Reuse your FLOPs: Scaling RL on Hard Problems by Conditioning on Very Off-Policy Prefixes
Abstract: Typical reinforcement learning (RL) methods for LLM reasoning waste compute on hard problems, where correct on-policy traces are rare, policy gradients vanish, and learning stalls. To bootstrap more efficient RL, we consider reusing old sampling FLOPs (from prior inference or RL training) in the form of off-policy traces. Standard off-policy methods supervise against off-policy data, causing instabilities during RL optimization. We introduce PrefixRL, where we condition on the prefix of successful off-policy traces and run on-policy RL to complete them, side-stepping off-policy instabilities. PrefixRL boosts the learning signal on hard problems by modulating the difficulty of the problem through the off-policy prefix length. We prove that the PrefixRL objective is not only consistent with the standard RL objective but also more sample efficient. Empirically, we discover back-generalization: training only on prefixed problems generalizes to out-of-distribution unprefixed performance, with learned strategies often differing from those in the prefix. In our experiments, we source the off-policy traces by rejection sampling with the base model, creating a self-improvement loop. On hard reasoning problems, PrefixRL reaches the same training reward 2x faster than the strongest baseline (SFT on off-policy data then RL), even after accounting for the compute spent on the initial rejection sampling, and increases the final reward by 3x. The gains transfer to held-out benchmarks, and PrefixRL is still effective when off-policy traces are derived from a different model family, validating its flexibility in practical settings.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about helping LLMs get better at hard reasoning tasks (like math and coding) using reinforcement learning (RL). The problem is that, on very hard questions, standard RL wastes a lot of computing power trying things that almost never work, so learning slows down or stops. The authors propose a new way, called PrefixRL, that reuses “good moments” from past attempts as short hints (prefixes) and then trains the model to finish the solution from there. This makes learning faster, more stable, and still helps the model solve the original, un-hinted problems later.
Key Objectives and Questions
In simple terms, the paper asks:
- Can we reuse earlier compute (past tries or runs) to help current RL training on hard problems?
- How can we use these past tries without causing the model to just memorize them or train unstably?
- If we train the model to finish problems from partial correct steps (prefixes), will it also improve at solving the full problems without any hints?
- Can we prove this idea is both correct (doesn’t bias the goal) and more sample-efficient (needs fewer tries)?
- Does it work in practice, across different models and benchmarks?
Methods and Approach
Why typical ways of reusing past tries fail
Think of “past tries” as example solution traces from earlier runs or other models. Two common ways to use them often backfire:
- Supervised fine-tuning (SFT) on those traces: This can make the model too “narrow,” like memorizing a few paths and losing diversity. Later, RL explores less and gets stuck.
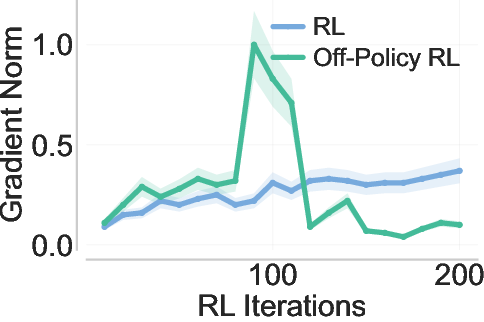
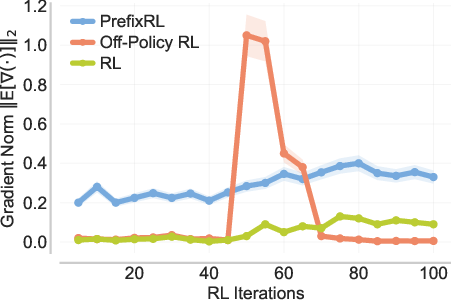
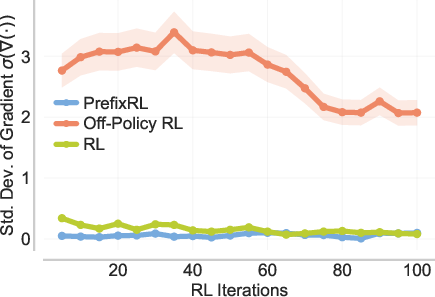
- Off-policy RL with importance weighting: This directly updates the model using past traces that the current model wouldn’t normally produce. That causes very unstable training because gradients (the learning signals) become huge or noisy.
Both approaches treat past tries as targets to imitate, which clashes with how RL should explore.
