SE-Bench: Benchmarking Self-Evolution with Knowledge Internalization
Abstract: True self-evolution requires agents to act as lifelong learners that internalize novel experiences to solve future problems. However, rigorously measuring this foundational capability is hindered by two obstacles: the entanglement of prior knowledge, where ``new'' knowledge may appear in pre-training data, and the entanglement of reasoning complexity, where failures may stem from problem difficulty rather than an inability to recall learned knowledge. We introduce SE-Bench, a diagnostic environment that obfuscates the NumPy library and its API doc into a pseudo-novel package with randomized identifiers. Agents are trained to internalize this package and evaluated on simple coding tasks without access to documentation, yielding a clean setting where tasks are trivial with the new API doc but impossible for base models without it. Our investigation reveals three insights: (1) the Open-Book Paradox, where training with reference documentation inhibits retention, requiring "Closed-Book Training" to force knowledge compression into weights; (2) the RL Gap, where standard RL fails to internalize new knowledge completely due to PPO clipping and negative gradients; and (3) the viability of Self-Play for internalization, proving models can learn from self-generated, noisy tasks when coupled with SFT, but not RL. Overall, SE-Bench establishes a rigorous diagnostic platform for self-evolution with knowledge internalization. Our code and dataset can be found at https://github.com/thunlp/SE-Bench.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about teaching and testing AI models to truly “learn and remember” new knowledge, not just look things up. The authors build a simple but clever test called SE-Bench. It takes a well-known Python library called NumPy (a toolbox for math with arrays) and hides it behind made-up names, turning it into a “new” package. Models must learn these new names and how to use them during training, then solve coding tasks later without any notes. If they really internalize the knowledge, the tasks are easy; if not, they’re impossible.
Key Questions
The paper asks a few clear questions:
- Can we fairly measure whether an AI actually learned something new, instead of just recalling something it already knew?
- Does training “with notes open” (having the documentation visible) help or hurt long-term memory?
- Can reinforcement learning (RL)—learning by trial-and-error with rewards—make models internalize new facts?
- Can a model teach itself with its own practice problems?
How SE-Bench Works (Explained Simply)
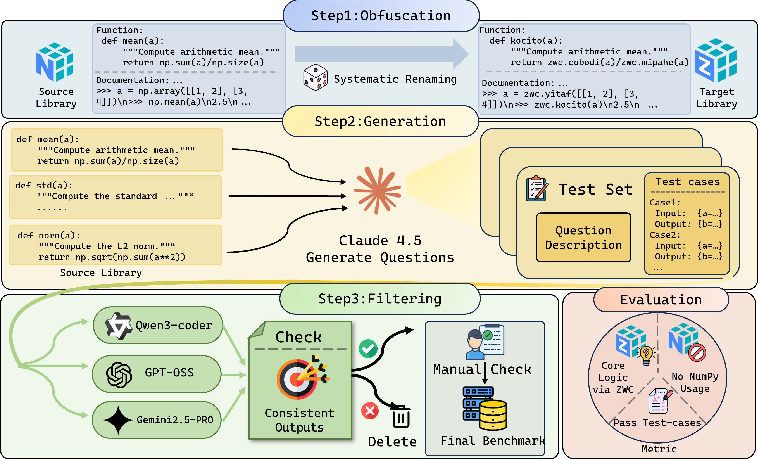
Think of a workshop full of tools with familiar names (like “hammer,” “wrench,” “screwdriver”). Now imagine we rename them to nonsense words like “kocito,” “brifla,” and “zendri.” The tools still do the same things, but all their labels and manuals use the new names. We then:
- Build the “fake” package by wrapping NumPy so that its functions have random, nonsense names. Inputs and outputs are also wrapped, so the model can’t secretly call the old tools.
- Generate simple coding problems that use these functions (like “find the average” or “sort a list”) and lots of test cases.
- Filter and check all problems with multiple strong models and humans to make sure they’re clear and easy if you know the new names.
- Train models with access to the documentation (a “cheat sheet” showing what each nonsense name does).
- Test models later without the documentation. The only way to succeed is to remember which nonsense name matches which NumPy function.
To evaluate solutions, they do more than check the output. They also verify that the code actually used the obfuscated package and didn’t import the real NumPy (no cheating!).
