- The paper presents CSRv2’s main contribution of integrating a k-annealing schedule to reduce dead neurons, cutting inactive rates from over 80% to ~20% at k=2.
- It introduces supervised sparse contrastive learning with end-to-end backbone finetuning, enhancing semantic alignment and task-specific performance on text and vision benchmarks.
- CSRv2 achieves significant efficiency gains with up to 300× improvement in compute/memory, while maintaining competitive accuracy against dense and medium-sparse baselines.
Ultra-Sparse Embedding Viability: A Technical Assessment of CSRv2
Motivation and Context
High-dimensional embeddings are a mainstay in modern large foundation models, driving semantic retrieval, classification, and recommendation, but they impose significant efficiency bottlenecks—particularly for real-time, large-scale, or resource-constrained deployments. Prior efficiency methods such as Matryoshka Representation Learning (MRL) and Contrastive Sparse Representation (CSR) offer partial solutions via dimension truncation or sparsification, respectively. However, both approaches deteriorate rapidly at extreme compression levels: notably, when only two or four active features are allowed (k≤4), accuracy declines sharply and most neurons remain dead.
CSRv2 is proposed specifically to address this ultra-sparse regime, which promises orders-of-magnitude reductions in memory and compute for practical applications, but has proven intractable using existing protocols due to dead neuron accumulation, downstream misalignment, and limited model capacity.
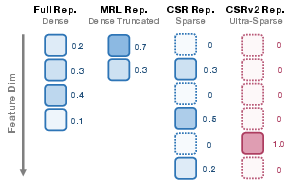
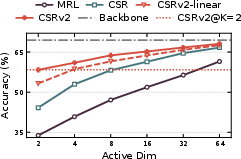
Figure 1: CSRv2’s embedding method achieves ultra-sparse representations, delivering high text embedding performance on diverse MTEB tasks compared to dense and medium-sparse alternatives.
Core Contributions and Algorithmic Innovations
Dead Neuron Mitigation via k-Annealing
Sparse representations inherently risk neuron inactivity, especially as k declines. Standard methods struggle as most neurons receive no gradient, becoming permanently dead. CSRv2 introduces a curriculum learning-based k-annealing schedule: training commences at high sparsity (kinit=64), gradually annealing to target k=2 or $4$. This strategy maintains activation diversity and preserves gradient flow, reducing dead neuron ratio from >80% to ~20% for k=2, as demonstrated empirically.
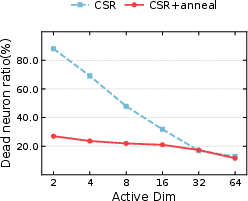
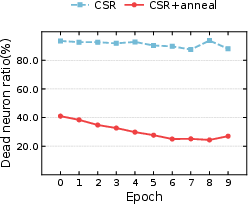
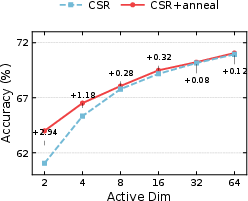
Figure 2: Progressive k-annealing sharply reduces dead neuron ratios and improves 1-NN accuracy on ImageNet-1k under ultra-sparse conditions.
Supervised Sparse Contrastive Learning
CSRv1 leverages self-supervised objectives (autoencoding and augmentation-based contrastive learning), but these signals become unreliable when information must be concentrated in very few active features. CSRv2 replaces this with supervised sparse contrastive losses: positive pairs are formed directly from real task labels (classification, retrieval, etc.), ensuring the active features encode task-relevant signals. This results in discriminative, downstream-aligned sparse embeddings with far greater robustness.
