- The paper introduces SemanticMoments, a training-free, backbone-agnostic method that aggregates mean, variance, and skewness over patch-wise features to capture motion similarity.
- It demonstrates superior performance on SimMotion-Synthetic and SimMotion-Real benchmarks by effectively disentangling motion dynamics from static appearance cues.
- By leveraging higher-order temporal moments, the approach establishes a new standard for perceptually aligned video retrieval and robust motion-centric analysis.
SemanticMoments: Training-Free Motion Similarity via Third Moment Features
Introduction and Motivation
The problem of representing and retrieving videos based on semantic motion has remained a central but underdeveloped topic in video analysis. While humans interpret motion as structured, high-level events unfolding over time, most computational approaches rely on features dominated by static appearance and scene context. Action-recognition datasets and prevailing objectives bias models toward extracting information that can be resolved from single frames—primarily object and background cues—rather than the actual temporal dynamics associated with perceptual motion, as illustrated by the prevalence of appearance cues sufficing for high-accuracy action classification.






Figure 1: Popular video retrieval benchmarks are dominated by appearance-centric cues, as static frames often suffice to distinguish actions, leading to representations that underutilize real motion dynamics.
Conventional alternatives, like optical flow, intend to capture frame-to-frame motion but fail to encompass high-level semantics necessary for precise motion understanding. To empirically demonstrate and address these representation biases, this work introduces two motion-centric benchmarks—SimMotion-Synthetic and SimMotion-Real—and proposes a conceptually simple yet effective method, SemanticMoments, for encoding motion via higher-order temporal statistics over pretrained semantic feature spaces.
SimMotion Benchmarks: Rigorous Evaluation of Motion Similarity
SimMotion-Synthetic
The SimMotion-Synthetic benchmark is constructed to diagnose the motion-invariance of representations under systematic, controlled changes. Each video triplet consists of:
- A reference video,
- A positive with the same motion but varying one visual factor (static/dynamic object, appearance, style, or view),
- A hard negative sharing appearance but with different motion.
These systematic factor isolations are essential to disentangle motion from confounding visual properties.


Figure 2: SimMotion-Synthetic visualizes controlled factor variations, ensuring only motion dynamics remain unchanged between reference and positive videos.
Synthetic data is generated with large-scale image-to-video models, leveraging synchronized prompts to guarantee motion consistency, and with negative samples enforcing strong appearance similarity but motion dissimilarity. This detailed curation enables examination of representation sensitivity to individual nuisance factors in isolation.
SimMotion-Real
A complementary real-world set, SimMotion-Real, is built around human-annotated motion similarity, with positive examples retrieved and ranked by crowd annotators for perceptual motion similarity, independent from appearance or background. Negatives are sourced from nearby frames in the same source video to be visually confusing. This allows evaluation of model robustness and generalization in unconstrained, naturally occurring scenarios, where factors like camera motion, occlusion, and diverse execution styles greatly increase task difficulty.
Analysis: Motion Versus Appearance Bias in Video Representations
Prior self-supervised and multimodal video encoders are evaluated on these benchmarks, revealing that they predominantly produce features sensitive to appearance changes, failing to cluster instances purely based on underlying motion when appearance is manipulated. For instance, mean-pooled features (i.e., first-order moments) cannot reliably distinguish motion-preserving transformations, yielding embedding similarities largely based on visual style or background.












