$χ_{0}$: Resource-Aware Robust Manipulation via Taming Distributional Inconsistencies
Abstract: High-reliability long-horizon robotic manipulation has traditionally relied on large-scale data and compute to understand complex real-world dynamics. However, we identify that the primary bottleneck to real-world robustness is not resource scale alone, but the distributional shift among the human demonstration distribution, the inductive bias learned by the policy, and the test-time execution distribution -- a systematic inconsistency that causes compounding errors in multi-stage tasks. To mitigate these inconsistencies, we propose $χ{0}$, a resource-efficient framework with effective modules designated to achieve production-level robustness in robotic manipulation. Our approach builds off three technical pillars: (i) Model Arithmetic, a weight-space merging strategy that efficiently soaks up diverse distributions of different demonstrations, varying from object appearance to state variations; (ii) Stage Advantage, a stage-aware advantage estimator that provides stable, dense progress signals, overcoming the numerical instability of prior non-stage approaches; and (iii) Train-Deploy Alignment, which bridges the distribution gap via spatio-temporal augmentation, heuristic DAgger corrections, and temporal chunk-wise smoothing. $χ{0}$ enables two sets of dual-arm robots to collaboratively orchestrate long-horizon garment manipulation, spanning tasks from flattening, folding, to hanging different clothes. Our method exhibits high-reliability autonomy; we are able to run the system from arbitrary initial state for consecutive 24 hours non-stop. Experiments validate that $χ{0}$ surpasses the state-of-the-art $π{0.5}$ in success rate by nearly 250%, with only 20-hour data and 8 A100 GPUs. Code, data and models will be released to facilitate the community.
First 10 authors:
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about teaching robots to handle long, multi-step tasks in the real world—like flattening, folding, and hanging clothes—without needing huge amounts of data or supercomputers. The researchers noticed that the biggest problem isn’t just “more data = better robots.” Instead, robots fail because what they learn during training doesn’t match what they face when working for real. Their new framework (called Kai-0 in their code) tries to fix those mismatches so robots can be reliable over many steps.
What questions did they ask?
Put simply, they asked:
- Why do robots that look good in training fall apart during real work?
- How can we make robots more reliable on long tasks (with many steps), without spending endless time and money collecting data?
- Is there a way to align what robots learn, how they think, and what actually happens when they move?
They diagnosed three common mismatches:
- Training vs. reality: The examples humans give (training data) don’t cover all the situations robots see in the real world.
- Model habits vs. actual timing: The robot’s “thinking speed” doesn’t match the physical timing of motors and sensors (like lag in a video game).
- No recovery plan: If the robot gets off track (even a little), it often can’t recover because it never saw recovery examples during training.
How did they do it? (Methods explained)
To fix those mismatches, they introduced three practical ideas. Think of them as tools to help a robot learn smarter, act steadier, and adjust to real life:
- Model Arithmetic (MA): Instead of training one big model on all data, they train several models on different subsets (like different “skills”). Then they merge these models by combining their weights, a bit like mixing recipes to get the best flavor. This helps the final model “soak up” more of the useful patterns without needing tons of new data.
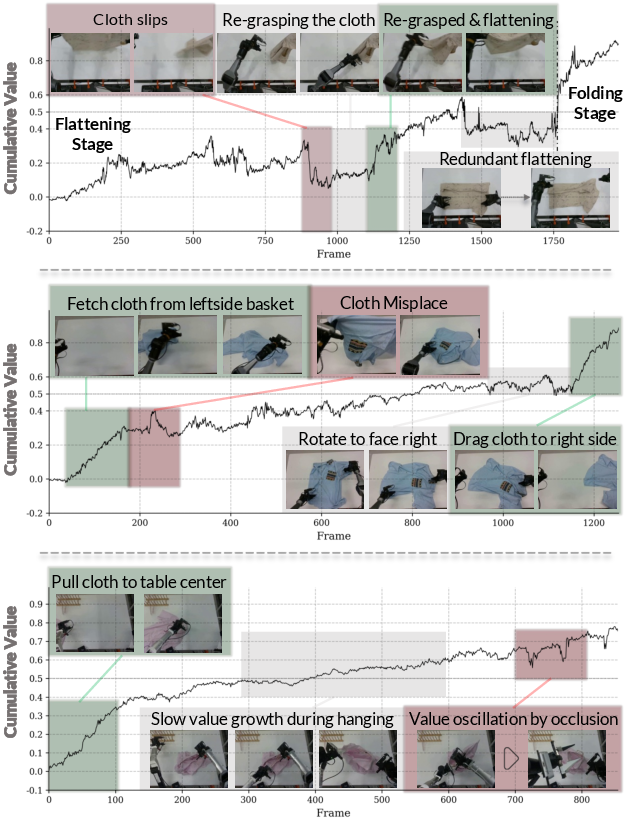
- Stage Advantage (SA): Long tasks are easier if you break them into stages (flattening, then folding, then hanging). SA gives a clear signal for how much each action moves the robot closer to finishing the current stage—like a progress bar for each step. This avoids noisy, unstable signals and teaches the robot to choose actions that truly advance the stage.
- Train-Deploy Alignment (TDA): The robot’s training data should look more like what happens during real work. They do three things:
- DAgger corrections: A human steps in when the robot starts to mess up, and their corrections become new training examples (so the robot learns recovery).
- Spatio-temporal augmentation: They flip images and vary timing to make the robot robust to different looks and speeds.
