The Entropic Signature of Class Speciation in Diffusion Models
Abstract: Diffusion models do not recover semantic structure uniformly over time. Instead, samples transition from semantic ambiguity to class commitment within a narrow regime. Recent theoretical work attributes this transition to dynamical instabilities along class-separating directions, but practical methods to detect and exploit these windows in trained models are still limited. We show that tracking the class-conditional entropy of a latent semantic variable given the noisy state provides a reliable signature of these transition regimes. By restricting the entropy to semantic partitions, the entropy can furthermore resolve semantic decisions at different levels of abstraction. We analyze this behavior in high-dimensional Gaussian mixture models and show that the entropy rate concentrates on the same logarithmic time scale as the speciation symmetry-breaking instability previously identified in variance-preserving diffusion. We validate our method on EDM2-XS and Stable Diffusion 1.5, where class-conditional entropy consistently isolates the noise regimes critical for semantic structure formation. Finally, we use our framework to quantify how guidance redistributes semantic information over time. Together, these results connect information-theoretic and statistical physics perspectives on diffusion and provide a principled basis for time-localized control.




Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper studies when and how diffusion models “make up their minds” about what they are generating. The authors show that a simple information measure—class-conditional entropy, which means “how unsure the model is about the class or meaning of what it’s making”—gives a clear signal of the short time window when the model switches from being confused to being confident about the content. They connect this to ideas from physics (like phase transitions) and show how to measure and use this signal in real image generators such as EDM2 and Stable Diffusion.
What questions does the paper ask?
- When, during the denoising steps of a diffusion model, does the model decide the main “semantic” content (like the class of an ImageNet image or a key attribute in a prompt)?
- Can we track this decision time reliably in real, trained models?
- How does guidance (extra steering toward a label or prompt) change where and when these decisions happen?
How did the researchers study it?
They use two complementary approaches:
- Theory with a simple thought experiment: They model data as a mixture of Gaussian blobs (think of well-separated clouds of points, one per class) and use a standard diffusion process that adds noise going forward and removes it going backward. In this setup, they can compute how uncertainty about the class changes over time.
- Practice with real models: They estimate class-conditional entropy along the actual denoising trajectory of trained models (EDM2-XS on ImageNet and Stable Diffusion 1.5 for text-to-image) using an online “posterior tracking” method. In plain terms, they compare how the conditional model (with a label or prompt) and the unconditional model (no label) reconstruct the image at each step, and from that infer “how sure” the model is about the class or attribute.
Key ideas explained in everyday language:
- Diffusion model: Imagine starting with a clear picture, then gradually adding fog (noise) until it’s just static. Generation reverses this: it starts with static and carefully removes fog to reveal a picture.
- Entropy: A measure of uncertainty. High entropy = very unsure; low entropy = confident.
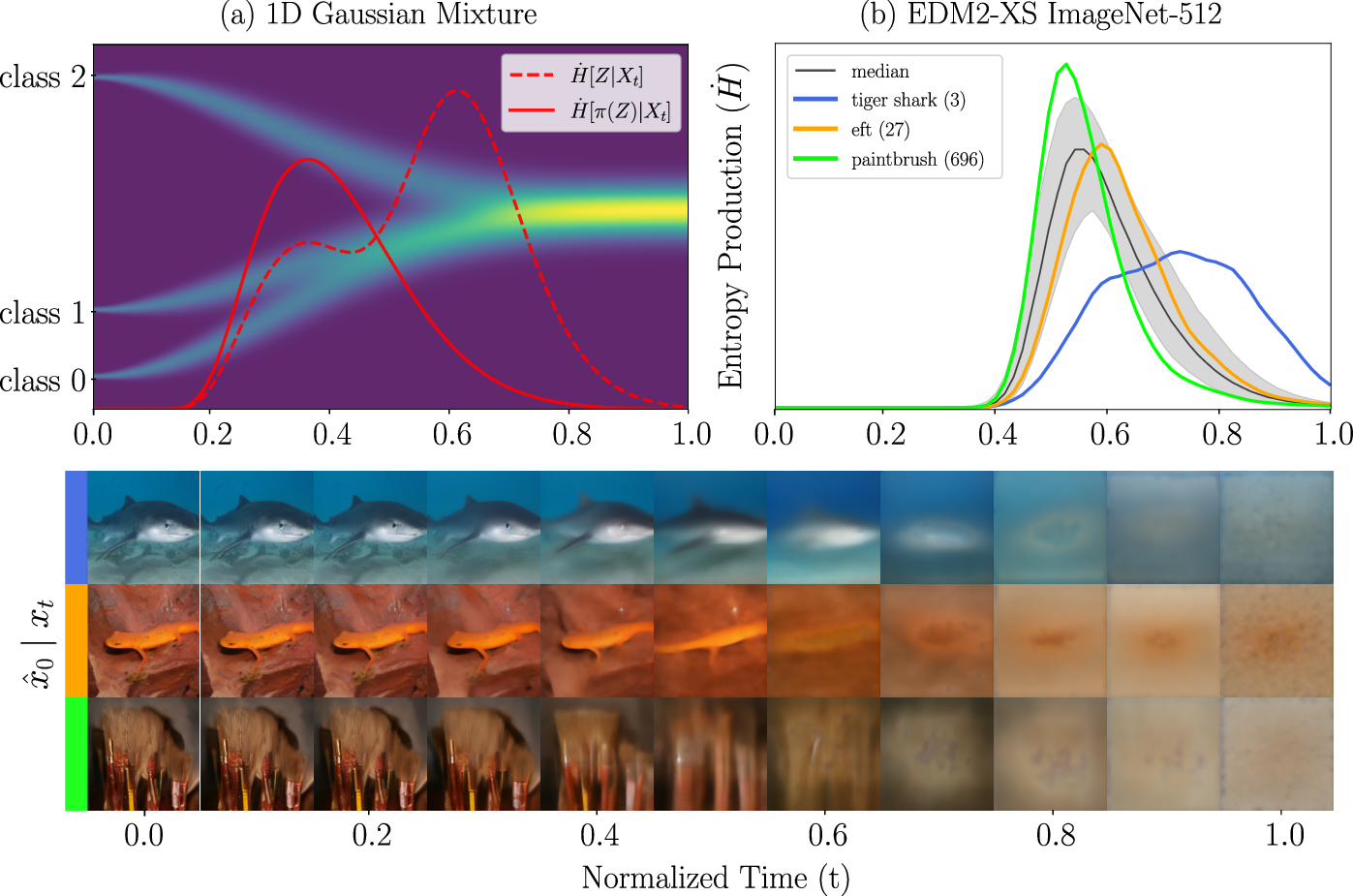
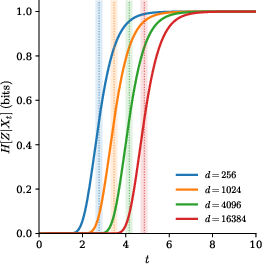
- Class-conditional entropy H[Z | X_t]: “How many questions are left about the class Z, given the current noisy image X_t?” Tracking this over time shows when uncertainty drops.
