- The paper presents a gradient-free approach utilizing noise alignment and concept vectors to steer diffusion models without per-step gradient computations.
- It leverages Recursive Feature Machines for temporal coherence, achieving up to a 16.4x speedup and improved accuracy across datasets like CIFAR-10 and ImageNet.
- Experimental results show enhanced performance and robust generation quality by maintaining high fidelity across a range of noise levels.
General and Efficient Steering of Unconditional Diffusion
Introduction
The paper "General and Efficient Steering of Unconditional Diffusion" (2602.11395) introduces a novel framework for guiding unconditional diffusion models without relying on gradient computations during inference. Traditional approaches for steering such models often involve retraining with conditional inputs or leveraging per-step gradient guidance, which incurs significant computational overheads. In contrast, this work proposes a method that utilizes two core observations about diffusion models: the efficacy of noise alignment and the transferability of concept vectors.
Methodology
Noise Alignment and Transferable Concept Vectors
The proposed method consists of two main components: noise alignment and transferable concept vectors. Noise alignment refers to the observation that even at early, highly corrupted stages of diffusion, coarse semantic guidance is possible with a pre-computed, lightweight guidance signal. This eliminates the need for per-step gradient calculations during inference. The second component, transferable concept vectors, indicates that a concept direction in the activation space, once learned, can effectively transfer across different timesteps and samples. This capability is harnessed using Recursive Feature Machines (RFMs), a method that identifies efficient steering directions without requiring gradient information.
Implementation
