Length-Unbiased Sequence Policy Optimization: Revealing and Controlling Response Length Variation in RLVR
Published 5 Feb 2026 in cs.CL | (2602.05261v1)
Abstract: Recent applications of Reinforcement Learning with Verifiable Rewards (RLVR) to LLMs and Vision-LLMs (VLMs) have demonstrated significant success in enhancing reasoning capabilities for complex tasks. During RLVR training, an increase in response length is often regarded as a key factor contributing to the growth of reasoning ability. However, the patterns of change in response length vary significantly across different RLVR algorithms during the training process. To provide a fundamental explanation for these variations, this paper conducts an in-depth analysis of the components of mainstream RLVR algorithms. We present a theoretical analysis of the factors influencing response length and validate our theory through extensive experimentation. Building upon these theoretical findings, we propose the Length-Unbiased Sequence Policy Optimization (LUSPO) algorithm. Specifically, we rectify the length bias inherent in Group Sequence Policy Optimization (GSPO), rendering its loss function unbiased with respect to response length and thereby resolving the issue of response length collapse. We conduct extensive experiments across mathematical reasoning benchmarks and multimodal reasoning scenarios, where LUSPO consistently achieves superior performance. Empirical results demonstrate that LUSPO represents a novel, state-of-the-art optimization strategy compared to existing methods such as GRPO and GSPO.
The paper introduces LUSPO, correcting the GSPO-induced length bias by scaling loss with sequence length, leading to enhanced reasoning capacity.
It provides rigorous gradient and empirical analyses showing that LUSPO generates responses up to 1.5x longer and improves accuracy on mathematical and multimodal benchmarks.
LUSPO's design ensures stable, length-unbiased training, which is crucial for complex RLVR tasks and scalable model deployment.
Length-Unbiased Sequence Policy Optimization for RLVR: An Analytical Perspective
Overview and Motivation
The paper "Length-Unbiased Sequence Policy Optimization: Revealing and Controlling Response Length Variation in RLVR" (2602.05261) addresses a fundamental challenge in training LLMs and vision-LLMs (VLMs) using Reinforcement Learning with Verifiable Rewards (RLVR). Specifically, it investigates the phenomenon of response length variation induced by prevalent RLVR algorithms, notably Group Relative Policy Optimization (GRPO) and Group Sequence Policy Optimization (GSPO). The authors provide a theoretical and empirical analysis uncovering length bias in these algorithms, which leads to suboptimal reasoning capacity and performance due to premature response truncation. To eliminate this bias, the paper introduces Length-Unbiased Sequence Policy Optimization (LUSPO), a method that modifies the sequence-level optimization by scaling loss proportionally to sequence length, thereby ensuring equitable gradient contributions irrespective of response length.
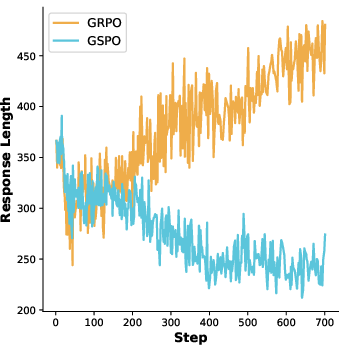
Figure 1: Response length during RLVR training for Qwen2.5-VL-7B-Instruct, highlighting GRPO's tendency toward longer responses versus GSPO's length collapse.
Technical Contributions
Response Length Bias in RLVR Objectives
The analysis reveals that GRPO and GSPO objectives inherently prefer shorter responses for correct answers and penalize shorter responses less for incorrect answers, resulting in systematic bias. In GRPO, token-level averaging disproportionately weights shorter sequences. GSPO adopts sequence-level importance weighting and clipping, but this amplifies the bias through sequence-level truncation and the Clip-Higher mechanism, where gradients become dominated by positive samples, causing the model to favor brevity.
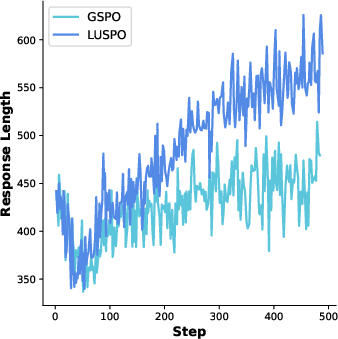
Figure 2: Response length during GSPO training on different datasets; reward-driven and loss-driven effects vary by dataset complexity.
LUSPO: Algorithm Design
LUSPO corrects the GSPO-induced bias by scaling each sequence's loss by its length ∣y∣. Formally:
This adjustment ensures trajectory-wise gradient contributions scale linearly with response length, neutralizing the prior bias without compromising optimization stability.
Gradient Analysis
A detailed gradient comparison demonstrates that LUSPO eliminates the length-dependent attenuation present in GSPO. LUSPO ensures consistent exploration space, promoting longer, richer responses and thus more advanced reasoning strategies, critical in mathematical and multimodal contexts.
Empirical Evaluation
Training Dynamics and Length Control
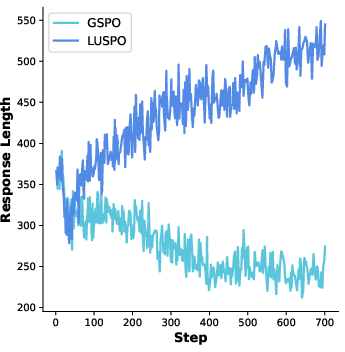
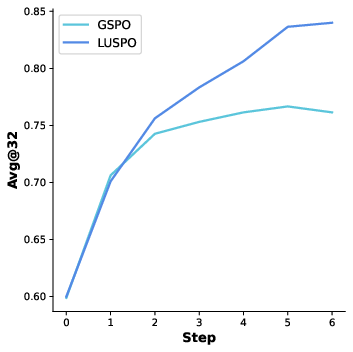
Comprehensive experiments on Qwen2.5-7B-Base (dense), Qwen3-30B-A3B-Instruct (MoE), and Qwen2.5-VL-7B-Instruct (VL) validate the theoretical claims. Models trained with LUSPO consistently generate longer responses, with average response lengths up to 1.5x greater than GSPO baselines. This facilitates enhanced reasoning and detailed solutions, particularly in complex tasks.
