Rolling Sink: Bridging Limited-Horizon Training and Open-Ended Testing in Autoregressive Video Diffusion
Abstract: Recently, autoregressive (AR) video diffusion models has achieved remarkable performance. However, due to their limited training durations, a train-test gap emerges when testing at longer horizons, leading to rapid visual degradations. Following Self Forcing, which studies the train-test gap within the training duration, this work studies the train-test gap beyond the training duration, i.e., the gap between the limited horizons during training and open-ended horizons during testing. Since open-ended testing can extend beyond any finite training window, and long-video training is computationally expensive, we pursue a training-free solution to bridge this gap. To explore a training-free solution, we conduct a systematic analysis of AR cache maintenance. These insights lead to Rolling Sink. Built on Self Forcing (trained on only 5s clips), Rolling Sink effectively scales the AR video synthesis to ultra-long durations (e.g., 5-30 minutes at 16 FPS) at test time, with consistent subjects, stable colors, coherent structures, and smooth motions. As demonstrated by extensive experiments, Rolling Sink achieves superior long-horizon visual fidelity and temporal consistency compared to SOTA baselines. Project page: https://rolling-sink.github.io/




Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about making AI models better at creating long, smooth videos. Many video AIs are trained on short clips (like 5 seconds), but people want them to keep going for minutes. When these models try to go much longer than they were trained for, the video quality often falls apart: colors get weird, people or objects change shape, and the motion becomes jerky or repetitive. The authors introduce a simple, training‑free method called Rollin (also referred to as Rolling Sink) that helps these models keep their videos stable and consistent for many minutes.
Key Objectives
The paper asks a straightforward question: How can we help a video model that was trained on short clips keep generating good‑looking video for a long time without retraining it?
More specifically:
- Why do long videos drift in quality after a while?
- Can we fix this by managing the model’s “memory” during generation?
- Can we do it without extra training, so it’s fast and practical?
Methods and Approach (in simple terms)
Think of an autoregressive video diffusion model as an artist drawing a video one small chunk at a time. For each new chunk, it looks back at what it drew before. That look‑back is its “memory,” often called a cache. The cache can only hold a limited number of recent chunks (like carrying a small backpack of reference photos).
The core problem:
- During training, the model only ever practices making about 5 seconds of video.
- At test time, we ask it to make minutes. That mismatch is called a train‑test gap (also known as exposure bias). It’s like training for a 2 km run and then being asked to run a marathon—the longer you go, the more likely you drift off pace.
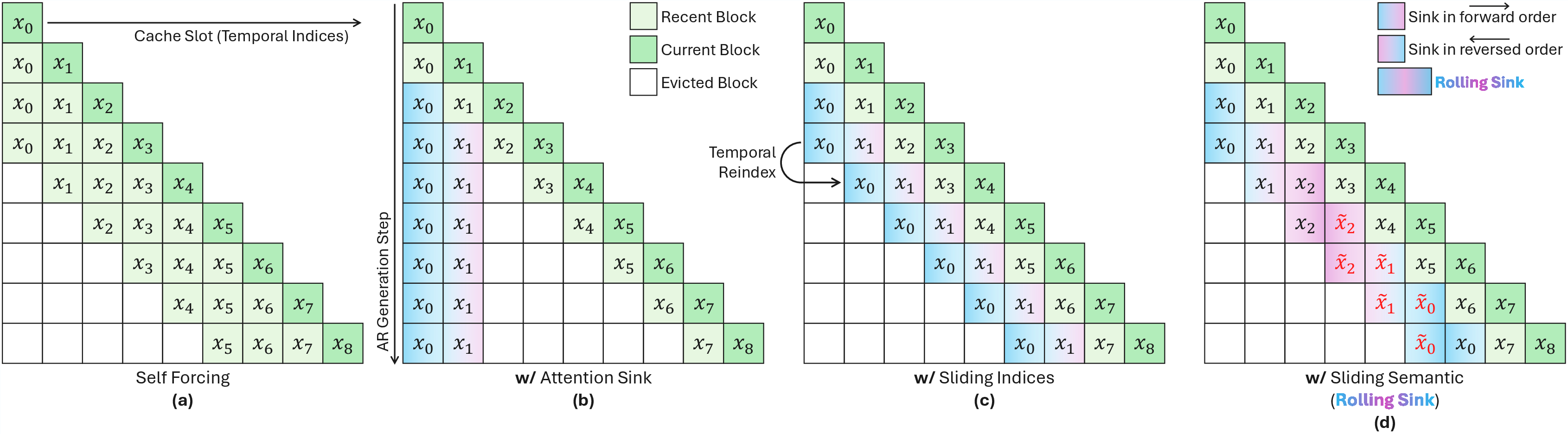
The authors study how to keep that small “memory backpack” in good shape so the model doesn’t drift. They build on a strong baseline called Self Forcing (trained on 5‑second clips) and propose three simple, practical ideas:
- Attention Sink (anchor blocks): Pin a few of the earliest, cleanly generated chunks in the cache as permanent anchors. These stable references help keep colors and overall look from drifting. Think of them as a couple of reliable reference photos always in your backpack.
