Shared LoRA Subspaces for almost Strict Continual Learning
Abstract: Adapting large pretrained models to new tasks efficiently and continually is crucial for real-world deployment but remains challenging due to catastrophic forgetting and the high cost of retraining. While parameter-efficient tuning methods like low rank adaptation (LoRA) reduce computational demands, they lack mechanisms for strict continual learning and knowledge integration, without relying on data replay, or multiple adapters. We propose Share, a novel approach to parameter efficient continual finetuning that learns and dynamically updates a single, shared low-rank subspace, enabling seamless adaptation across multiple tasks and modalities. Share constructs a foundational subspace that extracts core knowledge from past tasks and incrementally integrates new information by identifying essential subspace directions. Knowledge from each new task is incorporated into this evolving subspace, facilitating forward knowledge transfer, while minimizing catastrophic interference. This approach achieves up to 100x parameter reduction and 281x memory savings over traditional LoRA methods, maintaining performance comparable to jointly trained models. A single Share model can replace hundreds of task-specific LoRA adapters, supporting scalable, asynchronous continual learning. Experiments across image classification, natural language understanding, 3D pose estimation, and text-to-image generation validate its effectiveness, making Share a practical and scalable solution for lifelong learning in large-scale AI systems.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces a new way to help large AI models (like LLMs and image models) learn new tasks one after another without forgetting what they already know. The method is called “Share.” It focuses on making learning efficient so you don’t have to retrain millions of model parameters every time, and it avoids storing old data or keeping many separate “add-on” pieces. Share finds and updates a single shared “learning space” that different tasks can use, so the model keeps getting better while staying small and fast.
Key Questions
The paper asks:
- Can we make big AI models learn continuously (task after task) without forgetting old tasks, while using very few extra parameters?
- Is there a common “subspace” (think of it like a shared set of directions the model can adjust) that works across many different tasks?
- Can we update that shared subspace over time so new tasks benefit from old knowledge, and old tasks don’t get worse?
How the Method Works
Think of a large AI model as a huge machine with lots of knobs. Traditional fine-tuning turns many knobs, which is slow and memory-heavy. LoRA (Low-Rank Adaptation) is a popular trick that adds small, trainable “adapters” to each layer, so you only turn a few important knobs. However, standard LoRA usually needs one adapter per task, which piles up and doesn’t share knowledge well.
Share improves on this by learning a single, shared “toolbox” of key directions (basis vectors) the model can use for many tasks. For each new task, you only learn tiny “coefficients” that say how much to use each tool, instead of adding a whole new adapter.
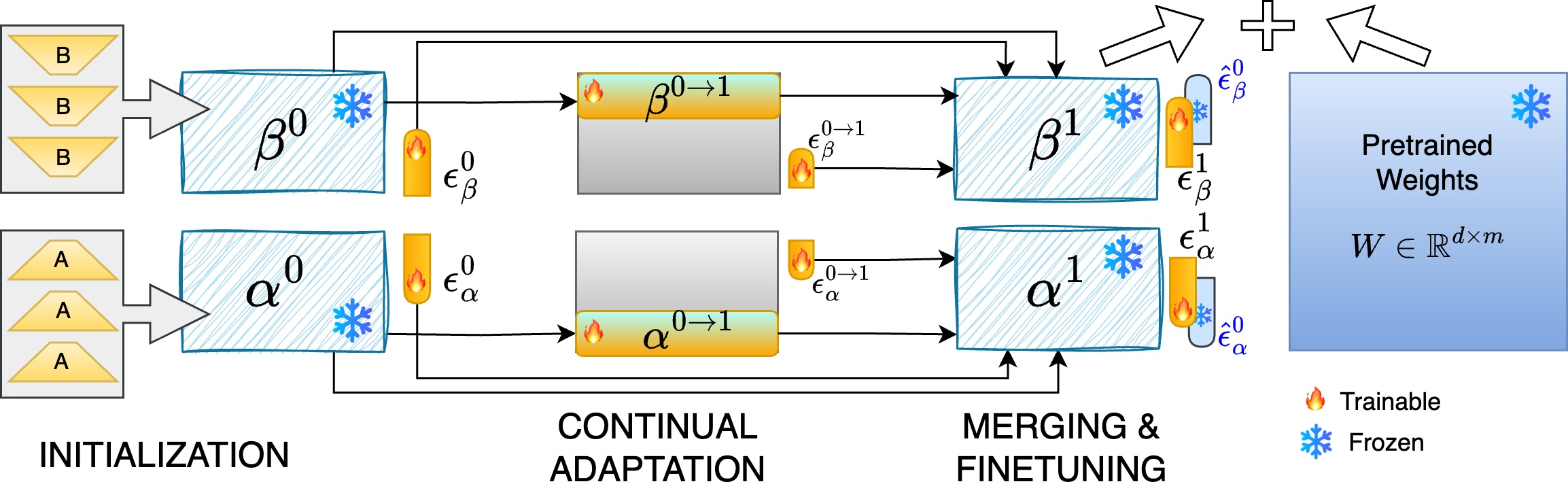
Step 1 — Build a shared toolbox (Initialization)
- Start with one or more LoRA adapters or some initial task data.
