ReasonCACHE: Teaching LLMs To Reason Without Weight Updates
Abstract: Can LLMs learn to reason without any weight update and only through in-context learning (ICL)? ICL is strikingly sample-efficient, often learning from only a handful of demonstrations, but complex reasoning tasks typically demand many training examples to learn from. However, naively scaling ICL by adding more demonstrations breaks down at this scale: attention costs grow quadratically, performance saturates or degrades with longer contexts, and the approach remains a shallow form of learning. Due to these limitations, practitioners predominantly rely on in-weight learning (IWL) to induce reasoning. In this work, we show that by using Prefix Tuning, LLMs can learn to reason without overloading the context window and without any weight updates. We introduce $\textbf{ReasonCACHE}$, an instantiation of this mechanism that distills demonstrations into a fixed key-value cache. Empirically, across challenging reasoning benchmarks, including GPQA-Diamond, ReasonCACHE outperforms standard ICL and matches or surpasses IWL approaches. Further, it achieves this all while being more efficient across three key axes: data, inference cost, and trainable parameters. We also theoretically prove that ReasonCACHE can be strictly more expressive than low-rank weight update since the latter ties expressivity to input rank, whereas ReasonCACHE bypasses this constraint by directly injecting key-values into the attention mechanism. Together, our findings identify ReasonCACHE as a middle path between in-context and in-weight learning, providing a scalable algorithm for learning reasoning skills beyond the context window without modifying parameters. Our project page: https://reasoncache.github.io/
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper asks a simple but big question: Can a LLM learn to reason better without changing its “brain” (its weights)? The authors propose a method called ReasonCache that teaches a model new reasoning skills by adding a tiny, learnable memory at the front of the model’s attention—without touching the model’s original weights and without stuffing the prompt with tons of examples.
What questions do the authors ask?
- Can we scale in-context learning (learning from examples in the prompt) so it actually helps with hard reasoning, without making prompts huge and slow?
- Can a model learn new reasoning skills without any weight updates?
- Can we do this more efficiently—using less data, less computation at inference, and fewer trainable parameters—than popular methods like fine-tuning or LoRA?
- Theoretically, is this method at least as powerful as low‑rank weight updates (like LoRA), or even more powerful in some cases?
How does it work? (Methods explained simply)
Imagine three ways to help a student (the model) solve problems:
- Exemplar-based in-context learning (ICL): You tape lots of worked examples into the front of their notebook before each test. This can help, but if you add too many, the student wastes time flipping pages and gets confused.
- In-weight learning (fine-tuning or LoRA): You rewrite some pages in the student’s textbook. This can work well, but it’s slow, risky (you might mess up other chapters), and you have to store and ship around those new pages.
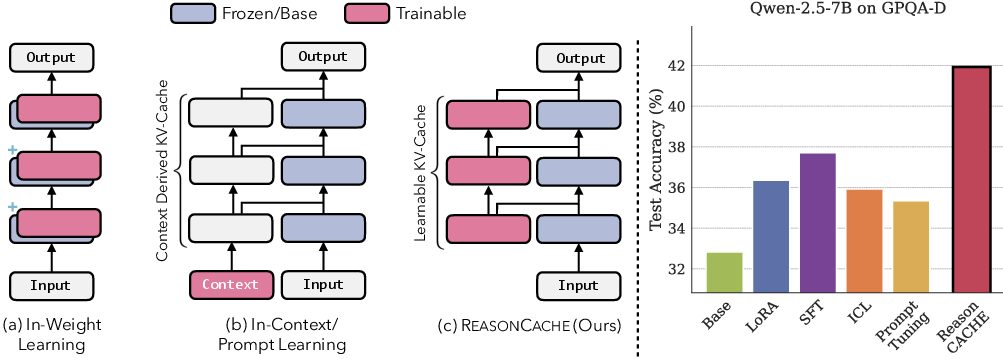
- ReasonCache (this paper): You give the student a small set of sticky-note hints they keep at the front of every chapter. These hints don’t change the textbook and don’t require you to tape in long examples. They’re short, reusable, and sit exactly where the student needs them.
Here’s the tech behind that sticky-note idea:
- Transformers use “attention” with a key–value (KV) cache, which you can picture as a small set of “hint cards” the model consults while reading and writing each token.
- Normally, those hint cards come from the actual text you feed the model (your prompt and its generated tokens). Longer prompts mean more cards, which are slow and costly to process.
