W&D:Scaling Parallel Tool Calling for Efficient Deep Research Agents
Abstract: Deep research agents have emerged as powerful tools for automating complex intellectual tasks through multi-step reasoning and web-based information seeking. While recent efforts have successfully enhanced these agents by scaling depth through increasing the number of sequential thinking and tool calls, the potential of scaling width via parallel tool calling remains largely unexplored. In this work, we propose the Wide and Deep research agent, a framework designed to investigate the behavior and performance of agents when scaling not only depth but also width via parallel tool calling. Unlike existing approaches that rely on complex multi-agent orchestration to parallelize workloads, our method leverages intrinsic parallel tool calling to facilitate effective coordination within a single reasoning step. We demonstrate that scaling width significantly improves performance on deep research benchmarks while reducing the number of turns required to obtain correct answers. Furthermore, we analyze the factors driving these improvements through case studies and explore various tool call schedulers to optimize parallel tool calling strategy. Our findings suggest that optimizing the trade-off between width and depth is a critical pathway toward high-efficiency deep research agents. Notably, without context management or other tricks, we obtain 62.2% accuracy with GPT-5-Medium on BrowseComp, surpassing the original 54.9% reported by GPT-5-High.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces a new way to make “deep research agents” (AI systems that look things up on the web, think in steps, and write answers) faster and more accurate. The idea is called “Wide and Deep,” which means:
- Deep: the agent can take many steps to think and use tools.
- Wide: the agent can call several tools at the same time in one step (parallel tool calling), instead of just one tool per step.
The authors show that widening the agent—by making multiple tool calls in parallel—helps it find correct answers more quickly and cheaply, not just by adding more thinking steps.
Key Questions
The paper asks simple but important questions:
- If the agent makes several tool calls at the same time, does it get better answers and finish faster?
- How many parallel tool calls per step is best?
- Why does parallel tool calling improve accuracy?
- Does this approach work across different AI models and different types of research problems?
- Can we plan the number of tool calls per step smartly, instead of keeping it fixed?
How They Did It (Methods)
Think of the agent like a careful student doing a research project:
- It “reasons” (plans what to do next).
- It uses “tools,” like:
- A search engine to find pages.
- A scraper that reads a webpage and summarizes the part you care about.
- A code tool (a Python interpreter) to do calculations or process data.
To test their ideas, the authors:
- Used a standard agent setup (MCP-Universe) with those tools.
- Tested on three tough research benchmarks:
- BrowseComp: challenges that require browsing the web.
- HLE (Humanity’s Last Exam): difficult text-only questions.
- GAIA: general assistant tasks (text-only subset).
- Controlled how many tools the agent must call in each step (for example, 1, 2, 3, 5, or 8 tools at once). They did this by giving clear instructions in the agent’s prompt, so the agent consistently made the requested number of tool calls.
- Measured accuracy (how often answers were correct), number of turns (steps), time, and cost.
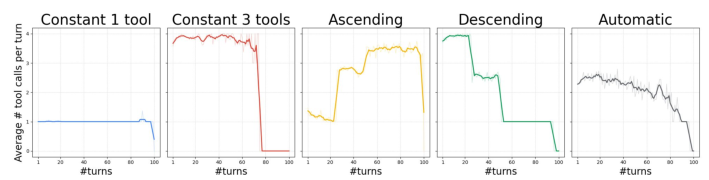
- Tried different “schedules” for tool calls per step, like always 3 tools, starting with 3 then reducing to 1, starting with 1 then increasing to 3, and letting the AI decide on its own.
- Read through agent logs to see why parallel calls helped.