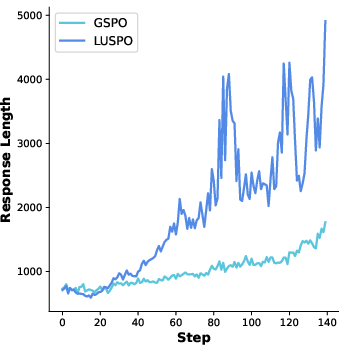
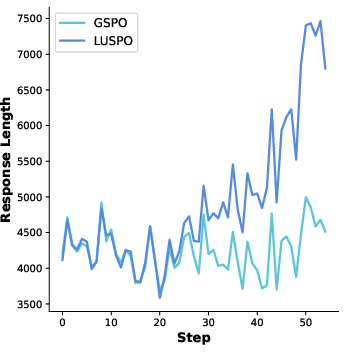
Figure 3: Response length curves during training on ViRL39k and DAPO-MATH-17k, demonstrating LUSPO's sustained length advantage.
Numerical Results
LUSPO's improvements are quantitatively affirmed on diverse mathematical and multimodal benchmarks:
On AIME24, Qwen2.5-7B-Base with LUSPO achieves a +2.9% accuracy gain over GSPO; Qwen3-30B-A3B-Instruct sees a +6.9% increase.
On multimodal MathVista-Mini, LUSPO outperforms GRPO and GSPO by +1.6% and +0.5%, respectively.
Substantial gains are observed on WeMath and LogicVista, with LUSPO exhibiting +5.1% and +6.0% improvement over GSPO.
These results substantiate the claim that LUSPO is a superior optimization strategy for RLVR, able to maintain and nurture longer response trajectories, which is critical for tasks requiring elaborate reasoning.
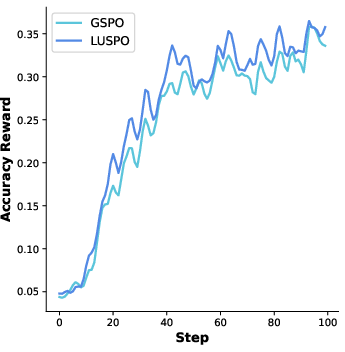
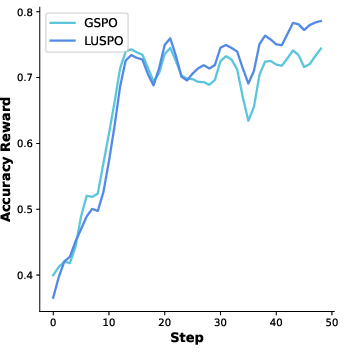
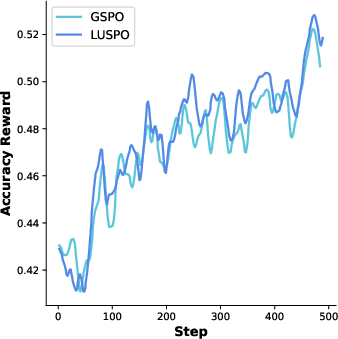
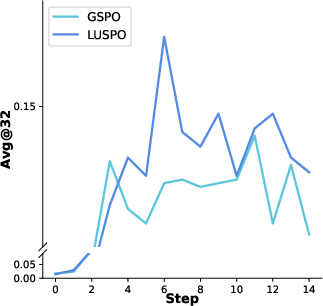
Figure 4: Qwen2.5-7B-Base visualization during RLVR training.
Figure 5: Qwen2.5-7B-Base: illustration of training dynamics.
Figure 6: Qwen2.5-7B-Base: further depiction of response evolution.
Multimodal Reasoning Robustness
LUSPO’s effectiveness on vision-language tasks confirms that length-unbiased optimization is crucial not only in textual settings but also in scenarios involving visual context, where exploratory reasoning is necessary to interpret diagrams and tables.
Practical and Theoretical Implications
The research has significant implications for RLVR algorithm design. Removal of length bias leads to improved stability and more sophisticated task handling, especially in advanced mathematics, scientific domains, and multimodal integration. For MoE architectures, LUSPO avoids instability caused by token-level variance, enabling scalable training. The findings motivate future RLVR work to systematically assess and neutralize potential biases along axes beyond length, such as complexity or logical depth.
Speculatively, as LLMs and VLMs continue to evolve, algorithms maximizing exploration space without bias will become foundational in driving general-purpose reasoning capability. LUSPO’s approach may generalize to other trajectory attributes (e.g., step-wise logical validity), supporting more robust RL training paradigms.
Conclusion
The paper establishes a rigorous connection between RLVR objective function design and response length dynamics in large models. By introducing LUSPO, it removes length bias from sequence-level optimization, enabling models to generate longer, more detailed responses, which directly translates to improved reasoning and accuracy in both textual and multimodal benchmarks. The work represents a technical advancement in RLVR methodology with notable implications for the scalability and robustness of large foundation models across complex domains.