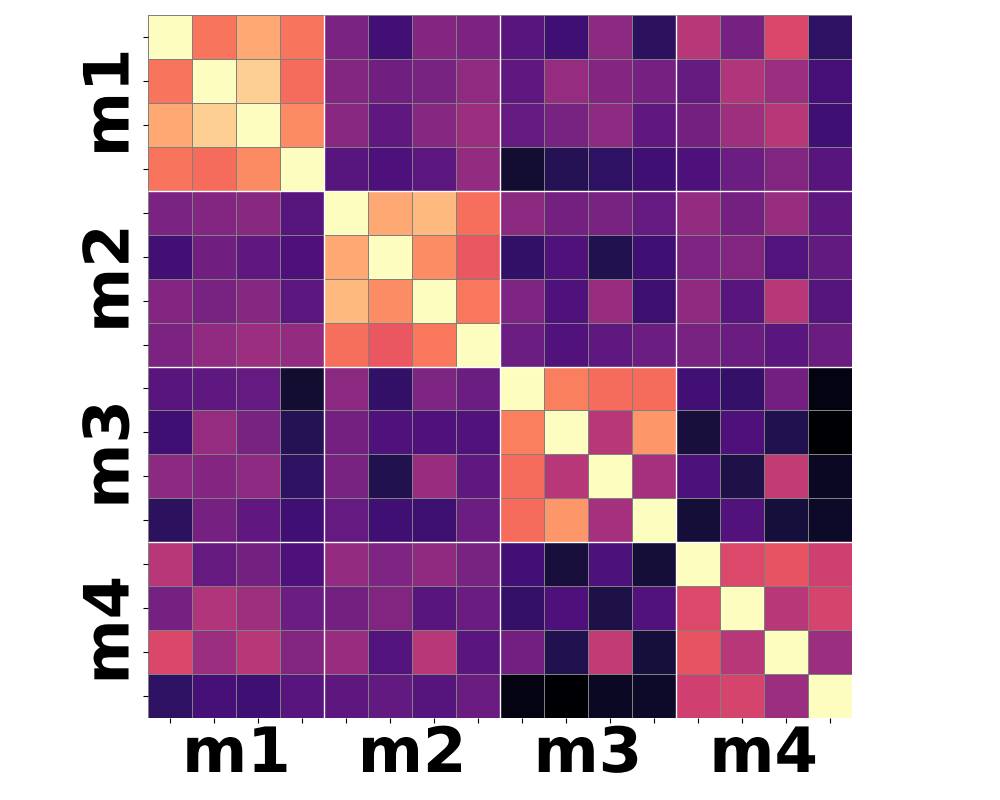
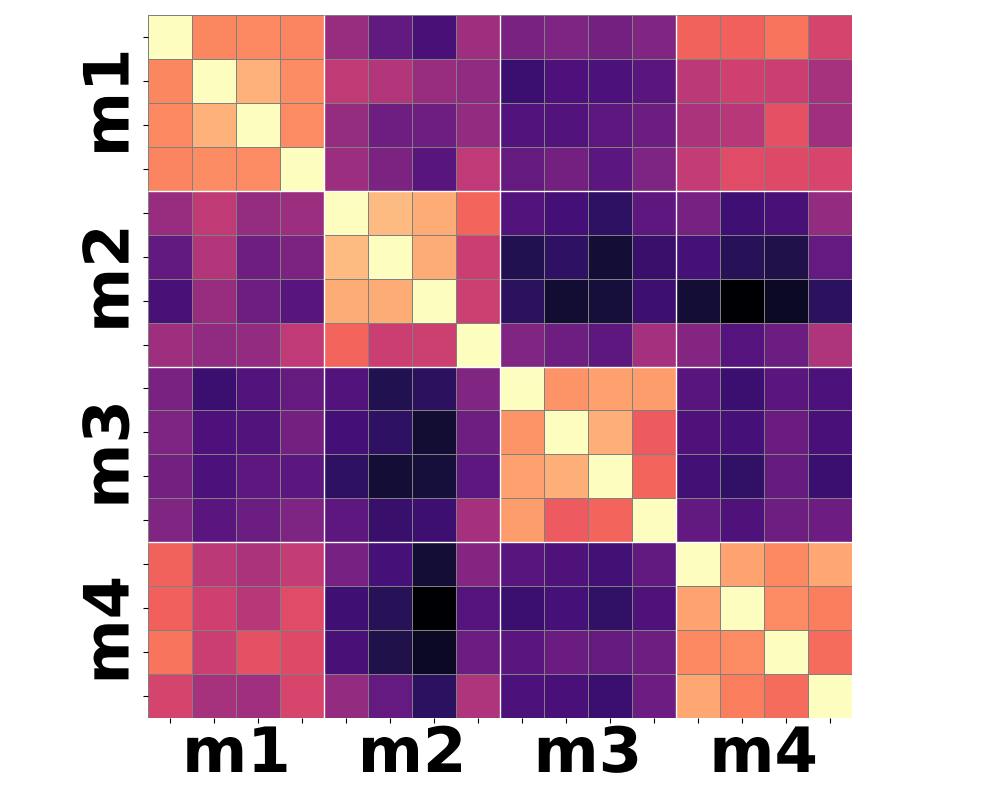
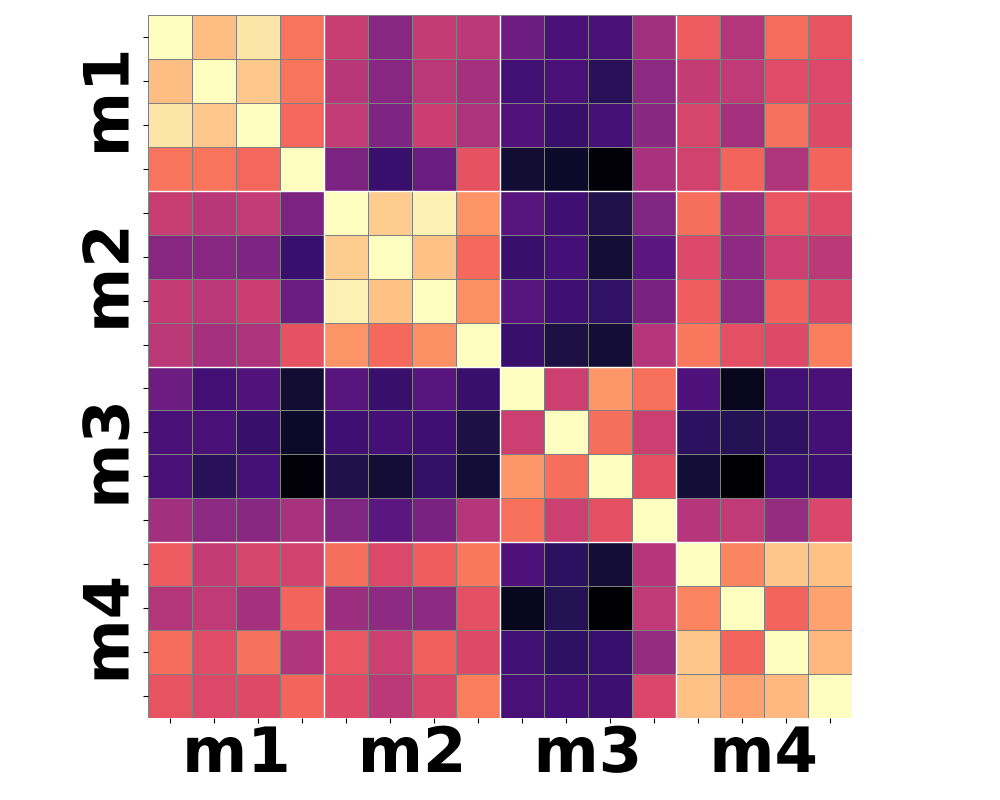
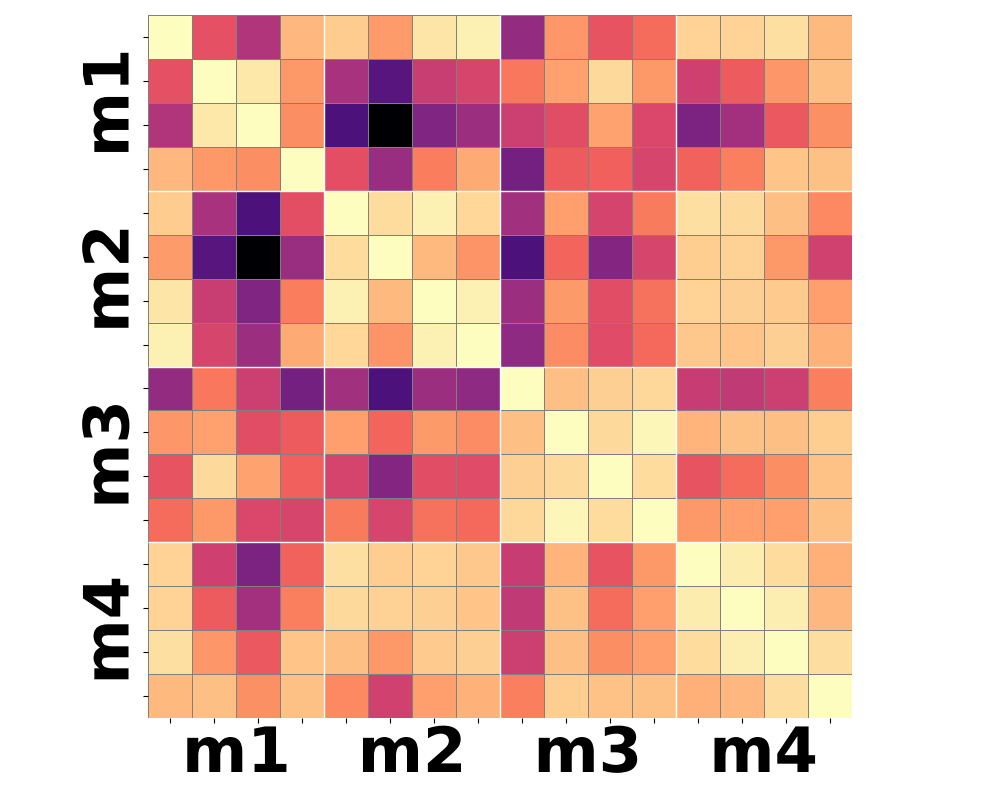
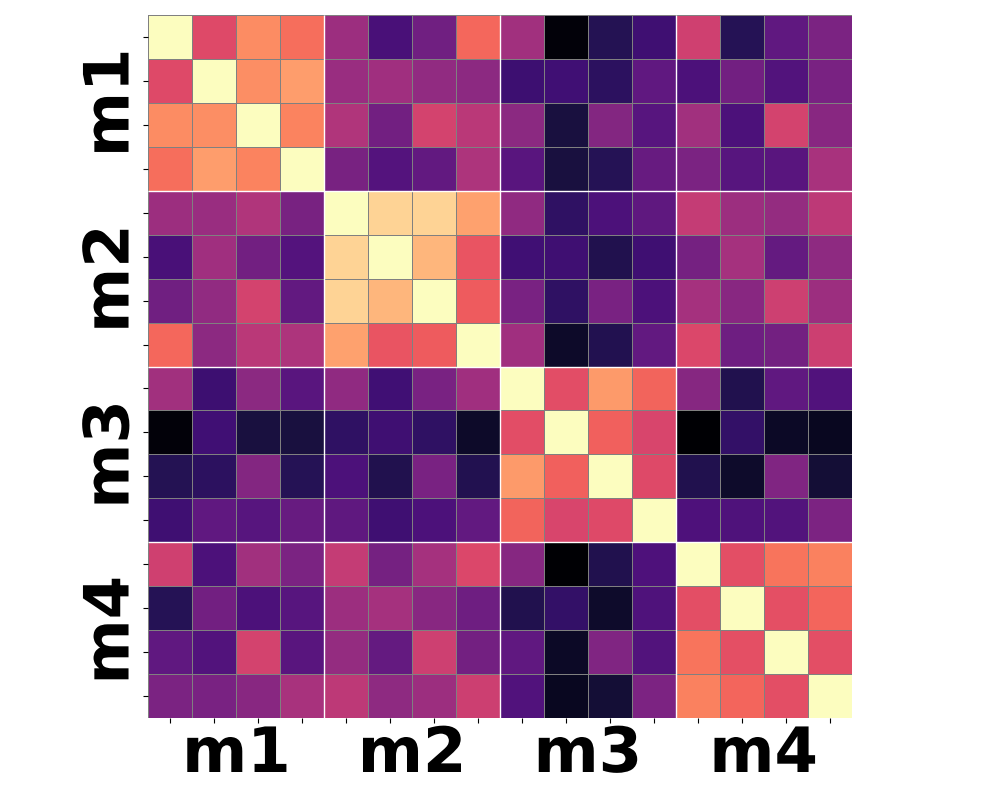
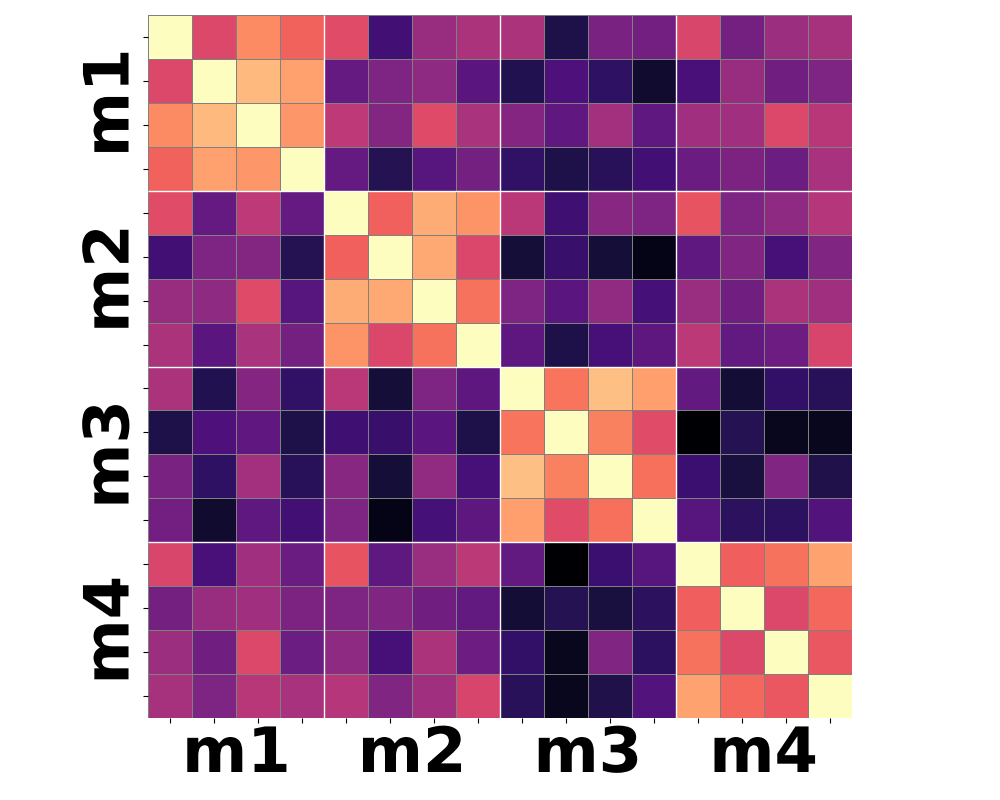