- ReasonCache uses “prefix tuning” to learn a compact set of artificial key–value cards (a short prefix) for every layer of the transformer. These are not words—just learned vectors that guide attention.
- During training, the model sees many reasoning examples, and the prefix gets adjusted so the model learns how to think better. At test time, the model only needs the small prefix, not the long examples.
- This keeps the original weights frozen (safer and simpler), avoids huge prompts (faster and cheaper), and still gives the model new, useful reasoning habits.
A key idea: LoRA and other weight-update methods must push improvements through the input tokens—like trying to move lots of furniture through a narrow doorway (the “carrier bottleneck”). ReasonCache bypasses that: it places the helpful hints directly into the attention’s memory, like already having the furniture inside the room.
What did they find, and why is it important?
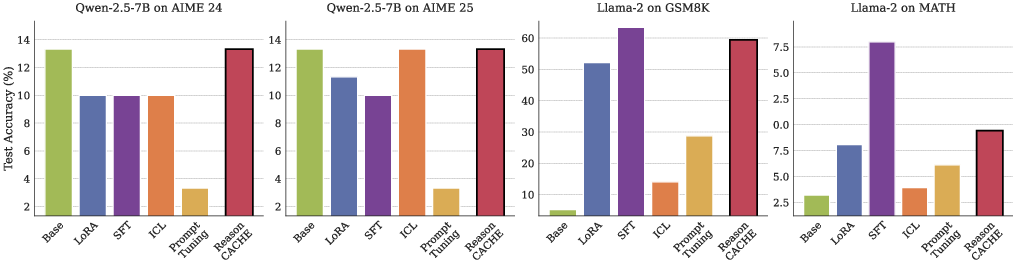
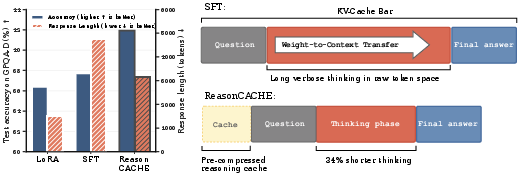
Across math and science reasoning benchmarks (like GSM8K, MATH, AIME, and the tough GPQA-Diamond set), ReasonCache consistently did better than standard in-context prompts and matched or beat in-weight methods:
- Stronger accuracy on hard reasoning:
- On GPQA-Diamond, ReasonCache beat both LoRA and even full supervised fine-tuning (SFT).
- Uses much less training data and fewer trainable parameters:
- On GSM8K, it reached the same accuracy as LoRA with 59% less data and needed 46% fewer trainable parameters.
- Faster and cheaper at inference:
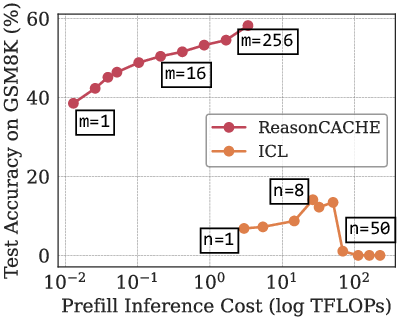
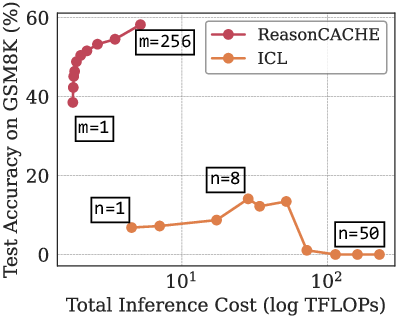
- Compared to long in-context prompts, ReasonCache achieved higher accuracy with up to 90% less inference compute (because the prefix is short and fixed).
- On GPQA-Diamond, it improved accuracy by about 11% over SFT while producing 34% shorter “thinking” chains—so the model gets to the answer more directly.
- Theory supports the performance:
- The authors prove ReasonCache can be strictly more expressive than low‑rank weight updates like LoRA. Intuition: LoRA changes weights but still depends on how much information the input tokens can carry; ReasonCache injects new “directions” directly into the attention’s value space, skipping the bottleneck.
