FMPose3D: monocular 3D pose estimation via flow matching
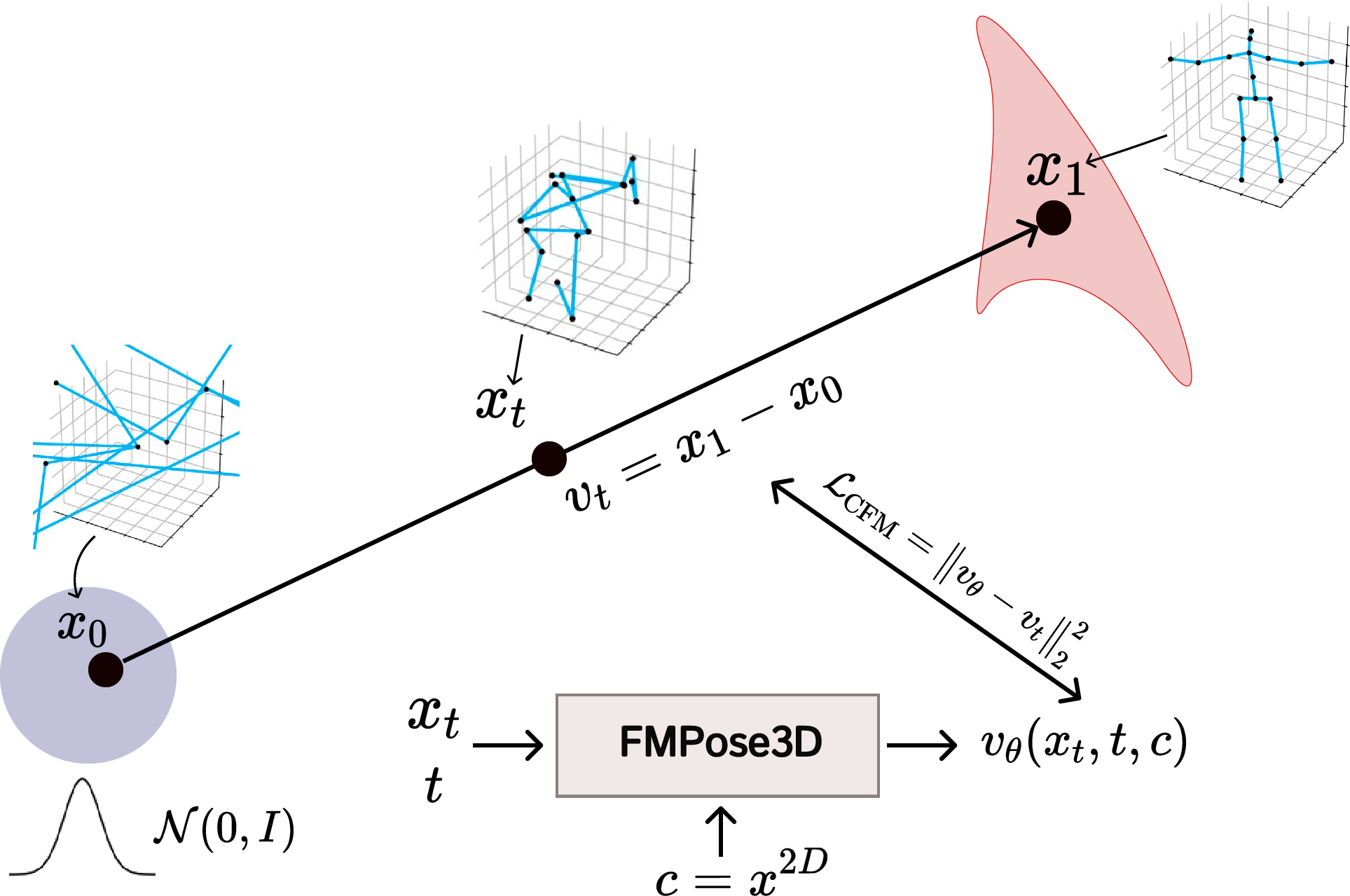
Abstract: Monocular 3D pose estimation is fundamentally ill-posed due to depth ambiguity and occlusions, thereby motivating probabilistic methods that generate multiple plausible 3D pose hypotheses. In particular, diffusion-based models have recently demonstrated strong performance, but their iterative denoising process typically requires many timesteps for each prediction, making inference computationally expensive. In contrast, we leverage Flow Matching (FM) to learn a velocity field defined by an Ordinary Differential Equation (ODE), enabling efficient generation of 3D pose samples with only a few integration steps. We propose a novel generative pose estimation framework, FMPose3D, that formulates 3D pose estimation as a conditional distribution transport problem. It continuously transports samples from a standard Gaussian prior to the distribution of plausible 3D poses conditioned only on 2D inputs. Although ODE trajectories are deterministic, FMPose3D naturally generates various pose hypotheses by sampling different noise seeds. To obtain a single accurate prediction from those hypotheses, we further introduce a Reprojection-based Posterior Expectation Aggregation (RPEA) module, which approximates the Bayesian posterior expectation over 3D hypotheses. FMPose3D surpasses existing methods on the widely used human pose estimation benchmarks Human3.6M and MPI-INF-3DHP, and further achieves state-of-the-art performance on the 3D animal pose datasets Animal3D and CtrlAni3D, demonstrating strong performance across both 3D pose domains. The code is available at https://github.com/AdaptiveMotorControlLab/FMPose3D.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Explaining “FMPose3D: Monocular 3D Pose Estimation via Flow Matching”
What is this paper about?
