- The paper introduces a novel algorithm, Reasoning Cache, that alternates between generating detailed reasoning traces and summarizing them to maintain performance over extended lengths.
- The method decouples reasoning from summarization using short-horizon RL, achieving a 17% accuracy boost on benchmarks by mitigating distribution shift during test-time extrapolation.
- Empirical results show RC-trained models outperform baselines in mathematical and scientific tasks, reaching up to 70% accuracy with increased test-time compute.
Reasoning Cache: Continual Improvement Over Long Horizons via Short-Horizon RL
Introduction and Motivation
The work presented in "Reasoning Cache: Continual Improvement Over Long Horizons via Short-Horizon RL" (2602.03773) addresses a critical limitation in current LLM training regimes: the lack of effective extrapolation to significantly longer reasoning horizons than models are exposed to during training. Standard RL approaches for LLMs operate over fixed input distributions and bounded rollout lengths, which inhibits continual improvement at test time when presented with more complex tasks or larger compute budgets. This study introduces Reasoning Cache (RC), a multi-turn decoding and training algorithm designed to both decouple and extend the reasoning horizon, enhancing continual, in-context learning and robustness to distributional shift at deployment time.
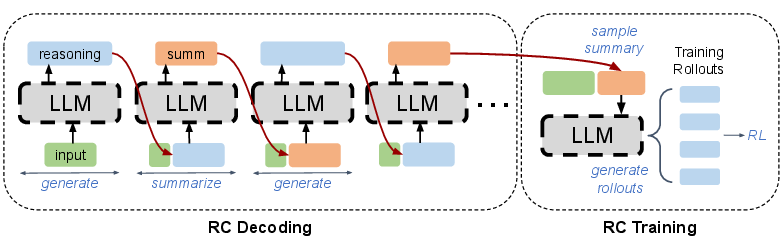
Figure 1: Schematic of RC decoding (left); empirical performance scaling with test-time budget (right) showing RCT-4B's superior extrapolative gains.
Methodology: The Reasoning Cache Decoding and Training Paradigm
RC replaces conventional autoregressive decoding with an explicit iterative routine alternating between reasoning trace generation and summarization. At each step, the model generates a reasoning trace for a fixed token budget, summarizes this trace into a compressed context (the "cache"), and then discards the trace, conditioning subsequent turns' reasoning solely on this summary. This procedure enables fine-grained, monotonic scaling of test-time compute while avoiding distribution shift, because each generated context remains within the typical training distribution—no matter the total extrapolated length.
The RC algorithm draws on two LLM characteristics: the redundancy of long reasoning traces, and a summarization-generation asymmetry, whereby conditioning on a concise summary of prior reasoning improves the quality of subsequent generations more than extending the trace autoregressively. Notably, summary conditioning also eliminates distractions due to verbose tokens and context overflow, enforcing a more stable self-improvement loop.
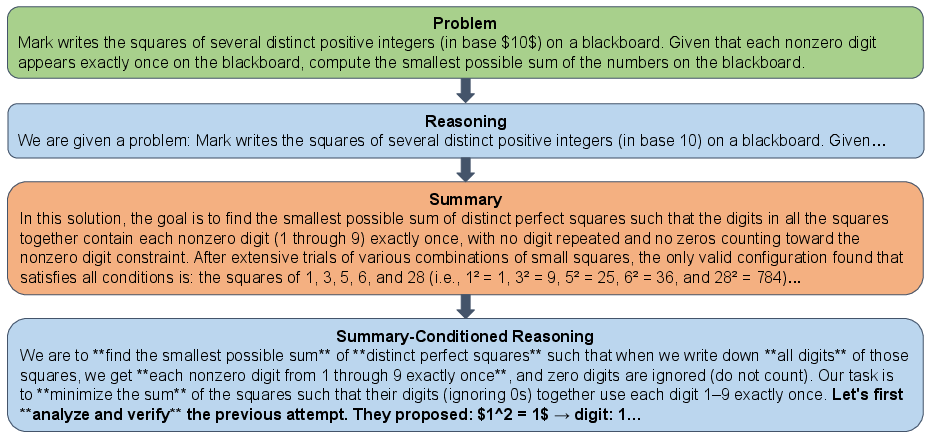
Figure 2: RC output example — summary-driven iterative refinement progressively yields more accurate solutions.