- Use a technique called SVD (Singular Value Decomposition). In everyday terms, SVD finds the most important directions of change across tasks—like discovering the main “axes” that explain how adapters adjust the model.
- Freeze these directions (basis vectors). They are your shared toolbox.
- Only learn small coefficients for each task that say “use tool 1 a bit, tool 2 more, tool 3 not at all,” etc.
- This already cuts the number of trainable parameters by a lot because you’re reusing the toolbox instead of building a new adapter each time.
Step 2 — Learn new tasks efficiently (Continual Adaptation)
- When a new task arrives, you temporarily add a few extra directions to the toolbox, just enough to capture what’s new.
- You update the small coefficients for the new task.
- This uses far fewer parameters than training a full LoRA adapter, but lets the model adapt to fresh information.
Step 3 — Merge and polish (Merging and Fine-tuning)
- Fold the newly learned directions back into the main toolbox using SVD again.
- Recompute all task coefficients mathematically (no gradients needed), so older tasks can benefit from the improved toolbox.
- Optionally, do a tiny fine-tune of the coefficients if you’re allowed a bit of extra training data.
- End result: one shared toolbox and a tiny set of coefficients per task—no stack of separate adapters.
A simple analogy
- Basis vectors = shared tools in a toolbox.
- Coefficients = instructions for how much to use each tool on a specific task.
- SVD = a smart way to discover which tools matter most across many tasks.
- Share = a system that keeps refining the toolbox and reuses it, instead of storing a new toolbox for every job.
Main Findings
Across many experiments (language understanding, image classification, 3D pose estimation, text-to-image generation), Share:
- Dramatically reduces cost:
- Up to 100× fewer trainable parameters than standard LoRA.
- Up to 281× memory savings compared to keeping many LoRA adapters.
- Maintains strong performance:
- On the GLUE language benchmark, Share reached about the same average score as separate LoRA adapters while using a tiny fraction of the parameters.
- In image classification (CIFAR‑100, Food‑101, Caltech‑101, Flowers‑102), Share matched or closely approached top performance with fewer parameters and very low forgetting.
- In 3D pose estimation with occlusion, Share outperformed several methods that store old examples, using about 96% fewer parameters.
- In text-to-image generation, Share produced results comparable to individual LoRAs, but with one shared model instead of many.
- Shares knowledge forward and backward:
- As the toolbox improves, earlier tasks sometimes get better too (this is called backward transfer). This is rare and valuable in continual learning.
- Scales to many adapters:
- A single Share model can compress and replace hundreds of task-specific LoRA adapters, and still keep strong performance—even on out-of-distribution tasks.
Here are a few highlights in a compact form:
- Similar accuracy to separate, non‑continual LoRAs in language tasks, with ~100× fewer parameters.
- Near upper‑bound accuracy in several image classification benchmarks, with fewer parameters and minimal forgetting.
- Better occlusion robustness in 3D pose estimation, without storing old data.
- One shared model for many styles in text‑to‑image generation, saving lots of memory and maintenance effort.
Why It Matters
- Lifelong learning: Share helps big models learn continuously, like students gaining new skills over time without forgetting old ones.
- Efficiency and access: Because it needs far fewer parameters and memory, Share makes advanced models more practical for researchers and teams without huge computers. It also reduces environmental impact by cutting training resources.
- Simplicity at scale: Instead of juggling many task-specific adapters, you maintain one shared model with tiny per-task coefficients. This makes deployment and personalization much easier.
- Strong generalization: The shared toolbox captures core knowledge across tasks and even across different types of models (language, vision, generation), helping new tasks start from a strong base.
In short, Share shows that large AI systems can keep learning new things efficiently, reuse what they’ve learned, avoid forgetting, and stay compact—bringing us closer to practical, lifelong learning in real-world AI.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of the paper’s unresolved issues, uncertainties, and areas needing further investigation. Each point is framed to be concrete and actionable for future research.
- Task-ID-free inference: The method retains per-task coefficient sets εi, but does not specify how to select the appropriate coefficients at inference when task identity is unknown. Develop task routing or unsupervised gating mechanisms that work without explicit task labels.