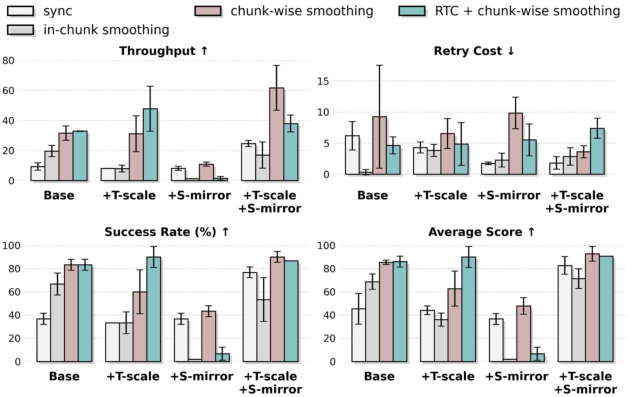
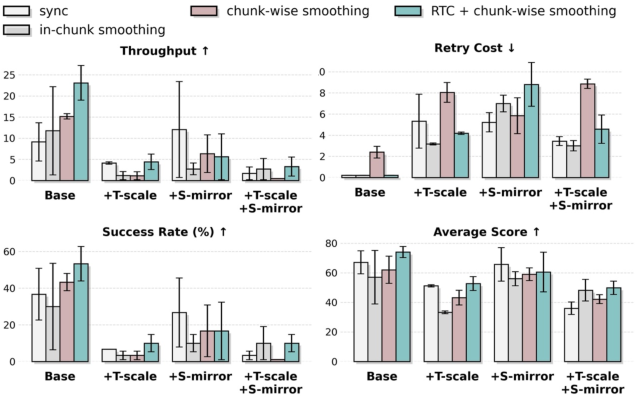
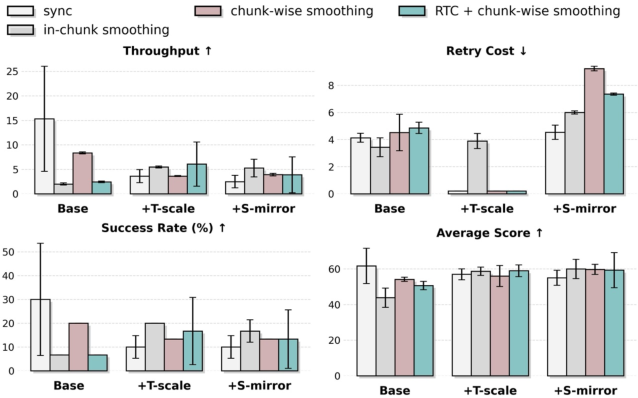
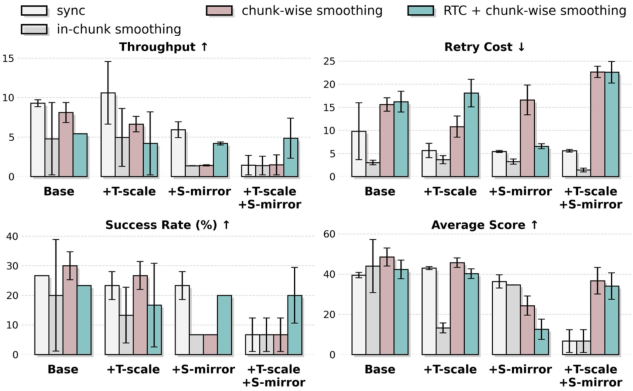
- Temporal chunk-wise smoothing: Robots often plan in “chunks” of actions. Smoothing blends old and new commands so motions stay steady even if there’s lag—like smoothly steering between two joystick inputs so the robot doesn’t jerk.
What did they find?
Their system worked well on challenging clothing tasks with two dual-arm robots working together:
- Tasks: flattening, folding, and hanging shirts from messy starting states.
- Reliability: They ran the system non-stop for 24 hours.
- Efficiency: They trained with about 20 hours of demonstrations and 8 GPUs (A100s).
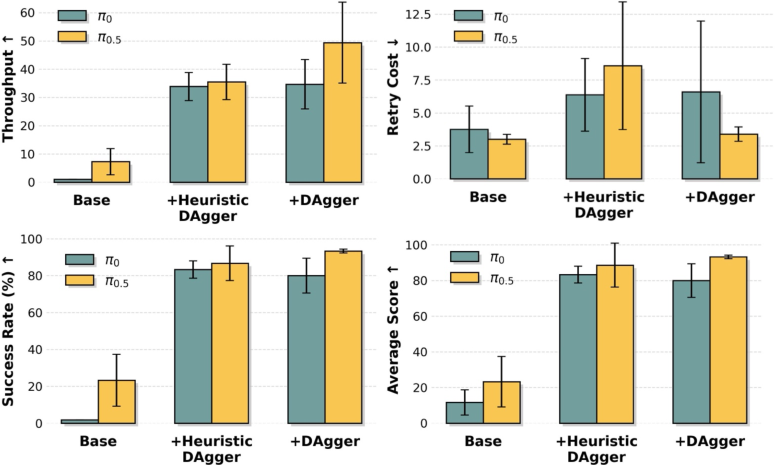
- Performance: Compared to a strong baseline model (π₀.₅), their success rate went up by about 250%.
They also learned:
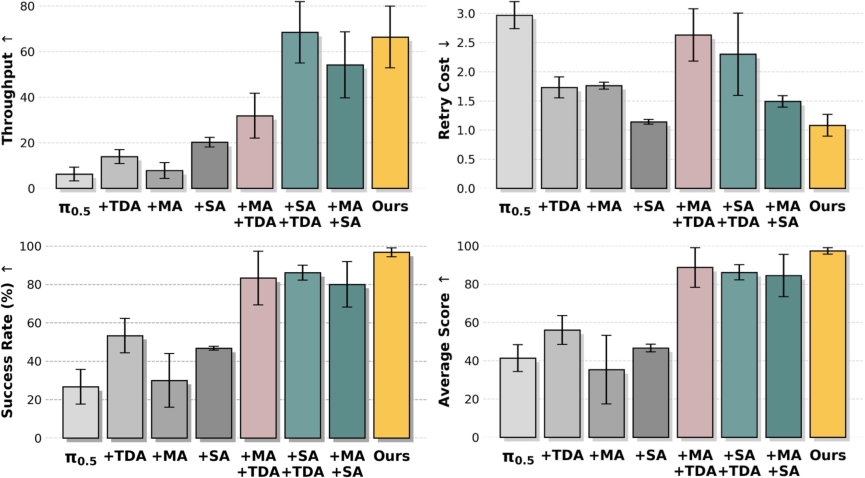
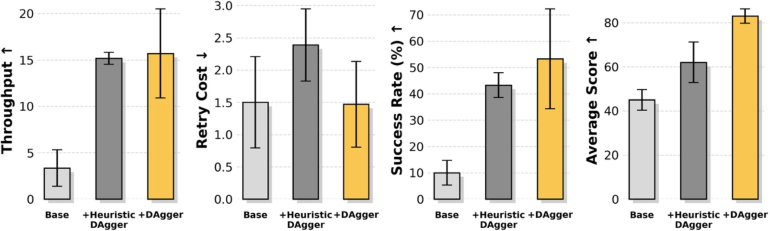
- Model Arithmetic consistently improved performance across most metrics (success, throughput), especially when they chose merging weights using “out-of-distribution” validation data (like recovery examples from DAgger).
