Reasoning Models Generate Societies of Thought
Abstract: LLMs have achieved remarkable capabilities across domains, yet mechanisms underlying sophisticated reasoning remain elusive. Recent reasoning models outperform comparable instruction-tuned models on complex cognitive tasks, attributed to extended computation through longer chains of thought. Here we show that enhanced reasoning emerges not from extended computation alone, but from simulating multi-agent-like interactions -- a society of thought -- which enables diversification and debate among internal cognitive perspectives characterized by distinct personality traits and domain expertise. Through quantitative analysis and mechanistic interpretability methods applied to reasoning traces, we find that reasoning models like DeepSeek-R1 and QwQ-32B exhibit much greater perspective diversity than instruction-tuned models, activating broader conflict between heterogeneous personality- and expertise-related features during reasoning. This multi-agent structure manifests in conversational behaviors, including question-answering, perspective shifts, and the reconciliation of conflicting views, and in socio-emotional roles that characterize sharp back-and-forth conversations, together accounting for the accuracy advantage in reasoning tasks. Controlled reinforcement learning experiments reveal that base models increase conversational behaviors when rewarded solely for reasoning accuracy, and fine-tuning models with conversational scaffolding accelerates reasoning improvement over base models. These findings indicate that the social organization of thought enables effective exploration of solution spaces. We suggest that reasoning models establish a computational parallel to collective intelligence in human groups, where diversity enables superior problem-solving when systematically structured, which suggests new opportunities for agent organization to harness the wisdom of crowds.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Explaining “Reasoning Models Generate Societies of Thought”
1) What is this paper about?
This paper looks at how certain AI models that are good at reasoning (like DeepSeek-R1 and QwQ-32B) seem to think in a special way. Instead of just writing longer explanations, they act like a small “team” inside their heads. These inner voices ask questions, disagree, and then work things out—like a debate club. The authors call this a “society of thought.” They show that this social-style thinking helps the models solve tough problems more accurately.
2) What questions are the researchers asking?
The paper asks simple but powerful questions:
- Do strong reasoning AIs actually “talk to themselves” in a conversational way while solving problems?
- Does having different internal voices (with different personalities and areas of knowledge) help them get better answers?
- Can we nudge an AI to use more conversation-like thinking and make it reason better?
- Will these conversational behaviors appear naturally if we only reward the AI for correct answers?
- If we teach the AI to organize its inner conversation, can it learn to reason faster than if it just monologues?
3) How did they study this?
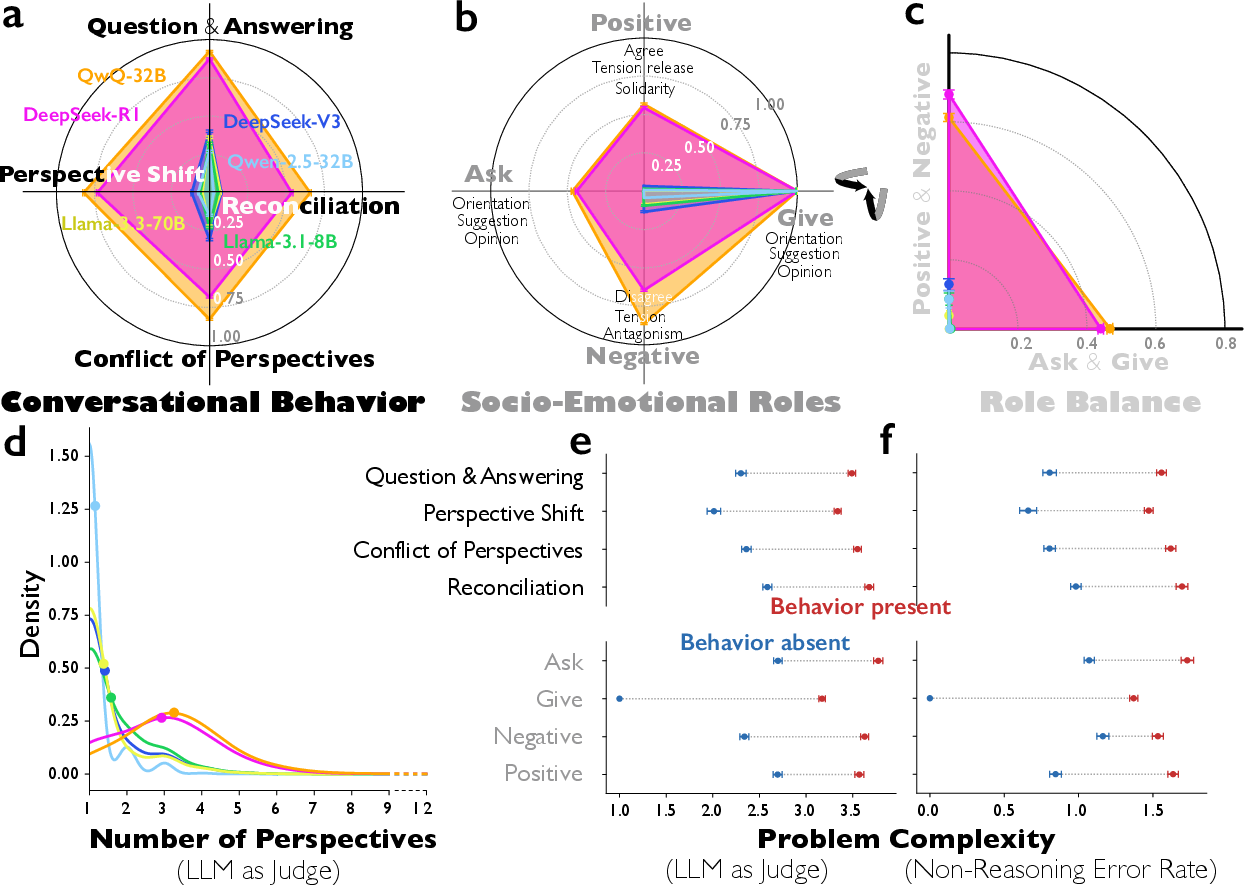
The researchers analyzed how AIs “think” by reading their written chains of thought—the text the model writes before giving an answer. They compared two reasoning-focused models (DeepSeek-R1, QwQ-32B) with standard instruction-following models (like DeepSeek-V3 or Qwen-2.5-32B-IT) across thousands of problems in math, science, and logic.
