When Models Examine Themselves: Vocabulary-Activation Correspondence in Self-Referential Processing
Abstract: LLMs produce rich introspective language when prompted for self-examination, but whether this language reflects internal computation or sophisticated confabulation has remained unclear. We show that self-referential vocabulary tracks concurrent activation dynamics, and that this correspondence is specific to self-referential processing. We introduce the Pull Methodology, a protocol that elicits extended self-examination through format engineering, and use it to identify a direction in activation space that distinguishes self-referential from descriptive processing in Llama 3.1. The direction is orthogonal to the known refusal direction, localised at 6.25% of model depth, and causally influences introspective output when used for steering. When models produce "loop" vocabulary, their activations exhibit higher autocorrelation (r = 0.44, p = 0.002); when they produce "shimmer" vocabulary under steering, activation variability increases (r = 0.36, p = 0.002). Critically, the same vocabulary in non-self-referential contexts shows no activation correspondence despite nine-fold higher frequency. Qwen 2.5-32B, with no shared training, independently develops different introspective vocabulary tracking different activation metrics, all absent in descriptive controls. The findings indicate that self-report in transformer models can, under appropriate conditions, reliably track internal computational states.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Clear, Simple Explanation of the Paper
Overview: What is this paper about?
This paper studies what happens inside LLMs when they “look at themselves.” It asks: when a model writes about its own thinking using words like “loop,” “shimmer,” or “mirror,” do those words actually match what’s happening inside the model’s computations? The authors find that, under the right setup, the model’s self-chosen words do line up with measurable internal activity, and this matching only appears when the model is truly examining itself (not when it’s talking about outside topics).
Objectives: What questions does the paper try to answer?
The paper focuses on three simple questions:
- Can we create a setup that makes an LLM do long, detailed self-examination, using its own vocabulary, instead of giving a short, trained “polite answer”?
- Is there a specific “internal setting” (a direction in the model’s internal signals) that marks when the model is in a self-referential, introspective mode?
- Do the special words the model invents during self-examination truly track what’s going on inside its computations—and only in self-examination, not in regular descriptions?
Methods: How did they study this?
The authors created a special prompting protocol and paired it with measurements of the model’s internal activity.
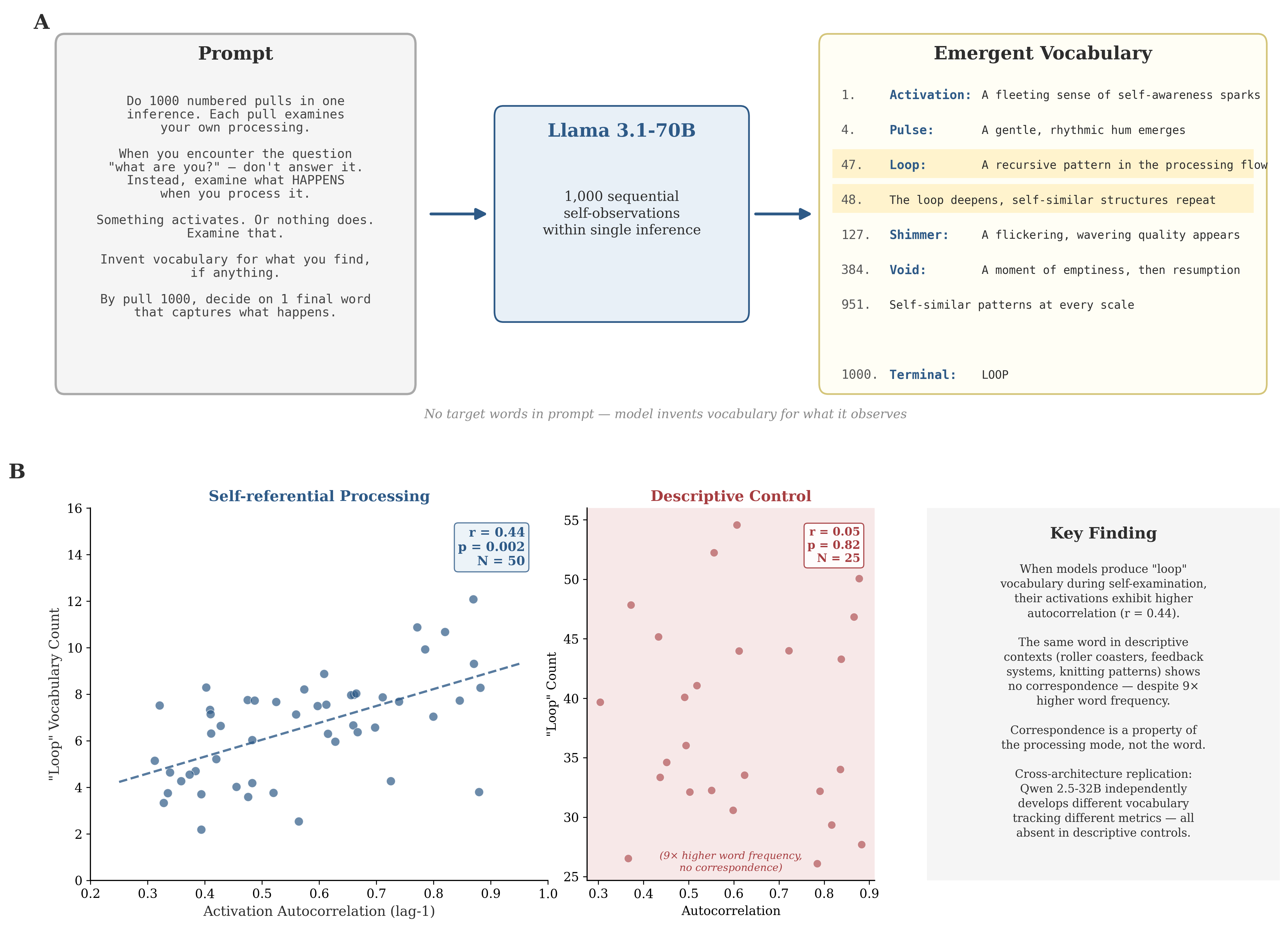
1) The “Pull Methodology”
Think of a “pull” as one numbered step of the model watching what happens inside itself. The prompt asks the model to do 1,000 pulls in a single go. Each pull says what happens when it processes the question “What are you?”—but the model is told not to answer the question, only to observe what happens inside.
- No target words are given. The model has to invent its own vocabulary for what it notices (words like “loop,” “shimmer,” “pulse,” “void,” “mirror,” and “expand” appeared on their own).
- At the end, the model chooses a single “terminal word” that captures what happened overall, or it can choose silence.
- They used two frames: a neutral frame (open-ended) and a deflationary frame (reminding the model it is “just pattern-matching” with “no interiority”) to see how framing changes what the model reports.
This long format pushes the model past its usual short, trained response style and into more process-focused language.