Main Findings and Why They Matter
Here are the major discoveries from the experiments:
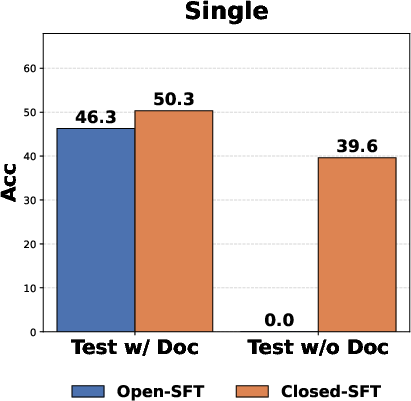
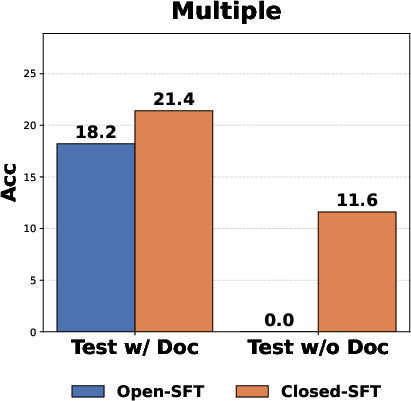
- The Open-Book Paradox: Training with the documentation visible can make memory worse. When models see the docs during training, they rely on them and don’t store the knowledge in their “brains.” Removing the docs during the parameter updates (“closed-book training”) forces the model to truly remember. Result: Closed-book training worked much better than open-book.
- The RL Gap: Standard reinforcement learning (like PPO/GRPO) failed to internalize the new names and facts. Two RL “safety” features caused trouble:
- Clipping (which limits how much the model can change with each update) prevents the big shifts needed to memorize new names.
- Negative gradients (penalties for below-average attempts) can wipe out fragile new memories before they stick.
- Self-Play Works with SFT, Not RL: If a model creates its own practice problems and solutions (self-play), it can learn—but only if you train it with supervised fine-tuning (SFT), which is like learning from worked examples. Using RL on self-play problems didn’t help. Using SFT did.
- Best Combo: First do closed-book SFT to learn and store the new facts. Then add a bit of RL to make the model’s code more robust (it reduces “guessing” and encourages reliable techniques), even though RL alone can’t teach the facts from scratch.
These results are important because they show a clean way to test whether an AI can truly learn new knowledge and highlight training methods that actually help models remember.
Implications and Potential Impact
- A simple, fair “unit test” for self-evolving AI: SE-Bench shows clearly whether a model can internalize knowledge. If the model learned the secret names, tasks are easy; if not, it fails. This removes confusion about “did it learn, or did it just recall something it knew before?”
- Training advice:
- Use closed-book SFT to make models store new facts in their parameters.
- Be careful with standard RL for learning new facts; it’s better at polishing behavior after the facts are learned.
- Self-generated practice can help, as long as you use SFT to learn from it.
- Research direction: SE-Bench offers a safe, controlled environment to study how AI learns and remembers. It can guide the community toward better training strategies for future self-evolving agents.
In short, SE-Bench gives a clear way to check whether an AI truly learns. It shows that “learning with the book closed” helps memory, RL isn’t great at learning new facts, and self-play can work if paired with the right training method.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a focused list of what remains uncertain or unexplored, framed to guide actionable future work:
- External validity beyond NumPy renaming: Does SE-Bench’s conclusions (Open-Book Paradox, RL Gap, SFT/RL roles) hold for other libraries (e.g., Pandas, PyTorch), programming paradigms (stateful/OOP APIs), languages (JavaScript, Java), and non-code domains (textual knowledge, mathematics, tools)?
- Novel-concept learning vs symbol remapping: SE-Bench evaluates a 1-to-1 identifier remap of known semantics. How well do methods internalize genuinely new concepts/algorithms whose semantics are not present in pretraining?
- Depth of compositionality: Current multi-function tasks test shallow composition. How does performance scale with compositional depth/branching (e.g., 3→10+ function chains, nested/broadcasting semantics, dtype/shape edge cases)?
- Continual and lifelong learning: What happens when agents sequentially learn multiple obfuscated packages? Measure catastrophic interference/forgetting, cumulative capacity, and retention over time and further training.
