- The paper introduces a generative formulation for visually-guided acoustic highlighting using conditional flow matching with a rollout loss to reduce error accumulation.
- The method leverages neural ODEs and multimodal cross-attention to fuse CLIP and CLAP embeddings for improved audio-visual alignment.
- Empirical results on the Muddy Mix dataset show enhanced source selection and robust audio improvements over prior approaches.
Conditional Flow Matching for Visually-Guided Acoustic Highlighting: Technical Analysis
The task of visually-guided acoustic highlighting (VisAH) concerns automatic audio rebalancing in multimedia, specifically aligning acoustic saliency with visual context for enhanced perception. While visual saliency manipulation has seen broad advances, audio curation remains comparatively underdeveloped, yielding systematic perceptual misalignment in consumer video (e.g., speech occluded by background elements). Previous approaches cast VisAH as a discriminative regression problem, typically employing sound separation networks for source enhancement based on visual cues. However, such framing is ill-suited to the inherent ambiguities of audio mixing: diverse poorly-mixed variants can correspond to multiple plausible well-mixed rebalancing outputs under the same visual context, i.e., the relationship is many-to-many, not one-to-one.
The paper reframes visually-guided acoustic highlighting as a generative mapping between two distributions—ill- and well-balanced audio—conditioned on visual input. This naturally motivates use of continuous flow-based generative modeling, which learns a vector field translating the input distribution to the target, as depicted in the iterative highlighting process.