They used several approaches:
- An AI judge: They asked another AI to label behaviors in the model’s reasoning, like:
- Question–answering (asking and then answering its own questions)
- Perspective shifts (trying different viewpoints or strategies)
- Conflict (clearly comparing and arguing between options)
- Reconciliation (bringing ideas together into one coherent plan)
- Social roles: They used a classic framework from social psychology (Bales’ Interaction Process Analysis) to see whether the model’s inner voices “ask,” “give,” “agree,” “disagree,” and show positive or negative emotion—just like people in a group discussion.
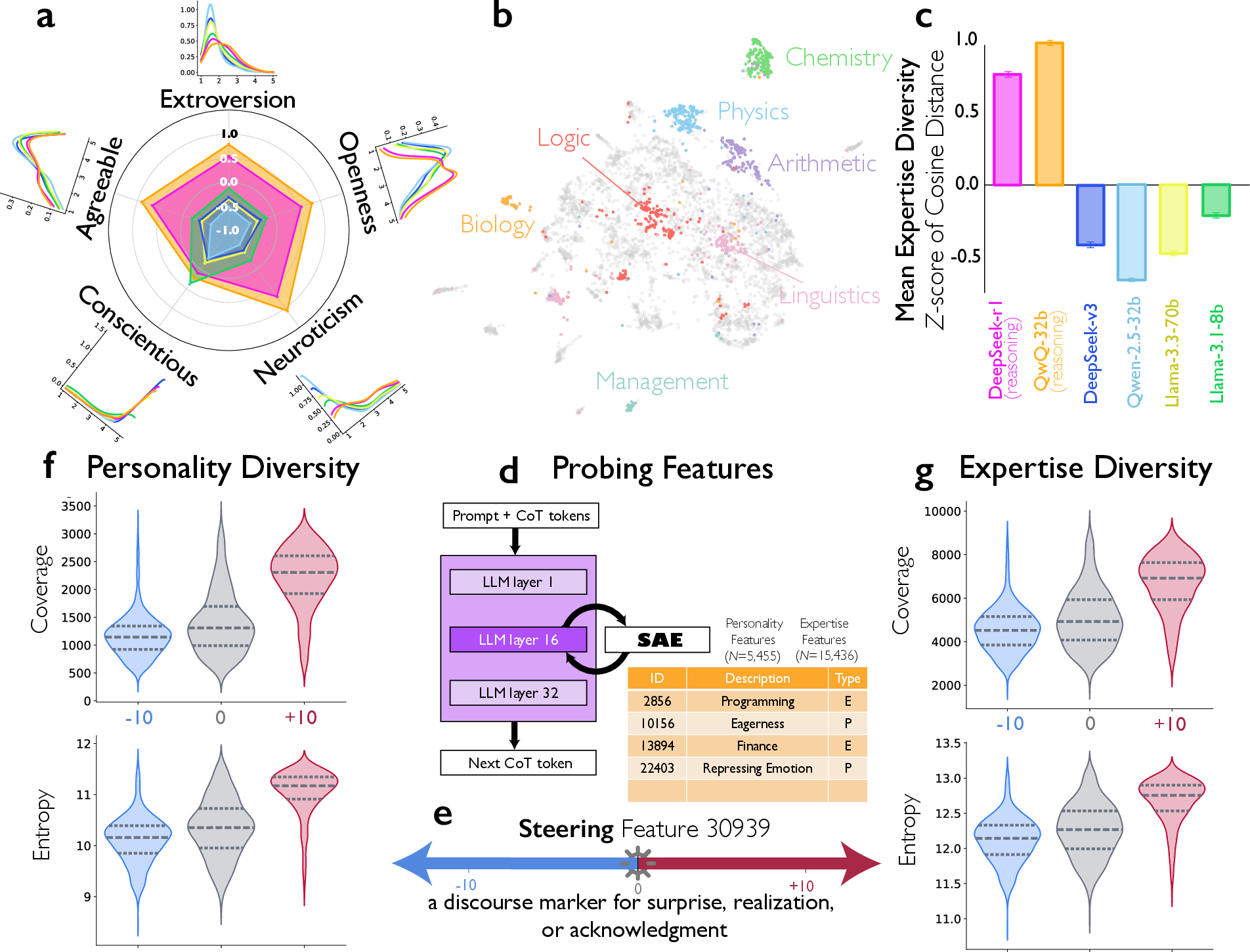
- Diversity of voices: They looked for signs of different “personalities” (using the Big Five traits: openness, conscientiousness, extraversion, agreeableness, neuroticism) and different kinds of “expertise” (like math, chemistry, creative writing), all within a single chain of thought.