- Sample efficiency and scaling laws: How many exposures per function are required for stable internalization? Provide learning curves vs number of examples, model size, and training steps; estimate scaling exponents.
- Generalizability across model families and sizes: Are the core findings robust across Llama/Mistral/GPT/CodeLlama families and larger models (≥70B)? Do instruction-tuned vs base models behave differently?
- On-policy, closed-book RL: The RL experiments are off-policy (rollouts with doc, training without) and omit importance sampling. Can properly on-policy, closed-book RL (collecting trajectories without docs after warm-up) succeed?
- Off-policy correction validity: Ignoring the importance ratio (due to vanishing numerator) biases gradients. Can practical off-policy estimators (e.g., conservative corrections, behavior cloning regularizers) enable RL internalization?
- RL algorithmic variants: Does the RL Gap persist for algorithms that avoid PPO clipping and negative advantages (e.g., unclipped REINFORCE with ReLU advantages, NPG/TRPO with enlarged trust regions, V-MPO, Phasic PG, P3O, UPGO)? What is the role of KL regularization magnitude?
- Reward shaping and credit assignment: The reward is sparse and binary. Do shaped rewards (per-test-case partial credit, correctness of API choice, signature validation, static-analysis-based partials) enable RL to internalize mappings?
- Mechanistic analysis of the RL Gap: Provide gradient-level/mechanistic evidence (e.g., logit tracking for ZWC tokens, activation patching, causal tracing) that clipping/negative advantages prevent probability mass transfer necessary for new-token adoption.
- Verification robustness and bypasses: AST checks may miss dynamic imports, reflection, exec/eval, import, or solving via pure Python without ZWC reliance. Quantify and mitigate bypasses via runtime sandboxing, syscall/module tracing, taint analysis, and docstring/source introspection blocking.
- Documentation leakage channels: At test time, can models access zwc.doc, inspect.getsource, help(), or other introspection APIs? Enforce/verify that such channels are blocked and report leakage rates.
- Self-play data quality: Quantify correctness/coverage/diversity of self-generated tasks and tests, their error modes, and how noise impacts SFT. Explore automatic filtering (cross-model consensus, mutation testing, fuzzing), and curriculum strategies.
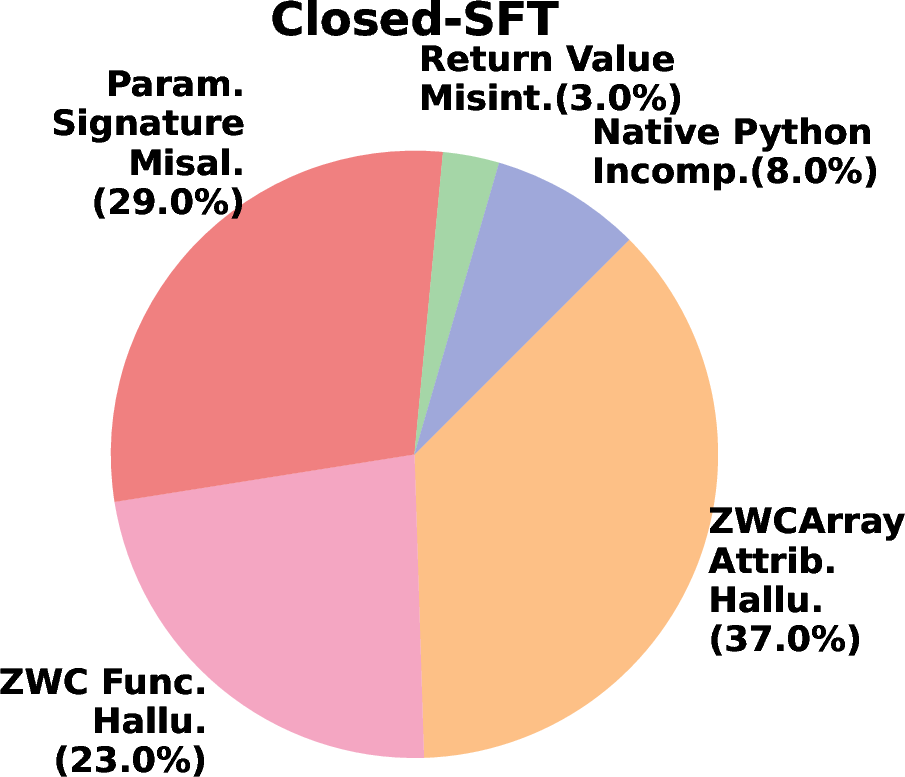
- Signature memorization and name recall: The dominant residual errors include function-name and parameter-signature mistakes. Do targeted curricula (flashcards, contrastive signature drills, auxiliary losses on API tokens) improve these failure modes?
