- The paper introduces an adaptive multi-agent framework combining a novel M500 dataset with a dynamic CEO agent for effective test-time scaling.
- The methodology leverages supervised fine-tuning to enhance long chain-of-thought reasoning, achieving up to 41% performance improvements on tasks like AIME2024.
- The study highlights optimal token usage and agent interactions, offering actionable insights for scalable and efficient multi-agent collaborative reasoning.
Test-time Scaling of Multi-agent Collaborative Reasoning
Introduction
The research paper entitled "Two Heads are Better Than One: Test-time Scaling of Multi-agent Collaborative Reasoning" explores an innovative approach to optimize collaborative reasoning in multi-agent systems (MAS) leveraging LLMs. The central problem addressed is the difficulty of scaling collaborative reasoning capabilities effectively within MAS, a challenge that persists despite advancements in test-time scaling (TTS) techniques for single-agent systems.
Methodology
The paper introduces an adaptive multi-agent framework designed to enhance LLM collaborative reasoning via a novel dataset and a dynamic coordination agent. The authors constructed the M500 dataset comprising 500 multi-agent collaborative reasoning traces. This dataset empowers the fine-tuning of Qwen2.5-32B-Instruct, resulting in the M1-32B model optimized for MAS integration. Core contributions include:
- Data Generation Pipeline: A process to construct high-quality collaborative reasoning data. Key attributes of the questions sampled include difficulty, diversity, and interdisciplinarity. The MAS generates comprehensive reasoning traces that document the entire problem-solving process (Figure 1).
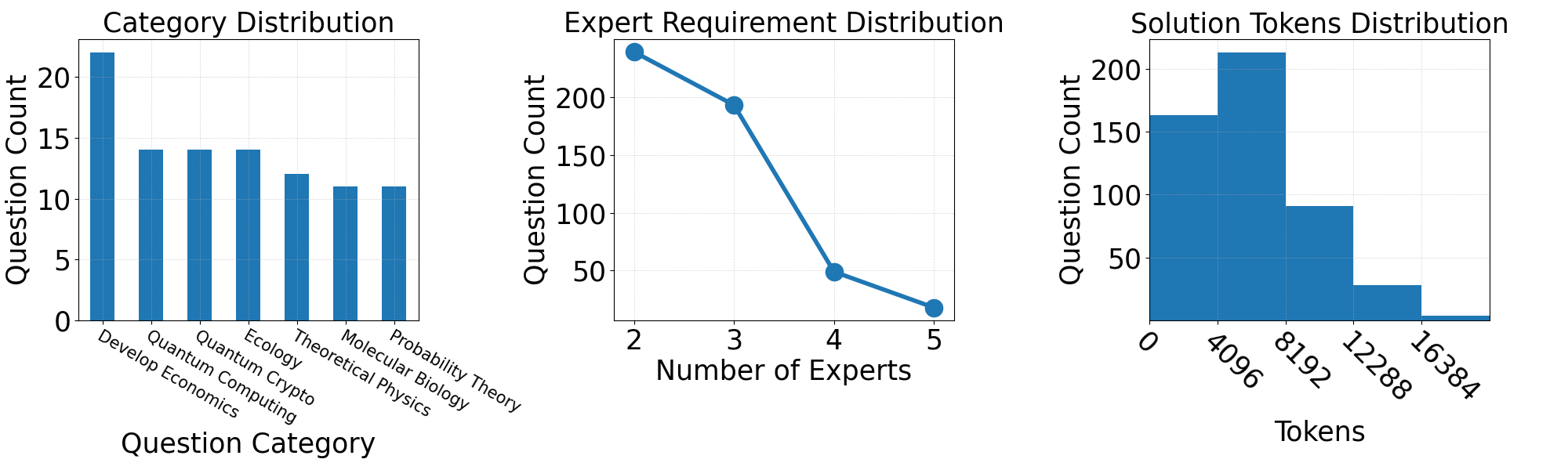
Figure 1: Distributions of key statistics in M500: question category (filtered with count >10), predicted number of experts required for solving each problem, and solution token usage.
