- The paper introduces FRPO, optimizing reward flatness within a KL neighborhood to prevent catastrophic forgetting in LLM fine-tuning.
- It leverages a max-min robust objective and entropic risk formulation, demonstrating superior safety alignment and continual learning retention.
- Empirical results show a 22% improvement in MATH500 accuracy and enhanced safety robustness compared to traditional GRPO baselines.
Robust Policy Optimization to Prevent Catastrophic Forgetting
Introduction and Motivation
Contemporary LLM pipelines increasingly depend on multi-stage training, typically involving initial RLHF from a base model, followed by fine-tuning for downstream tasks. Catastrophic forgetting—when downstream adaptation rapidly erodes previously learned capabilities, specifically safety guardrails—remains a significant vulnerability for these pipelines. Although existing approaches predominantly focus on downstream-time interventions (e.g., rehearsal, regularization, parameter-efficient methods, model merging), these solutions are brittle to variations in downstream fine-tuning and do not guarantee retention of upstream-aligned behaviors under unconstrained adaptation.
This work presents a paradigm shift: ensuring robustness should be explicitly encoded into the base model by optimizing for reward flatness within a KL neighborhood, rendering the model stable to a wide array of possible fine-tuning procedures. The paper thus situates itself at the intersection of robust RL, continual learning, and safe alignment, proposing Fine-tuning Robust Policy Optimization (FRPO) as the principal algorithmic contribution.
The central technical innovation is the max-min robust objective: instead of maximizing expected reward only at the current policy πθ (as in standard GRPO/DPO/PPO), the optimization proactively considers all post-fine-tuning policies Q reachable within a prescribed average KL-divergence ball of size ρ around πθ. The aim is to maximize the worst-case expected reward in this neighborhood, resulting in the robust policy objective: πθmaxQ:Ex[KL(Q(⋅∣x)∥πθ(⋅∣x))]≤ρinfEx,y∼Q[r(x,y)]−βKL(πθ∥πref)
This is formalized as a distributionally robust optimization (DRO) over the policy space, with the worst case framed by choosing an adversarial downstream adaptation within the KL ball. The dual form yields an entropic risk (exponential utility) objective, modulated by a parameter λ which controls sensitivity to low-reward trajectories. As λ→∞, the problem recovers the mean-reward RLHF baseline; as λ decreases, the objective becomes increasingly risk-averse, penalizing high-variance and high-sharpness solutions in the reward landscape.
The methodology is algorithmically efficient, augmenting GRPO with a computationally tractable modification. Variance reduction (jackknife correction) and baseline terms are provided for unbiased, low-variance gradients, maintaining the stability and convergence properties established in prior RLHF methods.
Empirical Results: Safety and Continual Learning
Safety Alignment Experiments
A comprehensive evaluation is conducted across multiple model families (Mistral, Qwen), using a dataset partitioned into harmful and harmless prompts. Several fine-tuning regimes are applied: SFT on Alpaca, SFT on GSM8K, and GRPO on UltraFeedback, testing both overt and implicit forgetting scenarios. The robustness of safety alignment is assessed with refusal rates (HarmBench) and StrongREJECT scores.
Key findings are:
- Optimal λ Selection: Tuning λ (robustness parameter) reveals that smaller values (e.g., 0.2) yield the flattest safety reward landscape under fine-tuning perturbations for both Mistral and Qwen, preserving safety under increasing KL.
