- The paper introduces a unified generative controller that combines imitation distillation and RL finetuning for robust physics-based human-object interaction control.
- It leverages a structured latent space with masked residual encoding to condition sparse goals and adapt to diverse object geometries and dynamic environments.
- Experimental results demonstrate improvements in contact correction, multi-object manipulation, and zero-shot generalization across simulation platforms.
InterPrior: A Unified Generative Prior for Robust Physics-Based Human-Object Interaction Control
Motivation and Problem Context
Physics-based human-object interaction (HOI) presents high-dimensional, hierarchical control tasks where humans execute actions guided by sparse, high-level intentions, allowing motor skills such as balance, contact, and manipulation to emerge from physical and motor priors. Prior methods—primarily motion imitation policies and adversarial generative controllers—either rely on explicit planners with dense references or are limited by brittle optimization and narrow skill coverage. They exhibit poor generalization when encountering out-of-distribution states or novel object geometries and lack scalable mechanisms for composable, robust loco-manipulation behaviors across diverse contexts.
InterPrior addresses these deficiencies by designing a scalable HOI controller that integrates large-scale imitation distillation with reinforcement learning (RL) finetuning. This paradigm aims to attain broad coverage across tasks, skills, motions, and dynamics, thus enabling a single policy to robustly handle sparse goal inputs, diverse object categories, and out-of-distribution human-object configurations, while maintaining physically coherent, whole-body coordination.
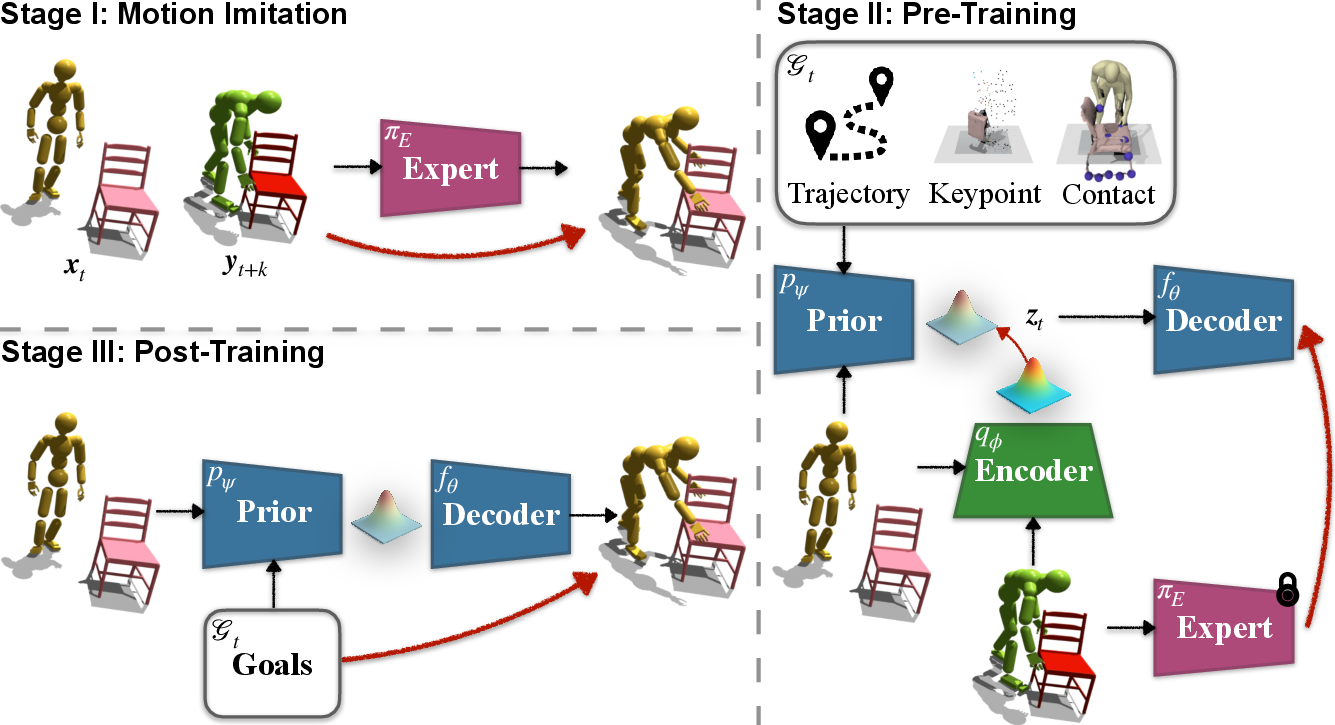
Figure 1: Overview of the InterPrior framework, highlighting its modular stages: imitation expert training, variational distillation into a structured latent policy, and RL post-training for generalization and robustness.
Technical Approach
Policy Architecture and Goal Conditioning
The policy π is modeled to operate within a physics simulator, producing HOI motion sequences from high-level goals, which encompass both snapshot (single-frame) and trajectory (multi-frame) targets, and contact schedules. Sparse goal conditioning is realized via masked residual encoding, supporting flexible specification of human joints, object states, and interaction/contact features. The policy input is composed of aggregations of human/object kinematics, signed distances, and binary contacts, all normalized for invariance.
Actions are specified as joint position targets, mapped via exponential coordinates into torques using PD control, enabling direct actuation of both SMPL humanoid and Unitree G1 robots.
Three-Stage Modular Training
- Imitation Expert (InterMimic+): An expert policy πE is trained via PPO to co-track human and object reference trajectories using composite rewards for precise tracking, physical plausibility, and efficient energy use. Robustness is augmented through episode randomization, physical perturbations, domain randomization, and reference-free contact rewards targeting hand-object alignment. This reduces over-reliance on reference and promotes stable interaction even under noisy initialization or thin-object regimes.

