Integrating Code Metrics into Automated Documentation Generation for Computational Notebooks
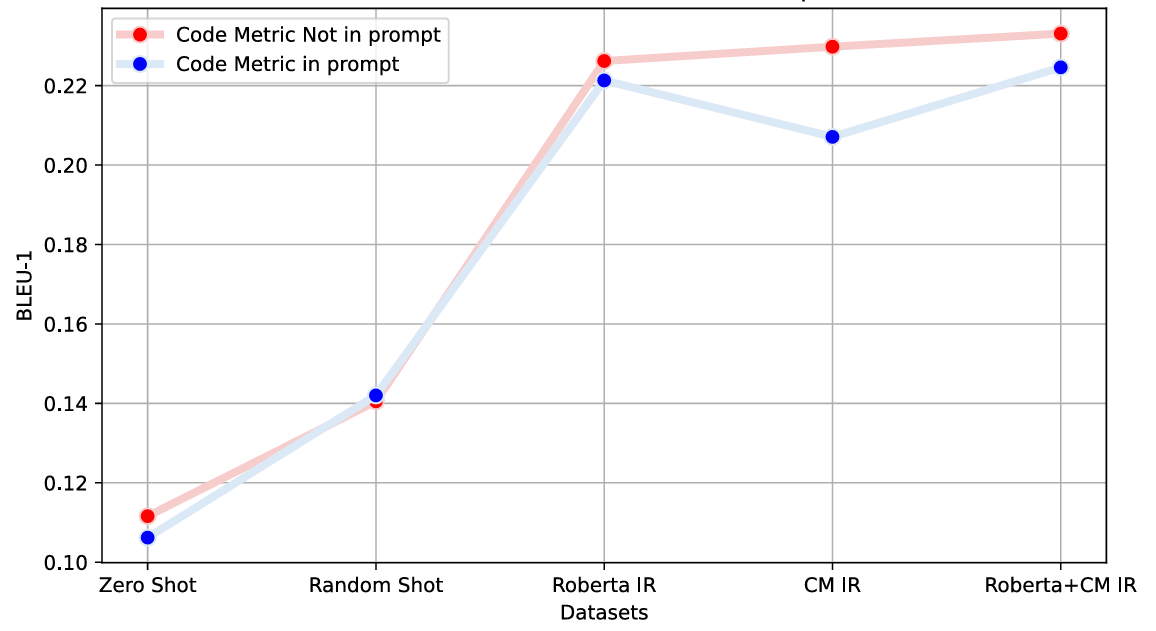
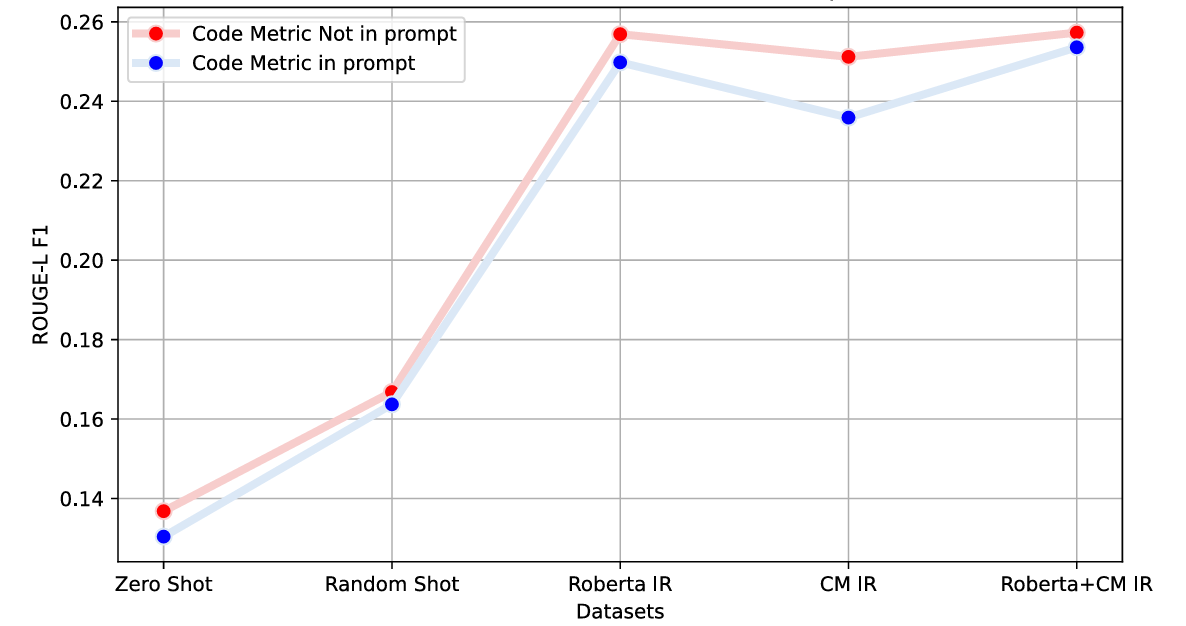
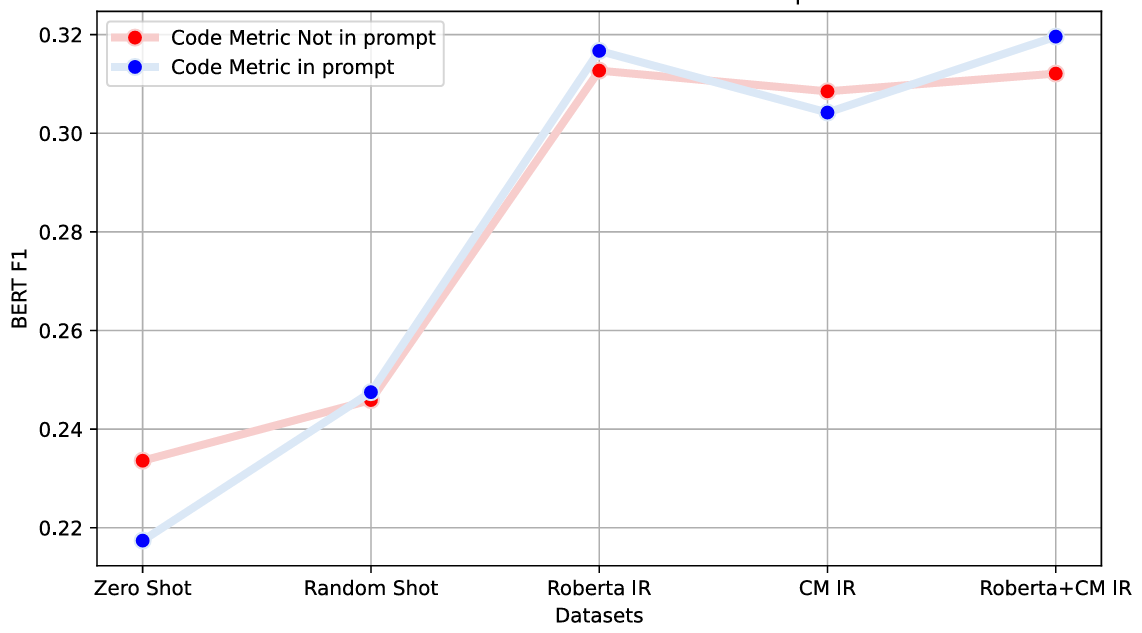
Abstract: Effective code documentation is essential for collaboration, comprehension, and long-term software maintainability, yet developers often neglect it due to its repetitive nature. Automated documentation generation has evolved from heuristic and rule-based methods to neural network-based and LLM-based approaches. However, existing methods often overlook structural and quantitative characteristics of code that influence readability and comprehension. Prior research suggests that code metrics capture information relevant to program understanding. Building on these insights, this paper investigates the role of source code metrics as auxiliary signals for automated documentation generation, focusing on computational