This paper is about teaching a computer to figure out how a body (human or animal) is posed in 3D using only a single picture or a single video frame. That’s called “monocular 3D pose estimation” (mono = one). The authors introduce a new method, called FMPose3D, that makes smart, fast guesses about possible 3D poses and then combines those guesses into one accurate answer.
What questions are the researchers trying to answer?
The paper focuses on three simple questions:
- How can we turn a 2D picture (with joint locations marked) into a correct 3D pose, even though many 3D poses can look the same in 2D?
- Can we generate multiple good 3D guesses quickly, instead of slowly refining one guess?
- How do we pick or combine those guesses to get the most accurate final 3D pose?
How does the method work (in plain language)?
Think of it like this:
- You start with a single photo where you’ve already found 2D keypoints (like where the elbows, knees, and shoulders are on the image).
- The big challenge is “depth”: from just one picture, you don’t see how far forward or backward each joint is. Many 3D poses can project to the same 2D picture.
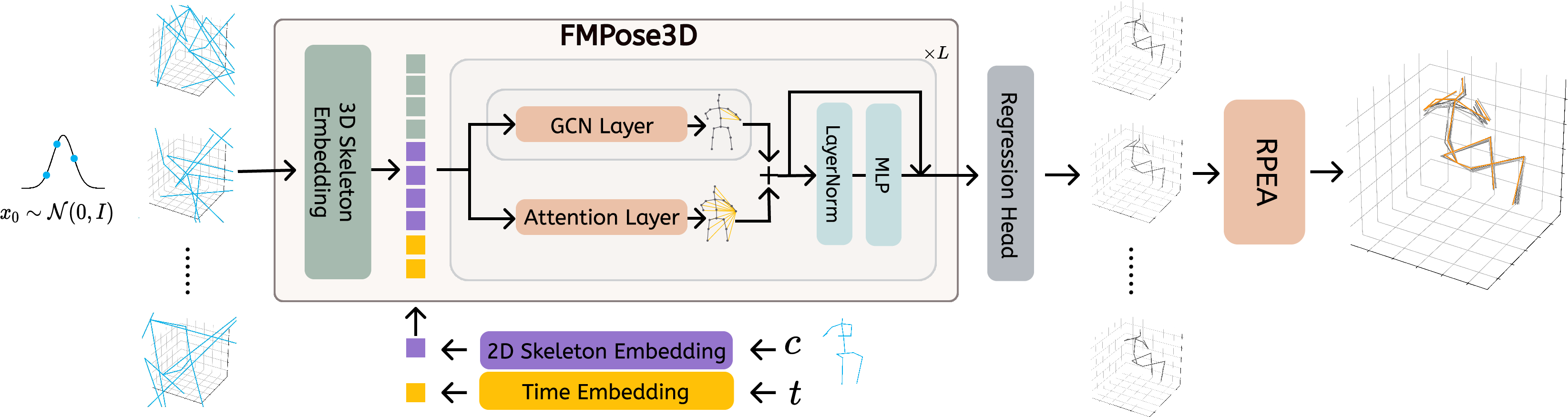
FMPose3D solves this by doing two things:
- Flow Matching (FM): Fast, guided generation of pose guesses
- Imagine placing a bunch of “points” (joints) at random positions in 3D space. Now imagine a gentle “wind” (a learned rule) that pushes these points from randomness toward a realistic 3D pose that matches the 2D keypoints.
- This “wind” is learned using a technique called flow matching. It’s an ODE-based method (an Ordinary Differential Equation) that teaches the model how to move from noise to a good pose smoothly and quickly.
- Compared to diffusion models (which are like cleaning a very noisy picture step-by-step many times), flow matching needs only a few steps, so it’s much faster.
- Each different random start (different “noise seed”) produces a different plausible 3D pose. That’s how the model generates multiple good guesses.
- RPEA (Reprojection-based Posterior Expectation Aggregation): Smart combining of guesses
- After making several 3D guesses, the model checks how well each guess matches the original 2D keypoints when you “re-project” it back onto the image.
- If a guess re-projects well (small error in 2D), it’s probably a good 3D pose.
- RPEA uses this idea to weigh each guess and average them in a smart way, joint by joint or pose by pose, to produce one final, accurate 3D result.
- In simple terms: it’s like voting, but with better guesses getting more votes.
What did they test, and what did they find?