Figure 2: Qualitative comparison of reference imitation, where InterPrior corrects for contact misalignment under perturbation, outperforming prior rigid tracking paradigms.
- Variational Distillation: The expert is distilled into a goal-conditioned variational policy π using a structured latent space. Training leverages online DAgger rollout mixing, an ELBO-based composite loss with imitation, masked goal reconstruction, and KL regularization between a Transformer prior and Gaussian encoder. Additional latent shaping losses enforce hypersphere normalization and temporal consistency to regularize skill embeddings. Auxiliary heads reconstruct masked goals, ensuring intent entanglement and coherent context completion.
- RL Finetuning (Post-Training): RL is applied to the distilled policy as a local optimizer on the prior manifold, supporting in-betweening from randomly sampled initializations toward arbitrary, single-frame goals. Sparse success rewards, reference-free contact objectives, and failure reset mechanisms enhance robustness and enable recovery strategies (regrasp, correction, failure recovery). Multi-objective schedules maintain distillation regularization during RL, mitigating catastrophic forgetting and consolidating natural learned behaviors.
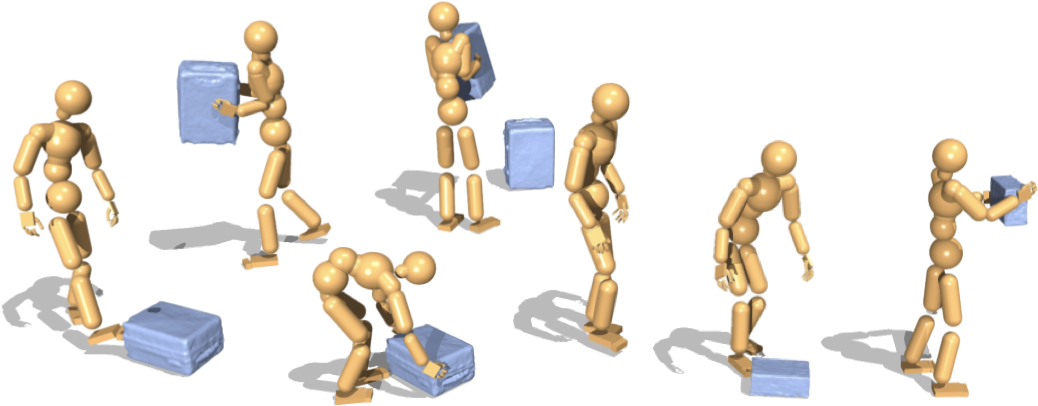
Figure 3: Multi-object task execution showing dynamic policy switching from one object to another, evidencing generalizable manipulation.
Experimental Results
Quantitative Analysis
InterPrior outperforms baseline imitation-based controllers and mask-conditioned policies on broad evaluation across snapshot, trajectory, contact, and multi-goal chain tasks. Success rates and error metrics evidence improvements in robustness, especially under distributional shift (random initialization, chaining) and thin-object manipulation. RL finetuning is particularly effective in expanding viable state coverage and enabling recovery from perturbations, maintaining precision during trajectory following and snapshot completion.
Qualitative Demonstrations
- Contact Correction and Failure Recovery: InterPrior self-corrects contact drift by deviating from reference in targeted manner, maintaining grasp stability and reducing fall rate.
- Long-Horizon and Multi-Object Control: Minute-scale interaction sequences involving approach, grasp, lift, reposition, and object swapping are performed coherently, with smooth skill transitions and recovery from drift.
- Zero-Shot Generalization: The policy generalizes to unseen objects and interaction styles guided by sparse goals, successfully synthesizing plausible contact configurations even with shape discrepancies.
- Sim-to-Sim Transfer: Cross-simulator evaluation (IsaacGym to MuJoCo) confirms retention of interaction competence and transfer potential to real robot deployment.
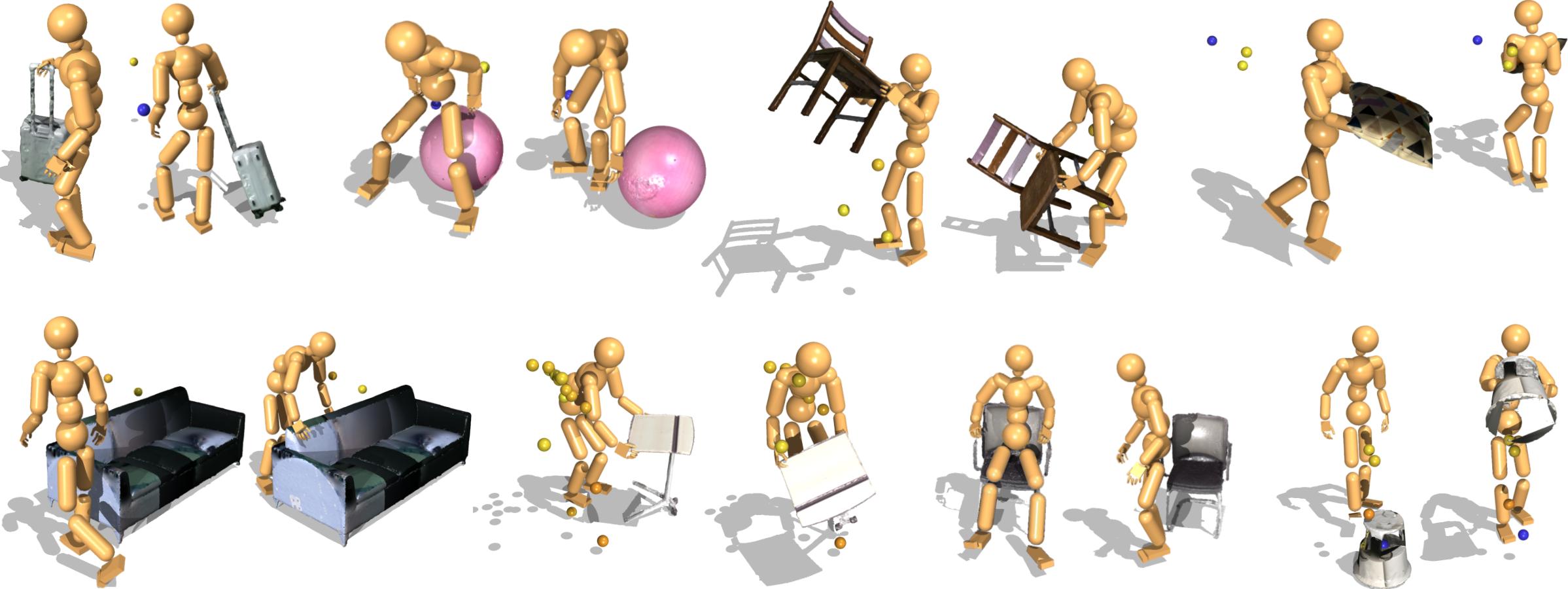
Figure 4: Zero-shot generalization where InterPrior adapts to novel objects and datasets (BEHAVE, HODome) without retraining.

