- The paper introduces a multi-agent framework where generator, verifier, and refinement models collaboratively enhance reasoning on complex problems.
- It employs synthetic data generation and credit assignment strategies to iteratively improve performance, achieving up to 14.14% gains on benchmark datasets.
- MALT’s strategy of majority voting and iterative refinement offers promising practical applications in domains like software development and autonomous driving.
Improving Reasoning with Multi-Agent LLM Training
This essay provides an authoritative summary of the paper "MALT: Improving Reasoning with Multi-Agent LLM Training" (2412.01928). The paper introduces a novel framework for training multiple LLMs in a cooperative setup designed to enhance reasoning capabilities on complex tasks.
Introduction to Multi-Agent LLM Training (MALT)
MALT consists of a sequential multi-agent system where heterogeneous LLMs are assigned specialized roles—generator, verifier, and refinement models—working iteratively to solve reasoning problems. By leveraging synthetic data generation and a credit assignment strategy based on joint rewards, MALT autonomously improves individual model capabilities as part of a joint system. The method demonstrates significant performance improvements over various benchmarks in mathematical and commonsense reasoning, indicating potential advancements in practical multi-agent LLM capabilities.
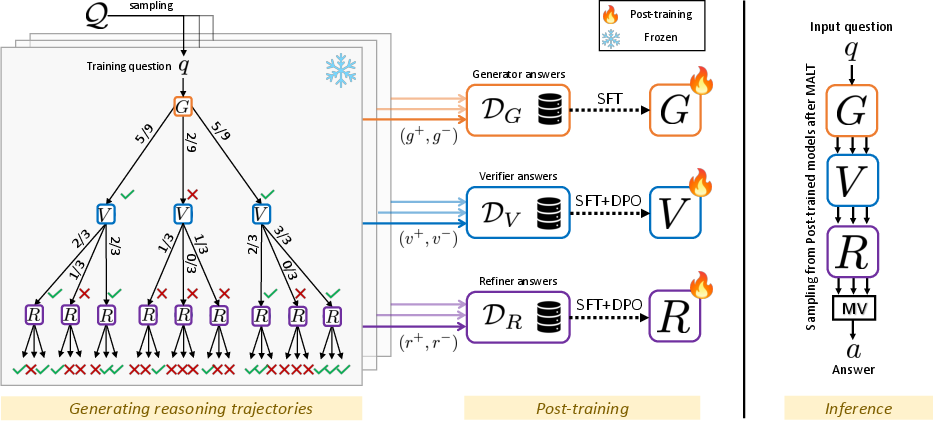
Figure 1: MALT Method Overview. Given an input, we consider a three-agent system composed of a Generator, Verifier, and Refinement Model integrating reasoning steps into a final output.
Synthetic Data Generation and Credit Assignment
In MALT, a trajectory-expansion-based process generates synthetic datasets by utilizing reasoning trajectory preference pairs for each model. These datasets feed into the post-training of individual models using supervised fine-tuning (SFT) and Direct Preference Optimization (DPO). During inference, a multi-agent system performs three parallel sequential passes, concluding with majority voting to obtain the final answer. This approach eliminates the need for human-labeled data by automatically generating reasoning traces from search trees, thus facilitating enhanced model capabilities.
MALT achieves substantial relative gains—14.14%, 9.40%, and 7.12% on the MATH, CSQA, and GSM8K datasets, respectively—compared to baseline single-model performance using Llama 3.1 8B models. Such improvements underscore the efficacy of multi-agent training on reasoning tasks, marking a promising exploration in collaborative model optimization.
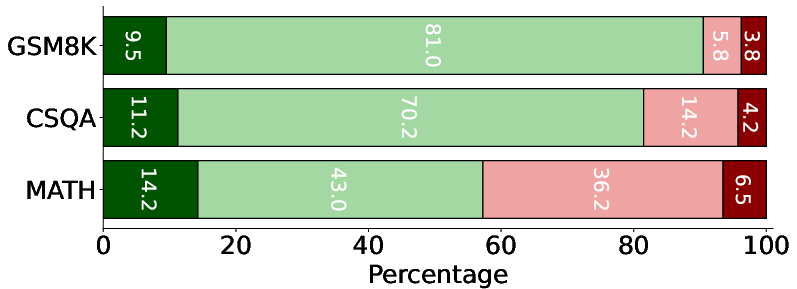
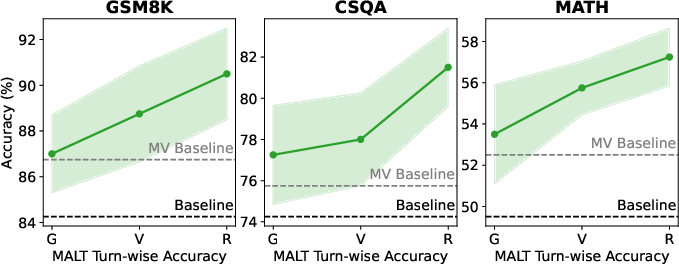
Figure 2: Self-correction and improvement over turns. MALT consistently increases the number of correct answers compared to introducing new mistakes, showcasing enhanced reasoning capabilities through iterative refinement.
Practical Implications and Future Directions
The outcomes from MALT highlight practical implications for integrating multi-agent systems into complex application domains such as software development and autonomous driving. Future developments may consider the expansion of adaptive thresholding strategies for preference data optimization and exploratory directions within policy optimization frameworks such as PPO for fine-grained reward signal extraction.
MALT establishes an early direction in leveraging strategic inference computations and collaborative model interactions, offering a productive pathway towards scalable reasoning enhancements in LLM systems.
Conclusion
MALT introduces a meticulously structured method for post-training LLM systems in a cooperative multi-agent setup. Through synthetic data generation and collaborative optimization, MALT showcases marked improvements in answering complex reasoning questions, paving the way for extensive advancements in multi-agent LLM capabilities. This work lays the foundation for exploring deeper integrations between search and learning paradigms within AI and beyond.