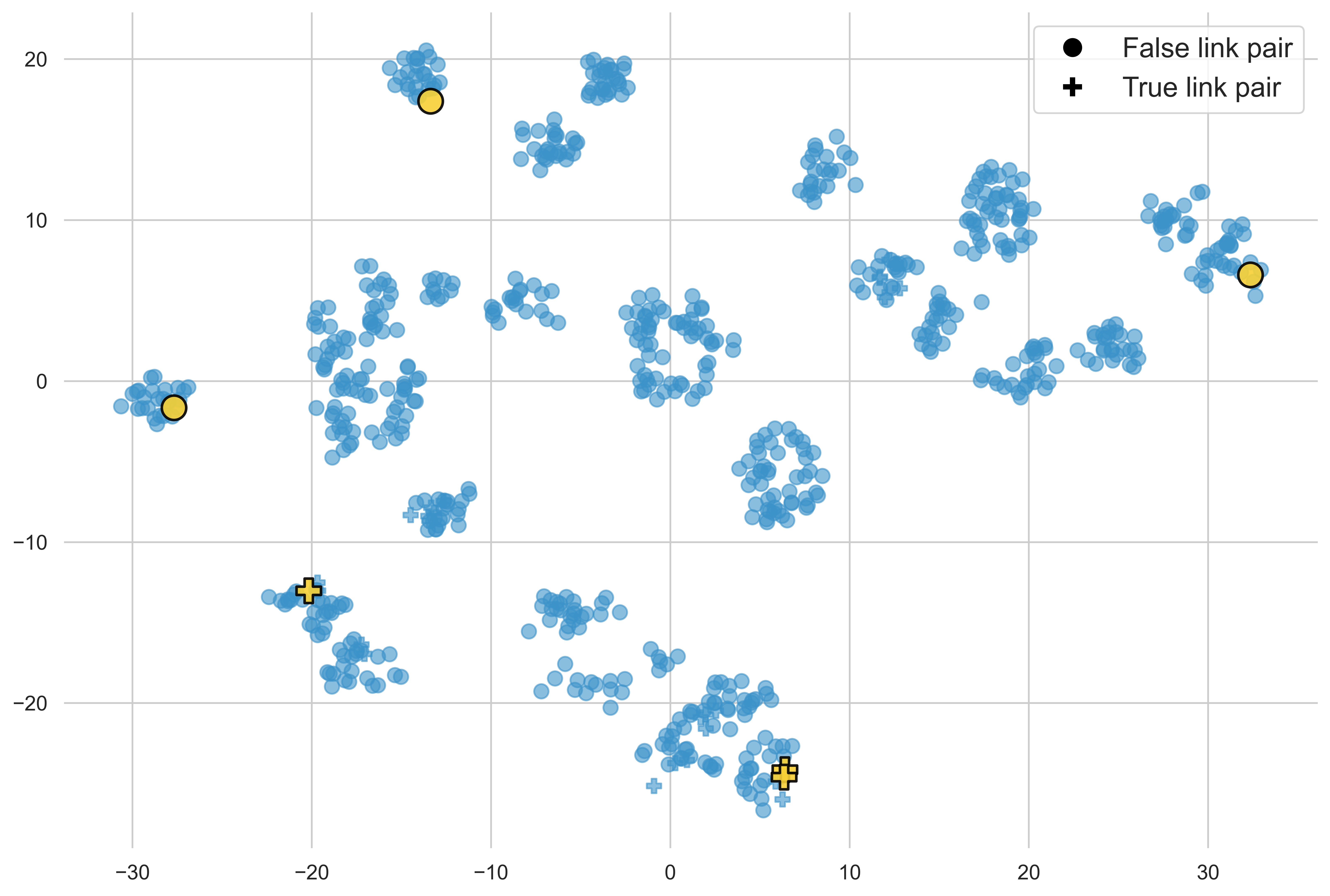
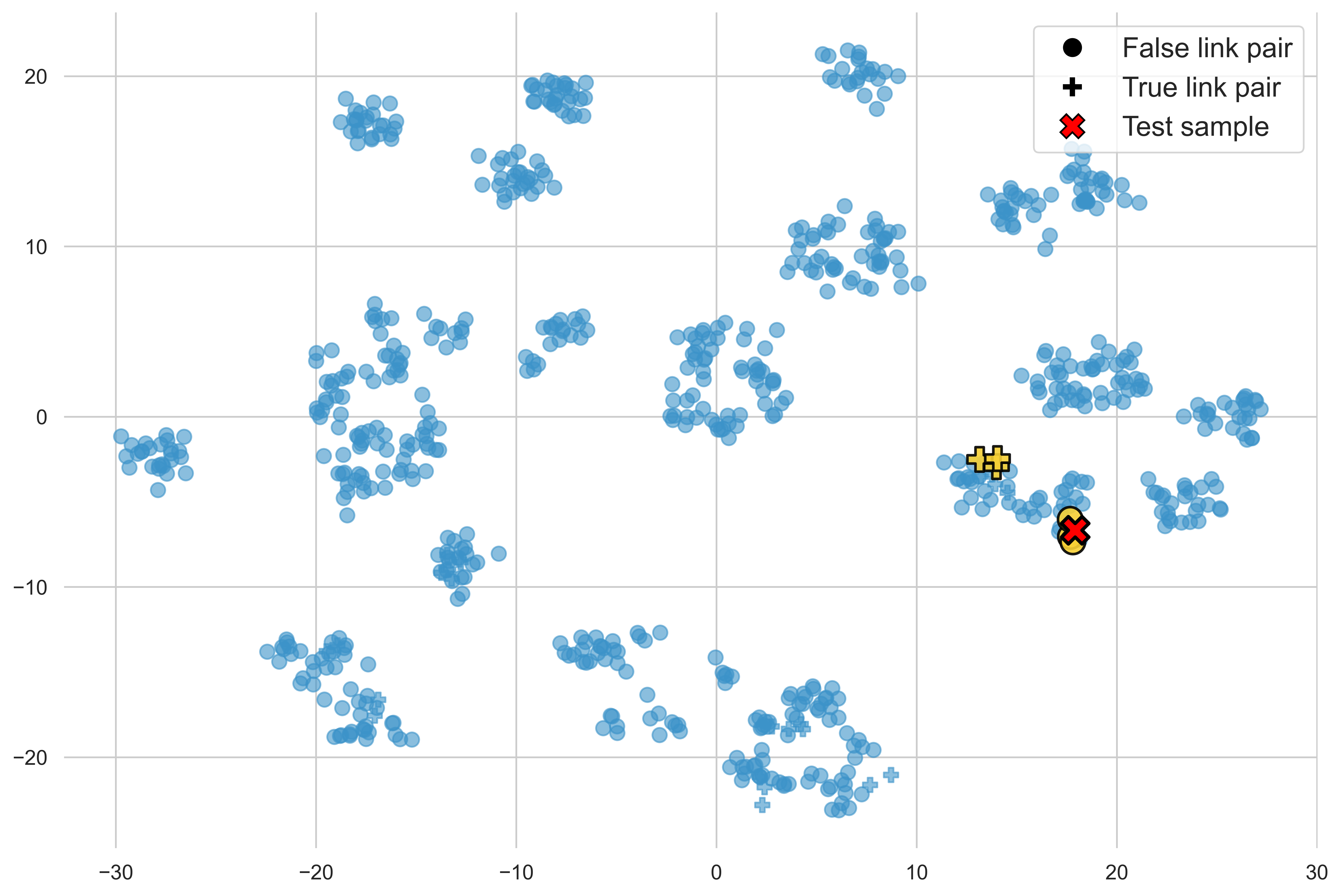
Figure 2: t-SNE visualization of demonstration selection strategies—random, diversity, and similarity; balanced selections ensure label representativity.
Iterative Prompt Engineering and Enrichment
Systematic ablation and error data analysis reveal that adding domain knowledge, explicit artifact roles, and relationship focus (e.g., replacing "fulfill" with "directly fulfill") substantially improves both model selectivity (precision) and coverage (recall):
- Initial prompts lacking context result in high false positives; model interprets any relation as a trace.
- Including domain/role context and explicit artifact relationship yields higher precision without recall loss.

Figure 3: Initial prompt and an LLM response, demonstrating over-prediction of trace links in absence of domain context.

Figure 4: Enriched prompt with explicit contextual information yields improved artifact disambiguation.
Further, moving from generic ("fulfill") to highly specific ("directly fulfill") reduces model overgeneration, as shown in the performance delta between prompt variants.

Figure 5: Prompt with artifact type information, achieving improved specificity over all-purpose prompts.

Figure 6: Additional enrichment with explicit relationship definition enhances traceability precision.