notebooks, a popular medium among data scientists that integrates code, narrative, and results but suffers from inconsistent documentation. We propose a two-stage approach. First, the CodeSearchNet dataset construction process was refined to create a specialized dataset from over 17 million code and markdown cells. After structural and semantic filtering, approximately 36,734 high-quality (code, markdown) pairs were extracted. Second, two modeling paradigms, a lightweight CNN-RNN architecture and a few-shot GPT-3.5 architecture, were evaluated with and without metric information. Results show that incorporating code metrics improves the accuracy and contextual relevance of generated documentation, yielding gains of 6% in BLEU-1 and 3% in ROUGE-L F1 for CNN-RNN-based architecture, and 9% in BERTScore F1 for LLM-based architecture. These findings demonstrate that integrating code metrics provides valuable structural context, enhancing automated documentation generation across diverse model families.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Practical Applications
Overview
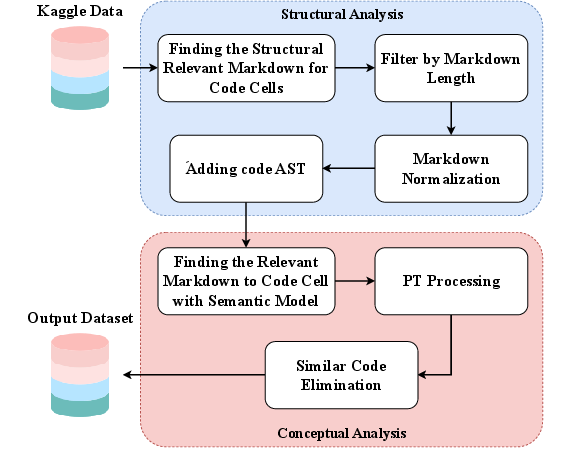
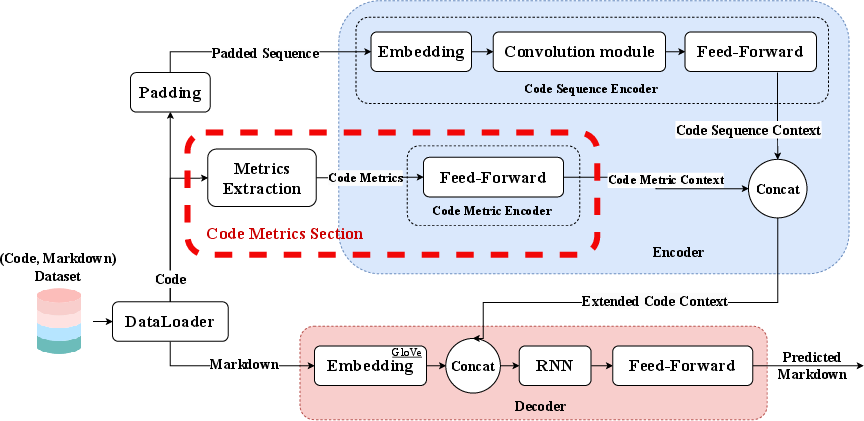
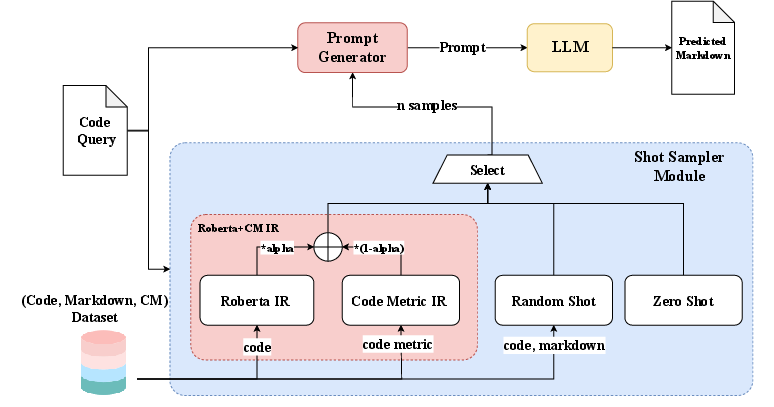
This paper shows that adding explicit source code metrics to documentation-generation pipelines for computational notebooks improves the accuracy, relevance, and abstraction level of generated markdown. The authors curate a 36,734-pair dataset of notebook code/markdown, design a metric-augmented CNN–RNN model, and introduce metric-informed few-shot prompting for LLMs (GPT‑3.5), with measurable gains (e.g., +6% BLEU‑1, +3% ROUGE‑L F1; +9% BERTScore F1). Core innovations include a robust notebook pairing methodology, a practical metric set (e.g., LOC, CyC, Halstead, API Popularity), and retrieval modules that combine semantic and metric similarity to select exemplar shots.