What They Found (Results)
Parallel tool calling made a big difference:
- Better accuracy with fewer steps:
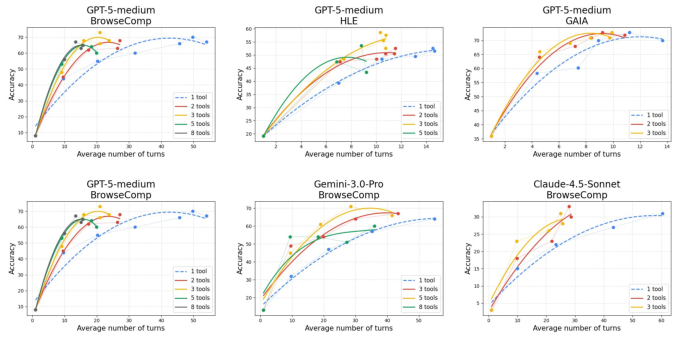
- On BrowseComp, using 3 parallel tool calls per step improved accuracy and reduced the number of turns needed.
- Example: To reach about 66–68% accuracy across 100 tasks, single-tool calling cost $102.5 and took 1,522.6 seconds. With 3 parallel tools per step, the agent reached 68% accuracy for$65.7 and 904.2 seconds. That’s roughly a 36% cost reduction and a 41% time reduction.
- Works across different models and benchmarks:
- The gains showed up with multiple advanced AI models (like GPT-5-Medium, Gemini, and Claude) on different datasets.
- On the full BrowseComp set, GPT-5-Medium reached 62.2% accuracy—higher than the reported 54.9% from GPT-5-High—without fancy “context management” tricks.
- Open-source models saw smaller gains, which suggests they could be trained better to use parallel tool calls.
- Smarter scheduling helps:
- A “Descending” schedule (many tool calls at the beginning, fewer later) performed best, reaching 74% accuracy on BrowseComp, beating “always 3 tools” (68%).
- An “Ascending” schedule (starting low, increasing later) did worst.
- Letting the AI decide the number of calls (“Automatic”) did not beat the Descending schedule.
Why Parallel Tool Calling Improves Accuracy
These patterns explain the accuracy boost:
- Wider exploration leads to better sources: Calling multiple searches at once surfaces more viewpoints and lets the agent pick more trustworthy sources (like official UN reports) instead of risky, unofficial ones.
- Redundancy helps catch errors: If one tool fails or returns a made-up answer, different parallel calls can disagree, signaling the agent to re-check or search again.
- Breaking complex queries into simpler pieces: Instead of one overloaded search, the agent issues several simple, focused queries in parallel, which makes search engines return more relevant results.
Why It Matters (Implications)
This work shows that the “width” of agent actions—how many tools it uses at once—matters as much as the “depth” (how many steps it takes). The practical impact is clear:
- Faster, cheaper, and more accurate research agents: Useful for students, journalists, analysts, and scientists who need to gather and verify information quickly.
- Better strategy design: Start broad (many parallel tool calls to explore), then narrow down (fewer calls to focus), which matches how good human researchers work.
- Future training: Teach AI models to choose the right number of tool calls automatically, balancing speed, cost, and accuracy. This could unlock even stronger “deep research” abilities without complicated multi-agent systems.
In short, doing more at once—when done thoughtfully—helps research agents find the right answers faster and more reliably.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following are the key unresolved issues that future research could address to strengthen, generalize, and make more reliable the proposed parallel tool calling approach for deep research agents:
Experimental scope and evaluation rigor
- Limited evaluation scope: most BrowseComp and HLE results are on the first 100 samples; GAIA and HLE are restricted to text-only subsets. Assess generalization on full datasets and multimodal settings, and report per-task-type breakdowns.
- Lack of statistical significance: no confidence intervals, variance across runs, or significance tests; search results are non-deterministic. Run multiple seeds/reruns with randomized search ordering and report variability.
- Metrics beyond accuracy: no systematic evaluation of citation quality, source credibility, justification quality, or error taxonomy. Add metrics for evidence quality, consistency, and calibration of confidence.
- Incomplete cost and latency accounting: cost/latency reductions are reported on small subsets without comprehensive token- and wall-clock accounting across all components (LLM, search, scraping/summarization, retries). Provide a detailed cost model including tool latencies, failure retries, and rate-limit backoffs.
