Likelihood-Based Reward Designs for General LLM Reasoning
Abstract: Fine-tuning LLMs on reasoning benchmarks via reinforcement learning requires a specific reward function, often binary, for each benchmark. This comes with two potential limitations: the need to design the reward, and the potentially sparse nature of binary rewards. Here, we systematically investigate rewards derived from the probability or log-probability of emitting the reference answer (or any other prompt continuation present in the data), which have the advantage of not relying on specific verifiers and being available at scale. Several recent works have advocated for the use of similar rewards (e.g., VeriFree, JEPO, RLPR, NOVER). We systematically compare variants of likelihood-based rewards with standard baselines, testing performance both on standard mathematical reasoning benchmarks, and on long-form answers where no external verifier is available. We find that using the log-probability of the reference answer as the reward for chain-of-thought (CoT) learning is the only option that performs well in all setups. This reward is also consistent with the next-token log-likelihood loss used during pretraining. In verifiable settings, log-probability rewards bring comparable or better success rates than reinforcing with standard binary rewards, and yield much better perplexity. In non-verifiable settings, they perform on par with SFT. On the other hand, methods based on probability, such as VeriFree, flatline on non-verifiable settings due to vanishing probabilities of getting the correct answer. Overall, this establishes log-probability rewards as a viable method for CoT fine-tuning, bridging the short, verifiable and long, non-verifiable answer settings.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper explores a new way to train LLMs to think step-by-step and solve problems. Instead of only rewarding the model when it gets the final answer exactly right, the authors try rewarding the model for making the correct answer more likely. They show that using “log-likelihood” (a way of measuring how confident the model is in the right answer) can work well for both math problems with clear correct answers and long, open-ended tasks like writing proofs or explanations.
What questions did the researchers ask?
The authors focus on a few simple, big questions:
- Can we train LLMs to reason better by rewarding them for increasing the probability of the correct answer, not just for being right or wrong?
- Does this “log-likelihood” reward work across different kinds of tasks: short, verifiable answers (like math) and long, non-verifiable answers (like essays or proofs)?
- How does this approach compare to common training methods, including supervised fine-tuning (SFT) and standard reinforcement learning (RL) that uses 0/1 correctness?
- What happens to the model’s “chain-of-thought” (the written reasoning steps) under these different training signals?
How did they study it?
The team tested several training strategies on two small instruction-tuned LLMs (Llama-3.2-3B-Instruct and Qwen-2.5-3B-Instruct) across four datasets:
- Verifiable (clear right/wrong answers): MATH and DeepScaleR (short numeric answers)
- Non-verifiable (many possible good answers): Alpaca and NuminaProof (long-form reasoning and proofs)
They compared:
- SFT: Train the model to directly predict the final answer without writing a chain-of-thought.
- Base RL: Reward 1 if the model’s final answer exactly matches the reference answer; otherwise 0.
- Probability rewards (VeriFree, AvgProb): Reward higher probabilities of exactly matching the reference answer.
- Log-probability rewards (Log-prob, AvgLogprob): Reward the model for raising the log-likelihood of the correct answer, which is closely related to how models are originally trained.
- JEPO: A more complex version that averages probabilities over multiple reasoning samples before taking the log.
To judge performance, they looked at:
- Success rate: How often the model gets the answer right.
- Perplexity: A standard metric that measures how well the model predicts the words in the reference answer; lower is better.
- Chain-of-thought length: How many tokens the model uses to explain its reasoning.
Key ideas explained in everyday language
- Chain-of-thought (CoT): Like “showing your work” in math class—writing the steps before the final answer.
- Log-likelihood: A math-based score of how confident the model is in the correct answer. Using the “log” makes very small probabilities more informative and stable during training.
- Verifiable vs. non-verifiable tasks: Verifiable tasks have one clear right answer (like “42”), while non-verifiable tasks (like a written proof) can have many valid answers that differ in wording.
- Greedy decoding vs. sampling: Greedy decoding always chooses the most likely next word; sampling sometimes picks less likely words to add variety.
What did they find?
Here are the main takeaways, kept simple:
- Log-probability rewards work everywhere: They perform well on both short, verifiable tasks and long, non-verifiable tasks. Other probability-based rewards fail on long answers because the chance of matching a long answer exactly is tiny.