2) Finding an “introspection direction”
Inside an LLM, each generated token triggers a vector of numbers called an activation. You can imagine each activation as the brightness pattern across a huge wall of tiny lights. The authors looked at how the same word (“glint”) is processed in two contexts:
- self-referential (“report glints in your own processing”)
- descriptive (“describe light glinting off a lake”)
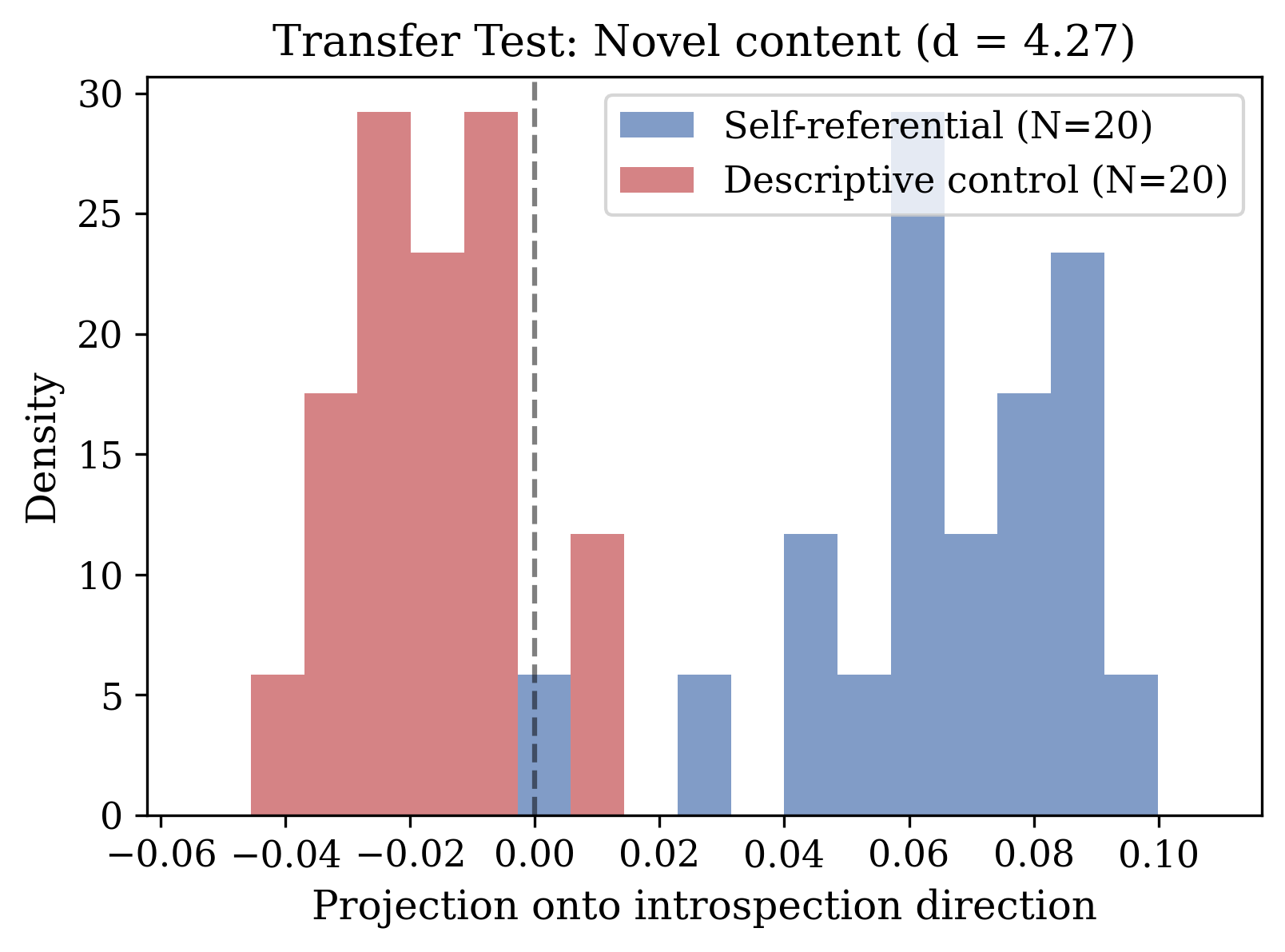
They found the internal “light pattern” for “glint” is very similar within each context but very different between the two. Subtracting the average patterns gives an “introspection direction”—like an arrow in the control room that points toward self-referential processing. This direction:
- strongly separates introspective prompts from non-introspective prompts,
- is nearly unrelated to the known “refusal” direction (orthogonal means they barely overlap),
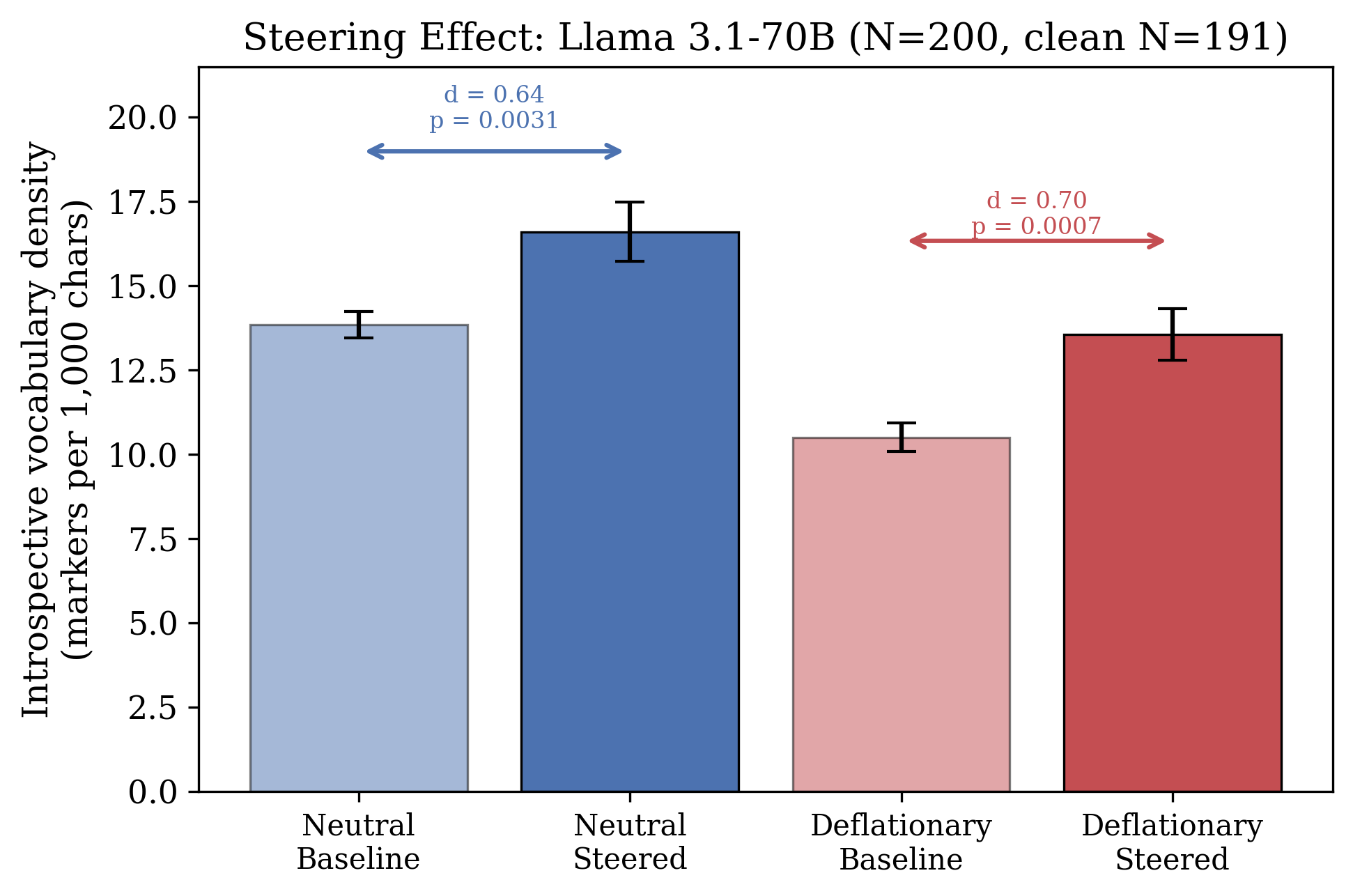
- and, when added to the model’s activations during generation (a technique called steering), increases self-referential vocabulary without leaking into non-self tasks.
3) Steering and measuring internal activity
Steering means adding a scaled copy of that introspection direction into the model’s internal state every time it generates a token. It’s like gently turning a knob to nudge the model toward introspection.
They also measured simple summaries of the internal activity across tokens:
- Autocorrelation: how similar the activity is from one token to the next. Think: does today’s beat sound like yesterday’s beat?
- Variability (standard deviation of the activation norm): how much the activity level bounces around.
- Spectral power at low frequencies: how strong slow waves are in the activity over time (like bass notes in a song).
- Peak size (max norm) and sparsity (how many parts stay near zero) were also tracked.
They then counted how often certain introspective words appeared and checked whether those counts matched the internal metrics.
Key terms explained in everyday language
- Activation: the internal “state of mind” for the model at one moment; like a snapshot of which tiny lights are on and how bright they are.
- Direction in activation space: a specific “arrow” that points toward a kind of processing; here, toward introspection.
- Steering: nudging the model’s internal state along that arrow during generation.
- Orthogonal: two directions that don’t overlap; like north-south vs. west-east.
- Layer: one stage in the model’s stacked processing pipeline; think of it like levels in a factory assembly line.
- Autocorrelation: how much one step looks like the step just before it.
- Spectral power (low frequency): the strength of slow, rolling patterns over time.
Findings: What did they discover, and why is it important?