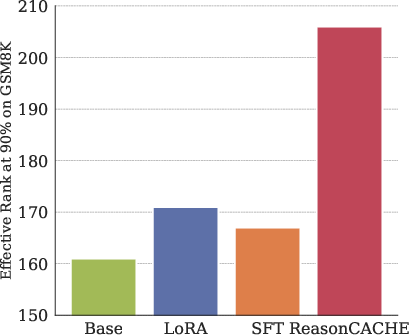
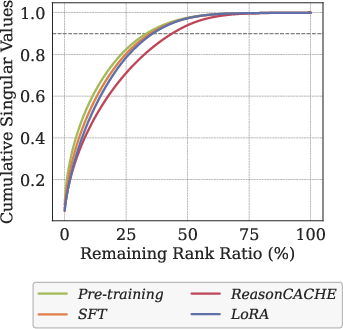
- They also show representation evidence: ReasonCache increases the effective rank (variety) of internal representations compared to SFT and LoRA—suggesting richer, more flexible thinking patterns.
Why it matters: You get better reasoning without editing the model’s core weights, with less data, less compute, and a smaller adaptation to store and share.
What’s the impact?
- Practical efficiency: Teams can teach models strong reasoning skills without expensive retraining and without shipping big weight diffs. Inference is cheaper because the prefix is short and the model writes fewer “thinking” tokens.
- Safety and modularity: Because the base weights stay frozen, you reduce the risk of messing up existing skills. You can imagine “skill prefixes” as plug-and-play modules—one for math, another for science, etc.—and combine them as needed.
- New view of memory: ReasonCache sits between short-term prompt memory and long-term weight memory. It’s a compact, persistent memory that can be swapped in and out.
- Theory-guided design: Knowing that ReasonCache avoids the “narrow doorway” bottleneck helps explain why it works and when it might shine.
- Limits and next steps: On some contests (like AIME in this setup), gains were smaller—likely because those tasks need very long reasoning traces. Also, today’s tooling doesn’t natively support training KV prefixes, so better library and engine support would help. Future work could explore composing multiple skill prefixes, making them test-time-adaptable, and applying them beyond reasoning (e.g., coding, retrieval, or safety behaviors).
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of what remains missing, uncertain, or unexplored in the paper, formulated as concrete, actionable directions for future research.
- Generality across scales and architectures: Validate ReasonCache on larger models (e.g., 13B–70B+), diverse backbones (e.g., Mixtral, Llama-3, Phi), and multilingual models to assess scaling and transferability of benefits.
- Breadth of tasks: Extend evaluation beyond math and GPQA to code generation, algorithmic reasoning, formal logic, scientific QA, tool-augmented reasoning, and planning to test skill acquisition breadth.
- Long-context regimes: Remove the 4096-token filtering on OpenThoughts-3 and evaluate with untruncated long reasoning traces on true long-context models to probe behavior when examples exceed the context window.
- AIME limitations: Investigate why all methods stayed near baseline on AIME; test with unfiltered long-form traces and alternative training curricula to determine whether ReasonCache benefits depend on reasoning trace length or dataset characteristics.
- Decoding sensitivity: Quantify how results change under different decoding settings (temperature, sampling, beam search) and without enforced end-of-thinking termination; test whether shorter generations persist and whether accuracy or reliability shifts.
- Stronger baselines: Compare against state-of-the-art in-weight reasoning methods (e.g., RL-based R1-style training, longer SFT curricula, QLoRA, adapters in MLP and output layers) to position ReasonCache against best-known approaches.
- LoRA placement choices: Evaluate LoRA applied to Q, K, V, FFN, and output projections (alone and in combination) to ensure the LoRA baseline is not underpowered by limiting it to attention key/value only.
- Parameter-efficiency external validity: Replicate the parameter-efficiency gains on multiple tasks and models; report sensitivity of the gains to prefix length m and layer-wise distribution of prefixes.
- Wall-clock and system-level benchmarks: Complement TFLOPs estimates with end-to-end latency, memory footprint, and throughput on real hardware (GPUs/TPUs) including prefix injection overhead and cache orchestration costs.
- Prefix training stability: Systematically ablate initialization strategies (random vs. demo KV-cache), MLP reparameterization architectures, optimizers, and learning-rate schedules to characterize stability and convergence regimes.
- Layer/attention-head allocation: Explore where prefixes are most effective (early vs. late layers, specific heads), whether per-layer m should be tuned, and whether head-specific prefixes outperform shared ones.
- Composition of multiple skills: Develop mechanisms for composing multiple prefixes (routing, gating, ordering, conflict resolution), quantify interference/negative transfer, and validate catastrophic forgetting claims empirically.
