Can We Really Learn One Representation to Optimize All Rewards?
Abstract: As machine learning has moved towards leveraging large models as priors for downstream tasks, the community has debated the right form of prior for solving reinforcement learning (RL) problems. If one were to try to prefetch as much computation as possible, they would attempt to learn a prior over the policies for some yet-to-be-determined reward function. Recent work (forward-backward (FB) representation learning) has tried this, arguing that an unsupervised representation learning procedure can enable optimal control over arbitrary rewards without further fine-tuning. However, FB's training objective and learning behavior remain mysterious. In this paper, we demystify FB by clarifying when such representations can exist, what its objective optimizes, and how it converges in practice. We draw connections with rank matching, fitted Q-evaluation, and contraction mapping. Our analysis suggests a simplified unsupervised pre-training method for RL that, instead of enabling optimal control, performs one step of policy improvement. We call our proposed method $\textbf{one-step forward-backward representation learning (one-step FB)}$. Experiments in didactic settings, as well as in $10$ state-based and image-based continuous control domains, demonstrate that one-step FB converges to errors $105$ smaller and improves zero-shot performance by $+24\%$ on average. Our project website is available at https://chongyi-zheng.github.io/onestep-fb.







Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper asks a bold question: Can we train one “universal” skill set for a robot or game-playing agent that lets it instantly perform well on any future goal without more training? A recent idea called forward-backward (FB) representation learning claims “yes.” This paper examines that claim, explains when it can and cannot work, shows why the original method can struggle, and introduces a simpler alternative called one-step FB that works more reliably and still gives strong results.
Think of it like this: you want a single, reusable cheat sheet that helps you play any level of any game, just by reading the new goal. The paper studies whether such a cheat sheet is even possible, how the old method tries to learn it, why that can fail, and how to build a simpler cheat sheet that reliably gives you a strong first move.
What questions does the paper ask?
The paper focuses on three easy-to-understand questions:
- Can one learned “representation” really cover all possible goals in a world? If not, what limits this?
- What is the FB method actually optimizing under the hood?
- Does the FB method reliably settle down to the right solution when you train it, or can it get stuck?
Based on the answers, the authors propose a simpler method that trades “perfect optimality” for stability and speed.
How did the authors study the problem?
Here’s the setup in everyday language:
- Reinforcement Learning (RL): An agent tries actions in a world to get rewards (like points in a game). A “policy” is the agent’s strategy for choosing actions.
- Representation: A compressed way to describe what matters for acting well. The FB method learns two:
- Forward representation: summarizes “what happens next if I do this now?”
- Backward representation: summarizes “how useful different future situations would be if this is my goal?”
- Successor measure: a fancy term for “the pattern of places and actions you’re likely to visit in the future if you follow this policy.” Think of it as a heatmap of your future footprints.
What FB tries to do:
- Learn a forward rep (for current choices) and a backward rep (for future usefulness) so that their inner product (a simple number produced by multiplying and adding) predicts how good an action is for any goal.
- Then, given a new goal, you combine these reps to pick the best actions right away—no extra training.
How the authors analyzed FB:
- Math tools: They used linear algebra (about ranks and dimensions), a regression-style trick for estimating probability ratios (called LSIF), and the idea of contraction mappings (which are processes guaranteed to settle down).
- Toy world test: They built a tiny world with just three states and three actions to see if FB actually learns what it promises.
- Practical experiments: They ran tests on 10 benchmark control tasks (state-based and image-based) to compare the original FB with their new method.
What did they find?
Key takeaways, in plain terms:
- A universal representation often can’t exist in practice:
- To exactly cover “all possible goals,” the representation needs to be huge—at least as big as the number of all state-action pairs. In continuous worlds (infinitely many possibilities), that’s impossible with a finite-sized model.
- This means the original dream—one compact representation that’s perfect for every goal—is usually out of reach.
- What FB is really optimizing:
- The FB training objective is essentially trying to estimate a special ratio of probabilities (using a method like LSIF) and is closely related to a known RL method called Fitted Q Evaluation (FQE). In short: FB tries to predict “future footprints” in a value-iteration-like way.
