- The paper introduces a novel residual-aware binarization method that sequentially derives binary paths from a shared full-precision weight to correct preceding errors.
- It achieves state-of-the-art performance on Llama2-7B with 5.78 perplexity and a 4.49× speed-up in token generation compared to matmul-based methods.
- The approach eliminates inter-path co-adaptation by enforcing negative correlation, preventing redundancy and stabilizing quantization losses.
Residual-Aware Binarization Training (RaBiT): An Expert Analysis
Motivation and Problem Identification
Extreme quantization of LLMs, particularly at the 2-bit level, faces a stringent trade-off between inference efficiency and model fidelity. Previous approaches, such as vector quantization (VQ), achieve superior accuracy but incur substantial hardware overhead from table lookups and rotational operations. In contrast, residual binarization architectures, which stack binary layers and operate in a matmul-free regime, offer exceptional memory efficiency and throughput but have exhibited persistent performance deficits owing to training instabilities. Fundamental to the degradation is feature co-adaptation, specifically labeled here as inter-path adaptation: parallel binary paths in residual binarization, optimized via standard quantization-aware training (QAT), become functionally redundant, undermining their intended error-compensation roles and restricting representational capacity.
RaBiT Framework and Structural Resolution
RaBiT enforces a residual hierarchy by algorithmically coupling the training of binary paths. Rather than maintaining independent latent weights, RaBiT derives each binary path sequentially from a shared full-precision anchor weight, $W_{\mathrm{FP}$, with specialized learnable scales. The binarization proceeds as follows: the first path is computed as $\text{sign}(W_{\mathrm{FP})$, and the subsequent path is binarized from the residual error $R_1 = W_{\mathrm{FP} - \hat{W}_1$. This sequential derivation ensures that each path corrects its predecessor's error, structurally promoting negative inter-path correlation—a property empirically validated across network layers and essential for loss minimization.
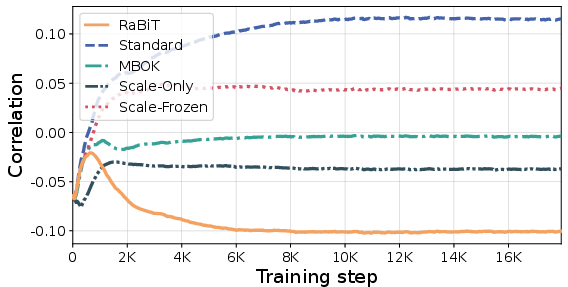
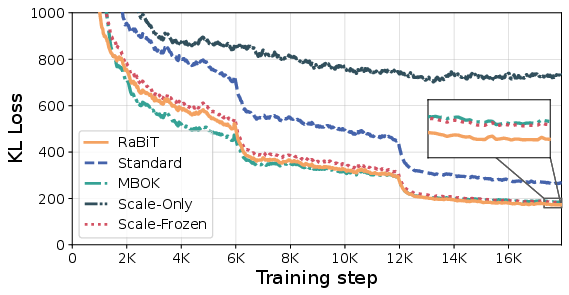
Figure 1: RaBiT consistently enforces negative inter-path correlation, breaking redundancy and enabling effective error compensation; Standard QAT exhibits positive correlation from co-adaptation.
The backward propagation employs a surrogate gradient for the shared weight and chain-rule gradients for the scaling vectors. Critically, path-specific scales are treated as independent learnable parameters, enabling efficient adaptation without the computational complexity of iterative scale recomputation. During inference, binary paths derived from the trained $W_{\mathrm{FP}$ are executed in parallel, discarding the anchor weight for maximum memory efficiency.
Initialization Strategies and Functional Preservation
Convergence in 2-bit QAT is highly sensitive to initialization. RaBiT employs a two-stage strategy: (1) Iterative Residual SVID, which iteratively refines paths and scales via rank-1 SVD decomposition of the residual matrix, thereby avoiding greedy scheduling bias, and (2) I/O Channel Importance Scaling, which preconditions the anchor weight based on activation and gradient statistics extracted from calibration data. This approach prioritizes preservation of functionally salient weight components over mere value approximation.
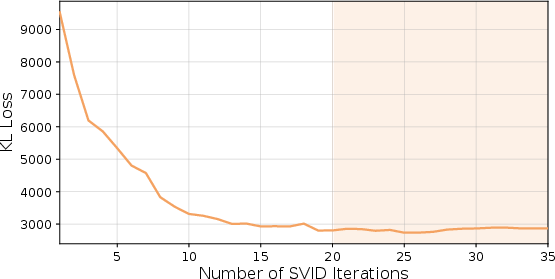
Figure 2: Iterative Residual SVID stabilizes the initial KL divergence loss, achieving optimal convergence within 20 iterations.
Empirical Results and Numerical Claims
RaBiT achieves state-of-the-art performance in 2-bit LLM quantization across Llama and Gemma model suites. On Llama2-7B, RaBiT yields 5.78 perplexity (WikiText-2) and 61.51% zero-shot QA average, surpassing prior matmul-free methods (e.g., DBF, MBOK) and even rivaling VQ-based methods (QTIP, QuIP#). Notably, RaBiT maintains robust convergence across architectures where alternatives collapse (BitStack yields 2.75e3 PPL on Llama3-8B). On challenging benchmarks (BBH, GPQA, MMLU-Pro, IFEval), RaBiT consistently outperforms QTIP and retains high functional capacity relative to full precision.
RaBiT also delivers substantial inference acceleration: a 4.49× end-to-end speed-up in token generation for Llama2-7B on RTX 4090, attributed to parallel matmul-free execution and weight bit-packing for memory bandwidth reduction.
