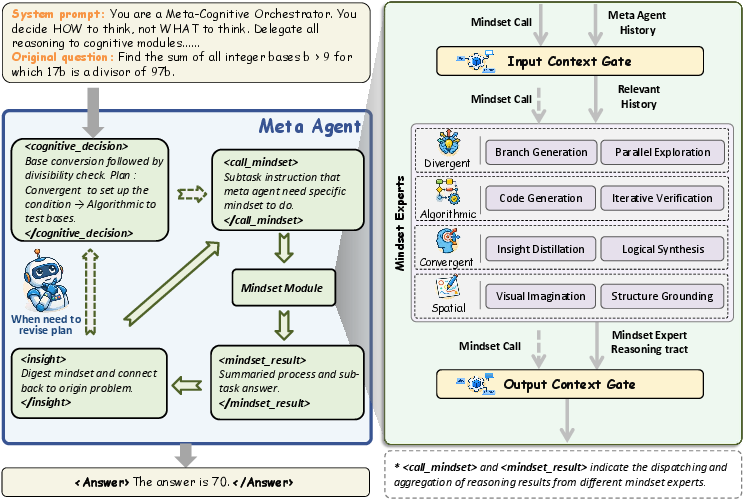
- The paper introduces a training-free, agentic reasoning framework that dynamically switches among Spatial, Convergent, Divergent, and Algorithmic modes.
- The paper demonstrates robust performance gains, achieving up to 63.28% accuracy and significant improvements on tasks requiring cognitive flexibility.
- The paper validates a Context Gate mechanism that efficiently filters information, ensuring relevant step-level reasoning across diverse benchmarks.
Chain of Mindset: Reasoning with Adaptive Cognitive Modes
Motivation and Background
LLMs have shown substantial progress in reasoning tasks through methods such as Chain-of-Thought (CoT) prompting, explicit decomposed reasoning, and meta-reasoning orchestration. Nonetheless, most existing frameworks apply a single cognitive paradigm uniformly across all steps of a task, ignoring the heterogeneity of subtask demands. Cognitive science posits that human experts leverage multiple complementary mindsets—Spatial, Convergent, Divergent, Algorithmic—transitioning adaptively as problem solving unfolds. This dynamic orchestration of cognitive modes is largely missing in state-of-the-art LLM frameworks, resulting in rigid, less efficient reasoning trajectories.
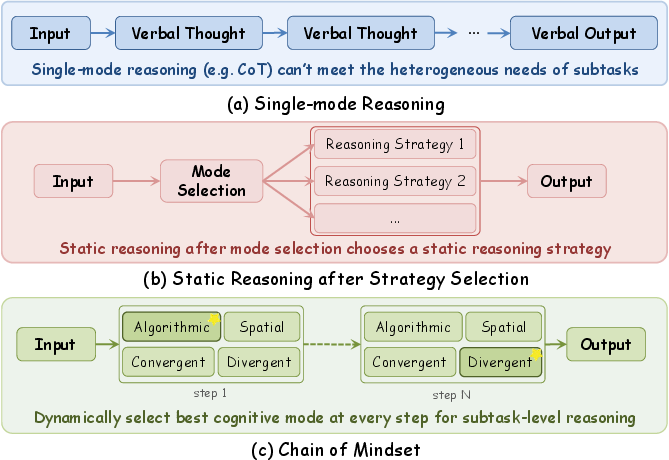
Figure 1: Comparison of reasoning paradigms. (c) Chain of Mindset supports step-level dynamic switches, while existing methods are locked to single or static strategies.
The Chain of Mindset Framework
Architecture and Design Principles
Chain of Mindset (CoM) introduces a training-free agentic reasoning paradigm that enables step-level switching among four functionally heterogeneous mindsets: Spatial, Convergent, Divergent, and Algorithmic. The architecture comprises:
Mindset Modules
- Spatial Mindset: Converts abstract descriptions into visual representations via generative modeling (Text→Image, Image+Text→Image, Code→Image), grounding reasoning in spatial intuition.
- Convergent Mindset: Performs focused, logic-driven analysis to distill key insights from multifaceted information, emphasizing fact-grounded deep reasoning.
- Divergent Mindset: Generates and evaluates multiple parallel solution branches, facilitating structured exploration beyond conventional approaches.
- Algorithmic Mindset: Handles precise numerical computation and formal verification through code execution with repair loops, overcoming LLM limitations in arithmetic and procedural logic.
Each mindset is subject to information filtering via the Context Gate to maintain relevance and efficiency, preventing context pollution during frequent transitions.
