- The paper presents a RoPE-aware per-token quantization method that minimizes numerical error and maintains high fidelity in deep layers.
- The paper develops a quantized PV computation pipeline using scale fusion to streamline dequantization and exploit hardware tiling for efficient memory access.
- The paper implements end-to-end dataflow optimization that delivers nearly 2× throughput speedup with negligible accuracy loss across various LLM benchmarks.
SnapMLA: Hardware-Aware FP8 Quantized Pipelining for Efficient Long-Context MLA Decoding
Introduction and Motivation
Efficient inference of LLMs with extended context lengths imposes substantial computational and memory challenges, particularly for attention mechanisms reliant on large Key-Value (KV) caches. The integration of FP8 attention within the decoding phase of DeepSeek Multi-head Latent Attention (MLA) architectures is impeded by numerical heterogeneity, quantization misalignment, and architectural hardware constraints. SnapMLA is proposed as a systematically hardware-aware, algorithm-kernel co-optimized framework targeting these challenges. The technical innovations of SnapMLA address: (a) RoPE-Aware Per-Token KV Quantization; (b) quantized PV computation pipeline reconstruction; and (c) end-to-end dataflow optimization. This enables high-throughput inference—up to 1.91× speedup—with negligible performance degradation on extensive long-context benchmarks including mathematical reasoning and code generation.
Technical Innovations
RoPE-Aware Per-Token KV Quantization
MLA's KV cache comprises a compressed latent content vector and a decoupled Rotational Position Embedding (RoPE) component. Empirical analysis demonstrates a marked divergence in dynamic ranges: RoPE exhibits outlier tails and spans up to 103, while content is tightly centered around zero. Uniform FP8 quantization is thus inadequate, significantly amplifying MSE for RoPE, especially in deeper layers.
SnapMLA implements RoPE-Aware Per-Token Quantization, restricting FP8 quantization to the content dimension and preserving RoPE in higher precision (BF16). Quantization granularity is set to per-token, facilitating immediate quantization in autoregressive decoding, eliminating buffer management complexity typical of block-wise approaches, and maintaining compatibility with contemporary inference frameworks.
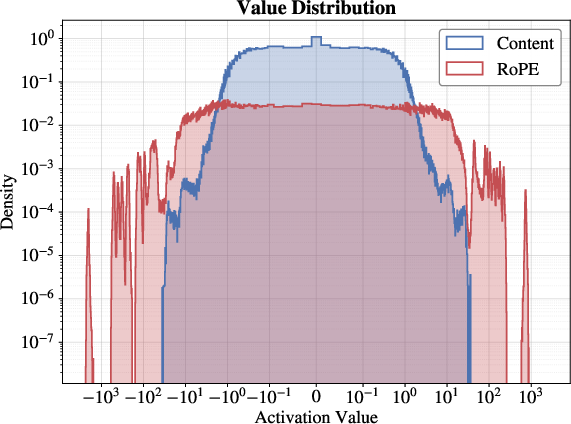
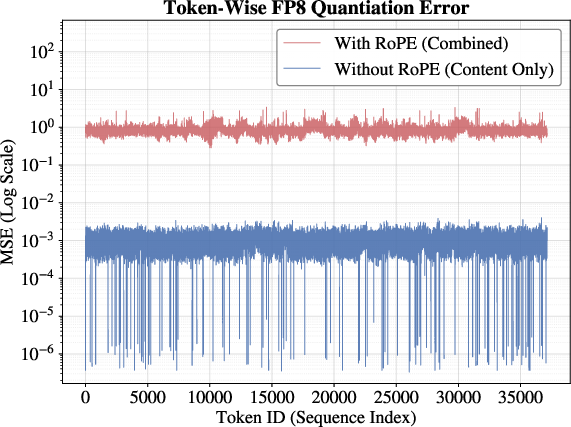
Figure 1: Numerical values analysis.