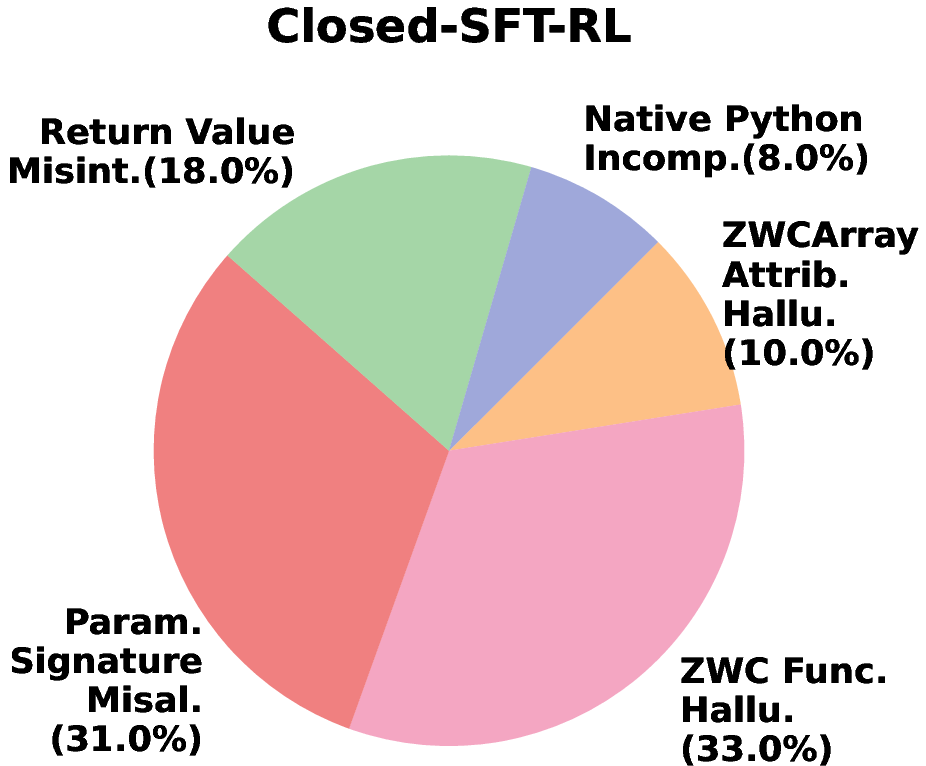
- Hybrid learning design: The hybrid Closed-SFT-RL improves utilization but not factual corrections. Can alternating schedules (SFT for acquisition, RL for consolidation, retrieval-assisted remediation for signature errors) further reduce hallucinations?
- Impact of closed-book training on general capabilities: Does Closed-SFT harm broader instruction following/coding ability or induce catastrophic forgetting elsewhere? Evaluate before/after on standard code and reasoning benchmarks.
- Robustness to noisy/misleading docs: How do methods respond to partially incorrect, outdated, or adversarial documentation during training? Can models detect, correct, or remain robust to doc noise?
- Cross-obfuscation generalization: After learning one random mapping, can the model adapt more quickly to a new mapping (meta-learning effects)? Does it learn general mechanisms for API mapping vs memorizing specific tokens?
- Memory vs parametric internalization: Memory-based methods help but are far from perfect. Can explicit memory + distillation (retrieve mapping at train time, then SFT into weights) outperform either alone? What retrieval and consolidation policies work best?
- Online, gradient-free adaptation: Can agents internalize mappings via test-time adaptation without gradient updates (e.g., iterative reasoning, external memory writes, tool-augmented self-explanation), and retain it across episodes?
- Benchmark breadth and difficulty control: Provide systematically parameterized hardness knobs (e.g., compositional depth, broadcasting quirks, dtype corner cases), formally document coverage, and report per-category performance.