The researchers tested FMPose3D on well-known datasets:
- Human3.6M (humans indoors)
- MPI-INF-3DHP (humans indoors and outdoors)
- Animal3D (real animal images with 3D labels)
- CtrlAni3D (synthetic animal images with accurate labels)
Important results:
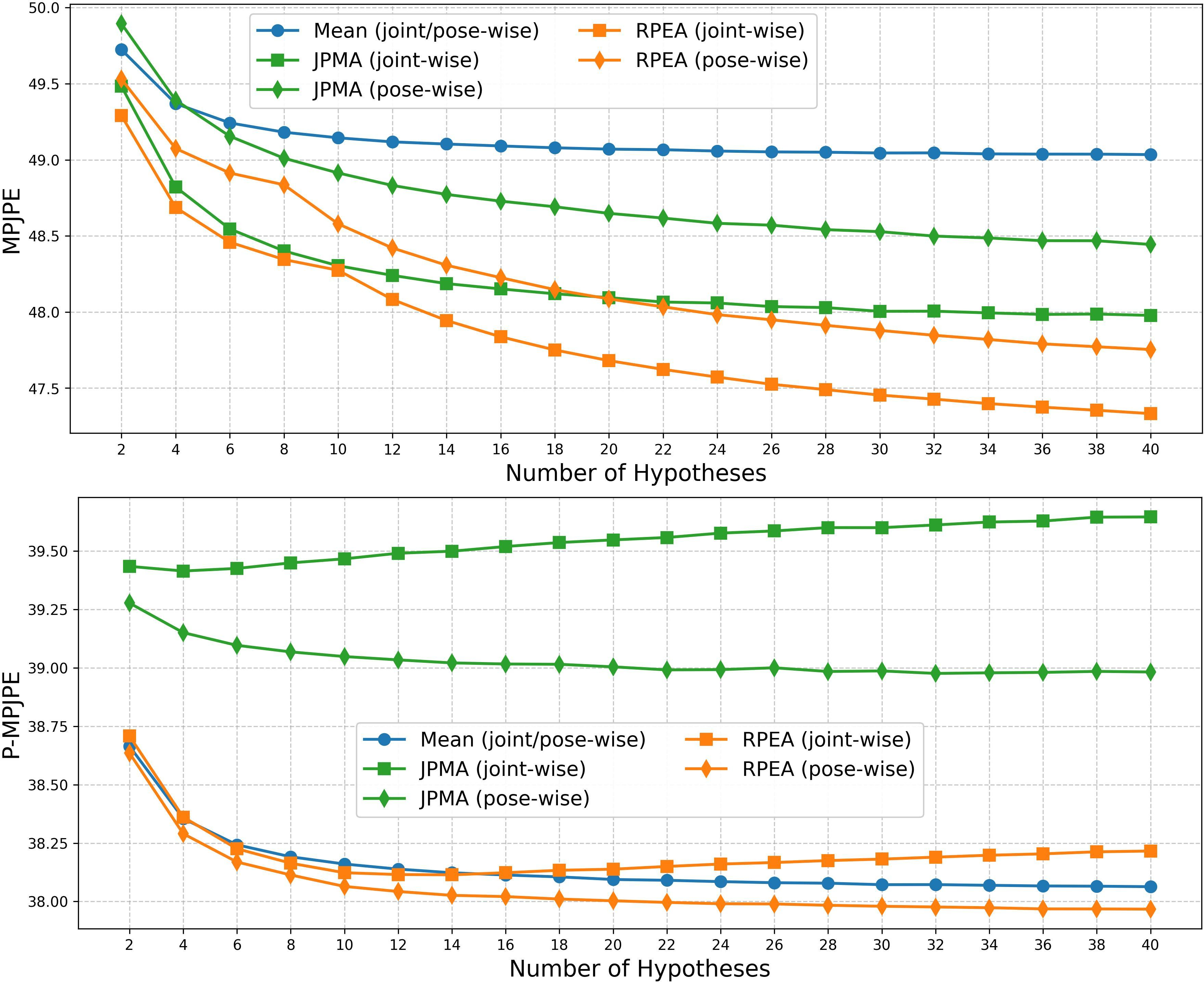
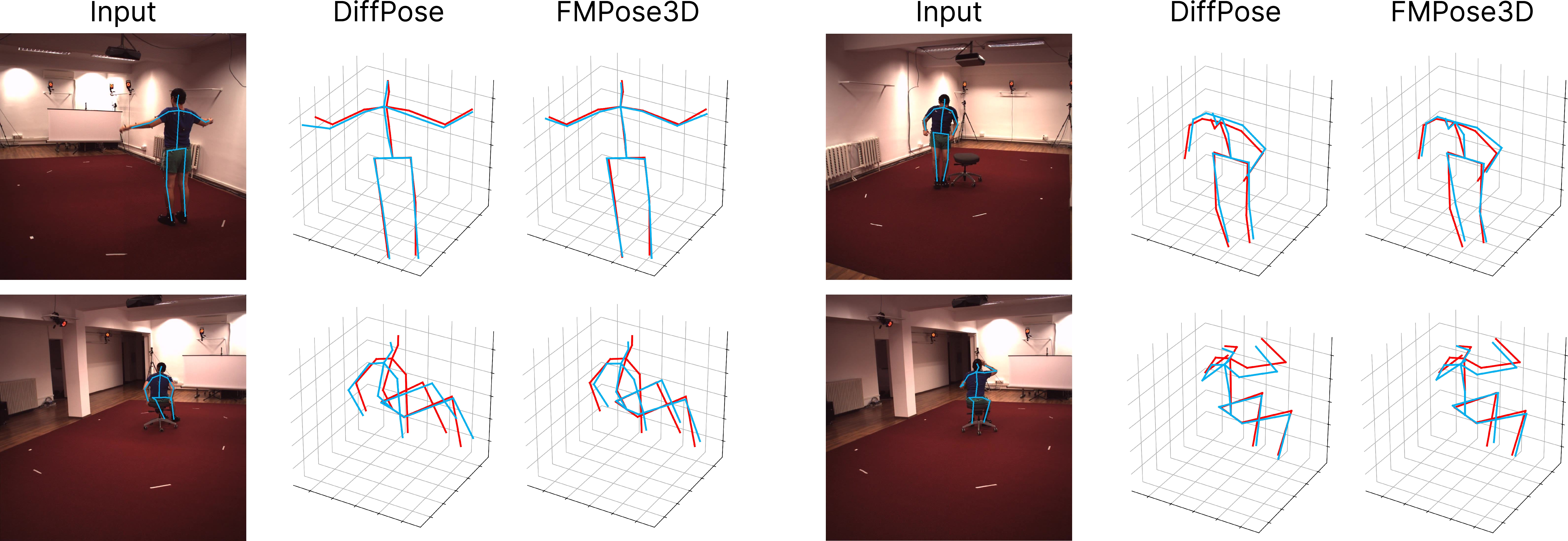
- Accuracy: FMPose3D beat or matched the best existing methods on these datasets. On Human3.6M, it improved the error (MPJPE) compared to strong baselines. It also achieved top scores on MPI-INF-3DHP and performed best on the animal datasets.
- Speed: It runs very fast. Even when generating many different hypotheses (like 40 guesses), it still works at real-time speeds (over 140 frames per second on a modern GPU), much faster than diffusion-based methods.
- Robustness: The smart combining (RPEA) improved accuracy more than simply averaging all guesses or picking just the single “best” guess.
Why is this important?
- Real-time applications: Because it’s fast, FMPose3D can be used in live systems like motion capture for animation, AR/VR, sports analysis, and robotics.
- Better understanding from one camera: It handles the tricky problem of depth from a single view by generating multiple plausible poses and then smartly combining them.
- Works for humans and animals: It’s not just for people; it also works well on animals, which vary a lot in shape and movement.
What does this mean for the future?
- Faster and smarter 3D pose: Flow matching gives a powerful way to quickly generate multiple realistic 3D poses. This could help many fields that need speed and accuracy.
- Better decision-making from uncertainty: The RPEA module shows how to turn many good guesses into one great answer, which is useful in lots of AI problems where there’s uncertainty.
- Broader applications: The method can be extended to other tasks (like tracking over time, different body types, or more complex scenes) and could improve tools in film, gaming, healthcare, sports, and animal behavior research.
In short, FMPose3D makes 3D pose estimation from a single image faster, more accurate, and more practical by quickly generating multiple good 3D guesses and cleverly combining them into one reliable result.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of unresolved issues that the paper leaves open, framed to be immediately actionable for future work.
