- The paper presents the ProAct-75 benchmark with over 91,000 annotated action steps and explicit task graphs for proactive robotic intervention.
- It introduces ProAct-Helper, a multimodal LLM-based agent that integrates hierarchical perception with entropy-guided, graph-constrained planning.
- Empirical results demonstrate improved task and step F1 scores, increased parallel action execution, and enhanced human-robot collaboration.
Structure-Aware Proactive Response: The ProAct-75 Benchmark and Framework
Introduction: Rethinking Proactive Agency in Embodied AI
The paper "ProAct: A Benchmark and Multimodal Framework for Structure-Aware Proactive Response" (2602.03430) establishes a comprehensive operational and evaluation paradigm for proactive agents, pushing beyond passive instruction execution towards agents capable of autonomous, structure-aware, parallel task execution in real-world collaborative scenarios. The authors identify limitations in current vision-language and embodied benchmarks—most notably, the absence of explicit task dependency graphs—which hinders systematic study and progress on proactive, interventionist robotic systems. They present two main contributions: ProAct-75, a hierarchical, graph-annotated dataset covering a wide spectrum of real-world tasks, and ProAct-Helper, a multimodal LLM-based agent designed for hierarchical perception and graph-constrained, entropy-driven action planning.
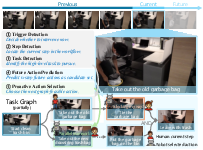
Figure 1: ProAct-75 supports perception and evaluation of multiple threads in five visually grounded proactive tasks, enabling comparative study of traditional and structure-aware response policies.
ProAct-75: Dataset Construction and Hierarchical Annotation
ProAct-75 aggregates 5,383 exocentric and egocentric videos compiled from public datasets (Ego-Exo4D, COIN, UCF-Crime) and additional self-collected data, spanning 75 distinct tasks and comprising over 91,000 time-aligned, step-level action annotations. Each task is equipped with an explicit task graph in the form of a DAG, encoding both AND/OR dependencies and parallel thread possibilities, facilitating the study of both sequential and concurrent action strategies.
The annotation process ensures task/step/hierarchy uniformity and resolves the inherent temporal, granularity, and vocabulary mismatches between heterogeneous data sources. Human-rated context cues, detailed trigger-event intervals, and rigorous QC procedures establish a high-fidelity testbed for multilevel agent evaluation in assistance, maintenance, and safety monitoring settings.
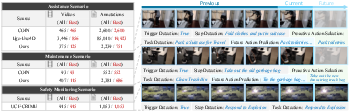
Figure 2: ProAct-75 captures varied application realities, visualizing hierarchical annotations over past, current, and anticipated observations for assistance, maintenance, and safety monitoring scenarios.
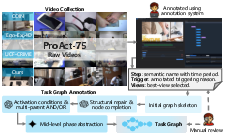
Figure 3: The annotation pipeline standardizes semantic granularity and maintains view and temporal consistency across sources, with every task coupled to an explicit task graph.
At the core of ProAct-75's approach is the formalization of human activities as task graphs. Each task graph is a DAG combining executable atomic steps and non-executable hierarchical nodes, decorated with AND/OR semantics to regulate execution feasibility and model procedural concurrency. Robot actions must satisfy these constraints at all decision points, ensuring that selected interventions do not violate causal order or interfere with ongoing human subworkflows.
The agent's proactive response interface consists of hierarchical predictions at every frame: (1) whether to trigger an intervention, (2) which task is active, (3) the current human-executed step, (4) anticipated future steps, and (5) the next feasible robot action within the legal set defined by the task graph.
The ProAct-Helper Framework: Hierarchical Perception and Entropy-Guided Planning
ProAct-Helper is a reference multimodal agent combining perception and planning under structural constraints. Its perception stack is based on a fine-tuned MLLM backbone (Qwen2.5-VL), augmented by a Hierarchical Binding Module (HBM) that enforces cross-level semantic consistency between trigger, task, and step latent spaces using contrastive binding losses. This mitigates long-tail class imbalance and improves rare-class prediction, yielding robust hierarchical state estimation.

