- The paper introduces EBPO, a novel method that blends local group statistics with a global prior via empirical Bayes shrinkage to reduce variance in policy optimization.
- It dynamically balances within-group and prompt-level variances, preventing gradient vanishing in saturated failure cases while ensuring stable advantage estimation.
- Empirical results demonstrate enhanced sample efficiency and robust training stability across diverse LLM architectures and reasoning benchmarks.
Empirical Bayes Shrinkage for Stabilizing Group-Relative Policy Optimization
Motivation and Problem Statement
Reinforcement Learning with Verifiable Rewards (RLVR) is widely adopted for post-training LLMs in domains requiring objective correctness, such as mathematical reasoning and code generation. Group Relative Policy Optimization (GRPO) is a dominant RLVR method due to its computational efficiency; it uses local group statistics (mean and variance of reward among sampled outputs) instead of value networks. However, GRPO suffers from high estimator variance with small group sizes and null gradients for saturated failure cases—all responses in a group receive zero reward, causing wasted training steps. Data-discarding attempts (e.g., DAPO) mitigate variance but inevitably waste samples and require large group sizes, which limits scalability.
EBPO Framework and Algorithmic Innovations
Empirical Bayes Policy Optimization (EBPO) addresses the fundamental deficiencies of GRPO by introducing Empirical Bayes regularization into the group baseline estimator. Instead of estimating baselines in isolation, EBPO computes a shrinkage estimator that combines the noisy local group mean with a global prior, which is updated online via Welford’s algorithm. The shrinkage factor Sq depends on the ratio of within-group variance to between-group variance, dynamically balancing local and global statistics. This mechanism enables EBPO to provide informative advantage signals even in regimes with high sparsity or saturated failures—where all responses are incorrect.
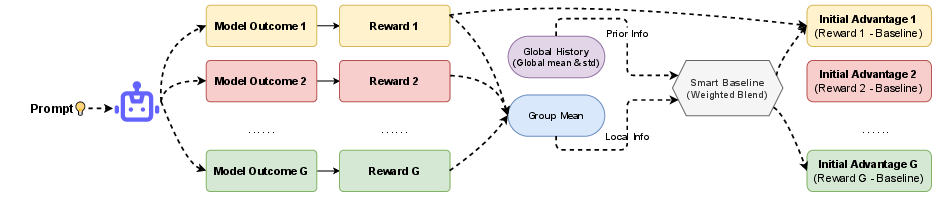
Figure 1: EBPO computes a shrinkage baseline by blending the noisy local group mean with a global prior, stabilizing advantage estimation in small or saturated groups.
The formal EBPO baseline for prompt q is:
VqEB=(1−Sq)μgroup+Sqμglob
with
Sq=σ2/G+τ2σ2/G
where σ2 is the within-group reward variance, τ2 is the variance of empirical prompt-level means, and G is group size. Online updates of μglob, σ2, and τ2 ensure stability at scale.
Theoretical Guarantees
EBPO strictly reduces the mean squared error (MSE) in estimating true prompt difficulty relative to GRPO. The shrinkage estimator, by trading unbiasedness for variance reduction, achieves lower MSE especially when G is small. Critically, EBPO avoids the vanishing gradient problem in saturated failure groups: for ri=0 across all responses, GRPO yields zero advantage, null gradient, and wasted optimization. EBPO assigns a penalty proportional to the global success rate, providing nonzero gradient and informative signal for learning.
