DFlash: Block Diffusion for Flash Speculative Decoding
Abstract: Autoregressive LLMs deliver strong performance but require inherently sequential decoding, leading to high inference latency and poor GPU utilization. Speculative decoding mitigates this bottleneck by using a fast draft model whose outputs are verified in parallel by the target LLM; however, existing methods still rely on autoregressive drafting, which remains sequential and limits practical speedups. Diffusion LLMs offer a promising alternative by enabling parallel generation, but current diffusion models typically underperform compared with autoregressive models. In this paper, we introduce DFlash, a speculative decoding framework that employs a lightweight block diffusion model for parallel drafting. By generating draft tokens in a single forward pass and conditioning the draft model on context features extracted from the target model, DFlash enables efficient drafting with high-quality outputs and higher acceptance rates. Experiments show that DFlash achieves over 6x lossless acceleration across a range of models and tasks, delivering up to 2.5x higher speedup than the state-of-the-art speculative decoding method EAGLE-3.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces a way to make big AI LLMs much faster when they’re writing long answers. The method is called DFlash. It combines two ideas:
- A small, fast “drafter” that guesses several next words at once.
- A big, careful “checker” (the main model) that quickly verifies those guesses in parallel.
The twist: the drafter uses a “diffusion” approach to write a whole block of words in one shot, and it gets helpful hints from the checker’s internal thinking. This keeps the final answer just as accurate as usual, while speeding things up a lot.
What questions does the paper try to answer?
In simple terms, the authors ask:
- Can we draft multiple future words at the same time (in parallel) without hurting quality?
- Can a small diffusion-based drafter be both fast and accurate?
- If the drafter uses extra “hints” from the big model, will the checker accept more of its guesses, making everything faster?
- Will this work in real systems and give big speed improvements?
How does DFlash work?
Think of writing with AI like this:
- Autoregressive writing: The model writes one word at a time, and each new word depends on everything written before. This is accurate, but slow.
- Speculative decoding: A smaller helper model (drafter) guesses a bunch of upcoming words. The big model (checker) then quickly verifies them all in parallel. If most guesses are right, we skip ahead fast.
DFlash’s key ideas:
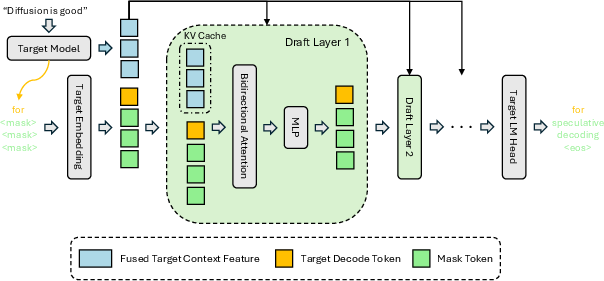
- Parallel drafting with diffusion: Instead of guessing words one-by-one, DFlash’s drafter guesses a whole block of words in one forward pass, like filling in multiple blanks at once. That’s much faster on GPUs.
- Using the checker’s hidden hints: The big model has rich internal features (its “hidden states”) that include information about likely future words. DFlash taps into those features and feeds them into the drafter, so the drafter isn’t guessing blind—it’s guided.
- KV injection (explained simply): Inside transformer models, each layer keeps short-term memory called a “KV cache” (Key-Value cache). DFlash injects the checker’s hints directly into the drafter’s KV cache at every layer. This keeps the drafter strongly guided throughout, helping it write better drafts the checker accepts.
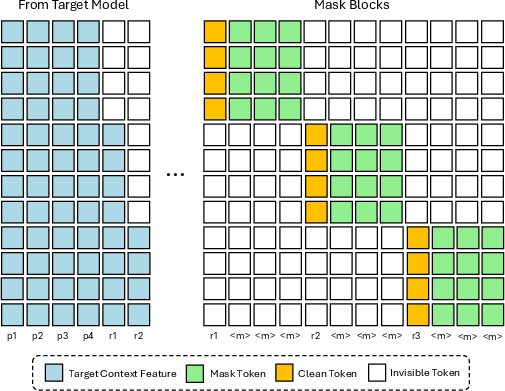
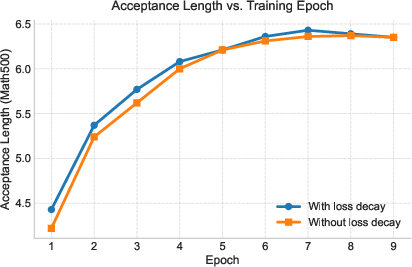
- Training that matches real use: During training, the drafter practices predicting the next block of words given a clean “anchor” word (just like it would after a checker accepts some words). The model is trained to pay extra attention to getting the early words in each block right (because one wrong early word can spoil the rest of the block).