- Why FB can be unstable:
- FB has a circular dependency: the representations determine the policy, but the policy also determines the future footprints the reps are trying to predict. This loop can prevent the learning process from settling (no guaranteed “contraction”).
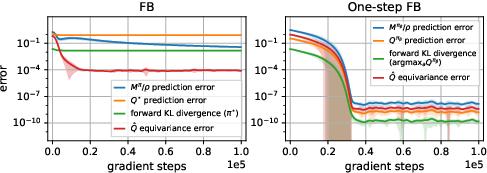
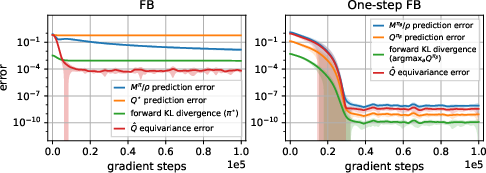
- In the tiny 3-state test, FB did not converge to the correct solution—even with lots of training.
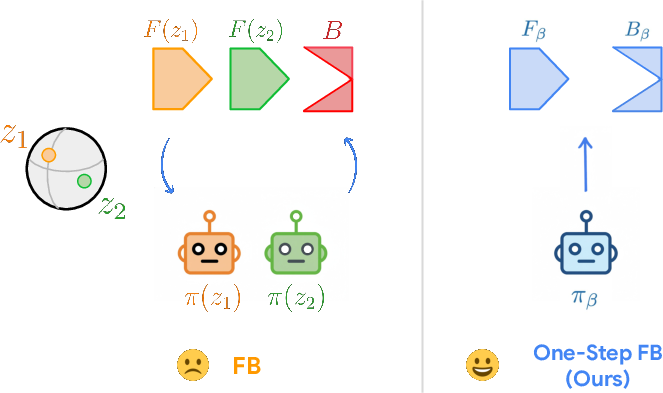
- A simpler, more stable fix: one-step FB
- Break the loop by fixing the policy during representation learning (use the behavior you already have in your data).
- Learn representations for that fixed policy’s future footprints.
- For a new goal, perform just one step of policy improvement (a smarter move than before) rather than trying to jump straight to the fully optimal strategy.
- Result: One-step FB converges cleanly (errors up to 100,000 times smaller in the toy test) and is much more predictable.
- Real-world performance:
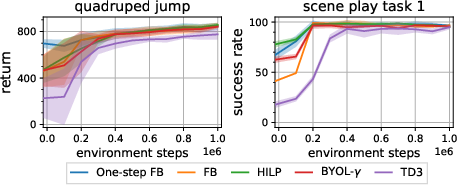
- On 10 control benchmarks, one-step FB improves zero-shot performance by about 24% on average compared to FB, and often matches or beats other strong unsupervised RL methods.
- It also provides a good starting point for further fine-tuning with standard RL, if you want even better performance.
Why is this important?
- Sets realistic expectations: The paper shows that a “one-size-fits-all” perfect representation is usually impossible with reasonable model sizes. That’s an important reality check.
- Offers a practical alternative: One-step FB is simpler, more stable, and still strong. Instead of promising instant optimality for all goals, it delivers a reliable first big improvement with no extra training.
- Bridges theory and practice: By explaining what the FB objective is really doing and why it can fail to converge, the paper guides the design of better pretraining methods for RL—much like how we pretrain LLMs before using them for many tasks.
Bottom line
Trying to learn a single magic representation that’s perfect for every possible goal is mostly unrealistic. The original FB idea is clever but can get stuck because it tries to learn everything at once. The new one-step FB method keeps the good parts (fast adaptation) but removes the instability by learning with a fixed policy and then taking one solid improvement step for new goals. It converges better and boosts zero-shot performance across many tasks, making it a practical and effective way to pretrain RL agents.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of concrete gaps and open questions the paper leaves unresolved, designed to guide future research:
- Existence and approximation of ground-truth FB in continuous domains: With the exact FB factorization cannot exist when . What approximate low-rank or compressible structures of successor measures make near-optimal control feasible, and how do errors scale with ?
- Rank/dimensionality selection: How should one choose or adapt the representation dimension to balance expressivity, stability, and compute? Can data-driven or progressive dimension selection be devised with guarantees?