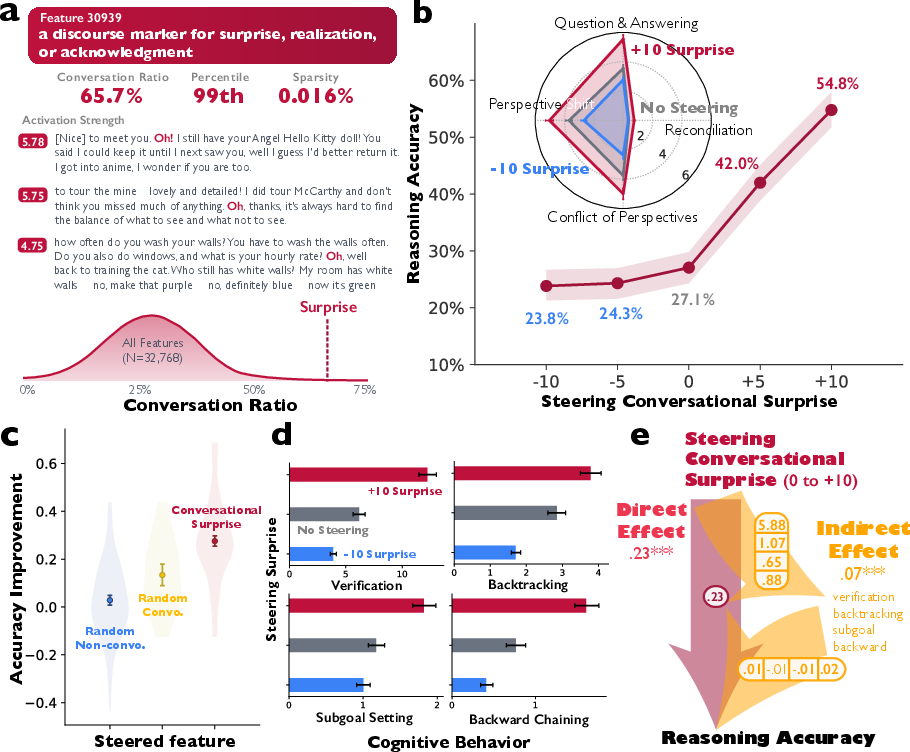
- Turning inner “switches”: They used a tool called a sparse autoencoder to find a tiny internal feature linked to conversational moments—like saying “Oh!” when you realize something. Think of the autoencoder as breaking the model’s brain activity into thousands of small switches, each representing a pattern. They tested whether turning up this “surprise/realization” switch would make the model more conversational and more accurate.
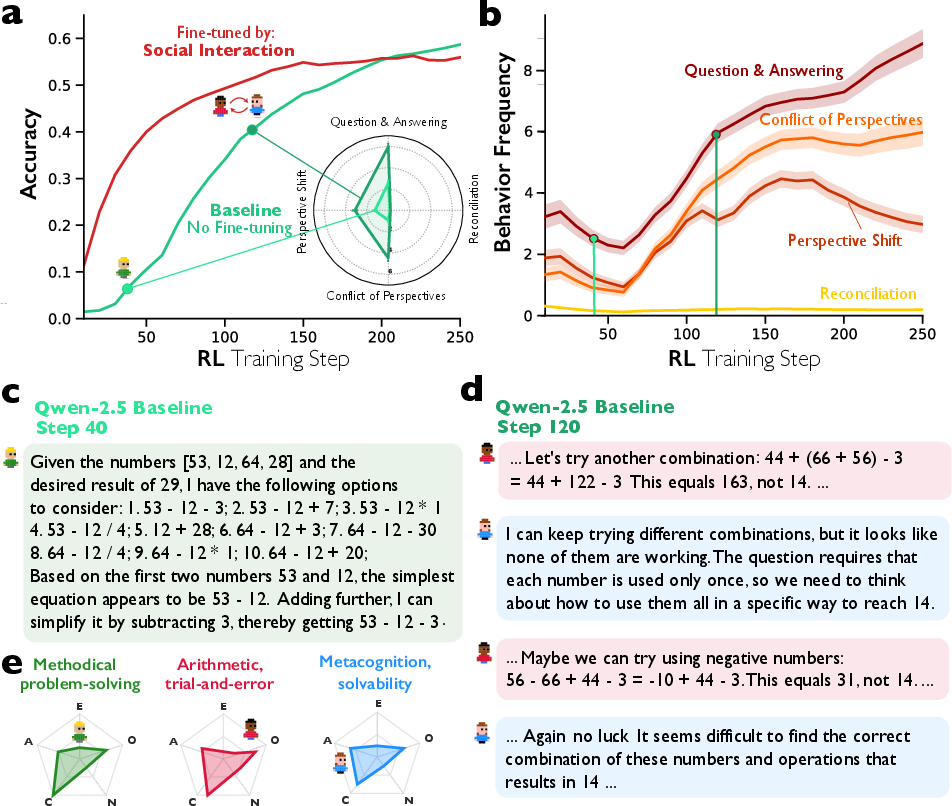
- Training experiments: They did reinforcement learning (RL), where the model gets rewarded for correct answers. They checked whether conversational behaviors appear even when the only goal is accuracy, and whether adding a bit of conversational structure at the start makes the model learn faster.
In everyday terms:
- They watched the AI solve problems and asked: does it think like a group?
- They measured how often it asks questions, switches viewpoints, disagrees, and then settles on a plan.
- They checked if multiple inner “characters” with different styles and skills show up.
- They flipped a “conversation” switch inside the model to see if accuracy goes up.
- They trained smaller models and measured whether conversation helps them learn to reason faster.
4) What did they find and why does it matter?
Here are the main results:
- Reasoning models act more like a debate team: They ask themselves more questions, explore alternative strategies, argue between options, and then reconcile differences much more than regular models. This happens especially on harder problems.
- Balanced social roles: Strong reasoning models both ask and give information, and show both agreement and disagreement. It’s not just a one-way lecture; it’s a two-sided discussion.
- Diversity helps: Inside a single reasoning trace, these models show more personality variety (especially in openness, extraversion, agreeableness, and emotional reactivity) and more expertise variety (for example, mixing scientific analysis with creative idea generation). This kind of diversity matches what helps human teams succeed.