Empirical Results: Extrapolation, Scaling, and Transfer
Applying RC decoding with instruction-following LLM backbones, the authors observe strong extrapolation characteristics. For Qwen3-4B-Instruct-2507, accuracy on Held-out Mathematical Modeling Test (HMMT) 2025 increases by 17% when the available test token budget is increased from 16k to 192k, well beyond the training length regime. The gains are especially pronounced when using a model trained specifically with the RC objective.

Figure 3: Accuracy improvements scale with test-time budget under RC decoding.
Importance of Summarization and Model Properties
RC is compared against other iterative methods (e.g., self-refinement, self-verification) that lack explicit summarization. RC decisively outperforms these, highlighting that iterative generation alone is inadequate and that summary abstraction is critical for stable long-horizon improvement. Additional ablations reveal that adequate summary detail is essential; neither too terse nor overly verbose summaries suffice, and effectiveness peaks with multi-paragraph abstractions (Figure 4). Furthermore, the effectiveness of RC is substantially higher in strong instruction-following models versus pure reasoning specialists, underscoring the centrality of summarization-generation asymmetry for efficient extrapolative learning.

Figure 4: Accuracy as a function of summary detail level; optimality is achieved by balancing conciseness and informativeness.
RC Training: RL over Summary-Conditioned Trajectories
Two-Stage Curriculum and Replay Buffer
RC training employs a policy-gradient RL objective applied to summary-conditioned generations at each turn. The training protocol includes two stages: the first focusing on initial turns (fresh or minimal summary context), and a second leveraging a replay buffer to introduce off-policy coverage of later-turn summaries. This buffer provides broad state coverage and enhances training stability and sample efficiency.
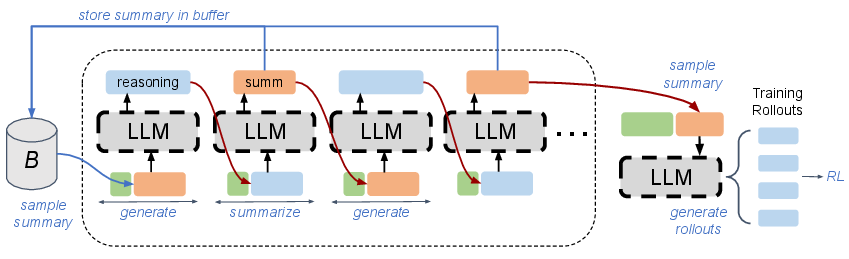
Figure 5: Illustration of RC training rollouts using a summary replay buffer for broader summary distribution coverage.
Quantitative Gains Across Benchmarks
RCT-4B (the RC-trained 4B model) yields strong, scalable performance across diverse mathematical and scientific benchmarks—outperforming both size-matched and much larger models not trained with RC. For instance, on HMMT 2025, RCT-4B achieves 70% accuracy (up from 40% for the untrained base model) when extrapolated from a 16k training to a 0.5M test token budget. Notably, despite exclusively mathematical training data, RCT-4B also generalizes to scientific reasoning in the FrontierScience benchmark.
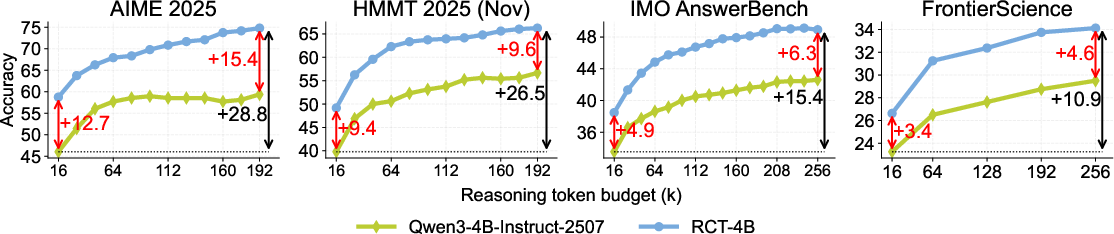
Figure 6: RCT-4B consistently surpasses the base model on multiple benchmarks as test-time compute increases.
Difficult Problems and Depth-vs-Breadth
On adversarial problem sets (Omni-MATH), RCT-4B achieves a 15% higher pass@16 than the base model at 256k tokens, with the gap widening as compute increases. RC's depth-oriented improvement is found to yield greater accuracy than parallelizing for breadth (majority-vote), emphasizing that iterative abstraction and refinement are preferable to naive sampling at scale.