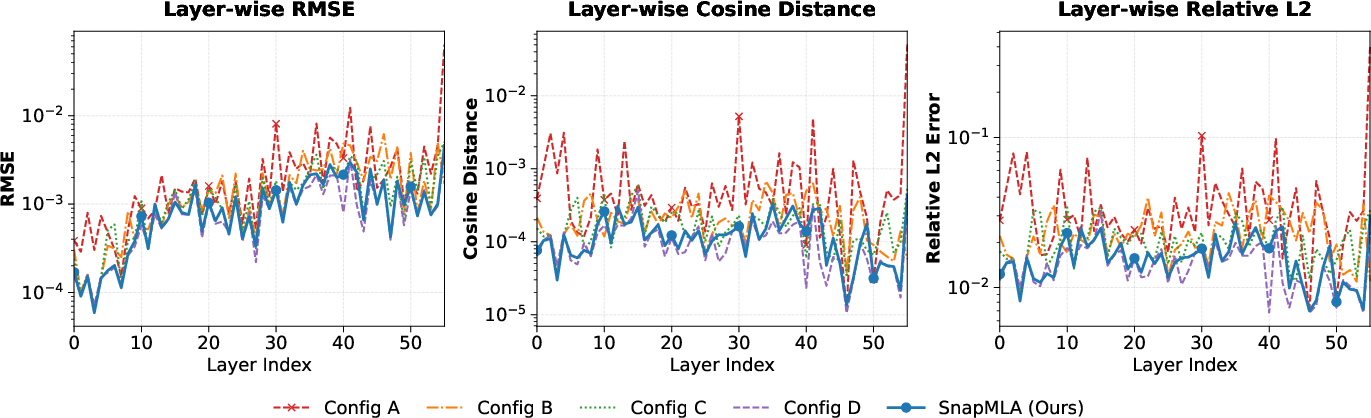
Figure 2: Layer-wise numerical fidelity analysis (context length = 32k).
Quantized PV Computation Pipeline Reconstruction
Execution of the PV GEMM with FP8 precision on NVIDIA Hopper Tensor Cores requires k-major contiguous memory layout for V. However, MLA’s V inherits per-token scales from the latent cache, misaligned with the reduction dimension, breaking conventional dequantization pipelines.
SnapMLA resolves this via Scale Fusion, integrating SV directly into the attention probability matrix P. This is followed by block-wise dynamic quantization and implicit dequantization fused into the softmax computation. The result is a scale-homogeneous pipeline, robust to dynamic range extension induced by fusion, and compatible with hardware tiling and efficient memory access patterns.
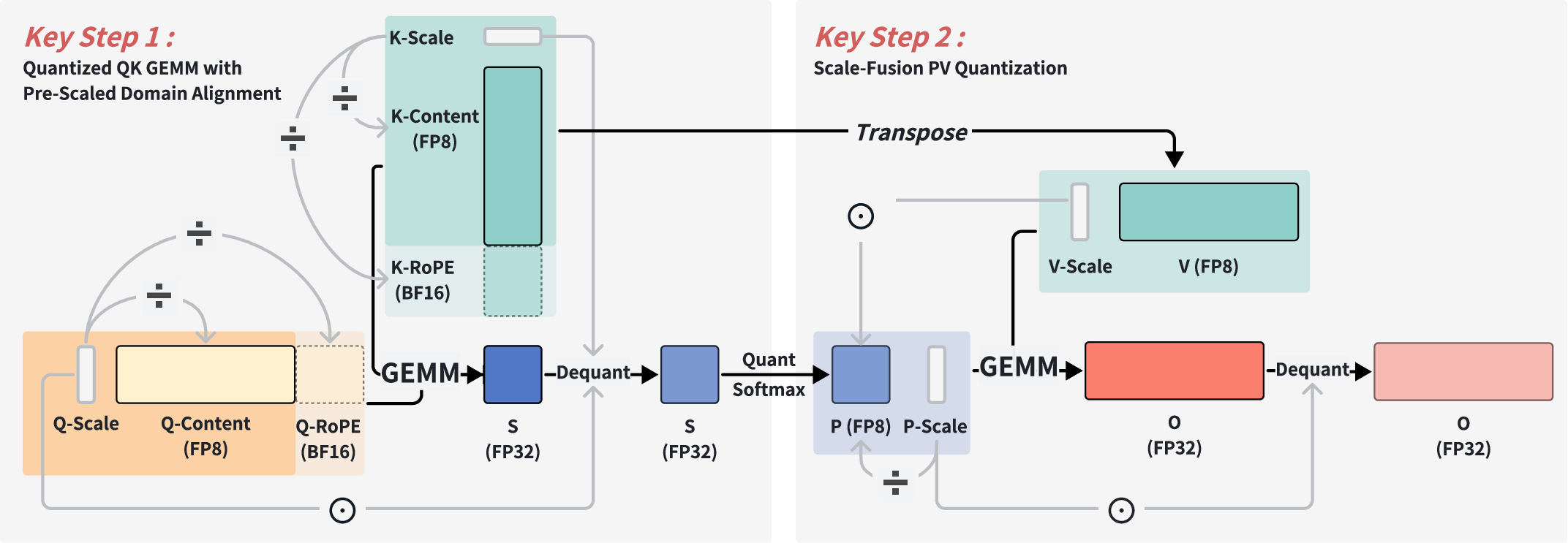
Figure 3: Overview of the scale fusion pipeline in SnapMLA.