- Storage growth in “almost strict” continual learning: Although basis vectors are shared, storage still grows linearly with tasks due to accumulating εi. Quantify and bound memory growth over long horizons; explore coefficient compression (e.g., clustering, product quantization, low-bit storage) or consolidation strategies.
- Automatic and adaptive hyperparameter selection: The choices of k (basis size), p (pseudo-rank), and φ (temporary expansion) rely on heuristics. Design adaptive criteria (e.g., streaming explained variance thresholds, Bayesian model selection, or MDL-based rules) and validate them under task drift.
- Incremental SVD scalability and stability: The merging step requires SVD over a growing stacked matrix. Analyze computational complexity for large layers and many adapters; implement and evaluate streaming/incremental SVD, randomized SVD, or distributed SVD with numerical stability guarantees.
- Robustness to outlier or adversarial adapters: Merging community LoRAs can introduce noise/poisoning. Investigate robust PCA/SVD variants, outlier detection, and adapter vetting pipelines; quantify subspace contamination and its effect on performance and forgetting.
- Theoretical guarantees for non-convex deep models: Current analysis assumes strong convexity and Lipschitz continuity—conditions that generally do not hold for deep networks. Provide non-convex optimization guarantees (e.g., convergence, generalization, forgetting/transfer bounds) aligned with modern deep-learning theory.
- Conditions for backward transfer: The paper observes backward transfer empirically but does not formalize when and why it occurs. Characterize the task similarity and subspace overlap conditions under which backward transfer is likely; provide diagnostic metrics and predictive criteria.
- Subspace existence and universality across modalities: Evidence for a “foundational subspace” is shown primarily within single modalities/architectures. Test whether shared subspaces exist across architectures and modalities (e.g., text vs. vision vs. diffusion), and analyze layerwise vs. global subspace consistency.
- Cross-layer dependencies: Share treats layers independently. Investigate whether cross-layer coupled subspaces or joint low-rank structures improve retention and transfer; study interactions between layers during merging.
- Freezing W0 limitations: The base weights W0 remain fixed. Explore selective unfreezing policies or hybrid updates that maintain continual constraints but allow limited base-weight adaptation when subspace capacity is insufficient.
- Handling tasks needing higher-rank updates: Fixed k may underfit novel tasks. Develop dynamic rank expansion/pruning policies with clear criteria (e.g., reconstruction error rises beyond a threshold) and analyze their impact on memory and forgetting.
- Long-horizon continual sequences: Most experiments involve ≤10 tasks (except large-scale LoRA experiments). Conduct studies with 100–1000 tasks to quantify stability, drift, memory growth, and retention over lengthy sequences and diverse domains.
- Evaluation breadth for NLU/LLM tasks: GLUE excludes MNLI and QQP; broader LLM capabilities (e.g., multi-step reasoning, tool use, dialog) are not evaluated. Extend benchmarks to complex, multi-turn tasks and safety-critical domains.
- Generative-model evaluation rigor: Text-to-image experiments primarily use qualitative comparisons and limited CLIP-based metrics. Add comprehensive quantitative metrics (e.g., FID, IS, TIFA, human preference studies, safety/toxicity assessments) and report statistical significance.
- Comprehensive baseline coverage: Comparisons omit several relevant PeFT/continual methods for LLMs and diffusion (e.g., prefix/prompt tuning variants, adapter routing/gating, O-LoRA-style orthogonal subspaces). Include broader baselines with consistent settings.
- Inference-time latency and hardware compatibility: The runtime impact of using shared factors vs. standard LoRA is not analyzed. Measure inference latency, memory footprint, and compatibility with quantization and accelerators across tasks/models.
- Asynchronous/distributed updates: The large-scale merging scenario lacks analysis of concurrency, staleness, and order sensitivity. Study merge-order effects, conflict resolution, and consistency in distributed/asynchronous settings; propose protocols for safe concurrent merges.
- Concept drift and continuous streams: The framework assumes discrete tasks. Evaluate performance with continuous, unlabeled streams and non-stationary data; develop online detection of novel directions and automatic subspace adaptation.
- Criteria for adding new directions (φ expansion): Define robust, data-free triggers to add/retain/prune temporary basis vectors (e.g., reconstruction error thresholds, subspace angle metrics, CKA drift); quantify trade-offs.
- Coefficient consolidation across tasks: Investigate whether multiple εi can be merged or factored (e.g., shared components plus sparse task residuals) to reduce storage and improve generalization.
- Safety, privacy, and licensing: Merging third-party adapters may violate licenses or leak private/biased information. Establish provenance tracking, privacy-preserving merging (e.g., DP mechanisms), and safety filters; assess ethical implications.
- Security against poisoning: Adapters can be maliciously crafted. Develop adversarial defenses and verification methods (e.g., certification tests, anomaly detection) before integrating into the shared subspace.