A friendly analogy:
- The big model is like a careful editor who knows the whole story.
- The small drafter is like a fast assistant who drafts the next paragraph.
- The editor gives the assistant strong hints about the plot (hidden features).
- The assistant writes several sentences at once (block drafting).
- The editor then checks the paragraph quickly. If it’s good, they keep it; if not, they correct it.
A simple speed formula:
- Average time per word is roughly: L = (time to draft + time to verify) / accepted words per cycle.
- DFlash reduces “time to draft” by doing blocks in one pass, and increases “accepted words per cycle” by using the editor’s hints.
What did the researchers do to test this?
They:
- Built a small block-diffusion drafter (often 5 layers).
- Conditioned it on the big model’s hidden features by injecting them into the drafter’s KV cache.
- Trained it to predict blocks of words (e.g., 16 at a time) with a special attention pattern so blocks don’t “peek” at each other.
- Weighted the training loss so early positions in each block are learned more carefully.
- Shared the token embedding and output head with the big model to keep training light and well-aligned.
- Ran many experiments on math, coding, and chat tasks using popular models like Qwen3 and LLaMA, and measured speedups and how many drafted words got accepted.
What were the main findings, and why do they matter?
Key results:
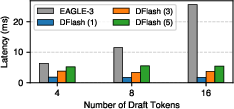
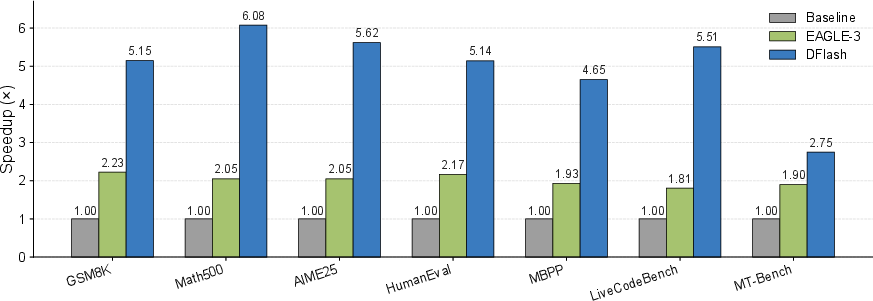
- Big speedups: DFlash achieved up to about 6× faster generation than normal one-word-at-a-time decoding, and about 2.5× faster than a leading speculative method called EAGLE-3.
- High acceptance: Because the drafter is guided by the big model’s hidden features, the checker accepts more drafted words each cycle. This is crucial for speed.
- Works in real systems: In a production-like setup (SGLang), DFlash improved throughput across different workloads and concurrency levels (how many requests run at once).
- Flexible design:
- More drafter layers can increase acceptance, but you balance depth with speed. In many cases, 5 layers gave the best overall speed.
- Using more hidden features from the big model improves draft quality.
- Training on larger block sizes (like 16) helps the model generalize well if you use smaller blocks at test time.
Why it matters:
- Faster responses: Long reasoning and coding answers can take a while. DFlash cuts that waiting time significantly.
- Better GPU usage: Generating blocks in parallel makes hardware run more efficiently.
- Lower serving costs: Speed and throughput improvements mean you can serve more users with fewer resources.
- Quality remains “lossless”: The big model still verifies the final output, so you don’t trade speed for correctness.
What’s the bigger impact?
DFlash shows a new way to combine two strengths:
- Autoregressive models are great at quality and understanding context.
- Diffusion-style drafting is great at parallel speed.
By letting diffusion be the fast helper (not the final writer) and letting the big model be the careful verifier, you get the best of both worlds: speed without losing accuracy. This could make powerful AI systems more accessible, cheaper to run, and quicker to respond—especially for long, complex tasks like math, coding, and step-by-step reasoning.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a focused list of what remains missing, uncertain, or unexplored, formulated to guide actionable future research:
- Theoretical correctness under stochastic decoding: Provide formal guarantees (and empirical verification) that DFlash’s speculative protocol with block diffusion and KV-injected conditioning preserves the exact target distribution for non-greedy settings (temperature, top-k/top-p, penalties), and under scheduling overlaps (Spec-v1/v2).
