Authorship Drift: How Self-Efficacy and Trust Evolve During LLM-Assisted Writing
Abstract: LLMs are increasingly used as collaborative partners in writing. However, this raises a critical challenge of authorship, as users and models jointly shape text across interaction turns. Understanding authorship in this context requires examining users' evolving internal states during collaboration, particularly self-efficacy and trust. Yet, the dynamics of these states and their associations with users' prompting strategies and authorship outcomes remain underexplored. We examined these dynamics through a study of 302 participants in LLM-assisted writing, capturing interaction logs and turn-by-turn self-efficacy and trust ratings. Our analysis showed that collaboration generally decreased users' self-efficacy while increasing trust. Participants who lost self-efficacy were more likely to ask the LLM to edit their work directly, whereas those who recovered self-efficacy requested more review and feedback. Furthermore, participants with stable self-efficacy showed higher actual and perceived authorship of the final text. Based on these findings, we propose design implications for understanding and supporting authorship in human-LLM collaboration.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about
This paper looks at what happens to people’s confidence and trust when they use an AI writing assistant (a LLM, or LLM) to help them write an essay. The authors call this “authorship drift”—how a person’s sense of being the true author can change as they work with the AI across multiple back-and-forth turns.
What questions the researchers asked
- How do people’s feelings of self-efficacy (confidence that “I can do this myself”) and trust in the AI change turn by turn while they write?
- Do different ways of prompting the AI (asking for edits, ideas, feedback, etc.) relate to these changing feelings?
- How do these changing feelings relate to who really authored the final text—both what people feel and what the text actually shows?
How the study was done
The researchers ran an online study with 302 participants who wrote an argumentative essay in English. The writing app had two panels: a chat panel to talk to the AI, and a text editor to write the essay.
Here’s the key setup, explained in everyday terms:
- Before each new prompt to the AI, participants rated:
- Self-efficacy: “Right now, how confident am I that I could complete this writing task on my own?”
- Trust: “Right now, how much do I trust the AI to reliably support me with this task?”
- They used a simple 1–7 scale each time, so the researchers could track how these feelings rose or fell across turns.
- The team saved all prompts, the AI’s replies, and the evolving essay text. Later, they categorized the intent of each prompt (for example: drafting, editing, ideating, searching for information, or reviewing/feedback).
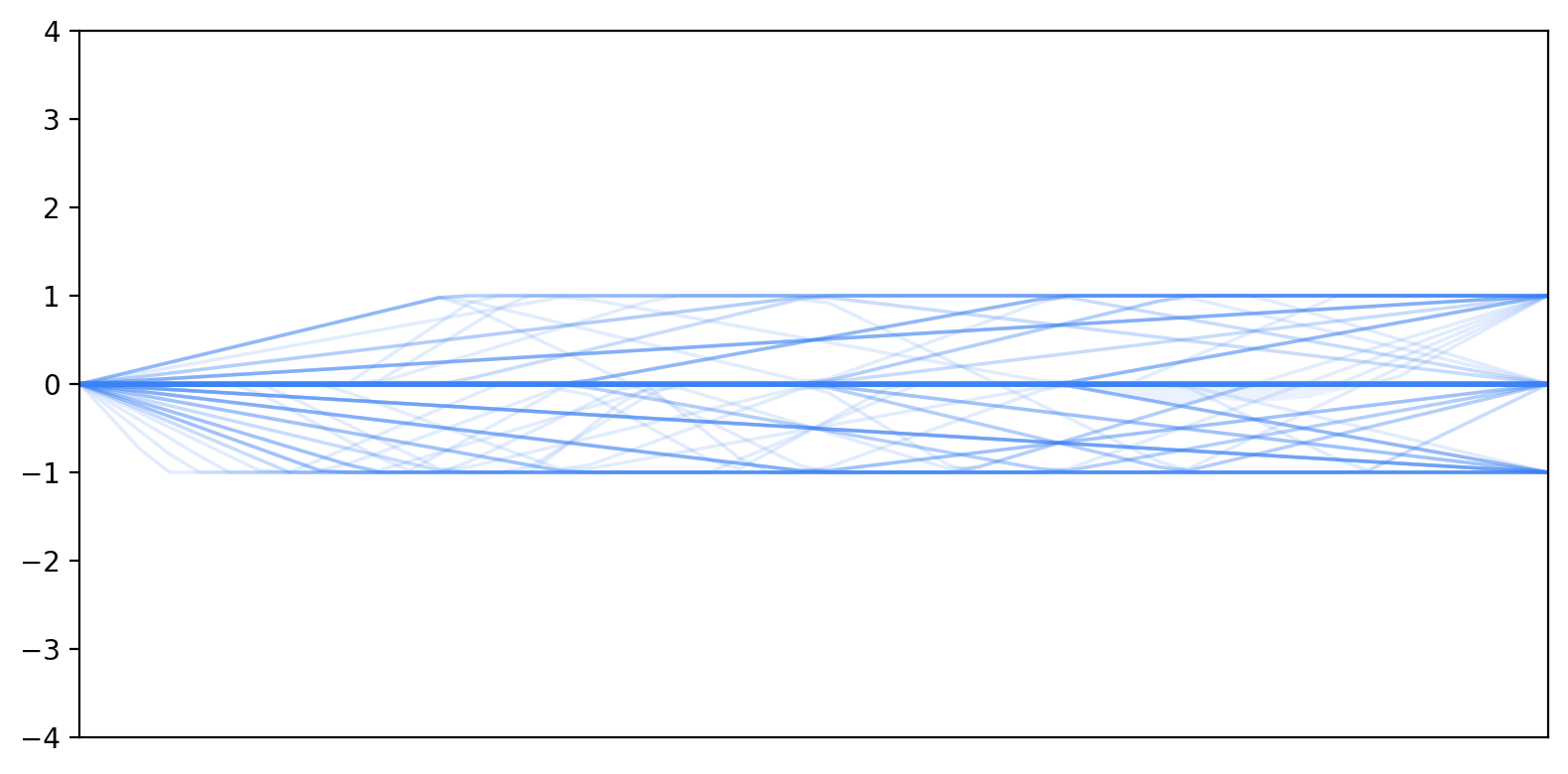
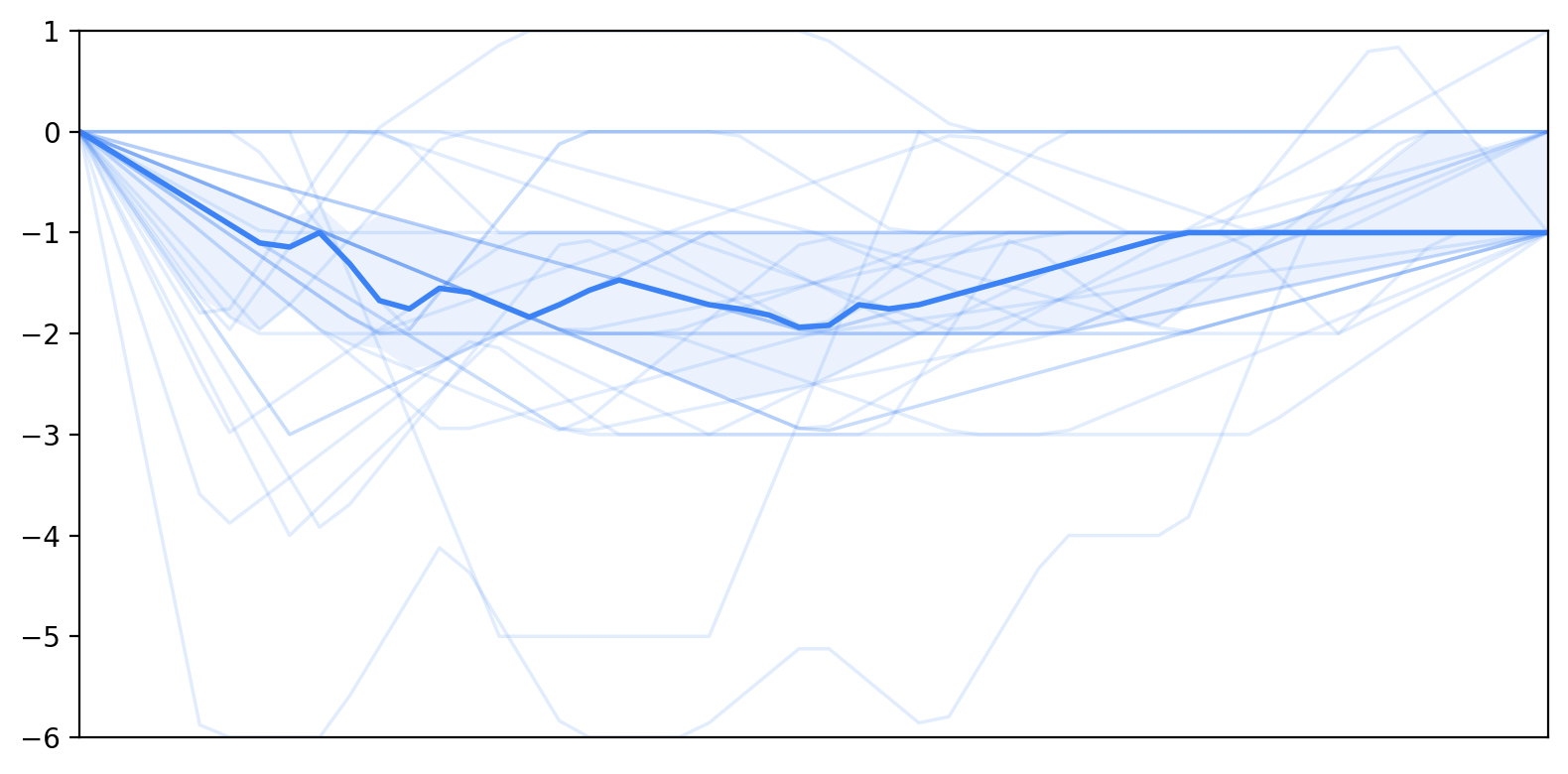