- Entropy production: How fast uncertainty is changing at a moment in time. A spike means “the model is deciding now.”
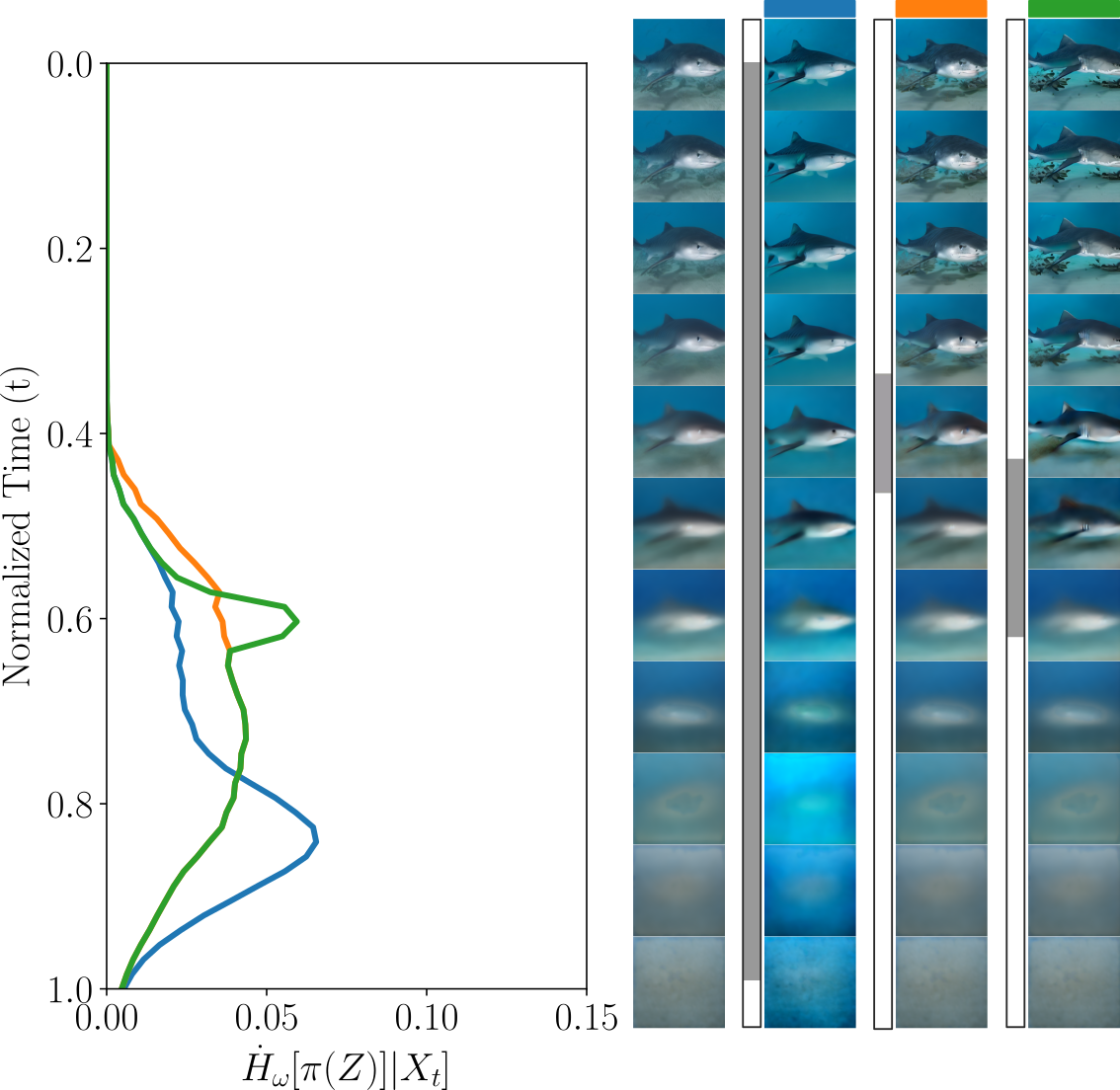
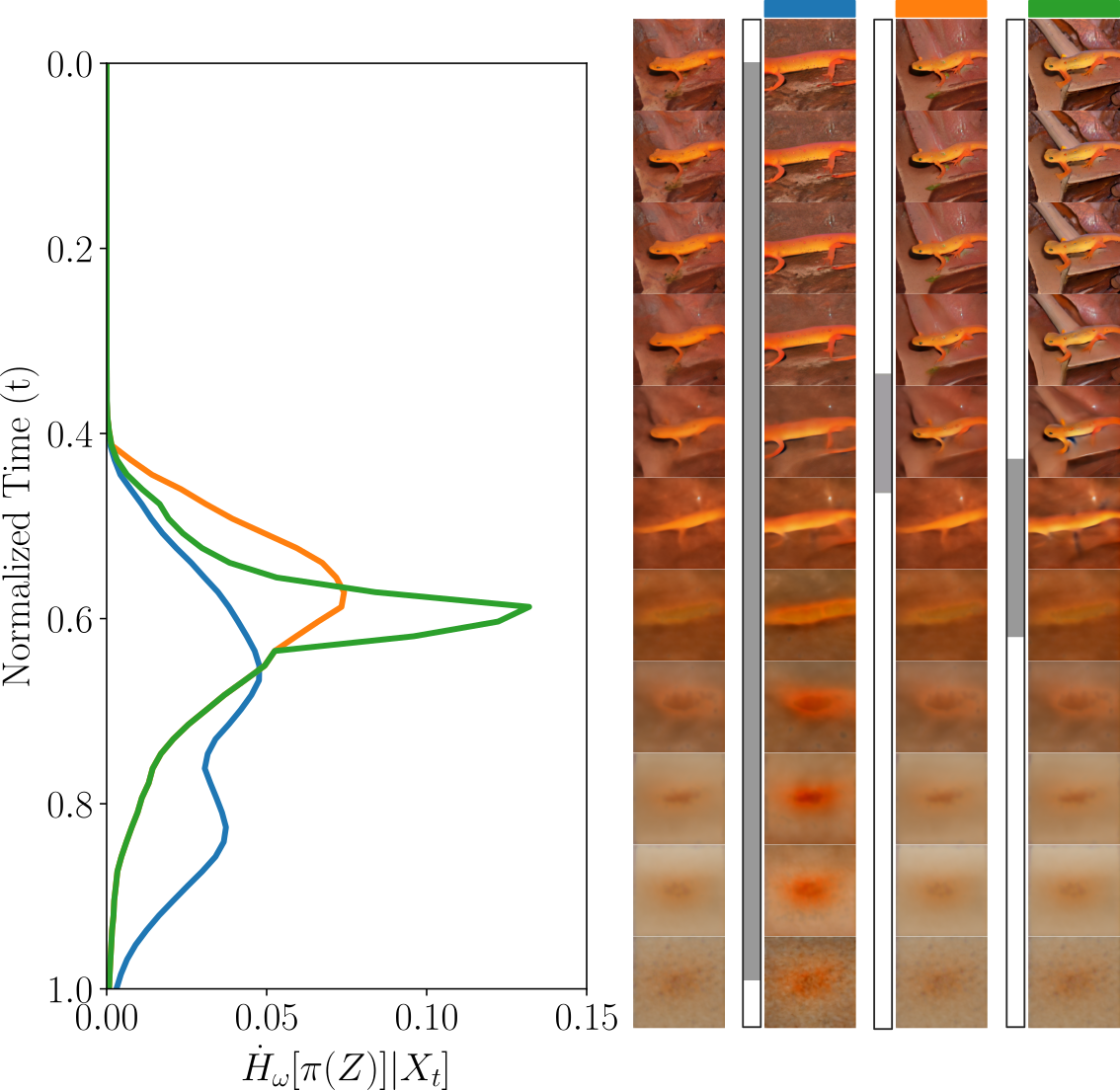
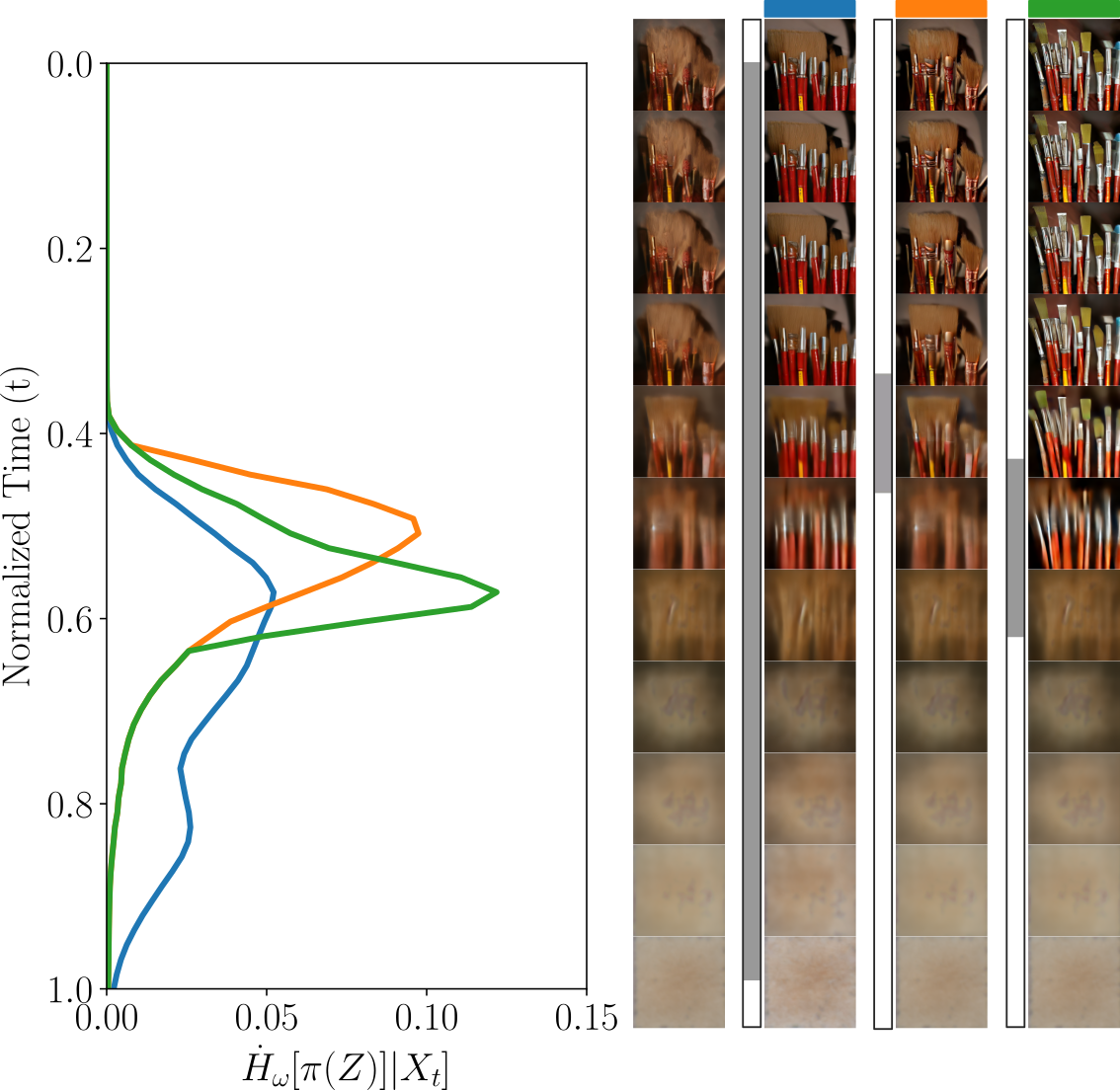
- Partitioned entropy: Instead of asking “Which of 1,000 classes is it?” you can focus on a simpler question, like “Is it a tiger shark or not?” This zooms in on a specific decision and shows when that particular choice gets resolved.