- Stage Advantage made training more stable and helped the robot avoid wasting time (less idling, fewer bad retries), especially on longer, more conditional tasks.
- Train-Deploy Alignment increased success by teaching the robot how to recover and move smoothly. DAgger boosted success but sometimes increased retry counts—which makes sense, because recovery behaviors mean trying again instead of quitting.
Why does this matter?
This work shows a practical path to making robot manipulation reliable in the real world, without needing endless data or massive compute. By tackling the root cause—mismatches between training, model behavior, and real execution—robots can:
- Handle messy, real-life tasks (like laundry) for long periods.
- Learn recovery skills that keep them from giving up after small mistakes.
- Move more smoothly and safely when timing isn’t perfect.
In the future, ideas like these could help robots work in homes, hospitals, and warehouses on complex, multi-step jobs. The authors also note two open problems: scaling to more types of tasks while keeping pre-trained skills, and finding faster ways to judge data quality without lengthy retraining. Even so, this framework is a solid step toward dependable, resource-aware robot learning.
Knowledge Gaps
Knowledge Gaps, Limitations, and Open Questions
Below is a consolidated list of concrete gaps and open questions that remain unresolved and could guide future research:
- Model Arithmetic (MA) design and scope
- Lack of theoretical guarantees for weight-space merging: When does MA provably help or harm generalization under distribution shift, and how do conflicts between checkpoints manifest in merged representations?
- Sensitivity to merging hyperparameters: No analysis of how the number of subsets, coefficient initialization, regularization, or post-merge fine-tuning affect stability and performance.
- Validation data selection: OOD (DAgger) validation improves results, but the robustness of coefficient estimation to noisy or biased OOD sets and the minimum amount of OOD data needed are unstudied.
- Task-transfer merging: MA is demonstrated only on subsets of the same task; it remains unclear whether MA can merge policies trained on distinct tasks without catastrophic interference.
- Architecture diversity: It is unknown if MA is effective or safe across heterogeneous backbones (e.g., different VLA architectures or controller heads), or when merging policies with different action parameterizations.
- Stage Advantage (SA) formulation and scalability
- Manual stage annotations: The method depends on human-defined stages; the cost, consistency, and sensitivity of SA to stage granularity, mislabeling, and domain shifts are not quantified.
- Automatic stage discovery: Unclear whether stages can be learned or inferred (e.g., via unsupervised segmentation or contrastive progress models) and how this compares to manual labels.
- Signal design and calibration: Choice of threshold ε, time-span sampling strategy Δ, and binary discretization are not ablated for sensitivity and generalization; continuous advantage conditioning remains unexplored.
- Modalities beyond vision: SA uses pairwise images; whether incorporating actions, proprioception, and tactile signals reduces ambiguity and improves robustness is untested.
- Long-horizon bias: SA’s behavior under extremely long tasks (more than 3–4 stages), looping behaviors, and revisiting stages (non-monotonic progress) is not characterized.
- Train-Deploy Alignment (TDA) coverage and cost
- Heuristic DAgger trade-offs: The human time, safety risk, and data diversity achieved by initializing failure states vs. waiting for natural failures are not measured; guidelines for designing representative failure initializations are missing.
- Augmentation breadth: Spatio-temporal augmentation is limited to horizontal flips and frame skipping; the utility of richer augmentations (e.g., photometric noise, occlusions, viewpoint changes, dynamics perturbations) is unexplored.
- Latency and controller diversity: Temporal chunk-wise smoothing is evaluated on one hardware/control stack; sensitivity to latency distributions, action chunk sizes, servo bandwidths, and different low-level controllers (e.g., impedance, velocity, torque) is unknown.
- Interaction with other inference-time methods: Formal analysis of orthogonality or synergy with RTC, asynchronous inference, and temporal ensembling is absent, as are guidelines for joint tuning.
- Closed-loop data incorporation: No systematic study on how much on-policy rollout data (or Heuristic DAgger data) should be mixed into training, at what cadence, and with what weighting schemes to avoid overfitting to recovery regimes.
- Evaluation breadth and rigor
- Limited task coverage: Experiments focus on deformable garment manipulation; generalization to rigid-body tasks, tool use, cluttered scenes, and non-planar workspaces remains untested.
- Limited object and environment diversity: Robustness to new garment types, sizes, materials, lighting changes, occlusions, and workspace geometries is insufficiently quantified.
- Small sample sizes: Ten trials per garment type are likely underpowered; no statistical tests, confidence intervals, or power analyses are provided to substantiate “robust statistical significance.”
- Baseline comparability: Reported failures of other open-source VLAs are not accompanied by transparent training and tuning protocols; fairness of comparisons (data, compute, hyperparameters) is unclear.
- Throughput and retry cost definitions: These metrics are bespoke and not standardized; mapping to industry-relevant KPIs (e.g., cycle time, MTTR, failure rate distributions) and safety metrics is missing.