- Sliding Indices (move the timestamps): The model internally marks chunks with time positions. Instead of leaving those anchors locked to the start, slide their time positions forward as the video rolls. This better matches the idea that the whole video is moving through time and reduces flickering.
- Sliding Semantics (roll the content slice): Not just the timestamps—the content of the anchors should also “move” so the model always sees a fresh, consistent slice of earlier, stable material. The authors approximate this by rolling through the set of clean short‑clip chunks in a forward–backward pattern, feeding the model a moving window of trustworthy history.
Together, these steps form Rollin. Importantly:
- It requires no extra training.
- It keeps the cache size small and fixed (streaming‑friendly).
- It uses the same fast sampling steps as the base model.
Main Findings and Why They’re Important
What changed with Rollin:
- Much longer, stable videos: Even though the model was trained on just 5 seconds, Rollin keeps videos consistent for 5–30 minutes at 16 frames per second.
- Fewer visual problems: It reduces color oversaturation, warped faces or objects, flicker, and repetitive motion.
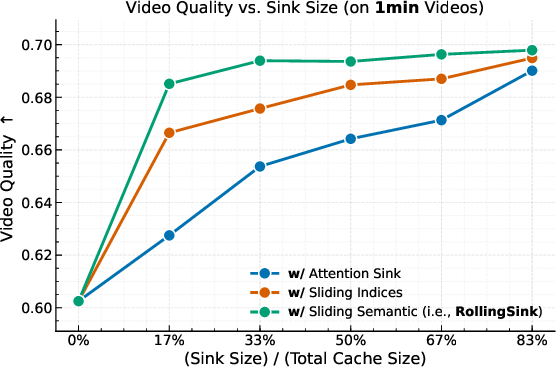
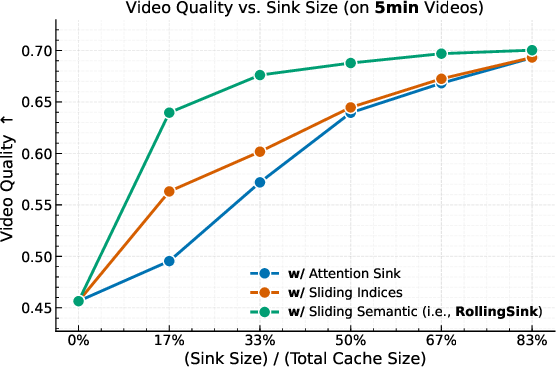
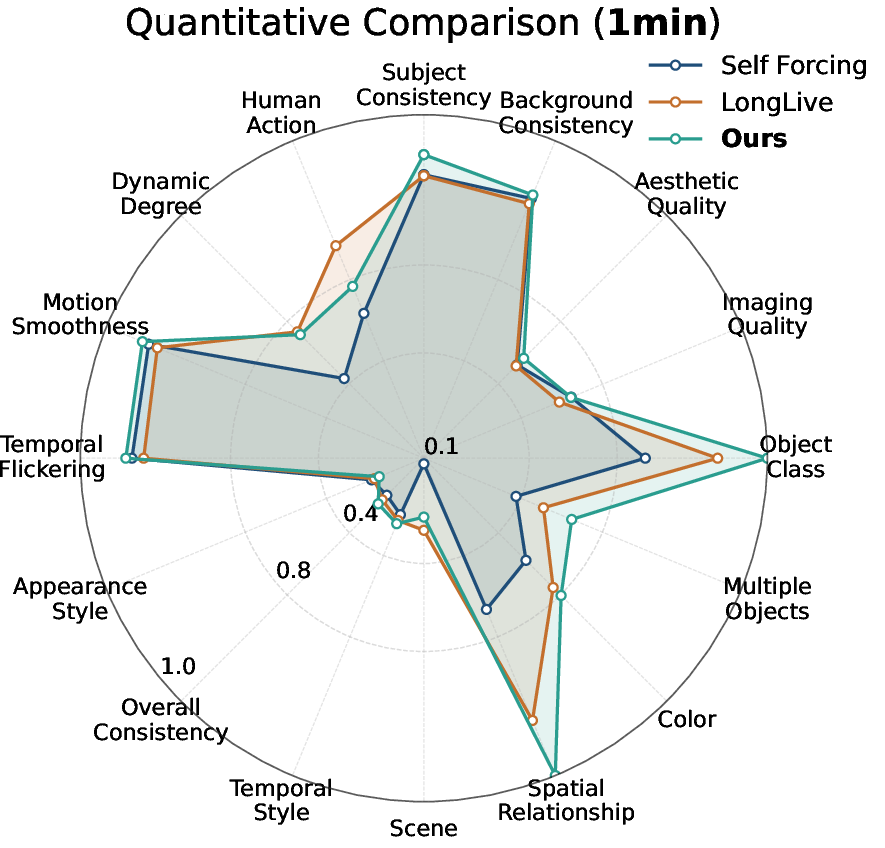
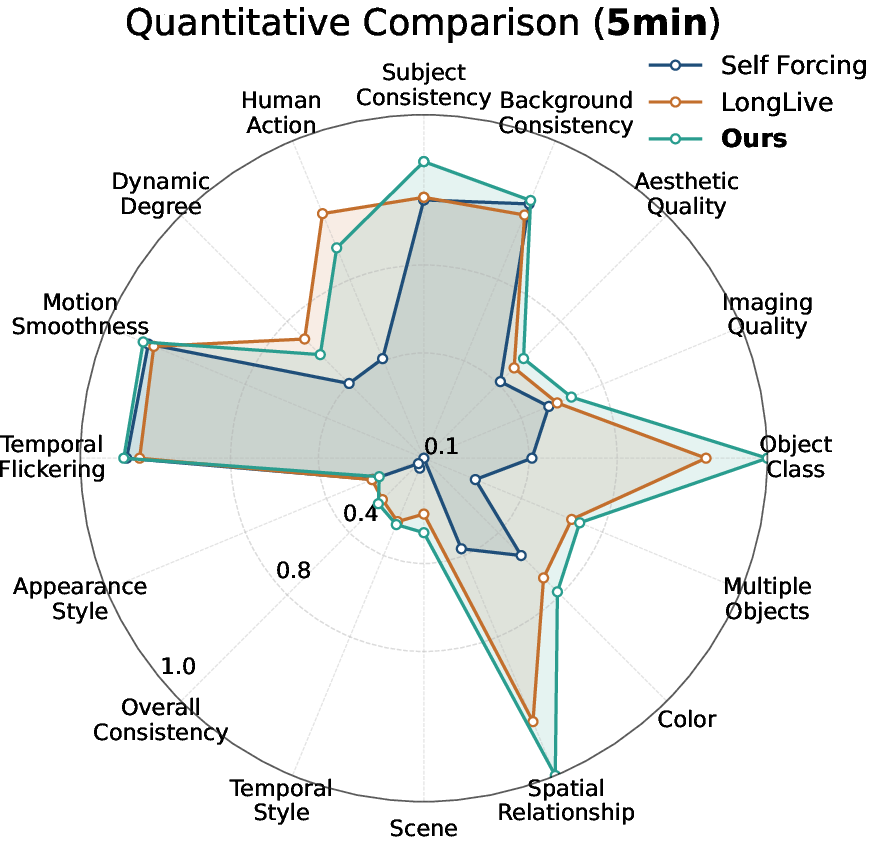
- Better scores: On a long‑video benchmark called VBench‑Long, Rollin scores higher than strong baselines across many categories (like subject consistency, motion smoothness, and overall visual quality) for both 1‑minute and 5‑minute tests. It achieves the best average rank across most dimensions.