- Diffusion process specification and ablation: Clarify the discrete diffusion kernel, noise/corruption schedule, timestep sampling, and number of denoising steps (if any); systematically ablate step count vs. acceptance length vs. latency to quantify the true “diffusion” contribution beyond single-pass masked prediction.
- Memory and compute overhead of KV injection: Quantify per-layer and end-to-end memory increase in the draft model’s KV cache due to injected target features; report the impact on bandwidth, cache size, and latency for long contexts (e.g., 32k–200k tokens), large batches, and multi-GPU pipeline/tensor parallelism.
- “Lightweight” drafter characterization: Report exact parameter counts, FLOPs/forward, and GPU memory footprint of DFlash drafters across settings; compare to EAGLE-3 and large dLLM drafters to substantiate the lightweight claim.
- Scaling to larger targets and architectures: Evaluate with ≥14B/32B/70B dense targets, MoE targets, and non-LLaMA/Qwen families; characterize whether acceptance gains persist and how many target layers/features are optimal at larger scales.
- Robustness across task families: Extend beyond math/code/chat to summarization, translation, factual QA, long-form creative writing, and instruction-following; analyze why acceptance is notably lower on chat tasks and identify remedies.
- Multilingual generalization: Test on diverse languages and tokenization regimes (morphologically rich, logographic scripts) to assess acceptance stability and block-size effectiveness across languages.
- Very long output regimes: Evaluate for outputs far beyond 2k tokens (e.g., 10k–100k), measuring speedup, acceptance drift over long horizons, KV/cache pressure, and latency tails (p95/p99).
- Adaptive block-size scheduling (explicitly left to future work): Design and evaluate online policies that adjust block size per step/batch/concurrency to optimize end-to-end speedup under compute- vs memory-bound regimes.
- Quantization compatibility: Measure effects of INT8/INT4/FP8 quantization (target and/or drafter) on hidden-feature fidelity, acceptance length, and speed; study mitigation (e.g., selective dequantization for feature layers).
- Compatibility with KV paging/compression and attention variants: Test with paged KV caches, KV compression, FlashAttention variants (FA2/FA3/FA4), and assess accuracy/speed trade-offs and potential conflicts with KV injection.
- Concurrency and backend generality: Provide broader evaluations across inference stacks (vLLM, TensorRT-LLM, FasterTransformer, DeepSpeed-FastGen) and hardware (A100/H100/consumer GPUs/TPUs), analyzing why speedups decay at high concurrency and how scheduler co-design can recover throughput.
- Comprehensive stochastic decoding study: Map acceptance and speed under systematic sweeps of temperature, top-k/top-p, repetition/frequency penalties, and mixed decoding strategies; verify correctness and practical speedups in highly stochastic regimes (e.g., creative writing).
- Fair comparisons with diffusion-based speculative baselines: Re-implement or re-run DiffuSpec, SpecDiff-2, TiDAR under a unified setup to isolate the gains from KV injection vs. model size/compute, avoiding ambiguity due to unavailable implementations.
- Conditioning mechanism alternatives: Compare KV injection against cross-attention, residual gating/conditioning, FiLM, and hybrid per-layer conditioning; characterize how acceptance scales with depth and where to inject features for best accuracy/latency.
- Training sensitivity and stability: Systematically study sensitivity to loss-decay factor γ, number/placement of target layers, number of anchors per block, masking ratios, optimizer and LR schedule, and draft depth; report convergence curves and compute budgets.
- Data dependence and domain shift: Quantify how training on target-generated responses affects overfitting to the target’s idiosyncrasies; test robustness under domain shifts (e.g., out-of-domain prompts, noisy inputs) and with alternative data mixtures/licensing constraints.
- Portability across targets: Investigate whether a single DFlash drafter can serve multiple targets (multi-target adapters, conditional routing) or be rapidly adapted via PEFT/LoRA to new targets to amortize training cost.
- Safety, isolation, and multi-tenant serving: Analyze risks of KV-injection bugs causing cross-request leakage in batched serving; propose formal isolation guarantees, unit tests, and runtime checks.
- Energy and cost efficiency: Report joules/token and $/1k tokens across concurrency levels to confirm that latency/throughput gains translate to real energy/cost savings in production.