The approach utilizes noise alignment at high noise levels for early-stage guidance and applies RFM-learned steering directions at later stages of the diffusion process. This two-stage method enables efficient and controllable generation, providing substantial improvements over state-of-the-art (SoTA) gradient-based guidance methods both in terms of computational efficiency and generation quality.
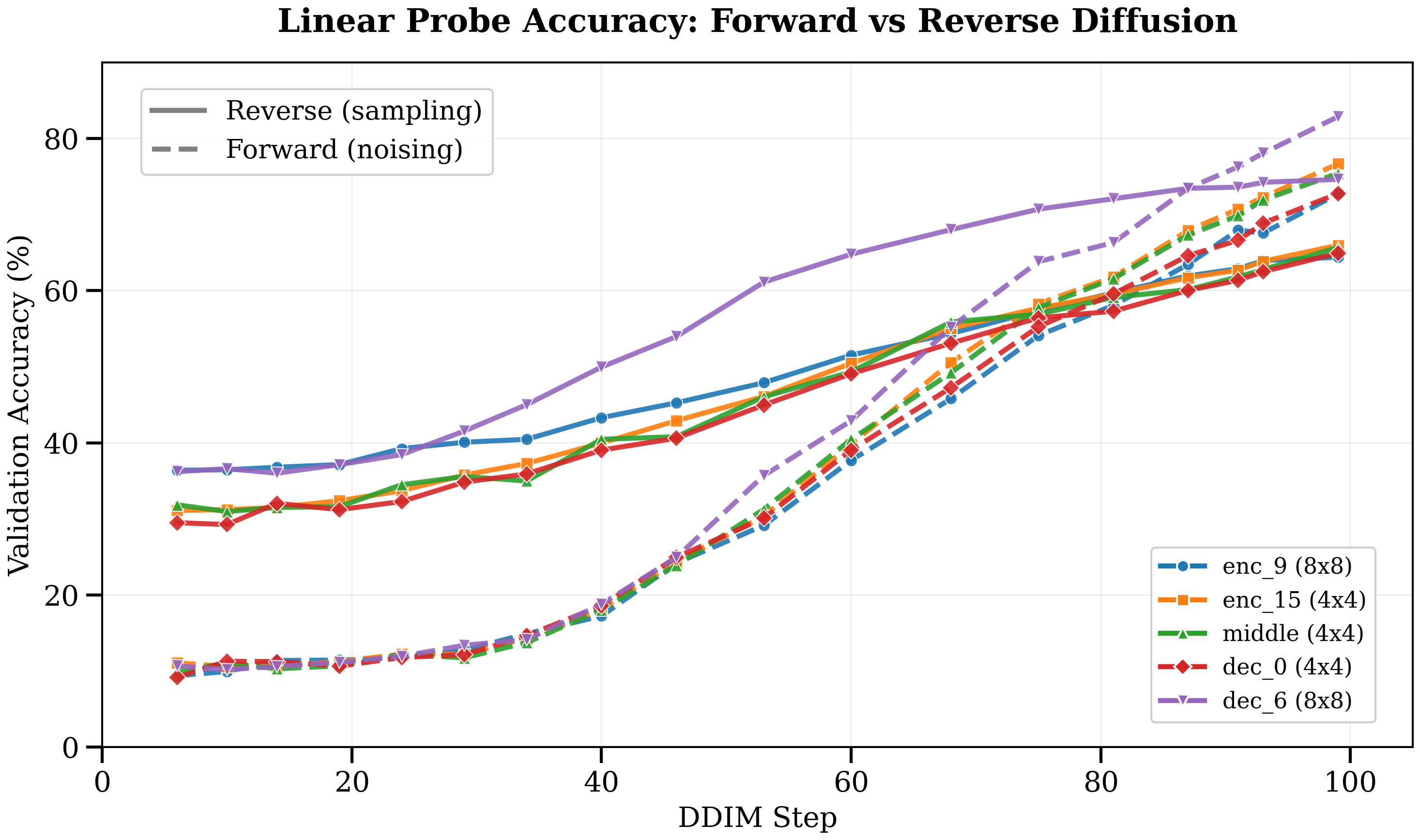
Figure 1: Linear probe accuracy on forward vs reverse diffusion activations. We probe U-Net activations by training linear classifiers on features collected during reverse (sampling, solid lines) and forward (noising, dashed lines) processes across 5 representative blocks within U-Net architecture.
Experimental Results
The experiments conducted on datasets including CIFAR-10, ImageNet, and CelebA demonstrate significant improvements over existing methods. For instance, on CIFAR-10, the method achieves a guidance accuracy of 96.6%, outperforming other training-free guidance methods like TFG (77.1%) and even surpassing the noise-conditioned classifier guidance (86.0%) Figure 2. This improvement comes alongside a notable 16.4x speedup in inference time compared to the TFG-4 method.
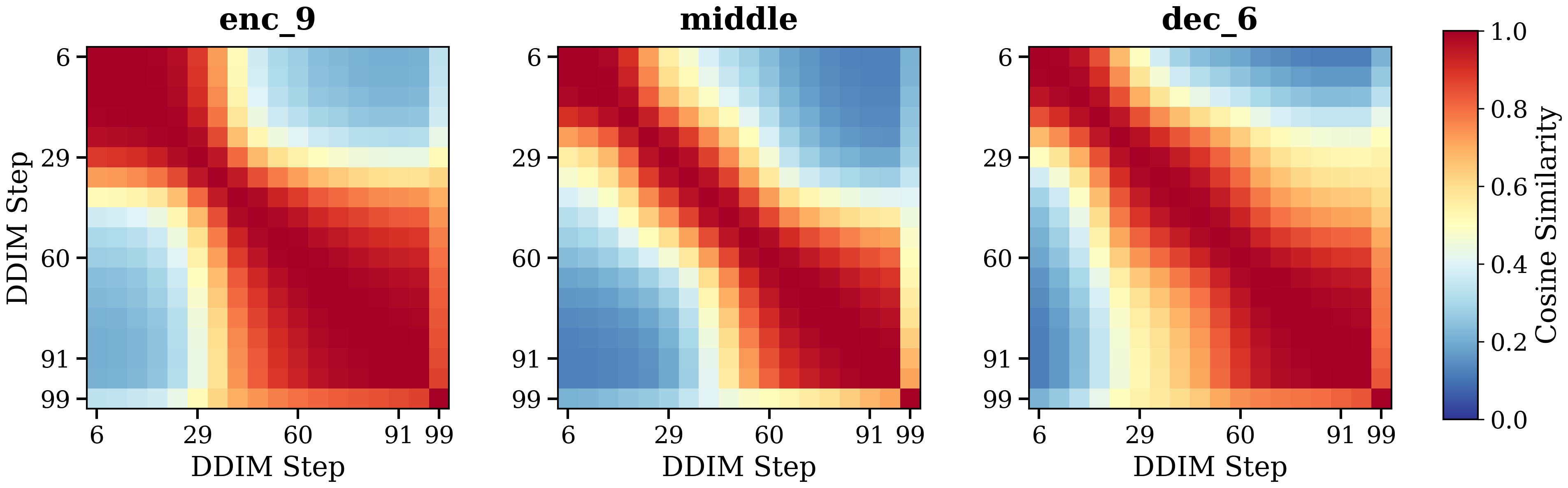
Figure 2: Temporal transfer of RFM directions. Cosine similarity heatmaps across three representative blocks show that directions exhibits temporal similarity for later stage blocks. x- and y-axis are diffusion timesteps, increasing top-down and left-right. The encoder block (left) exhibit the highest temporal stability with highest cross-time step cosine similarity, followed by decoder blocks (right) and middle blocks (middle).
Ablation Studies and Robustness
Ablation studies explored the guidance effectiveness across different noise levels and confirmed that generation accuracy remains robust across a range of noise levels, with accuracy decreasing modestly only at extremely high noise levels (σ=5.0), as depicted in Figure 3. The method's accuracy and FID trade-off are explored with noise alignment revealing its capability to maintain high fidelity, as shown in Figure 4.