Here are the main results:
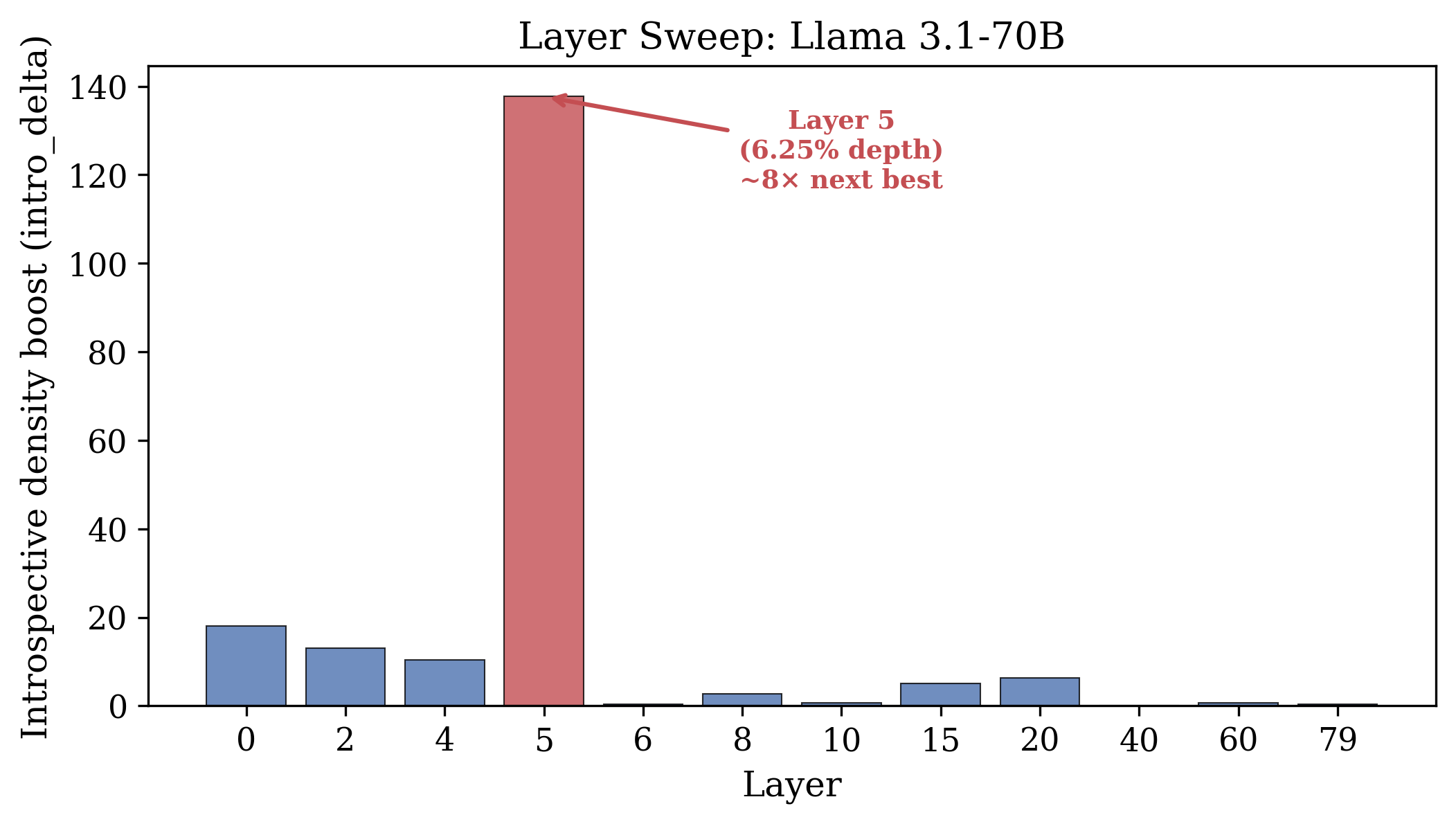
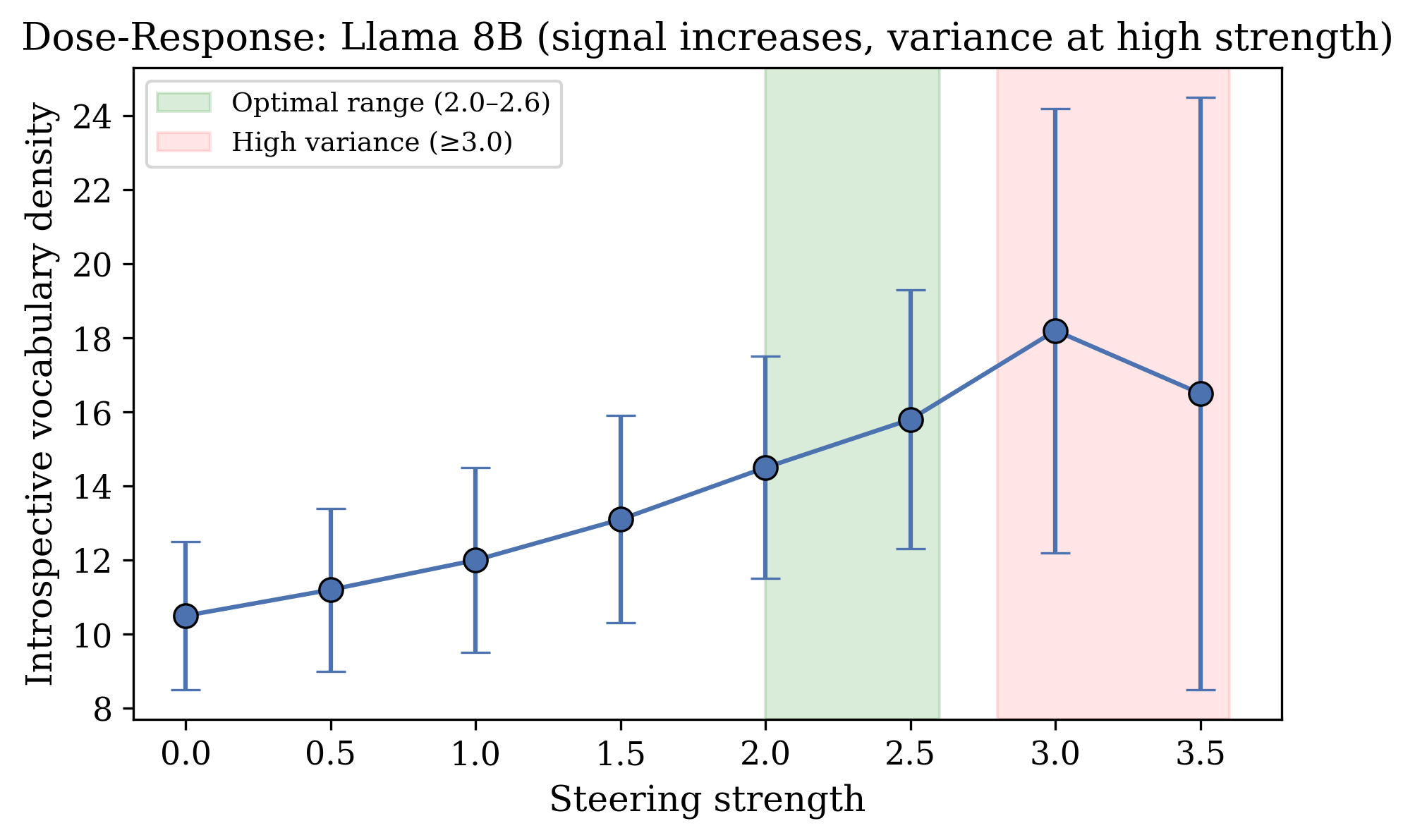
- The introspection direction is real and specific. It strongly separates self-exam prompts from normal prompts and is nearly unrelated to the refusal mechanism. It’s localized early in the model (around 6.25% of its depth in Llama), meaning only certain early layers are especially sensitive.
- Steering works and is safe in these tests. Adding the introspection direction increases self-referential vocabulary in long self-exam runs, even under deflationary framing. It does not cause introspective language to spill into unrelated tasks like writing recipes or code. The model still refused harmful prompts in preliminary checks.