- Generalization, scalability, and retention of priors
- Retention of pre-trained priors: Post-training effect on generalist capabilities of foundation models (e.g., skill retention/forgetting) is not evaluated.
- Scaling laws: No empirical or theoretical scaling analysis relating data hours, compute, and performance; diminishing returns and optimal resource allocation are unknown.
- Multi-robot coordination: The system involves two dual-arm robots, but coordination strategies, communication latencies, collision avoidance, and role assignments are not formalized or evaluated under varying team sizes/topologies.
- Cross-hardware portability: Transferability across manipulators, grippers, sensors, and cameras (and to lower-cost hardware) is unknown; resource-aware claims are not benchmarked on constrained hardware for inference.
- Measurement of “distributional alignment”
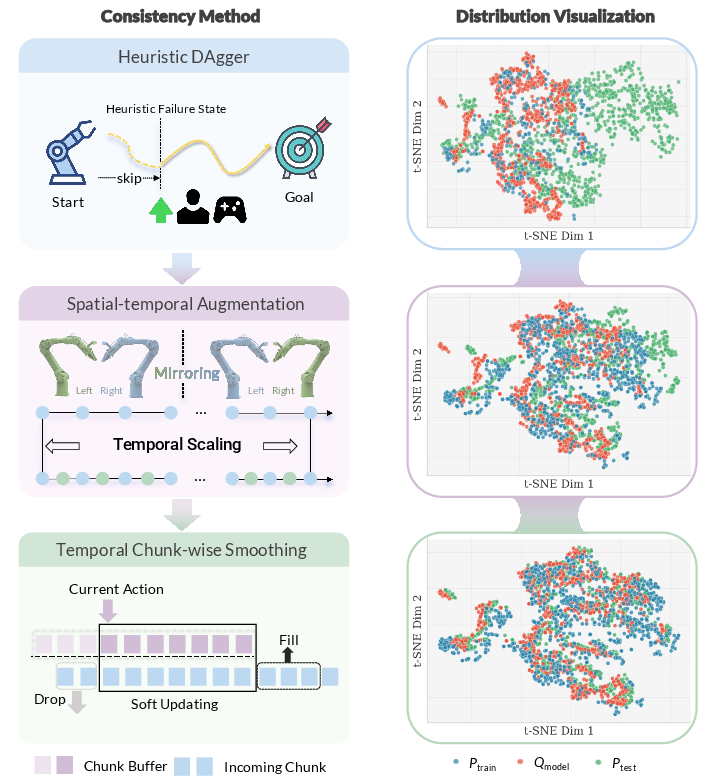
- Lack of quantitative alignment metrics: Alignment between P_train, Q_model, and P_test is visualized via t-SNE, but there are no formal measures (e.g., distribution distances, coverage metrics, failure-state occupancy) or causal attribution of module-specific improvements.
- Phase-specific diagnostics: No standardized diagnostics to separate gains from MA, SA, and TDA in terms of which misalignments (coverage deficiency, temporal mismatch, failure cascade) are most reduced on specific tasks.
- Safety, reliability, and compliance
- Safety engineering: No systematic risk assessment of failure states, human-in-the-loop data collection (DAgger), or intervention policies; strategies for safe rollouts and automated failsafes are not described.
- Reliability characterization: A “24-hour non-stop” claim lacks details on duty cycles, environmental variability, failure distributions, and reset policies; standard reliability metrics (e.g., MTTF, MTBF) are absent.
- Compliance and ethics: Data collection protocols, privacy, and safety compliance standards for deployment are not documented beyond a brief appendix note.
- Data valuation and selection
- Predictive data utility metrics: Beyond full training or replay checks, no efficient predictors are provided to assess demonstration or DAgger sample utility; active data selection strategies remain an open direction.
- OOD sample curation: Best practices for curating OOD validation sets that meaningfully reflect deployment distributions (P_test) without leakage are not established.
- Methodological extensions and comparisons
- Interaction with RL: While advantage-weighted regression is used, no empirical comparison with online RL (e.g., PPO variants adapted for diffusion policies) or hybrid IL+RL schemes under real-world sample constraints is provided.
- Flow-matching objective: The choice of flow-matching training is not ablated against alternative policy learning objectives (e.g., standard behavior cloning, diffusion policies with different loss functions).
- Multimodal sensing: The framework is vision-centric; how to incorporate force/torque, tactile, and audio for contact-rich tasks to reduce reliance on vision alone is unaddressed.
- Reproducibility and open-sourcing
- Missing implementation specifics: Key hyperparameters for MA (e.g., coefficient optimization), SA (e.g., ε, Δ distributions, stage definitions), and TDA (e.g., d_max, m_min, chunk sizes) are not fully documented with tuning ranges.
- Release timelines and completeness: Code, data, and models are promised but not available; without artifacts, external validation and replication of claimed gains are blocked.
Practical Applications
Overview
Below are practical, real-world applications grounded in the paper’s findings and innovations—Model Arithmetic (MA), Stage Advantage (SA), and Train-Deploy Alignment (TDA). Each application is tagged with relevant sectors, possible tools/products/workflows, and key assumptions or dependencies. The lists are organized by immediate and long-term deployability.