- Guidance: Extra steering that makes the model follow a label or text prompt more strongly. It can shift when decisions happen—earlier or later in the denoising process.
What did they find?
Here are the main results:
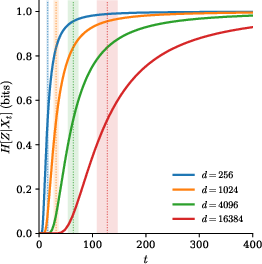
- There is a narrow “decision window”: The model stays semantically ambiguous for a while and then, in a short time window, commits to a class or attribute. In the theory setup, this window lines up with a predicted “speciation time” from physics (a symmetry-breaking transition), meaning the math and the real behavior agree.
- The timing depends on what you’re deciding:
- Coarse, low-frequency features (like overall color or big shapes) get decided earlier at higher noise levels.
- Fine, high-frequency details (like small objects or textures) get decided later when the image is less noisy.
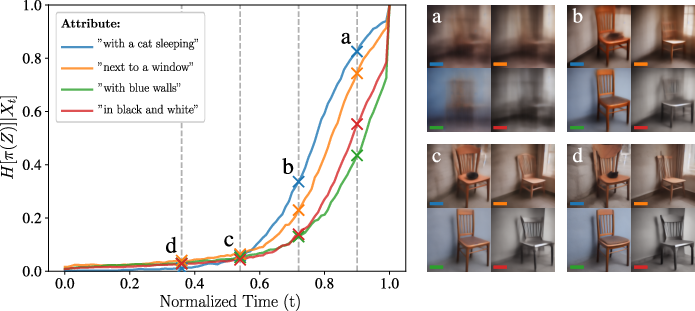
- Partitioned entropy lets you isolate exactly which decision (e.g., “blue walls” vs “has a cat”) is being made when.
- Real models show the same pattern:
- On ImageNet with EDM2-XS, class-conditional entropy pinpoints the noise range where each class’s features emerge. Different classes peak at slightly different times, but all peaks sit in a fairly tight band.
- In Stable Diffusion 1.5, prompt variants like “a wooden chair with blue walls” vs “a wooden chair” show early entropy drops for global color (blue walls), while “with a cat” resolves later. The pictures’ intermediate “previews” match the entropy curves: global color appears early, small objects appear later.
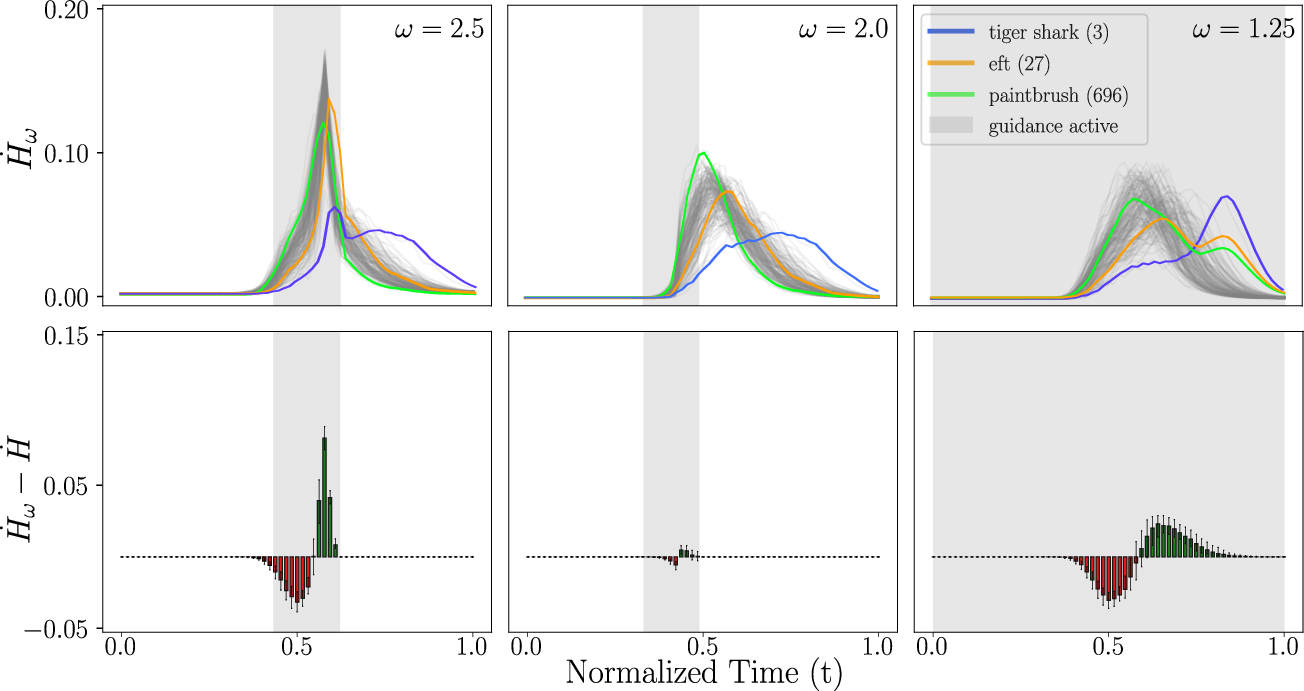
- Guidance redistributes information over time:
- Applying guidance in an optimal short interval causes the model to make semantic decisions earlier (a leftward shift of the entropy-production peak).