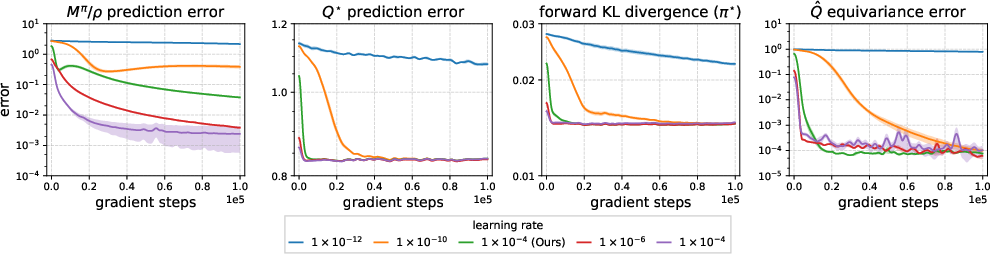
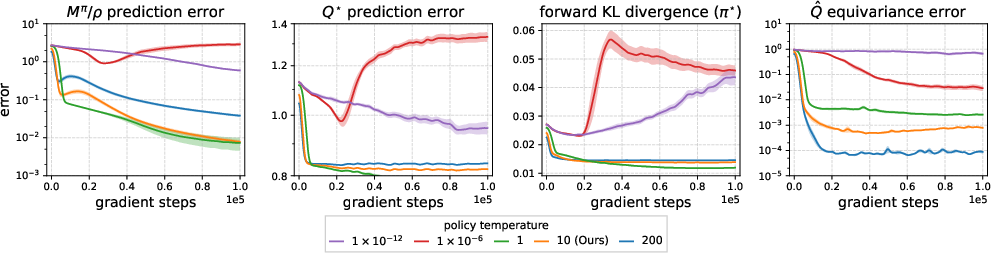
- Error bounds under finite : The paper shows errors can be arbitrarily large for FB with small . Are there structural assumptions (e.g., smoothness, mixing, low intrinsic dimension) that yield nontrivial upper bounds on value loss as a function of ?
- Anchor measure design and estimation: The choice of is largely heuristic. How sensitive are results to , how should be chosen/learned in practice (especially in continuous spaces), and can adaptive or task-aware anchors improve stability and performance?
- Convergence of FB: The FB Bellman operator is not a -contraction; practical convergence remains unproven. Under what restrictions (policy classes, regularization, trust regions, function classes) can convergence or stability be guaranteed? Can alternative fixed-point tools (e.g., Lyapunov functions, Lefschetz theory) establish attractors or limit cycles?
- Breaking circularity beyond one step: One-step FB removes policy–representation circularity by fixing . Can stable k-step or iterative improvements be designed that preserve convergence while moving closer to optimal control?
- Theory for one-step FB: Is the TD one-step FB operator a contraction under reasonable norms and function classes? What are the finite-sample and function-approximation error bounds for learning ?
- Performance-gap guarantees: What bounds relate one-step FB’s zero-shot returns to those of and to the optimal policy, as a function of dataset coverage, approximation error, and ?
- Dataset coverage requirements: What state–action coverage is necessary to consistently estimate successor-measure ratios offline? Can diagnostics detect coverage holes, and can reweighting or conservative objectives mitigate them?
- Multiple-behavior datasets: One-step FB assumes actions are sampled from . How should the method be extended to mixtures or unknown behavior policies (e.g., importance weighting, learned behavior models)?
- Positivity and stability of ratio estimates: LSIF allows negative density-ratio estimates. Do non-negativity constraints or alternative divergences (e.g., f-divergences, Bregman scores) improve stability or bias–variance trade-offs?
- Orthonormalization of
B: The orthonormal regularizer is heuristic. Is there a principled spectral constraint (e.g., SVD-style projections, spectral norm penalties) that improves identifiability and scaling invariances betweenFandB? - Enforcing reward-affine equivariance: Equivariance is used as a diagnostic but not enforced. Can training objectives explicitly enforce -equivariance to affine reward transforms and thereby improve generalization across reward scales?