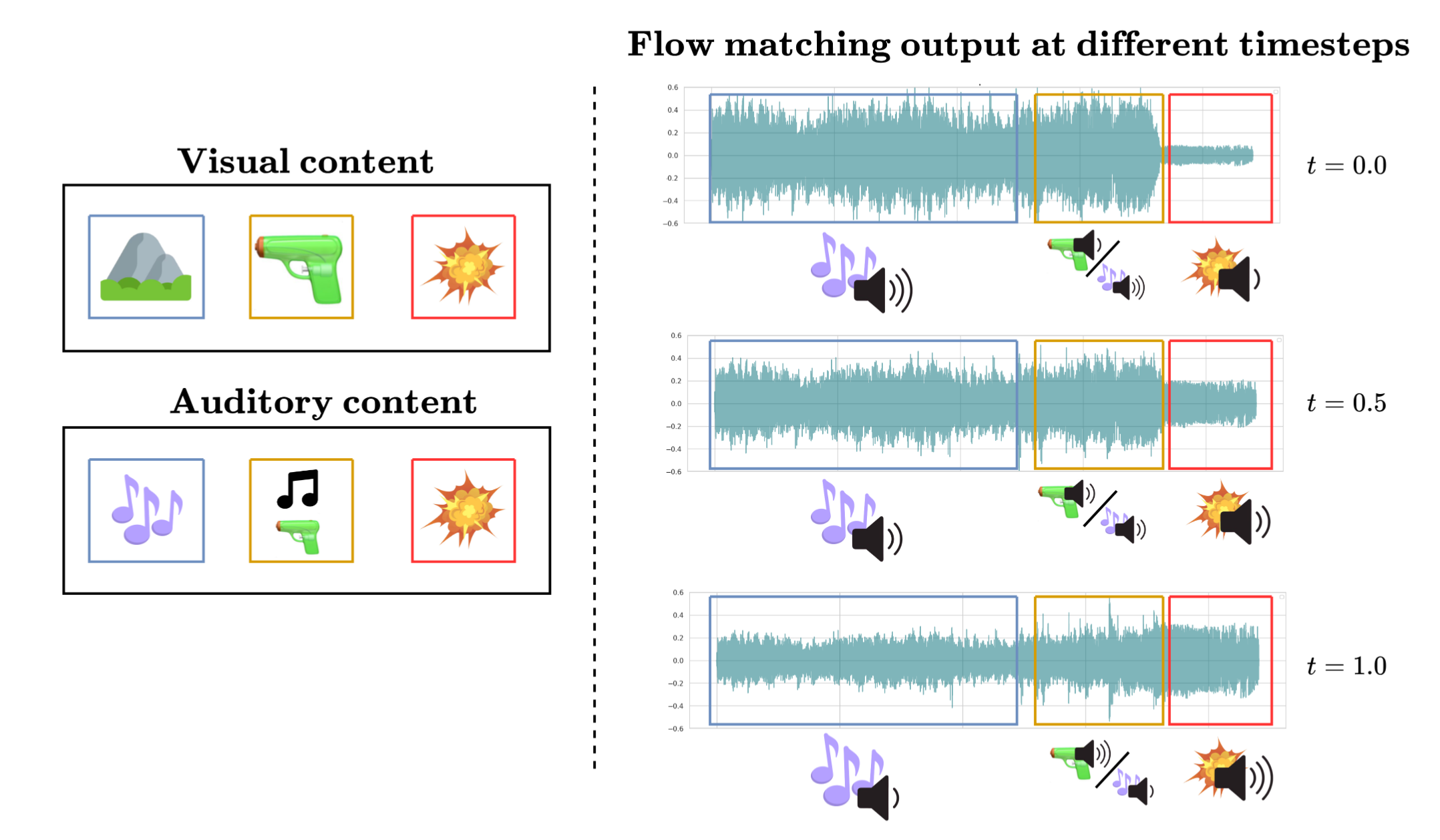
Figure 1: Acoustic sources are iteratively enhanced or suppressed according to their alignment with the visual context, forming the basis for conditional flow matching modeling.
Conditional Flow Matching Framework
The approach formalizes the generative process using conditional flow matching (CFM), leveraging a neural ODE parameterization to transform noisy or unbalanced audio (x0) towards the desired target (x1) via learned velocity fields. Visual context c guides the transformation, with CFM loss driving the alignment. Training requires sampling pairs (x0,x1) conditioned on shared visual context, reflecting real ambiguities in audio–visual correspondence.
Importantly, error propagation emerges as a significant failure mode in iterative flow integration: early decisions (e.g., which sound source to enhance) compound in later steps, resulting in off-manifold predictions. Standard CFM, which backpropagates loss locally, struggles to impose trajectory coherence over multiple steps.
To address this, the paper introduces a rollout loss—a global, trajectory-level penalty evaluating the terminal prediction after the entire flow, conditioned on self-generated (rolled-out) states rather than ground truth at each step.
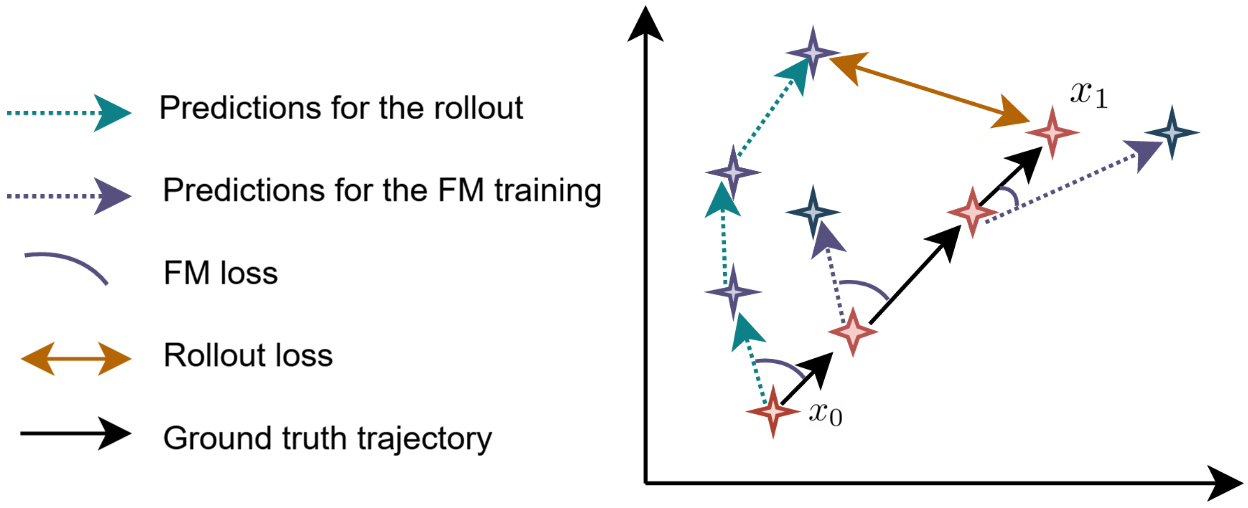
Figure 2: The rollout loss supervises the final trajectory output, directly penalizing accumulated drift caused by early prediction errors.
