- The paper presents a hybrid system that combines rough 3D scene blocking with AI generative stylization to produce flexible video previsualization.
- It introduces variable adherence controls, allowing filmmakers to balance between strict scene fidelity and creative styling.
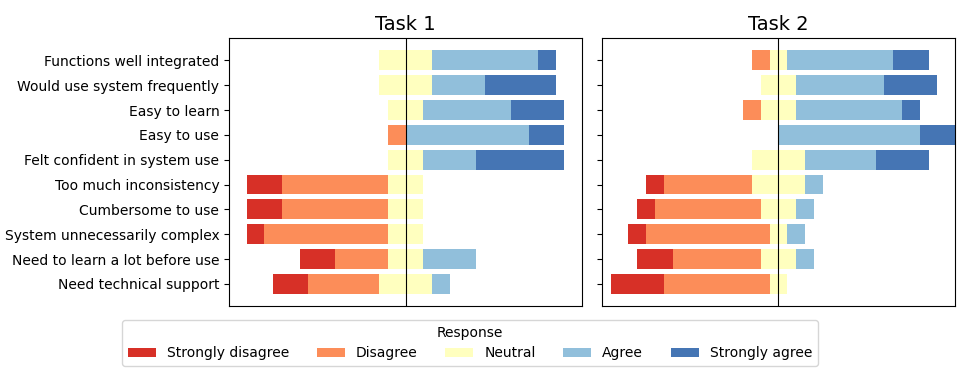
- User studies with industry professionals highlight rapid iteration, effective communication, and persistent challenges in achieving consistent control and temporal coherence.
PrevizWhiz: A Hybrid System for Generative Video Previsualization in Filmmaking
Introduction and Motivation
PrevizWhiz addresses a critical need in modern filmmaking pre-production: rapid, expressive, and controllable previsualization (previz) that does not require costly high-fidelity 3D assets or extensive technical expertise. Traditional approaches such as hand-drawn storyboards lack spatiotemporal precision for complex cinematography, while 3D previz tools are expensive and require skilled operators. At the same time, direct text-to-video/image generative models lack robust spatial grounding and control, and often cannot maintain temporal or stylistic consistency across sequences.
PrevizWhiz delivers a hybrid workflow, fusing the strengths of rough 3D scene blocking, generative stylization with variable adherence, and multimodal motion control via both keyframed animation and external 2D video. This empowers filmmakers to rapidly iterate on both compositional and aesthetic elements while flexibly controlling fidelity at each stage of previsualization, thus bridging the gap between rough exploration and polished, communicable outputs.
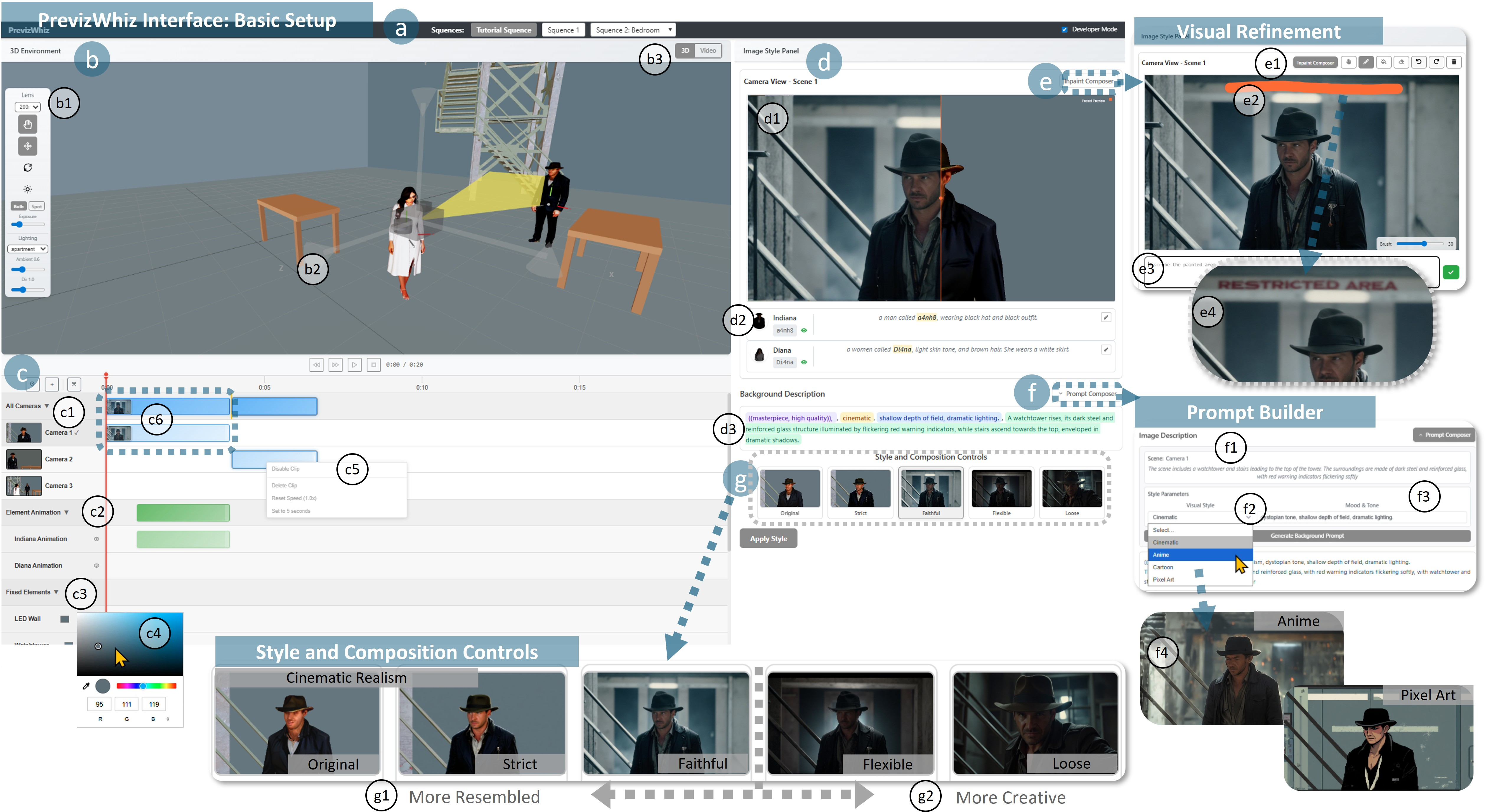
Figure 1: The PrevizWhiz interface supports scene setup, camera and element animation, style-guided image restyling, inpainting, prompt composition, and resemblance control between the 3D input and generated output.
