- The paper introduces SEAL, a framework that enables LLMs to autonomously generate self-edits for finetuning using a reinforcement learning loop.
- It employs a nested training loop where generated self-edits serve as both update directives and as a signal for performance improvement during supervised finetuning.
- Experimental results show significant boosts in few-shot learning and knowledge incorporation, though challenges like catastrophic forgetting remain.
Self-Adapting LLMs
The paper "Self-Adapting LLMs" (2506.10943) introduces Self-Adapting LLMs (SEAL), a framework that enables LLMs to adapt to new tasks and knowledge by generating their own finetuning data and update directives. The framework uses a reinforcement learning loop where the LLM generates "self-edits," which are natural language instructions specifying data and optimization hyperparameters for updating the model's weights. These self-edits are then used in a supervised finetuning step to update the model parameters. The downstream performance of the updated model is used as a reward signal to train the model to produce effective self-edits. This approach contrasts with traditional methods that rely on static adaptation modules or auxiliary networks, instead leveraging the LLM's generative capabilities to control its own adaptation process.
Background and Motivation
LLMs, despite their proficiency in language understanding and generation [brown2020language, touvron2023llama, grattafiori2024llama3herdmodels, groeneveld2024olmo, qwen2025qwen25technicalreport], face challenges in adapting to specific tasks [gururangan2020finetune], incorporating new information [zhu2021modifying], and mastering novel reasoning skills [chollet2024arc]. Traditional adaptation methods often rely on manually curated task-specific data, which can be limited in availability and may not be in an optimal format for learning. The SEAL framework addresses these limitations by enabling LLMs to generate their own training data and finetuning directives.
The authors draw an analogy to human learning, where students often rewrite and restructure information to improve understanding and retention. This process of assimilating and augmenting external knowledge contrasts with the way LLMs are typically trained, where models learn from task data "as-is" via finetuning or in-context learning [wei2022finetuned, rozière2024codellamaopenfoundation, chen2023meditron70bscalingmedicalpretraining, colombo2024saullm7bpioneeringlargelanguage]. By equipping LLMs with the ability to generate their own training data and finetuning directives, the SEAL framework aims to improve the scalability and efficiency of LLM adaptation.
Methodological Framework
The SEAL framework (Figure 1) involves training LLMs to generate "self-edits"—natural-language instructions that specify the data and optimization hyperparameters for updating the model's weights. The model learns to generate these self-edits through reinforcement learning (RL), where it is rewarded for generating self-edits that improve the model's performance on a target task.
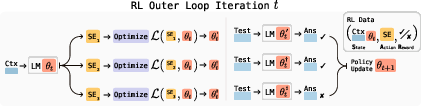
Figure 1: Overview of SEAL, showing how the model generates self-edits, applies updates, and evaluates performance in a reinforcement learning loop.
The framework can be viewed as having two nested loops: an outer RL loop that optimizes the self-edit generation process and an inner update loop that uses the generated self-edit to update the model via gradient descent. This method can be seen as a form of meta-learning, where the model learns how to generate effective self-edits.
Formally, let θ denote the parameters of the LLM LMθ. SEAL operates on individual task instances (C,τ) where C is a context containing information relevant to the task, and τ defines the downstream evaluation used to assess the model's adaptation. Given C, the model generates a self-edit SE and updates its parameters via supervised finetuning: θ′←SFT(θ,SE). The self-edit generation process is optimized using reinforcement learning: the model takes an action (generating SE), receives a reward r based on LMθ′'s performance on τ, and updates its policy to maximize expected reward:
$\mathcal{L}_{\text{RL}(\theta_t) := -\mathbb{E}_{(C, \tau) \sim \mathcal{D} \left[ \mathbb{E}_{SE \sim \text{LM}_{\theta_t}(\cdot \mid C)} \left[ r(SE, \tau, \theta_t) \right] \right].$
The reward is a binary signal based on whether the adaptation using SE improves the model's performance.
The authors employ ReSTEM [singh2023beyond], a filtered behavior cloning approach, for the RL update. This approach optimizes an approximation of the objective under the binary reward, reinforcing only those samples that receive positive reward through supervised finetuning. The SEAL training loop involves sampling candidate outputs from the current model policy (E-step) and reinforcing only those samples that receive positive reward through supervised finetuning (M-step).