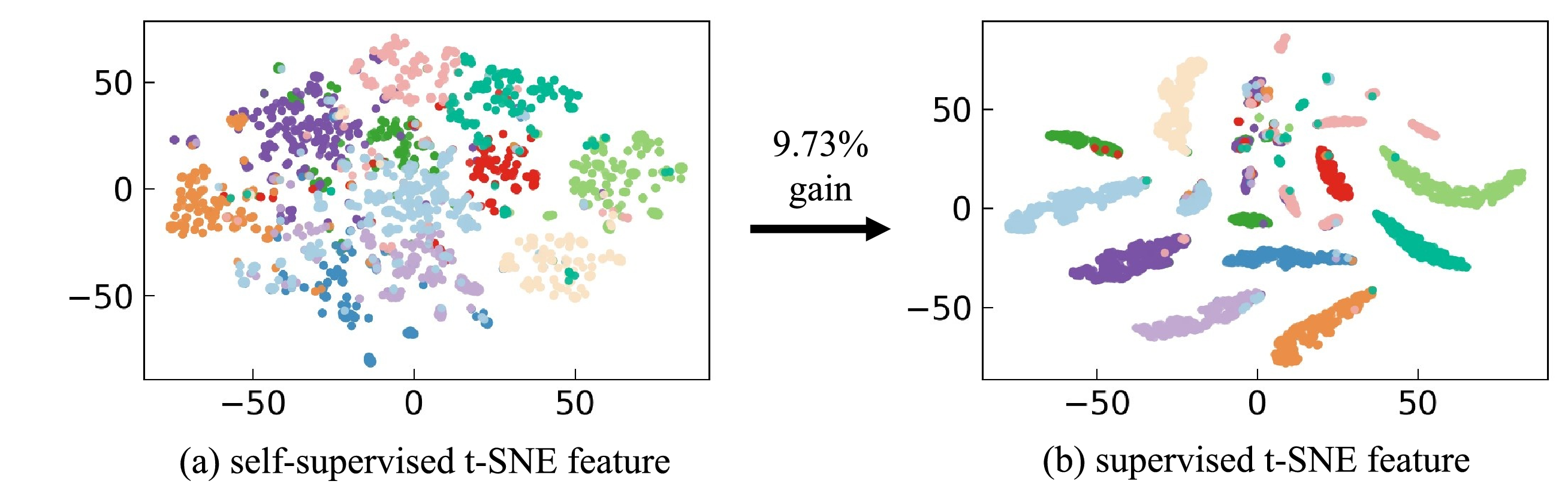
Figure 3: t-SNE visualizations reveal that supervision yields task-aligned, well-separated feature distributions