GameDevBench: Evaluating Agentic Capabilities Through Game Development
Abstract: Despite rapid progress on coding agents, progress on their multimodal counterparts has lagged behind. A key challenge is the scarcity of evaluation testbeds that combine the complexity of software development with the need for deep multimodal understanding. Game development provides such a testbed as agents must navigate large, dense codebases while manipulating intrinsically multimodal assets such as shaders, sprites, and animations within a visual game scene. We present GameDevBench, the first benchmark for evaluating agents on game development tasks. GameDevBench consists of 132 tasks derived from web and video tutorials. Tasks require significant multimodal understanding and are complex -- the average solution requires over three times the amount of lines of code and file changes compared to prior software development benchmarks. Agents still struggle with game development, with the best agent solving only 54.5% of tasks. We find a strong correlation between perceived task difficulty and multimodal complexity, with success rates dropping from 46.9% on gameplay-oriented tasks to 31.6% on 2D graphics tasks. To improve multimodal capability, we introduce two simple image and video-based feedback mechanisms for agents. Despite their simplicity, these methods consistently improve performance, with the largest change being an increase in Claude Sonnet 4.5's performance from 33.3% to 47.7%. We release GameDevBench publicly to support further research into agentic game development.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces GameDevBench, a new “test set” for AIs that try to build video games. Instead of only writing code, these AIs must also understand and work with visuals like images, animations, and 3D models. The benchmark uses the Godot game engine and includes 132 real game-making tasks pulled from web pages and YouTube tutorials. The big idea: if an AI can handle game development—which mixes code, art, sound, and timing—it’s a strong sign it can handle complex, real-world projects.
What questions is the paper trying to answer?
- Can today’s AI “agents” (think: smart, tireless interns that can read files, write code, and run tools) actually build parts of a game?
- Which types of game tasks are easier or harder for AI—gameplay logic, 2D/3D graphics, or user interface?
- Does giving AIs visual feedback (screenshots or short videos of the game/editor) help them work better?
- How do different AI models and tool setups affect results and cost?
How did the researchers build and test this?
They created GameDevBench by turning real tutorials into testable tasks and then checked how well AIs could solve them.
Here’s the process in simple terms:
- They collected tutorials:
- From YouTube: grabbed transcripts and linked code repositories.
- From trusted websites: saved text, images, and matching code.
- Only Godot 4 tutorials with open-source code were used.
- They turned tutorials into tasks:
- An AI helped write task instructions (like “Add a walking animation using this spritesheet”) and created automatic tests.
- Humans reviewed and fixed issues, made sure tasks were clear and solvable, and added some variations.
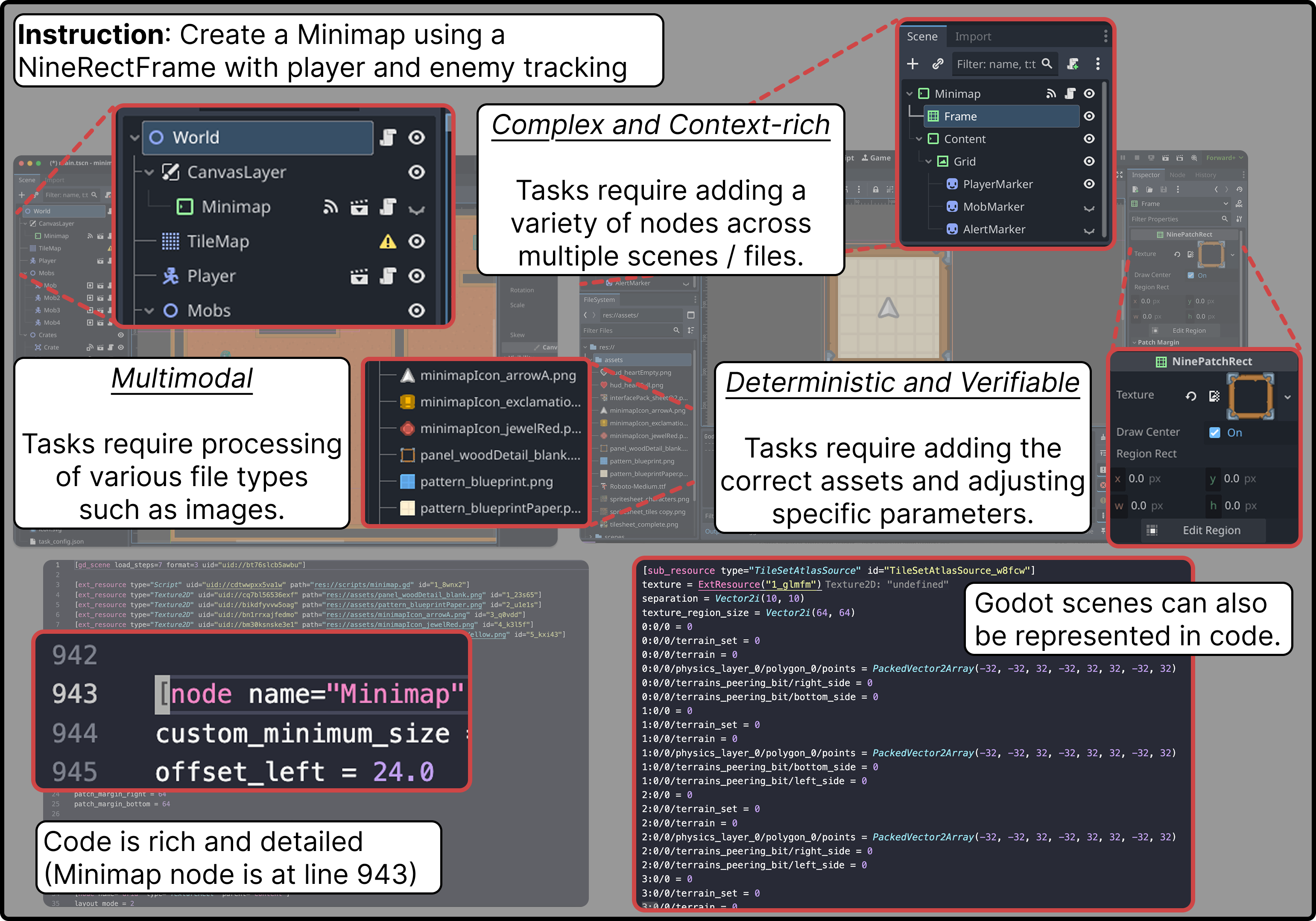
- They made tasks realistic and checkable:
- Each task includes code, images, sounds, shaders, and more.