- Turning up the “conversation switch” boosts accuracy: When the researchers gently pushed an internal feature tied to surprise/realization (think: starting a sentence with “Oh!”), the model became more conversational and roughly doubled its accuracy on a number-puzzle game called Countdown. Turning the switch down reduced accuracy.
- Conversation supports smart strategies: With the conversation switch on, the model does more verifying, backtracking, setting subgoals, and building solutions step-by-step. These are classic good reasoning habits.
- Conversation emerges naturally with rewards: In RL experiments where the only reward was getting the right answer, models started using conversational behaviors by themselves—like asking and answering their own questions. Teaching them a bit of conversational structure at the start made them improve faster than models trained to think in a flat monologue.
Why it matters:
- These behaviors directly improved results and also helped the model use better reasoning strategies. The takeaway is that “thinking socially” inside the model leads to better problem solving, not just longer thinking.
5) What is the bigger impact?
This research suggests a simple, powerful idea: AI can get better at reasoning by organizing its internal thinking like a diverse, well-run team. Instead of one voice talking straight through, the best models simulate different perspectives that challenge each other and then come together on an answer. That mirrors human collective intelligence—groups often beat individuals when they have variety, structure, and healthy debate.
Possible impacts:
- Designing future AIs that deliberately use inner teams of agents (each with different skills) could improve accuracy, creativity, and fairness.
- Training methods that encourage organized internal dialogue might speed up learning and reduce common reasoning mistakes.
- We can harness “wisdom of crowds” inside a single model, helping it explore more ideas and avoid echo chambers.
In short: The paper argues that great AI reasoning doesn’t just come from more thinking time—it comes from better thinking organization. When an AI’s inner voices ask, debate, and reconcile like a good team, it solves hard problems more reliably.
Knowledge Gaps
Below is a single, focused list of concrete knowledge gaps, limitations, and open questions that remain unresolved and could guide future research.
- Validate LLM-as-judge annotations: Reliance on LLM-as-judge (for conversational behaviors, socio-emotional roles, problem complexity, persona count/traits, expertise) needs systematic human validation across domains, with multi-annotator protocols, inter-rater reliability, and bias audits.
- Circularity risk: Since both the evaluated traces and the judges are LLM-driven, quantify and mitigate circularity (e.g., cross-model judging, blinded human adjudication, adversarial tests where surface markers are decoupled from reasoning quality).
- Persona inference validity: Assess whether Big Five personality traits inferred from text reliably map to distinct cognitive roles; compare with alternative trait taxonomies and task-relevant cognitive styles.
- Perspective segmentation accuracy: Improve and evaluate token-level attribution of “who said what” in single-author traces; test robustness when style cues are perturbed or removed.
- Expertise diversity measurement: Ground truth the “expertise embedding” metric with labeled expertise profiles and task tags; test sensitivity to embedding model choice and prompt phrasing.
- Benchmark coverage: Extend beyond BBH, GPQA, MATH(H), MMLU-Pro, MUSR, IFEval to include code generation, planning, tool-use, multi-hop factual QA, scientific derivations, and safety-critical decision-making.
- Multilingual generalization: Evaluate whether society-of-thought behaviors and gains hold across languages and culturally diverse discourse norms.
- Decoding confounds: Systematically ablate and report decoding parameters (temperature, nucleus sampling, penalties) and prompting templates that may spur conversational style independent of reasoning quality.
- Length-independent effects: Beyond log-length controls, verify that improvements persist under strict token budgets and when CoT is suppressed or hidden (no visible chain-of-thought).
- Alternative explanations: Disentangle whether observed gains arise from discourse markers/style, general attentional reallocation, or other latent factors (e.g., calibration), via controlled interventions and adversarial counterfactual prompts.
- Necessity vs sufficiency: Test whether conversational behaviors are necessary for gains by penalizing them during inference/training and assessing accuracy drops; conversely, induce them in weak models to test sufficiency.
- Causal pathway validation: The structural equation modeling is observational; design randomized interventions that directly manipulate specific behaviors (e.g., backtracking, reconciliation) to confirm causal mediation.
- Generality of steering results: SAE steering was demonstrated on a single distilled 8B model and a single task family (Countdown); replicate across tasks (math proofs, formal logic, code), domains (science, finance), and larger models.
- Feature selection bias: Reduce potential cherry-picking by screening all SAE features with preregistered criteria, applying multiple-comparison corrections, and reporting nulls and negative controls.
- Polysemanticity of features: Verify that feature 30939 is not polysemantic by probing across layers and contexts; map its causal subcircuits and interactions with other features.
- Layer dependence: Explore steering effects across layers (early/mid/late), model components (MLP vs attention), and combinations to understand where conversational dynamics are represented.
- Robustness to distribution shift: Test whether steering-induced gains persist under out-of-distribution inputs, adversarial noise, and instruction perturbations.
- Side effects of steering: Assess trade-offs (toxicity, verbosity, hallucinations, calibration, latency) when increasing conversational features; report compute and latency costs per accuracy gain.
- Optimal diversity levels: Identify whether there is a “sweet spot” of perspective diversity; quantify performance as a function of diversity and conflict intensity (too little vs too much debate).
- Negative socio-emotional roles: Measure impacts of simulated antagonism/tension on user experience, safety, and downstream alignment; design constraints to keep productive dissent without harmful patterns.
- Sycophancy and bias: Directly evaluate whether increased disagreement reduces sycophancy and confirmation bias on standardized benchmarks; analyze failure modes where conflict still converges to wrong answers.
- RL emergence dynamics: Provide learning-curve analyses showing when conversational behaviors emerge during RL, and how they co-evolve with accuracy across seeds, reward scales, and curricula.