- Dependence on 2D keypoints accuracy: results on MPI-INF-3DHP use ground-truth 2D joints, obscuring robustness under realistic detector noise. Evaluate with detector-produced 2D inputs (with occlusions, misses) and quantify degradation vs. confidence-weighted conditioning.
- Camera model assumptions in RPEA: the reprojection-based pseudo-likelihood requires known camera intrinsics/extrinsics, but details are unspecified and in-the-wild cameras are typically unknown. Investigate joint camera–pose inference, marginalization over camera uncertainty, and robustness to calibration errors and lens distortion.
- Posterior calibration and probabilistic evaluation: while the model is generative, there is no assessment with proper scoring rules (e.g., NLL via density surrogates, CRPS), calibration curves, coverage of credible sets, or sharpness. Develop evaluation protocols and metrics to verify that samples and RPEA estimates are well-calibrated posteriors.
- Diversity vs. accuracy trade-off: the paper does not quantify sample diversity, mode coverage, or correlation among hypotheses relative to diffusion baselines. Measure diversity (e.g., pairwise distances, coverage of multiple valid depths), success-at-k, and minMPJPE, and explore diversity-promoting seeding (quasi–Monte Carlo, Latin hypercube).
- Path choice in conditional flow matching: training uses a linear interpolation path from Gaussian to data, which can traverse off-manifold regions and bias the learned field. Compare alternative paths (e.g., rectified flows, curved/geodesic paths, noise-conditioned paths) and analyze their impact on sample quality, mode coverage, and required steps.
- ODE integration details: inference uses explicit Euler with S=3 steps; stability, error bounds, and optimality are unstudied. Benchmark alternative integrators (Heun, RK2/4, adaptive stepping), assess one-step sampling viability, and quantify accuracy–latency trade-offs.
- RPEA hyperparameters and design: the temperature α and Top-K are fixed and hand-tuned; no sensitivity or adaptive strategy is provided. Study data-driven or learned α/K, per-joint vs. pose-wise selection under constraints, and end-to-end training of the aggregator.