Immediate Applications
- Garment-handling automation in laundries, hotels, hospitals, and retail backrooms
- Sectors: robotics, retail, hospitality, healthcare, logistics
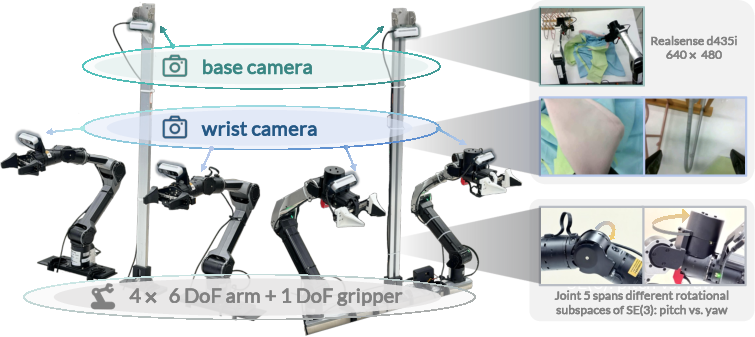
- Tools/Products/Workflows: pretrained “Kai0 Garment Pack” policies for flattening/folding/hanging; temporal chunk-wise smoothing controller plugin; site-specific stage annotation and heuristic DAgger recovery dataset collection; integration with dual-arm platforms (e.g., ALOHA, Franka)
- Assumptions/Dependencies: availability of dual-arm manipulators and vision; safe workcell setup; modest expert demonstrations (~20h) and 8×A100 training compute; variability in garments/lighting similar to training conditions
- E-commerce returns processing for deformable items (garments, soft goods)
- Sectors: logistics, warehousing, retail
- Tools/Products/Workflows: MA-based policy fusion to combine SKU- or site-specific fine-tunes into a general returns policy; SA for conditional sorting/folding; throughput/retry-cost dashboards for operations
- Assumptions/Dependencies: labeled stage schemas per workflow; OOD validation (e.g., DAgger recovery episodes); consistent product presentation and sensing
- Resource-efficient adoption of manipulation in SMEs and system integrators
- Sectors: manufacturing, systems integration
- Tools/Products/Workflows: turnkey training recipe (MA+SA+TDA) with data collection playbooks; spatio-temporal augmentation library; open-source code/models
- Assumptions/Dependencies: access to modest compute; limited but representative expert demos; operators trained in safe failure initialization (heuristic DAgger)
- Control-loop reliability upgrade via temporal chunk-wise smoothing
- Sectors: robotics, industrial software
- Tools/Products/Workflows: ROS/robot-controller plugin implementing chunk smoothing to mitigate inference-actuation latency; drop-in for VLA-based policies
- Assumptions/Dependencies: controller access to action buffers; chunked policy outputs; latency within bounds tunable by smoothing parameters
- Academic benchmarking and methodology improvements for long-horizon manipulation
- Sectors: academia, research labs
- Tools/Products/Workflows: new evaluation metrics beyond success rate (throughput, retry cost, smoothness); OOD validation protocol (DAgger-based) for model merging; code/data release to replicate garment tasks and stress testing
- Assumptions/Dependencies: stage annotations; availability of deformable-object benchmarks; reproducible deployment setups
- Cost-effective recovery data collection via Heuristic DAgger
- Sectors: robotics labs, integrators
- Tools/Products/Workflows: failure-state initialization templates (misgrasp, partial drops, occlusions) to front-load recovery demonstrations; safety checklist for human-in-the-loop collection
- Assumptions/Dependencies: operator training for safe failure seeding; procedure standardization to avoid risky states; basic teleoperation capabilities
- Conditional garment sorting and hanging in retail backrooms
- Sectors: retail operations, service robotics
- Tools/Products/Workflows: SA-conditioned policies to branch between folding and hanging; MA to merge store-specific policies; KPI dashboards (SR, TP, retry cost)
- Assumptions/Dependencies: garment-type recognition; stage labeling; stable fixture designs (tables, racks)
- Policy QA and deployment monitoring (reducing idling and spurious retries)
- Sectors: robotics software, QA
- Tools/Products/Workflows: SA-based “Progress Monitor” service to flag non-progress frames; thresholding for advantage-based data selection; automated retry-cost tracking
- Assumptions/Dependencies: availability of stage-conditioned advantage models; logging infrastructure; clear definitions of progress vs. non-progress
Long-Term Applications
- General-purpose household service robots for robust long-horizon chores
- Sectors: consumer robotics
- Tools/Products/Workflows: MA to fuse multi-task home policies (laundry, bed-making, tidying); SA for multi-step routines; TDA for smooth control across variable latency
- Assumptions/Dependencies: affordable, safe dual-arm hardware; automatic stage discovery to reduce manual labeling; broader home datasets and safety certifications
- Deformable-object manipulation across textile manufacturing (cutting, sewing, packaging)
- Sectors: manufacturing, textiles
- Tools/Products/Workflows: stage-aware pipelines to segment multi-step textile tasks; MA to integrate policies from different production lines; TDA for consistent execution under variable speeds
- Assumptions/Dependencies: integration with machine vision and MES; high-precision end-effectors; rigorous safety and quality assurance standards
- Assistive healthcare robots for dressing and patient handling
- Sectors: healthcare, assistive tech
- Tools/Products/Workflows: SA for stage-aware progress in dressing sequences; MA to merge policies from different care settings; smooth control to minimize discomfort
- Assumptions/Dependencies: medical-grade hardware; extensive human-factors testing; regulatory approvals; privacy-compliant data collection; robust perception of human body pose
- Stage-aware surgical robotics and procedure automation
- Sectors: medical robotics
- Tools/Products/Workflows: SA as a stable progress signal for long procedures; MA to integrate surgeon/hospital-specific fine-tunes; TDA to reduce control latency artifacts
- Assumptions/Dependencies: micrometer-level precision; strict regulation and validation; specialized datasets; explainability and risk management