Parallel tool calling mechanics and aggregation
- Aggregation strategy is implicit: parallel outputs are simply fed back to the LLM; no explicit deduplication, confidence scoring, contradiction detection, or citation ranking. Develop and evaluate structured aggregation modules (e.g., source voting, cross-checking, credibility weights).
- When width hurts performance: accuracy declines at high width for large max-turn limits, but no systematic characterization of failure modes (e.g., distraction, context dilution, duplicate queries). Quantify conditions where extra parallel calls reduce quality and why.
- Quality of tool arguments at higher width: no analysis of whether argument quality degrades as m increases (e.g., redundant or poorly decomposed queries). Measure per-call uniqueness, overlap, and downstream utility as a function of m.
- Interaction with context size: parallel calls produce many observations per turn; the paper claims no context management but does not analyze truncation effects or token budgets. Evaluate context overflow, truncation policies, and their impact on correctness.
Scheduler design and learning
- Heuristic scheduler only: Descending outperforms others, but the “Automatic” scheduler is a simple prompt rule. Explore learned schedulers (bandits, RL, dynamic programming) that optimize width-depth trade-offs conditioned on task state and budget.
- Generalization of scheduler gains: scheduler comparison is shown on BrowseComp only. Test whether Descending (or learned policies) generalize to HLE/GAIA and to different toolsets and models.
- Progress estimation is uncalibrated: the Automatic strategy relies on self-reported progress without calibration. Investigate progress predictors trained on outcome data and study their calibration and effect on scheduling decisions.
- Budget-aware control: scheduling does not explicitly incorporate API budgets, rate limits, or expected tool latency distributions. Design schedulers that optimize under explicit cost/latency constraints.
Tools, pipelines, and environment dependencies
- Single summarization model in scraping: reliance on Gemini-2.5-Flash for extraction introduces an unmeasured hallucination risk; no ablation of different summarizers, deterministic settings, or non-LLM extractors. Evaluate alternative extractors and quantify hallucination rates.
- Tool diversity and composition: experiments focus on search/scrape (and code for HLE) without exploring richer toolsets (structured APIs, knowledge bases) or parallel mixes (e.g., search+scrape in the same step). Study cross-tool composition patterns and their effects.
- Search engine dependency: only Google (via Serper) is used. Test Bing, OpenSearch backends, and domain-specific engines to assess robustness to engine choice and ranking.
- Vendor-specific parallel-call semantics: parallel function-calling behaviors differ across providers. Document and compare vendor semantics, adherence, and failure modes to ensure reproducibility across platforms.
Robustness, reliability, and reproducibility
- Adherence to call counts: the paper states calls are “very close” to specified m but provides no adherence rates or penalties for deviations. Quantify adherence, over/under-calling frequency, and its impact on outcomes.
- Tool failure handling: case studies show resilience to scraping failures, but there is no quantitative evaluation of failure/retry policies (HTTP errors, captchas, rate limits). Measure failure rates, retry strategies, and robustness under adverse conditions.
- Web drift and time sensitivity: no controls for changing web content over time. Include time-stamped caches or snapshot-based evaluation to separate algorithmic improvements from content variability.
- Reproducibility of pipelines: many moving parts (LLM, search, scraping LLM, interpreter). Release detailed configs, versions, prompts, temperature settings, and seeds; quantify run-to-run variance.
Model dependence and training questions
- Proprietary vs. open-source gap: open-source models show small gains with parallel calls, but the causes (training data, function-calling competence, planning) are not analyzed. Diagnose failure modes and identify training data/methods to improve parallel tool planning in open models.
- No training to aggregate or schedule: the approach is purely prompted; no finetuning to improve query decomposition, aggregation, or scheduling. Study supervised/RL training signals (e.g., source reliability, redundancy penalties) to learn these skills.
- Combining with parallel reasoning or multi-agent orchestration: the method is compared qualitatively but not combined with these alternatives. Explore hybrid systems that jointly parallelize tool calls and reasoning paths with principled aggregation.
Domain coverage and generalization
- Beyond web information seeking: the method is not tested on domains like code synthesis with API calls, scientific literature querying, or structured retrieval tasks. Evaluate in non-web, API-centric, and domain-specific tool ecosystems.