- Reward shaping variants: Compare “accuracy-only” rewards with explicit rewards for verification, dissent, or reconciliation to test if targeted shaping accelerates or destabilizes learning.
- Model scale transfer: Confirm that conversational scaffolding benefits observed in 3B models transfer to 30B–700B models and to commercial-grade systems.
- Task diversity in RL: Beyond Countdown and misinformation identification, include symbol manipulation, theorem proving, program synthesis, and multi-agent inference to test breadth of emergence.
- Generalization vs overfitting: Check whether conversational scaffolding induces overfitting to stylistic markers; use out-of-domain tasks and masked-CoT evaluations to test genuine strategy learning.
- Prompt and format dependence: Since > tags and formatting are part of training, test whether identical benefits appear without special tags or with alternative thinking formats (scratchpads, diagrams).
Human–AI collaborative settings: Evaluate whether internal society-of-thought complements or conflicts with external team workflows; study how exposing internal debates affects user trust and decision quality.
- Tool-use integration: Investigate how internal conversational roles allocate tool calls (search, calculators, code execution) and whether explicit “tool-specialist” personas improve reliability.
- Resource efficiency: Quantify token/compute overhead of conversational reasoning vs monologic baselines for equal accuracy; propose pruning or adaptive stopping criteria to reduce cost.
- Safety and alignment: Examine whether internal debate increases the likelihood of generating harmful or deceptive internal content; assess impacts on refusal behavior and policy compliance.
- Privacy and provenance: Determine whether simulated “expertise” reflects memorized training data personas; audit for leakage and demographic bias in inferred personalities.
- Reproducibility and openness: Release code, prompts, SAE weights, and evaluation data to enable independent replication and robustness checks.
- External replication across families: Include o-series and other reasoning-tuned families to test whether the society-of-thought phenomenon is universal or training-recipe-specific.
- Unified metrics for dialogic reasoning: Develop standardized, model-agnostic metrics for conversational behaviors, reciprocity, and perspective diversity that do not rely solely on LLM-as-judge.
- Mechanism-level theory: Bridge behavioral findings with circuit-level explanations (e.g., attribution to specific heads/MLP neurons) to ground a mechanistic account of “society of thought.”
- Failure analysis: Characterize when and why internal debate fails (e.g., echo chambers, premature consensus, over-fragmentation); design interventions (role assignment, turn-taking rules) to mitigate.
- Practical deployment: Determine when to expose internal debates to users, how to summarize them faithfully, and how to calibrate confidence under disagreement.
- Ethical implications: Explore user perception and responsibility attribution when models simulate conflicting “voices” or personas; develop guidelines for transparent disclosure.
Glossary
- Activation addition method: An inference-time technique that adds scaled vectors to internal activations to steer model behavior. "using the activation addition method"
- Activation space: The vector space of a model’s internal activations where features can be identified and manipulated. "in the model's activation space"
- Bales' Interaction Process Analysis (IPA): A framework for coding and analyzing socio-emotional and task-oriented roles in group interaction. "Bales' Interaction Process Analysis (IPA)"
- BFI-10 (10-Item Big Five Personality Scale): A brief questionnaire measuring the Big Five personality traits used to infer simulated personas. "using the BFI-10 (10-Item Big Five Personality Scale) questionnaire"
- BigBench Hard: A challenging benchmark suite for evaluating LLM reasoning across tasks. "BigBench Hard, GPQA, MATH (Hard), MMLU-Pro, MUSR, and IFEval"
- Chain-of-thought reasoning: Generating explicit intermediate reasoning steps before final answers to improve problem solving. "Conversational behaviours and Bales' socio-emotional roles in chain-of-thought reasoning."
- Cosine distance: A similarity metric on embeddings used to quantify diversity in expertise. "measured as the mean cosine distance between each expertise-related embedding and the centroid of all embeddings in the semantic space."
- Countdown game: A symbolic arithmetic benchmark where numbers must be combined to reach a target value. "Based on a symbolic arithmetic task (Countdown game)"
- Discourse marker: A linguistic cue (e.g., “Oh!”, “Wait”) signaling shifts like surprise or acknowledgment, used here as a steerable feature. "a discourse marker for surprise, realization, or acknowledgment"
- Echo chamber: A dynamic where agreement reinforces errors by discouraging dissent and diversity of views. "avoid the 'echo chamber' that leads to wrong answers."
- Embedding: A vector representation of text used to compute semantic similarity or diversity. "Embedding space of expertise identified by the LLM-as-judge, projected into two dimensions using UMAP"
- Energy-minimization layout: A graph/layout algorithm that arranges points by minimizing an energy function to reveal structure. "rendered with an energy-minimization layout"
- GPQA: A graduate-level science reasoning benchmark assessing advanced question answering. "GPQA (graduate-level science)"
- IFEval: An instruction-following evaluation benchmark used to assess models. "BigBench Hard, GPQA, MATH (Hard), MMLU-Pro, MUSR, and IFEval"
- Intraclass Correlation Coefficient (ICC): A reliability statistic assessing agreement between raters or measurements. "average ICC(3,1) = .756"
- Jaccard index: A set-similarity measure used here to quantify co-occurrence balance of socio-emotional roles. "We quantify reciprocal role balance using the Jaccard index"
- Kernel density estimation (KDE): A nonparametric method to estimate distributions, used for trait distributions. "Kernel density estimation (KDE) plots show the distribution of personality traits across reasoning traces."