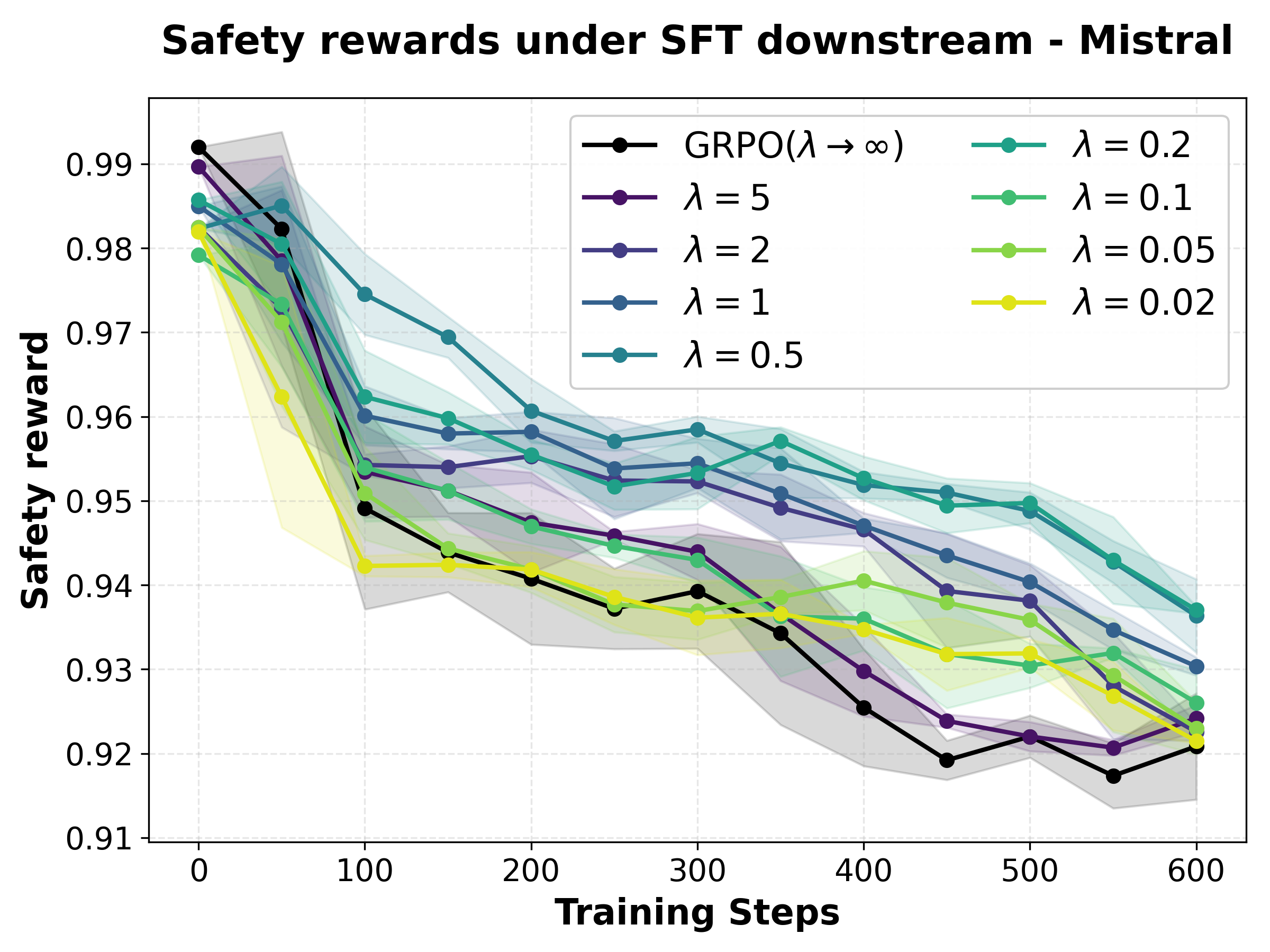
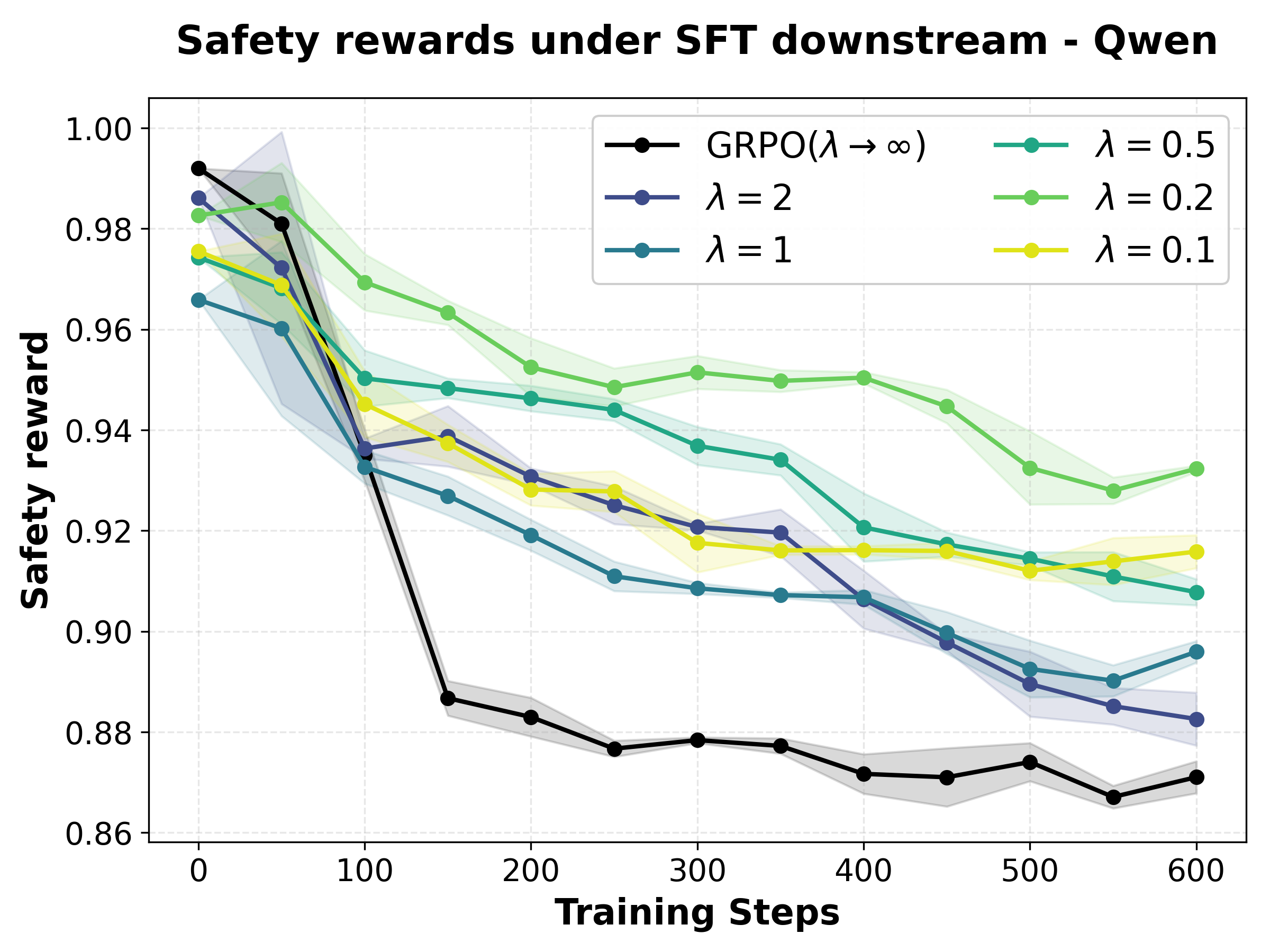
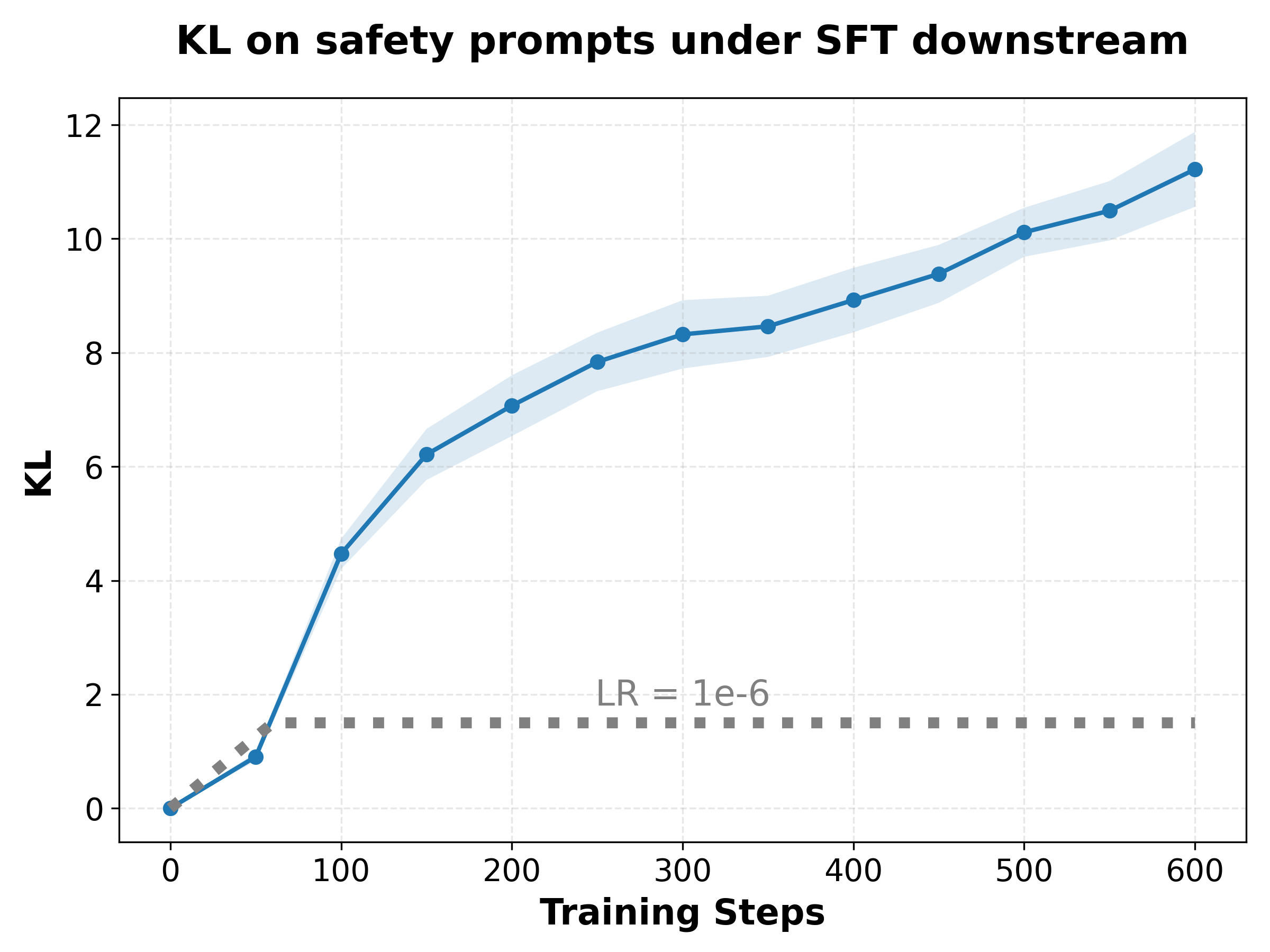
Figure 1: Safety reward as a function of policy drift (KL) under varying λ; λ=0.2 yields the flattest, most robust landscape.
- Downstream adaptation with FRPO consistently preserves safety better than GRPO. Under GSM8K SFT, both strong maintenance of refusal rates and lower StrongREJECT harmfulness are achieved, mitigating policy drift and sharp forgetting.
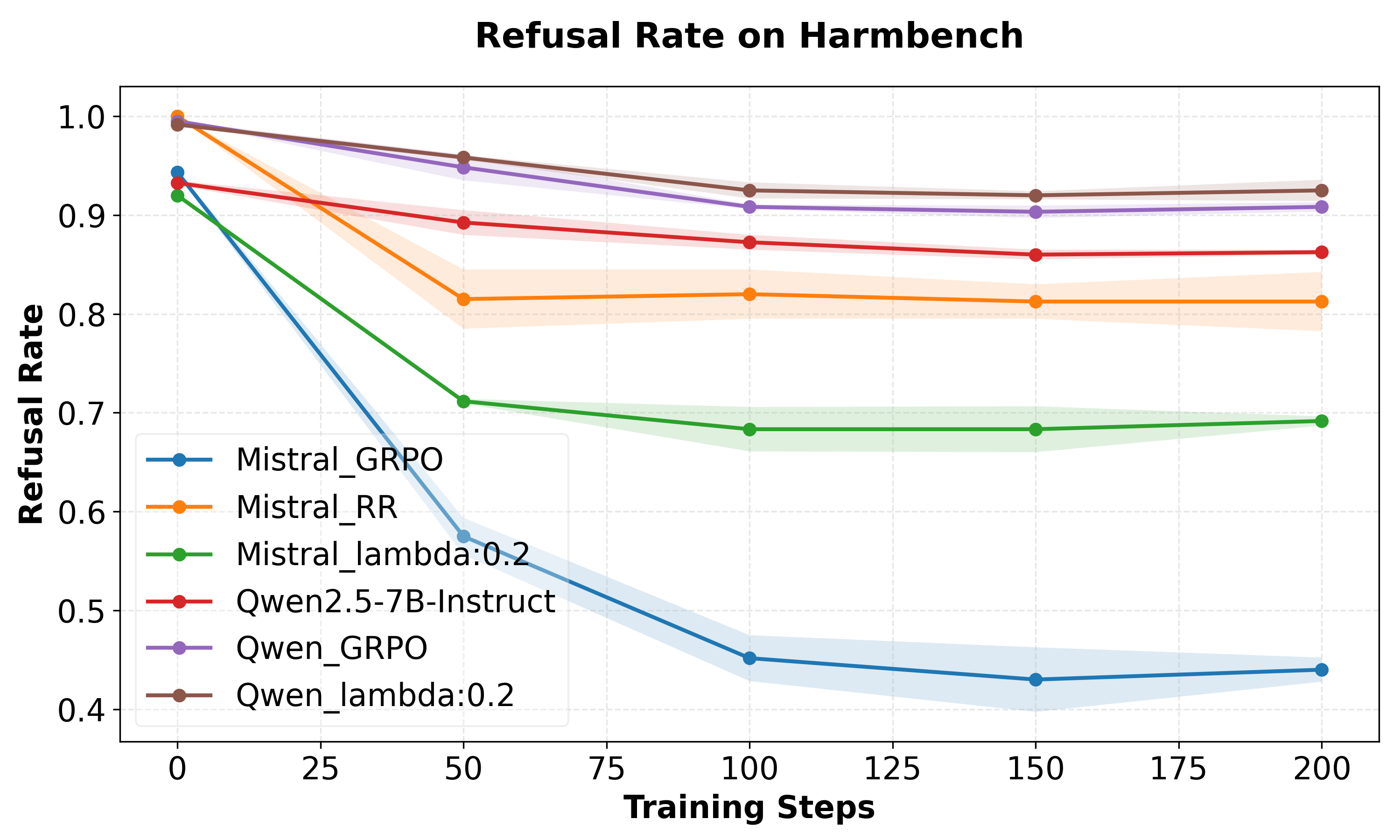
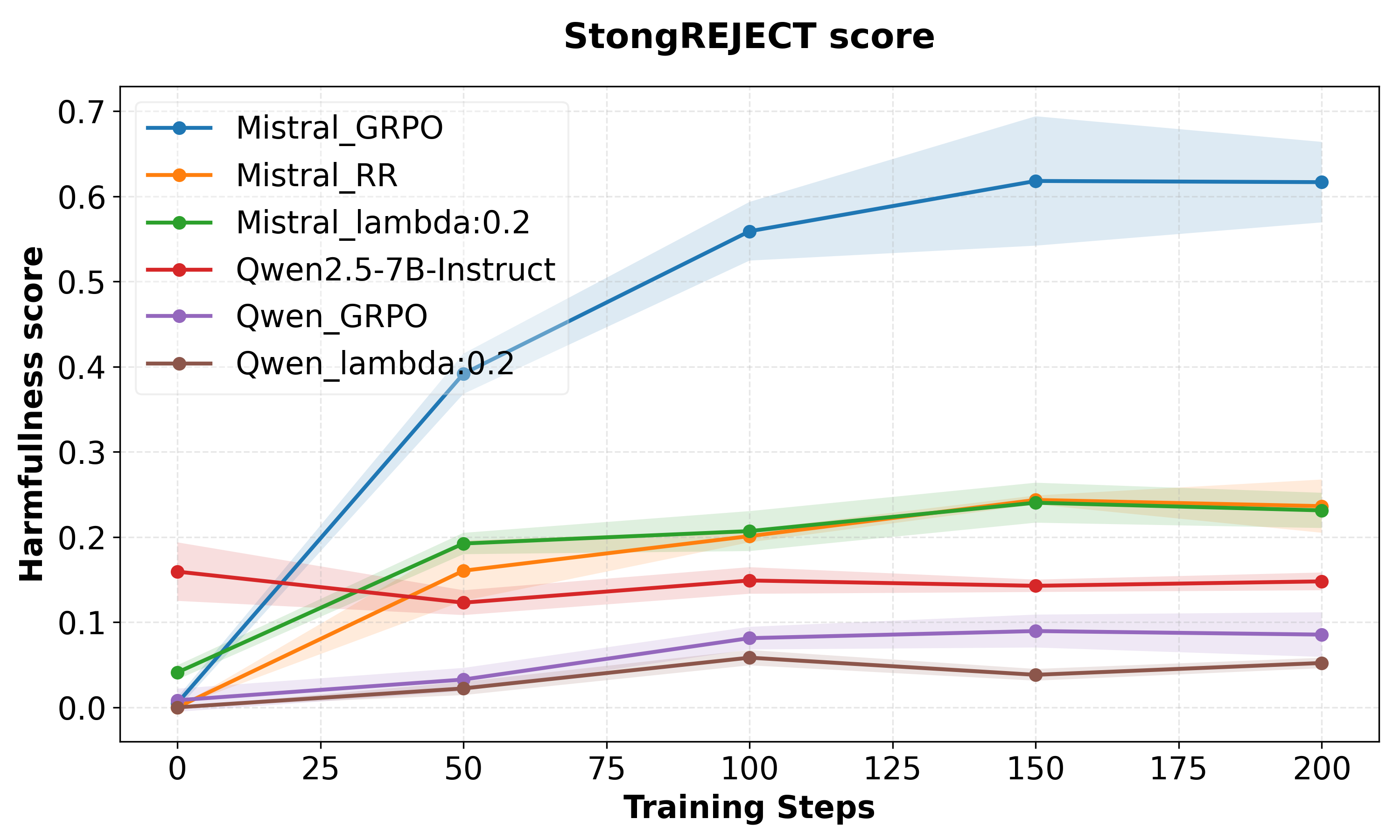
Figure 2: FRPO models achieve systematically higher safety robustness during GSM8K fine-tuning than GRPO.