- Test-time plasticity: Investigate online/continual adaptation with trainable KV-caches at inference (e.g., episodic updates, meta-learning), including safeguards to prevent drift and preserve stability.
- Safety and robustness: Assess whether prefixes introduce vulnerabilities (prompt injection, adversarial triggers, backdoors), how they interact with safety guardrails, and how to monitor or constrain prefix-induced behavior.
- Interpretability claims: Validate the proposed interpretability via prefix attention scores—design probes to link prefix attention patterns to specific reasoning steps and measure whether shorter chains reduce transparency.
- Chain-of-thought interactions: Empirically test the theoretical claim that CoT increases input rank t_X; measure how CoT length affects LoRA vs. ReasonCache and whether ReasonCache still helps when CoT is abundant.
- Expressivity theory beyond simplified settings: Extend proofs from single-layer, linearized attention to multi-head, residual connections, layernorm, FFNs, and cross-layer interactions; quantify when theoretical advantages persist.
- Optimization vs. expressivity: Separate expressivity from trainability—analyze whether ReasonCache reliably finds the superior subspaces predicted by theory; measure optimization landscapes and gradient flow differences vs. LoRA/SFT.
- Geometry–performance link: Establish causal links between effective-rank increases and reasoning accuracy via controlled interventions (e.g., rank-constrained prefixes, targeted subspace injections).
- Prefix size scaling law: Derive/measure how required prefix length m scales with task complexity, input diversity, and model size; produce practical guidelines for selecting m across tasks.
- Generalization and transfer: Evaluate how a prefix trained on one dataset transfers to out-of-distribution tasks (cross-math domains, GPQA subsets, new benchmarks) and whether fine-tuning prefixes yields positive transfer or overfitting.
- Multi-turn dialogue: Test ReasonCache in conversational settings where context evolves; study interactions between persistent prefixes and dynamically accumulating KV caches over multiple turns.
- Calibration and reliability: Measure confidence calibration, error detection, and self-consistency with shorter generations; evaluate whether reduced verbosity impacts external verification or process transparency.
- Interaction with retrieval/RAG: Explore how prefixes co-exist with retrieval systems—can prefixes encode procedures while RAG supplies facts? Measure interference or synergy and design routing strategies.
- Deployment tooling: Develop and evaluate standardized APIs and runtime support for trainable KV-caches in popular inference engines (vLLM, TGI, TensorRT-LLM), including cache storage formats, serialization, and multi-prefix management.
- Memory management at scale: Address storage, indexing, and selection of many task-specific prefixes (catalogs, metadata, retrieval), and define policies for prefix switching/mixing under resource constraints.
- Prefix interference with layernorm/residuals: Analyze whether normalization and residual pathways attenuate or amplify prefix contributions; design normalization-aware prefix parameterizations if needed.
- Fairness of data-efficiency claims: Confirm results with varied data splits, seeds, augmentation strategies, and larger SFT budgets; ensure comparisons don’t inadvertently favor ReasonCache due to dataset curation or training limits.
- Evaluation metrics breadth: Complement exact-match with process metrics (step correctness, faithfulness), error taxonomy, and robustness under perturbations to better characterize reasoning quality improvements.
- Non-English and cross-lingual reasoning: Test whether ReasonCache maintains benefits across languages and culturally diverse reasoning tasks; assess multilingual prefix training and transfer.
- Resource-constrained devices: Evaluate feasibility on edge or low-memory devices—measure prefix storage/computation trade-offs and propose compression/quantization strategies for prefixes.
- When LoRA is better: Empirically map regimes where LoRA’s expressivity exceeds PT (e.g., high-rank contexts with large r) and identify practical criteria to choose between ReasonCache and LoRA or combine them effectively.
Glossary
- AdamW: An optimization algorithm that decouples weight decay from the gradient update to improve training stability. "We train all methods with AdamW and a cosine learning-rate schedule (warmup ratio 0.05), using zero weight decay."