PrefixRL in simple terms
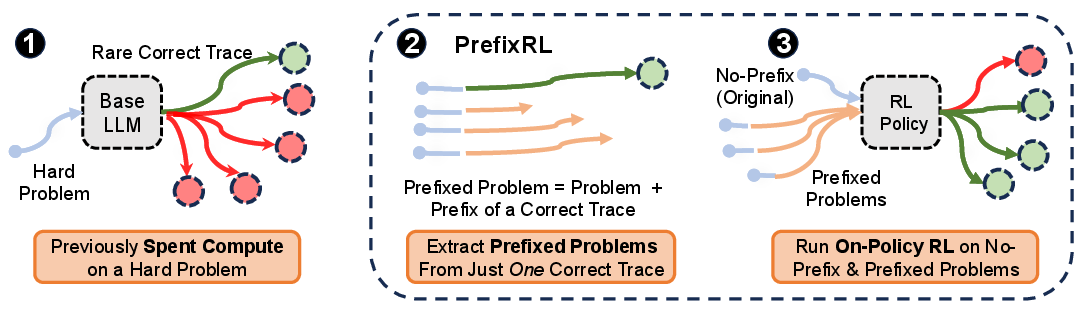
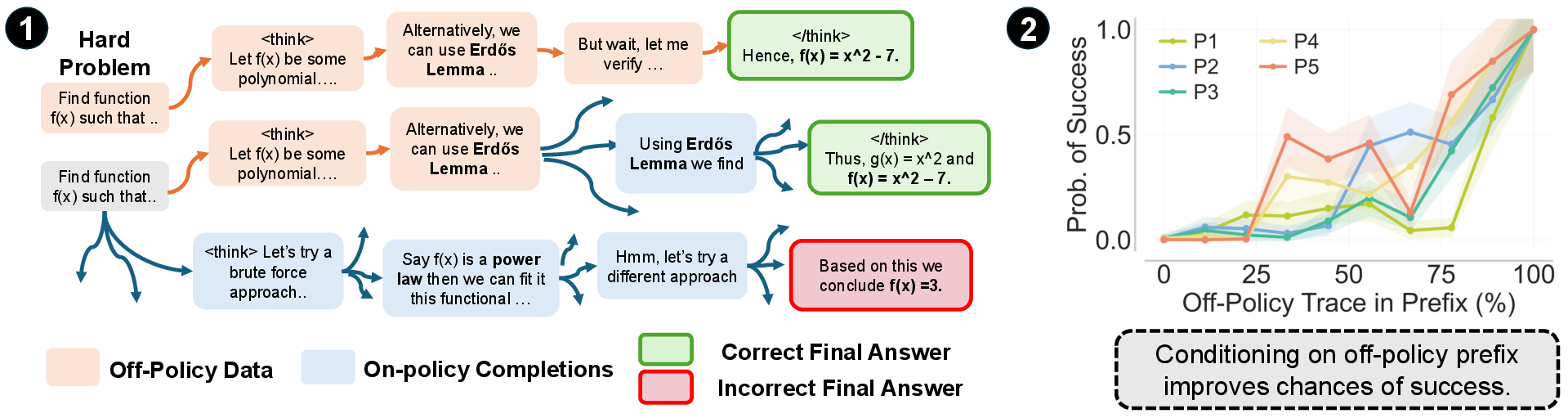
Imagine solving a maze. The model rarely finds the exit on its own. But if you give it a tiny head start—like putting it near a key fork where choosing left wins—it’s much more likely to finish correctly. PrefixRL does exactly that:
- Collect correct solution traces for hard problems from earlier compute (by rejection sampling: repeatedly try until you get a correct solution).
- Cut those traces into short prefixes—like “mini-hints” that put the model in promising states.
- Train with on-policy RL to complete the solution from the prefix, while also training on some original problems without prefixes.
- Importantly, the model’s gradients (updates) don’t try to imitate the prefix itself; they only learn from completing the rest. This avoids the instability and memorization problems.
In other words, PrefixRL uses hints to place the model in smarter starting positions, then lets standard RL do its job finishing the solution.
How did they test it?
- They built a “self-improvement loop”: collect correct traces by rejection sampling on the base model (keep trying until correct), use prefixes from those traces, then run RL on a mix of prefixed and original problems.
- They compare PrefixRL to strong baselines: (1) SFT on off-policy data then RL, and (2) off-policy RL variants.
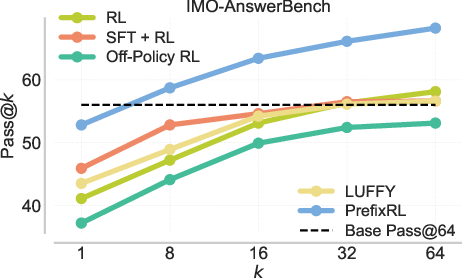
- They evaluate both training accuracy and transfer to real benchmarks (AIME ’25, HMMT, IMO-AnswerBench).
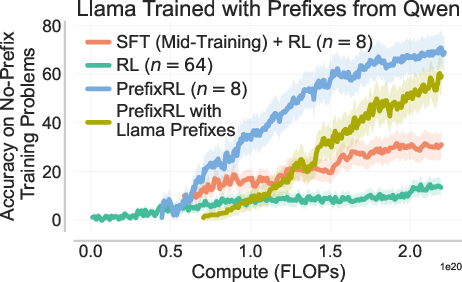
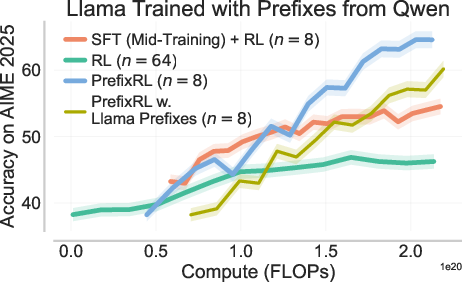
- They also test using prefixes from a different model family (e.g., Qwen prefixes to train Llama) to check flexibility.
What does the theory say?