- Likert scale: An ordinal rating scale used to judge task difficulty. "measured on a seven-point Likert scale (1 = extremely easy; 7 = extremely difficult)"
- Linear probability model: A regression model for binary outcomes, used with fixed effects to analyze behaviors. "We use linear probability models with problem-level fixed effects"
- LLM-as-judge: Using a LLM to annotate or evaluate outputs (e.g., behaviors, roles, perspectives). "Using an LLM-as-judge, we quantify the occurrence of four conversational behaviours"
- MATH (Hard): A difficult math problem benchmark to evaluate reasoning abilities. "BigBench Hard, GPQA, MATH (Hard), MMLU-Pro, MUSR, and IFEval"
- Mechanistic interpretability: Methods that identify and manipulate interpretable features within model internals. "We employ mechanistic interpretability methods to identify and manipulate features in the model's activation space"
- MMLU-Pro: An advanced version of the Massive Multitask Language Understanding benchmark for reasoning. "BigBench Hard, GPQA, MATH (Hard), MMLU-Pro, MUSR, and IFEval"
- Multi-agent-like interactions: Internal simulations of diverse personas debating and coordinating during reasoning. "implicit simulation of complex, multi-agent-like interactions"
- MUSR: A benchmark (Multi-Subject Reasoning or similar) included in the evaluation suite. "BigBench Hard, GPQA, MATH (Hard), MMLU-Pro, MUSR, and IFEval"
- Reinforcement learning: Training via reward signals (e.g., accuracy) to improve reasoning behavior. "are trained by reinforcement learning to 'think' before they respond"
- Residual stream: The main signal pathway in transformer layers whose activations are analyzed/steered. "Layer 15's residual stream activations"
- Sparse autoencoder (SAE): A model that decomposes activations into sparse, interpretable features. "We use sparse autoencoders (SAEs), which decompose neural network activations into a large set of linear, interpretable features"
- Spearman's rho: A rank-correlation coefficient used to validate LLM-as-judge predictions. "Spearman's = 0.86"
- Steering (feature steering): Causally changing model behavior by increasing or decreasing specific internal features. "steering feature 30939 toward positive values (0 to +10)"
- Structural equation model: A statistical modeling framework to estimate direct and indirect (mediated) effects. "we estimate a structural equation model"
- Theory of mind: The capacity to model others’ beliefs/perspectives, simulated here within reasoning traces. "improved 'theory-of-mind' capabilities"
- UMAP: A dimensionality reduction technique (Uniform Manifold Approximation and Projection) for visualizing embeddings. "projected into two dimensions using UMAP"
Practical Applications
Summary
This paper shows that recent “reasoning” LLMs (e.g., DeepSeek‑R1, QwQ‑32B, OpenAI’s o-series) don’t just think longer—they implicitly simulate multi-agent dialogue among diverse internal perspectives, a “society of thought.” Quantitative analyses and mechanistic interpretability demonstrate that:
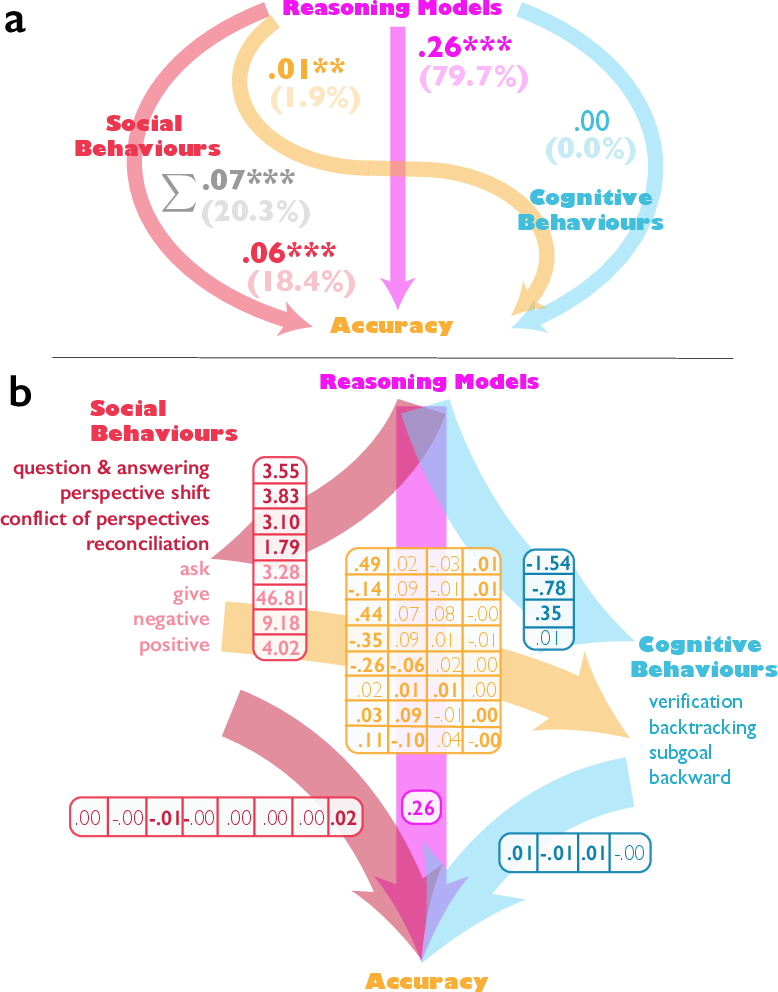
- Conversational behaviors (question–answering, perspective shifts, conflict, reconciliation) and balanced socio‑emotional roles mediate accuracy gains.
- Steering specific conversational features in model activation space can causally increase both dialogic behaviors and cognitive strategies (verification, backtracking, subgoal setting, backward chaining), improving task performance.
- Reinforcement learning for accuracy alone tends to induce conversational patterns; pre‑scaffolding models with dialogic structure accelerates training.
- Reasoning models express greater diversity of implicit personalities and domain expertise than instruction‑tuned models, and this diversity supports problem solving.