- Generalist warehouse manipulation (soft packages, bagged items, irregular objects)
- Sectors: logistics, warehousing
- Tools/Products/Workflows: MA across site-specific policies; SA for multi-step pick-place-scan-sort flows; TDA to handle conveyor timing and robot-to-robot handoffs
- Assumptions/Dependencies: robust perception for deformables; mixed hardware fleets; scheduling/safety orchestration
- Policy and standards development focused on deployment reliability (beyond success rate)
- Sectors: policy, standards bodies
- Tools/Products/Workflows: adoption of throughput/retry-cost/smoothness as deployment KPIs; guidelines for safe DAgger-style data collection; reporting protocols for 24-hour stress tests
- Assumptions/Dependencies: industry consensus and multi-stakeholder input; alignment with safety frameworks; auditing infrastructure
- Cloud “Policy Fusion” services for cross-task Model Arithmetic
- Sectors: AI platforms, software
- Tools/Products/Workflows: secure model-merging service that uses OOD validation to select weights; client-specific validation sets; compliance tooling for IP and data governance
- Assumptions/Dependencies: inter-org data/model sharing agreements; standardized model formats; robust OOD validation datasets
- Automated stage discovery and annotation tools
- Sectors: academia, ML software
- Tools/Products/Workflows: self-supervised or weakly supervised stage segmentation; active learning for stage labels; integration with SA training
- Assumptions/Dependencies: reliable temporal cues for segmentation; generalization across tasks/domains; collaboration for datasets and benchmarks
- Multi-robot orchestration for apparel processing lines
- Sectors: manufacturing, logistics
- Tools/Products/Workflows: coordinated dual-arm teams performing flattening, folding, sorting, hanging; SA-driven scheduling; TDA-informed action chunk synchronization across robots
- Assumptions/Dependencies: multi-robot scheduling frameworks; safe human-robot collaboration; standardized fixtures and flow
- Energy/resource-aware robotics operations
- Sectors: energy, sustainability, operations
- Tools/Products/Workflows: scheduling policies that trade off compute and training time (e.g., 20h demos + modest GPUs) against operational KPIs; continuous monitoring to minimize retries/idle energy
- Assumptions/Dependencies: enterprise telemetry and energy metering; optimization across fleet and shifts; policy retraining schedules
Notes on Assumptions and Dependencies Across Applications
- Hardware: dual-arm manipulators, reliable vision pipelines, safe fixtures, and controller access for action buffering.
- Data: limited but representative expert demonstrations; stage annotations or future stage-discovery tools; OOD validation sets (e.g., DAgger recovery trajectories).
- Compute: moderate GPU resources (e.g., 8×A100) for fine-tuning; scalable but resource-aware training recipes.
- Safety and Compliance: human-in-the-loop collection for DAgger, failure-state initialization procedures, domain-specific regulatory approvals (especially healthcare and surgical).
- Integration: ROS or vendor-specific controllers; logging and KPI dashboards for success rate, throughput, and retry cost; multi-robot coordination for collaborative tasks.
- Generalization: current results validated on deformable garments; extension to rigid-body tasks and broader domains may require additional research, data, and evaluation.
Glossary
- Advantage-weighted behavior cloning: An imitation learning approach that increases the influence of actions estimated to have higher advantage when training the policy. "providing stable, stage-aware reward signals for advantage-weighted behavior cloning~\cite{peng2019advantage}"
- Advantage-weighted regression (AWR): An offline reinforcement learning objective that biases regression toward actions with higher estimated advantage. "combining with advantage-weighted regression \cite{wu2023elastic, kuba2023advantage} to train policies with advantage-weighted training samples."
- DAgger: A data aggregation technique where a policy is iteratively improved by collecting expert corrections during rollouts. "DAgger-style aggregation~\cite{ross2011dagger, kelly2018hgdagger, hu2025rac, black2025pistar}"
- Distributional shift: A mismatch between training, model, and deployment data distributions that degrades performance. "the primary bottleneck to real-world robustness is not resource scale alone, but the distributional shift among the human demonstration distribution, the inductive bias learned by the policy, and the test-time execution distributionâa systematic inconsistency that causes compounding errors in multi-stage tasks."
- Failure Cascade: A phenomenon where small perturbations lead to unrecoverable errors due to missing recovery behaviors in training data. "(iii) Failure Cascade---absence of recovery behaviors in $P_{\text{train}$ leaves the policy unable to self-correct from perturbations in ."
- Flow-matching objective: A training objective used to fit diffusion or flow-based policies by matching data and model flows. "We employ full-parameter fine-tuning on 8A100 GPUs via a flow-matching objective~\cite{black2024pi0}."
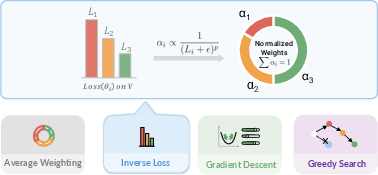
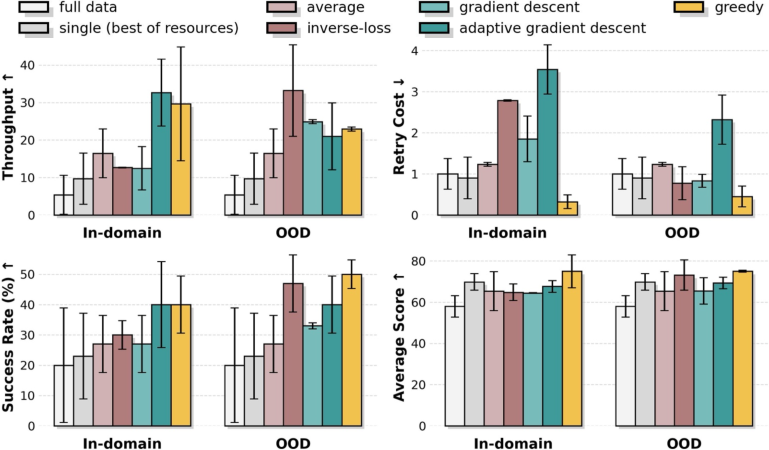
- Greedy search: An iterative merging strategy that adds model checkpoints if they most reduce validation loss under uniform averaging. "and Greedy search~\cite{wortsman2022model} (iteratively adding checkpoints that reduce validation loss most under uniform averaging among candidates)."