Model Architecture: VisAH-FM
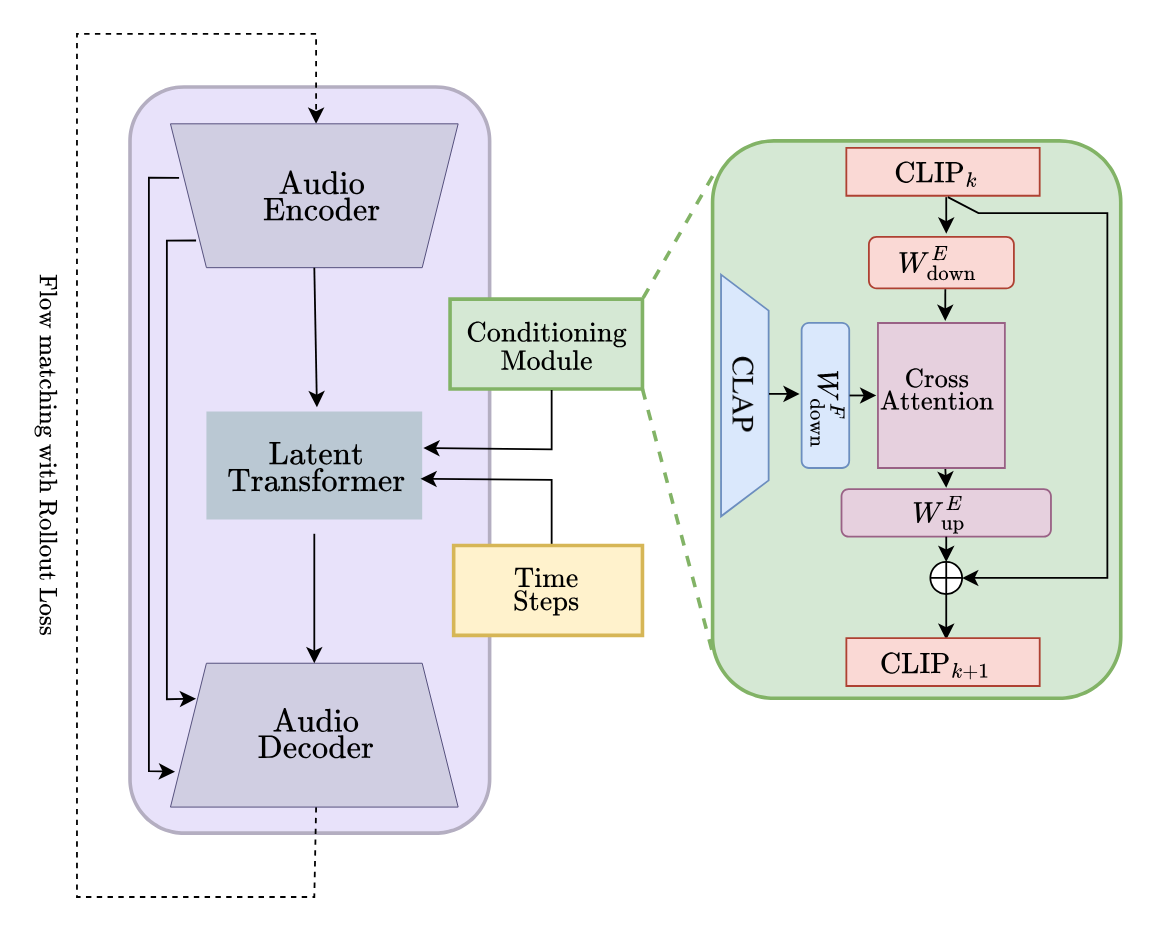
The architecture, VisAH-FM, extends the VisAH U-Net backbone with CFM and incorporates several novel design components:
The multimodal conditioning module uses an adapter layer to integrate audio-visual context inside visual features preceding vector field regression.