- OOD performance characterization: OOD results are limited and partly reported as relative performance. Systematically evaluate OOD generalization across diverse tasks, quantify degradation, and identify subspace properties that predict robustness.
- Memory savings accounting: The reported 281× savings lack detailed accounting (e.g., optimizer states, activation/gradient memory, temporary expansion φ). Provide comprehensive deployment-level memory profiles and standardized measurement protocols.
- Reproducibility and ablation completeness: Several critical ablations (hyperparameters, merging order, subspace size, per-layer vs. global) are deferred to appendices. Present thorough, main-text ablations with open-source code and seeds to ensure reproducibility.
Practical Applications
Practical Applications of “Shared LoRA Subspaces for almost Strict Continual Learning”
Below are applications derived from the paper’s findings, methods, and innovations. Each item notes sector links, potential tools/workflows, and assumptions/dependencies.
Immediate Applications
- Unified multi-tenant model serving with per-tenant personalization
- Sectors: software/SaaS, customer support, e-commerce, finance
- Tools/products/workflows: one “Share-enabled” model; a tenant registry storing only lightweight coefficients; adapter ingestion and merging pipeline; dashboards tracking forgetting/backward transfer; API to attach/detach tenant-specific coefficients at inference
- Assumptions/dependencies: tasks share modality/domain structure; legal rights to use community LoRA adapters; SVD-based merging fits deployment latency budget; secure isolation of tenant coefficients
- On-device continual adaptation (edge/mobile)
- Sectors: robotics, IoT, AR/VR, automotive infotainment, wearables
- Tools/products/workflows: Share runtime library for embedded platforms; local coefficient fine-tuning without replay; periodic “adapter updates” via OTA; fallback to base model if subspace mismatch
- Assumptions/dependencies: sufficient compute/memory (benefits from 96–281× savings); tasks are sufficiently similar to maintain a usable shared subspace; robust quantization support
- Enterprise knowledge integration without data replay (compliance-friendly)
- Sectors: finance, legal, healthcare, government archives
- Tools/products/workflows: scheduled ingestion of department-specific LoRA adapters; analytical merging (no gradient, no historical data retention); audit logs of coefficient updates; “Share-full” optional fine-tuning for selected previous tasks within policy bounds
- Assumptions/dependencies: availability of either adapters or limited current-task data; validated performance under compliance constraints; appropriate access control and provenance tracking
- Healthcare model customization across departments and evolving guidelines
- Sectors: healthcare
- Tools/products/workflows: hospital-level shared subspace with department-specific coefficients; guideline-update adapters merged analytically; evaluation pipelines to guard against catastrophic bias shifts
- Assumptions/dependencies: regulatory validation; strong monitoring to detect out-of-subspace tasks; privacy-preserving handling of coefficients (risk of indirect leakage)
- Education: personalized tutoring and curriculum adaptation
- Sectors: education
- Tools/products/workflows: “student profiles” as lightweight coefficients; incremental ingestion of curriculum adapters; teacher dashboards tracking performance and forgetting
- Assumptions/dependencies: similarities across curricula/tasks to sustain a common foundational subspace; fairness controls to avoid reinforcing biases
- Robotics perception with replay-free continual learning
- Sectors: robotics, logistics, manufacturing, retail
- Tools/products/workflows: sequential class expansion and 3D pose estimation with occlusions; small coefficient updates per new environment; periodic analytical merges to retain old skills
- Assumptions/dependencies: perception tasks share subspace; real-time inference constraints are met; robustness under domain shifts
- Creative agencies: single diffusion model serving many styles/themes
- Sectors: media/entertainment, marketing
- Tools/products/workflows: style libraries as coefficients; “Share-enabled” diffusion backbones replacing dozens of LoRAs; non-destructive style addition; batch style merges via SVD
- Assumptions/dependencies: style adapters are licensed; acceptable qualitative parity with per-style LoRA; content safety checks remain valid after merges
- MLOps: adapter lifecycle management and compression
- Sectors: software tooling/MLOps
- Tools/products/workflows: adapter registry; Share-based analytical merging (data- and gradient-free); automated selection of k, p, φ; monitoring for forgetting/backward transfer; rollbacks if subspace drift detected
- Assumptions/dependencies: robust SVD implementations; compatibility with popular frameworks (PyTorch/Transformers/Diffusers); governance around adapter provenance
- Community adapter curation and consolidation
- Sectors: open-source ecosystems, academia
- Tools/products/workflows: “LoRA compressor” that merges hundreds of community adapters into one set of factors + per-task coefficients; reproducible model-merging recipes; benchmarks using Share as a continual baseline