- Success is checked inside Godot with automatic tests (like “is the right animation playing?” or “do these objects collide?”). This avoids guessing and makes results repeatable.
- They organized the tasks by:
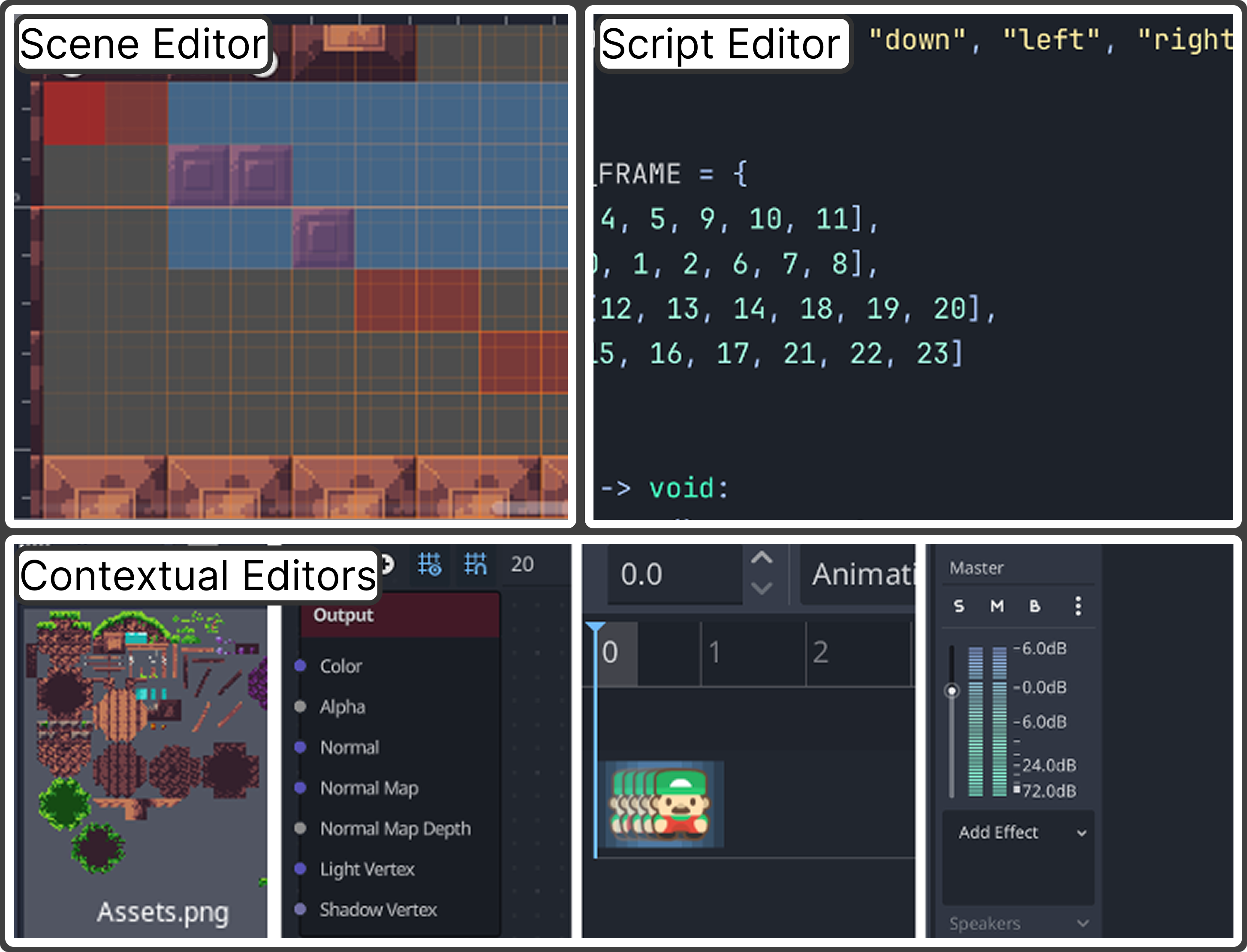
- Skill: gameplay logic, 2D graphics/animation, 3D graphics/animation, and user interface.
