- The paper presents a method that converts autoregressive decoders into bidirectional encoders using a diffusion noise objective for improved embedding.
- It details a multi-stage contrastive training pipeline, including contextual chunk and triplet training with hard negatives to refine performance.
- Quantitative benchmarks reveal competitive retrieval metrics and high storage efficiency through native INT8 and binary quantization techniques.
Diffusion-Pretrained Dense and Contextual Embeddings: An Expert Review
Architectural Overview and Training Methodology
The paper introduces \pplxfamily, a suite of multilingual dense embedding models trained with multi-stage contrastive learning atop diffusion-pretrained LLM backbones. The motivation stems from the limitations of autoregressive LLMs for embedding tasks, notably their unidirectional context handling. Diffusion LLMs, by contrast, utilize bidirectional attention, thus facilitating comprehensive global document context modeling.
A key innovation is the continued pretraining of autoregressive (decoder-only) Transformer models on a diffusion noise objective, effectively converting them into bidirectional encoders. The models (\pplx and \pplxcontext) are released at two parameter scales: 0.6B and 4B. The training pipeline comprises four branched stages—continued diffusion pretraining, contrastive pair training, contextual chunk training, and triplet training with hard negatives—followed by Spherical Linear Interpolation for model merging, enabling robust geometric alignment in embedding space.
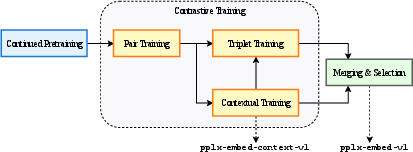
Figure 1: Schematic illustration of the multi-stage training pipeline in \pplx and \pplxcontext models.
Mean pooling is used as the default, facilitated by bidirectional attention, and further combined with native INT8 and binary quantization-aware training. Quantization is employed throughout both training and inference, using straight-through gradient estimation for differentiable rounding and yielding highly storage-efficient embeddings.
Diffusion Pretraining and Pooling Strategies
Diffusion-based pretraining disables causal masking and introduces a reversible corruption process, where each token is replaced with an absorbing [MASK] state with probability t∼U(0.001,1). Models are trained on a token-wise cross-entropy loss scaled by $1/t$, enhancing bidirectional context acquisition. Pretraining is performed on a balanced mix of FineWeb-Edu and FineWeb2(-HQ) datasets spanning 30 languages, totaling 250B tokens.
For pooling, token-level representations are mean-pooled and quantized using a scaled tanh operation, producing compact signed INT8 embeddings. Binary quantization is also supported, with minimal performance loss especially in larger models.
Contrastive and Contextual Training Paradigms
The contrastive curriculum uses InfoNCE loss variants:
- Pair training aligns queries and documents while mitigating false negatives via similarity threshold masking.
- Contextual training targets chunk-level embeddings that incorporate global document context, using dual-objective local/global losses and sophisticated masking strategies for chunk/duplicate handling.
- Triplet training operates with in-batch hard negatives to sharpen boundary learning in the embedding space.
LLM-based data synthesis pipelines generate high-quality multilingual and diverse query-document pairs for each stage, building upon approaches such as top-k persona extraction from web-scale corpora.
Benchmarking and Quantitative Results
Extensive evaluation encompasses both public and in-house web-scale retrieval scenarios. On the MTEB Multilingual v2 benchmark, \pplx-4B achieves competitive or superior average nDCG@10 (69.66%) with INT8 quantization, matching Qwen3-Embedding-4B and outperforming Gemin-embedding-001 in both multilingual and code retrieval domains. Storage efficiency is notably superior, with 390 document embeddings per MB (INT8) and 3,125 per MB (BIN).
On MIRACL, \pplx-0.6B surpasses Qwen3-Embedding-0.6B in all language subsets; even post-bin quantization, it outperforms Qwen3 counterparts. Significant performance gains for smaller models are evident across multilingual and domain-specific retrieval benchmarks.
On ConTEB, \pplxcontext-4B sets new state-of-the-art, attaining an average nDCG@10 of 81.96%, outperforming voyage-context-3 and Anthropic Contextual models. Notably, binary quantization only reduces scores by ~1% in 4B variants.