Two main ideas:
- Objective consistency: If prefixes come from correct traces that are achievable by some policy, then optimizing with PrefixRL reaches the same optimal solution as standard RL. In short: using prefixes doesn’t bias what “best” means—it only changes how you get there.
- Better sample efficiency: Because PrefixRL starts the model closer to good states, it needs fewer on-policy samples (tries) to get strong performance. This is especially helpful for long, complex problems with many steps.
Main Findings
Here are the most important results explained simply:
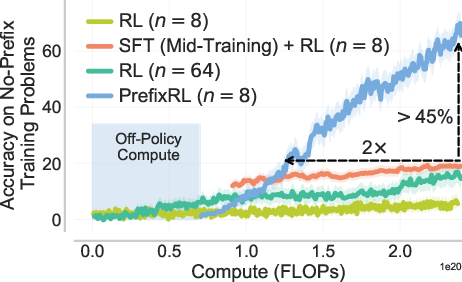
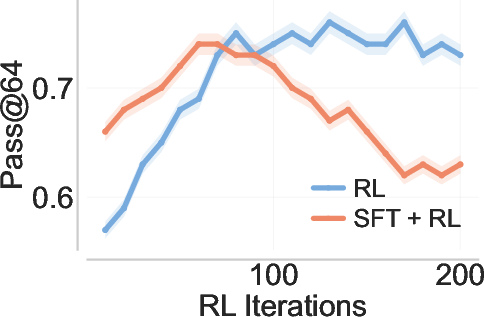
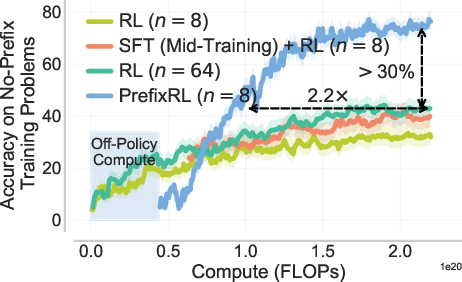
- Faster and higher rewards: PrefixRL reaches the same training reward about 2× faster than the best baseline (SFT + RL)—even after counting the extra cost to collect the prefixes—and ends up with much higher accuracy (over 3× relative increase in final training reward on no-prefix problems).
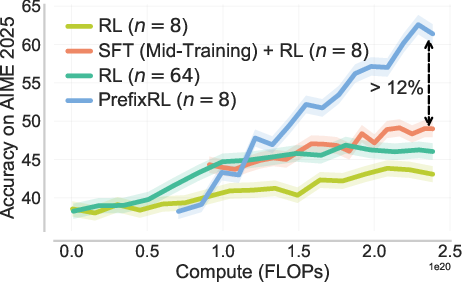
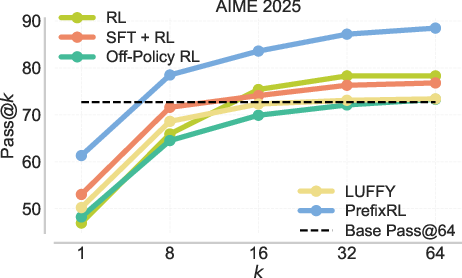
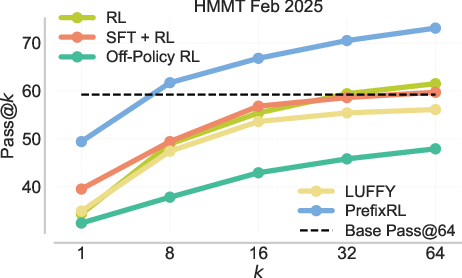
- Transfers to real tests: Gains on training problems carry over to benchmarks like AIME ’25 (pass@1 improves by about 12% over the strongest baseline in a compute-matched setting).
- Works across model families: Using prefixes from a different model (e.g., Qwen) still helps Llama, showing PrefixRL is flexible.