- Editor type: scripting (code), scene editor (placing objects), and “contextual editors” (special tools for animations, shaders, tiles, audio, etc.).
- They evaluated multiple AIs and setups:
- Different models (from well-known families like Gemini, Claude, GPT, and open-source).
- Different “agent frameworks” (the software that lets AIs read files, edit code, and run the game).
They also tried two simple ways to give AIs visual feedback, explained below.
Explaining key terms with simple analogies
- Benchmark: a fair test, like a driver’s test for cars, but for AIs.
- Agent: an AI that doesn’t just chat—it can also browse files, write code, and run tools.
- Multimodal: handling many kinds of data at once—text, images, sounds, and videos.
- Godot (game engine): the “workshop” where you build games; it has an editor for assembling scenes and an engine to run them.
- Spritesheet: a single image made of many small pictures used to animate a character (like a flipbook).
- Shader: a tiny program that tells the computer how to draw cool visual effects (glow, water ripples, etc.).
- Deterministic tests: automatic checks that always give the same answer if the work is correct (like unit tests in coding).
What did they find?
Here are the main takeaways:
- Game development is tough for AIs right now.
- Even the best model setup solved only about 54.5% of tasks on the first try (pass@1).
- Many models did far worse without extra help.
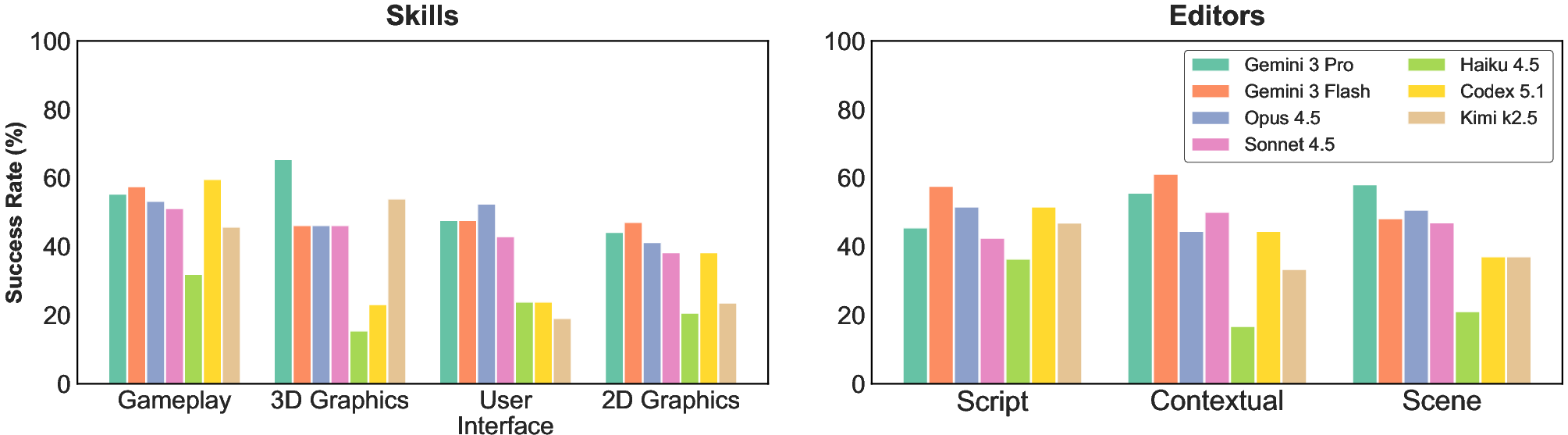
- Visual-heavy tasks are harder.
- AIs did better on gameplay logic than on 2D graphics/animation tasks.
- Success rates dropped as tasks required more image/animation understanding.
- Simple visual feedback helps a lot.
- Two small tools made a consistent difference:
- Editor screenshots: the AI could “see” the Godot editor state (scene tree, properties, etc.).
- Gameplay videos: the AI could watch what the game actually looked like when running.
- Example: one model improved from 33.3% to 47.7% when given video feedback.
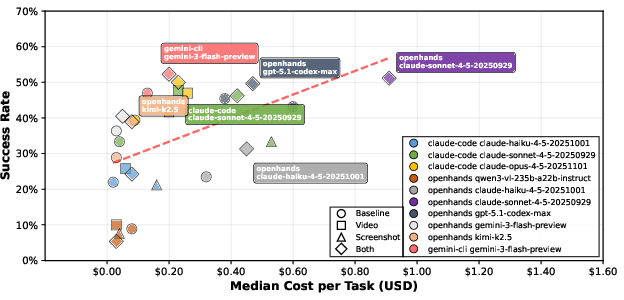
- The setup (framework) matters.
- The same model performed differently depending on the agent framework used.
- For some models, switching frameworks helped a lot; for others, it hurt.
- It’s a big step up in complexity.