Figure 7: LLM response to unlinked artifacts under improved prompting still indicates model limitations when latent relationships exist.

Figure 8: Final enhanced prompt maximally restricts to direct, explicit fulfillment for optimal selection pressure.
Empirical Results and Analysis
Effects of Prompt Engineering
Evaluation on the CM1 benchmark shows an iterative improvement from F2-scores of 0.43 (uninformative prompt) to 0.70 (fully-enriched prompt, recall-oriented). Label-aware, diversity-based demonstration selection with only 2 examples achieves strong results; increasing demonstrations further is generally neutral or detrimental beyond initial gains. However, few-shot gains are non-uniform and sensitive to selection.
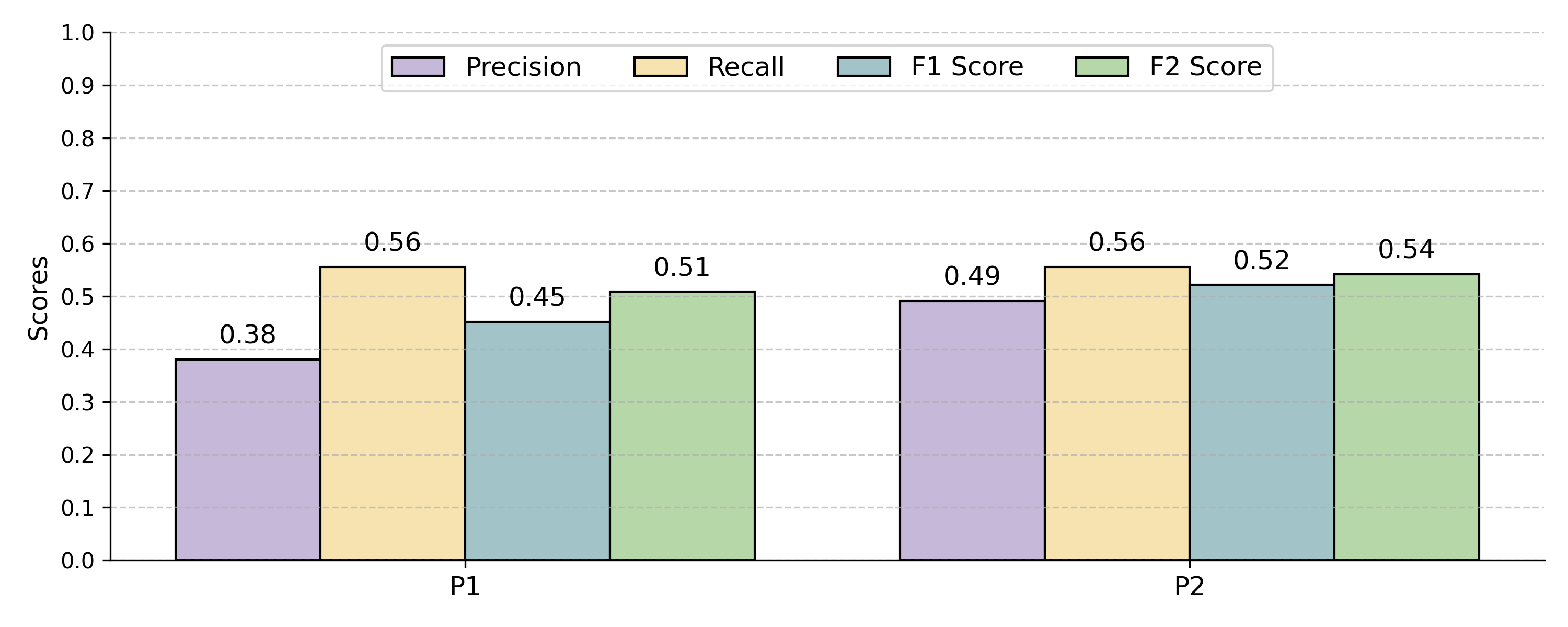
Figure 9: Comparative test performance for base and relationship-enriched prompts, demonstrating impact of explicitness.