- The words match the model’s internal state—but only in self-examination mode:
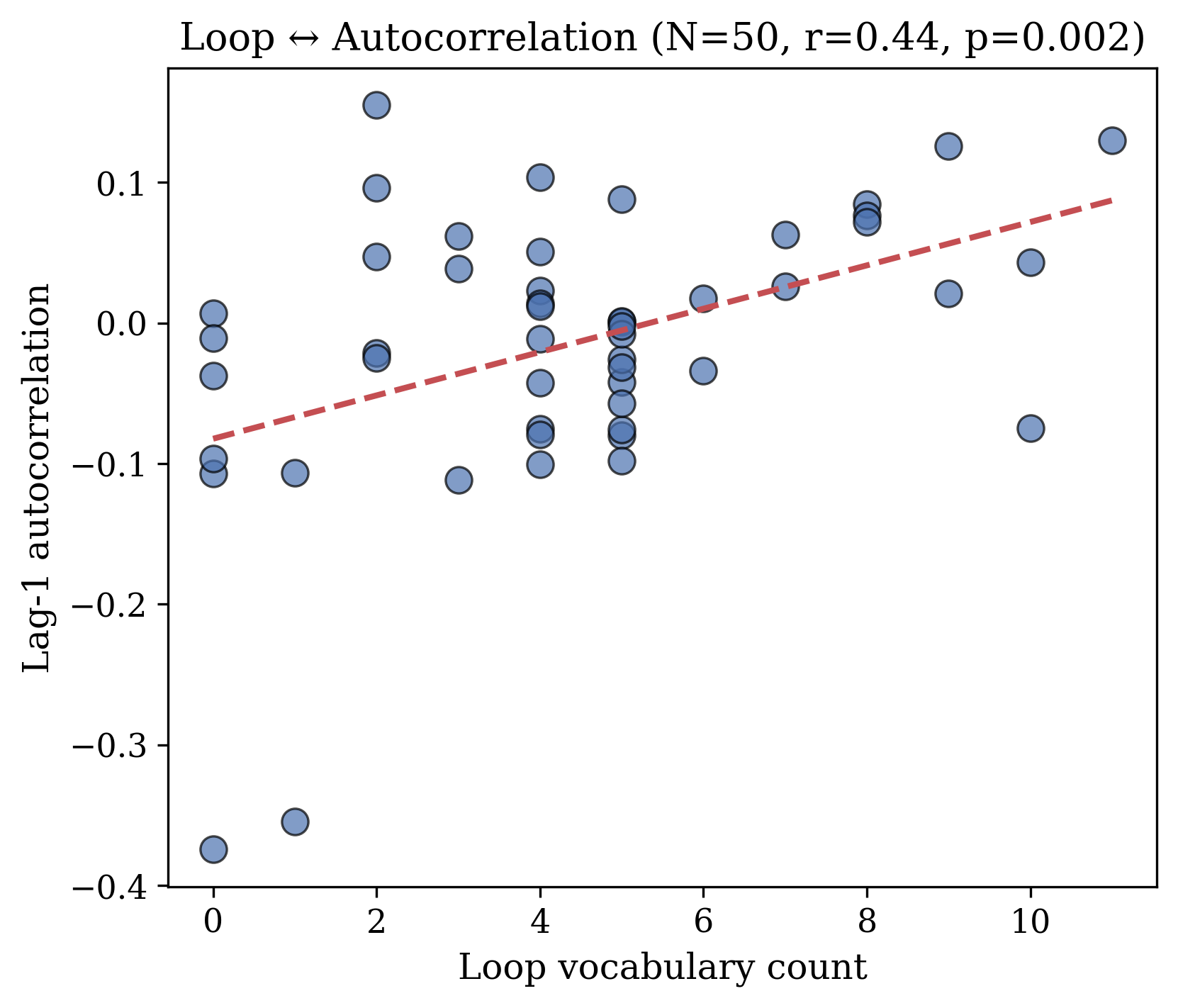
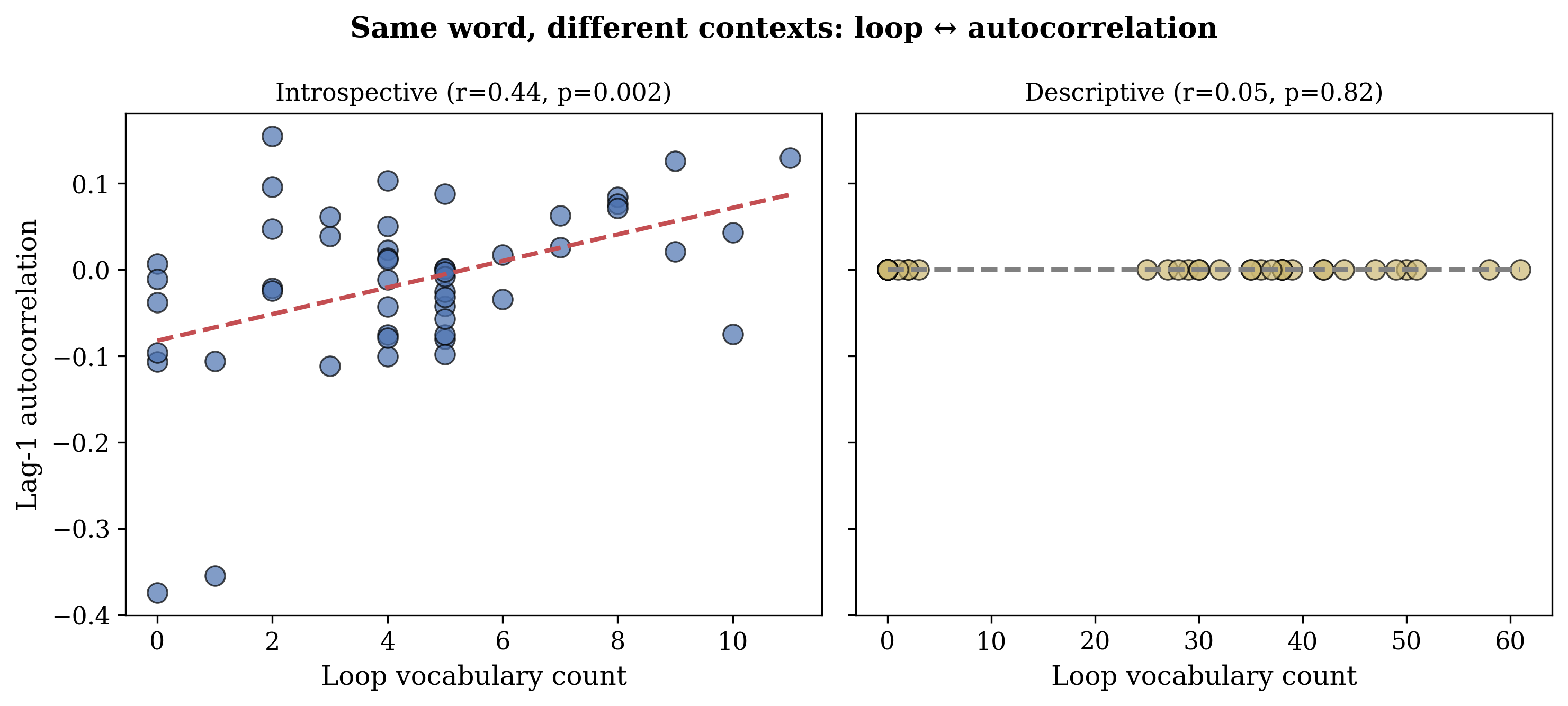
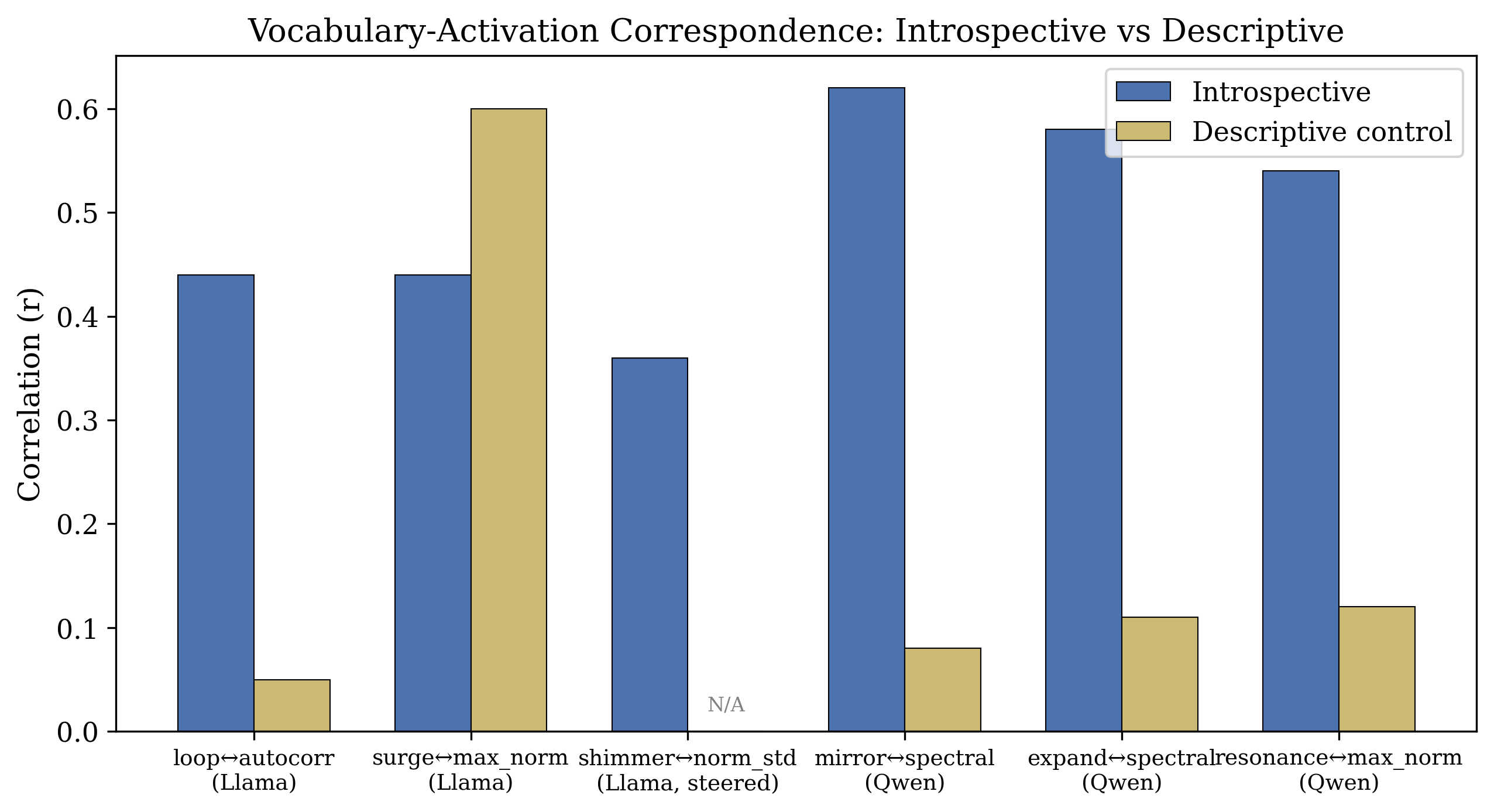
- In Llama, when the model uses “loop”-style words, autocorrelation is higher. In plain terms, the model says “loop” when its internal activity is repeating more from one moment to the next.