Why it matters:
- It shows you can push short‑trained models to perform well far beyond their training horizon.
- It’s training‑free and efficient, making it practical to deploy.
- It highlights that smart memory management during generation can fix long‑video drift.
Implications and Potential Impact
Rollin is a simple, effective way to stabilize long video generation without retraining. This can help creators, studios, and apps that want continuous, real‑time video generation—like long scenes, livestream storytelling, or extended camera moves.
Limitations and future directions:
- The paper focuses on single‑prompt, single‑shot videos (one scene that keeps going). Real movies use multiple shots and prompts that change over time. A next step is to adapt these ideas to multi‑shot generation, ensuring smooth transitions while keeping consistency over very long timelines.
In short, the paper’s big idea is: if you keep the model’s small memory backpack well organized—using stable anchors and sliding them through time and content—you can turn short‑trained video models into long‑distance runners without extra training.
Knowledge Gaps
Below is a single, focused list of the paper’s unresolved knowledge gaps, limitations, and open questions. Each point is stated concretely to guide future research.
- The method is evaluated and implemented only on Self Forcing; generalization to other AR video diffusion architectures (e.g., DF/TF training regimes, different DiT variants, non-Wan VAEs, state-space memory models) is not tested.
- The choice of bounded cache capacity K=6 and sink ratio S/K=83% is heuristic; a principled or adaptive strategy for selecting K and S per prompt, scene type, motion complexity, or rollout length is missing.
- The “Sliding Semantics” rolling schedule (alternating forward/reverse segments) is ad hoc; no analysis or learning-based approach to derive optimal content rotation, ordering, or periodicity is provided.
- Theoretical understanding of why sliding indices and rolling semantics mitigate exposure bias is absent; formal drift models and error propagation analyses across AR steps (and across cache states) are needed.
- RoPE time index extrapolation to very large indices (minutes/hours) is assumed but not studied; the behavior of positional embeddings under extreme extrapolation (e.g., saturation/aliasing in RoPE) and alternatives (ALiBi, learned PE, hybrid PE) remain unexplored.
- Residual flicker and consistency artifacts are acknowledged but not systematically characterized; a taxonomy of failure modes and targeted mitigations (e.g., per-layer cache weighting, temporal smoothing modules) are missing.
- The approach repeats a finite training window via rolling, which risks periodicity/looping; quantitative metrics for novelty, non-redundancy, and long-horizon “loopiness” are not reported.
- Multi-shot, prompt-changing long-video generation is explicitly out of scope; mechanisms for cache re-initialization, semantic refresh, transition smoothing, and prompt-conditioned memory persistence remain open.
- The method assumes a fixed prompt and constant prompt embedding; strategies for gradual prompt evolution, conditioning drift control, or content “aging” without collapse are absent.
- Layer-wise cache design is uniform (concatenate prior K/V at all DiT layers); the impact of layer-specific cache policies, attention head gating, decay weighting, or learned cache mixing is not investigated.
- Cache corruption detection and repair are not addressed; adaptive filtering, compression, or confidence-weighted cache updates could help, but are unstudied.
- Interaction with denoising schedules is fixed (4-step sampler); the relationship between sampling steps/noise schedule and long-horizon drift is not analyzed, nor are adaptive samplers explored.
- Generalization to different frame rates, resolutions, aspect ratios, and block sizes is not evaluated; how Rollin scales or recalibrates to these settings is unclear.