- RPEA likelihood surrogate limitations: weighting solely by 2D reprojection error ignores 3D plausibility (bone lengths, joint-angle limits). Integrate learned 3D priors, kinematic constraints, or energy-based scores into the weighting to prevent anatomically inconsistent aggregations.
- Handling occlusions and missing 2D joints: RPEA assumes all joints have valid reprojection losses. Develop occlusion-aware likelihoods that downweight missing/low-confidence joints and evaluate on occlusion-heavy scenarios.
- Temporal extension: the method is single-frame; temporal dynamics, motion consistency, and physics priors are not exploited. Extend to video with temporal flow fields, recurrent conditioning, and smoothness/physics constraints; evaluate on sequential benchmarks.
- Multi-view extension: the framework is monocular by design. Formulate multi-view conditional flow matching with cross-view consistency and a multi-view RPEA, and quantify gains on datasets with multiple cameras.
- Absolute scale and depth ambiguity: treatment of metric scale under perspective projection is not discussed. Evaluate absolute depth recovery, incorporate monocular depth/scale priors, and report scale-sensitive metrics.
- Cross-dataset generalization fairness: claims of generalization (H36M→3DHP) are confounded by GT 2D inputs at test time. Re-run cross-dataset tests with detector 2D joints and report domain-shift robustness.
- Animal domain generality: the approach assumes a fixed joint set and is not evaluated on unseen species/skeletons with different topologies. Explore species-conditioned flows, skeleton-agnostic representations, and adaptation to unseen taxa.
- Use of RPEA for animals: RPEA is not applied/evaluated on Animal3D/CtrlAni3D. Test whether multi-hypothesis aggregation helps under morphological variability and pseudo-label noise.
- Noisy or weak 3D supervision: robustness to noisy 3D labels (e.g., SMAL pseudo-annotations) is not analyzed. Investigate weak/self-supervised training with 2D reprojection, cycle consistency, or multi-view consistency losses.
- Multi-person scenes: applicability to crowded scenes with inter-person occlusions and identity association is not addressed. Extend conditioning to multi-instance 2D detections and test on multi-person datasets.
- End-to-end real-time claims: FPS excludes 2D detection and assumes an RTX 4090. Report end-to-end latency (detector + lifting), CPU/edge device performance, memory/energy footprints, and batching effects.
- Conditioning beyond 2D keypoints: only 2D joints are used as condition. Evaluate adding image features (RGB, segmentation, monocular depth), text/action cues, or scene context to reduce 3D ambiguity.
- Structural constraints during sampling: the velocity field is trained with an L2 velocity loss only. Explore training with kinematic penalties, learned anatomical constraints, or differentiable forward kinematics to keep trajectories on the pose manifold.
- Seed correlation and sampling strategy: independence and coverage of hypotheses drawn from different noise seeds are unexamined. Analyze correlation across seeds and develop diversity-aware sampling schemes.
- Base distribution choice: a standard Gaussian prior may be misaligned with pose manifolds. Study learned base distributions or preconditioners (e.g., normalizing flows over kinematic latents) to ease transport.
- Theoretical justification for pseudo-posterior: the approximation p(H|X2D) ∝ exp(−α·Lreproj) lacks analysis of bias/consistency. Derive conditions where this surrogate approximates the true posterior and compare to learned likelihood models or discriminators.
- Failure mode analysis: systematic errors (e.g., extreme foreshortening, sitting/crouching, heavy occlusions) are not characterized. Curate a failure taxonomy and quantify action/pose-specific weaknesses to guide targeted improvements.
- Evaluation breadth: results on additional in-the-wild datasets (e.g., 3DPW) and robustness studies are deferred to the supplement. Integrate these evaluations in the main paper and add stress tests (domain shift, sensor noise, calibration drift).
Practical Applications
Practical Applications of FMPose3D (Monocular 3D Pose via Flow Matching)
FMPose3D introduces a fast, probabilistic, markerless 3D pose estimator from a single RGB view by: (i) casting 2D-to-3D pose lifting as conditional flow matching for efficient sampling (3 ODE steps, 145–160 FPS on RTX 4090), and (ii) aggregating multiple 3D hypotheses with a reprojection-based posterior expectation (RPEA) for robust single-pose outputs. It demonstrates strong performance on humans and animals.
Below are actionable use cases grouped by deployment horizon, with sector tags, envisioned tools/products/workflows, and key assumptions/dependencies.
Immediate Applications
- Real-time, markerless motion capture for AR/VR and media production
- Sector: Software, Gaming, Media/Animation
- What: Drive avatars and pre-visualize motion from a single camera in real time; retarget to skeletons in Unity/Unreal; live motion streaming for VTubing and virtual events.
- Tools/workflows: Camera feed → 2D keypoint detector (e.g., OpenPose/Detectron2/HRNet) → FMPose3D (S=3) → RPEA → retarget → smoothing.
- Assumptions/dependencies: Reliable 2D keypoints; mostly single-person scenes; moderate occlusion; consumer GPU or optimized on-device inference.
- Sports broadcast analytics and coaching
- Sector: Sports Tech
- What: On-the-fly 3D pose metrics (joint angles, ROM, velocity) from broadcast or training footage; highlight uncertain joints via multi-hypothesis consistency.