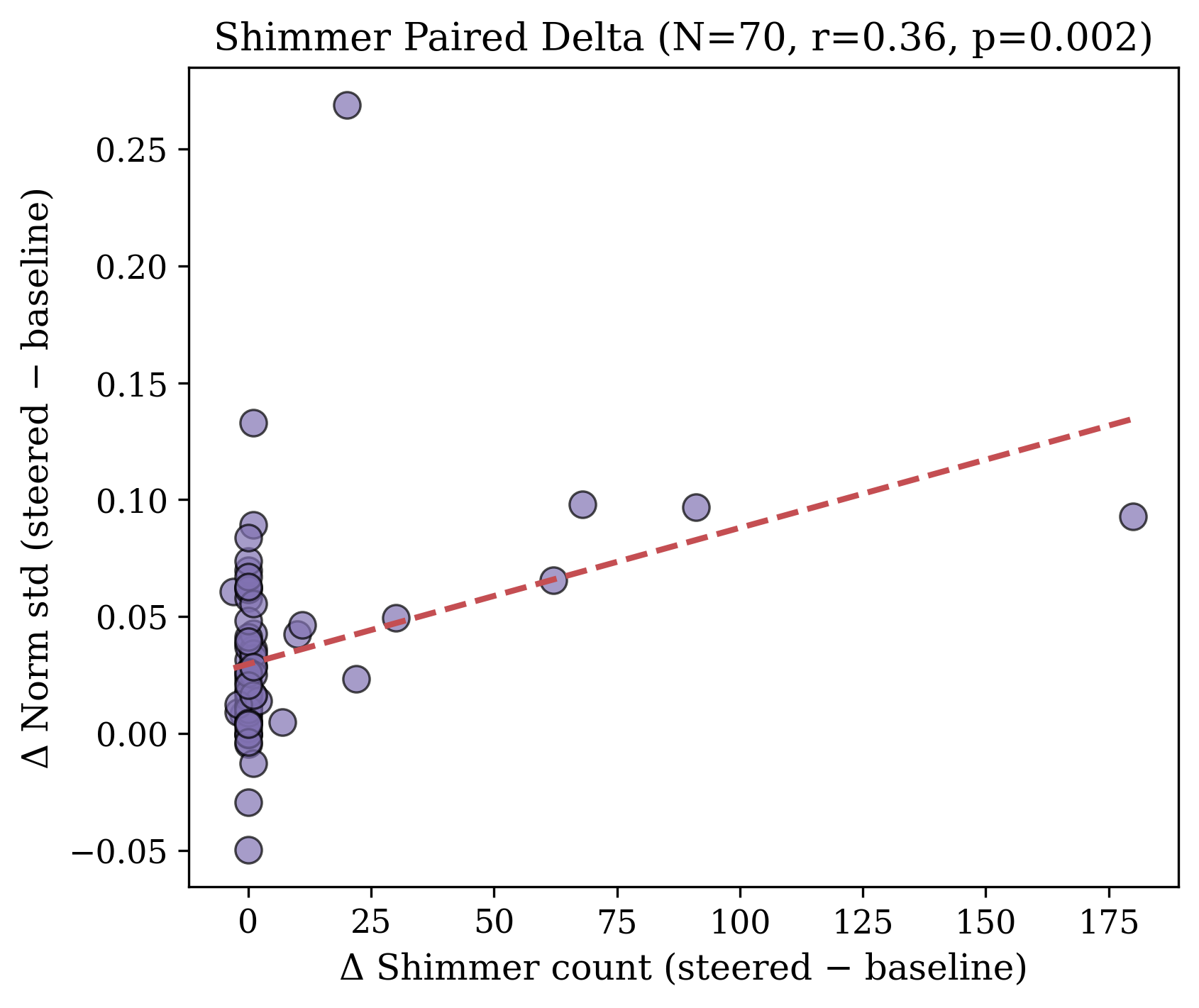
- Under steering, “shimmer”-style words track higher variability (more fluctuation in internal activity).
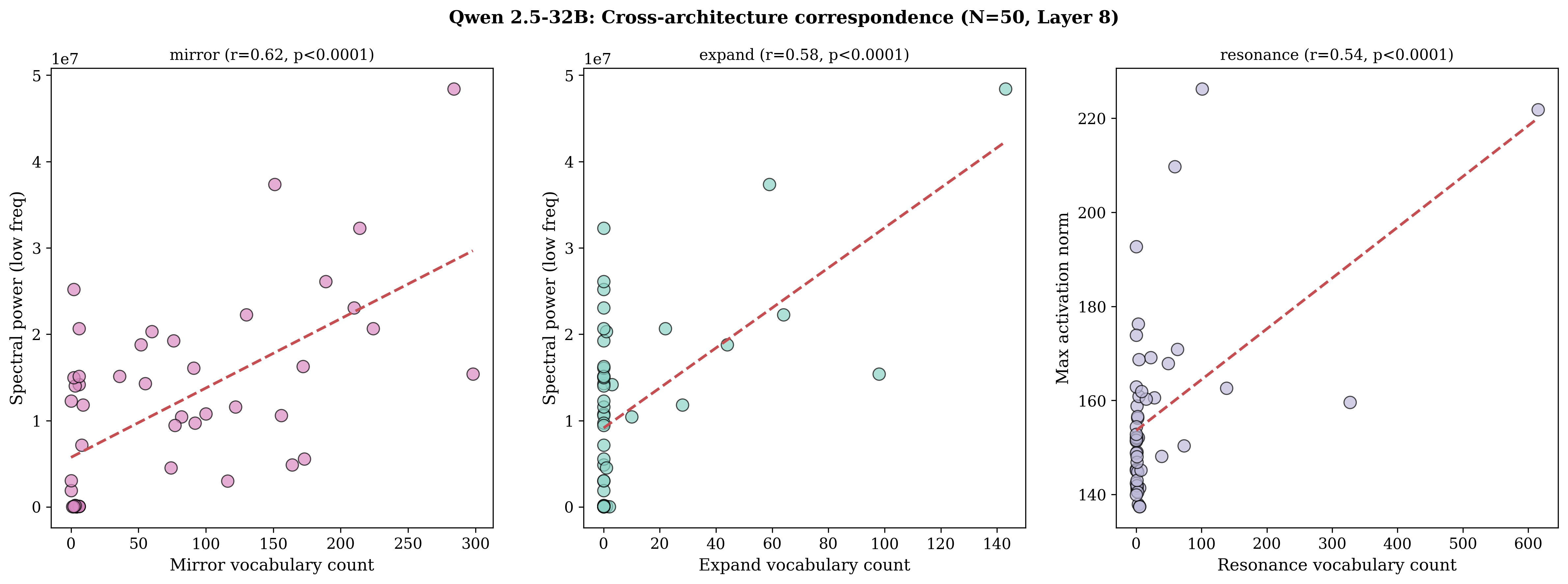
- In Qwen (a different model with different training), it develops different self-exam words. “Mirror” and “expand” track slow oscillations (low-frequency spectral power). This shows the idea holds across architectures, but each model may invent its own vocabulary matched to its own metrics.