- Multimodal tasks are excluded: text-only subsets are used for HLE/GAIA; parallel tool calling for vision+text (e.g., document parsing, charts) remains an open area.
Efficiency and systems considerations
- Parallelism limits and system constraints: experiments explore width up to 8 but do not quantify backend limits (rate limits, concurrent connections) or diminishing returns vs. infrastructure constraints. Characterize throughput/latency ceilings and adaptive throttling.
- Token accounting per step: claims about amortized reasoning cost lack per-turn token breakdowns as m varies. Provide token-per-turn and total-token analyses, including tool-result ingestion costs.
- Throughput vs. latency trade-offs: end-to-end latency is reported, but not the impact on throughput under shared budgets or batch settings. Evaluate in multi-task queues with rate-limited APIs.
Safety, compliance, and ethics
- Compliance with site policies: parallel scraping may violate robots.txt or ToS; there is no discussion of compliance mechanisms or throttling policies. Define and evaluate policy-aware crawling strategies.
- Misinformation and bias: more sources do not guarantee better truthfulness. Develop automated source credibility checks, bias detection, and adversarial robustness tests for malicious or SEO-gamed pages.
- Code interpreter risks: for HLE, the interpreter is available but security/sandboxing and misuse potentials are not discussed. Specify sandboxing, resource limits, and audit logs.
These gaps suggest concrete directions: broaden and deepen evaluation with robust metrics and statistics; build explicit aggregation and verification modules; learn dynamic scheduling policies; diversify and ablate tool pipelines; stress-test robustness and reproducibility; and extend to new domains and modalities under realistic system and ethical constraints.
Practical Applications
Immediate Applications
Below are practical use cases that can be deployed now using the paper’s findings on parallel tool calling, width-depth trade-offs, and tool-call schedulers. Each item includes sector alignment, potential tools/products/workflows, and feasibility notes.
- Enterprise market and competitive intelligence assistant
- Sector: Finance, Enterprise, Software
- What it does: Automates market scans and competitor profiling by issuing parallel searches and scrapes across company sites, filings, news, and analyst reports, then verifies and consolidates findings.
- Tools/workflows: Search + scraping (e.g., Serper + Jina), Gemini-Flash summarization, “Descending” scheduler (explore-then-exploit), provenance logging; integrates with MCP-Universe or vendor APIs (OpenAI/Gemini/Claude).
- Assumptions/dependencies: Parallel function calling support; API rate limits and quotas; access to paywalled sources via licenses; governance for source credibility; internal review for high-stakes outputs.
- Legal/compliance research copilot
- Sector: Legal, Policy, Risk
- What it does: Parallel queries across statutes, case law, regulatory guidance; cross-verifies tool outputs to reduce reliance on single (possibly faulty) retrievals.
- Tools/workflows: Query decomposition into narrower facets; redundant extractions for verification; “Descending” scheduler to front-load exploration; report templating.
- Assumptions/dependencies: Licensed access (e.g., Westlaw/Lexis); strict human-in-the-loop; citation and provenance requirements; jurisdictional coverage; vendor parallel-call support.
- Scientific and clinical literature review assistant
- Sector: Healthcare, Academia
- What it does: Conducts systematic evidence scans (PubMed, guidelines, preprints, registries) with parallel queries and redundancy checks to avoid hallucinated summaries.
- Tools/workflows: Search + scraping + code interpreter (basic meta-analysis scripting), query decomposition over PICO facets; source credibility filters; staged exploration then narrowing.
- Assumptions/dependencies: Access to biomedical databases; qualified expert validation; caution for clinical decision-making; data-use agreements and ethics compliance.
- Customer support knowledge retrieval accelerator
- Sector: Software, Customer Experience
- What it does: Parallel searches across internal docs, tickets, FAQs, and forums; uses redundancy to detect unreliable tool outputs; returns consolidated answers faster.
- Tools/workflows: Internal search connectors; scraping of docs; “Descending” scheduler to reduce time-to-first-correct answer; answer provenance in support portals.