Experimental Results and Numerical Findings
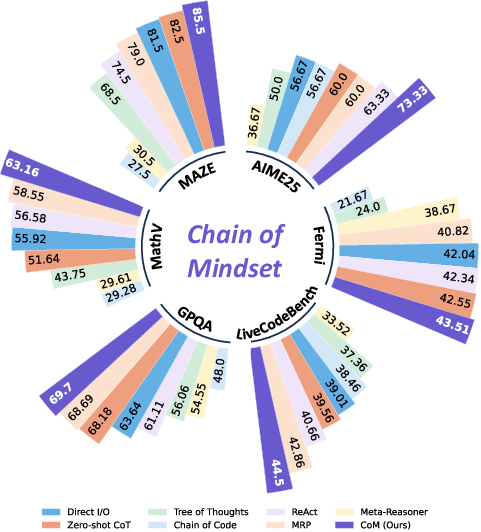
CoM was evaluated across six benchmarks covering mathematical reasoning, code generation, scientific QA, and spatial reasoning (AIME 2025, Real-Fermi, LiveCodeBench, GPQA-Diamond, MathVision-Mini, MAZE). Results demonstrate that CoM achieves superior pass@1 accuracy compared to strong baselines including direct reasoning, structured prompting, agentic reasoning (ReAct), and recent meta-reasoning methods (MRP, Meta-Reasoner):
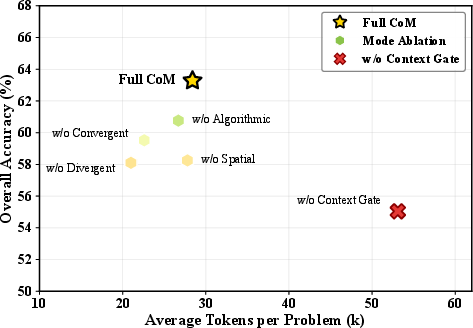
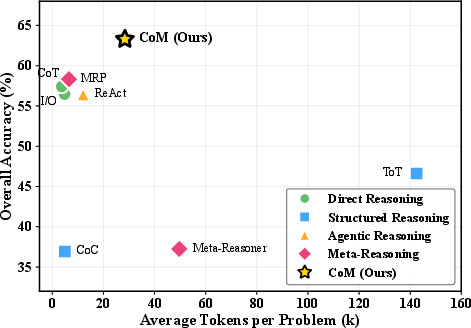
Figure 4: Accuracy-efficiency trade-off across methods. CoM dominates the Pareto frontier with highest accuracy at moderate token cost.
Qualitative Insights and Case Studies
CoM's adaptive switching enables both visual grounding and ambiguity resolution in reasoning. In Fermi estimation problems, the Spatial Mindset externalizes abstract proportions via generated diagrams, while the Convergent Mindset clarifies semantic ambiguities. Multiple mindset invocation patterns emerge with task-specific frequency: Fermi estimation tasks predominantly invoke Algorithmic and Convergent modules; multimodal reasoning leverages Spatial; mathematical proofs often benefit from Divergent-Convergent interplay.

Figure 5: Fermi problem (#494) demonstrating Spatial Mindset: anatomy diagram grounds abstract proportions, subsequent convergent reasoning resolves ambiguity.
Case studies show that CoM is robust to dead-ends—when an initial approach fails, the meta-agent recognizes the issue and re-plans by activating an alternative mindset, escaping static reasoning traps.
Theoretical and Practical Implications
CoM's framework advances the meta-reasoning paradigm by decoupling cognitive mode selection from task execution, allowing explicit, step-level control over cognitive strategies. The modular and training-free design enables rapid adaptation to new tasks and integration of novel mindsets. Bidirectional semantic filtering addresses the Relevance-Redundancy Trade-off in modular reasoning, scaling efficiently to long contexts.
Practically, CoM supports transparent reasoning trajectories suitable for safety auditing and user-guided cognitive interventions. The explicit switching mechanism aligns with cognitive neuroscience (PBWM model) and supports future plug-and-play mindset expansion, heterogeneous expert allocation per module, and tool-assisted reasoning.
Future Directions
Further development could include fine-grained mindset subsetting based on task characteristics, training the meta-agent's dispatch policy for optimal orchestration, and augmenting each mindset with specialized tools (e.g., symbolic solvers for Algorithmic mode). The framework serves as a testbed for studying cognitive mode interactions, advancing both AI and cognitive science.
Conclusion
Chain of Mindset (CoM) establishes a new paradigm for adaptive cognitive orchestration in LLM-based reasoning. Through dynamic mindset switching, modular architecture, and efficient semantic gating, CoM achieves consistent state-of-the-art accuracy and efficiency across diverse benchmarks, generalizing across both open-source and proprietary models. This approach unlocks new capabilities by emulating human cognitive flexibility, paving the way for more robust and interpretable reasoning systems in AI.