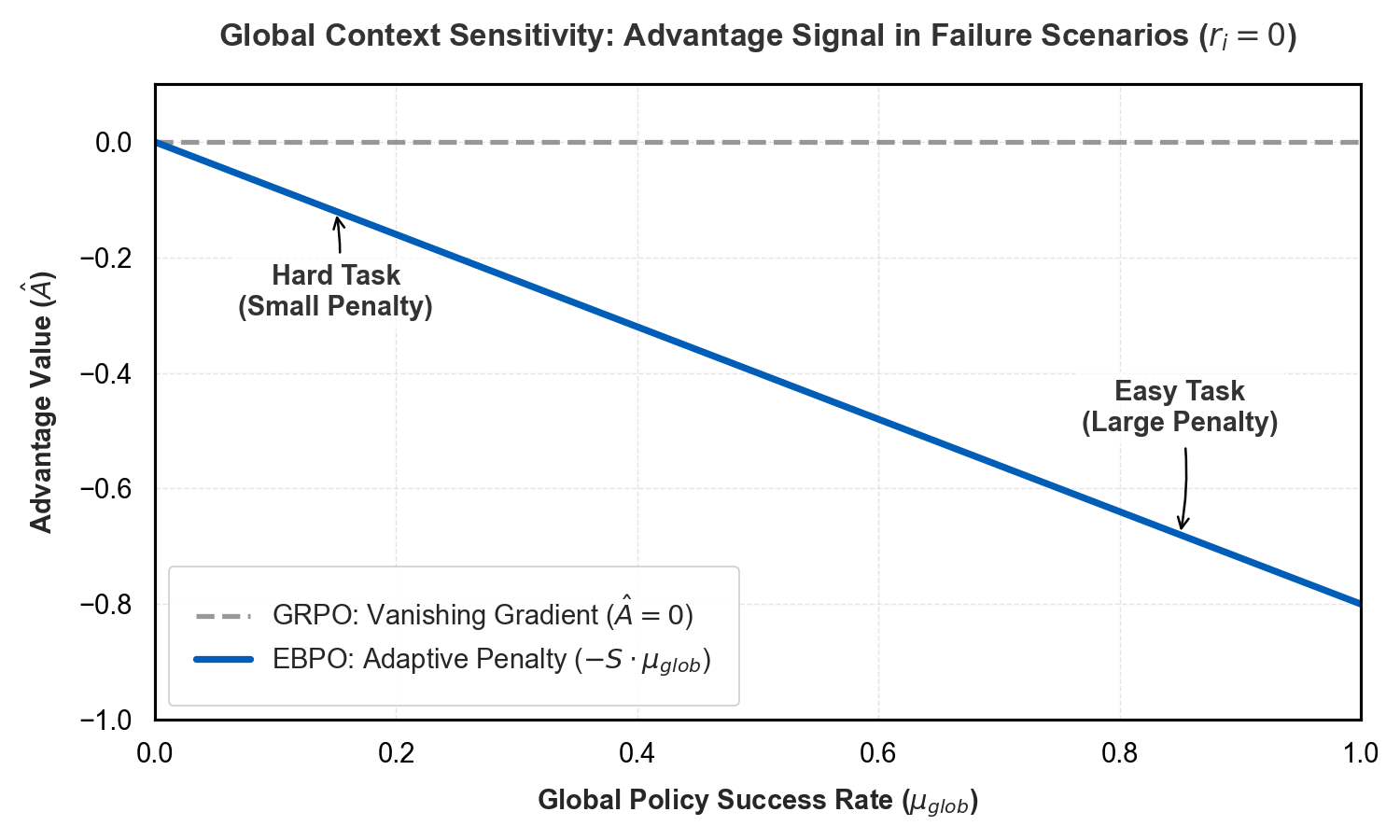
Figure 2: EBPO provides a dynamic penalty signal in saturated prompt failure scenarios, enabling learning when GRPO yields vanishing gradients.
Entropy conservation is another key property: EBPO bounds entropy decay, preventing premature policy collapse and maintaining exploration. The global prior acts as a regularizer, damping erratic policy updates caused by noisy local statistics.
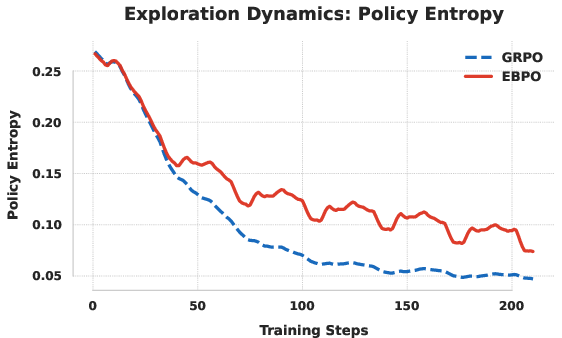
Figure 3: EBPO maintains higher policy entropy during training compared to GRPO, preserving broader exploration.
Topic- and difficulty-clustered sampling further improves EBPO’s efficacy. By grouping prompts semantically or by difficulty, the prior estimates become sharper, reducing estimation bias and improving advantage regularization.
Empirical Results
EBPO’s empirical evaluation spans multiple LLM architectures (LLaMA3.1-8B, Qwen3-8B, Qwen3-14B) and benchmarks (MATH-500, AIME-2024/2025, AMC23, OlympiadBench). Under topic-clustered group sampling (G=4), EBPO consistently outperforms GRPO and other baselines (DrGRPO, DAPO, EntropyMech). For Qwen3-8B, EBPO achieves average Pass@1 of 64.39%, surpassing GRPO by >5%.