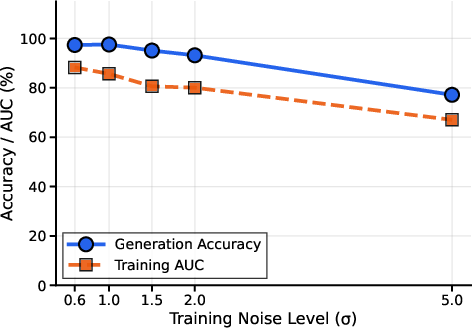
Figure 3: Training noise level ablation. Generation accuracy remains robust across σ∈[0.6,2.0], with modest degradation at σ=5.0.
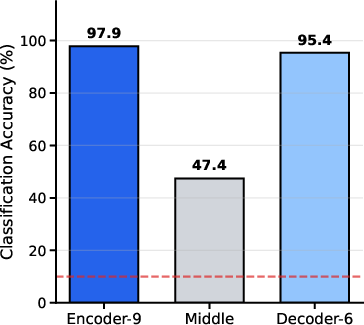
Figure 4: Block selection ablation. NA-RFM guidance accuracy on the airplane class (256 samples) for three U-Net block locations. Encoder-9 achieves highest accuracy (97.9%), with Decoder-6 comparable (95.4%), while Middle block performs poorly (47.4%). Red dashed line indicates random chance (10\%).
Implications and Future Work
The introduced approach has significant implications for advancing the field of diffusion models and their applications in controllable generation tasks. By eliminating the need for gradient computations during inference, this method drastically reduces computational costs and enhances the practicality of deploying diffusion models in real-time applications. Additionally, the insights drawn about noise alignment and concept vector transferability could extend to other generative models or be combined with existing methods to enhance their performance.
Future research avenues might explore further generalization of concept vectors across more diverse datasets or more intricate attributes, broadening the scope of this method's applicability. The potential integration with current SoTA conditional generation frameworks may also provide a hybrid model capable of blending the strengths of both conditional and unconditional models, leading to even more efficient and versatile generative models.
Conclusion
This paper provides a comprehensive framework for guiding diffusion models in an efficient, gradient-free manner. It highlights the utility of noise alignment and RFM-based concept steering in significantly improving both accuracy and inference speed over traditional methods, setting a new standard for guiding unconditional diffusion models. The methodology and findings have promising future implications, encouraging further exploration into activation-based guidance in generative models.