- Assumptions/dependencies: adapter metadata and licensing clarity; standardized adapter formats; similarity across adapters to ensure meaningful compression
- Cloud cost reduction in large-scale inference
- Sectors: cloud platforms, enterprise IT
- Tools/products/workflows: deploy one Share model instead of many per-task LoRAs; scale to many tenants by loading only coefficients; GPU memory savings (up to ~281×) for increased concurrency
- Assumptions/dependencies: accurate subspace for mixed workloads; amortized cost of occasional merges; robust VRAM management
Long-Term Applications
- Federated, privacy-preserving continual learning
- Sectors: healthcare networks, financial consortia, public-sector data collaboratives
- Tools/products/workflows: institutions share coefficients/adapters (no raw data); federated subspace refinement; governance for adapter provenance and evaluation
- Assumptions/dependencies: secure communication; cross-site task similarity; standards for subspace interoperability
- Universal subspace marketplaces
- Sectors: AI tooling, model hubs
- Tools/products/workflows: standardized “foundational subspaces” per modality/domain; third parties publish coefficients; versioned subspace catalogs; compatibility badges
- Assumptions/dependencies: community adoption of formats/APIs; licensing/IP frameworks; validation kits to certify subspace utility
- Continual autonomy for vehicles and embodied AI
- Sectors: automotive, drones, smart factories
- Tools/products/workflows: OTA updates as coefficients/adapters for perception/NLU copilots; safety cases using replay-free updates; compliance logs and rollback
- Assumptions/dependencies: rigorous verification; resilience to out-of-subspace conditions; real-time constraints
- Lifelong, multimodal healthcare personalization
- Sectors: healthcare
- Tools/products/workflows: shared subspaces across text (EHR), imaging, signals; per-patient coefficient trajectories; clinical drift monitoring; interpretable audit trails
- Assumptions/dependencies: validated multimodal subspaces; strict privacy controls; ongoing bias/robustness assessments
- Industrial predictive maintenance under limited memory/compute
- Sectors: energy, manufacturing, utilities
- Tools/products/workflows: edge models that absorb streaming sensor patterns as coefficients; centralized analytical merges; facility-level subspaces for equipment families
- Assumptions/dependencies: modality/task similarity across machines; fault coverage; reliable edge deployment pipelines
- Regulatory-compliant risk and compliance assistants
- Sectors: finance, insurance, legal
- Tools/products/workflows: replay-free continual updates to regulatory knowledge; subspace-based auditability; coefficient-level diffs as change logs
- Assumptions/dependencies: codified standards for continual-learning compliance; external validation of updates; robust robustness testing
- Cross-domain foundation models that grow skills without growing size
- Sectors: general AI, software platforms
- Tools/products/workflows: single Share backbone spanning NLU, vision, generation; evolving subspace with modular coefficients; unified eval across tasks
- Assumptions/dependencies: scalable cross-modality subspace discovery; scheduling strategies to avoid interference; continual hyperparameter tuning (k, p, φ)
- Share-aware inference engines and hardware/software co-design
- Sectors: semiconductors, cloud, AI tooling
- Tools/products/workflows: kernels optimized for basis-coefficient multiplication; fast SVD/low-rank updates; memory layout optimizations; inference-time coefficient switching
- Assumptions/dependencies: vendor support; standardization; measurable latency wins
- Policy frameworks for continual learning
- Sectors: public policy, standards bodies, corporate governance
- Tools/products/workflows: guidelines for replay-free training, adapter licensing, provenance, safety monitoring, and energy reporting; certification processes
- Assumptions/dependencies: multi-stakeholder consensus; alignment with existing AI risk frameworks; enforceable auditing mechanisms
- Distributed asynchronous learning in swarms or field operations
- Sectors: defense, disaster response, environmental monitoring
- Tools/products/workflows: local adapters from varied conditions merged centrally into subspaces; lightweight coefficients transmitted under low bandwidth; resilience planning via rollback strategies
- Assumptions/dependencies: communications reliability; robustness to heavy distribution shifts; careful subspace governance to avoid brittle merges
Glossary
- Asynchronous continual learning: A learning paradigm that integrates new tasks or adapters as they arrive, without synchronized training phases. "supporting scalable, asynchronous continual learning."
- Backward knowledge transfer: Improvement on previously learned tasks due to learning new tasks. "we also observe instances of backward knowledge transfer due to presence of this subspace."
- Catastrophic forgetting: The degradation of performance on earlier tasks when a model is trained sequentially on new tasks. "remains challenging due to catastrophic forgetting"
- Catastrophic interference: Negative interaction between tasks causing a model to overwrite or degrade prior knowledge. "while minimizing catastrophic interference."