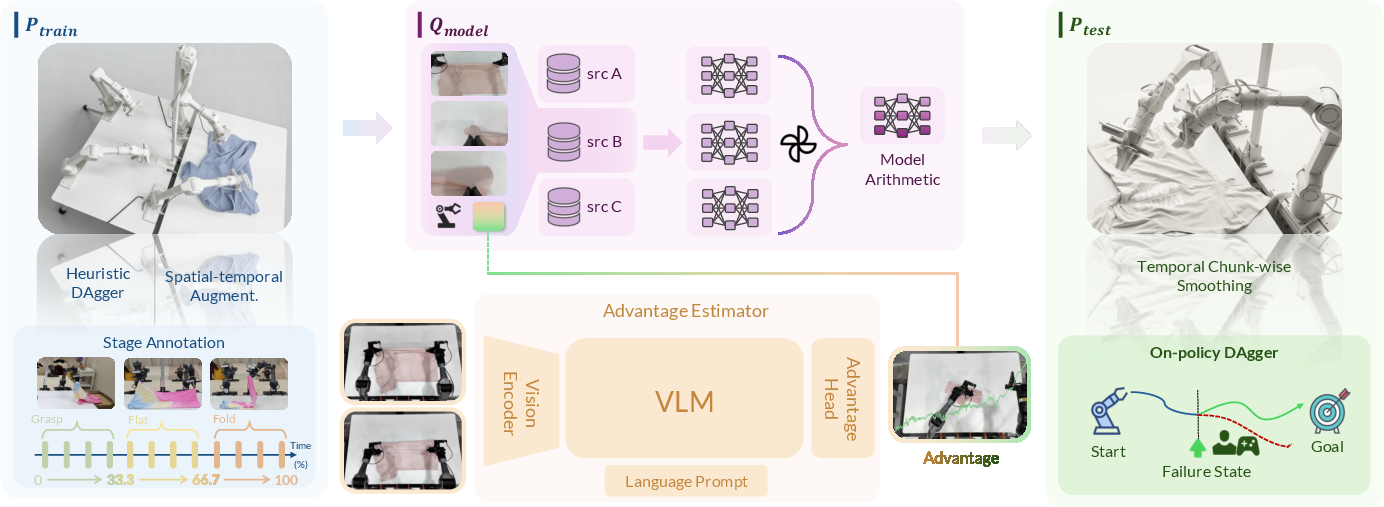
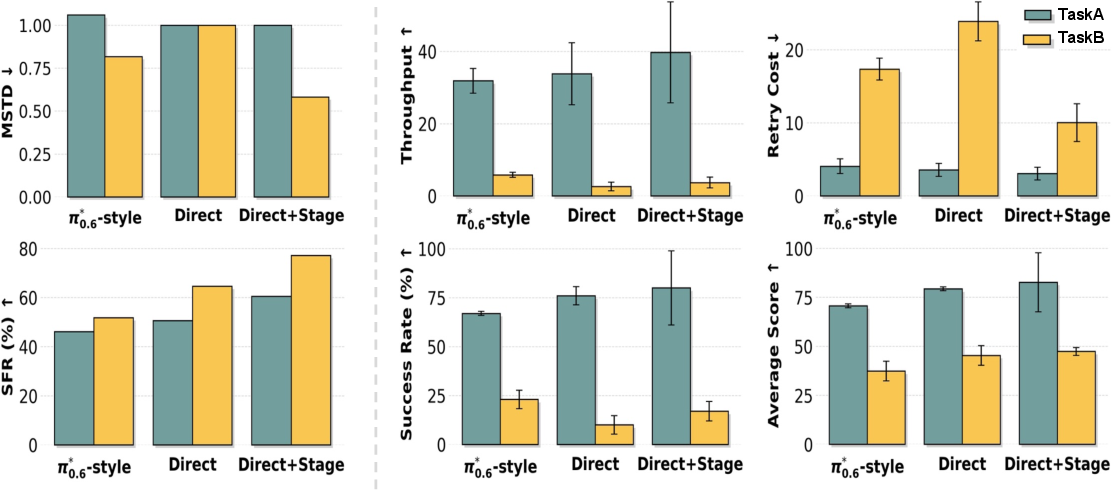
- Heuristic DAgger: A variant of DAgger that manually initializes failure states to collect targeted recovery demonstrations without waiting for natural failures. "We propose a Heuristic DAgger variant that directly initializes the system in manually designed failure states (e.g., misaligned grasps, partial drops) and collects recovery demonstrations, front-loading failure experience into data collection."
- Inductive bias: The model’s inherent assumptions or tendencies that shape how it generalizes from limited data. "the inductive bias learned by the policy"
- Inference-control latency: The delay between model output generation and physical action execution that can cause mismatches and instability. "inference-control latency causes mismatch between model outputs and physical execution."
- Inverse Loss (weighting): A model merging coefficient scheme that gives higher weight to checkpoints with lower validation loss. "Inverse Loss assigns higher coefficients to models with lower validation loss."
- Markov Decision Process (MDP): A formal framework for sequential decision-making with states, actions, transitions, and rewards. "we consider a finite-horizon Markov Decision Process (MDP)"
- Mixture-of-Experts (MoE): A neural architecture that routes inputs to specialized expert networks, often requiring a learned router. "Unlike Mixture-of-Experts (MoE), which requires explicit router mechanisms and complex training design~\cite{shazeer2017outrageously, fedus2022switch}"
- Model Arithmetic (MA): A weight-space merging technique that interpolates multiple policies to improve coverage and robustness. "Model Arithmetic merges complementary policies in weight space, guided by stage-aware advantage;"
- Model ensembling: Combining outputs of multiple models to improve robustness or accuracy. "or model ensembling that combines model outputs~\cite{lakshminarayanan2017simple}"
- Model merging: Integrating parameters from multiple trained models to consolidate knowledge and improve generalization. "Model merging has emerged as an efficient strategy for consolidating knowledge from multiple neural networks."
- On-policy DAgger: A DAgger variant where expert corrections are collected while the current policy is actively controlling the robot. "while on-policy DAgger enables closed-loop refinement."