- Tools/workflows: Ingest video → per-frame 2D detection → FMPose3D + RPEA → analytics overlay → coaching dashboard.
- Assumptions/dependencies: Camera viewpoint variability; optional camera calibration for metric scale; domain tuning for sports poses.
- Ergonomics and workplace safety monitoring
- Sector: Industrial/Occupational Health
- What: Low-cost posture risk scoring and alerting (e.g., RULA/REBA-like heuristics) without wearables; uncertainty-aware alerts using hypothesis spread.
- Tools/workflows: On-prem cameras → edge 2D keypoints → FMPose3D → posture scoring → alerting/BI.
- Assumptions/dependencies: Privacy/compliance; line-of-sight constraints; model adaptation to PPE and occlusions.
- Human–robot interaction (HRI) safety and intent cues
- Sector: Robotics
- What: Low-latency human pose for safety zones, handovers, and intent estimation; use uncertainty (multi-hypothesis) to trigger conservative behaviors.
- Tools/workflows: Robot vision → 2D keypoints → FMPose3D real-time → safety controller/HRI planner.
- Assumptions/dependencies: Single view coverage; tight timing on embedded GPUs; occlusions around manipulators.
- In-cabin driver/occupant monitoring (prototype-level)
- Sector: Automotive (R&D)
- What: Posture and limb tracking for distraction detection and restraint optimization; works with monocular RGB/IR streams.
- Tools/workflows: In-cabin camera → 2D keypoints → FMPose3D → state features → downstream DMS/OMS modules.
- Assumptions/dependencies: Domain shift (lighting, IR); regulatory validation pending; multi-occupant disambiguation needed.
- Consumer fitness and form feedback (non-clinical)
- Sector: Consumer Health/Fitness Apps
- What: Real-time form guidance for workouts/yoga using phone/laptop camera; confidence-weighted feedback.
- Tools/workflows: On-device 2D keypoint model → FMPose3D (pruned/quantized) → simple rules/ML for form scoring.
- Assumptions/dependencies: Model compression for mobile; camera placement guidance; non-medical disclaimers.
- Animal behavior and welfare monitoring in labs/farms
- Sector: AgTech, Academia
- What: Cage or pen camera pose tracking for activity patterns, lameness detection, and welfare indicators; supports multiple species.
- Tools/workflows: 2D animal keypoint detection → FMPose3D (trained on Animal3D/CtrlAni3D + target species) → behavior metrics.
- Assumptions/dependencies: Species-specific 2D detectors; camera vantage consistency; domain adaptation for farm environments.
- Fast 3D pre-annotations and active learning for datasets
- Sector: Academia, Data Ops
- What: Use multi-hypothesis outputs + RPEA to seed 3D labels, surface high-uncertainty frames for manual review, and accelerate curation.
- Tools/workflows: Batch video → N-hypotheses from FMPose3D → RPEA → uncertainty scoring → human-in-the-loop labeling UI.
- Assumptions/dependencies: Calibration optional; quality thresholds and QC pipelines needed.
- Enhanced action recognition via 3D skeletons
- Sector: Video Analytics, Security/Surveillance
- What: Feed 3D joint trajectories to action/activity recognition models for improved robustness over 2D-only features.
- Tools/workflows: Video → 2D keypoints → FMPose3D → 3D feature streams → action classifier.
- Assumptions/dependencies: Privacy-by-design; multi-person tracking extensions; dataset/domain adaptation.
- On-device, privacy-preserving pose pipelines
- Sector: Mobile/Edge AI
- What: Keep processing local by combining efficient 2D detectors with S=3-step FMPose3D on phones or embedded devices.
- Tools/workflows: Model distillation/quantization → deployment with Core ML/NNAPI/TensorRT → local analytics.
- Assumptions/dependencies: Performance depends on hardware; thermal/power limits; reduced accuracy with heavy compression.
Long-Term Applications
- Clinical-grade gait and movement disorder assessment
- Sector: Healthcare (Regulated)
- What: Remote or in-clinic 3D motion quantification for diagnostics and progression tracking (e.g., Parkinson’s, post-stroke).
- Tools/workflows: Validated acquisition protocols → calibrated setup → FMPose3D with medical-grade QA → clinician dashboards.
- Assumptions/dependencies: Regulatory approvals; rigorous validation; may require multi-view or sensor fusion for reliability.
- Wildlife conservation and ecology at scale
- Sector: Environmental/Conservation
- What: 3D pose from camera traps/drones to study locomotion, injury, or behavioral ecology across species in the wild.
- Tools/workflows: Species-adaptive 2D detectors → FMPose3D fine-tuned per biome → SfM-based camera calibration (if needed) → ecological analytics.
- Assumptions/dependencies: OOD generalization; sparse viewpoints; challenging lighting/occlusion; camera calibration strategies.
- Smart-city crowd behavior analytics and safety
- Sector: Public Policy, Urban Computing
- What: Aggregate pose signals for crowd safety, falls, or hazard detection with anonymized skeletons instead of raw video.
- Tools/workflows: Multi-camera ingestion → multi-person 2D detection/tracking → scalable FMPose3D → event detection and dashboards.
- Assumptions/dependencies: Multi-person lifting and tracking; compute scaling; strict privacy governance and auditing.