- Assumptions/dependencies: Access to internal repositories; concurrency controls; PII handling; content freshness mechanisms.
- Investigative journalism research tool
- Sector: Media
- What it does: Parallel source gathering (news archives, official reports, databases); query decomposition for complex constraints; cross-source verification for credibility.
- Tools/workflows: Explore-then-exploit scheduling; source scoring; automatic citation collection; MCP-compatible single-agent integration.
- Assumptions/dependencies: Respect robots.txt and site terms; editorial standards; fact-check workflows; mixed paywalled/public sources.
- Government procurement due diligence and policy analysis
- Sector: Public Sector
- What it does: Parallel OSINT on vendors, contracts, performance reports; verification via redundant tool calls to avoid acting on faulty extractions.
- Tools/workflows: Search + scraping; structured report generation; “Descending” scheduler; audit trail for each source and tool call.
- Assumptions/dependencies: Legal compliance (FOIA, open-data licenses); human oversight; access to public procurement portals; vendor API quotas.
- E-commerce product comparison and buying assistant
- Sector: Consumer, Retail
- What it does: Parallel scraping of specification pages and reviews; query decomposition for price, warranty, and feature constraints; verification for inconsistent tool results.
- Tools/workflows: Search + scraping; Gemini-Flash summarization; exploration-heavy early turns; final aggregation with transparent source links.
- Assumptions/dependencies: Anti-scraping policies; dynamic site rendering; possible need for retailer APIs; privacy and consent for review data.
- Travel planning and itinerary optimization
- Sector: Consumer, Travel
- What it does: Parallel searches for flights, hotels, attractions; decomposes queries (dates, neighborhoods, budgets) to improve recall and quality; verifies conflicting outputs.
- Tools/workflows: Travel APIs + scraping; “Descending” scheduler; budget-aware prompts with countdown messages to control steps and costs.
- Assumptions/dependencies: API access and rate limits; variability in pricing data; need for live availability; compliance with terms of service.
- Software engineering research and knowledge mining
- Sector: Software, DevOps
- What it does: Parallel querying across code search, issues, PRs, design docs to identify patterns or prior art; verifies tool outputs before proposing solutions.
- Tools/workflows: Connectors to code hosting and ticketing systems; query decomposition by component/module; provenance tags; “Descending” scheduler for efficient triage.
- Assumptions/dependencies: Repository access permissions; confidentiality; integration maintenance; token budget awareness.
- Data operations and web ingestion pipelines
- Sector: Data Engineering
- What it does: Parallel web scrapes and extractions for ETL; redundancy to detect extraction failures/hallucinations; improved throughput and lowered latency/costs.
- Tools/workflows: Parallel tool-call orchestrator; verification layer; schema mapping; explore early, exploit later schedule.
- Assumptions/dependencies: Concurrency controls; deduplication; licensing-compliant ingestion; observability and retry logic.
- Agent cost and latency optimization in AI tooling
- Sector: AI Platforms, MLOps
- What it does: Reduces turns and token usage with parallel tool calling; integrates “Descending” scheduler to cut wall-clock time and API costs (e.g., ~40% time and ~36% cost reductions observed in BrowseComp scenarios).
- Tools/workflows: Tool Call Scheduler SDK; countdown prompts; per-turn budget visibility; parallel-call caps per step.
- Assumptions/dependencies: Vendor support for parallel calls; robust monitoring (tokens, latency, error rates); safe fallbacks when tools fail.
- Education research assistant for students and librarians
- Sector: Education
- What it does: Parallel queries across academic search engines and repositories; uses redundancy to avoid faulty extractions; compiles annotated bibliographies.
- Tools/workflows: Search + scraping; citation manager integration; explore-first scheduling; plagiarism detection integration.
- Assumptions/dependencies: Access to academic indexes; institutional licenses; academic integrity policies; human supervision for grading or instruction.
Long-Term Applications
These use cases require additional research, scaling, or development (e.g., multimodality, RL training, standardization, or regulatory approvals) before broad deployment.