under ultra-sparse activation (k=2).
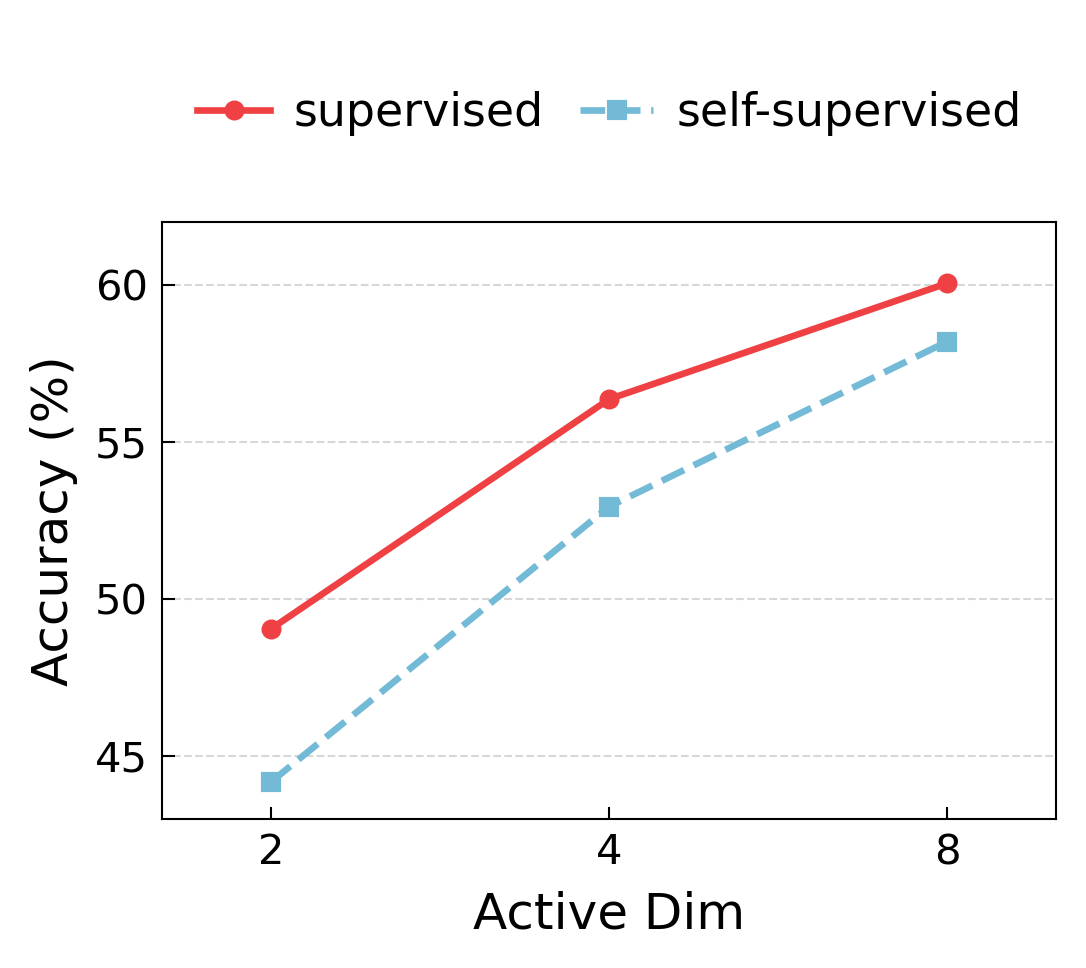
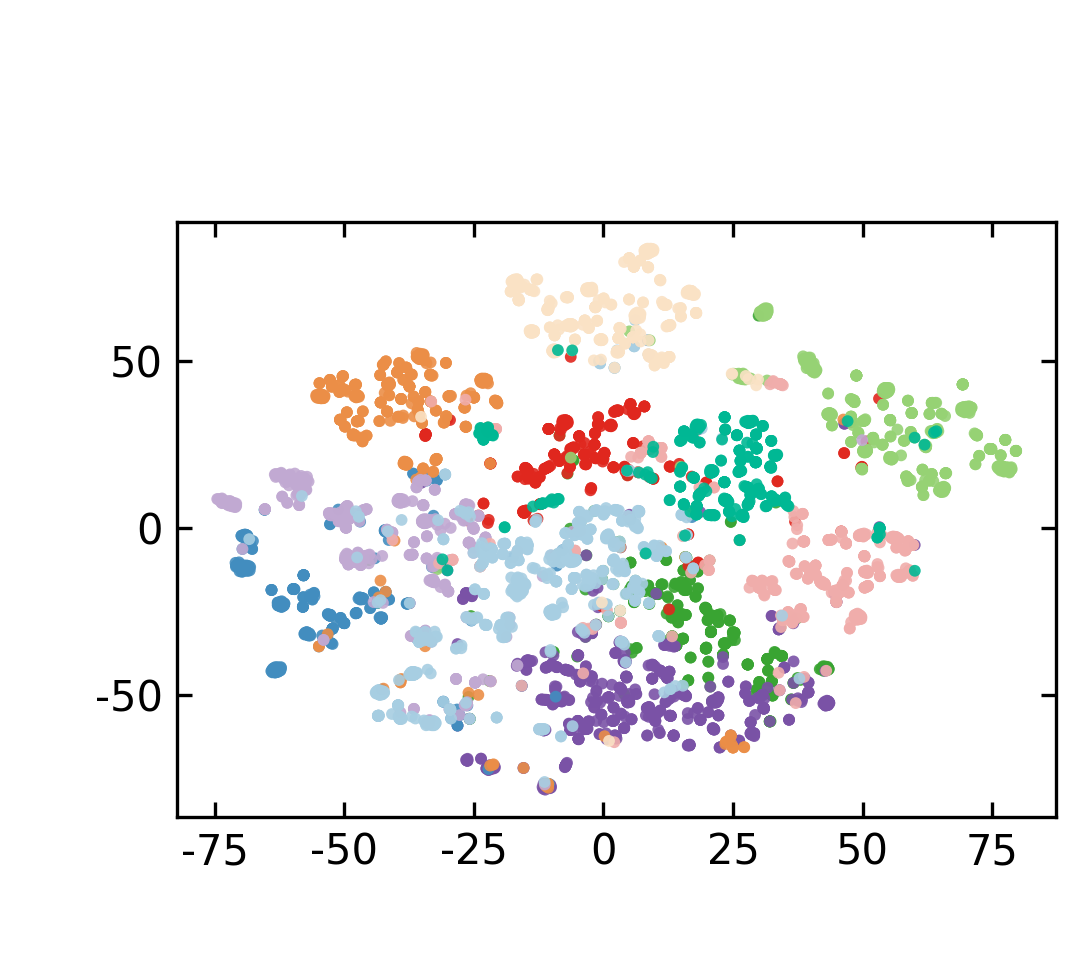
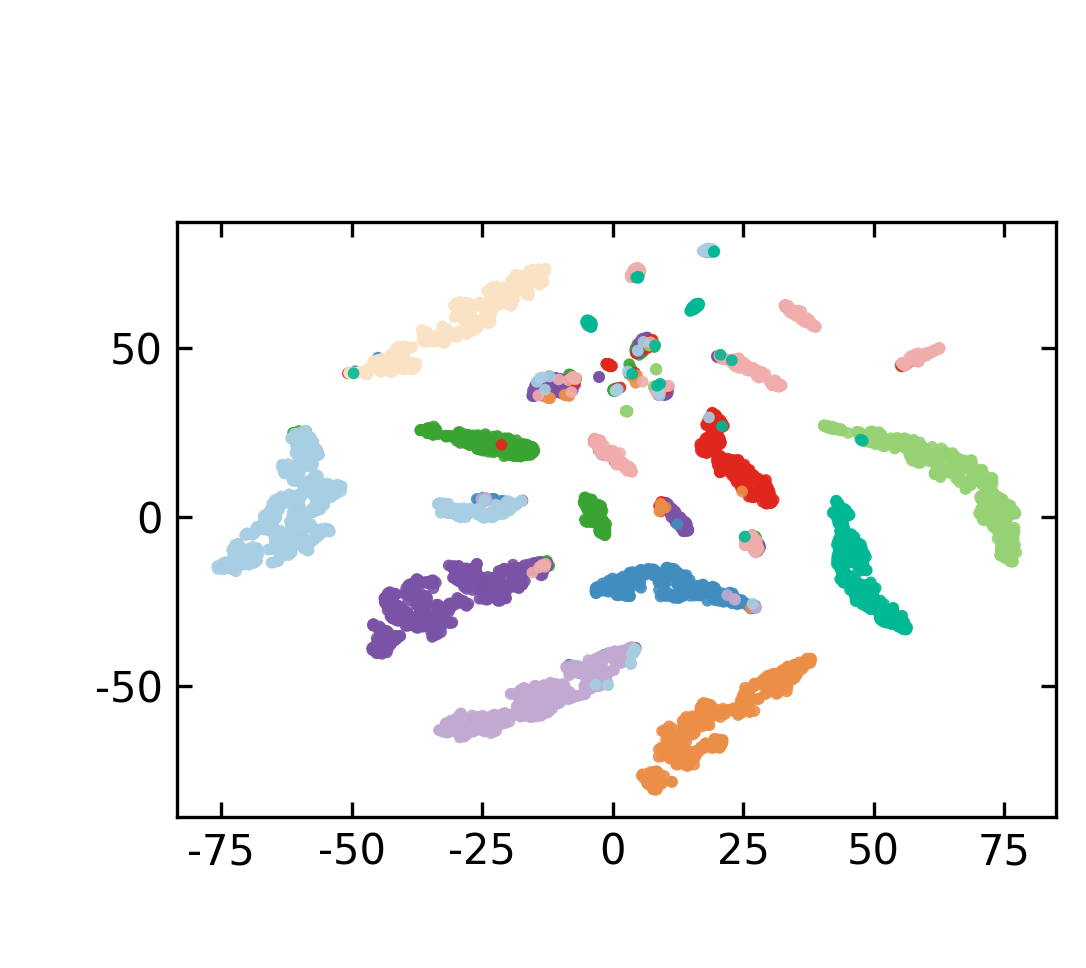
Figure 4: Supervision boosts classification accuracy in ultra-sparse settings and produces distinct feature clusters in MTOPDomain.