- Large-scale robot learning from human demonstrations
- Sector: Robotics/Embodied AI
- What: Use 3D human poses as compact supervision for imitation learning/teleoperation; uncertainty-aware training signals.
- Tools/workflows: Dataset generation from videos → FMPose3D → keypoint-to-robot retargeting → policy learning.
- Assumptions/dependencies: High-fidelity hand/finger/keypoint coverage; occlusion robustness; mapping to robot kinematics.
- Automated officiating and biomechanics in professional sports
- Sector: Sports and Entertainment
- What: Precise 3D joint analysis for judging, foul detection, and performance science during live events.
- Tools/workflows: Calibrated stadium cameras → high-reliability pose → rule-aware decision systems → broadcast integrations.
- Assumptions/dependencies: Standardized calibrations; fairness/appeals processes; vendor certification; multi-person robustness.
- Advanced automotive safety and restraint control
- Sector: Automotive (Safety-Critical)
- What: Real-time 3D occupant state for adaptive airbag deployment and crash mitigation.
- Tools/workflows: In-cabin IR/RGB → certified pose estimation → fusion with other sensors → safety controller.
- Assumptions/dependencies: ISO 26262 compliance; night/IR domain robustness; rigorous failure handling.
- Farm-scale, multi-species animal health platforms
- Sector: AgTech
- What: Continuous 3D motion-based health monitoring across barns and species with fleet cameras and cloud-edge orchestration.
- Tools/workflows: Edge inference for 2D+FMPose3D → centralized analytics → alerts and interventions.
- Assumptions/dependencies: Species-specific models; environmental variability; integration with farm management systems.
- K–12 and higher education curricula for biomechanics and physics
- Sector: Education
- What: Standardized, low-cost lab kits for teaching kinematics with single-camera 3D pose in classrooms.
- Tools/workflows: Bundled software + lesson plans → classroom capture → 3D analysis exercises.
- Assumptions/dependencies: Simplified setup; robust defaults without calibration; teacher training resources.
Cross-cutting assumptions and dependencies
- Input dependency on 2D keypoint quality: FMPose3D’s accuracy requires reliable 2D detections; poor 2D quality under heavy occlusions or rare poses degrades results.
- Camera model/projection: RPEA uses 2D reprojection errors; practical deployments may require known or approximated camera intrinsics/extrinsics (e.g., weak-perspective) for best performance.
- Single-person focus: The paper evaluates single-subject, monocular setups; multi-person and crowded scenes require tracking and per-person lifting extensions.
- Domain shift: Cross-dataset generalization is promising but in-the-wild robustness (lighting, clothing, accessories, species morphology) may require fine-tuning or domain adaptation.
- Hardware constraints: Reported 145–160 FPS is on a high-end GPU; mobile/edge deployment needs pruning, quantization, and performance tuning.
- Privacy and ethics: Human and animal monitoring use cases must address consent, on-device processing, data minimization, and regulatory compliance.
These applications leverage FMPose3D’s key advantages—fast inference, multi-hypothesis uncertainty modeling, and strong performance across humans and animals—to enable new products and workflows today, while laying groundwork for certified, at-scale systems in healthcare, automotive, conservation, and public safety.
Glossary
- 2D-to-3D lifting paradigm: A two-stage approach that first detects 2D keypoints and then predicts corresponding 3D joint coordinates. "Most recent works adopt a 2D-to-3D lifting paradigm"
- Animal3D: A multi-species dataset with pseudo-3D annotations for animal pose estimation derived from SMAL fits. "the 3D animal pose datasets Animal3D and CtrlAni3D"
- Area Under Curve (AUC): An evaluation metric that integrates PCK over a range of thresholds to summarize accuracy. "Percentage of Correct Keypoints (PCK) with a threshold of 150mm and the Area Under Curve (AUC) for a range of PCK thresholds for evaluation."
- base distribution: The simple source probability distribution that a generative flow transports to the data distribution. "was used to model the velocity field that transports a simple base distribution to the data distribution via ODEs."
- Bayesian decision theory: A framework for choosing estimators by minimizing expected loss under a posterior distribution. "Our method is motivated by Bayesian decision theory"
- Bayes-optimal estimator: The estimator that minimizes expected loss (risk) under the true posterior; under MSE, it is the posterior mean. "which corresponds to the Bayes-optimal estimator under squared-error loss."
- conditional distribution transport: Framing generation as moving samples from a simple prior to a target conditional distribution given observed data. "formulates 3D pose estimation as a conditional distribution transport problem."
- Conditional Flow Matching (CFM): A training objective for learning a conditional velocity field by matching target velocities along interpolated paths. "The Conditional Flow Matching (CFM) objective minimizes the expected squared error"
- Conditional Variational AutoEncoder (CVAE): A generative model that samples diverse outputs conditioned on inputs via latent variables learned by variational inference. "used a Conditional Variational AutoEncoder (CVAE) to obtain diverse 3D pose samples."
- CtrlAni3D: A synthetic animal 3D pose dataset rendered with SMAL structures and ControlNet guidance. "the 3D animal pose datasets Animal3D and CtrlAni3D"
- data manifold: The low-dimensional subset of the ambient space where valid data (e.g., plausible 3D poses) predominantly lie. "The red region illustrates the valid 3D pose data manifold."