- Acceptance error forensics: Provide per-position error distributions, typical failure patterns within blocks, and attention diagnostics; explore objectives that directly maximize expected acceptance rather than token-wise cross-entropy.
- Multi-step diffusion refinements: Evaluate whether 2–3 lightweight refinement steps meaningfully boost acceptance at modest latency cost, and characterize the Pareto frontier (latency vs. acceptance).
- Integration with tool use and CoT: Test when outputs interleave with tool calls/RAG retrieval or use explicit “thinking” traces; assess how KV resets and tool I/O affect conditioning and acceptance.
- Extensions to MoE and multimodal targets: Study how KV-injected conditioning works with expert routing in MoE and with vision-language/audio-LLMs (conditioning on multimodal hidden states).
- Reproducibility details: Provide missing training specifics (diffusion corruption schedule, masking/anchor sampling distributions, exact attention masks), seeds, and full configs; include wall-clock training cost and hardware profiles.
Practical Applications
Immediate Applications
The following items translate DFlash’s findings into deployable, real-world uses. Each bullet lists target sector(s), concrete use cases, likely tools/products/workflows, and key dependencies/assumptions that affect feasibility.
- Industry (Software, Cloud/AI Platforms, Customer Support)
- Use case: Cut LLM serving latency and cost for chatbots, copilots, and RAG services by replacing autoregressive-only decoding with DFlash speculative decoding.
- Tools/products/workflows:
- “DFlash-enabled” endpoints in inference platforms (e.g., SGLang integration as shown; vLLM/TensorRT-LLM plugins next).
- Deployment cookbook: pick target (e.g., Qwen3-8B, Llama-3.1-8B), train/plug in 5-layer DFlash drafter (block size 10–16), tune acceptance length τ and block size per workload, monitor throughput and TCO.
- Acceptance-aware autoscaling (scale-out based on τ, tokens/s).
- Dependencies/assumptions:
- Access to open-weight target models or internals (hidden states, KV cache hooks). Closed APIs that hide internals limit adoption.
- Inference stack that supports KV injection and block-parallel decoding (e.g., SGLang FA4; GPU kernels like FlashAttention-4).
- Drafter must be trained per target model (or per family); domain alignment of training data affects τ and speedup.
- Speedups are strongest with greedy or low-temperature sampling; high sampling temperatures may reduce τ.
- Use case: Accelerate CoT-heavy agents (planning, tool-use) without degrading quality.
- Tools/products/workflows:
- “Reasoning mode” endpoints with DFlash to maintain long CoT while hitting 4×–5× speedups.
- Agent frameworks (e.g., LangGraph/LangChain pipelines) with DFlash-aware nodes.
- Dependencies/assumptions:
- Train drafter on target outputs that include reasoning traces; ensure loss weighting prioritizes early-token accuracy within blocks.
- Verify acceptance under task-typical temperatures.
- Use case: Throughput gains for batch content operations (summarization, code generation, document processing) to meet strict SLAs.
- Tools/products/workflows:
- Batch servicers with dynamic block-size scheduling (use larger blocks at low concurrency; shrink blocks at high concurrency to balance verification cost).
- Cost-aware scheduling: co-optimize block size, concurrency, and τ to maximize tokens/s per GPU.
- Dependencies/assumptions:
- Hardware scaling behavior matters: verification can become compute-bound at high concurrency; block size tuning is needed.
- Requires measurement pipelines for τ, latency components (draft vs verify), and acceptance histograms.
- Use case: Edge/enterprise on-prem deployments that require faster responses on limited GPUs.
- Tools/products/workflows:
- Packaged DFlash drafters for popular open models (Qwen3-4B/8B, Llama-3.1-8B) with installation scripts for SGLang.
- Dependencies/assumptions:
- Sufficient GPU memory and kernel support; quantization/low-precision must preserve draft quality (τ).
- Admin ability to modify backends for KV injection.
- Academia (ML Research, Systems)
- Use case: Faster evaluation loops for long-context and reasoning benchmarks (GSM8K, MATH-500, AIME, HumanEval) while keeping results lossless.
- Tools/products/workflows:
- Benchmark harnesses with pluggable decoding backends; acceptance-length dashboards per task and temperature.
- Dependencies/assumptions:
- Reproducibility requires identical verification settings to baseline; ensure logging of τ, block size, draft depth.
- Use case: Study diffusion–autoregression synergy and future-token information in hidden states at scale.