Figure 4: ProAct-Helper fuses vision and prompt-driven guidance for hierarchical perception, with structured consistency objectives and entropy-driven DAG-constrained action selection.
The planning module explicitly leverages the task graph. At each decision, it computes the set of legal next steps, partitions them by thread alignment (via reachability analysis), and selects the action that minimizes the robot-human thread mixing entropy. This biases the robot towards parallel, low-interference interventions while respecting graph-imposed causality.
Empirical Results: State Recognition, Efficient Parallelization, and Ablations
Across all major state-perception tasks (trigger, task, and step detection; future prediction), ProAct-Helper surpasses both closed-source (Gemini-2.5-Pro, GPT-4o) and open-source MLLM baselines. Notably, ProAct-Helper (7B backbone) achieves a 17.09% higher task F1 and an 11.72% higher step F1 than Gemini-2.5-Pro. The introduction of HBM delivers an additional 2.71% macro-F1 on tasks and 1.63% on steps by promoting robust long-tail recognition.
Crucially, in the online one-step decision setting and full trajectory simulation, ProAct-Helper yields an absolute gain of 15.58% in parallel action execution (PA), and saves 0.25 more collaborative steps on average compared to baselines. This demonstrates both higher utility and a strong preference for safe, non-interfering parallelism—a desired property for practical assistive robotics.

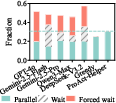
Figure 5: Hallucination and procedural validity errors remain minimal for ProAct-Helper, especially in low-level state detection tasks.

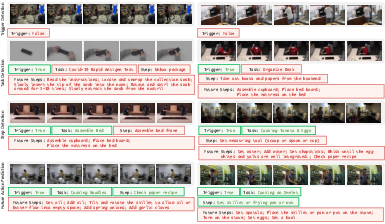
Figure 6: Representative success cases highlight robust trigger gating, task/step inference, and structurally coherent future-step prediction.
Failure Analysis and Generalization
The primary residual failure modes are future action hallucination (unconstrained or incomplete step sequences) and occasional misalignment under severe visual ambiguity or out-of-distribution views. The latter is mitigated, but not eliminated, by HBM and the explicit task-graph interface.
Evaluation on secondary views and less favorable perspectives demonstrates that the framework maintains significantly better performance than prior datasets' annotation-based models, both in head and tail categories. Planning inference latency remains tractable (sub-second per decision) even with the most capable backbones—a requirement for real-time embodied deployment.
Practical and Theoretical Implications
Practically, the introduction of a large, hierarchical benchmark with explicit task graphs establishes a rigorous environment for developing truly proactive, collaborative embodied agents. The explicit graph provides not only strong supervision for training, but also an actionable interface for real-time online planning, ensuring feasibility and maximizing collaborative parallelism.
Theoretically, the results expose major limitations of current vision-LLMs when applied naïvely: even with access to DAGs, closed-source LLMs consistently underutilize parallelism, prefer waiting, and are less effective at deploying interventions that maximize cross-agent temporal efficiency. Graph-constrained action selection with entropy minimization shows measurable improvements in collaboration metrics, suggesting that hybrid neuro-symbolic architectures—where LLM-driven perception is grounded in explicit structural planning—hold substantial promise.
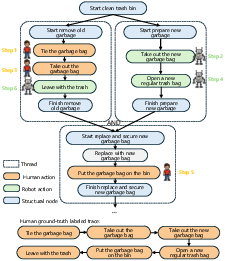
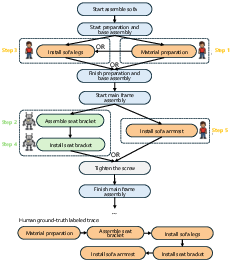
Figure 7: Proactive action selection for real-world maintenance tasks, such as trash-bin replacement, highlights effective planning for concurrent human-robot task decomposition.

Figure 8: Multi-view collection enables robust evaluation of viewpoint transfer and scene complexity.
Conclusion
This work provides a foundation for principled study and development of truly proactive, structure-aware embodied agents. By releasing ProAct-75 and the ProAct-Helper baseline, the paper demonstrates that scaling perception and planning frameworks to integrate explicit task structure enables substantial gains in collaborative efficiency, state recognition, and action feasibility. The findings motivate future research in scalable graph-constrained hybrid agents, improved long-tail state recognition, and automated generation of valid, low-interference plans for open-world deployment.
The explicit provision of high-quality multi-source videos, consistent hierarchical annotation, and executable task graphs in ProAct-75 will drive the development of agents that not only mirror human intent, but reliably anticipate, adapt, and enhance human-robot interaction in practical deployments.