- The paper introduces a novel multi-agent RL system that employs a lead-agent/subagent architecture to decompose broad queries into parallel subtasks.
- The paper demonstrates that width scaling via MARL achieves competitive performance (40.0% item F1) with ~170× fewer parameters than traditional depth scaling models.
- The paper presents an automated 20k-instance dataset for breadth-oriented tasks, validating the approach on both specialized benchmarks and general QA problems.
Introduction
WideSeek-R1 introduces a paradigm shift in LLM scaling, leveraging width scaling—parallelization via multi-agent systems—as a complement to the well-established depth scaling (multi-turn sequential reasoning in a single agent). Rather than augmenting LLM capabilities by increasing context length and turn count, this work exploits organizational capacity through MARL-based orchestration and execution, structured around a lead-agent/subagent topology. The system is evaluated on broad information-seeking tasks requiring the aggregation of disparate facts into structured outputs, a scenario where breadth rather than reasoning depth becomes the performance bottleneck.
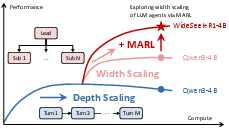
Figure 1: Comparison of depth and width scaling. Depth scaling bolsters sequential, multi-turn reasoning, while width scaling uses multi-agent parallelism; WideSeek-R1 advances width scaling via MARL for parallel orchestration and execution.
WideSeek-R1 embodies a hierarchical multi-agent architecture instantiated over a shared LLM. The lead agent is exclusively responsible for decomposing broad queries into independent, parallelizable subtasks and delegates them by invoking specialized subagents through a constrained interface. Subagents, operating under isolated contexts to prevent cross-contamination, use a limited set of external tools (search and access) to retrieve and synthesize evidence before returning results for further aggregation.
Key MARL innovations address the credit assignment and optimization bottlenecks posed by this paradigm:
- Group-Level Advantage Normalization: All agents within a single rollout share a normalized advantage across multi-agent groups, aligning incentives solely to verifiable, group-level rewards tied to the final output’s quality.
- Dual-Level Advantage Reweighting: Averaging at both token and agent granularity mitigates domination by longer trajectories or agent proliferation, pivotal for stable MARL in a variable-width setting.
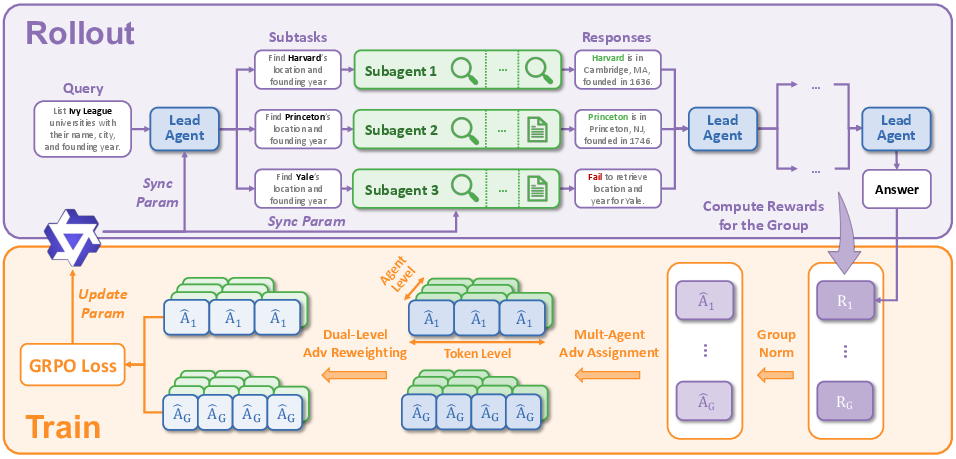
Figure 2: WideSeek-R1 rollout and training pipeline. (1) Rollout: The lead agent coordinates decomposition while subagents execute subtasks in parallel. (2) Training: Group-level advantage normalization and dual-level advantage reweighting are applied to the GRPO objective for effective multi-agent, multi-turn RL.
Automated Dataset Construction
Recognizing the deficit in existing QA datasets for breadth-oriented, schema-constrained tasks, the authors devise an automated data pipeline producing 20,000 high-quality broad information-seeking instances. Each instance aligns user intent, complex table schema requirements, and ground truth, with rigorous filtering via redundancy-based self-consistency and complexity constraints.
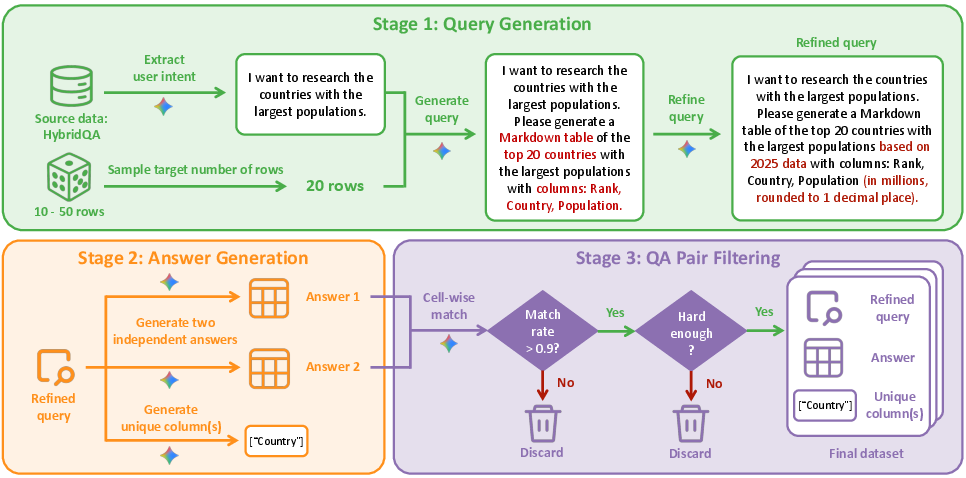
Figure 3: Automated data construction pipeline: (1) query extraction and schema synthesis; (2) answer generation and unique column identification; (3) robust filtering for consistency and complexity.