- Applying guidance later mostly helps refine details rather than changing big-picture semantics.
- Applying guidance all the way through pushes decisions earlier but can spread changes more uniformly, affecting how and when structure appears.
Why is this important?
- Better control: Knowing when decisions happen lets you apply guidance at the right time, improving quality and faithfulness to labels or prompts without overdoing it.
- Smarter schedules: You can design time steps or “denoising budgets” so that each step contributes useful information, potentially speeding up sampling.
- Interpretability: Partitioned entropy is a clear, operational signal to see what the model has decided so far and what remains undecided.
- Theory-practice bridge: The same transition time predicted by physics shows up as a clear entropy signature in real systems. This makes advanced theory actionable for building and steering diffusion models.
Key terms (simple definitions)
- Semantic structure: The meaningful content in an image (class, objects, attributes).
- Speciation (symmetry breaking): The moment the model stops being undecided and picks a side (like choosing a class).
- Noise regime: How blurry the current state is—early steps are very noisy, late steps are cleaner.
- Guidance interval: The time window where you apply extra steering toward a label or prompt.
Final takeaway
By measuring “how unsure” the model is about semantics as it denoises, we get a precise, practical marker for when the model decides what it’s making. This helps us analyze, time, and improve guidance, and connects deep ideas from information theory and physics to real, everyday use of diffusion models.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of what remains missing, uncertain, or unexplored in the paper and could guide follow-up research.
- Theory beyond simplified priors: Extend the analysis from equiprobable, equal-covariance Gaussian mixtures to more realistic priors (non-Gaussian, manifold-structured data, unequal covariances, class imbalance) and assess whether the speciation scaling and entropy dynamics persist.
- Finite-dimensional, non-asymptotic guarantees: Derive finite- bounds (or non-asymptotic rates) for the localization of entropy production and for the proximity between speciation time and the entropy peak location in practical settings.
- General SDEs and solvers: Provide theoretical results for broader forward processes (beyond VP and EDM/VE) and common reverse-time solvers (DDIM, Heun, predictor–corrector, rectified flows), including how discretization error affects the estimated and its derivative.
- VE/EDM regime significance: The paper notes that VE/EDM lacks sharp localization on a rescaled time axis but leaves its practical consequences unclear; determine how this affects scheduler design, guidance timing, and control policies in EDM-like models.
- Robustness under approximate scores: The derivation linking entropy production to Fisher divergence assumes exact (or well-approximated) scores; characterize how approximation error in trained denoisers biases and its temporal derivative, and provide error bounds.
- Estimator bias/variance: Quantify the statistical properties (bias, variance, confidence intervals) of the online posterior-tracking estimator for and partitioned entropies, including sensitivity to the number of trajectories, step size, and stochastic solver noise.
- Proxy for class complement: Using the unconditional model as a proxy for “class complement” can be biased; evaluate alternatives (e.g., learned one-vs-rest conditional models, calibrated discriminators, mixtures of other classes) and quantify the impact on entropy profiles.
- Calibration dependency: The estimator assumes calibration across noise levels for conditional and unconditional predictions; develop calibration procedures or correction methods and measure how miscalibration propagates into posterior updates and entropy estimates.
- Ground-truth validation: On synthetic datasets where is known (e.g., controlled Gaussian mixtures), validate the estimator by comparing estimated and true over time and across solvers/schedules.
- Hierarchical branching detection: While partitioned entropies can isolate distinctions, the paper does not provide an automatic method to discover semantic partitions/axes; develop procedures (e.g., unsupervised clustering of posterior ratios, classifier probes, or feature detectors) to identify and time-stamp branching events.
- Multi-branch interactions: Analyze how overlapping or interacting semantic decisions (multiple attributes resolving concurrently) shape the aggregate entropy curve and how to disentangle them using partitioned measures.
- Continuous/structured conditions: Generalize beyond discrete to continuous or high-dimensional conditions (e.g., text embeddings), including how to define and estimate or targeted attribute entropies without relying on manually constructed binary partitions.
- Guidance–entropy theory: Formalize how guidance scale, interval, and type (classifier-free vs classifier-based) control the magnitude and timing of entropy production (e.g., closed-form relationships, sensitivity analysis, or control-theoretic formulations).
- Entropy-driven control: Develop and test algorithms that use online entropy signals to choose per-sample guidance scales, guidance intervals, step sizes, or early stopping; quantify gains in FID, CLIP/DINO alignment, or reconstruction metrics.
- Scheduler design implications: Translate entropy localization into practical scheduler designs (e.g., non-uniform step allocation, adaptive noise schedules) and empirically test whether such schedulers improve quality/alignment or sampling efficiency.
- Cross-architecture and modality generalization: Evaluate whether the entropy signatures and derived insights hold across different model families (U-Nets vs transformers), modalities (audio, video), and latent vs pixel-space diffusion.