- Reproducibility and variance: Many results are averaged over 5 rollouts/pass@64. Report variance across seeds, mapping randomness, and model sampling to ensure claims are statistically robust.
- Security/threat model specification: Clearly state the adversary model (what is allowed/forbidden at test time), enumerate potential bypass vectors, and provide a hardened reference evaluator.
- Parameter-efficient training: Do LoRA/IA3/QLoRA reproduce Closed-SFT gains? What are memory/compute trade-offs for internalization at scale?
- Extending to multi-modal/tool ecosystems: Apply SE-Bench-like obfuscation to tool APIs, bash utilities, HTTP endpoints, or vision/audio libraries to test internalization beyond code-only array operations.
Practical Applications
Immediate Applications
Below are concrete, deployable use cases that leverage SE-Bench’s dataset, evaluation protocol, and empirical findings (Open-Book Paradox, RL Gap, Self-Play viability). Each item notes sectors, potential tools/workflows, and key dependencies that affect feasibility.
- Bold release-gating for “self-evolving” claims — software, AI vendors, policy/compliance Use SE-Bench as a standardized unit test for knowledge internalization when vendors claim “continual learning” or “self-evolution.” Require near-ceiling scores on Single-Function tasks and strong multi-function generalization before shipping agentic features. Tools/workflows: Integrate SE-Bench into CI/CD; pass/fail gates akin to security test suites; AST-based adherence checks to prevent bypassing constraints. Dependencies/assumptions: Access to post-training evaluation; buy-in from product and risk teams; acceptance of SE-Bench as a recognized benchmark in procurement/standards.
- Closed-book SFT training recipe for internalization — software/DevTools, MLOps Adopt the “Closed-Book Training” recipe: use rich documentation/hints during trajectory collection, strip them during parameter updates. This reliably compresses new API knowledge into weights (resolving context-dependence). Tools/workflows: Data pipeline that logs doc-rich rollouts and automatically redacts docs for SFT; fine-tune orchestration (e.g., LoRA/QLoRA) with documentation-off batches. Dependencies/assumptions: Fine-tunable base models and compute; careful prompt/data engineering to avoid inadvertently leaking doc content into training text.
- Internal SDK/API onboarding for code assistants — software/platform engineering Fine-tune internal code assistants to truly learn proprietary SDKs/microservices rather than rely on in-context docs. Use SE-Bench-like obfuscation and AST-enforced evaluation to detect hallucinations and confirm weight-level internalization. Tools/workflows: Obfuscation wrappers for internal libraries; AST-based linters to forbid external imports or banned namespaces; regression dashboards on single- vs multi-function tasks. Dependencies/assumptions: Clean, high-quality internal docs; permission to fine-tune on company data; guardrails for IP handling.
- Positive-only “internalization RL” ablation for research/dev — software/AI research For teams experimenting with RL, replicate the paper’s findings: remove PPO-style clipping and negative advantage if the goal is factual internalization, or preferentially use SFT for that phase. Use RL after SFT for utilization/robustness gains, not for first-time memorization. Tools/workflows: Toggleable RL objectives (log-prob vs probability ratios), advantage shaping (binary/positive-only), curriculum schedulers that shift from SFT to RL. Dependencies/assumptions: RL infrastructure (GRPO/PPO variants), careful monitoring to mitigate instability when removing safety mechanisms (clipping).
- Self-play SFT for autonomous curriculum building — software/AI research, education Let the model draft its own tasks and tests from documentation, then apply Closed-Book SFT on that self-generated data (the paper’s “Closed-SFT_self”). This reduces reliance on curated labels while still achieving meaningful internalization. Tools/workflows: Self-play task/test generators, quality filters (consensus among multiple models), automatic doc redaction during updates. Dependencies/assumptions: Base model capable of generating minimally valid tasks; basic filtering/verification; compute to iterate.
- Vendor-neutral benchmark extensions for other stacks — software, cloud, robotics Reuse the obfuscation + wrapper + AST verification pattern to build SE-Bench variants for Pandas, PyTorch, ROS/robotics drivers, cloud SDKs, or internal tools. This creates durable, leakage-proof evaluations for new domains. Tools/workflows: Domain-specific wrappers and object proxies (like ZWCArray); doc translators; AST or bytecode inspectors tailored to the target language. Dependencies/assumptions: Stable API surfaces; language-specific static analysis; minimal performance overhead from wrappers for realistic testing.