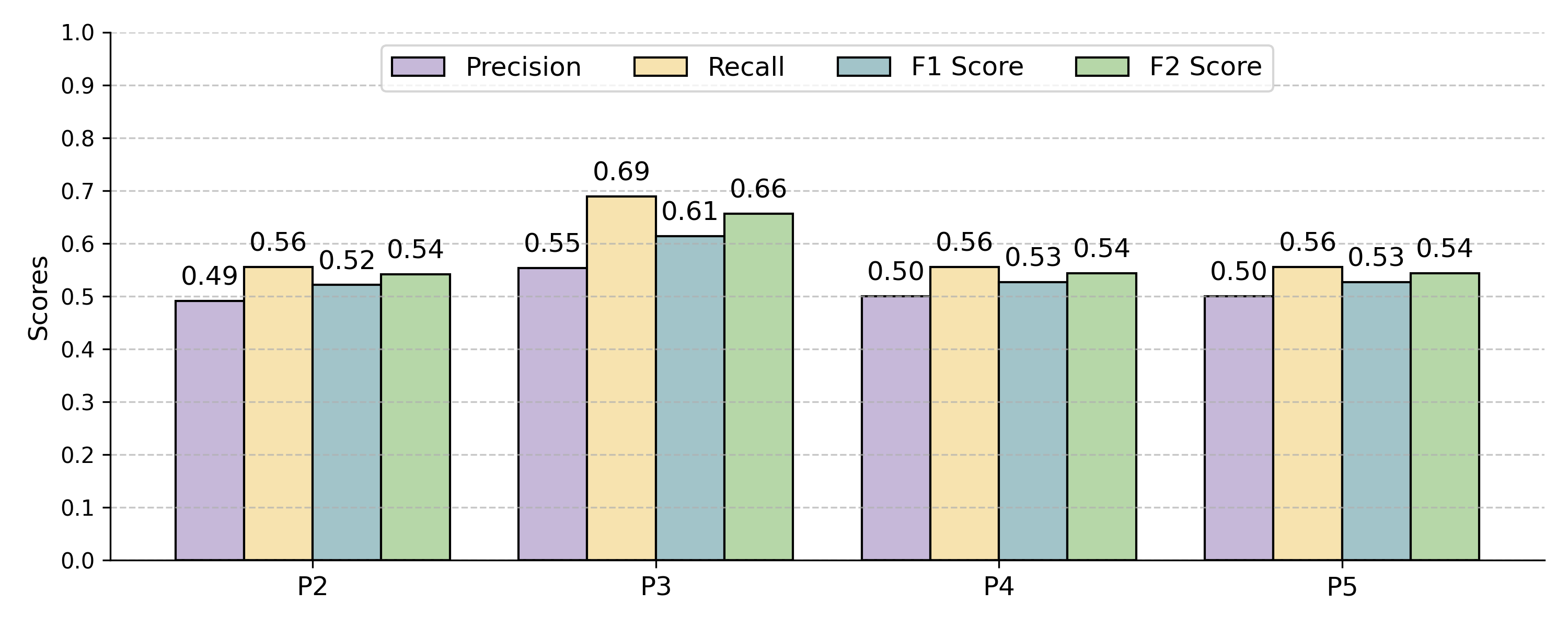
Figure 10: Effect of progressively specialized role-based prompts on traceability link prediction metrics.
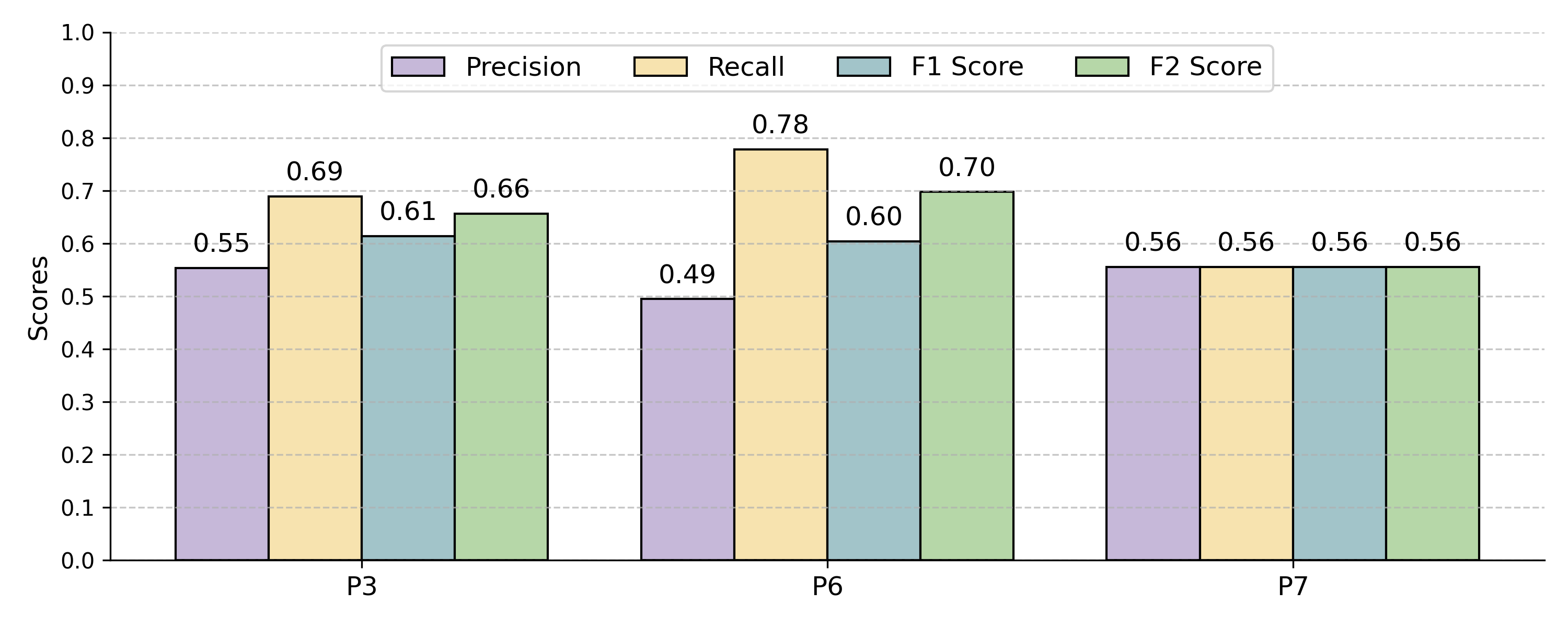
Figure 11: Domain-enriched and reasoning-enriched prompts compared; domain-specific context consistently outperforms explicit CoT-style reasoning.
LLM Cross-Model and Cross-Domain Generalization
Systematic evaluation across eight advanced LLMs (GPT-4o, Claude 3.5, Gemini, LLaMA-3.1) and four datasets (CM1, EasyClinic/UC–{TC,ID}, CCHIT) reveals that:
- Carefully engineered prompts generalize well: a single prompt optimized on CM1 performs competitively on healthcare/regulatory datasets after minor template adaptation.
- LLM-specific prompt engineering provides further, statistically significant improvements for certain proprietary models (GPT-4o, Claude 3.5, Gemini); the effect diminishes with parameter-matched or open-source models. Gains are most prominent for highly constrained, safety-critical datasets.
- Lightweight models (GPT-4o-mini, Gemini Flash, Claude Haiku) with effective prompt engineering match—or exceed—their large counterparts at a fraction of the cost, particularly in zero/few-shot settings.
Demonstration Selection: Statistical Effects
- Label-aware, diversity-based selection (2-shot) yields statistically significant improvements (F2-score +0.15 over random; p<0.001) with greater robustness across runs.
- Random selection is unreliable: variances of 0.03–0.08 in F2, frequently degrading performance below zero-shot baseline.
- Similarity-based and uncertainty-based methods offer no significant improvements over diversity for trace link recovery.
Comparison to State-of-the-Art
TraceLLM outperforms VSM, LSI, LDA, BERT, and recent LLM-based approaches, reaching F2 >0.80 on EasyClinic variants and 0.69 on CCHIT. It closely matches or surpasses advanced handcrafted pipeline approaches (NLTrace, TRAIL, WELR, S2Trace) without any dataset-specific adaptation or model fine-tuning.