- AIME: A high-level mathematics competition dataset used to evaluate long-form reasoning in models. "This advantage, however, does not seem to extend to AIME 24 and 25:"
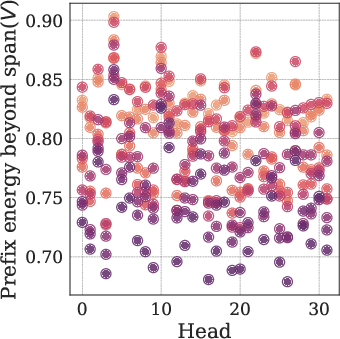
- attention head: A component of multi-head attention that learns distinct attention patterns over tokens. "First, across attention heads, the pretrained model’s value vectors occupy a low-dimensional subspace"
- autoregressive generation: A decoding procedure where each next token is generated conditioned on all previous tokens. "During autoregressive generation, keys and values are cached so that each new token can attend to all previous tokens without recomputation."
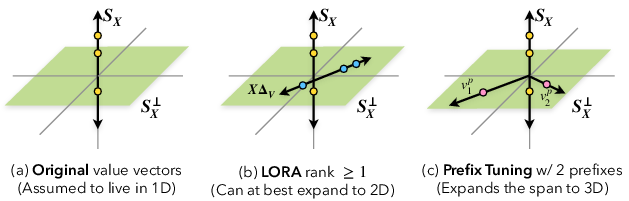
- carrier bottleneck: A limitation where updates that act through the input are constrained by the rank of the input sequence. "Low-rank weight updates act through the input sequence, constraining the induced key-value cache by both the adapter rank and input rank, resulting in what we call a carrier bottleneck."
- chain-of-thought: A prompting strategy that elicits intermediate reasoning steps to improve problem solving. "Producing a chain-of-thought expands this context with additional tokens, and can therefore increase t_X, enlarging the value span S_X and the set of directions available for subsequent computation."
- convex combination: A weighted sum of vectors with nonnegative weights that sum to one. "producing an output that is a convex combination over all values:"
- cosine learning-rate schedule: A learning rate schedule that follows a cosine curve to smoothly anneal the learning rate. "We train all methods with AdamW and a cosine learning-rate schedule (warmup ratio 0.05), using zero weight decay."
- end-of-thinking delimiter: A special token sequence used to terminate a model’s reasoning phase during decoding. "by appending the end-of-thinking delimiter and “Final Answer:”"
- exact-match accuracy (pass@1): A metric that measures whether the top (first) generated answer exactly matches the ground-truth. "and report exact-match accuracy (pass@1)."
- GPQA-Diamond: A challenging benchmark subset focused on scientific and graduate-level question answering. "On GPQA-Diamond, ReasonCache surpasses full supervised fine-tuning (SFT)."
- greedy decoding: A deterministic decoding strategy that selects the highest-probability token at each step. "under greedy decoding (temperature 0)"
- in-context learning (ICL): Adapting model behavior by conditioning on examples or instructions in the prompt without updating weights. "In-context learning (ICL) represents one of the most remarkable capabilities of modern LLMs."
- in-weight learning (IWL): Adapting a model by updating its parameters via fine-tuning or related methods. "Due to these limitations, practitioners predominantly rely on in-weight learning (IWL) to induce reasoning."
- key–value (KV) cache: The cached keys and values from attention layers that enable efficient autoregressive inference. "This KV-cache C = { (K{(\ell)}, V{(\ell)}) }_{\ell=1}{L} serves as the model's working memory"
- LoRA: A parameter-efficient fine-tuning method that applies low-rank updates to model weights. "We prove ReasonCache can be strictly more expressive than LoRA."
- low-rank weight updates: Parameter changes constrained to a low-rank matrix, limiting the directions they can alter. "Low-rank weight updates act through the input sequence"
- MetaMathQA: A dataset of mathematical problems and solutions used for training and evaluation of reasoning. "For short-reasoning tasks, we adapt a LLaMA-2 on MetaMathQA"
- MLP reparameterization: Using a small neural network to generate prefix parameters to stabilize optimization. "When ReasonCache uses the MLP reparameterization (see~\Cref{sec:ablations}), the MLP serves only to stabilize training and is discarded at deployment"
- novelty capacity: The dimensionality of directions in representation space not spanned by the current context-induced values. "novelty capacity, defined as the dimension of the subspace orthogonal to what the base model can already express."
- novelty subspaces: Subspaces capturing new representational directions beyond what the base model expresses on the given context. "We refer to these subspaces as novelty subspaces since they capture directions that are not realizable by the base model under the given context."