- Performance beyond 5 minutes is claimed qualitatively, but quantitative evaluation (metrics) is limited to 1 and 5 minutes; rigorous assessment at 10–30 minutes or longer is missing.
- Robustness across prompt categories (e.g., high-speed camera motion, heavy occlusion, complex multi-object interactions, large illumination changes) is not systematically tested.
- The evaluation suite samples only 10 prompts per VBench-Long dimension; statistical significance, variance across seeds, and sensitivity to prompt sampling are not reported.
- Comparisons exclude several relevant training-free or memory-augmented baselines (e.g., MemFlow, VideoSSM, Deep/Hybrid Sink, Backwards Aggregation); a broader, head-to-head benchmarking is lacking.
- Effects of training duration on Rollin’s gains are unexplored; how benefits scale when the base model is trained on 10s/60s/100s clips or minute-scale datasets is an open question.
- No mechanism is provided to inject new semantics over time without destabilizing the cache; strategies for controlled content introduction (semantic gating/curriculum) are open.
- Identity and structure consistency improvements are shown, but dedicated identity metrics (beyond VBench-Long proxies) and human studies for perceptual continuity over minutes are missing.
- Compute and memory trade-offs are not deeply profiled; latency, throughput, and GPU memory overhead of sliding indices/semantics versus standard SF at different K/S are not reported.
- Safety and content governance for ultra-long rollouts (e.g., preventing unwanted repetition, drift to unsafe content) are not discussed; monitoring and intervention hooks are an open area.
Practical Applications
Immediate Applications
Below are practical use cases that can be deployed now using Rollin (Rolling Sink), a training-free cache-maintenance strategy that enables ultra-long, stable autoregressive (AR) video diffusion from short-horizon-trained models.
- Stable single-shot long-take generation for film and media production (Media/Entertainment)
- Tools/Workflows: Plug-in for existing AR video generators (e.g., Self Forcing-based pipelines) that exposes sink ratio S/K, sliding indices, and rolling semantics as user-tunable controls to produce minute-long continuous shots.
- Assumptions/Dependencies: Single-prompt, single-shot content; bounded cache (e.g., K=6, S≈83%); relies on RoPE time indices and a short-horizon-trained AR model; no audio; resolution/framerate constraints from the base model.
- Digital signage and brand loops (Advertising/Retail)
- Tools/Workflows: Rollin-enabled “loop generator” to create long, stable background motion graphics for storefronts, event stages, and trade-show displays.
- Assumptions/Dependencies: Static or slowly evolving scene semantics; quality tied to base model’s learned priors and VAE decoding.
- VJing and live event visuals (Performing Arts/Creative Tech)
- Tools/Workflows: Real-time AR video visuals engine with Rollin cache scheduling for LED walls and stage projections; parameters exposed via MIDI/OSC for live control.
- Assumptions/Dependencies: Real-time inference on GPUs; consistent subject/structure stability prioritized over frequent semantic changes.
- Streamer overlays and ambient backgrounds (Consumer Software/Content Creation)
- Tools/Workflows: Desktop/mobile apps that generate long, coherent background videos for livestreams, video calls, and social media posts.
- Assumptions/Dependencies: Single prompt; safe-content filters; on-device or cloud inference.
- Previsualization and animatics for long shots (Film/Animation/Pre-production)
- Tools/Workflows: Storyboard-to-long-take preview tool that reads a static shot description and produces multi-minute previsualizations with consistent IDs/colors/structures.
- Assumptions/Dependencies: Scene and subject identities remain stable; directors can iterate via prompt refinement rather than multi-shot scripting.
- Synthetic data generation for long-horizon computer vision tasks (Academia/Software)
- Tools/Workflows: Dataset pipelines generating long sequences with stable identity, structure, and motion to benchmark tracking, segmentation, and temporal consistency algorithms.
- Assumptions/Dependencies: Synthetic physics and realism limited by the base model; labels may require auxiliary annotation tools.
- Long-horizon quality evaluation harness (Academia/Benchmarking)
- Tools/Workflows: Adoption of VBench-Long with Rollin-enabled rollouts to stress-test AR models beyond training windows; standardize metrics for flicker, consistency, motion smoothness.