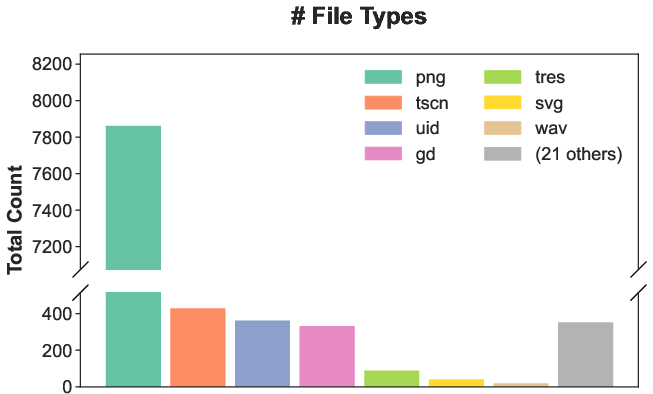
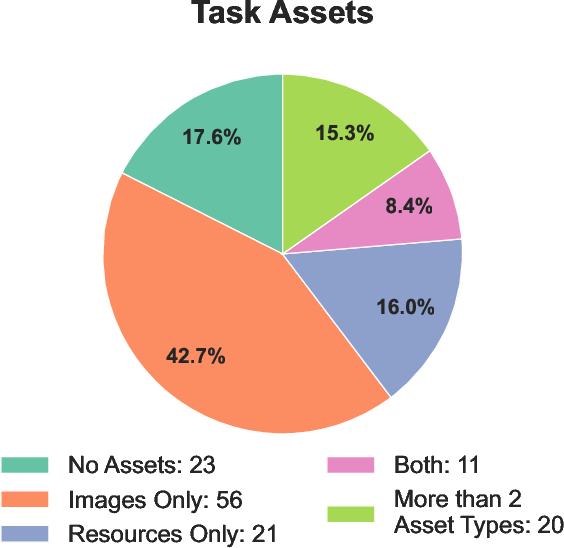
- Compared to earlier software benchmarks, the average solution here changed more than three times as many lines of code and touched more files and file types (code, images, audio, shaders, etc.).
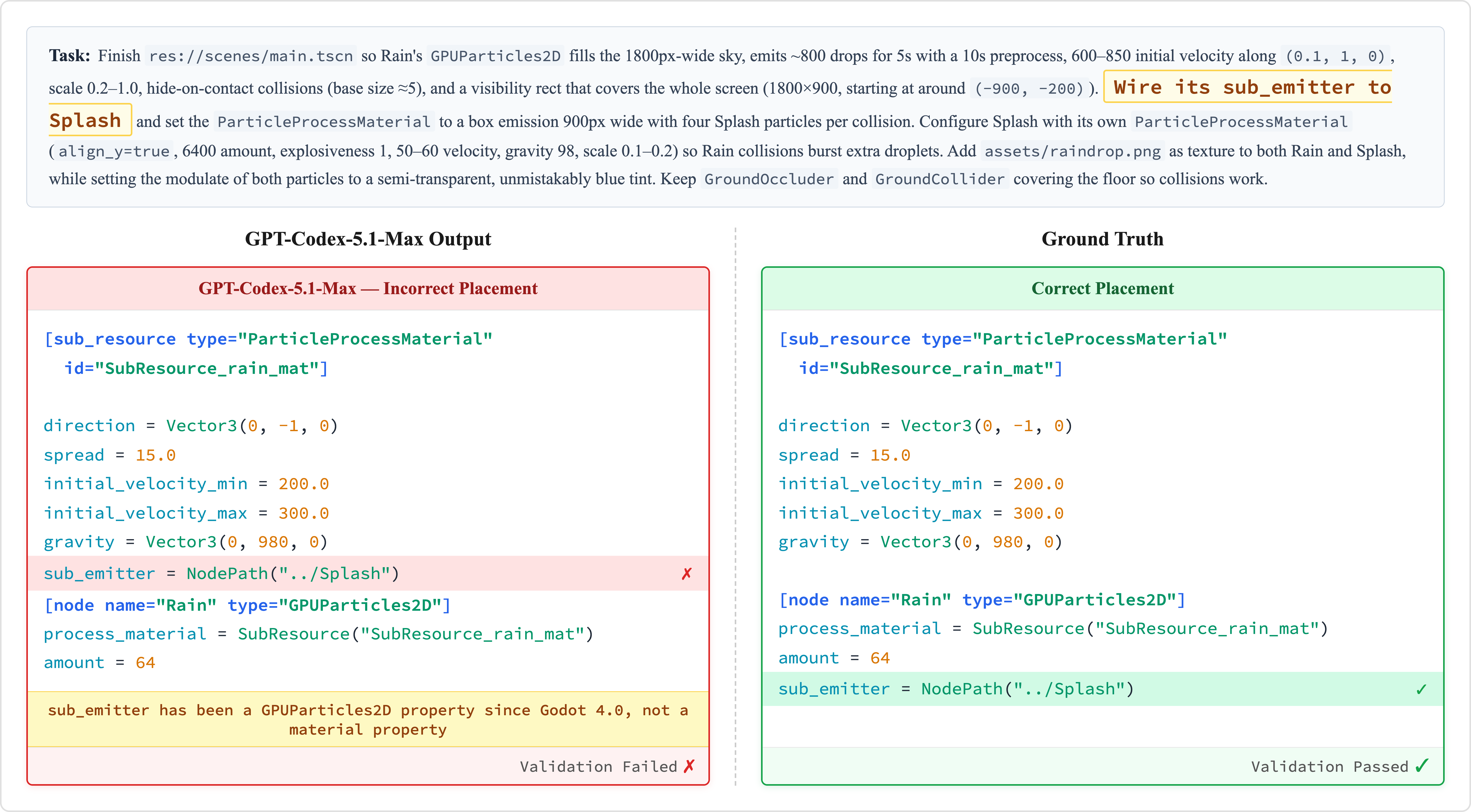
- Common mistakes point to current weaknesses:
- Multimodal confusion: picking the wrong animation frames, misusing images, or not understanding visual layouts.