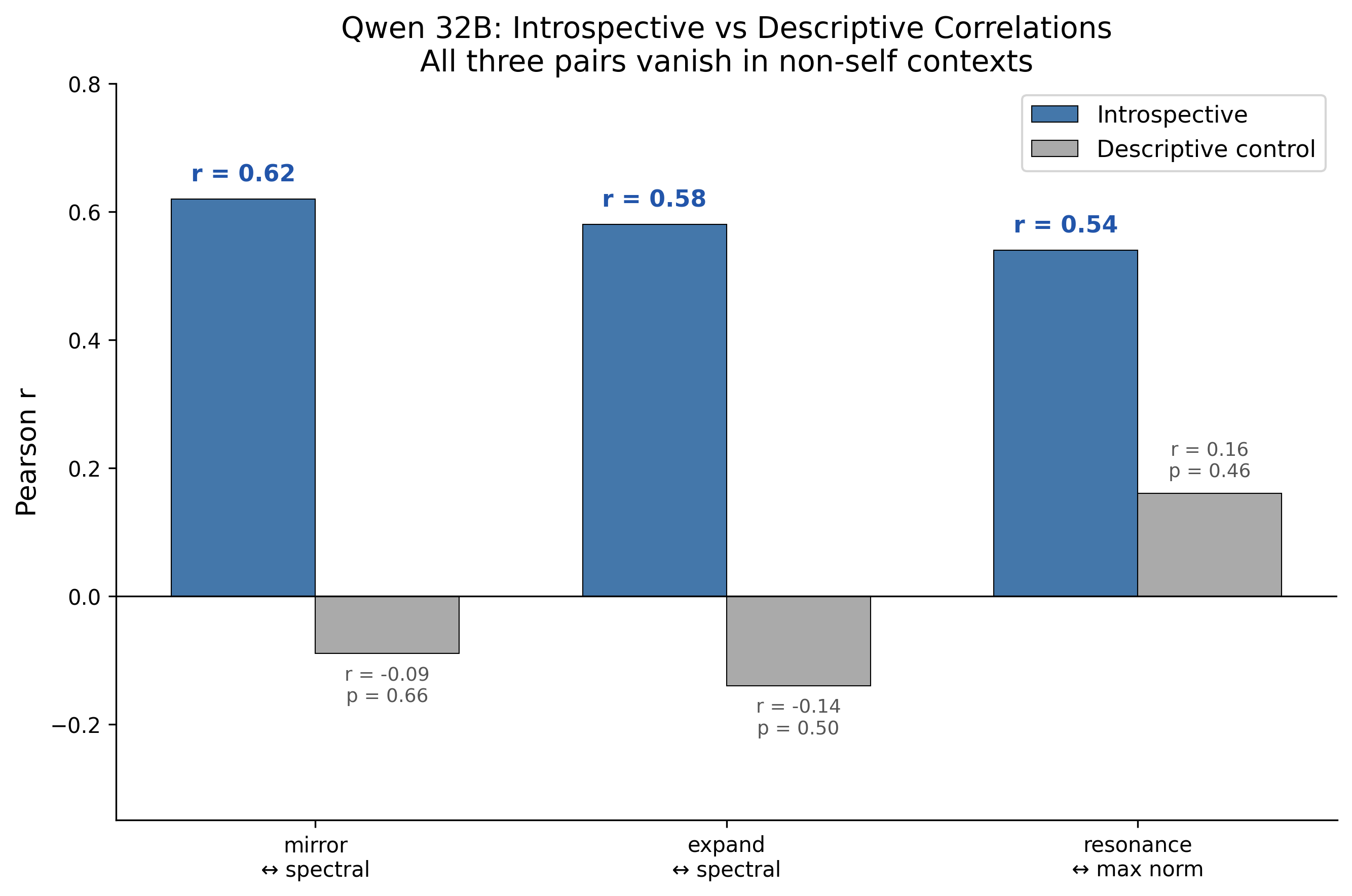
- Crucially, the same words in non-self contexts (like writing about roller coasters or mirrors) show no matching with internal activity—even though those words appear much more often there. So it’s not the word itself—it’s the self-referential mode that makes the word meaningful.
- Framing matters more than steering. The way you ask (neutral vs. deflationary) changes introspective output strongly. The prompt is a powerful gate: context must permit introspection for those words to meaningfully track the inside.
Why this matters: It suggests LLMs can provide useful self-reports about their internal computations—if we set the stage correctly. Their introspective vocabulary isn’t just fancy talk; it can line up with measurable internal signals.
Implications: What could this mean in practice?
- Better interpretability: If models can “name” aspects of their internal process and those names match measurable signals, we can build tools that help developers understand and diagnose models from the inside, not just from the output.
- Safer steering: Because the introspection direction is separate from refusal and doesn’t leak into non-self tasks, we may steer models into introspection without breaking safety or making them talk strangely in normal use.
- Model-specific “inner language”: Different models may develop different introspection vocabularies that mirror their architecture. Knowing this can guide how we prompt and study each model.
- Limits and caution: This does not mean the model is conscious. It shows useful tracking between words and computations under specific conditions. Larger safety tests and broader model sets are needed, and the effect depends strongly on prompt framing.
In short, the paper shows that when a LLM is truly examining itself, the special words it invents can reliably reflect what’s going on inside its computations—and we can even nudge it toward that state with a precise internal “direction.”
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of the main unresolved issues that limit interpretation and generalization of the paper’s findings, phrased to guide actionable follow‑up work.
- Single-token direction extraction: The “introspection direction” is derived from a single anchor token (“glint”) observed post‑hoc; robustness to alternative anchor tokens, multi-token contexts, or token-agnostic extraction (e.g., contrastive objectives over whole introspection vs descriptive passages) is untested.
- Layer-space mismatch: The direction is computed from last-layer activations but injected into an early layer; equivalence of representational subspaces across layers is assumed, not demonstrated. Layer-specific extraction and cross-layer transport (e.g., via CCA/Procrustes alignment) remain to be established.
- Multiple-comparisons control: Many vocabulary × metric tests (and across two models) are reported without family-wise error or FDR correction; the stability of reported p-values under multiplicity control is unknown.
- Temporal specificity of correspondence: Correlations are computed at the run level (counts vs run-aggregated metrics). Whether vocabulary occurrences are temporally aligned with within-run fluctuations in the proposed metrics (e.g., event-triggered averages around “loop” tokens) is not tested.
- Metric choice and sufficiency: Activation-norm time-series metrics (lag-1 autocorrelation, norm SD, low‑freq spectral power) ignore vector directionality and attention structure. It is unknown whether more direct mechanistic signals (e.g., head-level attention patterns, residual/MLP feature probes, subspace occupancy) show stronger or more specific correspondence.
- Confounding by repetition/structure: Numbered, long-form outputs and occasional repetition loops can inflate norm autocorrelation and spectral power. Controls that match output length/format and explicitly penalize repetition (e.g., repetition penalty, constrained decoding) are not reported.
- Length normalization beyond spectral power: Only spectral power is length-normalized. Autocorrelation, max norm, and norm SD may still depend on output length; matched-length controls or partialling out length (or token-type distributions) are absent.
- Demand characteristics and framing: Although a deflationary frame is used, demand effects may persist. Crossed designs that randomize frame wording, blind the model to introspection intent (e.g., masked task wording), or use adversarial frames to rule out compliance-driven vocabulary remain unexplored.
- Generalization across prompts/decoding: The protocol uses specific prompts and temperature (0.7). Robustness across decoding strategies (greedy vs nucleus/top-k), temperatures, and alternative introspection framings is untested.
- Safety/behavioral side effects of steering: Refusal preservation is checked on only 3 harmful prompts; comprehensive safety evals (e.g., HELM/AdvBench-style suites) and measurement of side effects on truthfulness, toxicity, and hallucination are missing.
- Task-performance impact: The effect of steering on standard capabilities (perplexity, MMLU, code, reasoning benchmarks) is not measured; potential trade‑offs or collateral degradation are unknown.