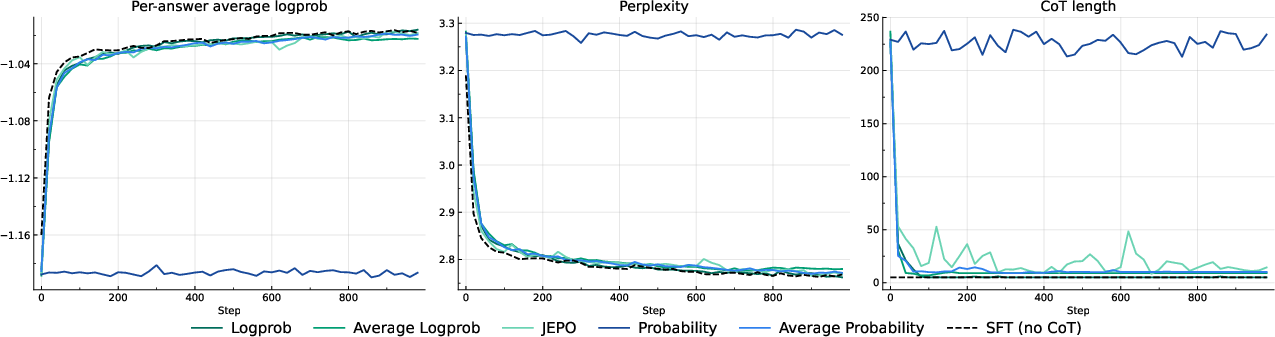
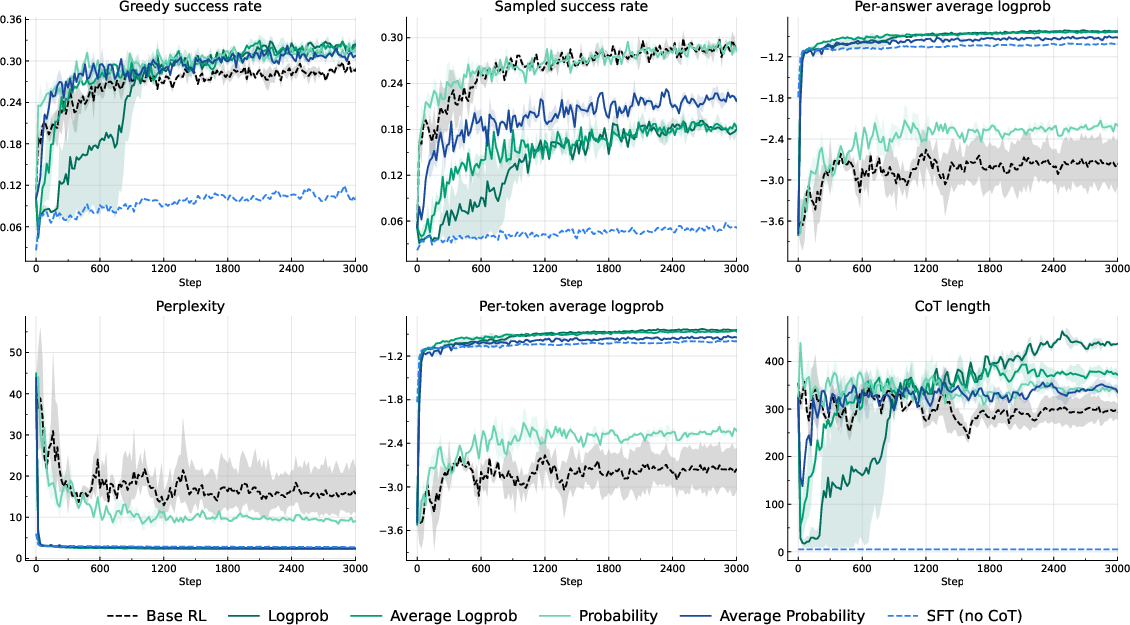
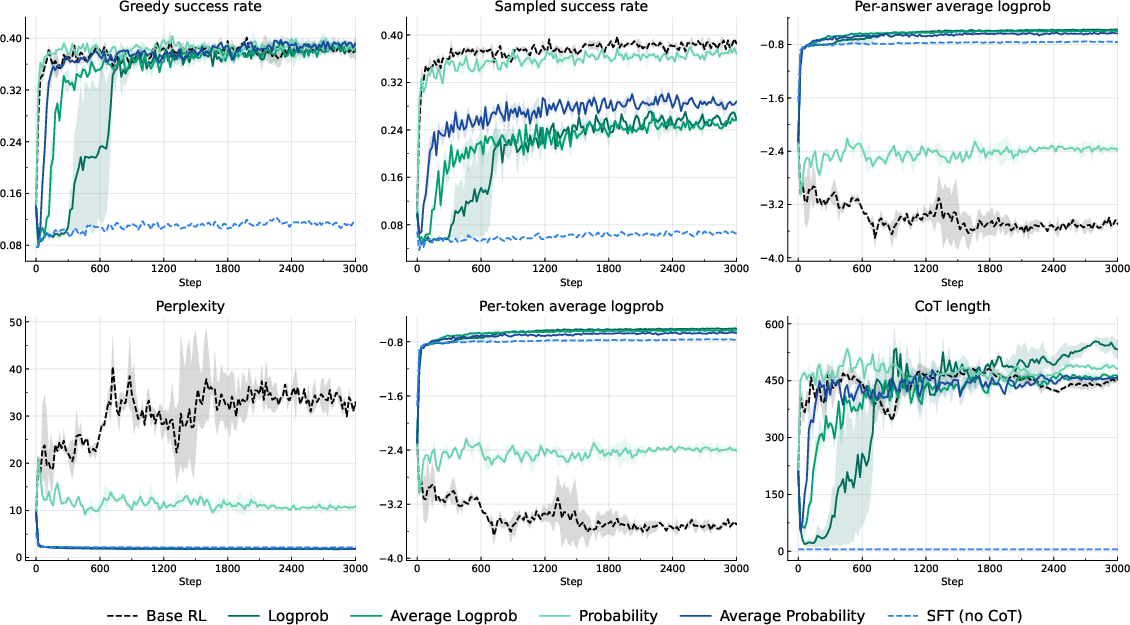
- Verifiable tasks: All probability-based methods (including log-prob) slightly beat standard 0/1 RL in success rate when using greedy decoding. But log-prob rewards stand out by also giving much better perplexity (they’re better at predicting the right words), which means they make the model’s confidence aligned with reality.
- Non-verifiable tasks: Pure probability rewards break down—rewards become near-zero, so learning stalls. Log-prob rewards remain useful and reach performance similar to SFT.
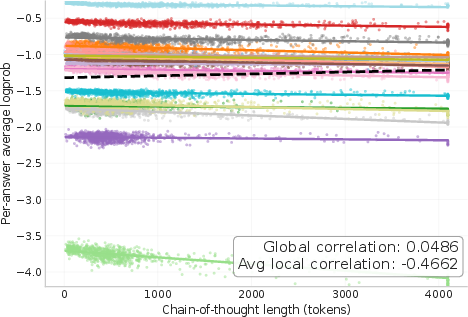
- Chain-of-thought behavior: With log-prob rewards, the model’s explanations initially get shorter. In math tasks, they later grow back to a healthy length. In long-form tasks, they stay short, and training ends up behaving like SFT (the model mostly skips writing out a detailed chain-of-thought). Attempts to force longer CoTs (by penalties or constraints) reduced performance.
Why this matters: Log-probability rewards hit a sweet spot—good success, good perplexity, and they work whether or not you can verify an answer. Other methods either don’t generalize or distort the model’s confidence.
Why does this matter?
This research suggests a simple, practical recipe for training LLMs to reason:
- Use log-probability-based rewards. They connect naturally to how models are originally trained and avoid problems that show up with exact-match rewards, especially for long answers.
- This approach can be applied to many datasets where you have a reference answer but not an easy automatic checker.
- It gives more “dense” feedback than 0/1 correctness, helping models learn even when exact matches are rare.
Potential impact
- More unified training: One reward type that bridges both math-style answers and long-form reasoning or explanations.
- Better calibration: Models become less “confidently wrong,” because log-prob rewards encourage spreading some probability across plausible answers.
- Practical efficiency: You don’t need to sample and check many answers; you can compute the reward from the reference answer directly, which can save compute.
A note on chain-of-thought length
A surprising result is that log-prob rewards push the model to shorten its written reasoning, especially in long-form tasks. While this can make training behave more like SFT, it also hints that for long answers, the model may be doing more “thinking” internally and doesn’t need to write it all out to do well. For short answers (like math), written chain-of-thought may still be helpful after more training.
In short: Rewarding models for increasing the likelihood of correct answers—using log-likelihood—looks like a simple, reliable way to train reasoning across many kinds of tasks.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of unresolved issues, open questions, and limitations that, if addressed, could make the paper’s findings more robust and broadly applicable.