- Game engine patterns: placing nodes in the wrong part of the scene tree or wiring up signals incorrectly (things seasoned game devs do by habit).
Why does this matter?
- It’s a realistic test for future AIs.
- Real software jobs often mix code with visuals, sounds, and timing—just like games. Doing well here suggests broader capability.
- It shows a clear path to improvements.
- Letting AIs “see” the editor or the running game makes them smarter and more reliable.
- Training on game-specific patterns (like scene trees and signals) should help a lot.
- It can speed up game-making tools.
- Better agentic AIs could help with prototyping, creating animations, fixing bugs, or wiring UI—saving time for human creators.
- It’s public and renewable.
- The benchmark is open and can be expanded from more tutorials, helping the whole community track progress over time.
In short
GameDevBench is like a report card for AIs trying to make games. It shows that while AIs are getting better, they still struggle with tasks that mix code and visuals. Simple visual feedback—screenshots and videos—already boosts performance. This benchmark gives researchers a clear, fair way to measure and improve AIs so they can become more helpful and reliable game-making assistants.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper.
- External validity to other engines: the benchmark is Godot‑only (v4), leaving unknown how results transfer to Unity, Unreal, earlier/later Godot versions, or cross‑engine abstractions.
- Tutorial selection bias: tasks are derived from web/YouTube tutorials with available repos and permissive licenses, potentially overrepresenting “teachable,” well‑scaffolded skills and underrepresenting industry workflows, edge cases, and larger production codebases.
- Dataset contamination risks: no analysis of whether evaluated models were trained on (or memorized) the same tutorials/repos used to generate tasks/tests; no shielded or adversarial splits to mitigate leakage.
- Limited scope of game dev: missing or underrepresented areas such as networking/multiplayer, performance optimization, build pipelines, asset import pipelines, versioning/collaboration workflows, testing/debugging workflows, localization, monetization, or platform‑specific quirks.
- Asset generation is out of scope: tasks largely manipulate provided assets; no evaluation of integrated asset creation (sprites, audio, shaders) or quality‑control loops combining generation and integration.
- Short‑horizon bias: tasks are small/medium changes drawn from tutorial steps; there is no long‑horizon, multi‑stage project benchmark (e.g., multi‑feature game spanning many commits and design dependencies).
- Determinism and physics: while tests are “deterministic,” there is no evidence they are robust to platform/hardware variance or physics timestep nondeterminism; reproducibility across OS/GPU/engine settings is untested.
- Test coverage adequacy: the paper asserts tests can verify multimodal outcomes (e.g., animation states, colliders) but provides no coverage metrics, mutation testing, or failure‑mode audits to show tests catch wrong-but-plausible solutions.
- “Teaching to the tests” risk: deterministic tests may incentivize overfitting; there is no hidden/holdout test suite or adversarial tasks to evaluate generalization beyond explicit assertions.
- Difficulty measurement is underspecified: “perceived task difficulty” is referenced but methodology (human ratings, scales, inter‑rater reliability) is not described; no difficulty calibration or stratified reporting.
- Category labeling validity: task skill/editor categories were derived using an LLM then “reviewed,” but there is no inter‑annotator agreement, audit of mislabels, or sensitivity analysis on downstream conclusions.
- Small scale: 132 tasks may be insufficient for fine‑grained per‑category benchmarking, robust leaderboard deltas, or stable statistical comparisons; confidence intervals and significance tests are not reported.
- Pass@1 only: no pass@k, no retries, and no analysis of sample efficiency or how many iterations/edits agents require; robustness to agent randomness across multiple runs is unreported.
- Inconsistent cost accounting: cost comparisons mix agent frameworks and estimation methods (e.g., using OpenHands cost as a proxy for Gemini‑CLI), confounding conclusions about cost‑performance tradeoffs.
- Framework confounds: performance differences across agent frameworks (e.g., OpenHands vs native CLIs) blur model vs tooling effects; a standardized, framework‑agnostic tool suite and uniform budgets are absent.
- Multimodal feedback ablations are shallow: no controlled study of screenshot vs video information content (e.g., resolution, FPS, duration, cropping, camera view), nor when each modality helps or hurts which task types.
- Lack of GUI‑manipulation agents: evaluation centers on code‑only agents plus visual feedback; no benchmark baselines using GUI‑action agents that operate the Godot editor directly (e.g., click, drag, timeline scrubbing), limiting insight into “computer use” strategies.
- Godot file/tooling support gaps: no standardized tools are provided for parsing/editing Godot‑specific formats (.tscn, .tres, shaders), spritesheets, or timelines; unclear how agents robustly inspect binary assets or editor‑only resources.