- Model scale and alignment: Current text-to-image results are limited by Stable Diffusion 1.5; replicate with stronger, better-aligned models (e.g., SDXL, SD3) to test attribute-level entropy profiles and their correlation with emergent semantics.
- Metric connections: Quantify how entropy peak location/area correlates with downstream metrics (FID, FD, CLIP score) and with human-perceived semantic fidelity; investigate whether entropy can predict optimal guidance intervals across classes/prompts.
- Sensitivity to discretization: Study the effect of the number of sampling steps, step distribution over , and solver choice on entropy profiles; determine minimal step budgets needed to resolve specific semantics.
- OOD and prompt pathology: Assess robustness of entropy tracking to out-of-distribution classes/prompts and ambiguous or conflicting instructions; characterize failure modes and propose robust estimation variants.
- Computational overhead: Report the runtime/memory cost of online posterior tracking in large-scale models and explore approximations (e.g., lower-precision updates, subsampling of steps, surrogate scores) that retain fidelity while reducing overhead.
- Attribute-level ground truth: For text-conditioned models, create or leverage benchmarks with labeled semantic attributes (e.g., presence/absence of objects, styles) to quantitatively verify that partitioned entropy collapse aligns with attribute emergence.
- Mutual-information perspective: Since , investigate whether mutual information trajectories offer complementary diagnostics (e.g., robustness to calibration errors), and how they relate to score norms and likelihood estimates over time.
- Link to training objectives: Explore whether training-time losses or curricula that explicitly shape the temporal distribution of semantic information (e.g., entropy-regularized schedulers) improve controllability and reduce reliance on heavy guidance.
Practical Applications
Immediate Applications
The following applications can be deployed now by leveraging class-conditional entropy and partitioned entropy as time-localized diagnostics during diffusion sampling, together with the provided online posterior-tracking estimator.
- Dynamic, interval-limited guidance scheduling — software/media, creative tools
- What: Automatically detect the “speciation window” (entropy peak) and restrict/scale classifier-free guidance to that interval to boost semantic fidelity without over-distortion.
- How: Monitor the temporal derivative of HZ|X_t during sampling; ramp guidance up near the peak and down elsewhere.
- Tools/workflows: “Entropy-aware guidance controller” plug-in for Stable Diffusion toolchains (e.g., Automatic1111, ComfyUI), EDM2 pipelines; dashboards showing entropy profiles per prompt/class.
- Assumptions/dependencies: Access to conditional and unconditional denoisers or a proxy; calibrated noise/data predictions; slight runtime overhead for Monte Carlo estimates.
- Time-step budgeting and sampler acceleration — software/infrastructure
- What: Allocate more solver steps where entropy production is high and fewer steps where it is negligible to reduce latency while preserving semantic quality.
- How: Use entropy rate as an online “information gain” signal to adapt step size and total steps per trajectory.
- Tools/workflows: Entropy-informed schedulers; integration with DDIM/ODE solvers; per-prompt budget plans.
- Assumptions/dependencies: Accurate online entropy estimation; compatibility with chosen sampler; stability with adaptive steps.
- Attribute-aware, time-localized editing and prompt mixing — creative tools, advertising, design
- What: Inject or modify guidance only at the noise scales where specific attributes (e.g., color vs. object presence) commit, improving controllability and reducing artifacts.
- How: Use partitioned entropy on binary prompt variants (e.g., “+ blue walls” vs. base) to identify when those attributes emerge; apply localized edits/guidance then.
- Tools/workflows: Attribute-timing maps; “edit at the right time” operators for image-to-image and inpainting pipelines.
- Assumptions/dependencies: Clear attribute partitions; availability of prompt variants or attribute detectors; calibrated models.
- Real-time alignment and quality diagnostics during generation — AIGC platforms, MLOps
- What: Detect misalignment or prompt under-conditioning by checking whether entropy collapses in the expected window; trigger fallback strategies (e.g., increase guidance or prompt reformulation).
- How: Compare observed entropy profile to class/prompt baselines; set thresholds for anomaly detection.
- Tools/workflows: Entropy monitors in inference services; alerting for drift or degraded alignment.
- Assumptions/dependencies: Baseline profiles per domain/prompt family; consistent inference settings.
- Early-stage content safety intervention — trust & safety, policy compliance
- What: Identify the temporal window when prohibited categories begin to commit and intervene before semantic commitment completes (e.g., suppress or redirect).
- How: Use partitioned entropy for “safe vs. unsafe” partitions; apply negative guidance or filtering within the critical window.
- Tools/workflows: Entropy-triggered safety filters; class-partition libraries aligned with policy taxonomies.
- Assumptions/dependencies: Reliable unsafe/allowed partitions (classifiers or curated prompt sets); low false positives; auditable logs.
- Model/debug instrumentation and interpretability — academia, applied research
- What: Compare architectures, schedulers, and guidance strategies by their entropy profiles and entropy redistribution effects (e.g., FID-optimal vs. feature-distance-optimal intervals).
- How: Profile H[Z|X_t] and its derivative across conditions; quantify how guidance shifts information over time.
- Tools/workflows: Research dashboards; ablation scripts; benchmarking suites that log entropy curves alongside FID/FD scores.
- Assumptions/dependencies: Comparable noise parameterizations; standardized evaluation datasets.
- Dataset and class difficulty analysis — data engineering, curation
- What: Identify classes or prompts with broad/shifted entropy windows (harder semantics) to target additional data collection or fine-tuning.
- How: Aggregate entropy profiles across samples by class/prompt; rank by peak width/shift.
- Tools/workflows: “Entropy difficulty” reports; active data acquisition for hard classes.
- Assumptions/dependencies: Stable taxonomy or prompt families; representative sampling.
- Training-time emphasis on critical timesteps — model training, academia/industry R&D
- What: Reweight losses or mini-batches toward timesteps where semantic information emerges to improve conditioning efficiency.