System Architecture and Authoring Workflow
PrevizWhiz is a web-based platform that modularizes the previsualization process into three core authoring phases:
Scene Blocking and Composition: Users define spatial structure, camera, and object blocking in a lightweight 3D environment. Manipulation tools support both direct placement and keyframed animation of cameras, avatars, and environmental elements. These components create the scaffolds for subsequent generative synthesis.
Image Styling with Controlled Adherence: 3D scene outputs are restyled into 2D images or video frames using diffusion-based generative models, specifically leveraging LoRA-adapted identity and style controls. A key innovation is the explicit support for four levels of adherence ("Strict", "Faithful", "Flexible", "Loose"), informed by tunable parameters in FlowEdit and ControlNet, enabling users to balance content preservation versus generative creativity.

Figure 2: Illustration of four resemblance levels in image generation, spanning from strict scene fidelity to creative departure, across two style LoRAs.
Motion Control via Multimodal Inputs: Motion in generated previews is specified at varying granularities—from coarse paths editable within the 3D timeline to fine-grained procedural extraction from external video sources. Video remixing panels allow segmentation, recomposition, and alignment of skeletonized motion references with 3D scene layout.
Figure 3: Video Style Interface including video import, skeleton extraction, timeline-based motion remixing, and integrated resemblance–creativity controls.
This tiered structure enables iterative enhancement: directors can restyle frames to explore aesthetic options, refine motion by mixing 3D-guided blocking with nuanced gestures from reference footage, and continually adjust resemblance versus generativeness according to communication or production requirements.