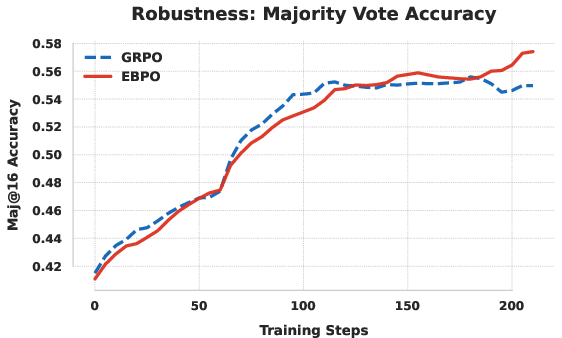
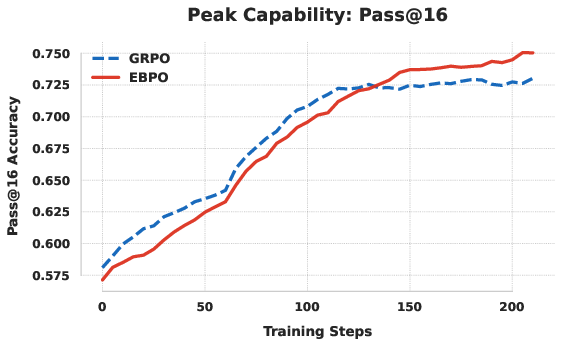
Figure 4: EBPO exhibits sustained validation performance, while GRPO degrades or plateaus due to policy collapse.
EBPO attains high sample efficiency: at G=8, it outperforms GRPO by over 11%. The benefits are most pronounced in computationally constrained settings and on elite-level reasoning benchmarks (AIME, OlympiadBench).
Curriculum learning experiments further establish EBPO’s advantage. Difficulty-based clustering (easy-to-hard exposure) improves transfer to multi-step reasoning and complex prompts, with EBPO outperforming GRPO by sizable margins on the hardest benchmarks.
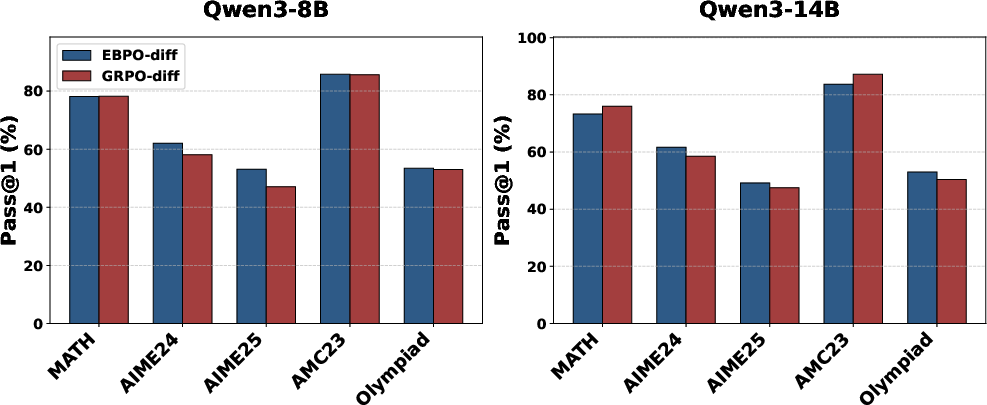
Figure 5: Difficulty-based curriculum learning amplifies EBPO’s performance advantage on high-difficulty reasoning benchmarks.
Practical and Theoretical Implications
EBPO’s approach bridges statistical shrinkage estimation and RL advantage normalization, offering a robust framework for optimizing LLMs in sparse, verifiable reward regimes. By borrowing statistical strength across prompt clusters, EBPO regularizes updates, mitigates variance, and avoids catastrophic instability. Practically, EBPO enables efficient RLVR training even with small sampling groups, unlocking scalable post-training for LLMs in reasoning-heavy domains.
Theoretically, EBPO’s integration of empirical Bayes estimation into policy optimization opens new directions for hierarchical RL methods, fine-grained curriculum learning, and adaptive evidence aggregation. EBPO’s strictly bounded entropy decay and dynamic penalty assignment point to new classes of regularized RL algorithms for non-i.i.d. environments and multi-task reasoning.
Future developments may focus on structured prior estimation, dynamic clustering, and integrating EBPO with token-level and sequence-level reward formulations. Extension to broader RL domains with complex, nonbinary reward signals and exploration–exploitation tradeoffs is plausible.
Conclusion
EBPO introduces statistically principled Empirical Bayes shrinkage into group-based RL for LLMs, stabilizing advantage estimation and enabling robust policy optimization under sparse and volatile reward landscapes. Empirically and theoretically, EBPO demonstrates superior training stability, sample efficiency, and generalization performance compared to standard GRPO and related baselines. The framework’s resilience, driven by evidence-based prior regularization and curriculum learning, establishes EBPO as an effective bridge between Bayesian estimation and scalable reinforcement learning for reasoning-centric AI.