- How: Estimate entropy profiles from a held-out set; bias the training schedule or augment timesteps near the peak.
- Tools/workflows: Entropy-weighted timestep samplers; curriculum over diffusion time.
- Assumptions/dependencies: Reliable proxy for training-time entropy; care to prevent overfitting to narrow windows.
- Prompt engineering assistance for end users — daily life, creative industry
- What: Provide user-facing hints (e.g., “Your prompt’s key attributes commit early; try higher early guidance”) based on entropy timing for common attributes.
- How: Precomputed timing dictionaries for common modifiers (color, style, object presence) mapped to recommended guidance schedules.
- Tools/workflows: UI hints in consumer apps; preset profiles (e.g., “low-frequency style vs. high-frequency details”).
- Assumptions/dependencies: Generalization across prompts/models; simple presets for non-experts.
- Cross-modal extensions (audio/video) with coarse timing — media, entertainment
- What: Apply interval-limited guidance for coarse vs. fine features in audio/video diffusion (e.g., global rhythm/timbre vs. transients; scene layout vs. small objects).
- How: Use analogous partitioned entropy across modalities to schedule guidance.
- Tools/workflows: Prototype interval schedulers for text-to-audio/video models.
- Assumptions/dependencies: Access to conditional/unconditional models; initial calibration per modality.
Long-Term Applications
These applications require further research, scaling, or ecosystem development, but follow directly from the paper’s theory and empirical findings.
- Standardized “entropic instrumentation” for generative model auditing — policy, governance, risk
- Concept: Mandate time-resolved information-flow metrics (e.g., class-conditional entropy) for transparency, reproducibility, and safety audits of conditional generation.
- Potential products: Compliance dashboards, audit logs of entropy profiles per generation, model cards including entropy statistics.
- Dependencies: Community standards for noise parameterizations; regulatory buy-in; privacy-aware logging.
- Learned controllers that shape entropy production — software, foundation models
- Concept: Train meta-controllers to shape when and how semantics commit (e.g., earlier commitment for high-level layout; later for fine detail), optimizing task-specific metrics.
- Potential products: “Entropy-shaping” controllers integrated into inference engines; policy networks that co-schedule guidance and step sizes.
- Dependencies: Differentiable proxies for entropy profiles; stable training of closed-loop controllers.
- Training objectives and schedulers co-designed for time-localized control — academia/industry R&D
- Concept: Incorporate entropy-based regularization or objectives to calibrate when semantics emerge; design VP/VE-like schedules that concentrate commitment where desired.
- Potential products: Entropy-regularized diffusion training; new schedulers that sharpen speciation in VE/EDM-like processes.
- Dependencies: Theory for VE/EDM sharpening; careful trade-offs with sample diversity and fidelity.
- Hierarchical, multi-attribute generation workflows — creative tools, gaming, robotics simulation
- Concept: Exploit partitioned entropy to stage multi-attribute generation (e.g., layout → materials → micro-details), enabling compositional control with reduced interference.
- Potential products: Pipeline orchestrators that trigger attribute-specific modules when their entropy collapses; scene-graph aware generation.
- Dependencies: Reliable attribute partitions; consistent timing across scenes/domains.
- Early-stage content moderation with proactive remediation — platforms, policy
- Concept: Use early detection of entropy collapse for prohibited attributes to automatically steer outputs (e.g., swap prompts, attenuate guidance) before commitment.
- Potential products: Policy engines integrated with entropy monitors; explainable enforcement (“intervened at T where unsafe class committed”).
- Dependencies: Robust classifiers for unsafe partitions; low-latency controllers; governance frameworks.
- Compute- and energy-aware inference via entropy-driven resource allocation — infrastructure, energy
- Concept: Tie GPU/TPU allocation and precision to entropy rate, using high precision/compute only in critical windows to reduce cost and emissions.
- Potential products: Entropy-aware schedulers in serving stacks; dynamic precision scaling.
- Dependencies: Hardware support for rapid mode switching; predictable latency bounds.
- Domain-specific deployments (healthcare, geospatial, finance) with semantic timing guarantees — regulated sectors
- Concept: Provide assurances that clinically relevant or compliance-critical features commit within validated windows; log timing for auditability.
- Potential products: Medical image synthesis with timing constraints; audit trails for synthetic data pipelines.
- Dependencies: Domain validation, regulatory approval; high-alignment models; rigorous calibration of entropy estimation.
- Cross-modal alignment budgeting in multimodal systems — XR/AR, education
- Concept: Allocate “information budget” across modalities (text, image, audio) over time, steering which modality dominates commitment in each window for better coherence.
- Potential products: Multimodal co-schedulers; educational content generators with staged alignment (curriculum-first, detail-later).
- Dependencies: Joint entropy estimation across modalities; synchronized inference pipelines.
- Open benchmarks and leaderboards using entropy metrics — academia, community
- Concept: Evaluate models by entropy timing (peak location/width), entropy redistribution under guidance, and correlation with downstream metrics (FID, feature distances).
- Potential products: Public datasets with canonical partitions; standardized evaluation harnesses.
- Dependencies: Agreement on reference schedules; widely available conditional/unconditional checkpoints.
Key Assumptions and Dependencies (across applications)
- Access to both conditional and unconditional denoisers (or suitable proxies) to track posteriors; black-box APIs may limit applicability.
- Calibration of model predictions across noise levels; miscalibration can bias entropy estimates.
- Monte Carlo estimation introduces runtime overhead; needs optimization for production.
- Clear semantic partitions (labels or prompt variants) are needed for partitioned entropy; auxiliary attribute detectors may be required.
- Theoretical sharpness is strongest in VP-type processes; VE/EDM transitions can be broader, though the diagnostic remains useful in practice.