BERGEN RAG evaluations index over 24M passages, showing \pplx-4B surpassing Qwen3-Embedding-4B in four of five QA tasks; even \pplx-0.6B beats Qwen3-Embedding-4B in several scenarios.
ToolRet assessments indicate \pplx-4B at 44.45% average nDCG@10, exceeding 7B baselines like NV-Embed-v1 and GritLM-7B. Internal Query2Query and Query2Doc benchmarks further demonstrate large real-world corpus recall—e.g., \pplx-4B achieves 88.23% Recall@1000 (English, 30M corpus).
Ablation Analysis: Diffusion vs. Autoregressive Pretraining
The ablation study systematically compares diffusion-pretrained bidirectional backbones vs. causally masked autoregressive Qwen3, with mean vs. last-token pooling (Figure 2). Diffusion-pretrained configurations yield consistently lower training loss and ~1% higher average retrieval scores on MTEB(En) and MIRACL tasks, emphasizing the practical superiority of bidirectional context modeling for dense embeddings.
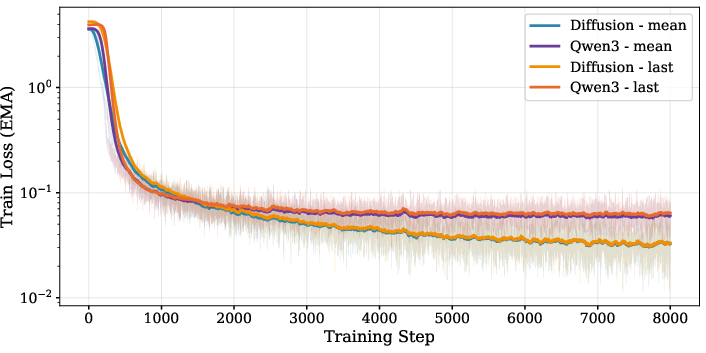
Figure 2: Training loss profiles demonstrate superior convergence of diffusion-pretrained, bidirectional models with mean pooling.
Storage and Efficiency Implications
Quantization-aware training enables direct inference of INT8 embeddings, providing several-fold gains in storage efficiency without compromising retrieval performance. Binary quantization incurs marginal loss for larger models (≤1.6%), but is harsher for smaller variants (up to 5%)—attributed to differences in output embedding dimensionality.
These attributes support scalable deployment in production retrieval systems, reducing infrastructure costs and latency under large corpus conditions, while maintaining strong recall and ranking performance.
Related Contextual Embedding and Diffusion Model Literature
\pplxfamily advances prior research in several ways:
- Leverages diffusion-pretrained encoders for retrieval as opposed to autoregressive decoders [austin2021d3pm, nie2025llada, gong2025cpt].
- Employs multi-stage contrastive curriculum, incorporating quantization directly into optimization [fu2022contrastivequant, vera2025embeddinggemma].
- Implements contextual chunk training with dual-objective loss for both local and global retrieval [conteb, gunther2024latechunking].
Theoretical and Practical Implications
The integration of diffusion-pretraining and bidirectional attention in embedding models yields improved global context sensitivity, thereby enhancing both dense retrieval and contextual passage encoding. Quantization-aware design fundamentally expands storage and inference efficiency, with binary vectors enabling unprecedented document-per-megabyte ratios, facilitating practical scaling atop large corpora or API collections.
These advances suggest a paradigm shift for embedding model deployment in RAG pipelines, knowledge-intensive QA, and tool retrieval applications, enabling lightweight, efficient, and robust retrieval components for cascaded search systems.
The demonstrated resilience of larger models to aggressive quantization points toward further optimization of embedding dimensions and architecture to maximize information retention under compression—potentially informing future architectures for web-scale retrieval.
Conclusion
The paper rigorously develops and analyzes a new family of diffusion-pretrained, dense and contextual embedding models, empirically demonstrating their superiority in global context modeling, multilingual and domain retrieval, and storage efficiency. The proposed multi-stage contrastive curriculum and quantization-aware methodology set a new standard for scalable deployment of embedding models. Theoretical results and empirical benchmarks collectively advocate for broader adoption of diffusion-based bidirectional encoders in large-scale retrieval architectures, opening prospects for further innovation in embedding compression, cross-lingual alignment, and contextualized passage representation.