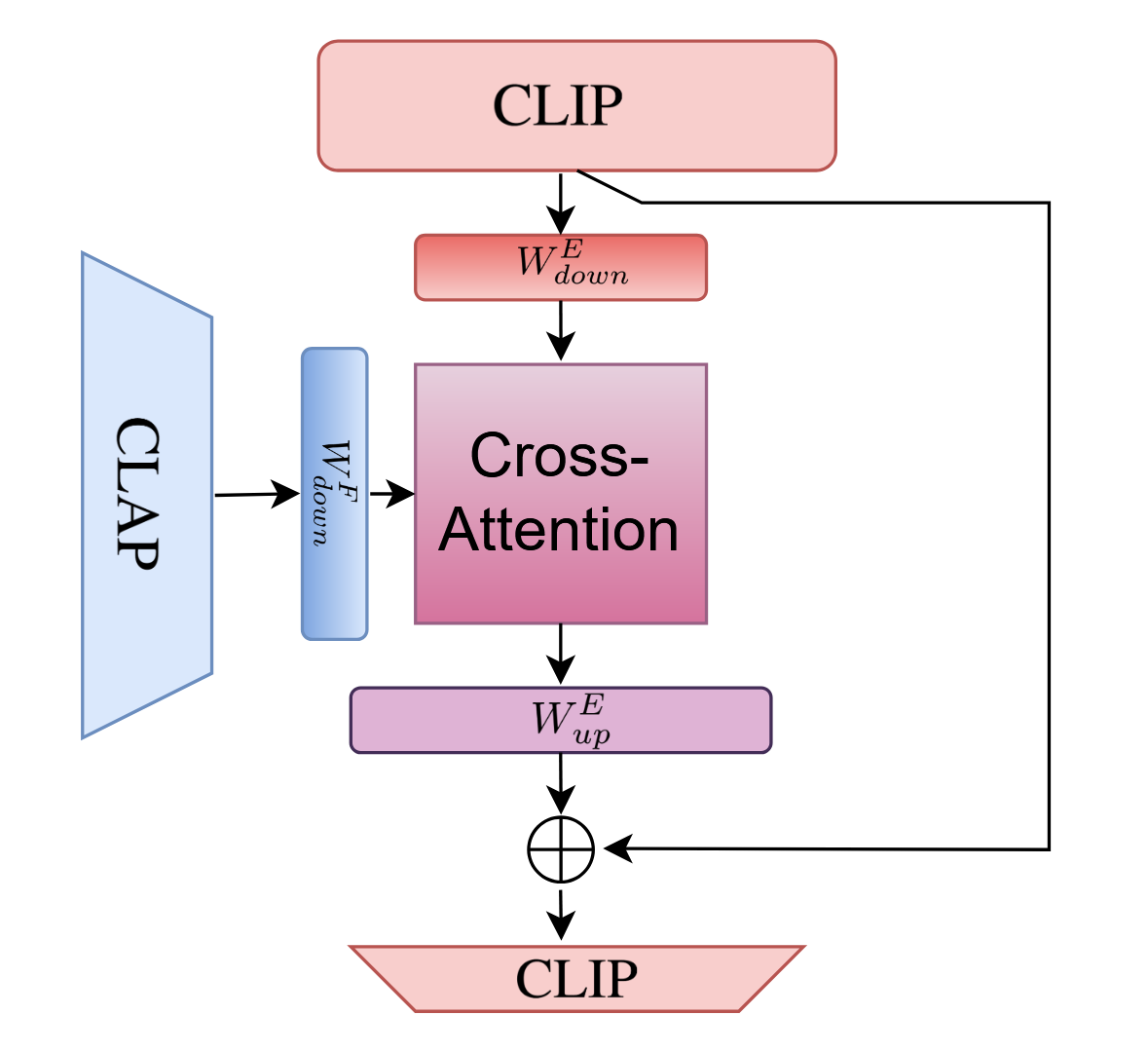
Figure 4: The conditioning module fuses frame-wise CLIP and additional modality (e.g., CLAP) features through cross-attention in a reduced-dimensional space, then projects back to the CLIP space.