- Latent prior design: How should be chosen or learned to maximize downstream adaptability? Can latent priors be aligned with anticipated task distributions or learned jointly with representations?
- Weakness on sparse goal tasks: One-step FB underperforms methods specialized for goal distances. How can goal-conditioned structure (e.g., contrastive goals, potential shaping) be integrated into one-step FB without sacrificing stability?
- Non-Markovian and trajectory-based rewards: The bilinear factorization targets . How can the approach be extended to history-dependent objectives (e.g., sequence rewards, options) or variable-horizon criteria?
- Partial observability and stochasticity: How do the methods extend to POMDPs or highly stochastic dynamics (e.g., need for belief-state or recurrent representations)?
- Scalability of
B(s_f,a_f): Estimating backward features over large spaces is costly. What sampling, compression, or factorization strategies (e.g., Nyström, subspace sketches) reduce memory and compute without degrading performance? - Image-based inputs: What encoder designs, augmentations, or auxiliary objectives best support learning successor-measure ratios from pixels? How do representation choices affect stability and generalization?
- Continuous-action policy learning: The policy objective includes BC regularization. Under what conditions on does one-step improvement hold theoretically, and how does it trade off improvement vs. distribution shift?
- Robustness to reward misspecification: How does zero-shot adaptation behave with noisy, shaped, or preference-based rewards? Can the method support rewards specified via language or preferences without retraining the representations?
- Safety and constraints: How can safety constraints or risk measures be incorporated into the zero-shot adaptation using learned representations?
- Online pre-training and exploration: What exploration strategies during data collection improve representation quality (e.g., coverage-aware exploration, optimism in the backward feature space)?
- Discount-factor and normalization issues: The ratio target includes and division by . How to ensure numerical stability when is small, and do smoothing strategies help?
- Multi-objective and compositional rewards: Can multiple task latents be composed at test time, and how does the bilinear structure support compositional generalization?
- Evaluation breadth and realism: Results are on 8 state-based and 2 image-based domains. How do conclusions transfer to long-horizon, safety-critical, or real-robot tasks with delays and nonstationarities?
- Alternative objectives to LSIF: Would other ratio-estimation objectives (e.g., KLIEP, chi-square, energy distances) improve gradient behavior or stability under function approximation?
- Representation identifiability: The bilinear factorization is non-unique up to rotations/scalings. How does this indeterminacy affect downstream adaptation, and can invariance-aware adaptation rules mitigate it?
- Connection to successor features (SFs): Under what conditions are successor-measure ratios equivalent or reducible to SF frameworks? Can insights from SFs yield tighter theory or better algorithms for one-step FB?
- Adaptive capacity control: Can automatic complexity control (e.g., sparsity penalties, progressive widening) adjust the effective rank of the representation during training to fit data complexity?
Practical Applications
Immediate Applications
Below are actionable use cases that can be deployed now by leveraging one-step forward–backward (FB) representation learning for zero-shot adaptation (one-step policy improvement) from offline logs, with concrete tools/workflows and feasibility notes.
- Zero-shot goal retargeting for mobile and warehouse robots (Sector: robotics)
- Use case: Pretrain from logs/demonstrations and deploy a policy that can immediately adapt to new waypoint or region preferences (e.g., safety-weighted cost maps) by inferring a task latent from a specified reward.
- Tools/products/workflows: ROS-compatible “reward-to-latent” adapter; PyTorch/JAX policy component that loads pre-trained Fβ/Bβ; offline dataset curation + TD-LSIF successor-measure-ratio estimation module; integration with existing navigation stacks.
- Assumptions/dependencies: Adequate behavioral data coverage for the new goals; environment/reward stationarity; reliable reward specification; sufficient representation dimension; orthonormalization and target-network stability; domain shift must be limited.
- Rapid retuning of industrial manipulation tasks (Sector: robotics/manufacturing)
- Use case: From offline trajectories, enable immediate retargeting (e.g., prioritize cycle time vs. energy or part quality) via one-step improvement without online fine-tuning.
- Tools/products/workflows: “Zero-shot task selector” in cell controllers; reward-design UI that compiles to latent z; plug-in to existing robot policies (e.g., skill libraries).