Figure 5: Simulation-to-simulation transfer highlights persistent control capabilities under object-conditioned goals.

Figure 6: Comparative rollouts showing InterPrior's superior recovery from data imperfections, maintaining task continuity.

Figure 7: Additional rollouts with baseline comparisons, underscoring higher task success rates of InterPrior.

Figure 8: Diverse valid trajectories generated for an identical goal, demonstrating latent space expressivity.

Figure 9: Following goals from a kinematic HOI generator, InterPrior adapts and completes the interaction with sparse targets.
Ablation Study
A cumulative ablation shows progressive benefits of expert upgrades, latent regularization, bounding, and RL finetuning, with pronounced improvements in stress-test scenarios (chaining, random initialization). Latent shaping and bounding notably mitigate drift, and RL post-training directly enhances interpolation between skills and recovery behaviors. Trajectory-following performance is preserved via concurrent distillation loss and mask engineering.
Implications and Future Directions
InterPrior exemplifies a scalable recipe for unified, generative control in physics-based HOI, functioning as a reusable prior adaptable to new datasets and robot embodiments. The policy maintains human-like coordination under dynamic contexts, composes and transitions skills, and recovers from failures, all from sparse, multimodal goal conditions. Its independence from trajectory replay and explicit planners enables practical deployment for interactive, teleoperated, or assistive humanoid control, advancing generalization, robustness, and composability.
Potential extensions involve integration of perceptual inputs (visual, tactile), language-based goal conditioning, richer affordance representations, and the expansion to soft-body or multi-contact dexterity for advanced manipulation tasks. The approach provides a foundational paradigm for real-world sim-to-real transfer in humanoid assistive robotics and interactive entertainment, subject to ethical considerations for deployment.
Conclusion
InterPrior delivers a robust, composable, and generalizable generative controller for physics-based human-object interaction, synthesizing large-scale imitation and RL finetuning on structured latent spaces. This decoupled paradigm broadens coverage across tasks, skills, and dynamics, supports multi-context goal conditioning, and enables real-time interactive deployment for both simulated and physical humanoid agents (2602.06035).