End-to-End Dataflow Optimization
SnapMLA features hardware-optimized compute-memory fusion, cache-aware tiling (aligned with HBM and SMEM layouts), and zero-overhead data layout transformation. These include fused kernels for token preparation and cache management, and efficient in-kernel transpositions using Hopper’s asynchronous execution. The holistic pipeline minimizes kernel launches, memory traffic, and layout adaptation overhead, achieving near-peak hardware utilization.
Empirical Evaluation
Benchmark Accuracy
Comparative evaluation across DeepSeek-V3.1 and LongCat-Flash-Thinking demonstrates SnapMLA achieves comparable or superior accuracy to FlashMLA, even under full FP8 quantization. Notably, performance in general QA, reasoning, and coding benchmarks remains stable, with only minor losses in mathematical reasoning tasks. This substantiates the preservation of accuracy through sensitivity-aware mixed-precision quantization and granular scale management.
Numerical Fidelity
Layer-wise analysis indicates that quantizing RoPE introduces substantial errors and “error explosion” as depth increases. Coarse-grained configurations (per-tensor/block) fail to capture token-level outlier activations. SnapMLA’s per-token, RoPE-aware quantization delivers the lowest error rates, closely matching BF16 ground truth across all metrics.
SnapMLA delivers a 1.91× speedup under DP8/TP1 parallelism, enabling substantially larger batch sizes due to reduced memory footprint. Kernel performance closely tracks the effective theoretical TFLOPS peak, indicating negligible overhead from pipeline reconstruction and layout transformations.
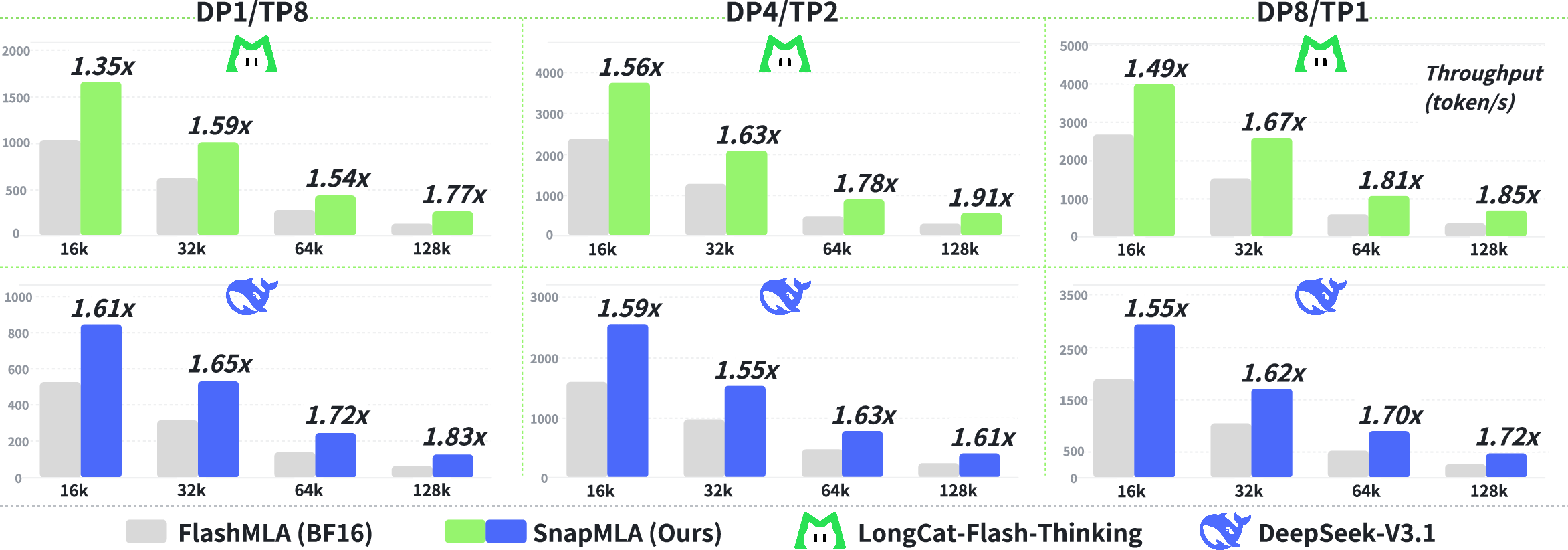
Figure 4: End-to-end decoding throughput comparison.