- Supervised Fine-Tuning (SFT): SFT enhances long chain-of-thought (CoT) reasoning capabilities in LLMs, leveraging the M500 dataset to improve multi-agent collaboration.
- CEO Agent for Adaptive TTS: Introduction of a "CEO" agent, which dynamically manages inter-agent discussions and resource allocations to optimize problem-solving depth and collaboration efficiency (Figure 2).
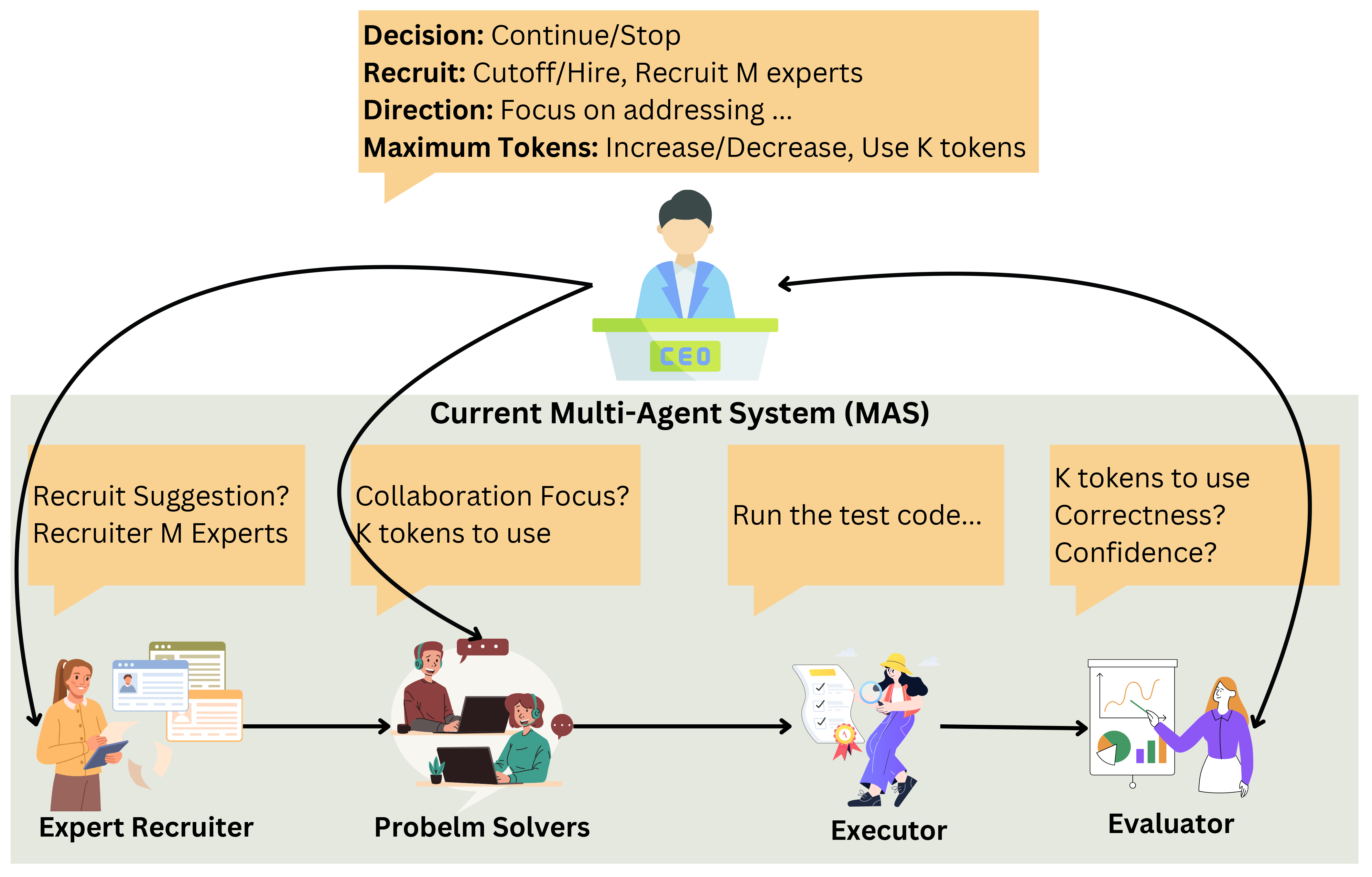
Figure 2: Overview of integrating the CEO agent into an existing MAS, using AgentVerse.
