- The paper introduces a GPU-native framework that renders 3D Gaussian Splatting in browsers via wait-free hierarchical sorting and opacity-culling.
- It employs innovative techniques such as dynamic AABB culling and spherical harmonic evaluation to optimize rendering throughput on diverse hardware.
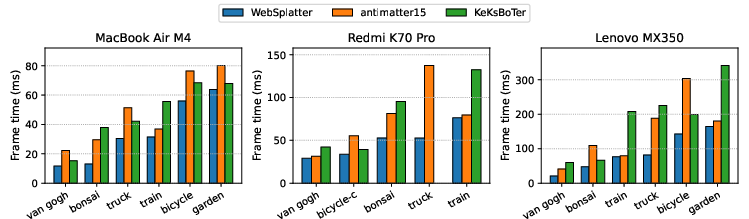
- Evaluations show up to 4.5× speedups and lower memory footprint, demonstrating robust performance across desktop, laptop, and mobile devices.
Introduction
WebSplatter presents a WebGPU-native framework for high-performance, cross-device rendering of 3D Gaussian Splatting (3DGS) scenes within web browsers. The system fundamentally rethinks 3DGS pipeline design for the web context, targeting hardware heterogeneity, GPU-access limitations (especially the absence of global atomics and cross-workgroup synchronization guarantees in WebGPU), and the distinct computational workloads of neural radiance field rendering. By combining a wait-free hierarchical radix sort for in-GPU depth sorting and opacity-driven geometry culling, WebSplatter achieves deterministic and robust rendering. Evaluation demonstrates superior throughput, memory efficiency, and platform stability relative to leading open-source baselines across desktop, laptop, and mobile hardware.
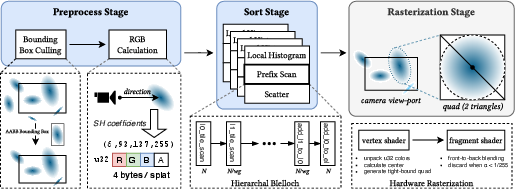
Figure 1: System overview of WebSplatter, highlighting its hybrid pipeline comprising compute-driven pre-processing, a novel wait-free radix sort, and hardware-accelerated rendering.
Technical Contributions
WebSplatter delivers several primary advances for web-based neural rendering:
- Vendor-Neutral Wait-Free Sorting: The system circumvents the lack of reliable cross-workgroup synchronization in WebGPU by adopting a wait-free, hierarchical Blelloch scan-based radix sort for depth ordering of Gaussians. This approach precludes deadlocks and busy-waiting, ensuring that the sort remains performant and deterministic across disparate devices, in contrast to conventional spin-wait-based solutions that fail on platforms enforcing unpredictable workgroup scheduling.
- Opacity-Aware Geometry Culling and Dynamic Sizing: WebSplatter introduces early-stage AABB culling and dynamic, opacity-based bounding quad sizing. Gaussians with contributions falling below a quantization threshold are eliminated early, and projected screen-space extents are tightly bounded according to opacity, minimizing rasterizer overdraw and fragment processing.
- Fully GPU-Resident Pipeline: All major pipeline stages, including 3D-to-2D projection, Spherical Harmonic evaluation, sorting, and rendering, are offloaded to the GPU using compute and render passes, eliminating costly CPU-GPU roundtrips, enabling real-time performance for million-splat scenes within browser environments.
Pipeline Architecture
The pipeline consists of three orchestrated GPU-centric stages:
- Pre-processing: Each Gaussian's 3D state is projected/covarianced to screen space, where out-of-view or negligible-contribution primitives are culled. Spherical Harmonics are directly evaluated per-splat for view direction-dependent radiance, with appearance attributes aggressively packed for bandwidth reduction.
- Sorting: A four-pass, 8-bit radix sort orders surviving Gaussians by camera depth using a fully wait-free, hierarchical Blelloch scan. The decomposition into intra/inter-workgroup phases (with only local barriers) and the absence of polling address non-uniform GPU scheduler behavior in WebGPU, providing robust scaling regardless of hardware.
- Rasterization: The sorted set is rendered via instanced quads, their screen-space extent parameterized by opacity. Alpha blending, achieved by stable back-to-front ordering, closely matches the visual result of the reference CUDA 3DGS implementation. The design leverages the raster pipeline’s interpolators to reconstruct local elliptical coordinates efficiently per fragment.
WebSplatter is exhaustively evaluated on a spectrum of devices (desktop dGPUs, integrated laptop GPUs, multiple mobile SoCs) and mainstream browsers (Chrome, Safari, Firefox with WebGPU). Benchmarks use established large-scale 3DGS scenes containing up to 6 million splats. Multiple device- and scene-complexity-dependent platform bottlenecks are analyzed.
Key results:
Visual fidelity is preserved: comparison with the reference CUDA renderer confirms negligible perceptual deviation.


Figure 3: Side-by-side garden scene renderings: left is native CUDA output, right is WebSplatter output in Chrome. Visual correctness is maintained despite aggressive pipeline and memory optimizations.
Ablation and Scalability
Disabling dynamic quad sizing increases render time by up to 19%, and eliminating the AABB culling pass leads to non-trivial regression in pre-processing, confirming the importance of tightly-bounded rasterization for efficient pipeline throughput. The sorting scheme alone yields over 24× speedup over JavaScript- or WASM-based CPU sorting on desktop, and up to 31× on M1 platforms relative to spin-wait GPU baselines.
Practical and Theoretical Implications
WebSplatter establishes that advanced differentiable rendering paradigms such as 3D Gaussian Splatting can be deployed in a browser in real-time with native-like quality and scalability. Its architectural innovations in wait-free GPU data processing could inform future WebGPU compute libraries, where lack of explicit cross-workgroup synchronization is a fundamental challenge. The genericity of the parallel scan/sort infrastructure built in WGSL, leveraging only device-agnostic primitives, is broadly applicable to large-scale neural graphics and in-browser ML inference.
The practical impact is immediate: browser-based, device-agnostic, photorealistic generative 3D content can be democratized, removing the dependency on native installations or platform-specific compilation. This is directly relevant for zero-install XR, creative/educational tooling, and streaming applications. The approach can further be adopted for low-latency, in-browser large model inference for real-time 3D generation, e.g., in DreamGaussian-derived pipelines.
Future Directions
Potential paths include:
- Generalizing device-agnostic, wait-free primitives for broader classes of high-throughput GPU compute in WebGPU,
- Integrating on-the-fly 3DGS learning/inference with just-in-time code generation (see related efforts such as NNJit [jia2024nnjit]),
- Exploring more aggressive memory compression and out-of-core streaming for scenes exceeding client VRAM,
- Interfacing with procedural content generation and view-consistent scene editing directly within browser sandboxes.
Conclusion
WebSplatter demonstrates that with careful redesign, WebGPU’s compute and render capabilities can deliver deterministic, high-throughput Gaussian Splatting in the browser, addressing fundamental web graphics limitations. The wait-free sort and opacity-driven culling strategies are directly responsible for achieving stable, scalable, and memory-efficient rendering where preceding approaches fail. WebSplatter sets a precedent for efficient, device-agnostic neural rendering pipelines on the open web and provides a blueprint for robust deployment of future GPU-accelerated AI and neural graphics algorithms in browser environments.