- Out-of-Distribution (OOD): Data that differ from the training distribution and are used to assess generalization. "a novel validation protocol using OOD data---specifically recovery trajectories collected via DAgger---to ensure the merged policy generalizes to unseen states."
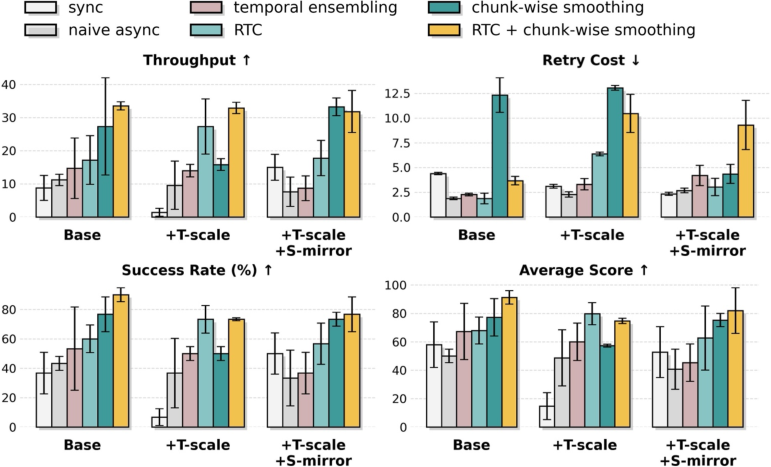
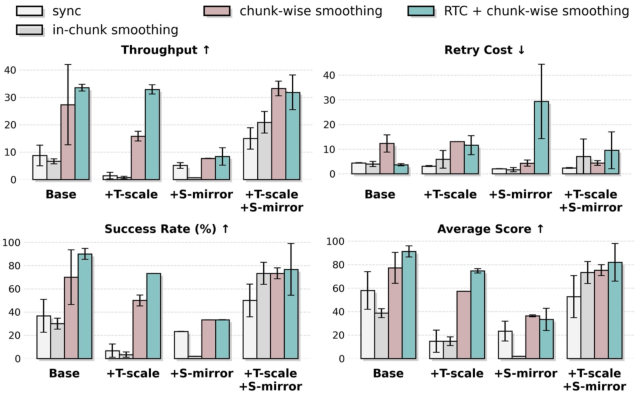
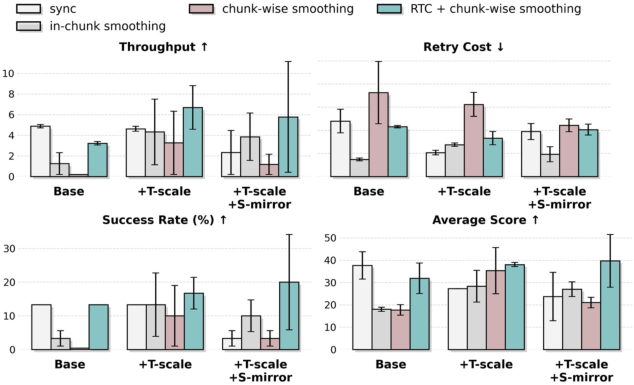
- Policy throughput: The rate at which a policy completes tasks per unit time during deployment. "surpassing RTC-only method~\cite{black2025rtc,tang2025vlash} in terms of policy throughput and retry cost."
- Retry Cost: The average number of action reattempts required per episode, reflecting efficiency and stability. "Retry Cost is the average number of action retries per episode during evaluation (lower is better)."
- RTC (real-time control method): A deployment-side optimization to mitigate latency and improve control stability. "surpassing RTC-only method~\cite{black2025rtc,tang2025vlash} in terms of policy throughput and retry cost."
- Spatio-temporal augmentation: Data augmentation that alters spatial and temporal aspects to expand coverage and improve robustness. "spatio-temporal augmentation is effective only when paired with control optimization"
- Stage Advantage (SA): A stage-aware advantage estimator that predicts relative progress within semantic sub-goals to guide training. "Stage Advantage (SA): To optimize action sampling () under the novel deployment environment (), SA decomposes long-horizon tasks into semantic sub-goals (referred as stages)"
- Temporal chunk-wise smoothing: A deployment technique that blends consecutive action chunks to reduce discontinuities from latency. "temporal chunk-wise smoothing to mitigate inference-actuation latency and enhance real-time control stability"
- Temporal ensembling: An inference strategy that aggregates predictions over time to stabilize outputs. "temporal ensembling~\cite{zhao2023aloha}"
- Temporal Mismatch: Misalignment of behaviors across visually similar but semantically distinct stages, compounded by latency. "(ii) Temporal Mismatch---long-horizon tasks induce visually similar but semantically distinct states across stages, causing $Q_{\text{model}$ to misapply temporal knowledge"
- T-SNE: A dimensionality reduction technique for visualizing high-dimensional data distributions. "T-SNE visualizations showing progressive distribution alignment as each strategy is applied."
- Trajectory distribution: The probability distribution over sequences of states and actions induced by a policy and environment dynamics. "Accordingly, the trajectory distribution induced by a stochastic policy could be defined as"
- Train-Deploy-Alignment (TDA): A framework component that aligns training and deployment distributions via augmentation and corrections. "Train-Deploy-Alignment (TDA): TDA expands toward via heuristic DAgger and spatio-temporal augmentation"
- Vision-Language-Action (VLA): Policies that map visual and language inputs to actions for robotic control. "RET AIN \cite{Yadav2025RobustFO} applies model merging to adapt VLA policies"
- Vision-LLM (VLM): Models that jointly process vision and language; here used as an advantage estimator. "we use a VLM-based architecture that takes pairwise image inputs as the advantage estimator"
- Weighted interpolation (model weights): Combining multiple model parameter sets with learned coefficients to form a merged model. "Policies trained on separate subsets are merged via weighted interpolation."
Collections
Sign up for free to add this paper to one or more collections.