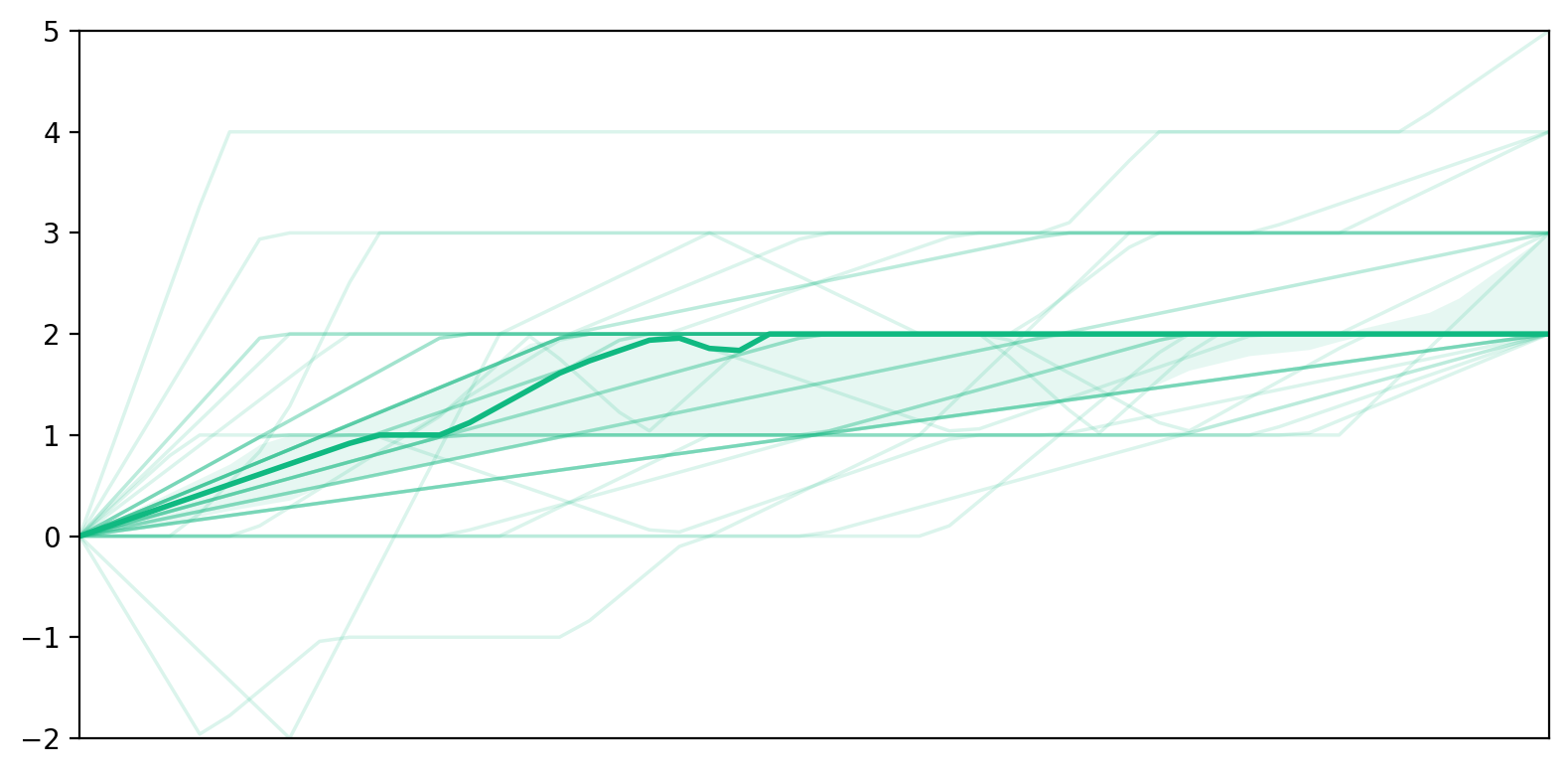
- To find patterns, they grouped each person’s changing scores into “trajectory” types (like stable, decreasing, or recovering) using a practical threshold: a 2‑point change on the 1–7 scale was considered a meaningful shift rather than random noise.
- To study how confidence and trust influenced each other over time, they used a statistical approach (a “mixed-effects model”). Think of this like tracking each person’s curve across turns while also recognizing that people start at different levels and change at different speeds.
- To measure “actual authorship,” they compared the final essay with the AI’s responses using:
- Lexical overlap (how much exact wording from the AI appears in the essay).
- Semantic similarity (how similar the ideas are, even if phrased differently).
- This tells whether people copied or closely used the AI’s content versus writing more from their own words and ideas.
What they found and why it matters
Here are the main takeaways:
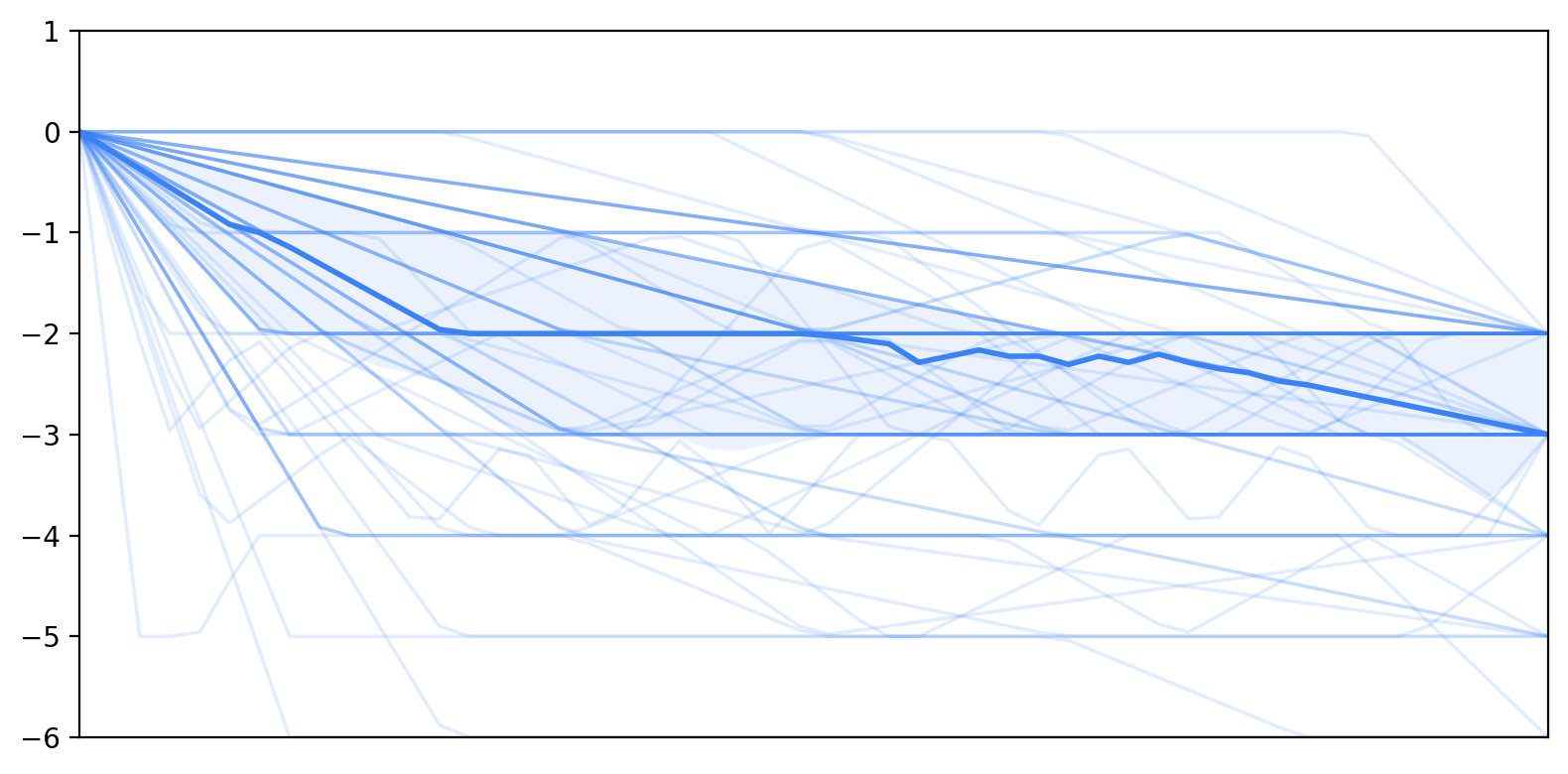
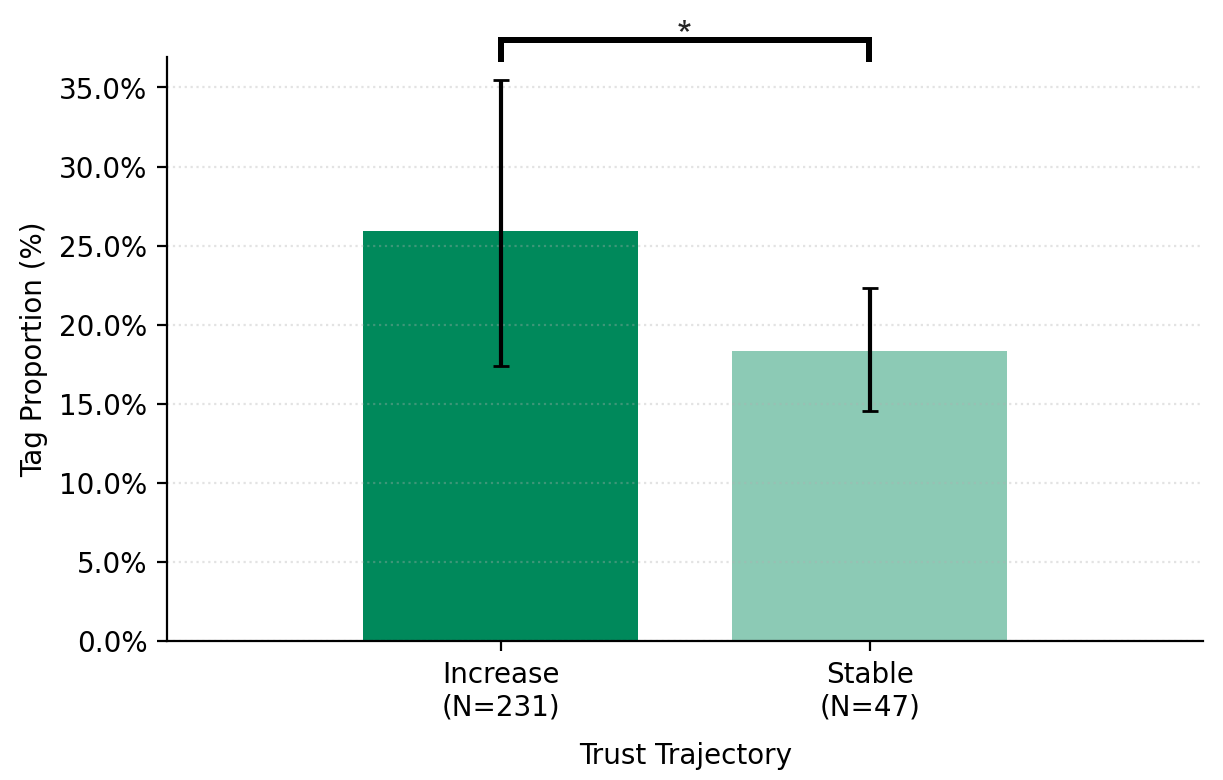
- Self-efficacy often went down, while trust often went up.
- As people interacted turn by turn, many felt less able to complete the essay alone, yet they increasingly trusted the AI to help.
- Trust mostly stayed high or rose; self-efficacy more often dropped than rose.
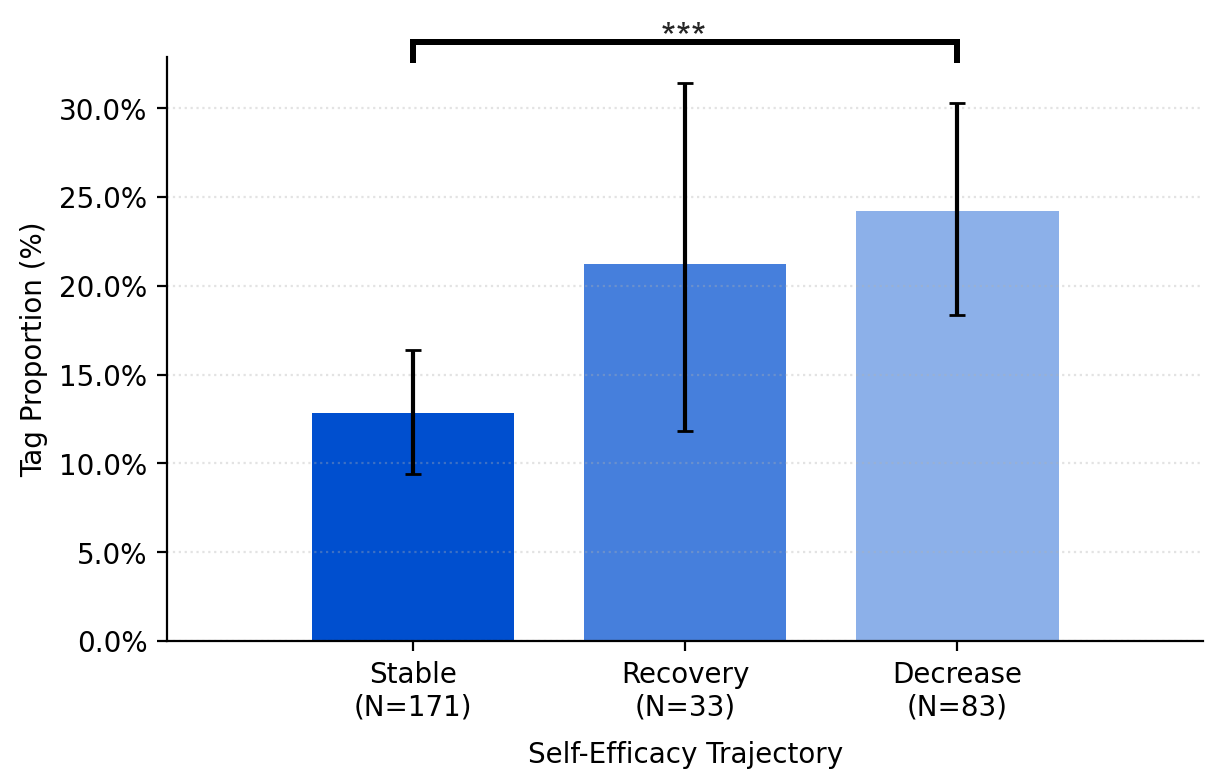
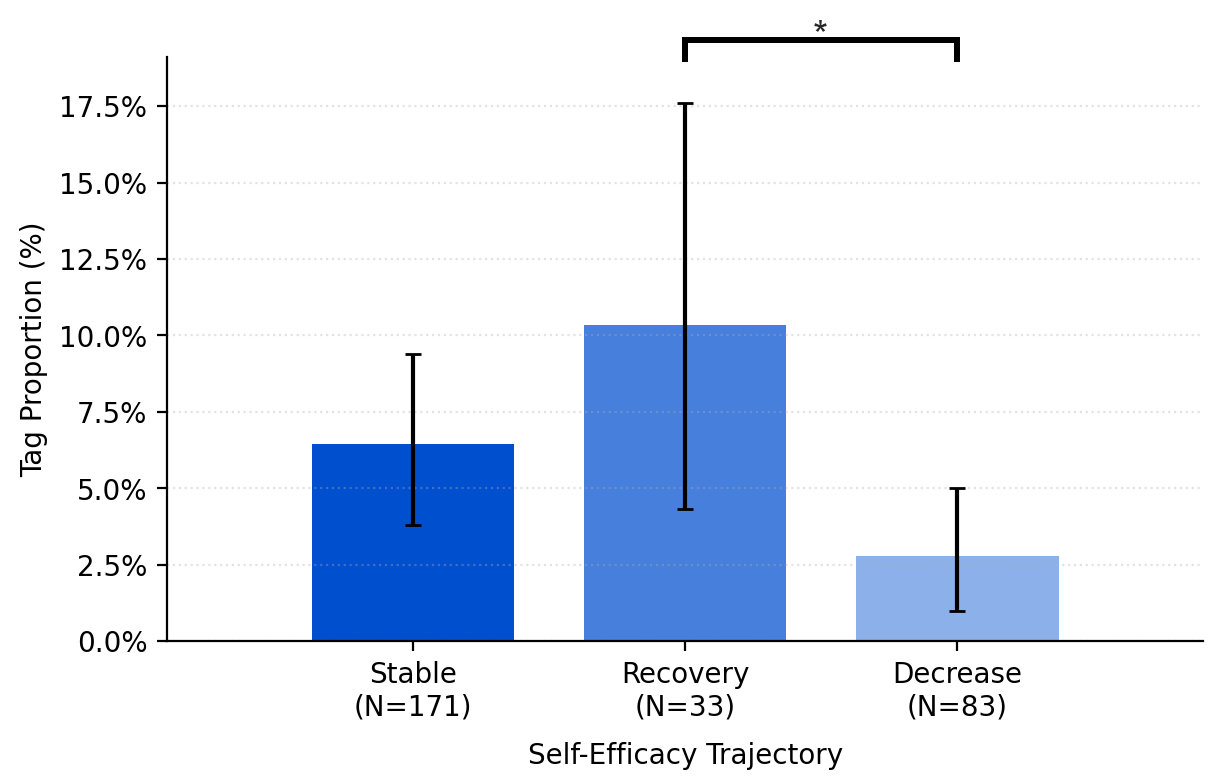
- Prompting strategies aligned with confidence changes.