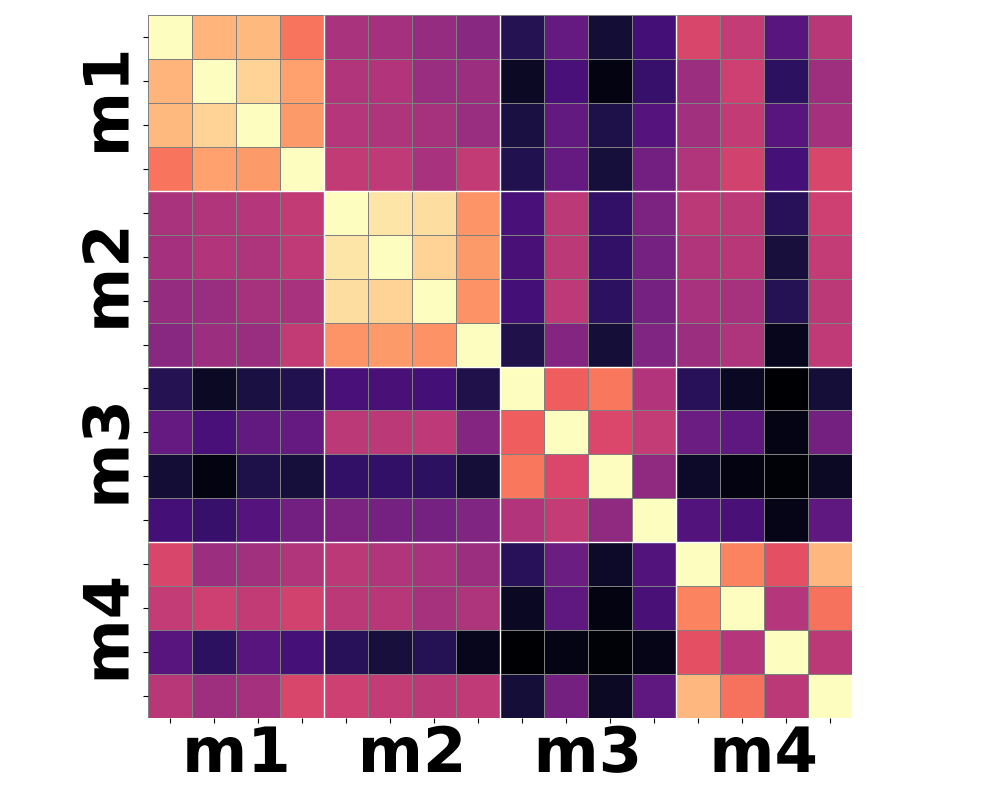
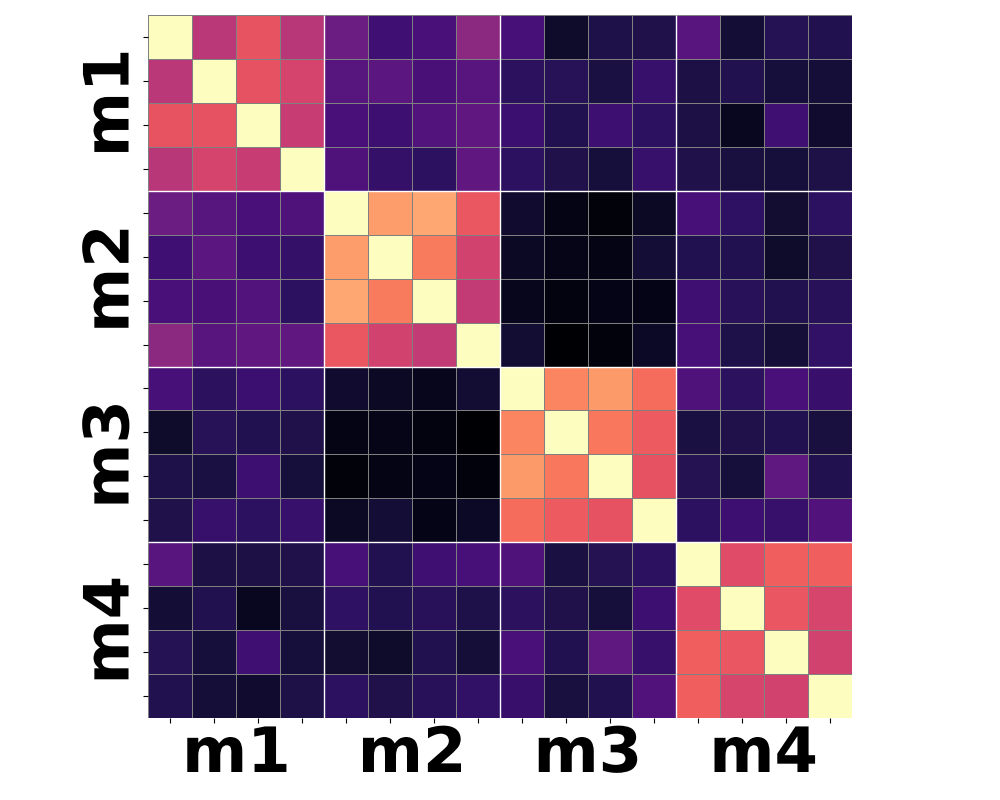
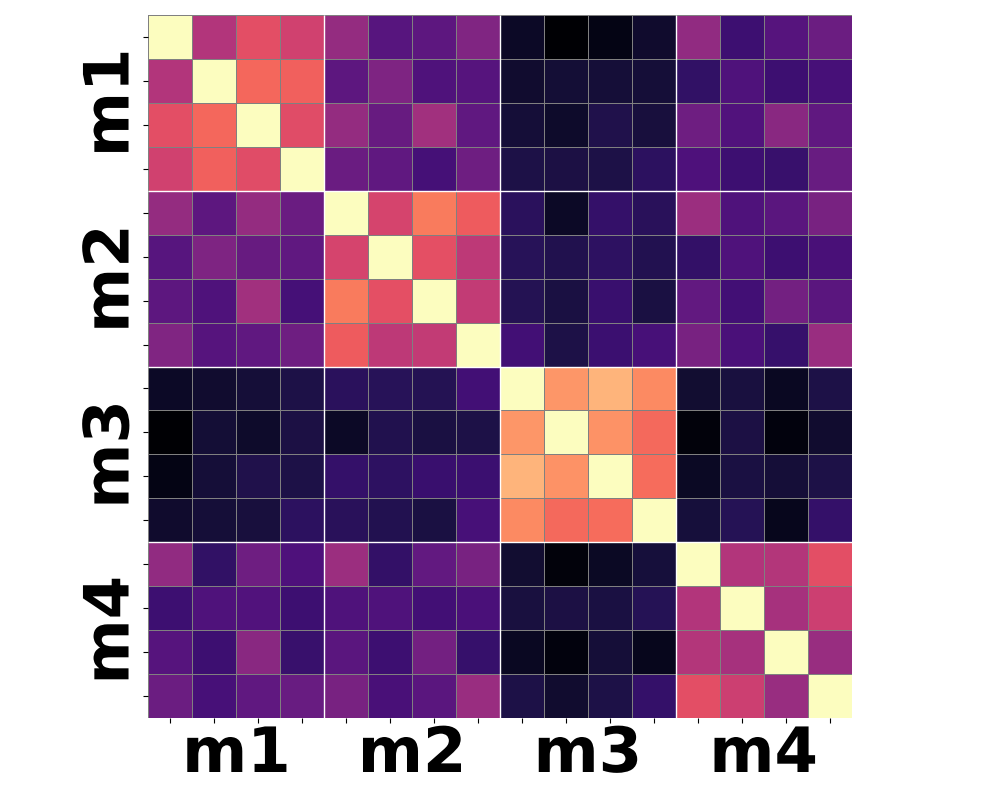
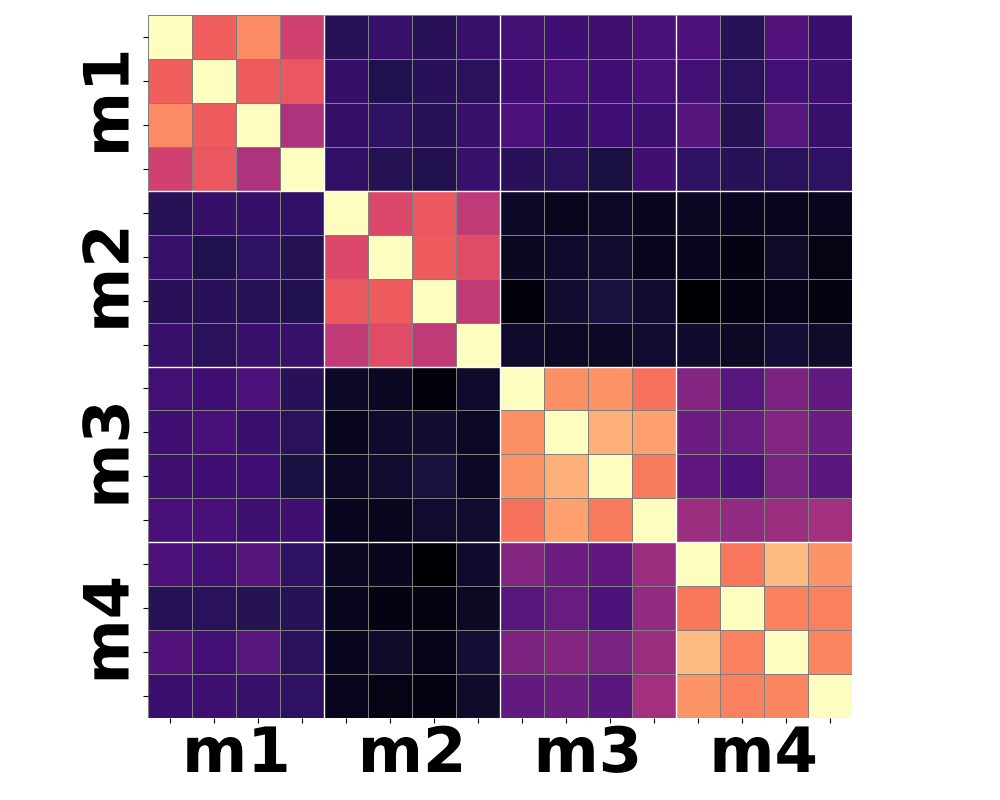
Figure 3: Moment-based statistics over patch-wise semantic features yield improved clustering according to shared motion compared to conventional mean-pooling approaches.
Qualitative analysis of heatmaps from various encoder baselines underscores the inherent limitations. Only by summarizing the higher-order temporal moments—notably variance and skewness—can feature trajectories begin to align with actual motion categories.
The SemanticMoments Approach
SemanticMoments extends traditional pooling strategies by aggregating temporal statistics at the level of patch-wise features extracted from image or video backbones, such as DINOv2, VideoMAE, and VideoPrism. Instead of compressing temporal information into a single global vector, it concatenates the first three moments (mean, variance, skewness) computed over each patch trajectory in feature space:
μp(1)=T1t=1∑Tft,p,μp(2)=T1t=1∑T(ft,p−μp(1))2,μp(3)=T1t=1∑T(ft,p−μp(1))3
These are then aggregated spatially and concatenated to form a descriptor encoding mean appearance, the energy of change, and directional asymmetry, respectively.