Technical Implementation
PrevizWhiz's architecture integrates a React/React Three Fiber frontend with a Node.js and ComfyUI backend. Generative imaging leverages diffusion pipelines (including FlowEdit (Kulikov et al., 2024), ControlNet [zhang2023adding], and Wan/Wan-Fun Control [wan2025wan]) with LoRA augmentation for identity and style preservation.
Key technical contributions include:
- Automated region segmentation for character-centric LoRA conditioning (utilizing Florence-2 [xiao2024florence] and SAM2 [kirillov2023segment]).
- Skeleton extraction and alignment from arbitrary 2D reference video for framewise motion conditioning.
- Structured prompt templates (optionally expanded with LLMs) to enhance accessibility and reduce prompt engineering effort.
- Asynchronous, progressive video generation to facilitate iterative editing with low latency.
Figure 4: Pipeline overview showing the correspondence between user interactions (scene, style, and motion setup) and backend processing (region LoRAs, multimodal compositing, and video generation).
User Study and Empirical Results
A formative study with 10 filmmaking professionals and 3D artists was conducted to evaluate authoring efficacy, control, usability, and the creative-exploratory spectrum supported by PrevizWhiz. Tasks encompassed both single- and multi-character scenes, requiring participants to iterate on color, lighting, object/camera motion, and integrate external reference videos.
Key findings include:
Generated outputs from the study demonstrate the system's capacity to support diverse genres, lighting setups, and scene complexities (see Figure 6). Moreover, walkthroughs and case studies presented in the paper illustrate real-world creative workflows, from initial blocking through restyling and motion remixing to final video generation.
Figure 6: Examples of output images and videos produced by filmmakers during the user study, encompassing variations in prompts, style, motion guidance, color, and lighting.
Implications, Limitations, and Future Directions
Practical Implications: PrevizWhiz's hybrid approach addresses the recognized limitations of prior generative AI pipelines in filmmaking, offering finer control, fast iteration, flexible creative exploration, and a single platform to unify 3D blocking and AI stylization. The explicit, user-tunable adherence controls are particularly impactful for bridging creative and technical intents, and lowering communication barriers both within creative teams and with external stakeholders.
Industry Impact: The system was perceived as especially valuable for teams lacking high-end 3D resources, independent creators, or pitch development scenarios—lowering technical barriers while supporting professional standards in visual communication.
Challenges and Limitations: Participants identified challenges in achieving exact alignment between generative outputs and narrative/production intent, highlighting: (1) lack of robust temporal coherence in current generative models, (2) degradation of identity/style in complex or occluded scenes, (3) inconsistencies when crossing shot boundaries or changing adherence levels, and (4) latent anxieties surrounding shifts in creative labor and budget as AI automation increases.
Future Directions: To address these gaps, further research is warranted on high-fidelity object/character LoRA training, hierarchical temporally-aware diffusion models, and cross-modal feedback mechanisms to mitigate misalignment. Richer integration with industry asset pipelines, automation of detection/correction for cross-modal mismatches (e.g., mood–lighting incongruence), and transparency in creative provenance are crucial for professional adoption.
Ethical and organizational implications concerning creative authorship, job displacement, attribution, and collaborative norms in AI-augmented pipelines must also be addressed as generative systems evolve [10.1145/360(0211.36046)81].
Conclusion
PrevizWhiz represents a comprehensive step toward integrating generative AI into pre-production by combining rough 3D blocking, advanced style transfer, and variable-fidelity motion control in an accessible authoring platform. The system enables lightweight, iterative, and expressive previz suitable for contemporary filmmaking workflows, while empirical evidence reveals both new creative possibilities and persistent technical and socio-ethical challenges. PrevizWhiz's explicit adherence and control paradigms are likely to inform subsequent tool development across HCI, creative AI, and production technology research.

Figure 7: Stepwise walkthrough of the PrevizWhiz workflow: spatial blocking, motion authoring and remix, and style-driven generative synthesis.

Figure 8: Example output sequence from a "Hacker Scene", demonstrating consistent spatial blocking, dynamic lighting, and style continuity across a narrative sequence.

Figure 9: Output from an outdoor fighting scene with dynamic motion transfer from reference video, showing continuity between blocking and high-energy stylized choreography.