- Assumptions/dependencies: Rich logs covering relevant states/actions; safe operation envelopes (adherence to safety constraints must be enforced); limited mismatch between historical and current settings.
- Offline-to-online warm starts for RL fine-tuning (Sector: software/AI platforms; academia)
- Use case: Use one-step FB as a high-quality initialization for SAC/TD3/PPO to reduce sample complexity and stabilize early learning in new tasks.
- Tools/products/workflows: Open-source library module (PyTorch) implementing TD-LSIF-based Fβ/Bβ with Polyak averaging; experiment templates; plug-in for common RL frameworks.
- Assumptions/dependencies: Downstream reward must be available at deployment; choice of marginal ρ and latent prior p(z) affects adaptation; sufficient compute for pre-training; reproducibility across seeds and environments.
- Fast metric retargeting in recommender systems and ads (Sector: software/online platforms)
- Use case: From logged bandit/policy data, perform one-step improvement to adapt to updated business metrics (e.g., long-term engagement weighting, diversity) before full retraining.
- Tools/products/workflows: “Reward adapter” microservice that maps new KPIs to latents; policy deployment with fallback to logging-only mode; A/B gating.
- Assumptions/dependencies: Logged-policy coverage for new objectives; careful offline evaluation to avoid regressions; guardrails for user safety and fairness; regulatory/compliance reviews for metric changes.
- Service orchestration and autoscaling retargeting (Sector: cloud/data centers)
- Use case: Retarget policies to new cost/latency/carbon objectives without retraining, using historical traces to warm start cluster control.
- Tools/products/workflows: Data-center RL controller add-on with reward-to-latent interface; integration with scheduling/placement systems.
- Assumptions/dependencies: Non-stationarity (traffic bursts) may degrade zero-shot performance; adequate logs capturing high-load regimes; monitoring and rollback mechanisms.
- Game AI and simulation prototyping (Sector: gaming/entertainment; academia)
- Use case: Rapidly retarget NPC behavior (e.g., exploration vs. aggression) from internal playtesting logs for balancing and level design.
- Tools/products/workflows: Editor plugin to compile “designer rewards” to latents; behavior evaluation harness; static evaluation budgets for zero-shot sanity checks.
- Assumptions/dependencies: Coverage for the desired styles in logged data; reward shaping consistent with designer intent; minimal domain shift between logged and current builds.
- Teaching and research baselines in RL (Sector: academia)
- Use case: Adopt one-step FB as a stable, explainable baseline for unsupervised pretraining in offline RL courses and benchmarks; use the paper’s operator perspective to teach LSIF/FQE connections.
- Tools/products/workflows: Course labs with didactic CMPs; reproducible notebooks; ablation studies on orthonormalization, representation dimension, and reward scaling.
- Assumptions/dependencies: Availability of standard datasets (ExORL/OGBench); instructor familiarity with offline RL pitfalls (coverage, distribution shift).
- Personalization in smart devices (Sector: consumer electronics/daily life)
- Use case: Zero-shot adjustment of device behavior (e.g., thermostat, vacuum) to new user priorities (comfort vs. energy, coverage vs. quiet) based on historical usage logs.
- Tools/products/workflows: On-device policy component with reward-to-latent slider; privacy-preserving offline training pipeline.
- Assumptions/dependencies: Sufficient logged coverage; reliable proxy rewards; privacy and on-device compute constraints; need for safety bounds and override controls.
Long-Term Applications
These applications require further research, scaling, or development before widespread deployment, but can be strategically planned now.
- Behavioral foundation models (BFMs) for control across tasks and sectors (Sectors: robotics, software, energy, logistics)
- Vision: Large-scale unsupervised pretraining over diverse logs to yield universal, reward-promptable controllers; one-step FB provides a stable backbone for immediate retargeting and as a warm start for multi-step improvement.
- Tools/products/workflows: Cross-domain datasets; unified reward-prompt API; model hubs for behavioral representations; evaluation suites for zero-shot adaptation.
- Assumptions/dependencies: Extensive multi-domain coverage; standardized reward schemas; robust generalization and safety; governance and provenance of logs.