Experimental Results
On the WideSearch benchmark, WideSeek-R1-4B achieves a strong 40.0% item F1—on par with DeepSeek-R1-671B (41.3%), but using ~170× fewer parameters, underscoring the effectiveness of width scaling with compact LLMs. Notably, multi-agent WideSeek-R1 substantially exceeds its own single-agent variant (by 11.9% in item F1), and also outperforms a range of multi-agent competitive baselines, including OWL-8B and MiroFlow-8B.
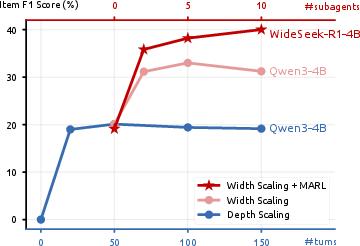
Figure 4: Depth (turns) versus width (subagents) scaling: depth scaling saturates quickly, while width scaling—when optimized via MARL in WideSeek-R1—yields consistent additive gains as subagent count increases, surpassing base model at all scales.
The width scaling property is uniquely unlocked by MARL-based end-to-end optimization: naively increasing subagents in an untrained multi-agent system leads to performance degradation due to uncoordinated aggregation, but WideSeek-R1 exhibits monotonic improvement with increasing parallelism.
Ablation Studies
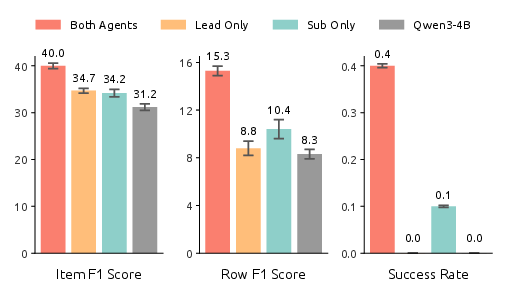
Figure 5: Ablation on lead agent and subagent roles with different model assignments: peak performance is realized only when both roles are jointly optimized with the WideSeek-R1-4B backbone.
Ablations confirm that both lead agent orchestration and subagent execution capabilities must be optimized jointly for maximal performance. Subagent improvements are particularly critical for metrics enforcing strict row and table accuracy. Data ablations reveal complementary synergy: models trained on the hybrid of broad (width-oriented) and deep (multi-hop, single-agent) data surpass those trained on either dataset exclusively.
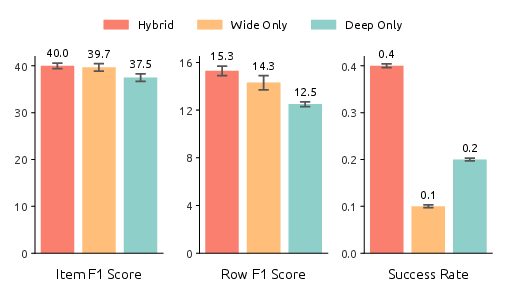
Figure 6: Ablation of training data: hybrid (wide+deep) training set yields best outcome on all granular metrics, illustrating necessity of diverse data for both orchestration and subtask proficiency.
Transfer to General QA Benchmarks
WideSeek-R1-4B delivers robust generalization: on a suite of single-hop and multi-hop QA benchmarks, it averages 59.0%—surpassing baseline 4B/8B models and closely matching larger agents in both single and multi-agent configurations. This evidences that width scaling via MARL does not compromise general reasoning, and supports practical deployment for both broad and standard QA scenarios.
Practical and Theoretical Implications
WideSeek-R1 demonstrates that organizational intelligence—structured, multi-agent policies optimized by MARL—enables small models to match or exceed giants on tasks requiring breadth and aggregation. By demonstrating consistent width scaling gains, the work challenges the paradigm of ever-larger monolithic LLMs and instead advances efficient, parallel architectures with verifiable, explicit coordination. The open-sourcing of the generated 20k-instance dataset enables reproducibility and accelerates further multi-agent RL research.
From a deployment perspective, the dramatic reduction in parameter count for comparable performance democratizes access to high-performance agentic systems, allowing wide adoption in resource-constrained settings. The authors also acknowledge potential misuse risks of scalable swarms for data extraction or misinformation, highlighting the need for responsible safety strategies.
Future Prospects
This work establishes the groundwork for RL-driven, scalable multi-agent LLM organizations capable of parallel, large-scale information synthesis. Key research vectors include hierarchical or recursive multi-agent orchestration, more granular credit assignment, and asynchronous/asymmetric MARL for greater scalability and real-world efficiency. Additionally, further explorations in hybrid wide+deep architectures and organization-autonomy for emergent task decomposition are warranted to elevate both breadth and depth in future AI systems.
Conclusion
WideSeek-R1 validates that width scaling, enabled via explicit MARL optimization across lead and subagent policies, constitutes a competitive, scalable alternative to depth-only LLM scaling for broad information-seeking tasks. This work demonstrates that compact, parallel agents—when properly coordinated—can rival the capabilities of massive single-agent models on complex, structured benchmarks, with broad implications for scalable, accessible, and efficient AI systems.