- CLIP score: A metric that measures alignment between text and images based on CLIP embeddings. "CLIP scores across sequential tasks (T1–T4) for continual text-to-image generation."
- Continual model merging: The process of incrementally combining multiple task-specific models/adapters into a single model over time. "Continual Model Merging and Learning at Scale"
- Data replay: Reusing stored examples from previous tasks during training to mitigate forgetting. "without relying on data replay, or multiple adapters."
- Diffusion models: Generative models that learn to produce data by reversing a diffusion (noise) process. "like LLMs, VLMs and Diffusion models"
- Empirical Risk Minimizer (ERM): A model that minimizes the empirical loss over a dataset. "be an independent empirical risk minimizer (ERM) of task τ_t"
- Explained variance: The proportion of total variance captured by selected principal components or factors. "determined by a threshold based on the explained variance of the factor data matrix D."
- Forward knowledge transfer: The improvement on future tasks due to knowledge learned from previous tasks. "facilitating forward knowledge transfer"
- Foundational subspace: A shared low-rank subspace that captures core, reusable knowledge across tasks. "Share constructs a foundational subspace that extracts core knowledge from past tasks"
- Frobenius norm: A matrix norm equal to the square root of the sum of the squares of all entries, used for measuring reconstruction error. "gives an upper bound on the Frobenius-norm error"
- Geodesic distance: The shortest path distance on a manifold; for rotations, it measures angular difference between rotation matrices. "the percentage of predictions where the geodesic distance between predicted and ground truth rotation matrices is below π/6 radians."
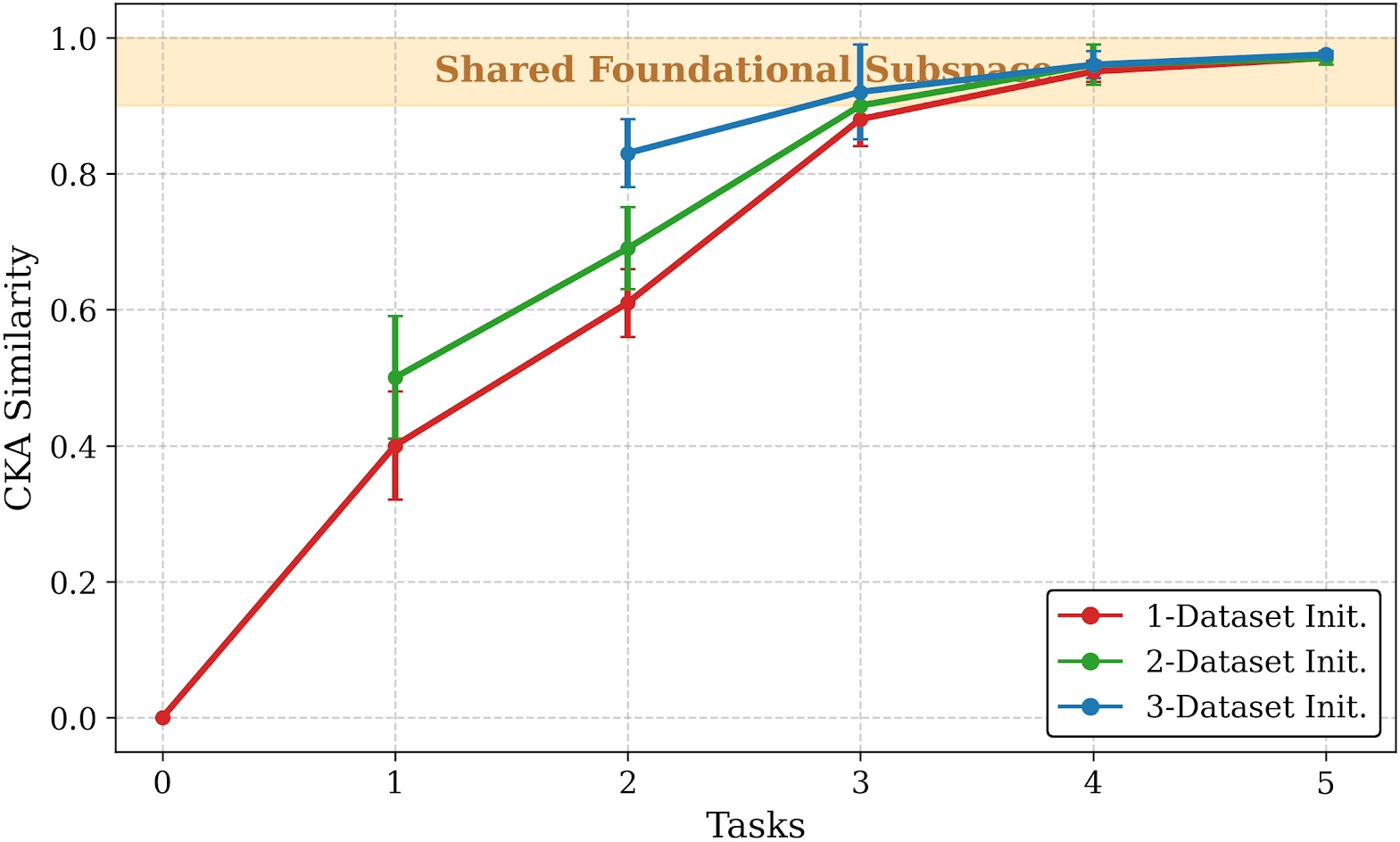
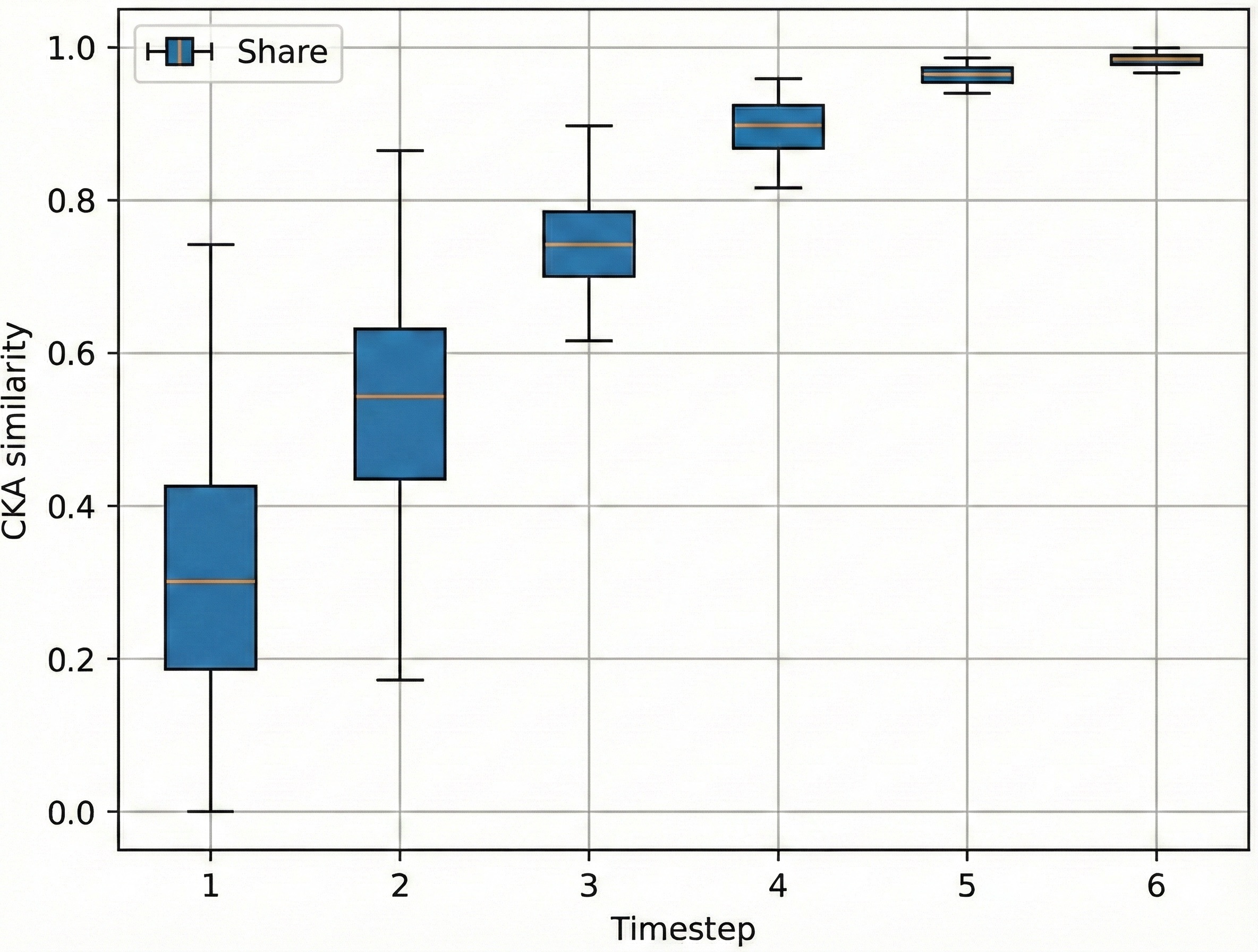
- Linear CKA (Centered Kernel Alignment): A similarity measure for comparing representations or weight spaces across models or tasks. "Linear CKA similarity analysis reveals a universal weight subspace"
- Lipschitz continuous loss: A loss function whose changes are bounded proportionally by changes in inputs, characterized by a Lipschitz constant. "Given a Lipschitz continuous loss (...) that is strong convex over the weight spaces spanned by D and VT_k"