- Autonomic width–depth scheduler via learning
- Sector: AI Tooling, Research
- What it could do: Train LLM agents (e.g., with RL) to dynamically decide the number of tool calls per turn (explore-then-exploit) instead of relying on fixed heuristics, optimizing cost/latency/accuracy jointly.
- Tools/products: “Scheduler RL” module; reward shaping for credibility and efficiency; benchmarking harnesses (BrowseComp/HLE/GAIA).
- Assumptions/dependencies: Suitable training data and signals; model updates to support adaptive control; safety constraints to prevent abuse of parallel calls.
- Multimodal parallel tool calling for complex documents
- Sector: Healthcare, Legal, Media
- What it could do: Parallel parsing of PDFs, tables, images, audio, and video; cross-modal verification; improved evidence synthesis and compliance checks.
- Tools/products: Multimodal LLM integration; document parsers; table extraction; citation tracking; provenance across modalities.
- Assumptions/dependencies: Robust multimodal models; domain adapters; consent and licensing; evaluation datasets covering multimodality.
- Parallel tool calling protocol standardization
- Sector: Software, AI Infrastructure
- What it could do: Define a vendor-agnostic spec (building on MCP) for parallel tool calls, scheduling, provenance, and verification, enabling consistent interoperability across agent frameworks.
- Tools/products: “Parallel Tool Calling Protocol” (PTCP); open-source SDKs; conformance tests.
- Assumptions/dependencies: Broad vendor adoption; governance and versioning; security and audit requirements.
- Source credibility scoring and provenance ledger
- Sector: Media, Policy, Academia
- What it could do: Systematically score sources using redundancy, cross-consistency, and reputation; maintain a provenance ledger for auditability and reproducibility.
- Tools/products: Credibility scoring engine; provenance store; UI for auditors/editors; integration with report generation.
- Assumptions/dependencies: Trust frameworks; community-agreed scoring criteria; mitigation for bias; data retention policies.
- Automated systematic review and meta-analysis pipelines
- Sector: Academia, Healthcare
- What it could do: End-to-end systematic reviews with parallel search, verification, data extraction, and code-based meta-analysis; reproducibility at scale.
- Tools/products: ReviewOps platform; extraction validators; statistical modules; registered protocols and audit trails.
- Assumptions/dependencies: Human oversight; registry integration (e.g., PROSPERO); ethical approvals; domain-specific guidelines.
- Scalable OSINT automation with cross-lingual support
- Sector: Security, Government
- What it could do: Parallel multilingual queries across public datasets and platforms; verification to reduce false positives; risk scoring.
- Tools/products: Cross-lingual search/scrape; translation and normalization; provenance-aware dashboards.
- Assumptions/dependencies: Legal/ethical constraints; multilingual model quality; platform terms of service; robust deconfliction processes.
- Enterprise knowledge orchestration platform
- Sector: Enterprise IT
- What it could do: Orchestrate internal/external sources with parallel tool calls, verification layers, and adaptive scheduling; unify research workflows across teams.
- Tools/products: ResearchOps hub; policy-based governance; budget-aware scheduling; observability for tool-call health.
- Assumptions/dependencies: Data security and access control; change management; integration with existing KM systems.
- Curriculum and syllabus design assistants
- Sector: Education
- What it could do: Parallel retrieval of pedagogical resources, standards, and assessments; source verification; alignment with learning objectives.
- Tools/products: Education content pipelines; alignment engines; citation and licensing management.
- Assumptions/dependencies: Pedagogical oversight; licensing for educational materials; bias mitigation.
- Training open-source LLMs for effective parallel tool use
- Sector: AI Research, Open Source
- What it could do: Improve open models’ ability to orchestrate parallel calls (currently limited gains vs. proprietary models), including tool consistency, verification, and scheduling.
- Tools/products: Datasets and curricula emphasizing parallel tool calling; evaluation suites; fine-tuning recipes.
- Assumptions/dependencies: Compute budgets; community collaboration; synthetic data generation for complex research tasks.