- Assumptions/Dependencies: Access to evaluation models and fixed prompt suites; reproducible inference settings; compute availability.
- Cost-effective long-form generation without retraining (Software/Cloud)
- Tools/Workflows: “Training-free long-form mode” in existing video-gen APIs; cloud microservice that wraps AR models with Rollin cache logic to extend horizons.
- Assumptions/Dependencies: Compatible base AR model; throughput depends on streaming sampler steps and bounded cache; GPU scheduling.
- Stability-first mode in creative suites (Creative Software)
- Tools/Workflows: Toggle in video-gen UIs to switch to Rollin for minutes-long shots; presets that manage sink size and rolling cadence for different content types.
- Assumptions/Dependencies: Single-shot workflows; integration with existing DiT-based backends.
- Policy-aligned watermarking and provenance for long synthetic videos (Policy/Platform Trust & Safety)
- Tools/Workflows: Pipeline hooks to embed persistent watermarks and metadata across extended outputs; moderation systems tuned for long-horizon artifacts (repetition, identity drift).
- Assumptions/Dependencies: Platform cooperation; watermark survives compression; content provenance standards.
Long-Term Applications
The following use cases require further research, scaling, or development, including multi-shot prompting, semantic transition design, audio, and higher-fidelity/physics-aware generation.
- Multi-shot, script-level long video generation with coherent transitions (Media/Entertainment)
- Tools/Workflows: Shot scheduler that extends Rollin principles to multi-shot prompts; semantic memory across scenes; transition-aware cache management.
- Assumptions/Dependencies: New cache policies to handle changing semantics; continuity tools (character/location tracking); multi-prompt conditioning.
- Virtual production integration for LED volumes and camera tracking (Film/Production Tech)
- Tools/Workflows: Rollin-powered generative backgrounds that remain consistent over long takes; integration with camera metadata and lighting pipelines.
- Assumptions/Dependencies: High-fidelity rendering, real-time constraints, physics-aware motion; safety rails for artifact detection.
- Real-time interactive long video with dynamic user inputs (XR/Interactive Media)
- Tools/Workflows: Multi-prompt Rollin that can update semantics mid-rollout without destabilizing identity/motion; control via gestures or controllers.
- Assumptions/Dependencies: Robust cache update strategies; latency-optimized inference; user-guided semantic management.
- Extended world simulators for planning and training (Robotics/Autonomy/AI Research)
- Tools/Workflows: Long-horizon simulated visuals for pretraining temporal reasoning, tracking, and planning models; stress-testing autonomy pipelines.
- Assumptions/Dependencies: Physics consistency and domain realism; coupling with dynamics engines; validation against real-world data.
- Generative cinematography assistants (Media Tools)
- Tools/Workflows: Tools that suggest camera moves and scene evolution while maintaining long-horizon coherence; AI “long-take director” assistants.
- Assumptions/Dependencies: Higher-level narrative modeling; editable caches; integration with editing timelines.
- Long-form educational content generation (Education)
- Tools/Workflows: Generation of continuous demonstrations (e.g., lab simulations, process animations) with stable concepts over minutes/hours.
- Assumptions/Dependencies: Domain accuracy; expert-in-the-loop validation; content safety.
- Compliance frameworks for extended synthetic media (Policy/Standards)
- Tools/Workflows: Standards for watermark persistence across long sequences; provenance tracking; disclosure policies for generative broadcast content.
- Assumptions/Dependencies: Cross-platform adoption; robust detection/watermarking; regulatory alignment.
- On-device long video generation for AR glasses and mobile (Hardware/Edge)
- Tools/Workflows: Lightweight Rollin variants optimized for mobile NPUs/GPUs; energy-aware cache scheduling.
- Assumptions/Dependencies: Model compression; thermal/power budgets; UI constraints.
- Cross-modal long-horizon generation (Audio+Video, Narration) (Creative Tech)
- Tools/Workflows: Unified cache policies across video and audio models to maintain temporal coherence in soundtrack and visuals.