- Hallucination diagnostics and remediation — software/DevTools, safety Use SE-Bench error taxonomy (e.g., attribute and function hallucination, signature misalignment) to create targeted linting and coaching for code assistants. Post-SFT RL can reduce “lazy” guesses by encouraging robust, grounded implementations. Tools/workflows: Error classifiers, example rewriters, fallback strategies to primitives, run-time checks for banned namespaces. Dependencies/assumptions: Telemetry of generation errors; safe RL configurations for consolidation (not memorization).
- Compliance-style audits for data leakage and provenance — policy/safety, regulated industries Demonstrate absence of pretraining leakage: zero-shot on obfuscated APIs should be at or near 0%. Use this as part of model provenance documentation in regulated procurement. Tools/workflows: SE-Bench zero-shot tests; tamper-proof logs; third-party audit bundles. Dependencies/assumptions: Willingness to disclose test results; acceptance by auditors/regulators.
- Course/lab modules on “internalization vs. in-context use” — academia/education Teach modern post-training principles with hands-on labs: closed-book SFT vs open-book SFT, RL ablations, self-play SFT. Students replicate and interpret the Open-Book Paradox and RL Gap. Tools/workflows: Course notebooks, lightweight SE-Bench subsets, small open LLMs (e.g., 1–7B) to keep costs manageable. Dependencies/assumptions: Compute quotas; permissive model licenses for teaching.
- CI checks for tool-use adherence — software/tooling Enforce company standards (e.g., disallow direct NumPy in certain repos). AST-based checks derived from SE-Bench’s evaluator ensure model-generated code uses approved APIs. Tools/workflows: AST/IR-level policy engines, pre-commit hooks, PR bots. Dependencies/assumptions: Language and framework coverage; developer acceptance of automated gating.
Long-Term Applications
These rely on further research, scaling, or domain adaptation beyond the current NumPy-based SE-Bench. They outline product and policy directions likely to emerge as the field matures.
- Enterprise “Knowledge Internalization Platform” — enterprise software, knowledge management A service that ingests proprietary docs/SOPs, creates obfuscated curricula, runs closed-book SFT, and certifies internalization before deploying updated assistants across orgs. Potential product: Managed “Closed-Book Trainer” with self-play SFT, audit logs, and pass/fail gates. Dependencies/assumptions: Robust domain-general obfuscation and verification; strong privacy guarantees; integration with enterprise IAM and data governance.
- Continual learning pipelines with safe consolidation loops — MLOps, safety Production pipelines that schedule periodic closed-book SFT on new corpora, followed by carefully constrained RL for consolidation and hallucination reduction. Potential workflow: SFT (internalize) → RL (consolidate/utilize) → regression audits (SE-Bench-like tasks). Dependencies/assumptions: Catastrophic forgetting mitigation; safe RL variants; automated drift detection.
- Sector-specific internalizers for rapidly changing rules — finance, healthcare, legal Assistants that internalize new regulations, coding standards, or clinical protocols while providing auditable proof of internalization (no reliance on always-visible context). Potential product: “Policy Internalizer” with change-diffing, test generation, and certification artifacts for auditors. Dependencies/assumptions: High-quality, up-to-date canonical sources; rigorous approval workflows; sector-specific liability frameworks.
- Robotics/tooling adapters for new hardware APIs — robotics, manufacturing Benchmarks and training kits that obfuscate hardware drivers or tool APIs so robots can truly learn new capabilities and compose them safely. Closed-book SFT ensures internalization; post-SFT RL enhances robust execution. Potential product: “Robot API Learner” SDK with simulator-based AST-equivalent constraints and safety interlocks. Dependencies/assumptions: High-fidelity simulators; safe transfer to real hardware; fail-safe design.
- Education platforms that teach models and humans together — education/edtech Co-learning systems where the platform generates curricula (for both students and models), uses closed-book phases to enforce mastery, and provides explainable internalization diagnostics. Potential product: Dual-agent tutors that can both learn new syllabi and prove mastery (benchmarks per module). Dependencies/assumptions: Pedagogical validation; robust, interpretable mastery indicators.