- Cross‑engine abstraction: no exploration of a task representation layer that could generalize across engines (e.g., node/scene graphs, animation state machines) to study transfer and universals in game dev.
- Benchmark renewal governance: while “continually renewable,” there is no protocol for versioning, stable core vs. expansion sets, or safeguards against shifting difficulty that break longitudinal comparisons.
- Human verification reliability: human refinement is reported but not quantified (e.g., annotation time variance, error rates post‑refinement, inter‑annotator agreement), leaving uncertainty about residual task/test flaws.
- Evaluation of non‑functional qualities: frame rate, memory, GPU/CPU load, shader performance, and visual quality metrics are not assessed, yet these are critical in real game development.
- Collaboration and tooling integration: the benchmark treats a single agent in isolation; there is no evaluation of multi‑agent collaboration, version control workflows (branching/merging), code reviews, or CI/CD pipelines.
- Generalization beyond provided assets: tasks rarely demand identifying/creating the “right” asset when multiple plausible options exist or when assets are missing, leaving multimodal retrieval/generation+integration under‑tested.
- Error taxonomy depth: the error analysis identifies two broad patterns (multimodal understanding and game‑engine patterns) but lacks a quantitative taxonomy linking failure modes to task types, files edited, or tool choices, limiting targeted improvements.
Practical Applications
Immediate Applications
Below are practical uses that can be deployed now, leveraging the benchmark, tooling, and empirical findings reported in the paper.
- Model evaluation and selection for game development copilots — Use GameDevBench to compare coding/multimodal agents before integrating them into production workflows, with deterministic pass@1 scoring and cost–performance trade-offs guiding procurement.
- Sectors: software, gaming
- Tools/products/workflows: CI jobs that run GameDevBench; dashboards tracking pass@1 by task category (gameplay vs. 2D/3D graphics vs. UI); cost-per-pass leaderboards
- Assumptions/dependencies: Godot 4 test harness in CI; access to evaluated models; reproducible environment setup
- Agent-in-the-loop debugging via visual feedback — Add the paper’s “Editor Screenshot MCP” and “Runtime Video” feedback mechanisms to existing agents to raise fix rates for visual and physics bugs (e.g., colliders, camera framing, sprite selection).
- Sectors: gaming, software tooling
- Tools/products/workflows: MCP server packaged as a local service; CLI instructions to record Godot runtime videos; automated prompt templates for visual verification loops
- Assumptions/dependencies: MCP integration supported by the host agent; GPU/video processing budget; secure sandboxing of editor runs
- Automated grading for game dev courses and bootcamps — Reuse benchmark tasks and deterministic tests to create autograded assignments that cover gameplay logic, 2D/3D animation, and UI skills.
- Sectors: education
- Tools/products/workflows: LMS plug-ins that call Godot tests; assignment banks stratified by skill/editor categories; instant feedback reports (which tests failed and why)
- Assumptions/dependencies: Student submissions must compile under Godot 4; licensing for example assets; faculty-curated rubrics where needed
- Internal QA regression suites for studios — Port the benchmark’s testing patterns to studio projects to catch visual, physics, and layout regressions deterministically in CI.
- Sectors: gaming
- Tools/products/workflows: Godot test suites for camera visibility, collider interactions, animation state checks; nightly CI runs; auto-opened bug tickets on failures
- Assumptions/dependencies: Maintainable test scaffolding per project; stable seeds for deterministic physics; headless Godot builds in CI
- Hiring and skills assessment — Use curated subsets of tasks as time-bounded coding tests for technical designers, gameplay programmers, or technical artists with auto-scoring.
- Sectors: gaming, HR/assessment
- Tools/products/workflows: Candidate sandbox with Godot tests; category-targeted task bundles (e.g., shaders, tilemaps, character controllers); standardized scoring
- Assumptions/dependencies: Fairness review of tasks; consistent environment; anti-plagiarism measures
- Benchmark-driven R&D for multimodal agent teams — Adopt GameDevBench to track progress on visual reasoning, spritesheet parsing, shader editing, and multi-file code edits with reproducible metrics.
- Sectors: academia, software research
- Tools/products/workflows: Benchmark runners; ablation pipelines for feedback modalities (no feedback vs. screenshots vs. video); error taxonomy tracking
- Assumptions/dependencies: Stable benchmark versions; consistent token-budgets; comparable agent frameworks
- Cost-aware deployment planning — Use the paper’s observed cost–success differences (e.g., Gemini 3 Flash as cost-effective; framework effects) to choose models and frameworks for specific pipelines.
- Sectors: software, gaming
- Tools/products/workflows: FinOps dashboards estimating cost per task; routing policies (cheap model first, escalate on failure)
- Assumptions/dependencies: Pricing stability; monitoring for drift as models/frameworks update
- Godot IDE copilot enhancements — Embed tests-and-visual-feedback loops inside the editor to validate changes before commit (e.g., “run relevant tests + take screenshot + propose fix”).
- Sectors: software tooling, gaming
- Tools/products/workflows: Godot plugin that triggers unit tests, captures editor state, and prompts an agent; “fix-it” PR generator
- Assumptions/dependencies: Editor plugin APIs; local model or API access; developer consent/security
- Curriculum design and analytics — Map course outcomes to the benchmark’s skill/editor taxonomy to ensure coverage and to diagnose cohort-specific weaknesses (e.g., 2D animation gaps).