- Tools/products/workflows:
- Ablation libraries for number of target layers used as conditioning, anchor sampling, and loss weighting strategies.
- Dependencies/assumptions:
- Availability of training data with target-generated responses; storage for cached hidden states increases with number of conditioned layers.
- Use case: Large-scale synthetic data generation and program synthesis at lower cost.
- Tools/products/workflows:
- DFlash-enabled data generation pipelines with safety verification unchanged (lossless).
- Dependencies/assumptions:
- Maintain the “lossless” verification path to keep data quality identical to baseline model.
- Policy and Public Sector (Energy, Accessibility, Procurement)
- Use case: Reduce datacenter energy per token for public-facing AI services without changing outputs.
- Tools/products/workflows:
- Energy/TPS reporting that includes speculative decoding metrics (τ, draft/verify latency, tokens/Joule).
- Procurement guidelines: require energy and throughput baselines with and without speculative decoding.
- Dependencies/assumptions:
- Actual energy savings depend on hardware, concurrency, and backend kernels; verify under representative loads.
- Use case: Broaden access to higher-quality models by lowering serving costs for public services.
- Tools/products/workflows:
- “Lossless acceleration” certification for regulated domains (outputs identical to baseline autoregressive decoding).
- Dependencies/assumptions:
- Must demonstrate equality of outputs across supported decoding settings (e.g., greedy or specified sampling).
- Daily Life (Consumer Apps, Productivity)
- Use case: Snappier AI assistants and code copilots on PCs and workstations running open-weight models.
- Tools/products/workflows:
- Desktop distributions bundling DFlash drafters for popular community models; toggles for block size vs quality.
- Dependencies/assumptions:
- User hardware must support modern attention kernels; acceptance may dip at high creative temperatures.
- Use case: Faster on-device/offline writing aids and translators using small-to-medium open models.
- Tools/products/workflows:
- Local inference launchers with DFlash baked in and pre-tuned defaults.
- Dependencies/assumptions:
- Room to train/ship a drafter aligned to the chosen target model; some devices may lack required GPU features.
Long-Term Applications
These items need additional research, scaling, standardization, or engineering before broad deployment.
- Cross-Model and Closed-Model Adoption (Software, Cloud)
- Use case: Universal or “family-level” drafters that generalize across multiple targets to avoid per-model training.
- Tools/products/workflows:
- Drafter adapters trained on mixed targets; APIs to negotiate conditioning features per model.
- Dependencies/assumptions:
- Requires standardized interfaces for hidden-state access or alternative conditioning (e.g., distilled feature predictors).
- Use case: DFlash-like speedups for proprietary/closed LLMs that do not expose hidden states.
- Tools/products/workflows:
- Logit-only conditioning approximations, feature predictors via side models, or server-side “feature plugin” APIs.
- Dependencies/assumptions:
- Needs collaboration with model vendors or advances in reconstructing useful context from accessible signals.
- Multimodal and Robotics (Vision, Speech, Embodied AI)
- Use case: Parallel drafting for multimodal LMMs (image, audio) to accelerate captioning, transcription, and agent planning.
- Tools/products/workflows:
- Multimodal block diffusion drafters with KV injection over cross-modal backbones; streaming-friendly schedulers.
- Dependencies/assumptions:
- Robust training of diffusion blocks for multimodal tokens; alignment with diverse hidden feature spaces.
- Use case: Real-time instruction following for robots with reduced language latency during planning/execution loops.
- Tools/products/workflows:
- ROS-compatible inference nodes with DFlash; acceptance-aware control policies that budget plan tokens.
- Dependencies/assumptions:
- Hard real-time requirements demand predictable τ and verification latency; safety validation needed.
- Hardware/Compiler Co-Design (Semiconductors, Systems)
- Use case: Specialized kernels/accelerators for block diffusion and KV-injection workflows.
- Tools/products/workflows:
- Compiler passes to fuse KV injection; hardware primitives for block-wise denoise and cache reuse; SRAM budgeting for injected features.
- Dependencies/assumptions:
- Requires stable abstractions for speculative decoding in compilers and runtimes; vendor support.
- Use case: Adaptive block-size schedulers integrated with cluster orchestration to optimize throughput under varying loads.
- Tools/products/workflows:
- Runtime controllers that tune block size and draft depth by monitoring verify cost and τ in real time.