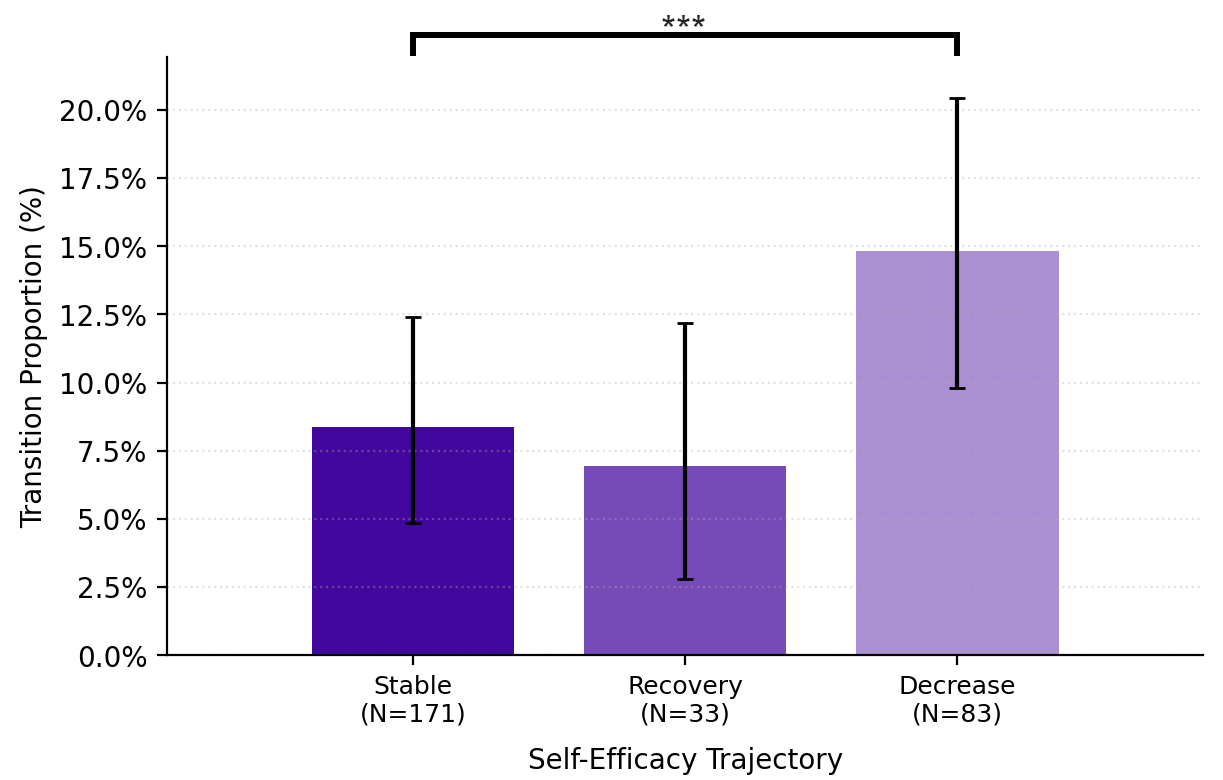
- When self-efficacy decreased, people were more likely to ask the AI to directly edit their text (for example, “Please polish my draft” or repeatedly going from draft to edit).
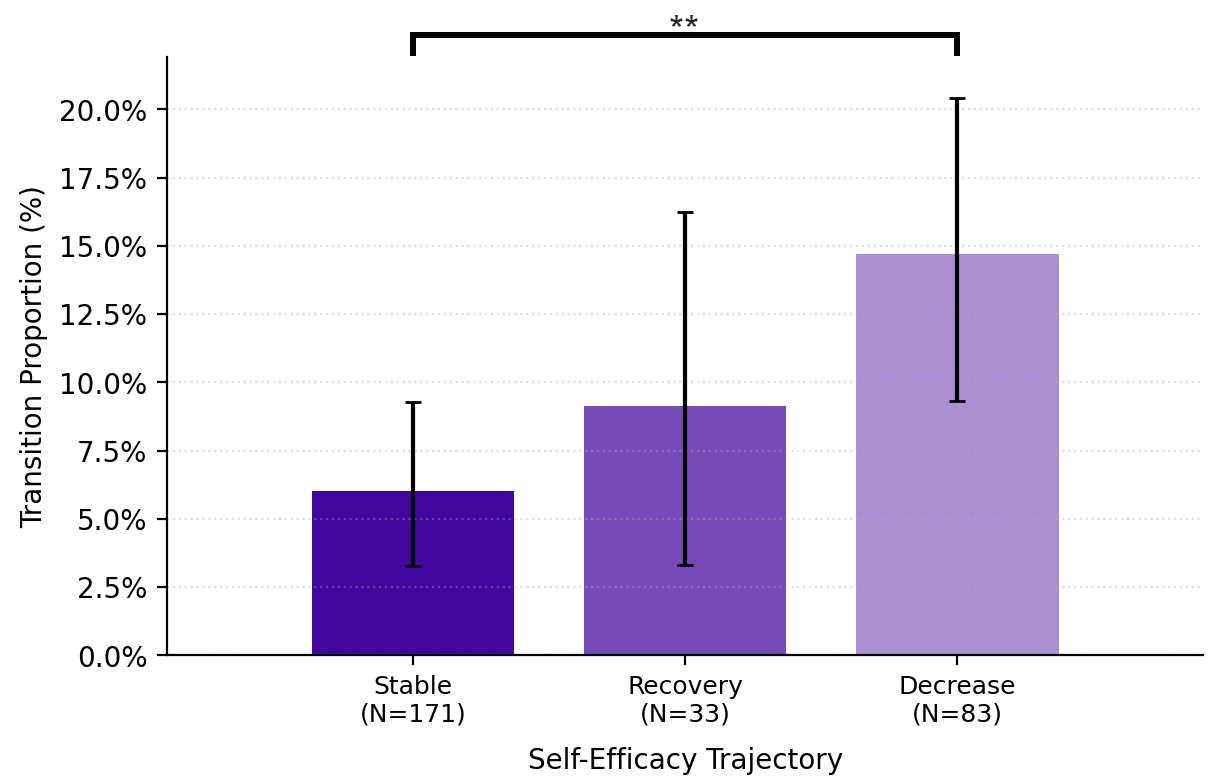
- When self-efficacy dipped but later recovered, people tended to ask for review and feedback (for example, “What do you think? Can you suggest improvements?”), which kept them more involved in decision-making.