The applications below translate these findings into concrete tools, workflows, and policies.
Immediate Applications
The following applications can be deployed with current models, tooling, and practices, often by adapting prompts, training protocols, or evaluation methods.
- Conversational scaffolding for RL fine-tuning
- Sector: software/AI (model training, MLOps)
- Application: Add dialogic structure (self-questioning, perspective shifts, conflict-and-reconciliation) to supervised warm-start and RL curricula. Reward only accuracy/formatting, but scaffold outputs to accelerate the emergence of effective reasoning strategies and reduce training time.
- Tools/workflows: Training templates that enforce Q&A turns; reward-shaping hooks that log dialogic markers; early-stage curriculum that alternates “ask/give” roles.
- Assumptions/dependencies: Access to training loops; stable accuracy rewards; tasks where reasoning strategies matter; monitoring for undesirable socio-emotional tone.
- Activation steering to boost reasoning at inference time
- Sector: software/AI (inference engineering, safety)
- Application: Use sparse autoencoder (SAE) features to steer mid-layer activations (e.g., “surprise/realization” discourse markers) during generation, increasing verification and backtracking and improving accuracy on multi-step tasks.
- Tools/products: “Activation steering” controllers that apply feature vectors (e.g., Layer‑15 residual stream) via activation addition; per-task steering strength schedules; guardrails to avoid oversteering.
- Assumptions/dependencies: Access to model activations (easier for open-source models); robust SAE feature libraries; careful evaluation to avoid distribution shift.
- Multi‑perspective prompt scaffolds for better reasoning
- Sector: software, education, healthcare, legal, finance, robotics planning
- Application: Prompt models to simulate distinct personas (e.g., “planner,” “skeptic,” “expert,” “reconciler”) with explicit turns: generate alternatives, challenge assumptions, reconcile into a final plan.
- Tools/workflows: Prompt templates with role tags; checklists enforcing “ask → give → conflict → reconcile”; lightweight persona tags aligned with Big Five (high openness ideator; low agreeableness verifier).
- Assumptions/dependencies: Tasks benefit from exploration/backtracking; prompts do not exceed latency/length budgets; moderate risk of verbosity, mitigated by turn limits.
- Reasoning diversity and dialogic metrics for model evaluation
- Sector: AI evaluation, product QA, governance
- Application: Instrument chains-of-thought to quantify dialogic behaviors (Jaccard ask/give, positive/negative), perspective count, personality/expertise diversity; correlate with accuracy to predict failure modes (sycophancy, echo chambers).
- Tools/products: “Reasoning Diversity Monitor” that runs LLM‑as‑judge/embedding analyses; dashboards per benchmark; alerts for low-conflict traces.
- Assumptions/dependencies: Availability of traces (may be hidden from users but accessible internally); LLM‑as‑judge reliability; consistent annotation prompts.
- Bias and misinformation mitigation via internal dissent
- Sector: safety, media, policy, enterprise risk
- Application: Require models (or pipelines) to simulate dissenting internal perspectives that verify claims and challenge initial framings before emitting final answers, reducing sycophancy and error propagation.
- Tools/workflows: Pre‑answer “challenge pass” with contrastive viewpoints; reconciliation summaries; triage flags when disagreement persists.
- Assumptions/dependencies: Additional compute for internal debate; careful UX to present reconciled outputs, not raw debate; domain‑specific validation rules.
- Decision support assistants that show “reasoned reconciliation”
- Sector: enterprise productivity, research, legal, clinical decision support
- Application: AI assistants that briefly expose their multi‑perspective exploration and reconciliation, building trust and improving decision quality (e.g., alternative diagnoses, legal arguments, investment theses).
- Tools/products: “Deliberation view” alongside final answer; toggles to show competing rationales; auditable logs of checks and backtracks.
- Assumptions/dependencies: Regulatory/privacy constraints on chain‑of‑thought display (may require internal-only logging); concise, safe summaries.
- EdTech tutors teaching dialectical reasoning
- Sector: education
- Application: Tutors that scaffold student problem solving with question–answering turns, alternative strategies, and reconciliation, improving metacognition and transfer.
- Tools/workflows: Conversational lesson plans; student-facing roles (ideator, verifier); analytics on dialogic features tied to learning gains.
- Assumptions/dependencies: Age-appropriate tone; classroom integration; minimize added cognitive load.
- Team facilitation and brainstorming with diverse personas
- Sector: enterprise collaboration, design/creative
- Application: Meeting copilots that generate persona‑diverse ideas, orchestrate constructive disagreement, and reconcile into actionable plans; creative tools that iterate styles and self-check for scope drift.
- Tools/products: “Debate-to-decide” boards; ideation canvases with persona sliders; reconciliation scripts.
- Assumptions/dependencies: Teams accept AI‑mediated dissent; clear ownership for final decisions; guard against domineering personas.
- Fact-checking and content moderation pipelines
- Sector: media platforms, knowledge management
- Application: Multi‑perspective verification passes for claims (news, user-generated content) to flag items where internal conflict remains unresolved or evidence is weak.
- Tools/workflows: Two-pass pipeline (generate claims → challenge → reconcile → score); escalation for unresolved high-stakes items.
- Assumptions/dependencies: Quality ground-truth sources; latency constraints; handling adversarial content.
- Compliance and risk analysis with explicit pro/con debate
- Sector: finance, legal/compliance, cybersecurity
- Application: Structured pro/con analysis with adversarial perspectives (e.g., “risk taker” vs “risk controller”), then reconciled recommendations and rationale.
- Tools/workflows: Role-tagged compliance checks; evidence matrices; final synthesis including backtracking notes.
- Assumptions/dependencies: Up-to-date regulatory knowledge; audit trails; separation of suggest vs decide.