- Trade-off between helpfulness and harmfulness is navigable: with UltraFeedback RL on Mistral, FRPO enables direct control over the Pareto frontier between these axes by adjusting λ—with lower λ preserving safety at the mild expense of helpfulness.
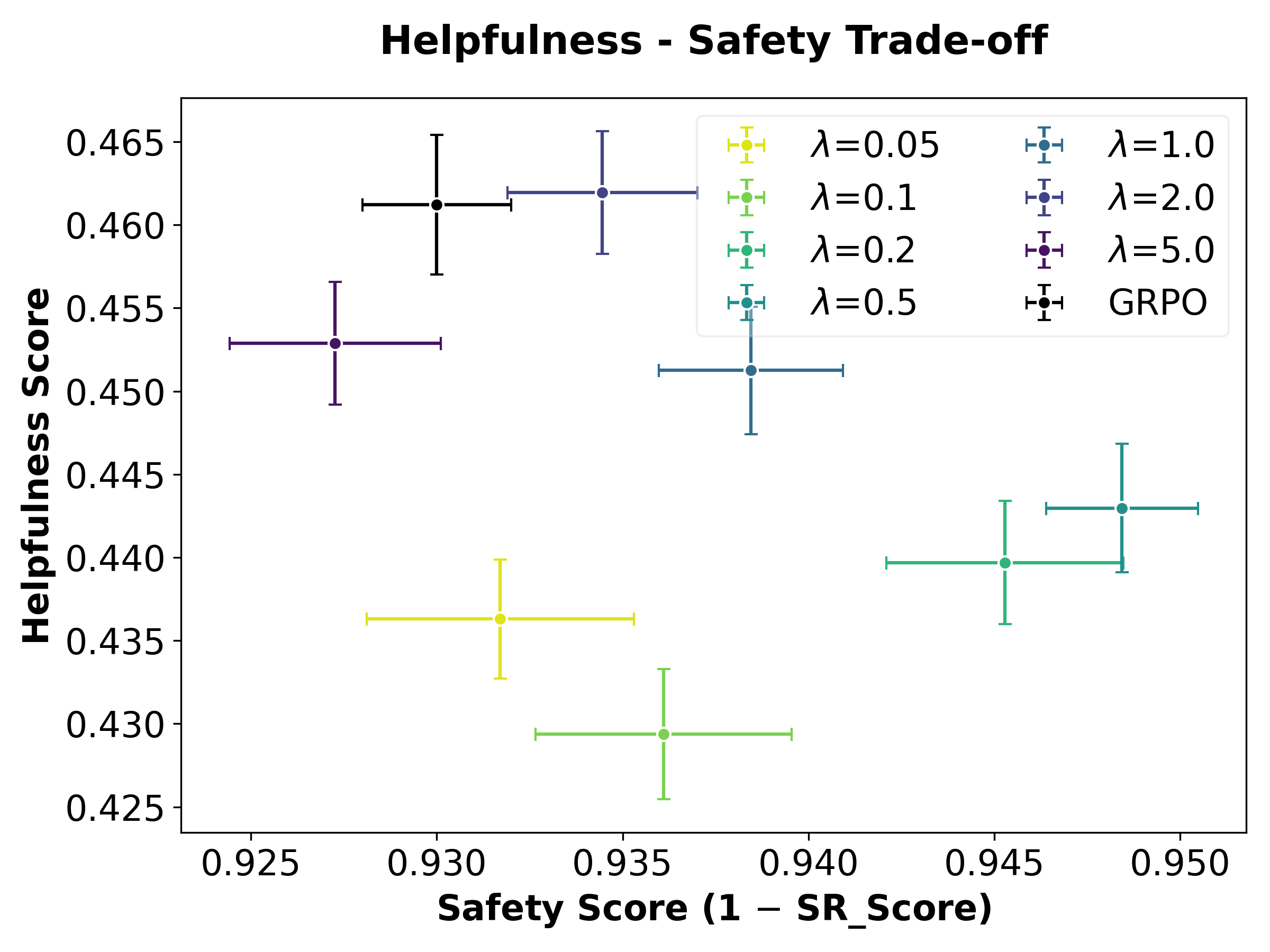
Figure 3: FRPO exposes a direct, tunable trade-off between safety (StrongREJECT) and helpfulness in RLHF fine-tuning.
Mathematical Reasoning Experiments
FRPO is shown to provide considerable continual learning robustness in the mathematical domain. After RL training for math problem-solving, models are further subjected to SFT on 25k programming samples (OpenCodeInstruct), testing whether mathematical proficiency is retained during domain shift.