- Dependencies/assumptions:
- Needs accurate online τ prediction and low-overhead telemetry.
- Sector-Specific High-Assurance Uses (Healthcare, Finance, Government)
- Use case: “Lossless-verified” assistants for clinical documentation, prior auth, or regulatory Q&A where output fidelity is critical.
- Tools/products/workflows:
- Certified pipelines that cryptographically attest verification and equivalence to baseline outputs; audit logs of draft/verify steps.
- Dependencies/assumptions:
- Formalization of “lossless” under sampling regimes; expanded test suites for edge cases.
- Education and Research Platforms
- Use case: Long-form tutoring and step-by-step reasoning with low latency to improve engagement and interactivity.
- Tools/products/workflows:
- Classroom-ready servers with DFlash-enabled reasoning models; dashboards for progress and explanation steps.
- Dependencies/assumptions:
- Additional UX studies; content safety policies unchanged by acceleration (verification ensures identical content).
- Sustainability and Policy
- Use case: Energy-aware inference standards and reporting frameworks that incorporate speculative decoding efficiency.
- Tools/products/workflows:
- Tokens-per-Joule benchmarks by scenario (concurrency, temperature, block size); procurement criteria for public funding.
- Dependencies/assumptions:
- Broad agreement on measurement protocols; cooperation from cloud providers on metering.
- Developer Tools and Ecosystem
- Use case: IDE/tooling support to profile and tune acceptance length τ and block size per project.
- Tools/products/workflows:
- “Spec-decoding profiler” plugins; CI checks that guardrail τ and latency regressions.
- Dependencies/assumptions:
- Stable APIs from serving stacks; standardized metrics.
- Generalization and Robustness Research
- Use case: Drafters that adapt to domain shifts (legal/medical) with minimal retraining while maintaining high τ.
- Tools/products/workflows:
- Lightweight finetuning recipes (LoRA) for the drafter; curricula for anchor sampling strategies.
- Dependencies/assumptions:
- Availability of target-generated responses in new domains; privacy constraints for logging hidden states.
Notes on Feasibility and Assumptions (Cross-Cutting)
- Model access: DFlash depends on conditioning the drafter with target hidden features and injecting them into KV caches. Open-weight models are ideal; proprietary models may require new APIs or approximations.
- Training cost: Each target model typically needs its own small drafter; training uses 100k–800k samples of target outputs. Storage for cached hidden states scales with number of conditioned layers.
- Workload sensitivity: Acceptance length τ and speedup vary by temperature, task (math/code/chat), and block size. Greedy decoding delivers the highest gains.
- Backend maturity: Current best results rely on backends like SGLang with FA4 and efficient KV handling; porting to other stacks may require engineering effort.
- Verification cost: Very large block sizes can increase verify cost under high concurrency; adaptive scheduling is recommended.
- Quality guarantees: When verification is unchanged, final outputs remain identical to baseline (lossless). Any deviation in verification settings or sampling changes this guarantee.
Glossary
- Acceptance length: The expected number of consecutive draft tokens accepted per cycle in speculative decoding, often denoted by τ. Example: "average acceptance length ()"
- Acceptance rates: The proportion of draft tokens accepted by the target model during verification. Example: "higher acceptance rates"
- Anchor tokens: Clean tokens used as starting points of blocks during training to condition parallel prediction of subsequent tokens. Example: "We randomly sample anchor tokens from the response"
- Autoregressive: A generation paradigm where each new token is produced sequentially conditioned on all previous tokens. Example: "Autoregressive LLMs deliver strong performance"
- Bidirectional context modeling: Modeling that uses both left and right context to inform predictions, typical in diffusion LLMs. Example: "bidirectional context modeling"
- Block diffusion: A diffusion approach that denoises multiple masked positions in a sequence block simultaneously. Example: "Block diffusion models can denoise a block of masked tokens simultaneously."
- Block-level diffusion process: A diffusion procedure that predicts an entire block of tokens in parallel rather than token-by-token. Example: "a block-level diffusion process"
- Block-wise parallel generation: Generating multiple tokens concurrently across a block to improve hardware utilization and reduce latency. Example: "block-wise parallel generation substantially reduces drafting latency"
- Bonus token: The extra token produced by the target model during verification that can be used to seed the next draft block. Example: "including the bonus token produced by the target model."