- LoRA (Low-Rank Adaptation): A parameter-efficient method that inserts trainable low-rank matrices into layers to adapt large models. "While parameter-efficient tuning methods like low rank adaptation (LoRA) reduce computational demands"
- LoRA adapter: The task-specific low-rank parameter module used to finetune a pretrained model. "A single Share model can replace hundreds of task-specific LoRA adapters"
- LoRA rank: The rank parameter r controlling the dimensionality of the low-rank adaptation. "Hyperparameters include LoRA rank "
- Low-rank matrix: A matrix whose rank is small relative to its dimensions, enabling compact parameterization. "LoRA introduces two low-rank trainable matrices"
- Low-rank subspace: A subspace spanned by a limited number of basis vectors that capture most of the variation. "learns and dynamically updates a single, shared low-rank subspace"
- Matrix projection: The operation of projecting a matrix onto a subspace, typically to minimize reconstruction error. "Using matrix projection and Moore-Penrose pseudoinverse of β{t+1}, we analytically calculate task coefficients"
- Mixture-of-experts systems: Architectures that route inputs to specialized expert models, often increasing parameter count. "primarily operate as mixture-of-experts systems"
- Moore-Penrose pseudoinverse: A generalized inverse of a matrix used for least-squares solutions and projections. "Using matrix projection and Moore-Penrose pseudoinverse of β{t+1}, we analytically calculate task coefficients"
- Orthogonal subspaces: Subspaces whose basis vectors are mutually orthogonal, used to separate task representations. "propose learning new tasks in orthogonal subspaces to mitigate forgetting."
- Orthonormal columns: Matrix columns that are both orthogonal and unit-length, simplifying projections and decompositions. "When β{t+1} has orthonormal columns, this simplifies to εi_β = (β{t+1})T \hat{B}_i"
- Parameter overhead: The additional parameters introduced during adaptation beyond the base pretrained model. "adapts to a sequence of tasks with minimal parameter overhead."
- Parameter-efficient finetuning (PaCT): Finetuning that minimizes additional trainable parameters, here done continually. "Parameter-Efficient Continual Finetuning (PaCT)"
- Principal basis vectors: The dominant basis vectors obtained (e.g., via SVD/PCA) that capture the main directions of variation. "principal basis vectors, which remain frozen during finetuning"