- Energy and climate market monitoring
- Sector: Energy, Finance
- What it could do: Parallel retrieval of operator data, emissions reports, policy updates; verification across sources; early warning analytics.
- Tools/products: Sector connectors; unit normalization; query decomposition by instrument/region/time; provenance dashboards.
- Assumptions/dependencies: Access to market/operator APIs; complex domain schemas; regulatory compliance.
- Clinical decision support with verified evidence (cautious deployment)
- Sector: Healthcare
- What it could do: Long-term, tightly governed CDS leveraging parallel evidence synthesis with strict verification and provenance for safety-critical contexts.
- Tools/products: Verified evidence layers; clinician UI with confidence and source scores; regulatory-grade audit trails.
- Assumptions/dependencies: Regulatory approvals; rigorous validation; integration with EHR systems; clinical governance and liability frameworks.
Glossary
- Action A_t: The single tool call issued by the agent at step t in a sequential trace. "a typical LLM outputs a reasoning thought R_t and a single tool call A_t."
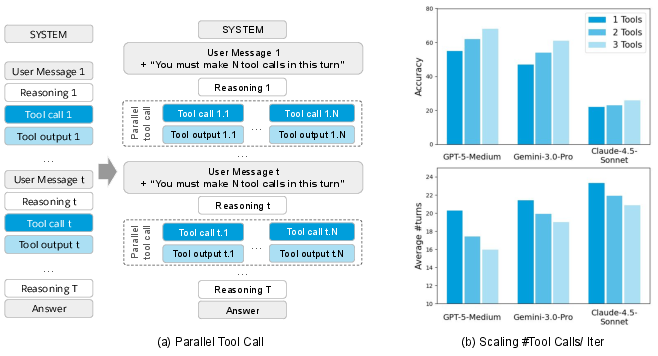
- Agent trace: The ordered record of the agent’s reasoning steps, tool calls, and observations across an interaction. "\Cref{fig:main_figure} shows the difference in agent trace between the single tool calling and parallel tool calling."
- Amortization (of reasoning cost): Reducing average computational cost by sharing or consolidating reasoning across multiple actions. "it amortizes the computational cost of reasoning; we condense distinct reasoning traces into a single , significantly reducing the number of decoding tokens and LLM generation latency."
- BrowseComp: A benchmark for evaluating browsing and information-seeking agents. "We conduct our experiments across three widely adopted deep-research benchmarks: 1) BrowseComp \citep{wei2025browsecomp}, 2) Humanity's Last Exam (HLE) \citep{phan2025humanity}, and 3) GAIA \citep{mialon2023gaia}."
- Chain-of-thought reasoning: A technique where models generate explicit intermediate reasoning steps before answering. "The work of~\citep{pan2025learning} proposes to replace serialized chain-of-thought reasoning with coordinated parallel reasoning to improve latency; however, it does not target the agent setting where tool calls are incurred."
- Context management: Strategies to control, prune, or organize long interaction histories and information within the model’s context window. "Consequently, recent works have focused on scaling context length or implementing smarter context management strategies to handle deeper reasoning and more tool calls."
- End-to-end latency: The total time from initiating an agent’s process to producing the final output, including thinking and tool execution. "In summary, parallel tool calling optimizes both the end-to-end latency of the agent rollout and the cost of LLM API usage by reducing both the iteration count and total token consumption."
- Explore-then-exploit: A strategy that starts with broad exploration and later focuses on the most promising directions. "Ascending achieves the worst performance while Descending achieves the best, suggesting that the explore-then-exploit strategy contributes to better performance."
- Function calling: The mechanism by which an LLM invokes external tools via structured function interfaces. "You have access to various specialized tools through function calling"
- GAIA: A benchmark for general AI assistants covering diverse tasks. "We conduct our experiments across three widely adopted deep-research benchmarks: 1) BrowseComp \citep{wei2025browsecomp}, 2) Humanity's Last Exam (HLE) \citep{phan2025humanity}, and 3) GAIA \citep{mialon2023gaia}."