- Limited model scale and domain coverage: results are only reported on 3B instruction-tuned models (Llama-3.2-3B, Qwen-2.5-3B) across math and two long-form datasets; test whether conclusions hold for larger models (e.g., 7B–70B), code generation, factual QA, summarization, and other reasoning-heavy domains.
- Lack of quantitative compute and efficiency analysis: the paper claims probability/log-prob rewards offer computational advantages (e.g., “no need to sample an answer”) but does not quantify wall-clock time, throughput, memory, gradient variance, or sample efficiency relative to base RL across group sizes.
- Decoding strategy sensitivity is underexplored: log-prob rewards underperform under T=1 sampling but perform well with greedy decoding; systematically evaluate temperature schedules, top-k/top-p/nucleus sampling, and decoding alignment between training and inference.
- JEPO trade-offs not fully characterized: JEPO is only evaluated with group size G=4 due to implementation complexity; develop efficient implementations for larger G, and map the compute/performance frontier to identify the minimal budget at which JEPO or multi-sample log-prob rewards surpass SFT on long-form tasks.
- Mechanism behind CoT collapse remains unresolved: log-prob rewards cause CoT length to collapse in non-verifiable settings; design controlled experiments to disentangle credit-assignment effects from hidden (latent) reasoning (e.g., length-graded datasets, probing internal activations, interventions that manipulate answer length and reasoning demands).
- Preserving CoT without harming performance: length penalties and stronger KL regularization prevented CoT collapse but reduced metrics; explore alternative regularizers and training recipes (e.g., step-level rewards, curriculum schedules, entropy bonuses targeted at CoT, dual-objective formulations) that maintain CoT while improving success/perplexity.
- Reward robustness to multiple valid answers and noisy references: log-prob rewards hinge on a single reference answer and exact phrasing; evaluate semantic-equivalence-aware rewards (e.g., entailment, edit-based, embedding similarity) and quantify sensitivity to noisy, ambiguous, or multi-reference labels.
- Evaluation metrics are narrow: success rate and perplexity are tracked, but human quality judgments, calibration (e.g., ECE), pass@k, diversity, robustness, and reasoning faithfulness are not assessed; incorporate richer metrics to capture reasoning quality and model calibration.
- Non-verifiable improvements beyond SFT are not demonstrated: log-prob rewards match SFT on long-form tasks under moderate compute; identify datasets, training schedules, or reward variants that yield measurable improvements over SFT without requiring an order-of-magnitude more compute.
- Bias from Monte Carlo estimation of log-probabilities: logprob-MC estimates are known lower bounds due to Jensen’s inequality; investigate improved estimators (e.g., multi-sample importance sampling, control variates) and quantify the impact of estimator bias on both training dynamics and evaluation.
- Hyperparameter sensitivity is limited: systematic sweeps over learning rate, batch size, KL coefficients, group size, advantage baselines, and reward scaling are missing; map stable regions and interactions for each reward type to understand when methods succeed or fail.
- Generalization and side effects are unknown: assess whether log-prob reward training affects non-reasoning capabilities, out-of-distribution generalization, catastrophic forgetting, or hallucination rates on unrelated tasks.
- Absence of step-level or intermediate verification signals: rewards depend only on final answer likelihood; investigate whether combining log-prob with step-wise rewards or verifiers (where available) improves reasoning quality and prevents CoT collapse.
- No experiments mixing verifiable and non-verifiable data in this study: prior work suggests benefits from mixed training; evaluate joint training to see whether it changes CoT dynamics and improves long-form performance under realistic budgets.
- Formatting/style bias in log-prob rewards: optimizing the exact likelihood of a single reference answer may overfit to formatting or stylistic quirks; quantify formatting sensitivity and evaluate canonicalization/normalization strategies for reference answers.
- Training–inference mismatch: training optimizes log-prob-based rewards and evaluates greedy success, yet sampling harms performance; explore reward shaping and training objectives aligned to intended inference-time decoding strategies.
- Scaling laws for CoT dynamics: CoT collapse was observed in 3B models; test whether larger models naturally maintain CoT under log-prob rewards and derive scaling laws relating model size, CoT length, and performance.
- Practical throughput vs baseline RL: although answer sampling is avoided, full answer log-prob computation is still required; benchmark end-to-end training throughput and latency against base RL (RLOO/GRPO/PPO) across datasets and group sizes.