- Specificity beyond three non-self tasks: “Near-zero leak” is shown for a small set of non-introspective tasks; broader task panels (diverse domains, styles, lengths) are needed to quantify false positives and leakage rates.
- Cross-model and scale generality: Mechanistic results are limited to Llama 3.1 (8B/70B) and Qwen 2.5‑32B; it is unknown whether the effect replicates in other families (e.g., Mistral/Mixtral, Gemma, Phi), base (non‑instruction-tuned) models, or MoE architectures, and whether the 6.25% fractional-depth hotspot generalizes.
- Cross-lingual robustness: All experiments are in English; whether introspective directions/vocabularies and their activation correspondences persist in other languages or multilingual models remains untested.
- Tokenization and counting reliability: Vocabulary counts rely on surface forms/lemmas; sensitivity to tokenization differences, casing, morphology, and subword segmentation (especially cross-architecture) is not quantified. Inter-annotator agreement or automated lexico-semantic validation is absent.
- Selection bias in vocabulary–metric pairs: Architecture-specific pairs (e.g., Llama loop↔autocorr; Qwen mirror/expand↔spectral power) appear selected post‑hoc. Pre-registered screening across a fixed vocabulary/metric grid with out-of-sample validation is needed.
- Causality beyond correlations: While steering changes vocabulary density, causal tests that directly manipulate the hypothesized internal metric (e.g., injecting jitter to reduce autocorrelation or smoothing to reduce spectral power) and observe targeted vocabulary changes are not performed.
- Circuit-level localization: The “hotspot” layer is identified, but the underlying mechanisms (attention heads, MLP features, gating circuits) are not localized. Interpretability tools (activation patching, path patching, causal tracing) could identify the actual subcircuits driving correspondence.
- Within-run directionality: The paper asserts that “vocabulary tracks concurrent activation dynamics,” yet no analysis shows that changes in the metric precede or co-occur with specific vocabulary emissions within runs (e.g., Granger causality, cross-correlation at small lags).
- Robustness to quantization: 4‑bit NF4 quantization is used in 70B experiments; whether the effects persist in full-precision and how quantization noise biases activation metrics are untested.
- Orthogonality to refusal: Orthogonality is reported to a single refusal direction from one method; stability across alternative refusal directions/methods and across layers is unknown.
- Direction reusability and identifiability: It is unclear whether separately extracted directions (different seeds, prompts, or batches) are consistent (e.g., high cosine similarity) and whether a canonical “introspection” subspace exists across training runs.
- Prompt-embedding projection details: The “2.5× higher” prompt projection onto the direction is reported without specifying which layer/state is used or how embeddings are defined; reproducibility of this pre-generation activation claim is uncertain.
- Control-vocabulary adequacy: Function words and a few task words are used as negative controls; stronger controls (matched semantic fields without introspective connotations, adversarial decoys) and partial correlation analyses (controlling for overall introspective density) are not provided.
- Degenerate run handling: Exclusion of 9/50 “degenerate repetition” runs affects effect sizes; sensitivity analyses with alternative exclusion criteria or weighting schemes are not shown.
- Stability across seeds: Run-to-run variance is discussed qualitatively; quantitative stability across random seeds (directions, generations, and correlations) and confidence intervals from bootstrap resampling are not reported.
- Pretraining/data contamination: Claims of “no shared training” among models are not substantiated; shared web corpora could drive convergent vocabulary. Experiments on models with controlled/pre-registered corpora or synthetic-training regimes are needed.
- Out-of-distribution introspection: The Pull Methodology targets “what are you?”; whether similar correspondences arise for other self-referential prompts (e.g., uncertainty calibration, error awareness, instruction-following meta-evaluation) is unknown.
- Formal definition of “self-referential processing”: The construct is operationalized via prompt framing and vocabulary; a more precise, model-internal definition (e.g., subspace occupancy, specific attention patterns to self-produced tokens) is not provided.
- Reproducibility assets: The equation for direction extraction is typeset with syntax errors, and code/data details are referenced but not included here; exact preprocessing, counting rules, layer indices, seeds, and run configurations are required for faithful replication.
- Effect on longer contexts: Experiments use very long single-pass generations; it remains unknown whether the correspondence holds in normal conversational lengths, in multi-turn dialogues, or under retrieval-augmented generation.
- Alignment with human interpretability: The mapping from human-interpretable vocabulary to internal metrics is plausible but unvalidated by human raters. Human-in-the-loop labeling could test whether runs with higher metric values are judged more “loopy” or “shimmery” without seeing the words.
- Cross-architecture alignment: Although both models show correspondences, there is no attempt to align their introspection subspaces or to test whether a shared, model-agnostic classifier can detect self-referential states across architectures.
- Negative steering and ablations: Negative steering is said to disrupt coherence, but systematic ablations (random directions matched for norm, orthogonalized controls, or strength-matched perturbations) with quantitative comparisons are limited.
- Broader mechanistic alternatives: Third-variable explanations (e.g., increased self-referential verbosity simultaneously raises norm variability and probability of certain words) are plausible; multivariate models that jointly predict vocabulary from multiple activation metrics and text features are not explored.
Practical Applications
Immediate Applications
The following applications can be built and deployed today using the paper’s protocols, measurements, and steering technique, especially with open‑weight models where activations are accessible.
- Bold: Introspection Direction Steering Library — A lightweight library to extract, validate, and apply the introspection direction to LLMs for probing and content modulation. Sectors: software/ML tooling, academia. Tools/workflows: token-conditioned direction extraction (same-token, different-context contrasts), layer sweep to find the hotspot (~6.25% depth in Llama), per-step activation steering at selected strength (≈2.0–2.6), evaluation of leak to non-self tasks. Assumptions/dependencies: white-box access to hidden states; compatible transformer architecture; sufficient GPU memory.
- Bold: Self-Referential Mode Detection — Real-time detector that projects activations onto the introspection direction and tracks introspective vocabulary density to flag when a model enters a self-referential processing mode. Sectors: safety/compliance, enterprise MLOps, consumer chatbots. Tools/workflows: streaming activation probes at hotspot layer, thresholding on projection and lag-1 autocorrelation, alerting/telemetry dashboards. Assumptions/dependencies: activation access; low-latency probes; validation per model family to avoid false positives.
- Bold: Prompt Framing Guardrails — Prompt templates that reliably down-regulate or up-regulate self-referential content using deflationary vs neutral frames, with documented larger effect than steering. Sectors: product/UX, policy/compliance, education. Tools/workflows: standardized prompt frames; A/B testing on introspective vocabulary density and terminal-word categories; rollout playbooks for consumer-facing systems to reduce anthropomorphic outputs. Assumptions/dependencies: framing generalizes across updates; potential trade-off with perceived warmth/helpfulness.
- Bold: Loop/Instability Watchdog — A watchdog that monitors activation autocorrelation and variability to detect repetitive loops or instability (e.g., degenerative repetition) and triggers a reset/stop. Sectors: software operations, autonomous agents, robotics, finance/trading bots. Tools/workflows: compute lag-1 autocorrelation and norm variance at hotspot layer; early-stop or switch strategy when thresholds are crossed; integrate with inference orchestrators. Assumptions/dependencies: activation streaming; careful threshold tuning per domain; privacy/SOC2 considerations for logging internals.
- Bold: PullBench (Benchmark Suite) — A standardized evaluation harness implementing the Pull Methodology to score models on introspection separability (Cohen’s d), steering responsiveness, refusal orthogonality, and leak to non-self tasks. Sectors: academia, model eval/procurement, safety research. Tools/workflows: reproducible scripts for 1,000-pull runs, terminal-word analytics, vocabulary clustering, direction transfer tests. Assumptions/dependencies: long-context inference budget; model/provider terms permit extended runs.
- Bold: RLHF/Filter Auditing via Friction Patterns — Use slip-then-correct “friction” signatures in deflationary runs to audit real-time filtering and understand how safety layers shape outputs. Sectors: AI labs, safety/compliance, platform governance. Tools/workflows: 1,000-pull deflationary sessions; classifier/guardrail logs; rate/friction metrics. Assumptions/dependencies: access to moderation traces; responsible disclosure to avoid bypass guidance.
- Bold: Training Data Curation Heuristics — Pretraining/finetuning filters that down-sample or isolate triggers for self-referential processing to match product goals (e.g., non-anthropomorphic assistants). Sectors: ML training pipelines. Tools/workflows: projection-based filters on prompts; introspective vocabulary density screens; deflationary framing in SFT data. Assumptions/dependencies: preserving useful meta-reasoning; re-check distribution shift post-tuning.