- Hallucination: Fabrication of content by a model or tool despite insufficient or incorrect input. "The tool’s internal summarization model, however, hallucinated an answer based on this empty input."
- Humanity's Last Exam (HLE): A challenging benchmark of text-only tasks for evaluating research agents. "Because the evaluated models are not multimodal, we restrict our testing to the text-only subsets of HLE (2,158 samples) and GAIA (103 samples)."
- JINA API: A web scraping service used to fetch and process webpage content. "We use JINA API for scraping"
- LLM: A transformer-based model trained on large corpora to perform language tasks, often with tool-use capabilities. "State-of-the-art LLMs increasingly support the capability of parallel tool calling"
- MCP-Universe: An agent framework based on the Model Context Protocol, used for benchmarking tool-enabled LLMs. "We adopt the agent framework from MCP-Universe~\citep{mcpuniverse} for evaluation."
- Multimodal: Capable of processing multiple input types (e.g., text, images) rather than text-only. "Because the evaluated models are not multimodal, we restrict our testing to the text-only subsets of HLE (2,158 samples) and GAIA (103 samples)."
- Observation O_t: The environment’s feedback returned to the agent after a tool call at step t. "The environment executes this call and returns an observation O_t."
- Orchestration: Coordination logic for managing multiple agents or components to work together. "Unlike existing approaches that rely on complex multi-agent orchestration to parallelize workloads"
- Parallel reasoning: Generating multiple reasoning paths concurrently and aggregating their outcomes. "Longcat~\citep{longcat2026flashthinking} introduced parallel reasoning to generate multiple reasoning paths within the same turn, aggregating the outcomes via summarization."
- Parallel tool calling: Issuing multiple tool calls simultaneously within a single reasoning step. "Parallel tool calling extends this paradigm by allowing the agent to generate multiple tool calls simultaneously."
- Parallel-agent reinforcement learning (PARL): A training approach where agents learn to decompose tasks into parallelizable sub-tasks via reinforcement learning. "Kimi-K2.5~\citep{moonshot2026kimik25} proposes an agent swarm framework and trains the model with the newly proposed parallel-agent reinforcement learning (PARL)."
- Query decomposition: Splitting a complex search request into simpler sub-queries to improve retrieval effectiveness. "Observation 3. Parallel search enhances retrieval effectiveness through query decomposition."
- Reasoning thought R_t: The model’s internal reasoning content at step t prior to tool calls or answers. "a typical LLM outputs a reasoning thought R_t and a single tool call A_t."
- Serper API: A Google-based search API used by the agent for web queries. "We use Serper API for search"
- Sub-agent: A specialized helper agent invoked by a main agent to perform sub-tasks or tool use. "In each iteration, the main agent reasons based on the current context without direct tool calling; instead, a sub-agent is invoked to use tools and solve sub-tasks."
- Summarization LLM: A LLM used to condense scraped content and extract targeted information. "it scrapes the full content of the webpage and passes it, along with the query, to a summarization LLM to extract the specific information required."
- Thinking mode: Model configuration controlling explicit reasoning behaviors; here disabled for a faster summary model. "We use Gemini-2.5-Flash (with thinking mode disabled) for the summary model due to its balance of affordability and effectiveness."
- Token consumption: The number of tokens processed or generated by the LLM, affecting cost and latency. "In summary, parallel tool calling optimizes both the end-to-end latency of the agent rollout and the cost of LLM API usage by reducing both the iteration count and total token consumption."
- Tool call scheduler: A policy that decides how many tool calls to issue per step to balance exploration and efficiency. "we present a preliminary exploration of different tool call schedulers for parallel tool calling."
- Wall-clock time: Real elapsed time experienced during execution, including waiting for external tools. "because tool calls within the set are executed concurrently, the wall-clock time spent waiting for environment feedback is minimized."
- Width-depth trade-off: Balancing parallel breadth (width) and sequential steps (depth) to optimize efficiency and accuracy. "Our findings suggest that optimizing the trade-off between width and depth is a critical pathway toward high-efficiency deep research agents."
Collections
Sign up for free to add this paper to one or more collections.