Empirical Results and Ablation Insights
Across several quantitative benchmarks on the Muddy Mix dataset, VisAH-FM demonstrates consistent superiority over discriminative and prior flow-matching baselines. Metrics include semantic and signal alignment, such as KL divergence of event logits, IB-Score for image-audio similarity, magnitude and envelope distances, and source-specific loudness deltas.
Key findings:
- Adding rollout loss to CFM yields a substantial reduction in error accumulation, with KLD and source loudness deltas outperforming all alternatives.
- Early fusion of audio features in the conditioning path notably improves performance over adding text features or using vision alone, supporting the claim that enriched audio-visual representations enable more effective source selection.
Analysis of model behavior shows the benefit of using rollout loss: without it, cosine similarity between predicted and ground-truth trajectories degrades rapidly with each step, while rollout regularization preserves global coherence.
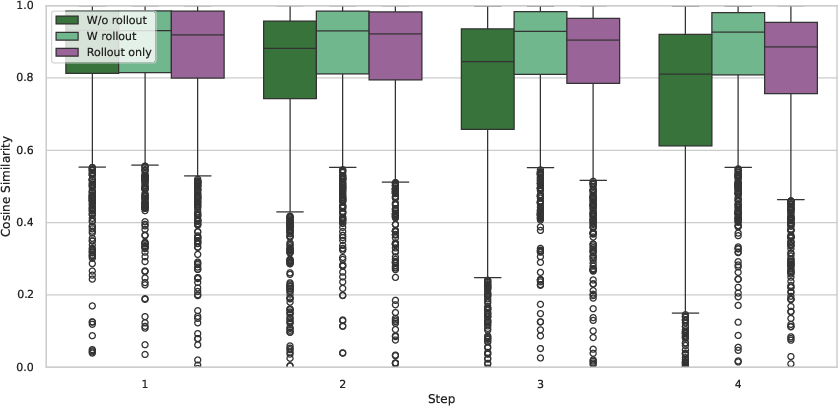
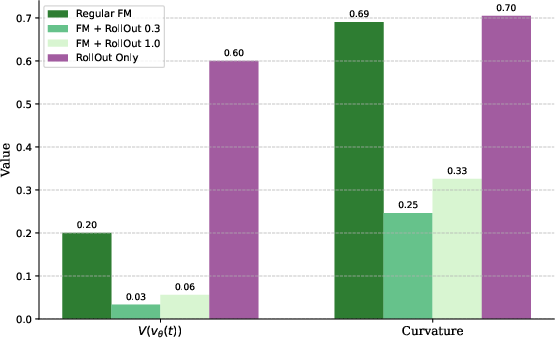
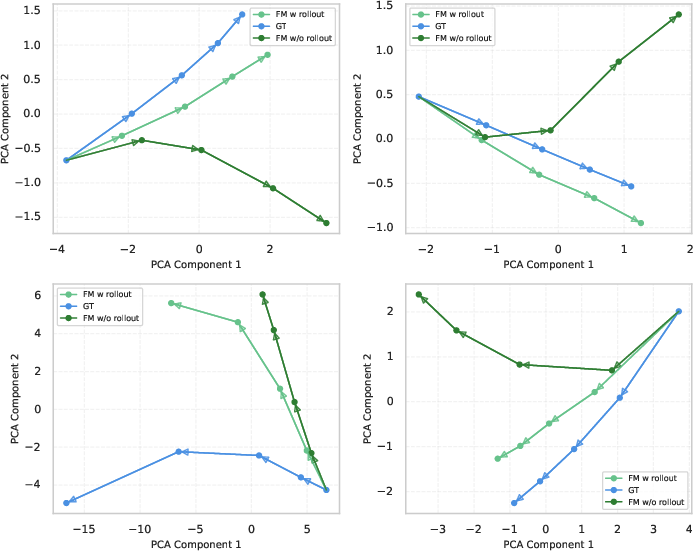
Figure 5: Cosine distance between predicted and true trajectories demonstrates error amplification without rollout loss, stabilized under rollout-conditioned training.