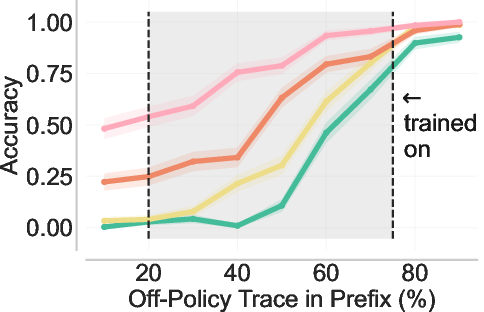
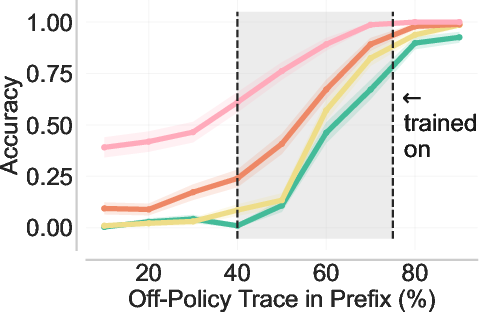
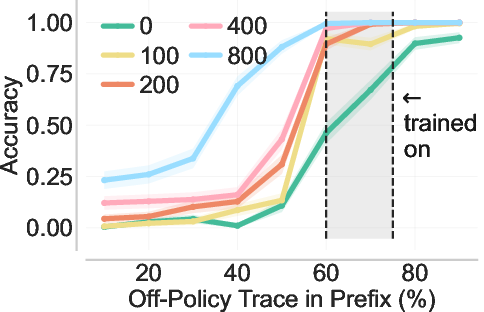
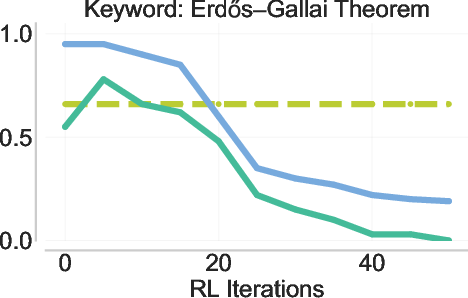
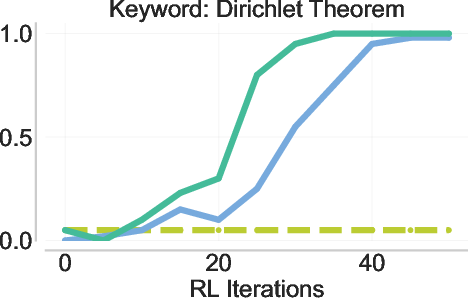
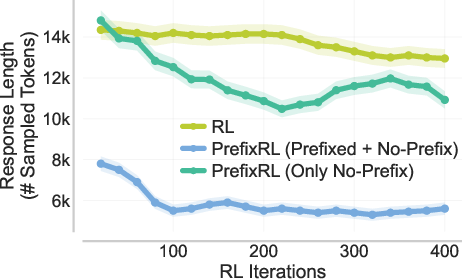
- Back-generalization: Training only on prefixed problems improves performance on the original, unprefixed problems. It’s like practicing with hints and then doing better even without hints.
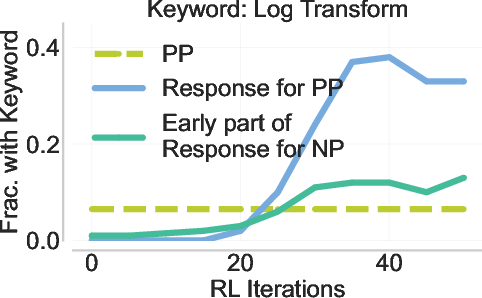
- Not just copying: The model doesn’t simply imitate the exact hint. It often discovers better strategies than the ones shown in the prefix and can suppress suboptimal ones. This shows real learning, not memorization.
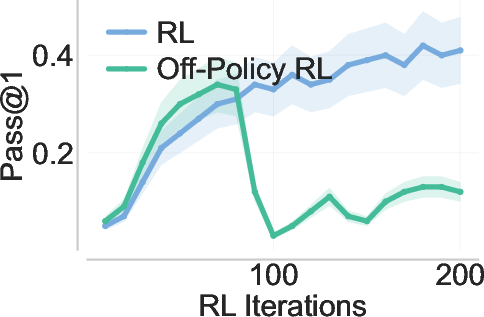
- More stable than off-policy RL: Unlike importance-weighted off-policy RL, PrefixRL avoids unstable gradients and training collapse.
Why This Is Important
- Reusing compute: Big models use huge amounts of compute (FLOPs). PrefixRL “reuses your FLOPs” by turning previously spent compute (past correct traces) into head starts that make future RL training more efficient.
- Better learning on hard problems: When correct answers are extremely rare, typical RL stalls. PrefixRL breaks through by placing the model in states where success is more likely and learning signals are stronger.
- Strong generalization: Back-generalization means improvements carry back to the original tasks without hints, and even to related problems (e.g., in-context learning setups). That suggests the model is truly learning robust strategies, not just parroting.
- Practical and flexible: It works with different models and data sources, scales well, and is less fragile than common alternatives (like SFT-only or off-policy RL).
In short, PrefixRL offers a simple-yet-powerful twist: give the model a smart head start from real, correct partial solutions, then let on-policy RL do the rest. This leads to faster learning, higher accuracy, and better generalization on difficult reasoning tasks.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper, targeted to guide future research.
- Robustness to imperfect prefixes: quantify PrefixRL’s sensitivity to incorrect, partially correct, or non-realizable off-policy prefixes (e.g., prefixes with flawed reasoning that nonetheless lead to correct final answers), and derive performance/consistency guarantees under prefix noise.
- Practical algorithm gap: extend the theoretical analysis (which assumes NPG and realizable traces) to the practical training algorithms used (REINFORCE/GRPO/PPO-clip with masking, entropy bonuses, KL controls), providing convergence and sample-efficiency guarantees under clipping, off-policy conditioning, and function approximation.
- Gradient variance and bias: formally analyze how conditioning on prefixes affects gradient variance and advantage signal as a function of prefix length, context window (H), and reward sparsity; include empirical variance measurements across training.
- Prefix selection policy: move beyond heuristic prefix length choices; design and evaluate adaptive scheduling (e.g., bandits/curricula) that select prefix lengths per-problem based on current pass@k, expected advantage, or uncertainty, and quantify the compute–performance trade-off.
- Multi-prefix diversity: study whether multiple distinct correct traces per problem (diverse prefixes) improve exploration or induce mode collapse; propose sampling/weighting strategies across prefixes and assess their impact on generalization.