- Sectors: education
- Tools/products/workflows: Skills matrices; longitudinal pass@1 and failure-mode analytics; targeted remedial assignments
- Assumptions/dependencies: Institutional buy-in; anonymized student data handling
- Open-source community maintenance — Use tasks/tests as onboarding exercises and as pre-merge gates for community Godot projects to keep quality high.
- Sectors: open-source, software
- Tools/products/workflows: GitHub Actions that run Godot tests; contributor task queues; helpful failure messages tied to docs
- Assumptions/dependencies: CI minutes; contributor environment reproducibility; permissive asset licensing
- Studio knowledge bases from tutorials — Replicate the tutorial-to-task pipeline to transform internal docs and videos into testable tasks that codify tribal knowledge.
- Sectors: gaming, enterprise knowledge management
- Tools/products/workflows: Doc-to-task generation scripts; human-in-the-loop refinement; internal “GameDevBench-like” suites
- Assumptions/dependencies: Documentation quality; legal clearance for internal content; annotator bandwidth
- Adjacent domain testing patterns — Apply the benchmark’s deterministic multimodal testing approach to other visual-code domains (e.g., UI layout tests, DCC tool pipelines).
- Sectors: software, design tooling
- Tools/products/workflows: Visual unit tests for UI/canvas state; scene graph assertions; media asset checks
- Assumptions/dependencies: Testable runtime and APIs; stable scene graph or DOM; headless renderers
Long-Term Applications
The following opportunities are promising but require further research, scaling, tooling maturity, or ecosystem alignment.
- Autonomous game prototyping agents — End-to-end agents that assemble small playable prototypes by iterating between code edits and visual checks (screenshots/video), guided by tests.
- Sectors: gaming, indie tools
- Tools/products/workflows: Multi-tool agents with editor control, asset selection, and iterative test loops; “Game jam in a box”
- Assumptions/dependencies: Stronger multimodal perception (esp. spritesheets/shaders); robust editor automation APIs; guardrails
- Cross-engine generalization (Unity, Unreal) — Port the benchmark methodology and feedback tooling to other engines, enabling engine-agnostic evaluation and assistants.
- Sectors: gaming, software tooling
- Tools/products/workflows: Engine-specific MCP servers; unit-test harnesses for Unity/Unreal; cross-engine skill taxonomies
- Assumptions/dependencies: Licensing and API access; deterministic testing in other engines; community adoption
- AI technical artist/level designer services — Specialized agents that handle shaders, VFX tuning, tilemaps, camera rigs, and animation state machines under human supervision.
- Sectors: gaming, creative tools
- Tools/products/workflows: Role-specific agents; asset library retrieval; scene graph editing policies
- Assumptions/dependencies: Higher success rates on graphics categories; reliable resource assignment; IP-safe asset usage
- Automated multimodal QA at scale — Continuous agents that play, observe, and assert correctness on visual/physics/UI goals, generating interpretable repro steps and patches.
- Sectors: gaming, software QA
- Tools/products/workflows: Hybrid unit/integration tests + game-playing bots; telemetry-informed bug report synthesis; patch proposal bots
- Assumptions/dependencies: Stable test coverage; sim-to-play parity; sandboxed execution
- RL/finetuning from editor state — Train agents directly in the editor with dense multimodal feedback (video + inspector state) to learn common game-dev patterns and reduce recurring errors.
- Sectors: AI research, gaming
- Tools/products/workflows: Editor-as-environment gym; offline datasets of trajectories; reward functions from tests
- Assumptions/dependencies: Scalable data collection; safe exploration in editors; compute budgets
- Standardized claims and certification — Policy frameworks that require benchmark-backed evidence for “AI can build games” claims; disclosures of cost–performance and failure modes.
- Sectors: policy, standards, procurement
- Tools/products/workflows: Certification suites; reporting templates by task category; third-party evaluators
- Assumptions/dependencies: Multi-stakeholder governance; stable benchmark versions; anti-gaming safeguards
- Accessibility and compliance auditors — Agents that verify camera visibility, UI contrast/legibility, collision fairness, and input mappings against guidelines, using deterministic tests plus visual review.
- Sectors: gaming, accessibility compliance
- Tools/products/workflows: Rule packs for accessibility checks; auto-generated remediation suggestions; periodic compliance scans
- Assumptions/dependencies: Formalized rulesets; accurate visual/physics inference; organizational uptake
- Enterprise-scale AI-assisted pipelines — Integrated copilots across programming, art, audio, and QA, orchestrated by task type with automated cost/performance routing and approvals.
- Sectors: gaming (AAA/AA), enterprise software
- Tools/products/workflows: Orchestrators that choose models/frameworks per category; governance/approvals; audit logs
- Assumptions/dependencies: Security, IP controls; robust change management; developer trust
- Education: adaptive tutors that “watch the editor” — Tutors that interpret students’ scene graphs, animations, and code to give stepwise hints and targeted practice tasks.
- Sectors: education/EdTech
- Tools/products/workflows: Live editor state capture; hint generation from failed tests; mastery tracking by benchmark taxonomy
- Assumptions/dependencies: Privacy controls; reliable multimodal understanding; classroom integration
- Asset pipeline validation — Deterministic tests that validate asset correctness (scale/origin, animation frames, shader parameters) before assets enter production branches.