Experimental Validation
The researchers conducted extensive experiments to validate their approach. The results demonstrated that the M1-32B model substantially outperformed baseline models like Qwen2.5-32B-Instruct and even matched the performance of SOTA models such as DeepSeek-R1 on several tasks, achieving improvements of up to 41% on AIME2024 and 10% on MBPP-Sanitized. The inclusion of a CEO agent further enhanced system performance by dynamically scaling the reasoning process.
Impact of Scaling and Task-Specific Optimizations
Experiments highlighted the effect of collaboration scaling on MAS performance, indicating that increasing agent interaction (i.e., more critic iterations or agents involved) generally enhances outcomes up to a point where excessive agent numbers may lead to performance degradation. Additionally, optimizing the token limit for reasoning is task-dependent; for example, 16,384 tokens yielded optimal results for AIME2024, while 8,192 were sufficient for GPQA (Figures 5 and 6).
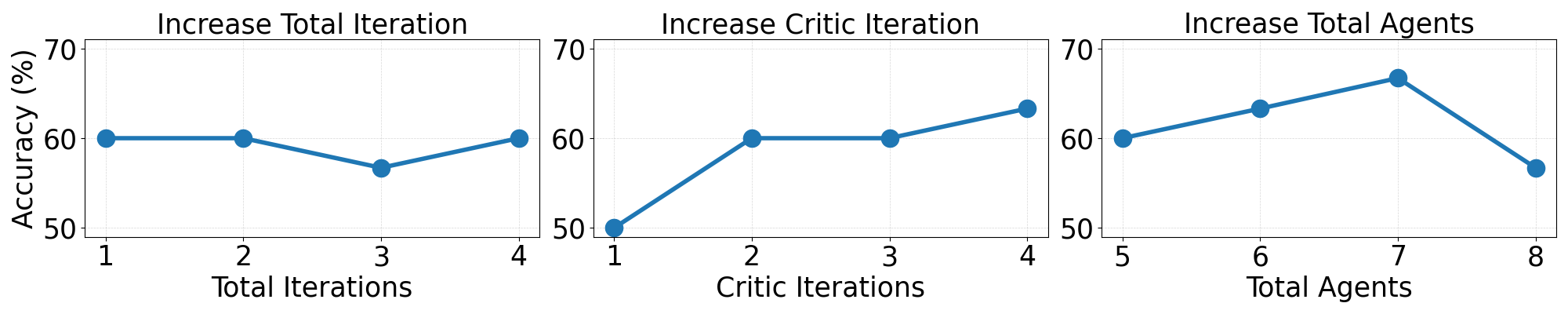
Figure 3: The effect of scale collaboration in AgentVerse using M1-32B by increasing the total iteration, critic iteration, and total agents involved in the MAS.