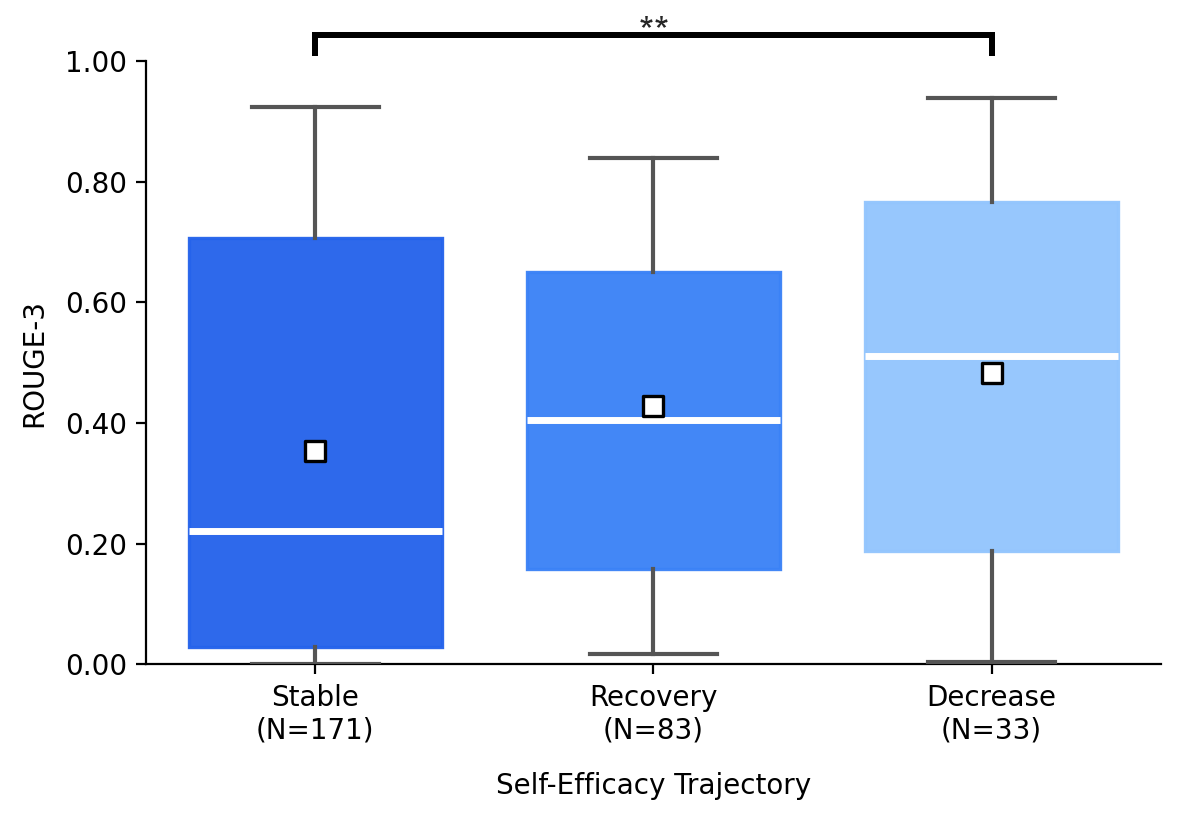
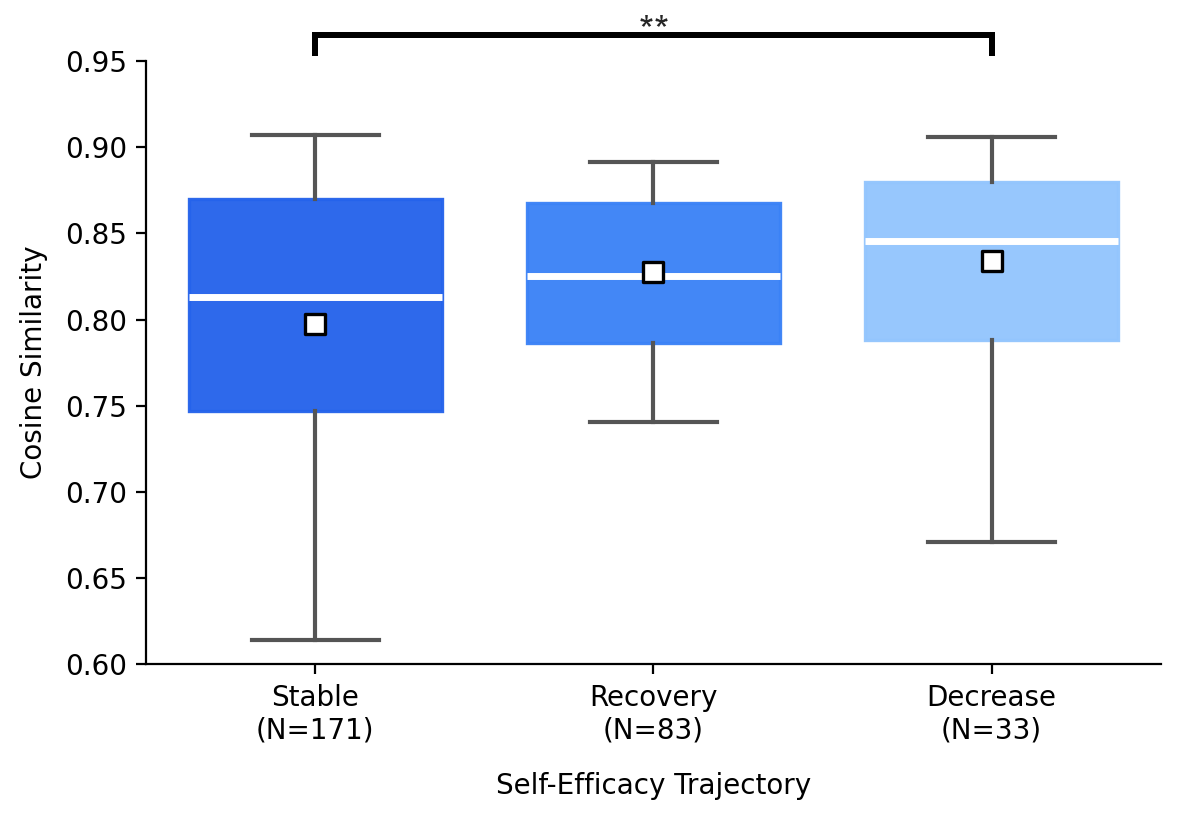
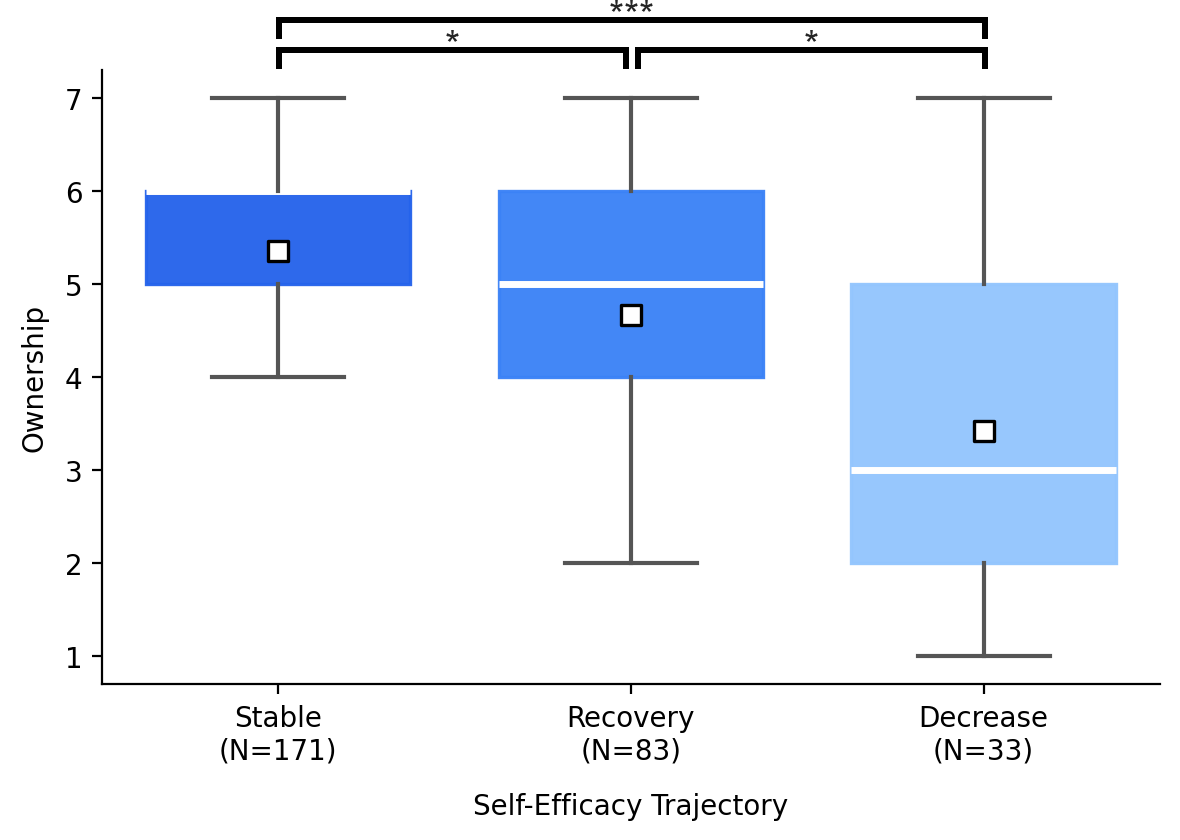
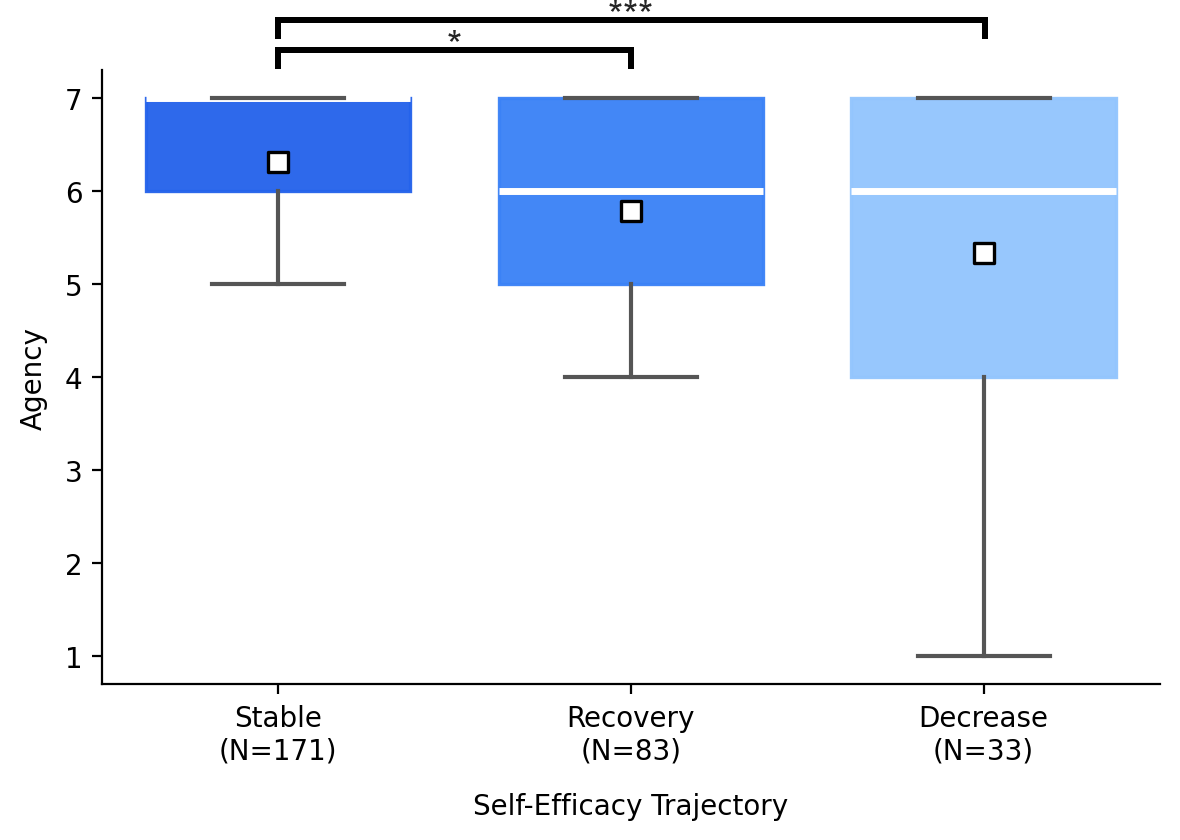
- Stable self-efficacy linked to stronger authorship.
- People whose confidence stayed steady reported higher perceived authorship (feeling ownership and control) and showed higher actual authorship (less direct adoption of AI content).
- In contrast, heavy reliance on direct edits was associated with lower human authorship.
Why this matters: It shows that the way we use AI can quietly shift our sense of control and ownership. If we keep asking for edits, we might rely more on AI phrasing and lose our authorial voice. If we ask for feedback and review, we stay more engaged and keep our voice in the work.
What this could mean going forward
The findings suggest simple, helpful design ideas for AI writing tools and habits:
- Nudge toward feedback, not auto-edit: Make it easy to request reviews and suggestions instead of immediate full rewrites, especially when a user’s confidence seems to be dropping.
- Show authorship signals: Clearly mark which parts came from the AI and which came from the user, so people can see and control their level of adoption.
- Reflective prompts: If confidence appears to dip, the tool could offer options like “Would you like feedback or a quick outline?”—choices that keep the user in charge.
- Encourage revision ownership: Provide step-by-step guidance (“highlight issues,” “suggest alternatives”) before offering a full rewrite, helping users practice decision-making and maintain their voice.
- Calibrate trust and skill: Support healthy trust in the AI’s help while strengthening the user’s skills and confidence over time (for example, by explaining edits and teaching writing strategies).
Overall, the study shows that small moment-to-moment choices in how we collaborate with AI can add up, shaping who truly authors the final text—and how confident we feel about our own abilities.
Knowledge Gaps
The paper advances understanding of self-efficacy and trust dynamics in LLM-assisted writing, yet several methodological, analytic, and external validity gaps remain that future research can address. Below is a consolidated, actionable list of limitations and open questions.
Methodological limitations
- Single-task, single-genre scope: Results were obtained only for time-limited AP-style argumentative essays; it remains unknown whether findings generalize to other genres (creative writing, technical reports, emails), tasks (summarization, coding, translation), or unconstrained writing timelines.
- Single-model setting: Only a “vanilla” GPT-4.1 chat assistant was tested. How trajectories change across models of different quality, cost, latency, safety tuning, or tool-integrations (e.g., retrieval, citation) is untested.
- Participant sampling bias: Recruiting only recent LLM users and self-identified native English speakers limits generalizability to novices, multilingual writers, and varied cultural contexts; differential effects for proficiency levels and demographics remain unexplored.