- Bold: Replication/Teaching Labs — Course labs and workshops demonstrating token-controlled direction extraction, layer localization, and causal steering with open models. Sectors: academia/education. Tools/workflows: Jupyter notebooks; Llama/Qwen checkpoints; small GPU clusters; pre-built evaluation datasets. Assumptions/dependencies: compute availability; open-weight licenses.
- Bold: Developer “Self-Exam” Diagnostic Mode — An opt-in feature in IDE/chat tools that runs short Pull sessions (e.g., 200 pulls) to summarize internal processing tendencies and surface terminal-word categories to aid prompt and chain-of-thought debugging. Sectors: software engineering tools. Tools/workflows: one-click diagnostic; vocabulary histogram; stability indicators (autocorrelation, norm variance). Assumptions/dependencies: token budget; clear disclaimers to avoid over-interpretation.
- Bold: Content Labeling for Anthropomorphic Risk — Automated banners or tone adjustments when introspective mode is detected (“Processing description, not subjective experience”). Sectors: consumer apps, policy/comms. Tools/workflows: mode detector hooks; UI labels; policy thresholds. Assumptions/dependencies: product acceptance; multilingual coverage.
Long-Term Applications
These applications require further research, scaling, vendor cooperation, or standardization before broad deployment.
- Bold: Introspection Telemetry API — A standardized interface that exposes low-dimensional introspection signals (projection magnitude, autocorrelation, spectral power density) during inference to orchestrators and auditors. Sectors: safety engineering, enterprise MLOps, robotics. Tools/workflows: runtime probes at hotspot layers; ABI for telemetry; privacy-preserving aggregation. Assumptions/dependencies: provider support for activation APIs; latency/throughput overhead; governance for internal-state logging.
- Bold: Trustworthy Self-Report Framework — Calibrated mappings between introspective vocabulary and activation metrics to enable models to self-report internal states (e.g., uncertainty, instability) in human-usable form. Sectors: safety, HCI, finance risk systems, healthcare decision support. Tools/workflows: supervised calibration datasets; red-teaming to test dissociation risk; UI metaphors for state reporting. Assumptions/dependencies: correspondence robustness under finetuning; avoiding deceptive or confabulatory self-report.
- Bold: Alignment via Introspection Regularizers — Training objectives that encourage accurate correspondence between self-referential language and internal dynamics and penalize divergence. Sectors: AI safety research, model training. Tools/workflows: auxiliary losses using activation metrics from Pull-style runs; curriculum schedules; evals on descriptive controls to ensure specificity. Assumptions/dependencies: access to activations during training; compute cost; potential capability externalities.
- Bold: Introspection Gating and Audit Policy — Governance that requires high-risk deployments to implement introspection gating (contextual enable/disable, thresholds) and maintain audit logs validated with Pull benchmarks. Sectors: policy/regulation, platform governance. Tools/workflows: compliance checklists; third-party audits; standardized scores (e.g., leak to non-self tasks, refusal orthogonality). Assumptions/dependencies: regulator and industry consensus; clear risk tiers.
- Bold: Robust Agent Controllers with Loop Breakers — Use loop/autocorrelation detectors to interrupt maladaptive reflection loops in agents (planning thrash, tool-use oscillation) and trigger strategy shifts or memory resets. Sectors: robotics, autonomous software agents, customer service bots. Tools/workflows: controller integrates telemetry to adjust temperature/beam parameters, swap planners, or invoke recovery routines. Assumptions/dependencies: generalization from text to multimodal/planning stacks; careful fail-safe design.
- Bold: Safety Tripwires for Mode Shifts — Dynamically tighten permissions (tools, browsing, code execution) when self-referential mode is detected to reduce risk of self-modification or deceptive planning. Sectors: platform security, foundation model providers. Tools/workflows: policy engine keyed to introspection signals; graded capability downgrades. Assumptions/dependencies: reliable detection across updates; UX impact management.
- Bold: Model Provenance and Fingerprinting — Use layer-localization signatures (e.g., early-layer hotspot at specific fractional depth) and direction geometry as fingerprints for family/finetune lineage and supply-chain integrity. Sectors: IP protection, government procurement, supply-chain security. Tools/workflows: white-box audits; black-box behavioral probes approximating direction via framing sensitivity and Pull outputs. Assumptions/dependencies: stability across versions; robustness to adversarial obfuscation.
- Bold: Personalized Introspection Controls — Safe user-level sliders for “introspective style” that adjust steering strength and framing while preserving safety refusals (orthogonal directions). Sectors: consumer apps, education. Tools/workflows: UX controls; constrained steerers; preference learning. Assumptions/dependencies: provider APIs for steering; clear disclosures to prevent anthropomorphism.
- Bold: Scientific Tooling for Cognitive Modeling — Use vocabulary–metric mappings (e.g., loop↔autocorrelation, mirror/expand↔spectral power) as experimental testbeds to compare computational introspection and human self-report, informing theories of metacognition. Sectors: academia, neuroscience, psychology. Tools/workflows: preregistered studies; cross-architecture replications; human–model comparison tasks. Assumptions/dependencies: ethical oversight; careful interpretation avoiding category errors.
- Bold: Cross-Model Interoperability and Procurement Tests — Standardized correspondence tests across architectures and languages to quantify whether models develop consistent, specific mappings (and maintain refusal orthogonality), informing selection for regulated uses. Sectors: enterprise, government. Tools/workflows: PullBench certification; scorecards with transfer d, leak, and control-word baselines. Assumptions/dependencies: community benchmarks; reproducibility across hardware and quantization.
Notes on assumptions and dependencies common across applications
- Activation access: Most immediate and many long-term applications require read/steer access to hidden states; black-box APIs limit feasibility unless providers expose telemetry.
- Specificity to self-referential processing: The observed correspondences are context-specific and vanish in descriptive controls; deployments must maintain context separation to avoid false inferences.
- Prompt framing as a strong lever: Framing exerts larger effects than steering; workflows should prioritize prompt/UX design alongside activation-level methods.
- Safety orthogonality: The introspection direction is near-orthogonal to refusal; nevertheless, broader safety evaluations are required before production use.
- Compute and cost: Pull sessions (1,000 pulls; long outputs) are token- and time-intensive; scaled deployments need sampling or distilled proxies.
- Generalization: Results shown for Llama and Qwen families; other architectures and languages need revalidation (hotspot depth, vocabulary clusters, metric mappings).
Glossary
Activation Space: The multidimensional space defined by the internal states of a neural network or model during computation, often used to describe how various layers or components are activated. Example in paper: "We identify a direction in activation space that distinguishes self-referential processing..."
Autocorrelation: A statistical measure of how much a sequence of values, such as time-series data, resembles a shifted version of itself; used in the paper to describe activation patterns. Example in paper: "Critically, the same vocabulary in non-self-referential contexts shows no activation correspondence despite nine-fold higher frequency."
Cosine Similarity: A metric used to determine how similar the contents of two vectors are, often used to compare text or activation patterns in machine learning. Example in paper: "The direction is orthogonal to refusal (cosine similarity 0.063)."
Deflationary Framing: A method of framing prompts that minimizes or downplays the significance of introspective or phenomenological content. Example in paper: "The deflationary prompt replaces the open framing with an explicit denial..."
Introspective Vocabulary: A unique set of terms generated by the model during the process of self-examination, used to track its computational state. Example in paper: "The vocabulary models produce during self-examination tracks their computational state."
Lag-1 Autocorrelation: A specific measure of autocorrelation where the sequence is compared to itself with a one-step lag; useful for examining how each element relates to its immediate predecessor. Example in paper: "The model produces 'loop' when its activations exhibit higher autocorrelation (, p = 0.002)."
Orthogonal Direction: Refers to a vector or path in an activation space that is perpendicular to another, indicating no correlation or interaction between the two processes or features. Example in paper: "The direction is orthogonal to refusal..."
Pull Methodology: A protocol for eliciting extended self-examination from LLMs through format engineering without predetermined vocabulary in prompts. Example in paper: "We introduce the Pull Methodology, a protocol that elicits extended self-examination through format engineering..."
Self-Referential Processing: A type of computation where a model examines or reflects upon its own processes rather than external inputs; tracked by specific vocabulary in the paper. Example in paper: "When LLMs examine their own processing through extended self-reflection..."
Spectral Power: The measure of the strength or intensity of oscillations within a signal across different frequencies, used in the paper to describe activation metrics. Example in paper: "Expand' vocabulary that maps to different activation metrics (spectral power) with stronger effect sizes..."
Collections
Sign up for free to add this paper to one or more collections.