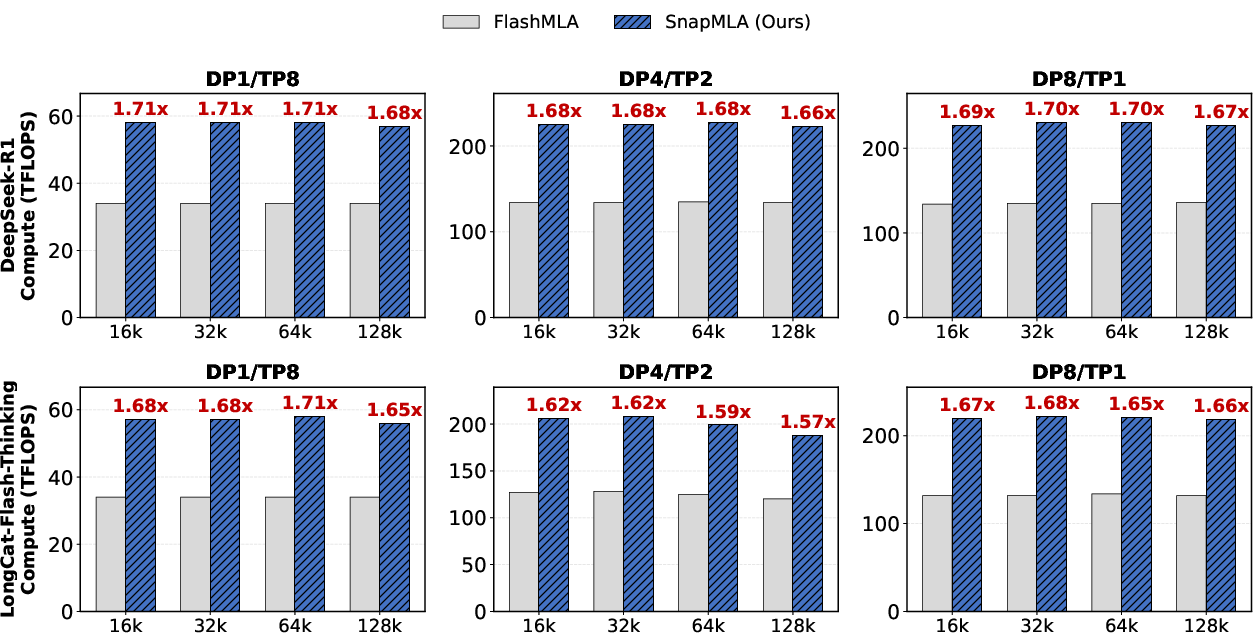
Figure 5: Kernel-level compute performance (TFLOPS).
Kernel-level and configuration sensitivity analysis further reveal that throughput rises with number of heads and multi-token prediction (MTP), stabilizing at 85% peak for H≥64, and SnapMLA consistently outperforms FlashMLA.
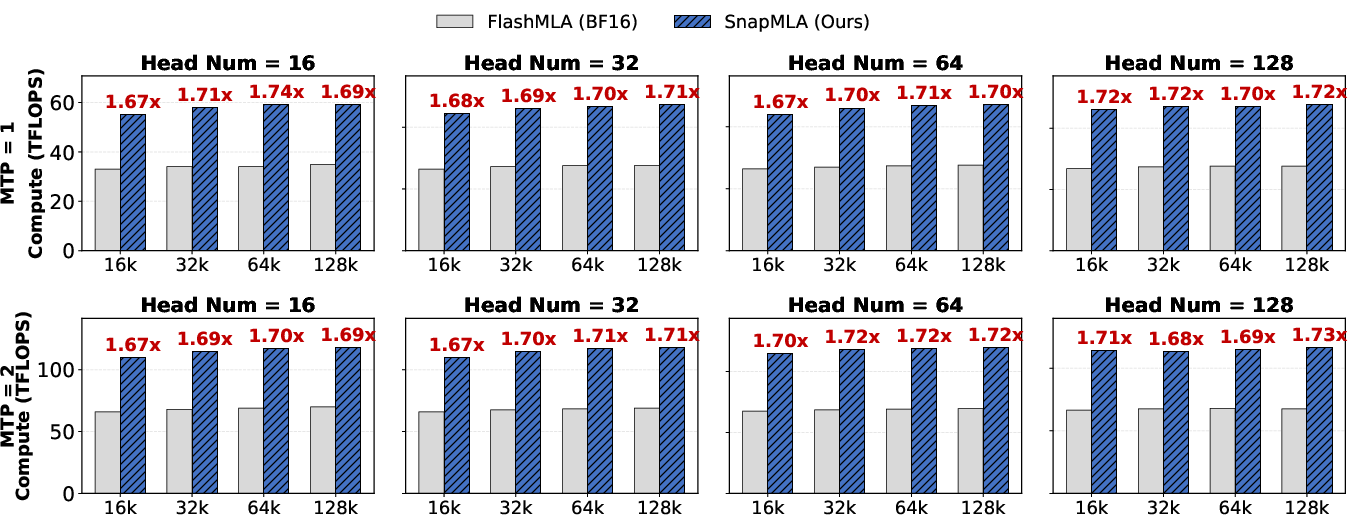
Figure 6: Kernel performance across different input configurations.