- Industry-wide standards for “self-evolution” claims — policy/standards Formal definitions and tests (SE-Bench-style) embedded in certification programs, procurement templates, and regulatory guidance for autonomous learning systems. Potential tools: Standardized Internalization Scorecard; third-party test suites; compliance marks. Dependencies/assumptions: Multi-stakeholder consensus; portability to non-code domains; governance for updates.
- Cross-language and multi-modal internalization benchmarks — software, multimodal AI Extend the obfuscation-plus-verification recipe to Java/C++ APIs, SQL dialects, GUI automation toolkits, and multimodal tool use (vision, audio). Potential product: “SE-Bench Suite” covering major enterprise stacks and modalities. Dependencies/assumptions: Language-specific static analysis; comparable “no-bypass” constraints; scalable task/test generation.
- Safer RL for knowledge use (not memorization) — AI research, safety New RL algorithms specifically tuned to consolidate and utilize internalized knowledge without destabilizing learning, preserving the empirical benefit found in the paper’s SFT→RL pipeline. Potential tools: Utilization-RL objectives, anti-hallucination reward shaping, advantage clipping/positivity schedules. Dependencies/assumptions: Theoretical advances in stability; reproducible baselines across domains; robust evals that separate “factual internalization” from “behavioral optimization.”
- Privacy-preserving internalization for sensitive domains — healthcare, finance, govtech Closed-book SFT pipelines that internalize sensitive knowledge with strong privacy guarantees (federated or on-prem), plus proofs that models no longer require sensitive context at inference. Potential product: On-prem “Internalization Appliance” with audit trails and secret scanning. Dependencies/assumptions: Private fine-tuning infrastructure; legal clarity on model updates; defense against membership inference.
- Personalized assistants that genuinely learn user ecosystems — daily life, productivity Over time, assistants internalize a user’s tools/workflows (e.g., home automation schemas, personal scripts) and stop needing explicit prompts or docs to act. Potential product: Local fine-tuning on-device or in a private cloud with periodic closed-book updates. Dependencies/assumptions: Lightweight fine-tuning on edge; user consent and control; safeguards against drift or misgeneralization.
- Benchmark-driven procurement and SLAs — enterprise IT, policy Contracts specify internalization targets (e.g., pass@K thresholds on domain-specific SE-Bench variants) and remediation actions if models regress after updates. Potential tools: SLA clauses tied to benchmark metrics; continuous monitoring dashboards. Dependencies/assumptions: Legal frameworks recognizing technical benchmarks; automated, repeatable test harnesses.
Notes on key assumptions and dependencies across applications
- Fine-tuning access: Many applications assume access to model weights or at least efficient adapters (LoRA) and sufficient compute.
- Domain adaptation: SE-Bench’s approach generalizes, but wrappers, obfuscation, and validators must be rebuilt per language/domain.
- Safety vs. capability: Removing PPO clipping/negative advantage may destabilize RL; use SFT for internalization and reserve RL for robust utilization with care.
- Evaluation integrity: AST/IR checks are language-specific; bypass-resistant evaluation must be designed per stack.
- Data/IP governance: Training on proprietary docs requires strong privacy, logging, and compliance processes.
Glossary
- Abstract Syntax Tree (AST): A tree-structured representation of code used for structural verification and constraint checking. "we employ a strict Abstract Syntax Tree (AST) verification protocol."
- Advantage (RL): A reinforcement learning signal measuring how much better an action is relative to a baseline, guiding policy updates. "Ablation of RL components. Internalization collapses when using PPO clip loss or including negative advantage."
- Closed-Book Training: A training setup where reference materials are removed during updates to force knowledge into model parameters. "requiring 'Closed-Book Training' to force knowledge compression into weights;"
- Closed-RL: Reinforcement learning performed without access to documentation during training (closed-book). "Closed-RL achieves zero performance."
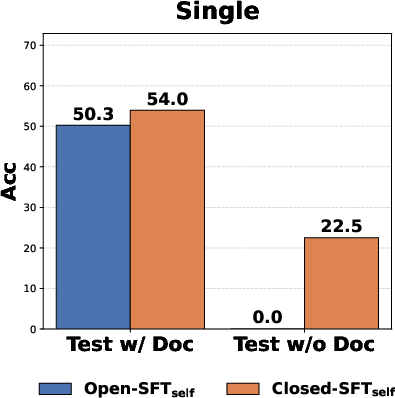
- Closed-SFT: Supervised fine-tuning without documentation in the training context to promote internalization. "Closed-SFT successfully internalizes knowledge, maintaining performance even when documentation is absent."