- Mixing strategy: determine optimal mixing ratios and schedules between prefixed and no-prefix training within PrefixRL; systematically ablate how mixture affects exploration, entropy, and no-prefix transfer.
- Back-generalization mechanism: move beyond speculation and validate the representational hypothesis by probing internal states; measure latent similarity between prefixed and no-prefix trajectories (e.g., CCA/probes), and perform causal counterfactuals (prefix swapping/shuffling) to identify when and why transfer occurs.
- Failure modes of back-generalization: identify and characterize conditions where back-generalization is weak or negative (e.g., very long, highly idiosyncratic prefixes; unrelated in-context pairs); develop diagnostics to predict transfer strength before training.
- Off-policy RL baselines: implement stronger sequence-level off-policy corrections (e.g., V-trace, Retrace, doubly robust estimators, sequence-level importance weighting) and compare stability, variance, and final performance to PrefixRL under identical compute budgets.
- Reward design: evaluate PrefixRL with dense/process rewards, partial credit, and step-level feedback (beyond binary outcome rewards), including how masking interacts with step-level credit assignment.
- No-correct-trace regime: study settings where pass@k≈0 and no correct off-policy trace exists; explore using near-miss prefixes, partial program states, or search-derived partial plans, and analyze their utility for PrefixRL.
- Prefix quality estimation: develop methods to automatically identify “strategy-revealing” states and filter harmful or low-quality prefixes (e.g., via advantage estimates, novelty metrics, verifier confidence), rather than relying on keyword heuristics or fixed bands.
- Cross-model family transfer: quantitatively relate transfer strength to distribution shift metrics (e.g., empirical KL(μ||π₀)), especially when sourcing prefixes from different model families (Qwen→Llama); explain and mitigate weakened transfer for long, heterogeneous prefixes.
- Scalability: assess PrefixRL on larger models (≥70B) and much longer contexts (≥32k tokens), including memory footprint, throughput, gradient-masking implementation costs, and distributed training considerations.
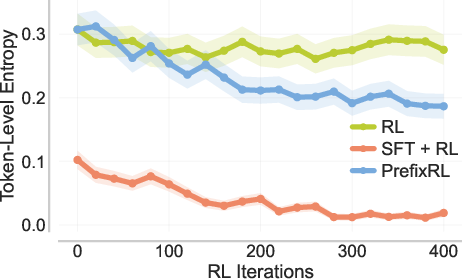
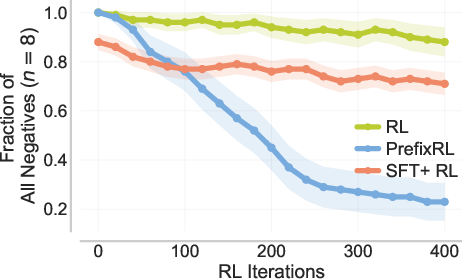
- Exploration and entropy: systematically measure how PrefixRL affects token-level entropy, diversity (pass@k), and exploration compared to SFT+RL and standard RL, across training phases and prefix-length bands.
- Safety and robustness: analyze behavior under adversarial, biased, or toxic prefixes; develop prefix sanitization, filtering policies, and robustness mechanisms to prevent harmful conditioning despite gradient masking.
- Autograder/reward noise: evaluate sensitivity to verifier errors and spurious solutions; measure how incorrect rewards interact with prefix conditioning and whether masking amplifies or mitigates such noise.
- Compute accounting and optimal allocation: provide a full FLOPs breakdown (rejection sampling, training, evaluation) and optimize the allocation between prefix collection and RL updates; study diminishing returns as more prefixes are added.
- Task breadth: test PrefixRL beyond math reasoning (e.g., coding, tool-use, program synthesis, long-form QA) to determine domain generality and failure modes.
- Inference-time benefits: measure whether PrefixRL reduces test-time sampling budgets (pass@1 vs pass@k improvements) and improves calibration/termination criteria, not just training reward.
- Data privacy and memorization: assess risks when prefixes contain private or proprietary content; ensure masked gradients do not preclude privacy attacks and evaluate memorization even without explicit supervision.
- Credit assignment on prefixes: explore partial or learned gradient masking on prefix tokens (e.g., allowing value function learning without direct log-prob updates) to improve credit assignment without instability.
- Scheduling across iterations: study dynamic reweighting of prefix bands over training (e.g., start with longer prefixes and anneal to shorter) and quantify how schedules affect back-generalization speed and stability.
- Multiple off-policy sources: analyze combining prefixes from varied sources (previous RL runs, human solutions, different LLM families) and propose weighting or domain-adaptation techniques to harmonize heterogeneous prefixes.
- Evaluation rigor: provide comprehensive dataset details and contamination checks for held-out benchmarks (e.g., AIME’25, HMMT, IMO-AnswerBench), ensuring strict separation from prefix sources and prior runs; include broader metrics (error taxonomy, reliability, robustness under perturbations).