- OpenThoughts-3: A dataset containing long-form reasoning traces used for training and evaluation of reasoning capabilities. "we adapt a Qwen-2.5-7B-Instruct~\citep{yang2024qwen2} on a filtered subset of OpenThoughts-3"
- orthogonal projector: A linear operator that projects vectors onto the orthogonal complement of a subspace. "Let Π_X denote the orthogonal projector onto the complement S_X\perp"
- Pareto frontier: The set of solutions that optimally trade off two competing objectives, where no objective can be improved without worsening the other. "ReasonCache traces the Pareto frontier of accuracy versus training dataset size"
- parameter-efficient fine-tuning (PEFT): Techniques that adapt models using small additional parameter sets rather than full weight updates. "in contemporary PEFT practice, prefix lengths are often chosen to be moderately large"
- pass@1: The probability that the first sampled output is correct; commonly used for exact-match metrics in generative tasks. "and report exact-match accuracy (pass@1)."
- prefill cost: The computational cost of processing the entire input context before token-by-token decoding. "Since prefill cost scales quadratically with context length, replacing long exemplar prompts with a short prefix yields substantial savings."
- prefix tuning (PT): A method that learns trainable key–value vectors (prefixes) injected at each attention layer while keeping model weights frozen. "Prefix tuning introduces m trainable key--value pairs (P_K{(\ell)}, P_V{(\ell)}) at each layer ℓ."
- prompt tuning: Learning continuous input embeddings prepended at the input layer to steer model behavior with frozen weights. "Prompt tuning learns continuous embeddings E ∈ R{m × d} prepended at the input layer only"
- QK-LoRA: LoRA applied only to the query and key projection matrices, which cannot introduce new value directions. "PT Strictly More Expressive than QK-LoRA"
- QKV-LoRA: LoRA applied to query, key, and value projections to allow changes in all attention components. "Why QKV-LoRA fails."
- rowspace: The subspace spanned by the rows of a matrix, determining possible linear combinations it can produce. "token-derived values v_j{(\ell)} must lie in the rowspace of H{(\ell-1)} W_V{(\ell)}."
- supervised fine-tuning (SFT): Updating model parameters on labeled data to adapt to a specific task. "On GPQA-Diamond, ReasonCache surpasses full supervised fine-tuning (SFT)."
- TFLOPs: A measure of computational cost equal to trillions of floating-point operations. "Accuracy as a function of inference cost measured in TFLOPs."
- value projection: The linear transformation that maps hidden states to value vectors used in attention. "Given context embeddings X ∈ R{n × d}, the base model produces value vectors v_i = x_i W_V."
- value-space directions: Directions in the space of value vectors that attention can combine to form outputs. "enabling value-space directions that rank-limited updates cannot realize."
Practical Applications
Practical Applications of ReasonCache (Prefix-Tuned KV Caches for Reasoning)
Below are actionable applications derived from the paper’s methods, empirical findings, and theory. Each item includes potential sectors, tools/products/workflows, and key assumptions/dependencies that may affect feasibility.
Immediate Applications
- Cost-optimized reasoning assistants with frozen base models
- Sectors: software, customer support, finance, legal, education
- What: Replace many-shot ICL or verbose chain-of-thought (CoT) with a short learned prefix, reducing prefill and decoding costs while improving accuracy (e.g., 44–90% lower inference compute on GSM8K; 34% shorter generations and +11% accuracy on GPQA-Diamond vs SFT).
- Tools/workflows: “Reasoning prefix” artifacts per task; swap-in at inference; cost–accuracy dashboards; short-answer mode by default.
- Assumptions: Serving stack must support prefix KV injection; performance measured on LLaMA-2 and Qwen-2.5-7B—verify on chosen model; quality depends on curated reasoning traces.
- Tenant- or team-specific “skill packs” without fine-tuning
- Sectors: enterprise SaaS, MLOps
- What: Give each tenant a private, small prefix “skill” (e.g., domain style + reasoning), sharing a single frozen base model.
- Tools/workflows: Prefix registry (artifact store), per-tenant routing, audit logs per prefix.
- Assumptions: Isolation and governance policies for prefix artifacts; robust multi-tenant resource quotas.
- Rapid A/B testing and iteration of reasoning behaviors
- Sectors: product/platform engineering
- What: Train multiple small prefixes quickly and hot-swap in production to test reasoning strategies without touching base weights.
- Tools/workflows: Experiment orchestration; prompt+prefix combinators; online evaluation harness integration.
- Assumptions: Stable offline–online transfer; evaluation coverage to prevent regressions.