- Causal consistency: An attention masking property ensuring tokens only depend on allowable prior information, preserving causal structure. Example: "enforces causal consistency"
- Conditioning: Incorporating auxiliary context (e.g., target-model features) into a model’s computations to guide predictions. Example: "Conditioning via KV injection enables acceptance scaling."
- Denoising steps: Iterative steps in diffusion models used to progressively refine predictions from noise. Example: "a high number of denoising steps"
- Diffusion adapter: A lightweight module that leverages diffusion-style prediction while relying on a target model’s representations. Example: "becomes a diffusion adapter"
- Diffusion drafters: Draft models that use diffusion to propose multiple tokens in parallel for speculative decoding. Example: "Diffusion drafters generate all tokens in parallel"
- Diffusion LLMs (dLLMs): LLMs trained with diffusion objectives enabling parallel token prediction. Example: "Diffusion LLMs (dLLMs) offer a promising alternative"
- Draft model: A smaller model that proposes candidate tokens which are later verified by a larger target model. Example: "a lightweight draft model"
- Draft tree: A tree-structured set of speculative token proposals to increase the chance of acceptance. Example: "adaptive drafting trees"
- EAGLE-3: A state-of-the-art speculative decoding method that scales speedups via training-time test refinements. Example: "EAGLE-3 refines training objectives to scale speedups."
- Flex Attention: A programmable attention mechanism enabling efficient custom sparsity patterns during training or inference. Example: "using Flex Attention"
- FlashAttention-4 (FA4): A high-performance attention kernel/backend optimized for fast transformer inference. Example: "FlashAttention-4 (FA4) backend."
- Flashinfer backend: An inference backend providing optimized kernels for transformer decoding. Example: "Flashinfer backend"
- Greedy decoding: Deterministic decoding that selects the highest-probability token at each step. Example: "Under greedy decoding (temperature = 0)"
- Key and Value projections: The linear transformations producing K and V tensors for attention mechanisms. Example: "Key and Value projections of every draft model layer"
- Key-Value cache (KV cache): Cached K and V tensors reused across decoding steps to avoid recomputation. Example: "injected into each draft layer's Key-Value cache"
- KV injection: Injecting external context features directly into the Key and Value tensors of attention layers. Example: "KV injection enables acceptance scaling."
- Language modeling head (LM head): The final projection layer mapping hidden states to token logits. Example: "Shared embedding and LM head."
- LoRA adapter: A low-rank adaptation module enabling parameter-efficient fine-tuning of large models. Example: "train a LoRA adapter to enable parallel drafting"
- Lossless acceleration: Speedup techniques that preserve the exact output distribution of the base model. Example: "achieves lossless acceleration"
- Medusa: A speculative decoding approach that uses multiple decoding heads in the base model rather than an external drafter. Example: "Medusa eliminates the external draft model"
- Pareto frontier: The trade-off curve where improving one metric (e.g., latency) cannot occur without degrading another (e.g., acceptance). Example: "a more favorable Pareto frontier"
- Prefill pass: An initial forward pass over the prompt (and possibly first token) to populate caches and context. Example: "performs a standard prefill pass"
- SGLang: An open-source inference framework for efficient structured LLM execution. Example: "the popular open-source inference framework SGLang"
- Sparse attention mask: An attention pattern where only a subset of token pairs are allowed to attend, improving efficiency. Example: "a sparse attention mask"
- Speculative decoding: A method that drafts tokens with a small model and verifies them in parallel with a larger model for speed. Example: "Speculative decoding accelerates LLM inference"
- Speculative verification: The process of checking drafted tokens with the target model to guarantee output quality. Example: "speculative verification provides a principled guarantee of output quality."
- Target hidden features: Internal representations extracted from the target model to condition the drafter. Example: "The target hidden features are extracted from 5 layers uniformly selected"
- Temperature: A sampling parameter controlling randomness by scaling logits before softmax. Example: "Temperature = 0"
- Top-k: A sampling technique restricting choices to the k highest-probability tokens. Example: "top- are set to 7 and 10, respectively."
- Tree attention: An attention mechanism tailored to verify multiple draft branches in parallel. Example: "using tree attention for parallel verification."
- Verification: The step where the target model evaluates drafted tokens, accepting as many as match its own predictions. Example: "verified in parallel by the target model"
- Verification overhead: The computational cost incurred by the target model when checking drafted tokens. Example: "lower verification overhead"
Collections
Sign up for free to add this paper to one or more collections.