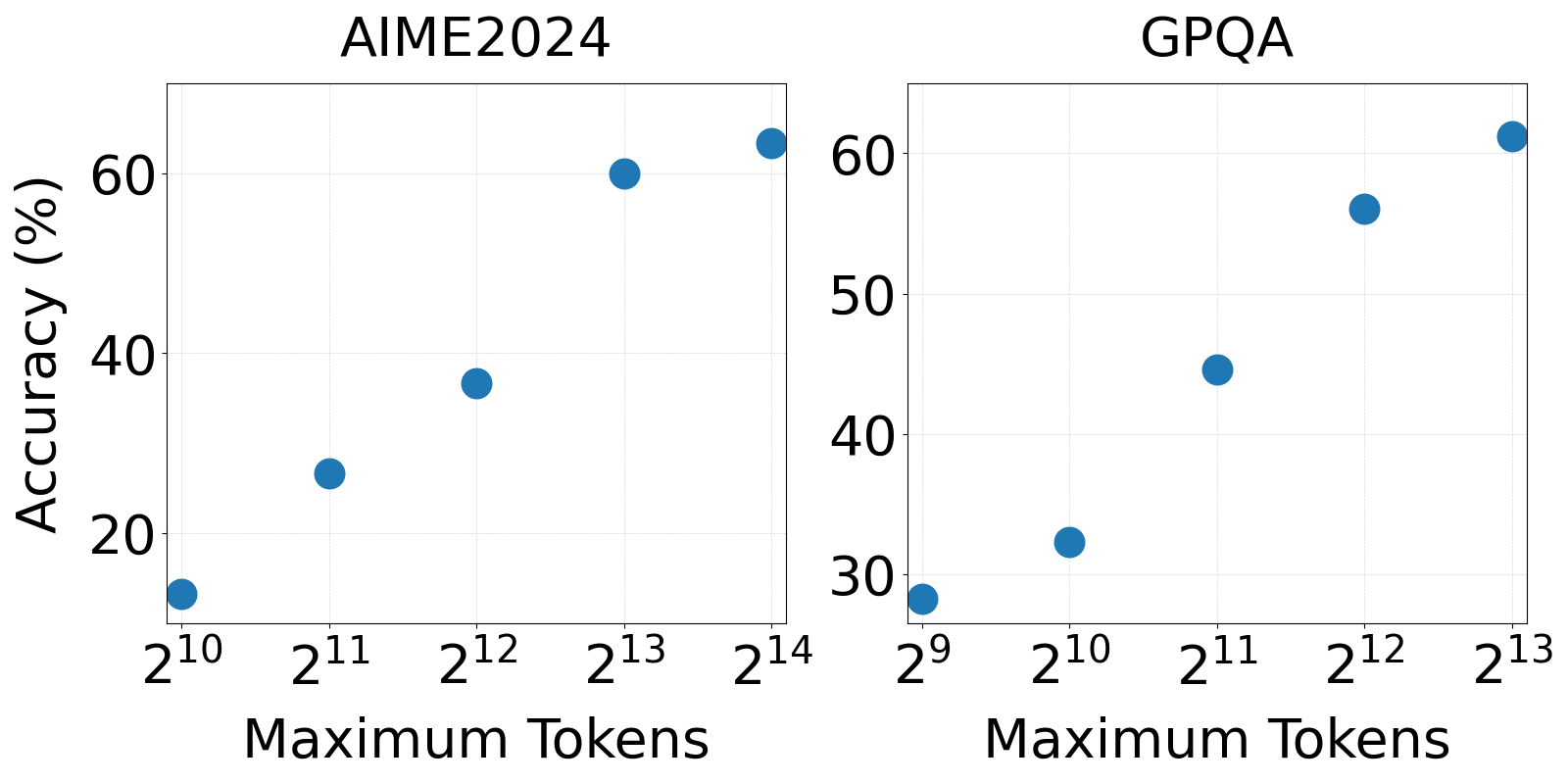
Figure 4: Effect of scaling reasoning on AgentVerse using M1-32B by controlling the maximum token usage.
Conclusion
In summary, this paper presents a significant advancement in scaling collaborative reasoning in MAS. By combining a novel dataset, a fine-tuned model specific to the task, and an innovative CEO agent for adaptive resource management, the approach enables effective test-time scaling of LLMs. Future work may involve expanding the scope of tasks these systems can handle and refining the adaptive mechanisms for better resource efficiency and scalability in broader contexts.