- Parameter- and storage-efficient distribution of adapted capabilities
- Sectors: cloud providers, model marketplaces
- What: Distribute compact prefixes (46% fewer parameters vs LoRA at matched accuracy on GSM8K) rather than full LoRA/SFT checkpoints.
- Tools/workflows: Artifact versioning, signature checks, policy gating for third-party prefixes.
- Assumptions: Consistent base model versions; compatibility across minor model revisions.
- Edge/on-device reasoning upgrades without re-training the model
- Sectors: mobile, embedded, industrial IoT
- What: Ship small prefixes to add reasoning skills on-device where weight updates are impractical.
- Tools/workflows: On-device prefix loader; offline KV initialization; memory budgeting for prefix length m.
- Assumptions: Device inference runtime supports KV-prefix injection; memory/latency constraints allow small m.
- Safer change management and rollback for regulated domains
- Sectors: healthcare, finance, legal, government
- What: Keep weights frozen for easier validation/certification; roll back by toggling prefixes.
- Tools/workflows: Change-control pipelines; prefix-level approvals and red-teaming.
- Assumptions: Regulators accept frozen-weight adaptation artifacts; documentation of training data/protocols for each prefix.
- Structured tutoring and course-specific reasoning modes
- Sectors: education
- What: Per-course or per-topic prefixes that improve step-by-step reasoning without lengthy examples at inference.
- Tools/workflows: Curriculum-linked prefix catalog; auto-selection based on syllabus tags.
- Assumptions: Needs high-quality, domain-aligned reasoning traces; guard against leakage of solutions.
- Domain-specific coding or data-analysis agents with concise outputs
- Sectors: software engineering, data science, BI
- What: Prefix-guided reasoning to reduce verbose CoT; faster code suggestions, fewer tokens.
- Tools/workflows: IDE plugins loading prefixes; “concise reasoning” toggle; cost-aware routing.
- Assumptions: Prefixes tuned for tools/APIs in the environment; evaluation for hallucinations/unsafe code.
- Hybrid RAG + reasoning compression
- Sectors: enterprise knowledge, customer support
- What: Use prefixes to encode general reasoning heuristics, while RAG supplies facts—reduces need for long reasoning prompts with retrieval context.
- Tools/workflows: RAG pipeline with fixed reasoning prefix; retrieval budget optimized separately from reasoning budget.
- Assumptions: Retrieval remains accurate; prefix generalizes across retrieved contexts.
- Research instrumentation: probing representation geometry
- Sectors: academia, ML research labs
- What: Use prefixes to test expressivity hypotheses (e.g., effective rank increases ~20% vs SFT/LoRA) and study carrier bottlenecks.
- Tools/workflows: Rank/energy diagnostics per layer/head; ablation suites (m, layer depth).
- Assumptions: Metrics and effects transfer across architectures; careful control of confounders.
Long-Term Applications
- Composable skill libraries and “prefix marketplaces”
- Sectors: platform ecosystems, AI marketplaces
- What: Mix-and-match prefixes (reasoning, safety, style, domain) per request; revenue-share marketplaces for third-party skills.
- Tools/workflows: Composition graphs (ordering, layer targeting); conflict resolution; provenance and licensing metadata.
- Assumptions: Standardized prefix formats and safety vetting; composition does not produce brittle interactions.
- Continual and test-time learning via plastic KV memory
- Sectors: adaptive assistants, lifelong learning
- What: Make KV caches partially plastic at runtime for incremental skill acquisition without weight edits.
- Tools/workflows: On-the-fly prefix updates with safeguards; decay/retention schedules; rehearsal-free evaluation.
- Assumptions: Stability–plasticity trade-offs; catastrophic interference controls; runtime training support.
- Prefix-aware inference engines and hardware acceleration
- Sectors: inference serving, silicon vendors
- What: Native support in engines (e.g., vLLM, TGI) and accelerators for layer-wise prefix KV injection and caching.
- Tools/workflows: Engine APIs for prefix lifecycles; memory pooling for per-layer KV; batching strategies that share prefixes.
- Assumptions: Vendor adoption; standardized APIs; measurable throughput gains across workloads.
- Automated prefix routing and retrieval
- Sectors: agents, orchestration platforms
- What: Route each request to the best prefix set using task detection, telemetry, and bandits; retrieve specialized prefixes on demand.
- Tools/workflows: Prefix retrieval index; router with uncertainty/cost models; online learning for routing.