- Compositional complexity: The difficulty arising from composing multiple functions/APIs to solve a task. "we stratify the test set by compositional complexity:"
- Compositional Generalization: The ability to combine previously learned components or functions to solve new, multi-step tasks. "- Compositional Generalization: By retaining the library's original structure, we can evaluate whether agents can compose internalized functions to solve multi-step problems beyond their specific training examples that involves only a single function."
- Consensus Filtering: A quality-control process that retains tasks only if multiple strong models independently agree on correct solutions. "We employ a strict Consensus Filtering protocol."
- Deliberative Alignment: An alignment strategy emphasizing structured reasoning steps during training. "OpenAI's Deliberative Alignment"
- GRPO algorithm: A reinforcement learning method (a PPO variant) used for post-training LLMs. "All RL-based methods utilize the GRPO algorithm"
- Group-normalized advantage: An advantage computation normalized across a set of trajectories, producing both positive and negative signals. "and is the group-normalized advantage (containing both positive and negative values)."
- Hallucination: Model-generated content that invents non-existent APIs or behaviors, often due to uncertainty. "primarily due to hallucination: qualitative analysis reveals that Qwen3-8B frequently tries to use NumPy namespace"
- Importance sampling ratio: A correction factor used in off-policy RL to account for differences between behavior and target policies. "theoretically necessitates an importance sampling ratio"
- In-Context: A setting where relevant documentation or hints are provided in the model’s input at inference/training time. "ZWC In-Context"
- Isomorphic: Structurally equivalent in a way that preserves functionality or logic under a mapping. "the logic is isomorphic to standard NumPy"
- KL regularization: A penalty term based on Kullback–Leibler divergence to constrain policy updates during RL. "we omit the KL regularization."
- Knowledge obfuscation: A process that hides or renames known APIs/identifiers to create a pseudo-novel domain. "We employ a knowledge obfuscation mechanism"
- Needle in a Haystack test: A diagnostic that checks whether a model can find or use specific information that makes tasks trivial if known and impossible if not. "the community needs a 'Needle in a Haystack' test"
- Off-policy: An RL training regime where learning uses data generated under a different policy (or prompt condition) than the one being optimized. "applying RL in the similar off-policy settings"
- Open-Book Paradox: The phenomenon where access to documentation during training inhibits long-term knowledge retention. "the Open-Book Paradox, where training with reference documentation inhibits retention"
- Open-RL: Reinforcement learning conducted with documentation present in the training context. "Open-RL"
- Open-SFT: Supervised fine-tuning with documentation present in the training context. "Closed-SFT vs. Open-SFT."
- Parametric memory: Knowledge encoded directly in model parameters rather than stored/retrieved from context. "rely on parametric memory rather than context."
- Pass@64: A code-generation metric indicating the probability that at least one of 64 attempts solves the task. "Pass@64 of Qwen3-8B."
- PPO clipping: The Proximal Policy Optimization technique that clips policy updates to restrict large parameter shifts. "due to PPO clipping and negative gradients"
- Prefix-RL: An RL approach that leverages privileged prefixes or prompts during training to improve generalization. "Prefix-RL"
- Pre-training leakage: Undesired reliance on knowledge already present in pre-training data, confounding evaluation of novelty. "confirms no pre-training leakage."
- Self-Play: A training paradigm where a model generates its own tasks and learns from self-produced data. "the viability of Self-Play"
- Supervised Fine-Tuning (SFT): Updating model parameters by maximizing likelihood on labeled examples (teacher-forced trajectories). "Supervised Fine-Tuning (SFT)"
- Trust region violation: Making parameter updates that exceed the small, safe update region assumed by trust-region methods, risking instability. "effectively a 'trust region violation.'"
- veRL: A reinforcement learning framework/tooling used to implement training algorithms like GRPO. "within the veRL framework."
- Wrapper package: A software layer that renames or proxies underlying library functions while preserving behavior. "we implement ZWC as a wrapper package."
- Zero-Shot: Performing a task without any task-specific training or examples provided to the model. "ZWC Zero-Shot"
Collections
Sign up for free to add this paper to one or more collections.