End-to-End Backbone Finetuning
Standard CSR only adapts a linear layer on top of frozen backbone embeddings, which is insufficient for multi-domain robustness. CSRv2 enables full backbone finetuning with supervised sparse contrastive objectives, establishing new state-of-the-art performance and generalization across data regimes.
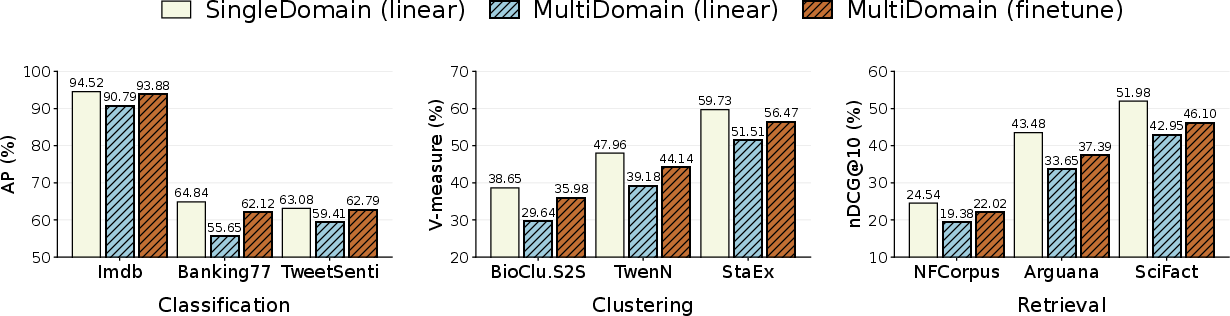
Figure 5: Comprehensive finetuning on multi-domain datasets with CSRv2 achieves consistent gains in classification, retrieval, and clustering tasks.
Benchmark Results and Efficiency Gains
CSRv2 is validated rigorously across text (MTEB benchmark, e5-mistral-7b-instruct, Qwen3) and vision (ImageNet-1k). At k=2, CSRv2 outperforms CSR by 14% (text) and 6% (vision); at k=4, the gains are 7% and 4% respectively. Ultra-sparse CSRv2 achieves parity with MRL at much higher dimensions (CSRv2-k=2 matches MRL-32) and rivals CSR-k=8 with only two activated features. Efficiency analysis shows 7× faster retrieval against MRL and up to 300× compute/memory improvement over dense embeddings.
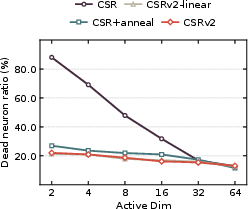
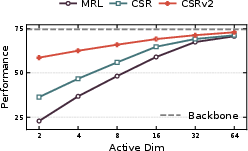
Figure 6: Dead neuron analysis across methods with fixed ResNet-50 backbone; CSRv2 achieves dramatically lower inactivity in sparse regimes.