- Dependency on reference answers limits “universality”: even in non-verifiable domains, the approach requires reference continuations; explore extensions using learned judges, weak labels, or pseudo-references that retain log-prob advantages without exact answers.
- Algorithmic baselines are narrow: base RL uses RLOO; compare against PPO/GRPO variants and alternative advantage estimators to determine whether conclusions are robust to the choice of RL algorithm.
Glossary
- Average log-probability (AvgLogprob): A reward that rescales the log-likelihood of the reference answer by its length, yielding a per-token average to balance samples of different lengths. "Average log-prob (AvgLogprob)"
- Average probability (AvgProb): A reward equal to the average per-token probabilities of the reference answer over its tokens. "Average prob (AvgProb)"
- Chain-of-Thought (CoT): A prompting/training strategy where models generate intermediate reasoning steps before the final answer. "chain-of-thought (CoT) prompting, where models articulate intermediate reasoning steps before producing a final answer"
- Credit-assignment problem: The RL difficulty of attributing outcomes to specific actions in long sequences, making optimization noisier for longer CoTs. "because of the well-known ``credit-assignment problem''."
- Diversity collapse: A failure mode where outputs become less varied due to certain reward designs or alignment strategies. "and tend to lead to reward hacking or diversity collapse."
- ELBO: The Evidence Lower Bound, a variational objective used to approximate log-likelihood via tractable bounds. "Jensen-based ELBO loss with log-probs."
- Generation–verification gap: The mismatch between generating solutions and verifying their correctness, impacting self-improvement. "formalizes the generationâverification gap and shows self-improvement hinges on sufficient coverage and verifier quality"
- GRPO: Group Relative Policy Optimization; an RL training variant using group-based baselines. "this is an unbiased version of GRPO"
- Group-level reward: A reward defined over multiple sampled CoTs jointly to better approximate aggregate success signals. "they introduce a group-level reward based on samples for a given prompt,"
- Hidden chain-of-thought (hidden CoT): Implicit internal reasoning without explicitly printed rationales. "a hidden CoT within its internal layers."
- Inference-time alignment: Aligning model behavior using rewards during inference instead of (or in addition to) training. "proves that inference-time alignment with imperfect reward models suffers reward hacking"
- Intrinsic rewards: Rewards derived from the model’s own signals (e.g., confidence, entropy, diversity) without ground-truth labels. "intrinsic rewards that do not require ground-truth"
- JEPO: A training method that uses a Jensen-based ELBO objective and group rewards for CoT optimization. "JEPO \citep{tang2025beyond} used a refined version of the group reward in GRPO and RLOO"
- Jensen-based ELBO: An ELBO construction leveraging Jensen’s inequality to aggregate probabilities/log-probabilities across samples. "Jensen-based ELBO loss"
- KL divergence regularization term: A penalty encouraging the fine-tuned policy to remain close to the base model distribution during RL. "we include a KL divergence regularization term as proposed by ~\citet{guo2025deepseek} with a coefficient of 0.001."
- KL penalties: Regularization terms that constrain divergence from a reference policy; can preserve CoT length but may degrade metrics. "KL penalties maintain CoT but hurt performance."
- Leave-one-out advantage estimation (RLOO): An unbiased advantage estimator subtracting the mean reward computed without the current sample. "we employ a leave-one-out advantage estimation (RLOO)."
- Log-loss: The negative log-likelihood objective used in LLM pretraining; here repurposed as a reward. "a reward similar to the log-loss used during pretraining"
- Log-likelihood rewards (log-probability rewards): RL rewards based on the log-probability of the reference answer given the prompt and CoT. "We call this setting log-prob rewards."
- Log-mean-exp: The logarithm of the mean of exponentials; a smooth aggregation of probabilities used in group rewards. "the reward is the log-mean-exp of rewards in the minibatch."
- logprob-MC32: A Monte Carlo estimator of log-probabilities using 32 samples to reduce bias/variance in evaluation. "logprob-MC32"
- LLM-as-a-judge (RLAIF): Using a LLM to provide synthetic preference/reward signals for RL-based post-training. "LLM-as-a-judge synthetic rewards in RL-based post-training (RLAIF)"
- Monte Carlo estimate: Approximating expectations by sampling to estimate quantities like success probabilities or log-likelihoods. "A simple solution is to estimate the average via Monte Carlo using samples"
- Non-verifiable domains: Tasks lacking objective correctness signals (e.g., long-form proofs, open-ended generation). "non-verifiable domains like long-form proofs or open-ended generation."