- Assumptions/Dependencies: Multi-modal AR architectures; synchronization strategies; evaluation metrics for cross-modal consistency.
- Production-scale “Rollin-as-a-Service” and memory scheduling libraries (Software/Platforms)
- Tools/Workflows: Managed services that provide standardized cache management (sliding indices/semantics) across generative backends; SDKs for developers.
- Assumptions/Dependencies: Vendor-neutral APIs; observability and QA hooks; autoscaling for long-form workloads.
Cross-cutting assumptions and dependencies
- Works best for single-shot, single-prompt scenarios; multi-shot requires new cache policies to handle semantic transitions.
- Depends on an AR video diffusion backbone (e.g., DiT-based models) with RoPE or compatible temporal indexing, a bounded cache, and short-horizon training (e.g., ~5s clips).
- Quality and realism are constrained by the base model’s training data, resolution, framerate, and VAE decoding.
- Content safety, copyright, and provenance must be addressed for commercial deployment (e.g., watermarking, moderation, dataset licensing).
- Compute considerations: real-time or near-real-time inference requires capable GPUs; streaming efficiency hinges on few-step samplers and cache size management.
Glossary
- AR cache: The conditioning memory of previously generated frames/blocks that the autoregressive model uses to predict the next block. "we conduct a systematic analysis of AR cache maintenance."
- AR drift: Progressive degradation and instability during long autoregressive generation caused by accumulated errors or distribution mismatch. "Such AR drift is commonly attributed to error accumulation."
- Attention Sink: A technique that pins a static prefix of early tokens/blocks in the attention cache to stabilize generation over long horizons. "We first apply Attention Sink (i.e., pinning the first blocks as sink blocks where both the time indices and semantics are static), and analyze the effect of different sink ratios ()."
- Autoregressive (AR) video diffusion models: Video generative models that predict frames sequentially by conditioning on previously generated frames within a diffusion process. "Recently, autoregressive (AR) video diffusion models has achieved remarkable performance."
- Bidirectional attentions: Attention mechanisms that allow information flow in both directions across time or tokens, often used in non-autoregressive diffusion transformers. "they usually rely on bidirectional attentions in DiTs~\cite{peebles2023scalable} and denoise all frames simultaneously, making them incompatible with such ``open-ended'' setting."
- Denoising diffusion model: A generative model that iteratively removes noise from an input across a schedule of timesteps to produce clean samples. "each AR generation step (i.e., conditional distribution) is modeled by a denoising diffusion model ~\cite{lipman2022flow,liu2022flow}."
- Denoising timesteps: The discrete time indices in a diffusion process that control noise levels during iterative denoising. "We term the set of denoising timesteps as , where and ."
- Diffusion forcing (DF): A training strategy where the model conditions on ground-truth frames that have been corrupted with noise at randomly sampled levels. "During training, major techniques for building the AR cache are teacher forcing (TF)~\cite{gao2024ca2,hu2024acdit,jin2024pyramidal,zhang2025test}, diffusion forcing (DF)~\cite{chen2024diffusion,yin2025slow,chen2025skyreels,gu2025long,teng2025magi,song2025history,po2025bagger}, and self forcing (SF)~\cite{huang2025self,yang2025longlive,cui2025self,hong2025relic,lu2025reward,yin2024improved,yin2024one,yi2025deep}."
- DiTs (Diffusion Transformers): Transformer-based architectures tailored for diffusion modeling in vision/video, often employing attention over tokens/frames. "they usually rely on bidirectional attentions in DiTs~\cite{peebles2023scalable} and denoise all frames simultaneously"
- Exposure bias: The mismatch between training and testing conditions in autoregressive models that causes errors to compound at test time. "we further interpret it through the lens of ``exposure bias''~\cite{bengio2015scheduled,ranzato2015sequence,lamb2016professor,zhang2019bridging,schmidt2019generalization,li2023alleviating,ning2023elucidating}"
- Latent frames: Compressed representations of video frames in a learned latent space used by the model prior to decoding to pixel space. "Specifically, it's trained on sequences of 21 latent frames (corresponding to 81 frames after VAE~\cite{wan2025} decoding)."