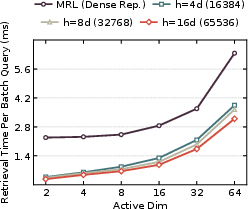
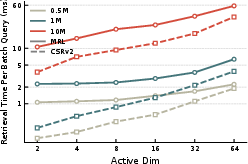
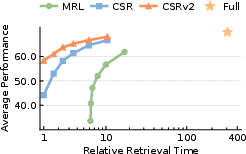
Figure 7: CSRv2 retrieval efficiency holds steady as hidden dimension and database scale increase, greatly outperforming dense baselines in throughput.
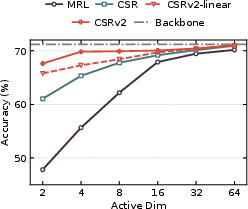
Figure 8: Visual embedding evaluation and dead neuron tracking across compression levels confirm CSRv2’s superior accuracy and efficiency.
Ablation and Sensitivity Studies
Ablation experiments verify that k-annealing and supervision are each individually beneficial, but their combination with full finetuning is synergistic, especially under extreme sparsity. Dead neuron ratios are primarily controlled by annealing, while accuracy is maximally improved only when supervision and backbone adaptation are included. The k-annealing schedule exhibits robust performance across choices of schedule shape, annealing length, and initial k.
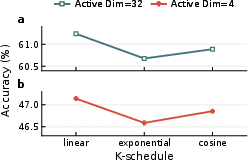
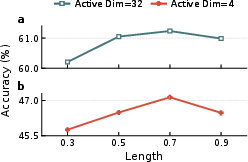
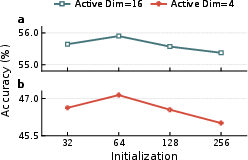
Figure 9: k-annealing sensitivity studies confirm that linear schedules, 70% annealing, and kinit=64 deliver optimal results under varying configurations.
Interpretability and Semantic Structure
Empirical analysis of 2D feature projections (IMDb dataset) shows that CSRv2’s supervised sparse features achieve both fine-grained semantic interpretability and global sentiment separation, outperforming both MRL (dense) and CSR (unsupervised sparse). Neuron activation studies further confirm that under ultra-sparsity, features specialize to emotionally salient task signals.
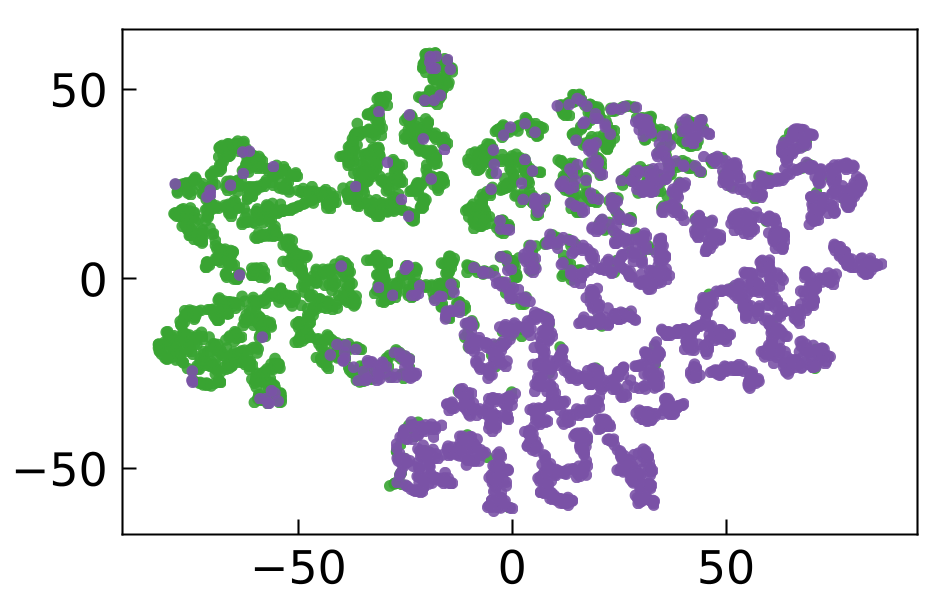

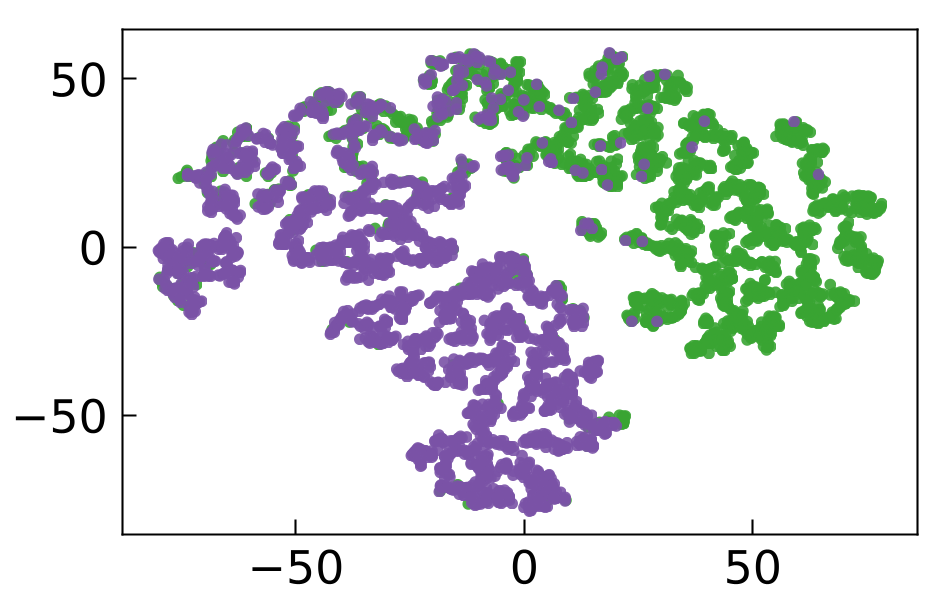
Figure 10: CSRv2 2D embeddings yield highest sentiment AP scores and interpretable separation in IMDb reviews.