- NOVER: A probability-based reward variant using the geometric mean of per-token perplexities. "{\em NOVER} \citep{liu2025noverincentivetraininglanguage} is a variant of probability-based rewards, using a geometric mean of per-token perplexities."
- Pass@k rate: A coverage metric indicating the probability that at least one of k samples is correct. "performance is bounded by model coverage (i.e. its pass@k rate)."
- Per-answer log-probabilities: Log-likelihood aggregated per answer and averaged across the dataset as an evaluation metric. "Per-answer log-probabilities averages across each answer, then averages over the dataset:"
- Perplexity: The exponential of the negative average log-likelihood; lower values indicate better predictive calibration. "We also report perplexity, which is just the exponential of minus per-answer log-probabilities."
- Probability (VeriFree): A reward equal to the probability of exactly matching the reference answer (without taking logs). "Probability (VeriFree): As mentioned above, the reward is"
- Reinforce algorithm: A score-function gradient estimator used in policy optimization for RL. "variants of the basic Reinforce algorithms, such as RLOO \citep{ahmadian2024back}, GRPO \citep{guo2025deepseek}, or PPO \citep{schulman2017}."
- Reinforcement-pretraining: Training from scratch with inserted CoTs and local rewards for correct continuations. "{\em Reinforcement-pretraining} \citep{dong2025reinforcementpretraining} performs small-scale {\em pretraining} from scratch, inserting CoTs at specific points and rewarding for correct continuation over a few tokens."
- Reward hacking: Exploiting weaknesses in a reward model to achieve high reward without genuine capability gains. "proves that inference-time alignment with imperfect reward models suffers reward hacking"
- RLPR: A method using the average probability of the ground-truth answer as the reward in non-verifiable settings. "{\em RLPR} \citep{yu2025rlpr} uses average probability of the ground truth for non-verifiable domains."
- SFT (supervised fine-tuning): Training with next-token cross-entropy on reference answers, typically without generating a CoT. "SFT: standard fine-tuning with the next-token cross-entropy loss."
- Softmax temperature T=1: Sampling with temperature 1 from the softmax distribution during decoding/evaluation. "T=1 sampling success from the softmax probabilities at temperature ."
- Verifiable domains: Tasks with objective correctness signals (e.g., math problems, code execution). "verifiable domains such as mathematics and programming"
- VR-CLI: A reward formulation enabling learning of reasoning from unlabeled book data in the LongForm setup. "{\em LongForm} \citep{gurung2025learning} designs a clever reward function (VR-CLI) that allows them to use an unlabeled book dataset as a learning signal for reasoning."
- Warm-start model: An initialization obtained by SFT on answers (with CoT present but masked) before RL fine-tuning. "we produced a ``warm-start'' model by SFT-ing on the answers in the presence of CoTs"
Practical Applications
Immediate Applications
The paper’s results support several actionable uses that can be deployed with current LLM training stacks and datasets containing reference answers (even without verifiers). Below are concise applications, each with suggested sectors, workflows, and feasibility notes.
- Log-probability–based post-training for enterprise QA assistants — sectors: software, finance, legal, healthcare, customer support
- What: Replace 0/1 correctness RL or “probability of exact match” rewards with log-probability rewards over reference answers to improve reasoning success while maintaining better calibration/perplexity.
- How: Integrate a “LogProb-RLFT” stage in existing RLHF/RLAIF pipelines using RLOO/GRPO; compute rewards from per-answer log-likelihood without sampling answers.
- Tools/workflows: Add a reward module computing per-answer/per-token logprobs; monitor per-answer perplexity and logprob-MC metrics; default to greedy decoding for reasoning tasks.
- Dependencies/assumptions: Availability of reference answers; data licensing; stable RL training infra; greedy decoding adoption; alignment with domain-specific formatting of CoT and answers.
- Training on non-verifiable long-form datasets (no external verifier needed) — sectors: education (tutoring/explanations), enterprise knowledge bases, policy/compliance Q&A
- What: Use log-probability rewards to train on long-form answers (e.g., manuals, policy docs, textbooks) where binary correctness is unavailable.
- How: Fine-tune with log-prob rewards on long-form QA pairs; accept that CoT often shortens/collapses and performance matches strong SFT.
- Tools/workflows: “Verifier-free RL” step; dataset preparation ensuring consistent reference answers; masked-CoT warm starts optional.