Glossary
- Advantage: In policy gradient RL, the difference between the return of a trajectory and a baseline (often the value or Q-function) used to reduce variance. "the advantage "
- AIME '25: A 2025 benchmark derived from the American Invitational Mathematics Examination used to evaluate mathematical reasoning performance. "on AIME '25, PrefixRL improves pass@1 by 12\%"
- Back-generalization: The phenomenon where training only on prefixed (augmented) problems improves performance on the original, unprefixed problems. "we empirically find an additional phenomenon behind the gains in PrefixRL we call back-generalization"
- Behavior policy: The policy that generated logged (off-policy) data, used for analysis of distribution shift and importance weighting. "the induced behavior policy is conditioned on success"
- Context length (Horizon): The maximum number of tokens (time steps) considered in the sequence generation or RL episode. "within a maximum context length of tokens."
- Critic: A learned estimator (e.g., Q-function) of returns used to guide policy improvement in actor-critic methods. "policy evaluation by fitting a critic or -function"
- Distribution shift: The mismatch between the data distribution used for training/evaluation and the target distribution, often causing instability or bias. "This term is not impacted by any distribution shift penalty"
- Empirical distribution: The observed data distribution over a finite dataset, often used as the training distribution. "which is the empirical distribution over "
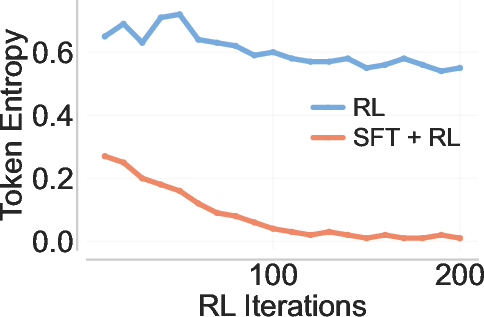
- Entropy collapse: A rapid reduction in the model’s output entropy, often harming exploration by making outputs too deterministic. "sharp entropy collapse after SFT"
- FLOPs: Floating-point operations; a measure of computational cost in model training or inference. "spends enormous amounts of sampling FLOPs"
- Function approximation: Using parameterized models (e.g., neural networks) to approximate value functions or policies, enabling generalization across states. "Benefitting from function approximation, PrefixRL alters the next-token distribution on unseen states"
- GRPO: An RL algorithm for LLMs; here used as a reference method approximating policy gradients. "Following GRPO~\citep{guo2025deepseek}, the expectation in \eqref{eq:policy-gradient-reinforce} is approximated"
- Importance weighting: Correcting for distribution mismatch by weighting off-policy samples by the ratio of target to behavior policy probabilities. "importance-weighted off-policy RL"
- In-context learning: Conditioning an LLM with examples or solutions in the prompt so it can adapt behavior without gradient updates. "in an in-context learning setup"
- KL divergence: A measure of difference between two probability distributions, often used for regularization in RL. "satisfies "
- KL-regularized mirror descent: An optimization update that uses a KL divergence term to regularize policy updates, as in natural policy gradient variants. "policy improvement using the fitted critic via a KL-regularized mirror-descent update of NPG"
- Mid-training: A stage of supervised fine-tuning on curated data before RL (also called continued pretraining). "mid-training (SFT)"
- Natural Policy Gradient (NPG): A policy gradient method that uses the Fisher information metric to precondition updates, improving stability. "We analyze PrefixRL by instantiating the policy update to be natural policy gradient~\citep{kakade2001natural} (NPG)"
- Negative log-likelihood (NLL): The negative logarithm of predicted probabilities; a standard loss for language modeling. "we measure the negative log-likelihood (NLL)"
- Off-policy prefix: A prefix of a trajectory generated by a different policy than the current one, used here for conditioning while masking gradients. "off-policy prefixes"
- Off-policy RL: Reinforcement learning using data generated by a different policy than the one being updated, often requiring importance weighting. "Directly using during online RL by updating the current RL policy with importance-weighted off-policy traces"
- On-policy RL: Reinforcement learning where data is collected using the current policy being optimized. "run on-policy RL"
- Pass@k: The probability of at least one correct solution among k sampled outputs. "We define the pass rate @ (pass@)"
- Policy class: The set of allowable policies (models) considered during optimization. "in policy class "
- Policy evaluation: Estimating the expected returns (e.g., Q-function) under a given policy to support policy improvement. "policy evaluation by fitting a critic or -function"
- Policy gradient: Methods that optimize policies by ascending the gradient of expected returns with respect to policy parameters. "policy gradient RL algorithms"
- Policy improvement: Updating the policy to increase expected returns using information from the critic or advantages. "policy improvement using the fitted critic via a KL-regularized mirror-descent update"
- PPO-clip: Proximal Policy Optimization with clipping; a popular stable policy gradient algorithm. "PPO-clip~\citep{schulman2017ppo}"
- Prefix length: The number of tokens taken from an off-policy trace and prepended to the problem as a conditioning context. "prefix length lies in the shaded interval."
- PrefixRL: The proposed method that runs on-policy RL conditioned on off-policy prefixes to stabilize and accelerate learning. "We introduce PrefixRL"
- Q-function: The expected return conditioned on state-action (or problem-response) pairs under a policy. "where "
- Realizability: The assumption that there exists a policy in the class that can produce the logged (correct) trajectories with probability 1. "there exists an optimal policy s.t. ."