Knowledge Incorporation
In the knowledge incorporation task, the goal is to efficiently integrate new factual knowledge into the model's weights. The authors adopt an approach of generating content derived from the passage, followed by finetuning on both the original passage and the generated content [yehudai2024genie, akyurek2024deductive, yang2025synthetic, lampinen2025generalizationlanguagemodelsincontext, park2025textitnewnewssystem2finetuning]. The self-edit takes the form of implications derived from the passage. (Figure 2)

Figure 2: Knowledge Incorporation Setup using self-generated implications for finetuning.
The model is prompted to "List several implications derived from the content," converting a given context C into a set of implications SE={s1,s2,…,sn}. These self-generated statements form the training data for a supervised finetuning (SFT) update. The adapted model LMθ′ is then evaluated on the task τ. During RL training, the adapted model's accuracy on τ defines the reward r that drives the outer RL optimization. This trains the model to restructure the passage in a way that is most effective for assimilation via finetuning.
Few-Shot Learning
In the few-shot learning domain, the authors evaluate SEAL on a simplified subset of the ARC-AGI benchmark [chollet2024arc], which tests abstract reasoning and generalization from limited examples. Each task includes a small set of input-output demonstrations and a held-out test input whose correct output must be predicted.
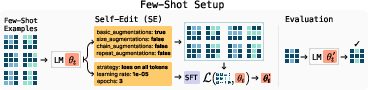
Figure 3: Few-Shot Learning Setup, where the model generates augmentations and training hyperparameters for test-time training.
They adopt the test-time training (TTT) protocol of [akyurek2025TTT], where augmentations of the few-shot examples are used to perform gradient-based adaptation. Rather than relying on manually tuned heuristics for selecting augmentations and optimization settings, they train SEAL to learn these decisions.
The model is prompted with a task's few-shot demonstrations and generates a self-edit, which in this case is a specification of which tools to invoke and how to configure them. This self-edit is then applied to adapt the model via LoRA-based finetuning. The adapted model is evaluated on the held-out test input, and the result determines the reward for training the self-edit generation policy.
Experimental Results
The authors empirically evaluate SEAL across two adaptation domains: few-shot learning and knowledge incorporation. In the few-shot learning experiments, they use Llama-3.2-1B-Instruct, a small open-source model with no ARC-specific pretraining. SEAL substantially improves adaptation success rate compared to baselines, achieving a 72.5% success rate versus 20% for self-editing without RL and 0% for in-context learning. However, performance remains below Oracle TTT, suggesting room for further improvement.
In the knowledge incorporation experiments, the authors use Qwen2.5-7B on incorporating novel factual content from SQuAD passages [rajpurkar2016squad]. They compare SEAL against several baseline approaches, including finetuning directly on the passage, training on the passage with synthetic data generated by GPT-4.1, and training on the passage with synthetic data generated by the base Qwen-2.5-7B model. SEAL outperforms all baselines, achieving 47.0% accuracy in the single-passage setting and 43.8% accuracy in the continued pretraining setting. Notably, SEAL outperforms using synthetic data from GPT-4.1, despite being a much smaller model.
Limitations and Future Directions
The authors acknowledge several limitations of the SEAL framework. One key limitation is the issue of catastrophic forgetting [mccloskey1989catastrophicinterference, goodfellow2015catastrophicforgetting], where new updates interfere destructively with past learning. Experiments in a continual learning setting show that performance on earlier tasks gradually declines as the number of edits increases, suggesting that SEAL is still susceptible to catastrophic forgetting. The TTT reward loop is significantly more computationally expensive than other reinforcement learning loops used with LLMs.
Future work could address these limitations by incorporating mechanisms for mitigating catastrophic forgetting, such as reward shaping [hu2020learning, xie2023text2reward, fu2025reward] or null-space constrained edits [fang2025alphaeditnullspaceconstrainedknowledge]. Additionally, the authors suggest exploring ways to scale RL training of SEAL to unlabeled corpora by having the model generate its own evaluation questions. The authors also propose meta-training a dedicated SEAL synthetic-data generator model that produces fresh pretraining corpora, allowing future models to scale and achieve greater data efficiency without relying on additional human text.
Discussion and Conclusion
The SEAL framework demonstrates that LLMs can autonomously incorporate new knowledge and adapt to novel tasks by learning to generate their own synthetic self-edit data and applying it through lightweight weight updates. The ability of LLMs to self-adapt in a data-constrained world may be necessary given projections that frontier LLMs will be trained on all publicly available human-generated text by 2028 [villalobos2024rundatalimitsllm].
The authors envision extending the SEAL framework to pretraining, continual learning, and agentic models. They suggest that this continual refinement loop could be promising for building agentic systems, where models operate over extended interactions and adapt dynamically to evolving goals.