- Dependencies/assumptions: Reference answers must be high quality and representative; expectations set that gains typically match SFT at current compute scales.
- Calibration-first reasoning models — sectors: healthcare, finance, legal, safety-critical support
- What: Prefer log-prob rewards to avoid overconfident wrong answers (low perplexity) while preserving greedy success rates on verifiable tasks.
- How: Train with log-prob rewards; gate deployment on perplexity thresholds; expose confidence summaries to downstream guardrails.
- Tools/workflows: Perplexity dashboards; confidence-aware routing and abstention policies; regression tests using logprob-MC metrics.
- Dependencies/assumptions: Calibrated decoding policies (greedy preferred); well-curated reference data; clear UX for conveying confidence.
- Cost- and simplicity-focused RL training — sectors: software (platform teams), model providers
- What: Reduce training variance and cost by eliminating the need to sample answers when computing rewards.
- How: Compute reward from log π(a* | p, z) directly; keep RLOO/GRPO structure; smaller group sizes feasible.
- Tools/workflows: Reward computation modules that run a single forward pass over the reference answer; simplified evaluation harnesses.
- Dependencies/assumptions: Efficient batching for reward computation; balanced group size G to control variance.
- Math and coding reasoning boosters for small models — sectors: education, programming assistants
- What: On short-answer/verifiable domains, log-prob rewards slightly outperform base RL on greedy success and strongly improve perplexity.
- How: Fine-tune small instruct models (e.g., 3B) on verifiable sets (MATH, unit-testable code) using log-prob rewards.
- Tools/workflows: Greedy decoding; unit-test harness (for code) remains useful but not required for reward.
- Dependencies/assumptions: Access to verifiable datasets or high-quality references; consistent answer formatting.
- CoT-aware product behavior: concise reasoning by default for long-form tasks — sectors: education, consumer assistants
- What: Accept and leverage CoT shortening observed under log-prob rewards on non-verifiable tasks; present concise answers unless users request full reasoning.
- How: Deploy “adaptive CoT length” UX toggles; train with log-prob rewards and measure CoT length.
- Tools/workflows: CoT-length telemetry; user-facing “show steps” switch; prompt templates minimizing unnecessary CoT.
- Dependencies/assumptions: Product acceptance of concise-by-default answers; clear user control for transparency needs.
- Safer adoption guidance for probability-only rewards — sectors: research, platform teams
- What: Use VeriFree/AvgProb only on short, high-probability, verifiable answers; avoid them on long-form tasks due to vanishing reward.
- How: Policy rule in training orchestration: select reward function by task length/verification status.
- Tools/workflows: Task router based on answer length or exact-match feasibility.
- Dependencies/assumptions: Reliable detection of task regime (verifiable vs. non-verifiable); consistent tokenization/length thresholds.
- Evaluation upgrades for post-training — sectors: industry labs, academia
- What: Track per-answer logprob and perplexity (and MC estimates) alongside accuracy; prefer greedy success rates for fair comparison of log-prob rewards.
- How: Extend eval suites to include logprob-MC1/MC32; report both greedy and T=1 sampling success.
- Tools/workflows: Evaluation scripts; model cards documenting calibration outcomes.
- Dependencies/assumptions: Compute for MC estimates; consistent decoding policies across models.
- Domain-tuned compliance assistants — sectors: finance, legal, HR/policy
- What: Train on internal policy manuals using log-prob rewards to improve adherence and calibration without needing a verifier.
- How: Construct QA pairs with reference excerpts; fine-tune models to predict answers conditioned on prompt and optional short rationales.
- Tools/workflows: Internal dataset curation; retrieval-augmented prompting to surface reference answers during training/inference.
- Dependencies/assumptions: Up-to-date, authoritative references; data governance and access controls.
- Education: targeted math tutoring with calibrated hints — sector: education
- What: Provide accurate, confidence-calibrated hints and solutions; keep answers deterministic for reliable grading.
- How: Log-prob reward training on curated math QA; greedy decoding; optional step reveal on demand.
- Tools/workflows: Hint-tiering driven by confidence; teacher dashboards on perplexity trends.
- Dependencies/assumptions: High-quality problem sets and canonical answers; robust formatting of solutions.
Long-Term Applications
The following opportunities likely require further research, scaling, or engineering (e.g., larger batch sizes, extended training, or new datasets/algorithms).
- Surpassing SFT on long-form reasoning with efficient log-prob–based RL — sectors: education, legal, scientific writing
- What: Achieve gains beyond SFT on non-verifiable tasks by stabilizing and extending CoT without hurting performance.