- Possible outside-tool use: The study did not verify that participants avoided external tools or LLMs in parallel; contamination effects on authorship and interaction dynamics are unknown.
- Interface-induced behavior: Mandatory per-turn ratings that disable input may have altered natural workflows (19.2% reported an effect); lack of a no-rating control condition prevents estimating measurement reactivity.
- Incentive effects: Performance-based bonuses and exam framing may have shifted strategies (e.g., more model reliance); impacts of incentive structure on agency and authorship are unmeasured.
Measurement limitations
- Single-item state measures: Self-efficacy and trust were captured with single-item Likert ratings, limiting reliability and construct coverage (e.g., trust facets of competence, integrity, benevolence). Multi-item, validated state scales and facet-level measures are needed.
- Minimal Detectable Change (MDC) derivation: MDC thresholds were applied to single-item measures without reporting test–retest reliability or measurement error estimates specific to this instrument/context; the validity of the 2-point cutoff requires empirical justification.
- Authorship operationalization: Actual authorship was proxied by ROUGE-3 overlap and embedding similarity to LLM responses. This misses structural, argumentative, and idea-level influence, and may conflate paraphrasing with original synthesis. Validation against expert human attribution is absent.
- LLM-original content extraction: The method for isolating “LLM-original” text from responses (excluding restatements of user input) is error-prone and unvalidated; span-level precision/recall and sensitivity analyses are not reported.
- Perceived authorship scope: Ownership and agency were measured with two items; other salient dimensions (responsibility, voice authenticity, satisfaction, accountability) were not assessed.
- Lack of factuality/audit measures: Trust calibration was not assessed against output quality (e.g., factuality, coherence, harmful errors); overtrust vs undertrust cannot be evaluated without quality ground truth.
Analytic limitations
- Discretized trajectory classes: Grouping trajectories by net change and MDC may obscure rich intra-session dynamics; growth mixture models, spline/nonlinear time-series, HMMs, or cross-lagged panel models could better capture heterogeneity and directionality.
- Bidirectional dynamics and endogeneity: Mixed-effects regressions predicting self-efficacy from trust (and vice versa) with concurrent measures risk simultaneity bias; cross-lagged or time-varying effect models are needed to infer temporal precedence.
- Turn/time normalization: Using linear “turn” as time may miss nonlinear or event-triggered effects (e.g., large edits, high-agency prompts). Analyses conditioned on interaction events or essay state changes could be more informative.
- Prompt-intention taxonomy granularity: The five-category coding collapses meaningful distinctions (e.g., critique vs revision vs rewrite; micro- vs macro-editing). A finer, validated taxonomy and span-level annotation could reveal more actionable strategy patterns.