- Rejection sampling: Sampling method that repeatedly generates candidates until one meets a criterion (e.g., correctness), used here to collect correct traces. "we source the off-policy traces by rejection sampling with the base model"
- Reset distribution: The effective initial distribution over states induced by conditioning or environment resets, relevant to evaluation and variance. "under the same reset distribution induced by off-policy prefixes from "
- REINFORCE: A classic Monte Carlo policy gradient algorithm using returns or advantages for updates. "the REINFORCE algorithm we use in our experiments"
- Rollout: A sampled trajectory (sequence of tokens/actions) generated by a policy. "sample multiple reasoning traces (rollouts) from the current model"
- Sample complexity: The number of samples required to achieve a desired performance or error bound. "converts information already paid for in logged prefixes into sample-complexity advantages over standard RL."
- Suboptimality gap: The difference between the optimal achievable return and the return of a learned policy. "PrefixRL reduces suboptimality gap with less samples compared to standard RL (by a factor of context length)."
- Supervised fine-tuning (SFT): Training the model on labeled demonstrations or correct traces to shape its behavior before or alongside RL. "perform supervised fine-tuning (a.k.a., mid-training or continued pretraining)"
- Tabular RL: Reinforcement learning with a finite, explicit state-action representation (no function approximation). "impossible in the tabular RL setting"
- Token entropy: The entropy of the model’s next-token distribution, reflecting diversity vs. determinism. "reduces token entropy"
- Variance (high-variance gradient estimates): Large variability in gradient estimates, often causing instability in off-policy policy gradients. "high-variance gradient estimates"
- Vanishing gradients: The issue where gradients become too small to drive learning, here due to rare correct traces on hard tasks. "policy gradients vanish"
Practical Applications
Immediate Applications
Below are actionable, near-term uses of PrefixRL that can be deployed with today’s LLM training stacks and verification tools.
- LLM self-improvement pipelines for math and coding (Software, Education)
- Use rejection sampling to build an off-policy trace warehouse of correct chains-of-thought on hard, verifiable tasks (e.g., unit-tested code problems, math with answer checkers), then run on-policy RL with gradient masking on off-policy prefixes to boost pass rates and compute-efficiency.
- Tools/products/workflows: off-policy trace store; prefix-length scheduler to modulate task difficulty; RL trainer (PPO/GRPO/REINFORCE) with prefix conditioning and gradient masking; back-generalization monitor that evaluates across prefix-length spectra (including no-prefix).
- Assumptions/dependencies: availability of verifiable rewards (tests/answer checkers); enough correct prefixes from prior inference/RL runs; trace realizability in the model class; careful choice of prefix-length distribution to “bridge” from long prefixes to no-prefix performance.
- Continual post-training that reuses prior compute across model versions (Software, MLOps)
- When refreshing a model, log and reuse correct traces gathered in production or earlier training runs to bootstrap the next RL cycle via PrefixRL; amortize FLOPs and shorten time-to-quality on hard problem sets.
- Tools/workflows: compute ledger and trace logging across versions; deduplication and provenance tagging; policy for reuse thresholds based on pass@.
- Assumptions/dependencies: governance for storing user interaction traces; privacy/PII scrubbing; stable reward definitions across versions.
- Cross-model prefix transfer for smaller-to-larger models (Software)
- Import prefixes from a different model family (e.g., Qwen→Llama) to guide training of a target model; accelerate learning where the target’s pass@ is near zero.
- Tools/workflows: cross-family trace format; likelihood diagnostics to detect overly long or distribution-mismatched prefixes; prefix-length mixing to avoid train–test gaps.
- Assumptions/dependencies: prefix realizability and semantic compatibility across model families; broader prefix-length distribution improves back-generalization.
- Program synthesis RL with unit tests (Software/DevOps)
- Treat passing unit tests as binary rewards; mine partial correct code snippets or tool call sequences from prior runs as prefixes; train with PrefixRL to reduce exploration burden on complex synthesis tasks.
- Tools/workflows: test harness integrated into RL; prefix curator that extracts strategy-revealing partial solutions (function skeletons, API call sequences); gradient masking on prefixes.
- Assumptions/dependencies: robust test coverage; careful handling of code diversity to avoid premature entropy collapse from SFT-only warm starts.
- Curriculum design in AI tutoring and exam prep (Education, Daily life)
- Construct training/evaluation tasks prefixed with concise, strategy-revealing hints derived from prior correct traces; leverage back-generalization to lift performance on unprefixed tasks while limiting over-imitation.
- Tools/workflows: hint generator selecting minimal prefixes that spike success probability; adaptive prefix-length scheduling per learner/task; correctness verification at end of response.
- Assumptions/dependencies: reliable answer verification; UX guardrails around chain-of-thought exposure; balance between hinting and independent problem solving.
- Stabilized RL training for reasoning models (Industry R&D)
- Replace unstable off-policy RL and entropy-collapsing mid-training (SFT-only warm starts) with PrefixRL’s gradient-masked prefixes; reduce gradient blow-ups and sharpen sample efficiency on hard problems.
- Tools/workflows: training dashboards for gradient norms and entropy; masking utilities; pass@ cohorts of “hard” tasks to target.
- Assumptions/dependencies: proper advantage estimation on mixed prefixed/no-prefix batches; monitoring to avoid prefix overuse on trivial tasks.