- Principal coefficients: The learned coefficients that weight principal basis vectors to reconstruct adapters or weights. "where only principal coefficients are trained."
- Pseudo-rank: An effective small rank (p) used to parameterize coefficients within the shared subspace. "where (pseudo-rank) can be as small as 1."
- Right singular vectors: The V components of SVD associated with columns, defining directions in input space. "VT_k are fixed right singular vectors from \text{SVD}(\mathcal{D}t)_{[:k]}"
- Rouge-L: A text evaluation metric based on longest common subsequence overlap. "We report the absolute and relative Rouge-L scores at each time-step."
- Shared subspace: A common subspace across tasks where weights or adapters align. "neural network weights often converge to layerwise, shared subspace across tasks and datasets"
- Singular Value Decomposition (SVD): A matrix factorization into UΣVT used to extract principal bases and ranks. "perform SVD on the mean-centered matrices"
- Singular values: The diagonal entries of Σ in SVD, representing the strength of each singular direction. "where 's are the singular values of for the non-principal basis vectors."
- Strong convexity: A curvature property of a function ensuring a unique minimizer and improved optimization bounds. "that is strong convex over the weight spaces spanned by D and VT_k"
- Strict Continual Learning: A setting that forbids data replay, additional models, and parameter growth during sequential learning. "All such methods fall short of Strict Continual Learning~\cite{kaushik2021understandingcatastrophicforgettingremembering}, which requires models to learn continually, without data replay, additional models, or increase in model size, much like humans."
- Universal Weight Subspace Hypothesis: The hypothesis that neural network weights converge to shared subspaces across tasks. "Universal Weight Subspace Hypothesis~\cite{kaushik2025universalweightsubspacehypothesis} has proven that neural network weights often converge to layerwise, shared subspace across tasks and datasets"
- π/6 metric: An accuracy measure for pose estimation based on a rotation error threshold of π/6 radians. "measure accuracy using the π/6 metric—the percentage of predictions where the geodesic distance between predicted and ground truth rotation matrices is below π/6 radians."
Collections
Sign up for free to add this paper to one or more collections.