- Stronger, better-aligned models (e.g., SDXL/SD3) will improve attribute-level timing precision and downstream control.
Glossary
- Class-conditional entropy: The uncertainty of a class label given a noisy latent state in a diffusion process. "class-conditional entropy provides such an operational marker of speciation"
- Classifier-free guidance: A conditioning technique that steers the reverse diffusion using a learned conditional/unconditional score difference without an external classifier. "Guidance, especially classifier-free guidance, underlies many of the most capable conditional generators"
- Conditional entropy: The expected uncertainty of one random variable given another. "The conditional entropy quantifies the remaining uncertainty about given knowledge of ."
- Denoising trajectory: The sequence of states during reverse diffusion as noise is progressively removed. "We track class-conditional uncertainty along the denoising trajectory."
- DINOv2 Fréchet Distance (FD_DINOv2): A distributional distance computed in DINOv2 embedding space used to evaluate text-to-image alignment or image quality. "FD$_{\text{DINOv2}$ (limited interval)"
- Drift field: The deterministic component of an SDE that directs the evolution of states over time. "where is a standard Wiener process, is a drift field, and is a time-dependent diffusion coefficient"
- EDM (Elucidated Diffusion Models): A family of diffusion processes/samplers with specific noise parameterizations and solvers. "Examples of widely used SDEs are Variance-Preserving (VP) \citep{song2021scorebased} and Elucidated Diffusion Models (EDM) \citep{karras2022elucidating}."
- EDM2-XS: A specific trained diffusion model variant used in experiments. "We validate our method on EDM2-XS and Stable Diffusion 1.5"
- Effective signal-to-noise ratio (SNR): A measure of separability between classes at a given noise level based on posterior log-evidence. "we use the effective signal-to-noise ratio"
- Entropy production: The time derivative of (partitioned) class-conditional entropy along the denoising process. "Figure~\ref{fig: entropy_overview} illustrates the entropy production, i.e., the termporal derivative of the class conditional entropy"
- Entropy rate: The rate at which entropy changes over time in the process. "the entropy rate concentrates on the same logarithmic time scale"
- Fisher divergence: A measure of the squared difference between score fields of two distributions. " is the Fisher divergence between the class-conditional and unconditional marginal densities:"
- Fokker--Planck equation: The PDE governing the time evolution of the probability density of an SDE. "The evolution of the marginal densities is governed by the associated Fokker--Planck equation:"
- Forward SDE: The stochastic process that progressively corrupts data with noise. "The forward SDE gradually decreases information about the data by injecting noise"
- Fréchet Inception Distance (FID): A metric comparing distributions of images via Inception features. "we identify empirically optimal guidance intervals using FID"
- Gaussian mixture (model): A probabilistic model representing data as a mixture of Gaussian components. "We analyze this behavior in high-dimensional Gaussian mixture models"
- Guidance (in diffusion models): The practice of steering sampling toward a conditioning signal (e.g., text or labels) by modifying the score. "we use it to analyze how guidance redistributes semantic information over time."
- Log-likelihood ratio: The difference in log-likelihoods between two hypotheses, used here to update posteriors online. "accumulating the log-likelihood ratio between the conditional and reference denoisers."
- Log-posterior ratio: The logarithm of the ratio of posterior probabilities between two classes. "we define the log-posterior ratio"
- Marginal density: The probability density of a subset of variables irrespective of others. "The evolution of the marginal densities is governed by the associated Fokker--Planck equation:"
- Markov structure: The property that the future state depends only on the current state, not on the past. "takes advantage of the Markov structure of the forward diffusion process"
- Mutual information: The reduction in uncertainty of one variable given knowledge of another; a measure of dependence. "use mutual information between the text prompt and the final generated image"
- Order parameter: A macroscopic summary statistic that signals phase transitions or symmetry breaking. "the order parameter studied in~\cite{biroli2023generativediff}"
- Partitioned class-conditional entropy: Conditional entropy restricted to a binary partition of classes to isolate specific semantic distinctions. "We refer to the resulting quantity as the partitioned class-conditional entropy:"
- Posterior-tracking: An online procedure to estimate posteriors along trajectories by incremental updates. "we therefore adopt an online posterior-tracking procedure"
- Reverse SDE: The time-reversed SDE used for generation, driven by (conditional) score estimates. "sampling this reverse SDE (initialized from the approximately Gaussian final state of the forward process) would yield exact data samples."
- Reverse-time dynamics: The behavior of the system under the time-reversed generative process. "A prominent line of work studies the reverse-time dynamics under exact or near-exact score assumptions"
- Score (score function): The gradient of the log-density, ∇ log p(x), used to guide reverse diffusion. "introduces an additional drift term involving the score "
- Score-based diffusion models: Generative models that rely on learning the score of intermediate noisy distributions. "score-based diffusion models can be used to estimate mutual information"
- Speciation (symmetry-breaking class speciation): A sharp transition from semantic ambiguity to class commitment during denoising. "a sharp transition from semantic ambiguity to class commitment, termed symmetry-breaking class speciation"
- Speciation time: The characteristic time scale at which class distinctions emerge sharply. "the speciation time becomes some power of "
- Spontaneous symmetry breaking: A phenomenon where symmetric states become unstable and the system selects a particular structure. "spontaneous symmetry breaking in statistical physics."
- Transition kernel: The conditional distribution mapping states across time in the forward SDE. "the forward process admits a closed-form transition kernel "
- Variance-exploding (VE) process: A diffusion parameterization where noise variance increases with time (α_t ≡ 1, σ_t grows). "variance-exploding (VE) / EDM-style forward processes."
- Variance-preserving (VP) process: A diffusion parameterization where the data’s variance is preserved (α_t decays, σ_t compensates). "Variance-Preserving (VP)"
- Wiener process: A standard Brownian motion driving the stochastic term of the SDE. " is a standard Wiener process"
Collections
Sign up for free to add this paper to one or more collections.