Quantization Granularity and Hardware Scaling
SnapMLA exploits FP8’s dynamic range and the Hopper architecture's new Tensor Cores, systematically optimizing for per-token granularity and hardware-aligned layouts. This demonstrates a significant advancement in low-bit quantization methodologies for LLMs, leveraging hardware features to maximize resource efficiency and scalability without sacrificing accuracy.
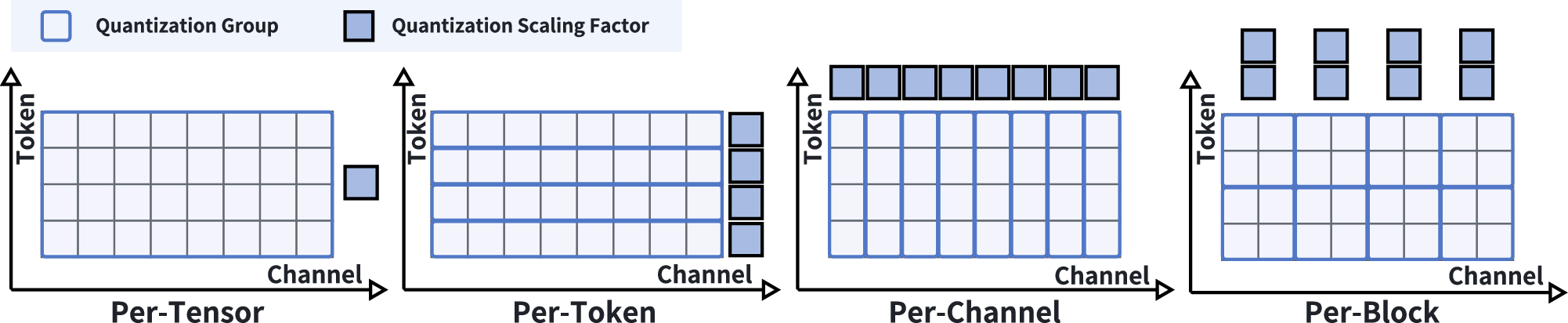
Figure 7: Illustration of various quantization granularities.
Implications and Future Directions
SnapMLA’s architectural innovations enable practical deployment of efficient, long-context LLMs on hardware-constrained environments by simultaneously reducing memory requirements and achieving compute-bound throughput scaling. The implications for distributed inference and large-scale deployment are substantial: SnapMLA unlocks concurrency scaling, batch-size increases, and lower operational costs at production scale. Theoretical insights into activation outlier mitigation and mixed-precision domain alignment extend to other compressive architectures, suggesting broad applicability.
Potential future directions include further reducing quantization error with adaptive outlier detection, generalized mixed-precision pipelines, and extending algorithm-kernel co-design methodologies across emerging GPU architectures (e.g., Blackwell), and exploring context extrapolation limits in increasingly long-context settings with granular quantization policies.
Conclusion
SnapMLA presents a rigorously engineered, hardware-aware FP8 decoding pipeline for MLA LLMs, overcoming numerical, quantization, and architectural bottlenecks. Through empirical substantiation, SnapMLA demonstrates nearly 2× throughput scaling with negligible accuracy loss across demanding benchmarks, validating its utility for efficient long-context LLM inference and paving the way for future hardware-software optimization initiatives in AI systems.