- Rare but critical patterns: Transitions present in <10% of participants were excluded; these may capture important failure modes (e.g., trust collapse) that warrant targeted analysis.
- No moderation analysis: Potential moderators (baseline writing skill, essay quality, prior LLM reliance, personality traits) were not examined; heterogeneity of effects remains unknown.
External validity and generalizability
- Tooling/ecosystem differences: Results from a chat+editor interface may not transfer to in-situ editors (e.g., Google Docs inline suggestions), versioned drafts, or collaborative settings with multiple human authors.
- Language and culture: Effects across languages, rhetorical traditions, and non-Western academic norms are untested.
- Longitudinal effects: Only single-session dynamics were measured; impacts on long-term self-efficacy, reliance habits, learning, and authorship identity over repeated use are unknown.
Unaddressed mechanisms and causal inference
- Why self-efficacy drops: The mechanisms behind self-efficacy decreases (e.g., unfavorable social comparison to fluent outputs, cognitive offloading, perceived deskilling) were not directly tested.
- Causality of strategies → authorship: Associations between prompting strategies and authorship outcomes are correlational; interventions that manipulate strategy scaffolds are needed to establish causal effects.
- Trust calibration: With generally high/stable trust, whether trust was appropriate to actual model performance is unknown; experiments varying output reliability are needed to study calibration and its effect on authorship.
Design and intervention gaps
- Scaffolds for vulnerable moments: The paper proposes implications but does not evaluate concrete designs (e.g., reflection prompts, critique-first modes, idea- vs wording-level assistance, gradual disclosure, contribution visualizations) to prevent authorship drift or restore self-efficacy.
- Adaptive assistance: No tests of adaptive policies that adjust the assistant’s behavior based on real-time trajectories (e.g., reduce direct editing when self-efficacy drops; nudge toward review/feedback modes).
- Transparency of provenance: Interfaces that surface provenance and contribution breakdowns (human vs AI spans, idea lineage, edit provenance) were not prototyped or evaluated for effects on perceived and actual authorship.
Ethical and operational considerations
- Responsibility and accountability: The study does not examine how trajectory patterns affect users’ attribution of responsibility for errors or harms in the final text.
- Hallucinated evidence: Information-seeking/evidence prompts were allowed without verification workflows; impacts of AI-fabricated evidence on trust, authorship, and downstream misuse are unassessed.
Data and reproducibility
- Reproducibility of authorship metrics: Embedding model choice (gemini-embedding-001) and prompt extraction procedures may affect results; robustness across embedding models and release of code/data for replication are not addressed.
- Human validation: No reported human evaluation of the authorship overlap pipeline or inter-rater reliability for authorship attribution beyond prompt-intention coding.
Glossary
- Actual authorship: An objective measure of a human’s contribution to the final text, often quantified by overlap with AI outputs. "participants with stable self-efficacy showed higher actual and perceived authorship of the final text."
- Agency: The writer’s sense of control and intentional influence over the writing process and outcome. "weakened sense of agency and ownership of the final result"
- Authorship: The attribution of creative contribution and responsibility for a written work. "LLM-assisted writing introduces a critical challenge of authorship"
- Authorship Drift: The evolving shift in perceived and actual authorship during human-LLM collaboration. "Authorship Drift: How Self-Efficacy and Trust Evolve During LLM-Assisted Writing"
- Confidence interval: A statistical range that likely contains a true parameter value with a specified probability. "At a 95\% confidence interval, we found the theoretical threshold to be 2.080 points for self-efficacy and 2.037 points for trust."
- Cosine similarity: A measure of similarity between two vectors based on the cosine of the angle between them. "by computing the cosine similarity of high-dimensional vector embeddings from both the LLM response and user text."
- Institutional Review Board (IRB): A committee that reviews research involving human participants to ensure ethical compliance. "The study was reviewed and approved by the Institutional Review Board (IRB) of our institution prior to conducting the study."
- Interquartile range: The middle 50% spread of a distribution, between the first and third quartiles. "the shaded band indicates the interquartile range."
- Inter-rater reliability: The degree of agreement among independent coders/raters. "Inter-rater reliability was high in this round ()."
- Kruskal–Wallis test: A nonparametric statistical test for comparing medians across multiple groups. "we compared these initial scores using a KruskalâWallis test."
- Likert scale: A psychometric scale for measuring attitudes or perceptions using ordered response options. "on a 7-point Likert scale (1 = Not at all, 7 = Completely)"
- Likelihood ratio test: A statistical test for comparing the fit of nested models. "A likelihood ratio test showed that the model with random slopes had a significantly better fit"
- Linear mixed-effects model: A regression model that includes both fixed effects and random effects to handle grouped or repeated-measures data. "we analyzed their bidirectional relationship using a linear mixed-effects model."
- Mean-centering: Transforming variables by subtracting their mean to aid interpretation and reduce multicollinearity. "We mean-centered all continuous predictors so that zero corresponded to the sample mean."
- Minimal Detectable Change (MDC): The smallest change that reflects a true difference beyond measurement error. "we adopted the Minimal Detectable Change (MDC) threshold"
- Ownership: A subjective sense of being the author or proprietor of the produced text. "They rated their perceived authorship of their final essay using two dimensions---ownership and agency---each measured on a 7-point Likert scale"
- Perceived authorship: A subjective assessment of one’s authorship contribution to the final text. "participants with stable self-efficacy showed higher actual and perceived authorship of the final text."
- Random effects: Model components capturing variability attributable to grouping factors (e.g., participants). "We tested two alternative random-effects structures."
- Random intercepts: Random-effect terms allowing each group/participant its own baseline level. "The first only included random intercepts"
- Random slopes: Random-effect terms allowing each group/participant its own rate of change for a predictor. "the second included both random intercepts and random slopes for turn."
- Reliance calibration: The process of adjusting how much users depend on AI assistance to match its reliability and their needs. "reliance calibration~\cite{he2023knowing,schemmer2023appropriate,li2025confidence}"
- ROUGE-3: An evaluation metric measuring recall-based trigram overlap between texts. "Lexical overlap was measured using ROUGE-3, which calculates recall-based tri-gram overlap"
- Semantic similarity: The degree to which two pieces of text share meaning, regardless of exact wording. "Semantic similarity was measured via text embeddings"
- Text embeddings: Numerical vector representations of text capturing semantic information. "Semantic similarity was measured via text embeddings using gemini-embedding-001"
- Trajectory patterns: Categorized shapes of change over time in measured constructs. "we established five distinct trajectory patterns: increase, decrease, stable, recovery, and reversion."
- Turn-level trajectories: Temporal patterns tracked at each interaction turn within a session. "Empirical characterization of turn-level trajectories of self-efficacy and trust in LLM-assisted writing."
- Zero-centering: Shifting data so that a chosen baseline (often a mean or initial value) becomes zero. "after zero-centering all trajectories at each participant's pre-survey rating."
Practical Applications
Immediate Applications
Below are actionable applications that can be deployed with today’s tools and practices, grounded in the paper’s findings on self-efficacy decline, trust increase, prompting strategies, and authorship measurement.
- Software/productivity (Office suites, docs, email)
- Authorship meter and disclosure
- Add an “AI Contribution” indicator in editors (e.g., Word, Google Docs, Notion), powered by lexical overlap (ROUGE-n) and embedding similarity, to show how much text originates from the LLM versus the user. Offer one-click export of contribution reports for sharing and compliance.
- Tools/workflows: “Authorship Meter” sidebar, document-level disclosure badge, exportable “AI Contribution Report.”
- Assumptions/dependencies: Access to interaction logs; embedding computation; clear privacy policy; acceptance by users; false positives/negatives for paraphrases.
- Review-first nudges and edit guardrails
- Detect “direct edit” intents (draft-to-edit, edit-to-edit sequences) and nudge users toward “review/feedback” prompts when self-efficacy appears to dip (via lightweight heuristics like repeated edit requests or declining manual edits).
- Tools/workflows: “Review Mode by default,” “Convert to comments” guardrail, inline advice like “Try ‘review’ rather than ‘rewrite’ to keep your voice.”
- Assumptions/dependencies: Intent classification from prompt taxonomy; minimal friction to avoid user annoyance.
- Prompt strategy coach
- Surface quick actions based on intent taxonomy (drafting, editing, ideating, info search, reviewing) with examples; encourage “review/feedback” requests to maintain agency when users trend toward direct edits.
- Tools/workflows: Prompt palette with categorized exemplars; inline suggestions (“Ask for feedback on structure?”).
- Assumptions/dependencies: Accurate prompt labeling; UX that doesn’t interrupt flow.
- Education (LMS, writing courses, writing centers)
- Assignment templates with agency safeguards
- Embed an “AI usage with authorship report” workflow: students can use LLMs but must submit the document plus an authorship contribution report and a short reflection on when they asked for edits vs reviews.