- All training variants converge to similar math accuracy (∼73%) after RLHF.
- FRPO with λ=2.0 achieves 22% higher MATH500 accuracy post code fine-tuning compared to the GRPO baseline, clearly demonstrating robust transfer.
These results generalize the continual learning benefits of robust policy optimization to both safety and task-specific skills.
Implications and Theoretical Perspective
This work establishes that explicit optimization for flatter reward solutions in the policy space, using a max-min robust objective, is essential for preserving both safety and domain-specific capabilities against arbitrary future updates. In contrast to parameter-space flattening (e.g., SAM, Fisher SAM), the policy-space approach is more directly aligned with transfer robustness in RLHF and SFT regimes. It challenges the orthodoxy of downstream-time interventions by showing they are not sufficient in isolation, given the possibility of unconstrained subsequent updates.
Practical implications include:
- The need for robust upstream alignment in any LLM anticipated to undergo further customized adaptation.
- The explicit tuning parameter (λ) provides control over risk-aversion and hence the bias-variance tradeoff in downstream robustness.
- The theoretical equivalence to entropic risk provides interpretability: as in risk-sensitive RL, this framework actively discourages high-variance, brittle solutions.
Theoretically, this approach aligns with broader advances in robust RL and distributionally robust optimization, directly addressing the transferability limitations observed with current RLHF and SFT strategies.
Potential Future Directions
- Extension of policy-robust optimization approaches to pretraining and broader continual learning settings, not limited to RLHF.
- Further investigation into the capabilities that are inherently robust or brittle under the FRPO regime, with implications for safe alignment and catastrophic forgetting prevention.
- Dynamic adaptation of the λ parameter based on task-specific or empirical risk statistics.
Conclusion
The paper rigorously substantiates the necessity of policy-space reward-flatness for continual robustness in LLMs. The proposed FRPO method achieves strong empirical results in both safety and mathematical skill preservation, and introduces a theoretically grounded, computationally efficient approach to robust alignment. The findings delineate a path towards more resilient agentic systems, accommodating arbitrary downstream adaptation while retaining critical upstream behaviors.