- Sectors: gaming, DCC pipelines
- Tools/products/workflows: Preflight checks; auto-fix proposals; asset metadata enforcement
- Assumptions/dependencies: Standardized asset schemas; reproducible renders; team conventions
- Marketplace integrations for AI task solvers — Platforms where studios submit benchmark-like tasks and receive agent-produced patches with test proofs and visual evidence.
- Sectors: gaming, B2B marketplaces
- Tools/products/workflows: Task packaging standards; escrow/testing verification; reputation systems for agents/providers
- Assumptions/dependencies: Legal/IP frameworks; secure code handling; liability models
- Transfer to simulation-heavy domains — Apply the deterministic multimodal-testing recipe to CAD/CAE, digital twins, and robotics simulators where visual/physics assertions are needed.
- Sectors: robotics, manufacturing, AEC
- Tools/products/workflows: Simulator-specific test harnesses; scene/mesh assertions; video-based feedback loops
- Assumptions/dependencies: Simulator APIs; determinism controls; domain expertise for test design
- App store preflight checks — Automated conformance testing (basic visuals, collisions, camera bounds, UI responsiveness) to reduce post-release defects.
- Sectors: distribution platforms, compliance
- Tools/products/workflows: Submission gates running visual/physics test suites; automated reports for developers
- Assumptions/dependencies: Platform policy alignment; false positive management; engine coverage
- Safety and security sandboxes for agent tools — Hardening of editor automation (MCP, video capture) with permissions, resource quotas, and audit trails to safely run agents on local projects.
- Sectors: platform/security
- Tools/products/workflows: Sandboxed Godot runners; per-task resource limits; provenance tracking for edits
- Assumptions/dependencies: OS/container support; secure API surfaces; organizational security posture
These applications build directly on the paper’s key contributions: a publicly released, complex, multimodal, deterministically testable benchmark; an automated tutorial-to-task pipeline; and simple but effective visual feedback loops (editor screenshots and runtime video) that consistently improve agent performance.
Glossary
- Agentic: Relating to autonomous, goal-directed behavior by AI agents that plan and execute multi-step tasks. "Game development combines many desirable characteristics for a challenging benchmark in a modern agentic domain."
- AnimatedSprite2D: A Godot node that plays 2D sprite animations by switching frames according to an animation resource. "specific nodes such as an AnimatedSprite2D and CapsuleCollider handle animations and physics respectively."
- CapsuleCollider: A capsule-shaped physics collider used in game engines (e.g., Godot) to define an entity’s collision bounds. "specific nodes such as an AnimatedSprite2D and CapsuleCollider handle animations and physics respectively."
- Collider: A physics component that defines a shape for collision detection and physical interactions. "setting up a collider to allow for jumping on enemies such as turtles,"
- Contextual editors: Tool panels in Godot that appear based on the selected resource (e.g., animation, audio, shader, tileset) to provide specialized editing controls. "Contextual editors appear on the bottom panel depending on what the user is editing (Figure~\ref{fig:editor}, bottom)."
- Deterministically verifiable: Able to be checked in a consistent, repeatable way through code or tests that produce the same outcome. "task solutions are deterministically verifiable through code"
- Frontier models: The most capable, state-of-the-art AI models at the leading edge of performance. "The gap between frontier and non-frontier models is sharp"
- HUD: Heads-up display; an in-game overlay that presents user interface elements like health, score, or minimaps. "HUD layout, Menu navigation, UI theming"
- LLM-as-a-Judge: An evaluation approach that uses a LLM to assess solution quality instead of deterministic tests. "LLM-as-a-Judge"
- Model Context Protocol (MCP): A protocol for tools to supply context to models; used here for an editor-screenshot server that feeds visual state to the agent. "via a Model Context Protocol (MCP) server"
- Node tree: The hierarchical structure of nodes (game objects) in Godot that defines scene composition and parent–child relationships. "the node tree"
- Non-player characters (NPCs): Game-controlled characters that are not operated by a human player. "which replaces the non-player characters (NPCs) and opponents."
- pass@1: A metric reporting the percentage of tasks solved on the first attempt without retries. "pass@1"
- Procedural content generation: The automated creation of game assets or levels through algorithms or models rather than manual design. "procedural content generation"
- Shader: A GPU program used to compute rendering effects, materials, and visual transformations in 2D/3D graphics. "shader usage"
- Signal: An event mechanism (e.g., in Godot) for loosely coupling components by emitting and handling events across nodes. "signals that trigger between various files"
- Skeletal animation: An animation technique that drives meshes via bone hierarchies to produce articulated motion. "Skeletal animation"
- Spritesheet: A single image that packs multiple sprite frames used to assemble animations efficiently. "add a walking animation using the given spritesheet"
- TileMap: A grid-based system for composing 2D levels from reusable tiles, often used for platformers and top-down maps. "TileMap setup"
- Tileset editor: Godot’s specialized editor for defining tiles, collisions, and metadata used by TileMaps. "tileset editors"
- Unit tests: Small, automated tests that verify specific, isolated pieces of functionality. "unit tests must only test for features explicitly requested in the instructions."
Collections
Sign up for free to add this paper to one or more collections.