- Denoising Diffusion Implicit Models (DDIM): A faster sampler for diffusion models that reduces steps while approximating reverse diffusion. "Even with accelerated samplers such as Denoising Diffusion Implicit Models (DDIM)"
- diffusion-based models: Generative models that sample by reversing a noising process through iterative denoising steps. "diffusion-based models have recently demonstrated strong performance"
- explicit Euler: A first-order numerical ODE solver that updates the state by a step along the current velocity. "Using explicit Euler, the update is"
- Flipped-Hypothesis Aggregation (FHA): An inference trick that treats original and horizontally flipped inputs as separate hypotheses for aggregation. "We refer to this strategy as Flipped-Hypothesis Aggregation (FHA)."
- Flow Matching (FM): A generative modeling approach that learns a deterministic velocity field whose ODE transports a base distribution to the data distribution. "we leverage Flow Matching (FM) to learn a velocity field defined by an Ordinary Differential Equation (ODE)"
- Gaussian prior: A normal distribution used as the base noise source for generative sampling. "samples from a standard Gaussian prior"
- Graph Convolutional Network (GCN): A neural architecture that performs convolutions over graph-structured data (e.g., skeletons). "based on Graph Convolutional Network (GCN)"
- Human3.6M: A large-scale indoor human pose dataset widely used to benchmark 3D pose estimation methods. "Human3.6M"
- LayerNorm: A normalization layer that standardizes activations across features per sample to stabilize training. "passed through a LayerNorm"
- Mean Per-Joint Position Error (MPJPE): The average Euclidean distance between predicted and ground-truth joints in millimeters. "MPJPE (Mean Per-Joint Position Error)"
- Mixture Density Network (MDN): A model that outputs parameters of a mixture distribution (e.g., Gaussians) to capture multi-modality. "Mixture Density Network (MDN)"
- Minimum Mean Squared Error (MMSE) estimator: The estimator equal to the posterior mean that minimizes expected squared error. "known as the Minimum Mean Squared Error (MMSE) estimator:"
- Monte Carlo estimator: A sampling-based estimator that approximates expectations with weighted or unweighted sample averages. "a weighted Monte Carlo estimator"
- MPI-INF-3DHP: A challenging 3D human pose dataset with diverse indoor and outdoor scenes used for cross-dataset evaluation. "MPI-INF-3DHP"
- normalizing flows: Invertible transformations that map a simple base distribution to a complex target distribution with tractable densities. "normalizing flows"
- Ordinary Differential Equation (ODE): An equation describing continuous-time dynamics; here used to transport samples via a learned velocity field. "Ordinary Differential Equation (ODE)"
- Percentage of Correct Keypoints (PCK): A keypoint accuracy metric counting predictions within a distance threshold. "Percentage of Correct Keypoints (PCK)"
- P-MPJPE: MPJPE computed after rigid alignment (scale, rotation, translation) between predicted and ground-truth poses. "P-MPJPE is the MPJPE after rigid alignment with the ground truth in translation, rotation, and scale."
- posterior distribution: The conditional distribution of unknown variables given observed data. "posterior distribution "
- posterior expectation: The mean of the posterior distribution; the MMSE estimator under squared-error loss. "posterior expectation of the 3D pose"
- Procrustes alignment: A rigid alignment (including scaling) used to compare shapes/poses up to similarity transforms. "up to Procrustes alignment"
- Reprojection-based Posterior Expectation Aggregation (RPEA): An aggregation method that weights hypotheses by a pseudo-likelihood derived from 2D reprojection loss to approximate the posterior mean. "Reprojection-based Posterior Expectation Aggregation (RPEA)"
- re-projection error: The discrepancy between observed 2D keypoints and 2D projections of a predicted 3D pose under a camera model. "2D re-projection error"
- reverse diffusion process: The generative sampling process in diffusion models that iteratively denoises noise into data. "reformulate 3D pose lifting as a reverse diffusion process"
- self-attention: A mechanism that models global dependencies by relating all pairs of positions within a sequence or set. "a global self-attention branch"
- Skinned Multi-Animal Linear (SMAL) model: A parametric 3D shape model for multiple animal species used to obtain 3D keypoints/meshes. "Skinned Multi-Animal Linear (SMAL) model"
- Stochastic Differential Equation (SDE): A differential equation with stochastic terms governing diffusion models’ denoising dynamics. "Stochastic Differential Equation (SDE)"
- temperature hyperparameter: A scalar controlling the sharpness/peakedness of a softmax-like weighting over hypothesis scores. " is a fixed temperature hyperparameter."
- Top-K: A selection strategy that retains the K candidates with the best (lowest) losses or highest scores. "Top-K candidates"
- Transformers: Neural architectures based on attention mechanisms that capture long-range dependencies. "Inspired by the success of Transformers"
- velocity field: A function that specifies instantaneous motion in state space; integrating it transports samples to target distributions. "learn a velocity field defined by an Ordinary Differential Equation (ODE)"
Collections
Sign up for free to add this paper to one or more collections.