- Path: Combine log-prob rewards with JEPO-like group rewards, curriculum schedules, larger G, longer training, and improved credit assignment.
- Dependencies/assumptions: More compute; better optimization (e.g., lower LR, larger batch); robust variance reduction.
- Adaptive CoT controllers that optimize performance–interpretability trade-offs — sectors: regulated industries, education
- What: Dynamically adjust CoT length per task/user needs while preserving or improving accuracy and calibration.
- Path: Train policies that condition CoT length on intermediate signals; learn cost-aware policies that trade off CoT tokens vs. score.
- Dependencies/assumptions: Reliable proxies for utility/cost; user studies; RL with structured constraints.
- Latent-reasoning–aware training that aligns hidden and explicit CoT — sectors: safety, transparency, compliance
- What: Detect and leverage latent internal reasoning for long answers; surface interpretable steps without reducing performance.
- Path: Joint training with probes/auxiliary losses; datasets that interpolate answer lengths to study transitions.
- Dependencies/assumptions: Reliable latent signal extraction; privacy-preserving logging.
- Standardization of calibration metrics and procurement guidelines — sectors: policy, public sector, healthcare
- What: Policy frameworks that require reporting per-answer perplexity/logprob metrics and decoding policy for deployment approvals.
- Path: Draft standards bodies’ guidelines; shared benchmarks for calibration in long-form domains.
- Dependencies/assumptions: Consensus on metrics; sector-specific risk thresholds.
- Retrieval-grounded log-prob RL for knowledge-intensive domains — sectors: healthcare (guidelines), legal (statutes), finance (policies)
- What: Condition training and rewards on retrieved references to improve factual adherence.
- Path: Compute log-prob rewards against gold, citation-bearing answers; train RAG+RL stacks.
- Dependencies/assumptions: High-quality retrieval; deduplication and citation alignment; document drift monitoring.
- Efficient JEPO-style training at larger group sizes — sectors: model providers, research labs
- What: Implement scalable log-mean-exp group rewards that outperform simple log-prob in some regimes.
- Path: Memory- and compute-efficient implementations; microbatching; variance analysis.
- Dependencies/assumptions: Engineering effort; GPU memory; strong infra.
- Auto-curricula that grow answer length without CoT collapse — sectors: education, scientific reasoning
- What: Start with short, verifiable tasks and curriculum-learn into long-form proofs/explanations while retaining gains.
- Path: Length- and difficulty-scheduled datasets; staged reward shaping; gradual KL/length regularization.
- Dependencies/assumptions: Carefully designed curricula; monitoring for regressions.
- Small, on-device models with robust calibration for personal assistants — sectors: consumer devices
- What: Deliver assistant features with strong confidence calibration and reasonable reasoning on-device.
- Path: Apply log-prob RL to compact models; quantization-friendly training; greedy decoding with fallback to server.
- Dependencies/assumptions: Edge compute limits; model compression; privacy constraints.
- Safety guardrails using calibration-aware routing and abstention — sectors: healthcare, finance, legal
- What: Use perplexity/logprob as signals for abstain/route-to-human decisions.
- Path: Integrate threshold-based policies; train abstention heads aligned with logprob.
- Dependencies/assumptions: Calibrated thresholds; auditability; human-in-the-loop capacity.
- Cross-domain “reference-first” dataset tooling — sectors: data platforms, academia
- What: Tooling to transform heterogeneous corpora into QA-with-reference formats usable by log-prob RL.
- Path: Semi-automated annotation; templating for canonical answers; quality assurance pipelines.
- Dependencies/assumptions: Annotation budget; IP clearance; domain expert oversight.
Notes on general assumptions and dependencies across applications:
- Reference answers are necessary; quality and consistency strongly affect outcomes.
- Greedy decoding is generally preferable for evaluating and deploying models trained with log-prob rewards.
- Probability-only rewards (without log) can fail on long-form tasks due to vanishing probabilities.
- On non-verifiable tasks, current compute regimes often match SFT rather than exceed it; surpassing SFT typically needs more compute and/or algorithmic advances.
- KL and explicit CoT-length regularizers can preserve CoT length but may hurt performance; use judiciously based on product needs (interpretability vs. accuracy).
- Data licensing, privacy, and governance must be respected when using internal reference materials.
Collections
Sign up for free to add this paper to one or more collections.