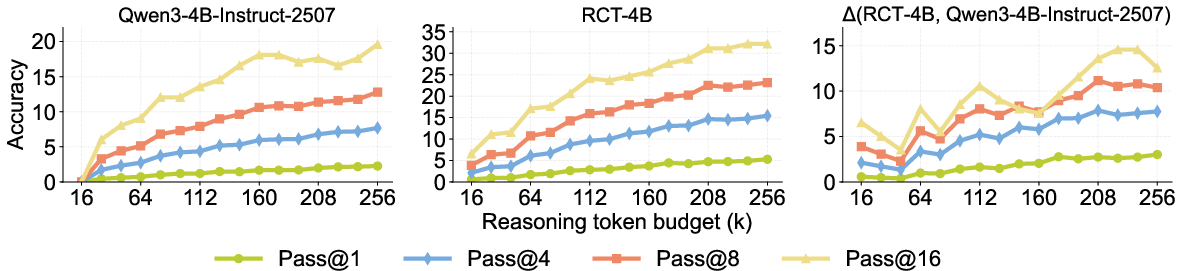
Figure 7: Superior pass@k scaling for RC-trained models on intrinsically hard benchmarks.
Model and Training Ablations
Ablation studies demonstrate that the inclusion of a summary replay buffer during training and the choice of the number of training iterations critically control extrapolative scaling and performance. Training with RC is shown to offer more substantial gains than increasing single-turn RL budgets or simply improving general reasoning proficiency.
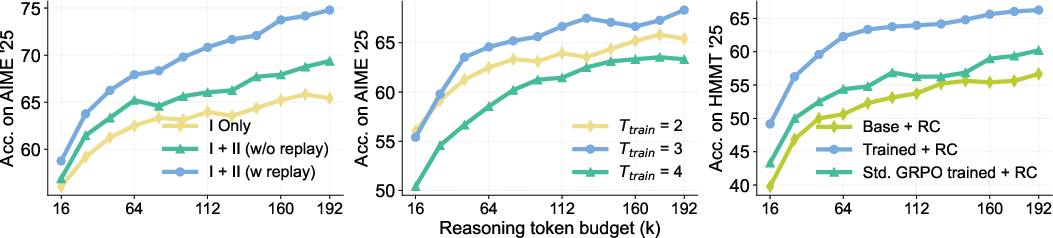
Figure 8: Enhanced extrapolation and overall accuracy through multi-stage RC training and replay.
Integration with Test-Time Scaffolds and Broad Implications
RC-trained models further excel when incorporated into advanced test-time scaffolds (e.g., recursive aggregation, self-verification agents), leveraging improved abstraction-conditioned reasoning to realize additional gains beyond standalone inference. This suggests RC learning produces robust, transferable skills for abstraction-guided reasoning, not merely idiosyncratic gains for summary prompts.
Theoretical and Practical Implications
The RC paradigm introduces a principled mechanism for test-time compute scalability and robust long-horizon performance, offering a pathway toward LLMs capable of continual, in-context self-improvement. The explicit alternation between summarization and reasoning tightly couples the acquirement of useful abstractions to downstream utility. This approach is especially promising for domains requiring deep, exploratory reasoning without reliable reward signals for intermediate steps.
RC also opens several theoretical and practical avenues: enhancing non-myopic reward assignment, optimizing both summarizer and reasoner jointly, and developing algorithms that work for open-ended tasks without final answer supervision. Its practicality is evidenced by compute and memory efficiency, as well as domain transfer, making RC adaptable to a growing variety of reasoning-intensive applications.
Conclusion
The Reasoning Cache framework demonstrates that short-horizon RL—when combined with iterative summary abstraction and targeted training—enables LLMs to continually improve over horizons far longer than those seen during training, overcoming fundamental autoregressive and RL-based limitations. RC-trained models achieve state-of-the-art performance in both math and science reasoning under increased compute budgets and exhibit emergent generalization and transfer properties across benchmarks and scaffolds. Future work should explore non-myopic training, joint summarization-reasoning optimization, and adaptation to open-ended domains to further extend the capabilities of inference-efficient, self-improving LLMs.