- The paper presents a single-stage framework that integrates camera and LiDAR sensors using modality-specific VAEs and a diffusion transformer.
- It leverages a Unified Latent Anchoring method to align latent features across modalities, thereby stabilizing training and improving cross-modal synthesis.
- Empirical results demonstrate superior performance with improved FID, FVD, mAP, and NDS metrics, setting a new benchmark for autonomous driving data synthesis.
UniDriveDreamer: A Single-Stage Multimodal World Model for Autonomous Driving
Introduction
The paper "UniDriveDreamer: A Single-Stage Multimodal World Model for Autonomous Driving" (2602.02002) presents a novel framework for synthesizing multimodal future observations in autonomous driving without reliance on intermediate representations or cascaded modules. Building on the concept of world models, UniDriveDreamer addresses the limitations of previous methods focused predominantly on single-modality generation, such as either multi-camera video or LiDAR sequence synthesis. The framework proposes a unified approach that integrates diverse sensor data and enhances both the generation quality and downstream task performance.
Framework Overview
UniDriveDreamer consists of four primary components: modality-specific VAEs for encoding multi-view camera images and LiDAR range maps into a latent space, a layout encoder for structured scene data, a text encoder for multi-view prompts, and a diffusion transformer to model spatiotemporal and cross-modal consistency.
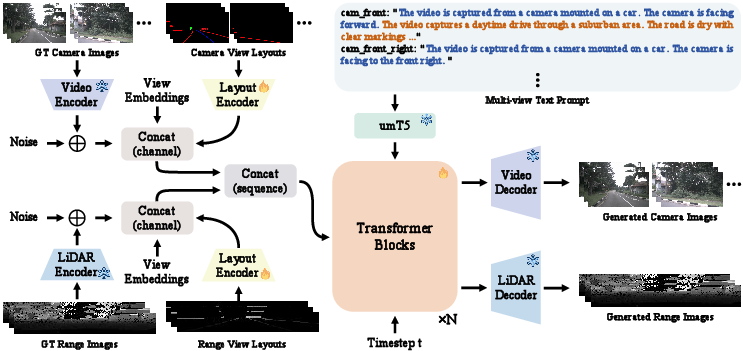
Figure 1: The overall framework of UniDriveDreamer.
Key innovations include the LiDAR-specific variational autoencoder and the Unified Latent Anchoring (ULA) method, designed to ensure compatibility and stabilize training by aligning the distribution of latent features across modalities. This alignment facilitates deep fusion and allows the diffusion transformer to effectively model geometric correspondences and temporal evolution within each modality.
Empirical Results
Quantitative and qualitative evaluations demonstrate that UniDriveDreamer achieves superior performance against existing single-modal and multimodal synthesis methods. For camera video generation, UniDriveDreamer scores an FID of 2.81 and an FVD of 11.44. For LiDAR synthesis, it achieves improvements with an MMD of 0.27 and a JSD of 0.039, marking substantial advancements over comparable methods like UniScene.
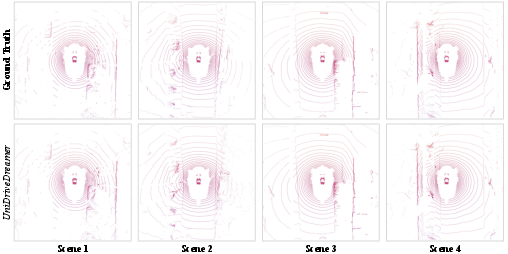
Figure 2: Qualitative visualization of LiDAR reconstruction.

Figure 3: Qualitative visualization of multimodal outputs generated by UniDriveDreamer.
Extensive experimental results confirm that UniDriveDreamer not only surpasses previous state-of-the-art methods in synthesis quality but also significantly enhances downstream perception task performance, demonstrating tangible improvements in mAP and NDS metrics for 3D object detection.
Considerations and Future Implications
The success of UniDriveDreamer opens opportunities for developing more data-efficient simulation environments that support multimodal sensor integration. The model's architecture suggests potential advancements in real-time systems capable of leveraging multimodal inputs for autonomous driving. Further exploration might involve extending this approach to additional sensor modalities or refining latent anchoring techniques for broader application coverage. Moreover, there is room to investigate the scalability of UniDriveDreamer to different driving contexts and environments.
Conclusion
UniDriveDreamer represents a significant step forward in the integration of multimodal data synthesis for autonomous driving. By addressing the challenges associated with cross-modal generation and distribution alignment, the framework sets a new benchmark in the quality and efficacy of synthesized driving data. As autonomous systems continue to evolve, methods like UniDriveDreamer will be instrumental in driving innovation and enhancing perceptual capabilities.