Qualitative waveform visualizations further corroborate that VisAH-FM’s iterative procedure incrementally enhances target sources in a manner more consistent with the visual narrative.
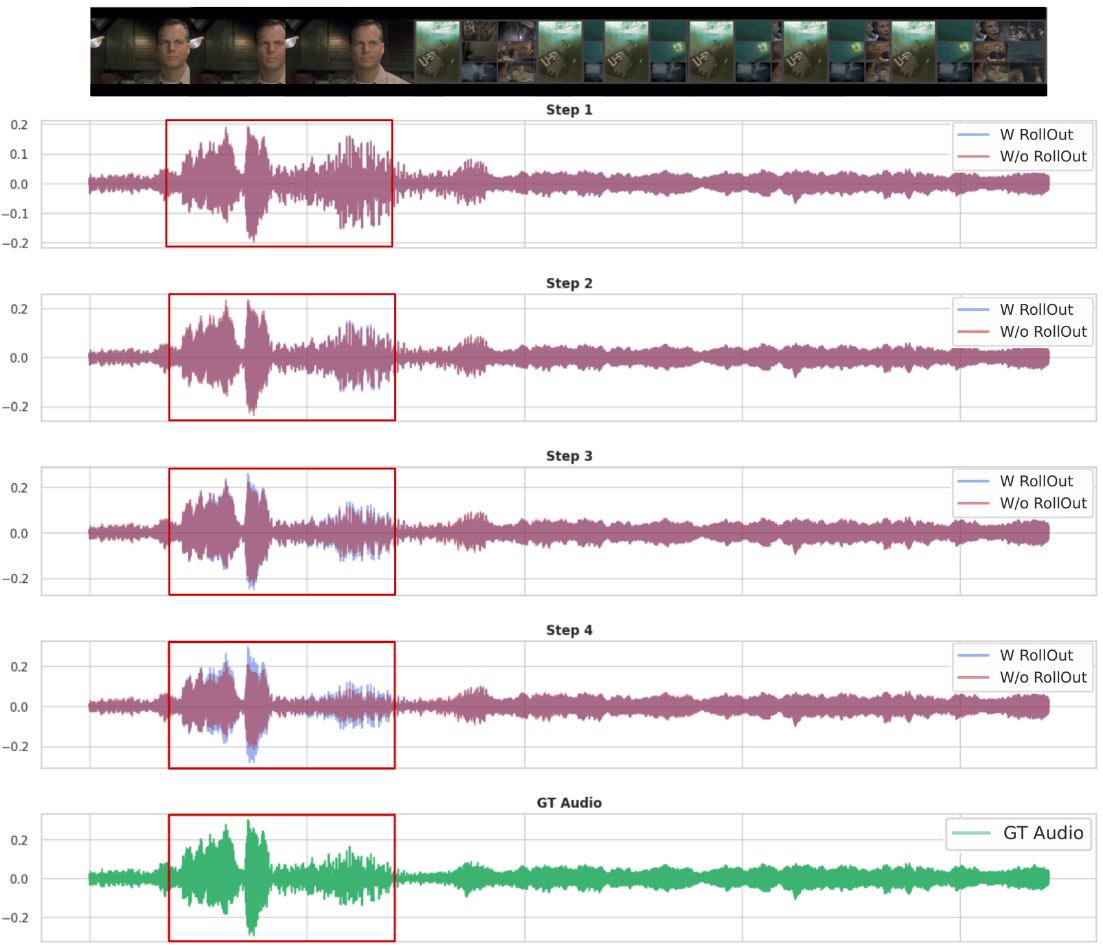
Figure 6: The rollout-trained model effectually enhances speech presence throughout the steps, in contrast to standard CFM that fails at later iterations.
Similarly, direct comparison of VisAH and VisAH-FM reconstructions reveals that the generative reformulation is systematically more precise in source highlighting and display artifact management.