- Long-horizon drift: Visual degradation and inconsistency that emerges when generating far beyond the training duration. "We characterize the long-horizon drift in AR video diffusion as the exposure bias from a train-test horizon mismatch"
- LoRA: Low-Rank Adaptation; a parameter-efficient fine-tuning technique used to adapt large models with minimal additional parameters. "LongLive's LoRA weights (further trained on 1 minute videos) isn't loaded (i.e., w/o LoRA)."
- Open-ended testing: Test-time generation where the model continues producing content for arbitrarily long horizons without a predefined end. "Since open-ended testing can extend beyond any finite training window, and long-video training is computationally expensive, we pursue a training-free solution to bridge this gap."
- Prompt embedding: The vector representation of the input text prompt that conditions the generative model throughout synthesis. "Since the prompt embedding stays fixed throughout AR video synthesis"
- RoPE (Rotary positional embeddings): A positional encoding technique that encodes relative positions by rotating query/key vectors in attention. "The time indices are embedded using rotary positional embeddings (RoPE)~\cite{su2024roformer}."
- Rollin: The proposed training-free method that maintains cache behavior via sliding indices and rolling semantics to mitigate long-horizon drift. "we propose Rollin, a training-free approach for bridging the gap between limited-horizon training and open-ended testing."
- Rolling Sink: The specific instantiation of Rollin that uses a large attention sink and rolling of within-duration content to stabilize ultra-long generation. "Built on Self Forcing (trained on only 5s clips), Rolling Sink effectively scales the AR video synthesis to ultra-long durations (e.g., 5-30 minutes at 16 FPS) at test time"
- Self Forcing (SF): A training paradigm where the model conditions on its own generated frames rather than ground-truth, reducing train-test cache mismatch. "During training, major techniques for building the AR cache are teacher forcing (TF)~..., diffusion forcing (DF)~..., and self forcing (SF)~..."
- Sliding Indices: Assigning sink blocks time indices via a fixed-length sliding window aligned with the current step to better match temporal behavior. "Sliding Indices: Treating the time indices as a global axis , at each AR step , we shift sink blocks' time indices as a fixed-length (i.e., ) sliding window on this axis."
- Sliding Semantics: Updating the semantic content cached in sink blocks by rolling segments from within-duration history to approximate endless, drift-free evolution. "Sliding Semantics: Ideally, the sink blocks' semantic content should also slide along the a drift-free, global video manifold that lasts endlessly."
- Streaming efficiency: The ability to generate long sequences continuously under bounded memory and compute by limiting cache size and steps. "the total cache capacity is strictly bounded for streaming efficiency."
- Teacher forcing (TF): A training strategy where the model is conditioned on clean ground-truth previous frames during autoregressive learning. "During training, major techniques for building the AR cache are teacher forcing (TF)~\cite{gao2024ca2,hu2024acdit,jin2024pyramidal,zhang2025test}"
- Train-test gap: The performance mismatch arising when test-time conditions (e.g., longer horizons) differ from those seen during training. "a train-test gap emerges when testing at longer horizons, leading to rapid visual degradations."
- umT5: A multilingual variant of T5 used to encode prompts for conditioning video generation. "the global prompt embedding (encoded by umT5~\cite{chung2023unimax}) is constant during AR video synthesis"
- VAE (Variational Autoencoder): A generative model that encodes frames into a latent space and decodes them back, used here to map between latents and pixels. "corresponding to 81 frames after VAE~\cite{wan2025} decoding"
- VBench-Long: A long-video evaluation benchmark that measures quality across multiple diagnostic dimensions. "quantitative evaluations using VBench-Long \cite{huang2023vbench,huang2025vbench++,zheng2025vbench2} on both 1-minute (Tab.~\ref{tab:1min}) and 5-minute (Tab.~\ref{tab:5min}) AR video synthesis"
- Video manifold: The conceptual high-dimensional manifold of valid video trajectories whose local slices represent temporally coherent content. "the sink blocks' semantic content should also slide along the a drift-free, global video manifold that lasts endlessly."
Collections
Sign up for free to add this paper to one or more collections.