- Compute reuse tracking and sustainability reporting (Energy/Policy within organizations)
- Operationalize “reuse your FLOPs”: attribute and recycle previously spent inference/training compute via prefix collection and PrefixRL; report reductions in additional sampling required on hard tasks.
- Tools/workflows: compute ledger tied to trace warehouse; KPIs for pass@, time-to-reward, and FLOPs amortization.
- Assumptions/dependencies: trace provenance; internal policies on data retention and compliance.
Long-Term Applications
These uses require further research, scaling, domain adaptation, or governance before broad deployment.
- Sample-efficient robotics learning from partial trajectories (Robotics)
- Prefix on logged segments of successful robot manipulation/planning trajectories to place policies in higher-reward states during on-policy training; reduce exploration in sparse-reward settings.
- Tools/workflows: trajectory segment extractors; success verifiers; prefix-conditioned policy updates for continuous control.
- Assumptions/dependencies: mapping textual “prefix” concept to embeddings or state-action prefixes; safety verification; simulators and real-world transfer.
- Training tool-using agents on complex procedural tasks (Software/AI agents)
- Condition training on partial sequences of successful tool calls (search, code execution, calculators) mined from prior sessions; use PrefixRL to learn robust multi-tool strategies.
- Tools/workflows: centralized tool-trace warehouse; mixed-prefix RL curricula; execution-verification of final outcomes.
- Assumptions/dependencies: reliable tool feedback loops; scalable verifiers; prevention of brittle overfitting to tool-call syntax.
- Clinical decision support with verified outcomes (Healthcare)
- Leverage prefixes from prior, guideline-concordant cases to guide training of reasoning models; aim to reduce exploration on high-stakes, long-horizon decisions.
- Tools/workflows: de-identified case repositories; outcome verifiers (e.g., adherence to protocols, retrospective outcomes); audit trails for trace provenance.
- Assumptions/dependencies: rigorous safety, privacy, and regulatory compliance; validated reward functions beyond simple 0/1 correctness; domain expert oversight.
- Strategy formation and planning in finance/operations (Finance)
- Train planning models conditioned on prefixes derived from historical successful strategies (e.g., risk-managed trades, logistics plans), improving exploration on complex decision trees.
- Tools/workflows: backtesting engines as verifiers; prefix extraction from multi-step strategy descriptions; risk controls and compliance checks.
- Assumptions/dependencies: robust, non-leaky reward signals; guardrails against learning spurious correlations; governance around proprietary data.
- Trace marketplaces and standards for cross-organization reuse (Policy/Governance)
- Develop shared formats and provenance standards for exchanging verified off-policy prefixes across organizations to accelerate learning while respecting rights and privacy.
- Tools/workflows: trace schemas; licensing and de-identification pipelines; auditability features.
- Assumptions/dependencies: legal frameworks; trust and quality metrics for shared traces; mechanisms to prevent data leakage or memorization risks.
- Adaptive inference-time hinting systems for end-users (Education, Daily life)
- Generate dynamic, strategy-level hints (prefixes) at inference to boost success on hard problems without revealing full solutions; informed by learned prefix-length effects.
- Tools/workflows: hint selection policies; user-level calibration; correctness verifiers.
- Assumptions/dependencies: robust UX research to avoid over-reliance; content safety; measuring effectiveness across diverse users/tasks.
- Compute planning and sample-complexity budgeting (MLOps, Academia)
- Use theoretical insights (e.g., dependence on KL between behavior and base policy; horizon scaling) to plan rejection budgets, prefix mixtures, and training iterations for target reward levels.
- Tools/workflows: modeling tools that translate bounds into operational budgets; simulators of prefix-length distributions and expected pass@.
- Assumptions/dependencies: alignment between theoretical conditions (realizability, verifiable rewards) and practical training regimes.
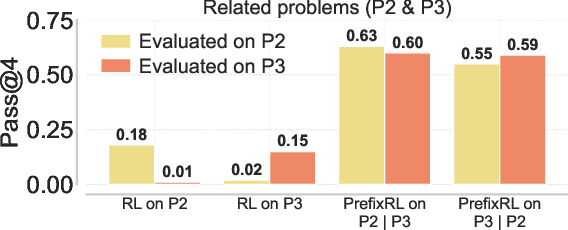
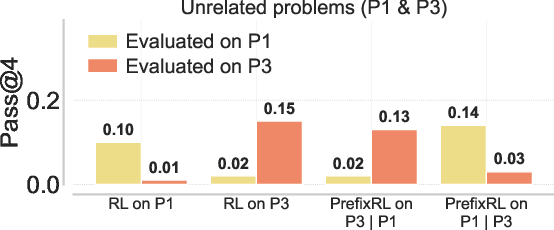
- Task-network curricula via in-context pairing (Academia, Education)
- Systematically pair related problems (P2|P3) to harness stronger back-generalization than standard transfer, scaling curricula across domains that share strategies.
- Tools/workflows: task relationship graphs; automatic pairing/selection based on strategy similarity; evaluation across no-prefix endpoints.
- Assumptions/dependencies: reliable measures of task relatedness; scalable curation; avoidance of prefix cloning rather than strategy learning.
Collections
Sign up for free to add this paper to one or more collections.