Practical and Theoretical Implications
CSRv2 establishes that ultra-sparse embeddings are not inherently constrained, but rather require a fundamentally different optimization regime: k-annealing for activation coverage and supervised contrastive learning for semantic precision. This unlocks a new design space for large-scale, real-time, and edge AI systems, supporting efficient vector search, semantic retrieval, and resource-aware deployment without accuracy compromise.
CSRv2’s compatibility with standard quantization and indexing schemes (PQ, AVQ, etc.) further strengthens its practical value for production-scale retrieval and recommendation pipelines. Dead neuron minimization and semantic alignment carry strong implications for interpretability and mechanistic feature analysis, supporting ongoing work in sparse codes and feature disentanglement.
Theoretical extrapolation suggests that k=1 (hard clustering) remains a difficult frontier, likely requiring entirely new approaches (balanced assignment, entropy maximization, prototype-based learning). However, the regime k∈{2,4,8} is now reliably addressable, with direct utility in low-latency applications.
Conclusion
CSRv2 delivers a principled, generic, and empirically validated recipe that renders ultra-sparse embeddings both practicable and competitive, surpassing dense and medium-sparse baselines in efficiency without sacrificing semantic quality or accuracy. With curriculum k-annealing and supervised sparse contrastive objectives, CSRv2 redefines the viability frontier for extreme embedding compression, offering robust solutions for modern AI deployment and opening avenues for future research in interpretability, quantization, and further sparsity-driven architectures.