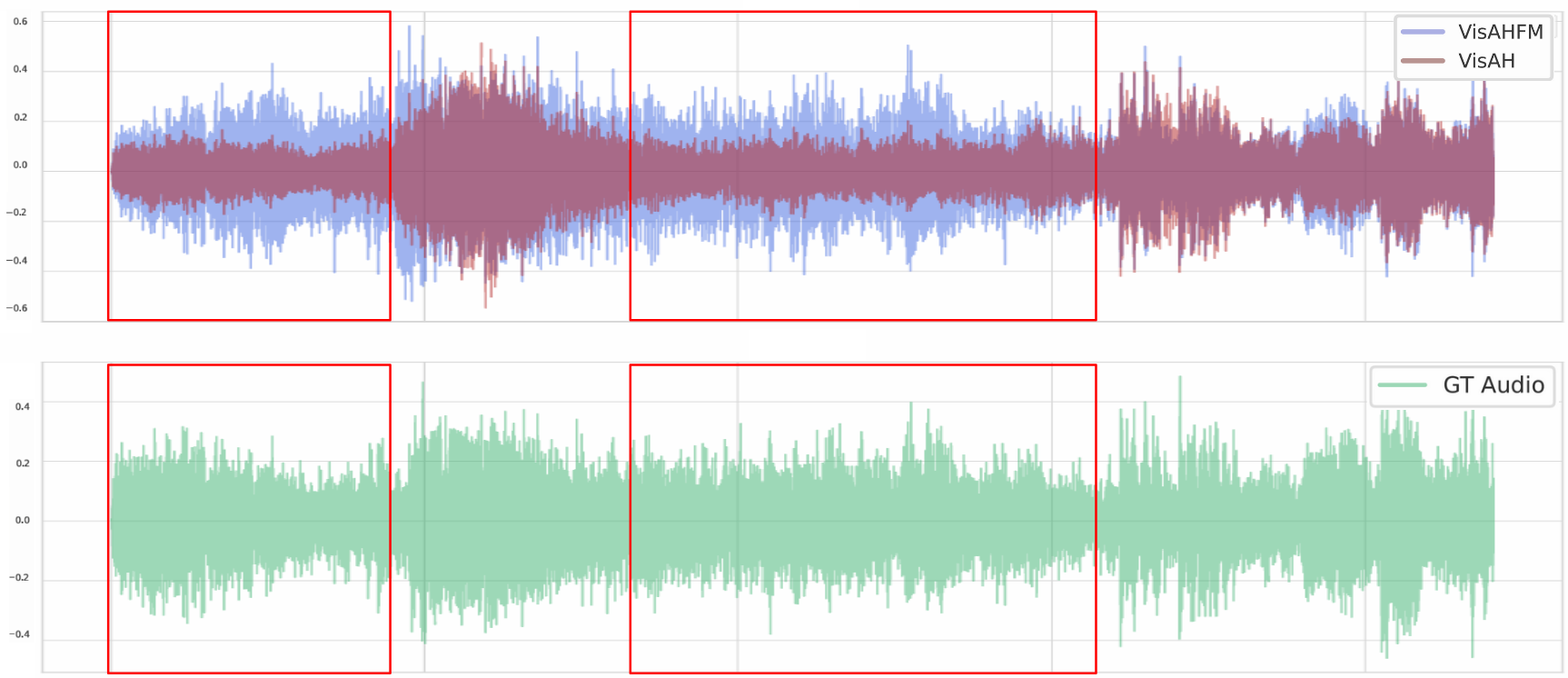
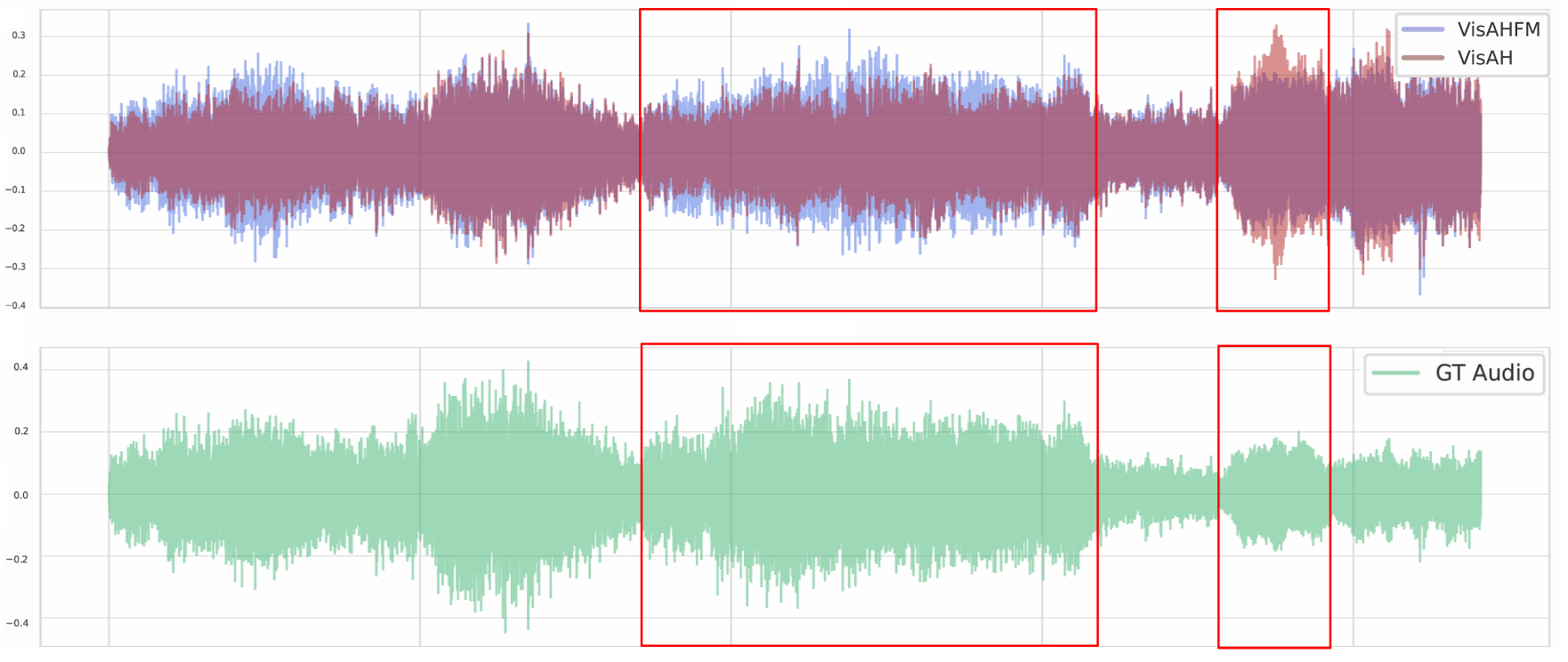
Figure 7: VisAH-FM yields more robust and focused enhancement of visually relevant sources compared with VisAH.
Theoretical and Practical Implications
This work asserts that generative, flow-based approaches are fundamentally better equipped for visually-guided acoustic highlighting due to their ability to model distributional ambiguity. The rollout loss regularizes long-range consistency, a crucial property for iterative or recurrent audio manipulation where compounding errors are otherwise inevitable. From an engineering perspective, the architectural design separates modality fusion (source selection, via conditioning) from low-level regression (audio synthesis), a paradigm likely to generalize to other cross-modal translation tasks.
The approach is computationally more demanding, due to increased reliance on large pretrained encoders (CLIP/CLAP) and iterative inference, but the observed improvements in alignment and subjective quality (60% preferred on Muddy-Mix, 70% on MovieGen) indicate significant gains in output fidelity and interpretability.
Future Directions
Potential future research includes direct extension of VisAH-FM to unpaired real-world data, relaxing current simulation requirements, as well as adaptation of the rollout-conditioned CFM paradigm to other ambiguous translation tasks in multi-modal generation and controlled editing. There is additional space for advancing the efficiency of conditional architectures and for understanding the dynamics of error correction under various forms of long-range trajectory supervision.
Conclusion
This paper provides strong evidence that visually-guided acoustic highlighting is better addressed with generative modeling and distribution-matching techniques. By combining conditional flow matching with a global rollout loss and early multimodal feature fusion, VisAH-FM establishes a new state-of-the-art on this task, exhibiting both superior quantitative metrics and consistent qualitative improvements over previous discriminative and flow-matching baselines (2602.03762).