Below are practical applications derived from these findings, grouped by immediacy and linked to sectors, tools/products, workflows, and key assumptions.
Immediate Applications
These are deployable now with existing tooling (e.g., Python/Jupyter, off‑the‑shelf LLM APIs).
- Metric‑informed auto‑documentation plugins for JupyterLab/VS Code
- Sectors: software, education, healthcare, finance
- Tools/products/workflows: a JupyterLab or VS Code extension that computes notebook metrics and invokes a metric‑aware prompt generator with Roberta+CM IR to produce concise, purpose‑level cell summaries
- Assumptions/dependencies: access to LLM APIs (e.g., GPT‑3.5), reliable metric extraction for Python, team acceptance of auto‑generated text
- CI/CD “documentation gate” for notebooks
- Sectors: software/data engineering
- Tools/products/workflows: Git pre‑commit hook or GitHub Action that (1) computes metrics (CyC, LOC, EAP), (2) flags under‑documented high‑complexity cells, (3) auto‑generates draft markdown, and (4) requires reviewer sign‑off
- Assumptions/dependencies: repository access, build minutes/compute budget, policy alignment with teams’ quality standards
- Code review prioritization and suggestion feed
- Sectors: software, finance, healthcare
- Tools/products/workflows: PR bot annotating cells with high complexity or unfamiliar APIs (low EAP), attaching LLM‑generated summaries and links to canonical API docs
- Assumptions/dependencies: integration with code hosting platforms, accurate API popularity index, human‑in‑the‑loop review
- RAG‑enhanced notebook assistants
- Sectors: software, data science
- Tools/products/workflows: internal assistants that use Roberta+CM IR to fetch metric‑similar exemplars before prompting the LLM, improving abstraction consistency and fluency
- Assumptions/dependencies: vector store (e.g., Faiss/Pinecone) containing embeddings and metric vectors; data privacy controls
- Knowledge base generation from notebooks
- Sectors: enterprise ML platforms, research labs
- Tools/products/workflows: pipeline converting notebooks to wiki pages/READMEs with standardized, metric‑aware summaries, glossary of APIs, and links to results/output cells
- Assumptions/dependencies: markdown normalization, stable notebook structures, organizational knowledge‑base platforms (Confluence, Notion, GitHub Wiki)
- Educational auto‑annotations aligned to complexity
- Sectors: education, MOOCs
- Tools/products/workflows: classroom tooling that produces succinct explanations for simple cells and richer narrative for complex ones, leveraging CyC/NBD and EAP to calibrate style
- Assumptions/dependencies: curated prompts/templates per course level; educator oversight to prevent hallucinations
- Lightweight audit artifacts for regulated workflows
- Sectors: healthcare, finance
- Tools/products/workflows: auto‑generated run‑books that summarize data loading, preprocessing, and model training steps, annotated with structural metrics (for reproducibility and audit traceability)
- Assumptions/dependencies: regulator acceptance of AI‑assisted documentation; secure handling of sensitive code/data
- Notebook linting and refactoring hints
- Sectors: software/data science
- Tools/products/workflows: “doc linter” that flags long cells (LOC/ALLC), deep nesting (NBD), or poor identifier density (KLCID), with auto‑generated summaries and split recommendations
- Assumptions/dependencies: non‑disruptive refactoring suggestions; compatibility with existing style guides
- Academic benchmarking and replication
- Sectors: academia/software engineering research
- Tools/products/workflows: using the curated dataset and replication package to evaluate metric‑augmented documentation, enabling comparative studies with BLEU/ROUGE/BERTScore
- Assumptions/dependencies: dataset licensing/availability, adherence to Kaggle TOS
- API popularity–aware help links
- Sectors: software/education
- Tools/products/workflows: tooling that surfaces canonical examples and official docs for popular APIs detected via EAP, embedded into generated summaries
- Assumptions/dependencies: up‑to‑date API frequency index across notebooks; robust mapping to documentation URLs
Long‑Term Applications
These require further research, scaling, integration, or standardization beyond the current prototypes.