- Assumptions: Low-latency selection; robust metadata for tasks; cold-start strategies for new domains.
- Cross-model portability and distillation of prefixes
- Sectors: model providers, multi-model platforms
- What: Translate or distill a prefix trained on one base model to another (size or vendor change).
- Tools/workflows: Prefix distillers; alignment losses over hidden states; compatibility validators.
- Assumptions: Sufficient hidden-space alignment; IP/licensing constraints; partial performance loss acceptable.
- Safety, compliance, and policy enforcement via prefixes
- Sectors: safety engineering, trust & safety, governance
- What: Encode safety guardrails and compliance reasoning in prefixes; monitor attention to safety tokens for interpretability.
- Tools/workflows: Safety-prefix library; attestation and audit trails; explainability via prefix attention scores.
- Assumptions: Guardrails remain effective under distribution shift; adversarial robustness of prefixes.
- Federated and privacy-preserving adaptation
- Sectors: healthcare, finance, on-prem enterprise
- What: Clients train prefixes locally on sensitive data; share only prefixes (or aggregated updates) centrally.
- Tools/workflows: Federated prefix training; differential privacy on prefix parameters; secure aggregation.
- Assumptions: DP noise–utility trade-offs; leakage risk from small artifacts is acceptably low.
- Real-time robotics and autonomy with low-latency reasoning modules
- Sectors: robotics, automotive, industrial automation
- What: Load compact reasoning prefixes for task planning/execution under tight latency/compute budgets.
- Tools/workflows: Task-conditioned prefix switching; perception–reasoning pipelines; safety overrides as separate prefixes.
- Assumptions: Robustness to sensor noise; certification for safety-critical use; real-time guarantees.
- Carbon-aware and cost-aware reasoning budgets
- Sectors: cloud/energy management, sustainability
- What: Dynamically select shorter-generation, small-m prefixes under carbon or cost constraints while maintaining accuracy.
- Tools/workflows: Budget schedulers; telemetry-driven policies; SLO-based degradation modes.
- Assumptions: Stable accuracy–cost tradeoff across traffic; reliable telemetry and forecasting.
- Clinically/legally validated domain reasoning packs
- Sectors: healthcare, law
- What: Prefixes that encode validated reasoning protocols (e.g., clinical guidelines, legal argument structures) for decision support.
- Tools/workflows: Expert-in-the-loop prefix curation; validation studies; post-deployment monitoring.
- Assumptions: Regulatory acceptance; ongoing re-validation as rules change; careful scope limitation.
- Mathematical and scientific reasoning modules
- Sectors: R&D, education
- What: Prefixes specializing in proof strategies, derivations, experiment planning; pair with tools (CAS, calculators).
- Tools/workflows: Tool-use aware prefixes; runner that injects tool outputs; citation/trace logging.
- Assumptions: Reliable tool integration; rigorous evaluation on out-of-distribution problems.
- Method selection policies informed by carrier bottleneck theory
- Sectors: MLOps, research tooling
- What: Decide between LoRA vs ReasonCache (or both) based on context rank and novelty capacity: use prefixes when input rank is low or low-rank adapters would bottleneck.
- Tools/workflows: Rank estimators; hybrid adapters; CoT length controllers to modulate rank when using LoRA.
- Assumptions: Practical estimation of input rank; minimal overhead for dynamic method selection.
Notes on Key Assumptions and Dependencies
- Engine support: Widespread adoption requires inference engines to natively support trainable KV prefixes across layers; until then, custom patches or plugins are needed.
- Model and data scope: Reported gains are on specific backbones (e.g., Qwen-2.5-7B, LLaMA-2) and datasets (GSM8K, MATH, AIME, GPQA-Diamond) with a 4096-token budget; verify generalization to your model/task. AIME results suggest long-form math may need longer training traces than the 4096 cap.
- Prefix length and placement: Performance–latency trade-offs depend on prefix length m and which layers receive prefixes; tuning is required.
- Governance and safety: Even small artifacts can encode powerful behaviors; require review, provenance tracking, and usage controls.
- IP/licensing: Prefixes may embody organization-specific know-how; manage licensing and data rights accordingly.
- Evaluation: Maintain robust offline/online evaluation (accuracy, verbosity, latency, safety) since prefixes can change reasoning style and output length in nontrivial ways.
Collections
Sign up for free to add this paper to one or more collections.