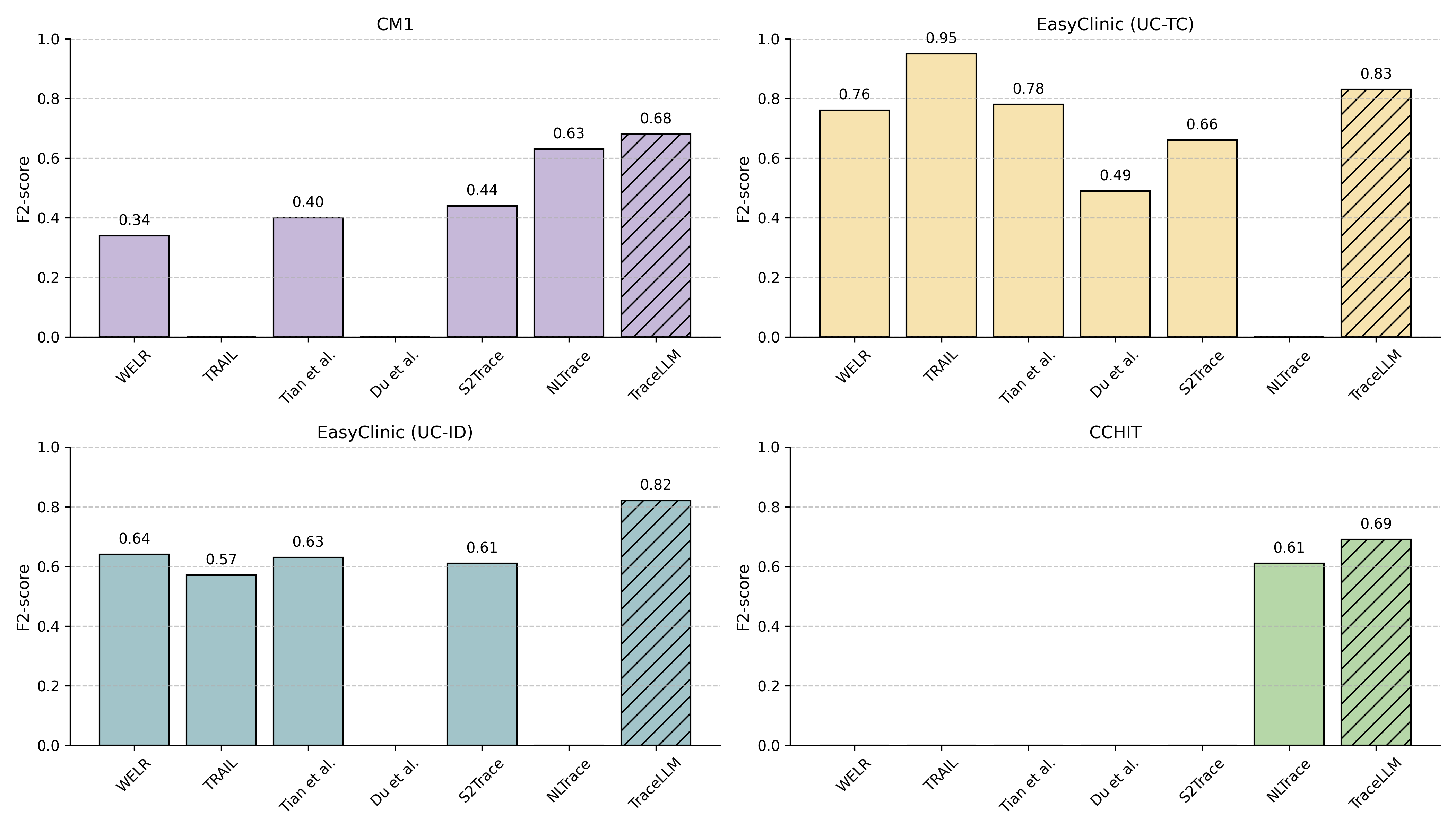
Figure 12: F2-score comparison across datasets: TraceLLM vs. ML, DL, and state-of-the-art ICL traceability techniques; gaps correspond to unavailable results.
Practical Implications and Cost
TraceLLM, with recall-centric optimization (F2), does not address fully automated trace recovery, but instead best supports semi-automated, analyst-in-the-loop workflows. It excels as a candidate link filter for human validation in large-scale/compliance-critical domains.
Costs, critical for industrial adoption, are minimized by using lightweight, high-performing models—inference costs for Gemini 1.5 Flash and GPT-4o-mini are <10% those of flagship models with negligible performance loss.
Theoretical and Future Implications
TraceLLM demonstrates that algorithmic advances in traceability are now dominantly governed by prompt/DSS/role/context optimization, rather than by further scaling LLMs. This invites future research in programmatic prompt generation, meta-learning for prompt search, integration with CoT/ToT paradigms, and industrial validation on large-scale, evolving trace matrices. There is clear evidence that prompt engineering, not model parameter count, now offers the best ROI for traceability link automation in software engineering.
Conclusion
TraceLLM establishes a rigorous, empirically validated prompt engineering and DSS framework for requirements traceability with LLMs. It achieves state-of-the-art performance, generalizes across domains and artifact types, and enables cost-effective, semi-automated traceability for practical workflows. Its reproducible protocol and ablation studies provide a foundation for further systematic advances in LLM-based software engineering automation.