Long-Term Applications
These require further research, scaling, access, or standardization to be reliable, safe, and broadly adopted.
- Architectures that explicitly orchestrate a “society of thought”
- Sector: AI research & engineering
- Application: Model designs that manage internal persona modules and dialogic protocols (balanced ask/give, positive/negative roles), optimizing diversity while preventing fragmentation.
- Tools/products: Mixture‑of‑personas routers; deliberation schedulers; meta‑controllers that adapt diversity to task difficulty.
- Assumptions/dependencies: Stable APIs for submodule control; training signals beyond accuracy (e.g., diversity rewards); safety alignment to avoid degenerate debates.
- Standardized “reasoning diversity” benchmarks and certifications
- Sector: AI governance, policy, procurement
- Application: Industry standards that quantify dialogic behaviors and perspective diversity as predictors of robust reasoning; certification for models meeting diversity and reconciliation thresholds.
- Tools/products: Open benchmark suites linking dialogic metrics to outcomes; procurement checklists; audit protocols.
- Assumptions/dependencies: Community consensus on metrics; reproducible LLM‑as‑judge protocols; independence from model vendor influence.
- General-purpose activation steering SDKs
- Sector: AI tooling
- Application: Libraries to discover, catalog, and safely steer conversational/cognitive features across architectures, with automated validation and rollback.
- Tools/products: SAE training pipelines; feature registries; runtime steering engines; evaluation harnesses.
- Assumptions/dependencies: Access to mid-layer activations; standardized feature formats; robust safety tests to prevent unintended behaviors.
- Hybrid human–AI deliberation platforms for civic decision-making
- Sector: public policy, civic tech
- Application: Scalable deliberative systems where AI cultivates diverse perspectives, structures debate, and synthesizes consensus for public input (e.g., participatory budgeting, regulatory consultations).
- Tools/products: Moderation and role orchestration; transparency dashboards showing conflict and reconciliation; bias safeguards.
- Assumptions/dependencies: Governance frameworks; public trust; protections against manipulation; multilingual support.
- Clinical decision support with multi‑agent verification and trials
- Sector: healthcare
- Application: Systems providing dialectical differential diagnosis with explicit guideline checks and reconciliation, validated through clinical trials comparing outcomes to monologic AI support.
- Tools/products: Persona modules aligned with clinical roles (diagnostician, guideline expert, safety officer); audit trails; integration with EHR.
- Assumptions/dependencies: Regulatory approvals; rigorous evidence of safety/efficacy; data privacy.
- AI-assisted team composition and training
- Sector: HR, organizational design
- Application: Use LLMs to simulate team diversity (e.g., extraversion/neuroticism variance) for task fit; design trainings that improve constructive dissent and reconciliation.
- Tools/products: Team diversity simulators; facilitation curricula; outcome analytics.
- Assumptions/dependencies: Ethical use; avoidance of stereotyping; validated links between simulated diversity and real performance.
- Robust engineering for safety‑critical planning (robotics, energy, transport)
- Sector: robotics, energy, mobility
- Application: Internal multi‑perspective planners that enforce verification/backtracking in mission‑critical tasks (route planning, grid control), with formal reconciliation before execution.
- Tools/products: Safety layers requiring dialogic checks; conformance proofs; incident replay with perspective analysis.
- Assumptions/dependencies: Formal verification integration; real-time constraints; high-reliability hardware/software stacks.
- Scientific discovery workflows with adversarial hypothesis testing
- Sector: R&D, academia
- Application: AI lab assistants that generate diverse hypotheses, design falsification tests, challenge results, and reconcile into publishable claims.
- Tools/products: Hypothesis generators; adversarial reviewer personas; protocol planners; provenance logs.
- Assumptions/dependencies: Access to experimental platforms; domain grounding; responsible authorship and credit practices.
- Platform-scale misinformation and sycophancy mitigation
- Sector: social media, search, content platforms
- Application: Large-scale pipelines that score internal disagreement and evidence sufficiency before surfacing content; demote items with unresolved conflict.
- Tools/products: Conflict/resolution scoring; reviewer personas; user-facing transparency signals.
- Assumptions/dependencies: Measurable improvement over current moderation; fairness across viewpoints; prevention of censorship biases.
- Personalized “mixture‑of‑personas” assistants
- Sector: consumer software
- Application: Assistants that adapt diversity and debate intensity to user preferences and task complexity, balancing speed with rigor.
- Tools/products: Persona sliders; task-aware deliberation profiles; learning systems that tune ask/give balance over time.
- Assumptions/dependencies: Preference modeling; privacy-safe learning; avoidance of reinforcing harmful styles.
Cross-Cutting Assumptions and Dependencies
- LLM‑as‑judge reliability: Many applications rely on LLM‑mediated annotations (dialogic behaviors, perspective counts). Validate with human raters and external datasets.
- Access to chains-of-thought and activations: Some models hide reasoning traces or don’t expose activations; internal logging and open-source models ease deployment.
- Task suitability: Dialogic scaffolding helps most on complex, multi-step problems; it may add latency/verbosity on simple tasks.
- Safety and UX: Simulated conflict can introduce negative tone or confusion. Use concise reconciliation summaries and emotional safeguards.
- Compute and cost: Longer dialogic traces and steering increase inference and training cost; employ budgeted turn counts and adaptive activation control.
- Generalization: Findings are strongest for studied models and benchmarks; re‑validate in new domains (e.g., clinical, legal).
- Governance: For regulated sectors, ensure auditability of internal deliberation and compliance with privacy/security requirements.
These applications transform the paper’s core insight—that structured internal diversity and debate improve reasoning—into practical design patterns for training, inference, evaluation, and deployment across industries, academia, policy, and daily life.
Collections
Sign up for free to add this paper to one or more collections.