- Fine‑tuned, metric‑aware documentation LLMs
- Sectors: software, enterprise ML tooling
- Tools/products/workflows: train/fine‑tune domain LLMs on metric‑augmented inputs across notebooks/codebases to surpass few‑shot baselines and reduce API costs
- Assumptions/dependencies: large, high‑quality training corpora; compute budgets; licensing for model weights/data
- Cross‑language and multi‑environment support
- Sectors: data platforms (R, Julia, Scala/Spark), robotics
- Tools/products/workflows: port metric definitions and extraction to other notebook ecosystems; adapt prompts for domain‑specific libraries (e.g., ggplot2, Flux, ROS)
- Assumptions/dependencies: language‑specific metric tooling; diverse training datasets; domain prompts/templates
- Adaptive IDE documentation at scale
- Sectors: software, finance, healthcare
- Tools/products/workflows: IDE services that dynamically switch summary granularity and tone based on live metrics (complexity, identifier density, API familiarity), integrated with Copilot‑style assistants
- Assumptions/dependencies: real‑time metric computation; UX acceptance; privacy/security constraints
- Documentation governance platforms and SLOs
- Sectors: enterprise/DevOps
- Tools/products/workflows: dashboards tracking maintainability metrics, documentation coverage, and “documentation SLOs”; automated routing of high‑risk notebooks for review
- Assumptions/dependencies: organizational buy‑in; integration with CI/CD, issue trackers, and data catalogs
- Compliance‑grade audit trails for MLOps
- Sectors: healthcare, finance, energy
- Tools/products/workflows: lineage‑aware documentation generation that ties metric‑tagged code steps to datasets, parameters, and outputs for end‑to‑end auditability
- Assumptions/dependencies: instrumentation of pipelines; alignment with standards (e.g., model risk management, reproducible research guidelines)
- Knowledge graphs of code by metric and semantics
- Sectors: software, robotics, energy
- Tools/products/workflows: internal search mapping fragments via semantic embeddings and structural metrics, enabling rapid comprehension and reuse across large repos
- Assumptions/dependencies: scalable ingestion; consistent pairing of code/markdown; governance over proprietary code
- Risk scoring and operational readiness checks
- Sectors: production analytics, fintech, healthcare
- Tools/products/workflows: metric‑based risk scores (e.g., high CyC + low EAP + sparse comments) to gate deployments of notebooks/pipelines
- Assumptions/dependencies: calibrated thresholds; avoidance of false positives; integration with approval workflows
- Personalized learning systems
- Sectors: education
- Tools/products/workflows: adaptive teaching agents that tailor explanations and exercises to student proficiency using code metrics as a proxy for cognitive load
- Assumptions/dependencies: student modeling; ethical AI practices; educator‑defined learning objectives
- Platform‑level auto‑documentation features
- Sectors: developer platforms (Kaggle, GitHub, Databricks)
- Tools/products/workflows: native features suggesting metric‑aware summaries upon commit or notebook save, with community feedback loops
- Assumptions/dependencies: platform partnerships; rate‑limit policies; content moderation
- Standardization and policy guidance
- Sectors: academia, research policy, regulated industries
- Tools/products/workflows: best‑practice guidelines recommending metric‑informed documentation minimums for notebooks and ML experiments, supporting reproducibility mandates
- Assumptions/dependencies: consensus among stakeholders; alignment with journal/regulatory requirements
Collections
Sign up for free to add this paper to one or more collections.