- Tools/workflows: LMS plugin that ingests logs and renders student-facing and instructor dashboards; rubric items for ownership/agency.
- Assumptions/dependencies: Institutional policy supports AI-assisted writing; student consent for logging; fair use across varying abilities.
- Instructor dashboards on interaction patterns
- Aggregate per-student proportions of intent categories and transitions (e.g., draft→edit vs draft→review) to flag over-reliance risks and provide formative feedback.
- Tools/workflows: “Interaction Pattern Dashboard” showing intent proportions and trajectories; anonymized cohort comparisons.
- Assumptions/dependencies: Privacy safeguards; clear instructional framing to avoid punitive use.
- Journalism and publishing
- Editorial workflows that preserve author voice
- Default LLM to “review/critique” mode and require human acceptance of changes. Provide per-article AI contribution summaries for internal review and public disclosure as needed.
- Tools/workflows: CMS integration with “AI Suggestion Mode,” authorship meter, automated disclosure snippet.
- Assumptions/dependencies: Organizational policy on AI transparency; alignment with brand voice.
- Enterprise compliance and IP risk (legal, governance, risk, and compliance)
- AI contribution audit logs for compliance
- Provide document-level audit trails summarizing LLM content adoption and edit lineage to support disclosure, IP assessments, and client/partner assurances.
- Tools/workflows: “AI Usage Audit” service; threshold-based alerts (e.g., >30% AI-originated content).
- Assumptions/dependencies: Secure log storage; cross-jurisdictional data handling; buy-in from legal/compliance teams.
- Healthcare documentation (clinical notes, scribing)
- Agency-preserving scribe settings
- Configure AI scribes to propose suggestions as comments first and provide contribution meters on drafts, ensuring clinicians retain ownership and oversight.
- Tools/workflows: “Suggest-only” defaults; clinician-facing contribution meter; audit-ready reports for chart integrity.
- Assumptions/dependencies: EHR integration; clinical workflow acceptance; regulatory alignment.
- Customer support and marketing content teams
- Brand voice control with authorship monitoring
- Keep humans in the loop by prioritizing “review” requests and measuring AI contribution to protect tone and brand consistency.
- Tools/workflows: Content pipeline step that checks AI contribution ratio and flags high-AI drafts for additional review.
- Assumptions/dependencies: Accurate attribution; team training on new workflow.
- UX research and AI product teams
- Telemetry for “authorship drift” segments
- Use the MDC-based trajectory classification and intent taxonomy to segment users (e.g., stable, decreasing, recovering self-efficacy) and A/B test targeted interventions (e.g., review-first nudges for decreasing group).
- Tools/workflows: “Authorship Drift Monitor” analytics; mixed-effects modeling for longitudinal feature impact.
- Assumptions/dependencies: Ethical telemetry collection; consent; team capacity to analyze and iterate.
- Policy/guidance (institutional, organizational)
- Immediate guidelines on agency-preserving practices
- Recommend review-first defaults, explicit disclosure of AI contributions, and access to contribution summaries for stakeholders (students, clients, readers).
- Tools/workflows: Organizational AI usage policies; templates for disclosures; procurement checklists requiring authorship metrics.
- Assumptions/dependencies: Clear communication and training; enforceability varies by context.
- Daily life (individual writers, freelancers)
- Personal writing coach extensions
- Browser/Docs extensions that show authorship meters, suggest review-first prompts, and provide post-session reflections on reliance patterns.
- Tools/workflows: “AI-usage weekly digest,” suggested goals (e.g., increase review prompts by 20%).
- Assumptions/dependencies: Willingness to share interaction logs; balance between insight and cognitive load.
Long-Term Applications
The following applications will require further research, scaling, integration, or standardization to reach production readiness.
- Cross-task agency monitoring (software, IDEs, analytics, data science)
- Passive inference of self-efficacy and trust
- Replace explicit ratings with behavioral proxies (e.g., prompt types, edit acceptance rates, back-and-forth cycles) to estimate trajectories in real time and adapt UI without interrupting flow.
- Tools/workflows: On-device models predicting trajectory states; adaptive assistants that modulate assertiveness.
- Assumptions/dependencies: Robust predictive models; bias monitoring; privacy-preserving telemetry (e.g., differential privacy).
- Coding assistants and developer tools
- “Authorship & Agency Monitor” in IDEs
- Bring authorship meters and review-first recommendations to code completion and refactoring, discouraging over-reliance in complex changes and prompting code reviews.
- Tools/workflows: VS Code/JetBrains plugins; per-PR contribution reports; adaptive completions.
- Assumptions/dependencies: Mapping authorship metrics to code (e.g., AST-based overlap); developer acceptance.
- Standards and regulation (policy, compliance, certification)
- Standardized “AI contribution score” and provenance labels
- Define sector-wide metrics and thresholds for AI contribution and disclosure (akin to nutrition labels), aligning with content provenance standards and watermarking.
- Tools/workflows: Certification programs; auditing APIs; interoperable schemas for authorship metadata.
- Assumptions/dependencies: Multi-stakeholder agreement; regulatory adoption; reliable provenance signals from model providers.
- Learning and workforce development
- Longitudinal agency metrics tied to learning outcomes
- Track how reliance patterns affect skill growth over semesters or quarters; tailor curricula or training plans to maintain self-efficacy while leveraging AI.
- Tools/workflows: LMS/HRIS integrations; skill progression dashboards; intervention libraries (e.g., reflection assignments).
- Assumptions/dependencies: Data linkage across terms; ethical use to avoid punitive tracking.
- Organizational performance and fairness
- Performance evaluation frameworks that account for AI augmentation
- Use authorship metrics responsibly to contextualize output quality and ensure fairness, avoiding penalization for permitted AI usage while safeguarding human agency.
- Tools/workflows: Policy-aligned metrics and review guidelines; manager training.
- Assumptions/dependencies: Cultural acceptance; careful change management to prevent metric gaming.
- Multimodal creative suites (design, video, audio)
- Agency drift detection across modalities
- Extend authorship measurement and review-first defaults to image/video editors and multimodal LLMs, providing transparent attribution and preserving creator voice.
- Tools/workflows: Multimodal similarity measures; layered provenance tracking across assets.
- Assumptions/dependencies: Reliable multimodal attribution; model cooperation for provenance.
- Adaptive “trust thermostat” for AI systems (healthcare, finance, safety-critical)
- Dynamic model assertiveness and explanation depth
- Use inferred trust/self-efficacy to modulate the AI’s tone, verbosity, and requirement for human verification (e.g., stricter review gates when user trust spikes and self-efficacy declines).
- Tools/workflows: Policy engines tied to trajectory states; risk-tiered UI components.
- Assumptions/dependencies: Strong calibration; domain validation; regulatory compliance.
- Privacy-first telemetry frameworks
- On-device authorship analytics and consent architectures
- Build private, opt-in analytics that compute contribution and trajectory metrics locally, sharing only aggregates or redacted signals.
- Tools/workflows: Federated analytics; consent dashboards; data minimization patterns.
- Assumptions/dependencies: Platform support; performance overhead; user trust.
- Provenance integration at the platform level
- System-level origin tags and watermarks
- Collaborate with model providers to tag AI-originated spans at generation time, enabling precise, non-heuristic authorship meters and downstream compliance.
- Tools/workflows: Token-level provenance in APIs; editor support for provenance-aware operations.
- Assumptions/dependencies: Ecosystem alignment; robustness against transformations and paraphrase.
- Equity and accessibility research
- Tailored interventions for diverse users
- Investigate how authorship drift patterns vary across languages, abilities, and contexts; design accessible prompts, guidance, and metrics that support, not penalize, low self-efficacy users.
- Tools/workflows: Inclusive UX libraries; adjustable guardrails and nudges.
- Assumptions/dependencies: Representative datasets; participatory design.
Key Cross-Cutting Assumptions and Dependencies
- Generalizability: Findings are based on LLM-assisted argumentative writing by native English speakers using GPT-4.1; effects may differ across tasks, languages, and model families.
- Measurement validity: MDC thresholds, ROUGE-3, and embedding similarity provide useful but imperfect proxies for authorship; provenance tags would improve accuracy.
- User impact: Turn-by-turn ratings can be intrusive; production systems should prefer passive inference or optional lightweight check-ins.
- Privacy and ethics: Interaction logging must be consented, minimized, and secured; telemetry should not be used punitively.
- Change management: Review-first defaults and nudges must balance agency with productivity and avoid frustrating expert users; allow override and personalization.
These applications translate the paper’s insights into concrete tools and policies that preserve human agency, calibrate trust, and make AI contributions transparent across writing and adjacent knowledge-work domains.
Collections
Sign up for free to add this paper to one or more collections.