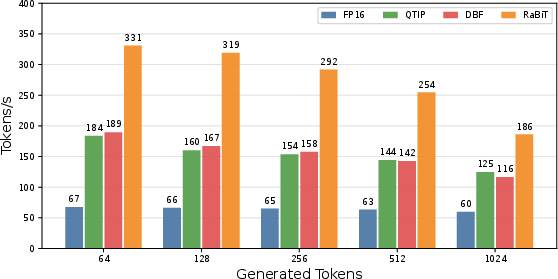
Figure 3: RaBiT achieves superior end-to-end decoding throughput compared to other 2-bit methods, maintaining consistent advantage across generation lengths.
Layer-wise MSE decomposition demonstrates RaBiT's structural advantage in inducing strong negative covariance and actively lowering total error, as compared to Standard QAT's negligible correlation. The approach also suppresses layer sensitivity in early network stages, stabilizing quantization losses well beyond conventional architectures.
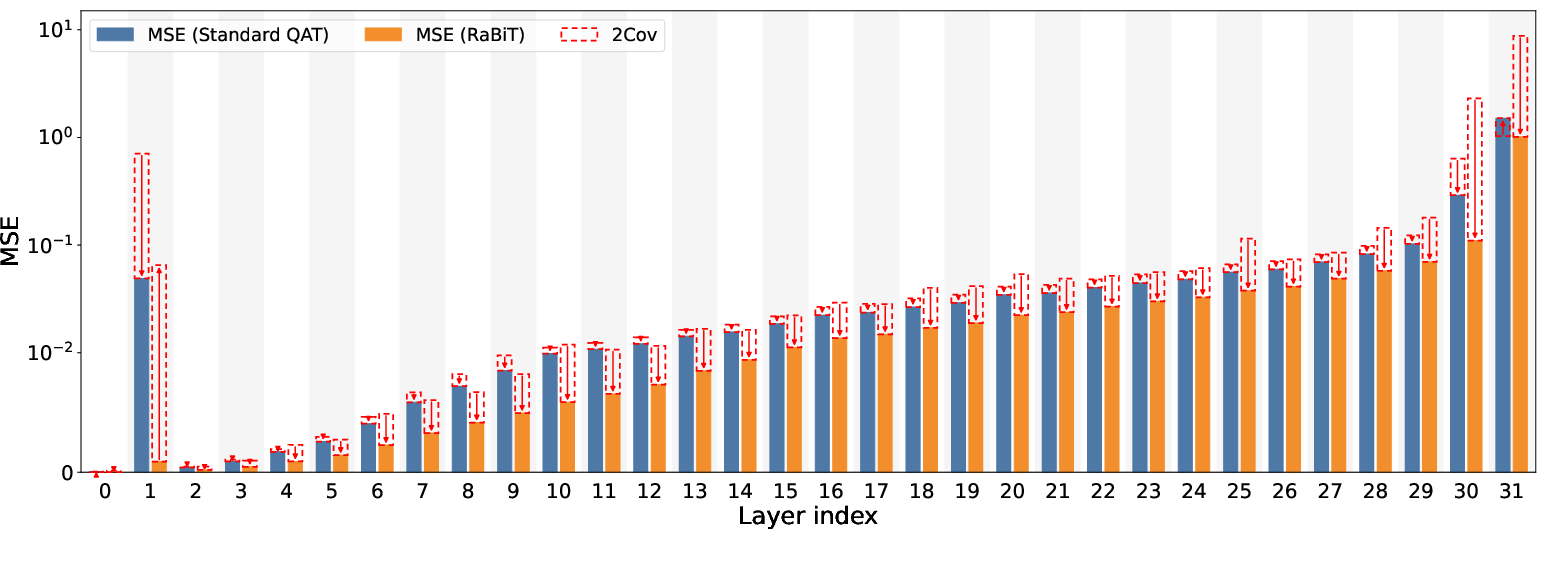
Figure 4: RaBiT's negative covariance term in layer-wise decomposition actively reduces total MSE, confirming structural loss reduction.
Theoretical Implications and Future Directions
RaBiT fundamentally resolves inter-path adaptation in binary-quantized residual architectures, establishing negative correlation and robust error-correction where prior methods were structurally incapable. The approach generalizes to the KL divergence loss used in contemporary LLM training, optimally canceling bias terms that destabilize standard QAT. The results support the hypothesis that enforcing a learnable residual hierarchy enables matmul-free architectures to approach, and even surpass, conventional hardware-intensive quantizers without constraining the solution space or optimization dynamics.
Practical implications are profound: RaBiT enables deployment of high-fidelity LLMs on consumer-grade hardware, democratizing access and enhancing privacy by facilitating local computation. The method halves optimizer state memory, providing scalable efficiency for both training and inference. However, the effects of extreme quantization on safety alignment remain insufficiently understood and warrant further investigation.
Future work should examine RaBiT's stabilization of layer sensitivity, its extension to deeper model quantization, and integration with adaptive bit allocation. The structural principles underlying residual coupling may prove essential for reliable low-bit generalization in future large-scale AI systems.
Conclusion
RaBiT offers a principled and efficient solution for 2-bit LLM quantization, combining optimal coupled training with initialization strategies focused on functional preservation. The framework eliminates redundancy in residual binarization, achieves hardware-efficient accuracy previously unobtainable without costly vector quantization, and scales to diverse architectures and tasks. By addressing fundamental bottlenecks in extreme quantization, RaBiT establishes a robust foundation for future research in scalable, high-performance LLM compression (2602.05367).