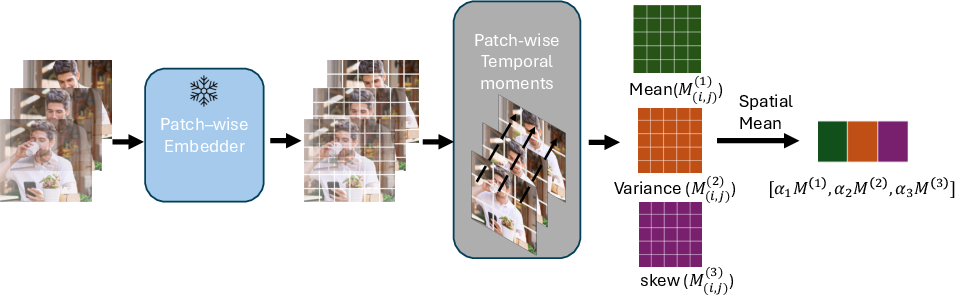
Figure 4: SemanticMoments pipeline: Patch-wise semantic features are temporally summarized using mean, variance, and skewness, then spatially aggregated and concatenated, yielding a global motion-centric embedding.
Importantly, this method operates entirely training-free and is agnostic to the underlying backbone encoder, incurring negligible extra computation and readily scaling to large collections.
Experimental Results
Synthetic Benchmark
On SimMotion-Synthetic, SemanticMoments demonstrates consistent improvements over state-of-the-art models across all categories, being especially robust in cases where appearance or viewpoint is changed but motion remains identical. Notably, for categories such as "Dynamic Object" and "View", where other models (including those using optical flow) degrade substantially, SemanticMoments maintains high accuracy due to its semantics-aware temporal summarization.
Real-World Motion Similarity
In SimMotion-Real, the method achieves a dramatic improvement in retrieval accuracy over diverse baselines, including CLIP-based, RGB-supervised, and flow-based models, and is notably more robust to complex, unconstrained variations typical of real-world settings.
Robustness to Appearance and Semantic Bias
Qualitative examples highlight the failure of traditional models when motion is decoupled from appearance. Baselines tend to retrieve visually similar but dynamically unrelated videos, whereas SemanticMoments identifies clips sharing motion regardless of substantial changes in subject identity or background.




Figure 5: In comparatives, SemanticMoments retrieves true motion similarity despite large differences in object or scene appearance, outperforming both VideoPrism and VideoMAE which are dominated by static cues.
Gesture Recognition and Ablations
Applying the method to gesture recognition datasets, SemanticMoments consistently leads to improvements in kNN-based accuracy, suggesting richer intra-class clustering for fine motion patterns. Ablation experiments systematically confirm that higher-order temporal moments and patch-level granularity are critical for achieving superior motion discrimination.
Implications and Future Work
SemanticMoments exposes fundamental weaknesses in existing video representation paradigms and provides a practical, scalable method for motion-centric retrieval and analysis. The method's backbone-agnostic, training-free construction allows immediate integration with emerging semantic feature extractors, suggesting direct applicability to large-scale video search and motion-driven generative modeling.
Practically, enhanced motion discrimination could benefit:
- Video content search engines,
- Video recommendation and deduplication,
- Controllable video synthesis and editing (e.g., motion transfer),
- Fine-grained motion analysis in behavioral or surveillance studies.
Theoretically, this work advocates for moment-based video descriptors as an attractive direction for bridging the gap between static representation learning and true spatiotemporal reasoning. Advances in generalized, video-native backbone architectures are expected to further elevate the effectiveness of SemanticMoments and similar strategies.
Current limitations revolve around subtle or long-range dynamics, multi-agent interactions, and edge cases (e.g., absence of motion) where training-free methods struggle. Extending this approach with trainable moment selection, learnable weighting, and integration with temporal attention mechanisms offers promising research trajectories.
Conclusion
SemanticMoments establishes a new framework for motion-centric video similarity, exposing and mitigating existing biases in modern video encoders. Empirical evaluations on rigorously designed synthetic and real-world benchmarks demonstrate that temporal moments over semantic features enable accurate, training-free, and backbone-agnostic motion retrieval, marking a foundational step towards perceptually aligned, motion-aware video understanding (2602.09146).