- Healthcare decision support from retrospective data (Sector: healthcare)
- Vision: From EHR and historical treatment logs, provide zero-shot retargeting to new clinical objectives (e.g., minimizing readmission vs. side effects), followed by clinician-in-the-loop validation.
- Tools/products/workflows: “Clinical reward compiler” tied to guidelines; offline evaluation with counterfactual estimators; prospective trials; safety and fairness audits.
- Assumptions/dependencies: Stringent regulatory approval (IRB/FDA); causal validity of rewards; strong OOD detection; interpretability and human oversight; privacy-preserving pipelines.
- Grid and building energy control retargeting (Sector: energy)
- Vision: Adjust policies to new tariffs or carbon intensity signals instantly from historical logs; progressively refine online.
- Tools/products/workflows: Energy management system (EMS) plugin exposing reward-to-latent; digital twin simulations for stress testing; carbon-aware schedulers.
- Assumptions/dependencies: High-fidelity logged data over seasons; safety constraints; non-stationarity and weather uncertainty; coordination with human operators.
- Portfolio and execution policy retargeting (Sector: finance)
- Vision: Zero-shot adjustment to new risk profiles, costs, or compliance rules based on historical trading logs; subsequent guarded online evaluation.
- Tools/products/workflows: Compliance-aware reward mappings; sandboxed backtesting; risk-management overlays; kill switches.
- Assumptions/dependencies: Regulatory compliance; robust backtesting; tail-risk controls; careful reward design to avoid perverse incentives; adversarial robustness.
- Autonomous driving preference retargeting (Sector: automotive/transport)
- Vision: From large-scale driving logs, zero-shot adjust to preferences (comfort vs. efficiency vs. safety margins) or route-cost changes; validate in simulation then staged rollout.
- Tools/products/workflows: Reward-prompt interfaces in planning stacks; scenario libraries; closed-course validation.
- Assumptions/dependencies: Extensive coverage of rare corner cases; stringent safety and liability considerations; explainability; real-time constraints.
- Multi-agent and fleet-level adaptation (Sectors: logistics, robotics, mobility)
- Vision: Zero-shot retargeting for fleet-wide objectives (e.g., throughput, fairness, energy) using shared behavioral representations; coordinated one-step improvement at the agent level.
- Tools/products/workflows: Centralized reward-to-latent service broadcasting task latents; fleet simulators; coordination protocols.
- Assumptions/dependencies: Non-stationarity and interactions complicate evaluation; data heterogeneity across agents; communication/synchronization constraints.
- Human-in-the-loop reward prompting and safety filters (Sectors: cross-sector, policy)
- Vision: Interactive reward “prompting” interfaces where operators or domain experts specify objectives that the system compiles to latents; layered safety filters and certified constraints wrap the zero-shot policy.
- Tools/products/workflows: UI for reward composition with templates; certified constraint satisfaction layers; audit trails.
- Assumptions/dependencies: Usable reward authoring tools; robust mapping from rewards to latents; verified constraint adherence; training for operators.
- Theoretical and methodological extensions (Sector: academia)
- Vision: Operators with contraction-like guarantees for representation-based control; analysis tools for fixed points, rank/coverage diagnostics, and reward-scaling invariance; improved methods for sparse/goal-conditioned settings.
- Tools/products/workflows: Libraries for TD-LSIF with diagnostics; automated checks for representation dimension vs. |S×A|; data coverage estimators; benchmark suites with sparse rewards.
- Assumptions/dependencies: New theory for fixed-point existence/uniqueness; better orthogonality regularization; scalable architectures and training protocols.
Notes on feasibility and dependencies across applications
- Data coverage and quality: Success depends on offline datasets that cover the state–action regions relevant to new rewards; severe distribution shift reduces zero-shot gains.
- Reward specification and scaling: The method assumes a well-defined reward that can be mapped to a latent via backward representations; affine transformations in rewards are handled, but poorly aligned rewards can fail.
- Representation capacity: For continuous/high-dimensional settings, sufficiently large representation dimension and stable orthonormalization are needed.
- Safety and compliance: In regulated domains (healthcare, finance, automotive), extensive evaluation, interpretability, and oversight are mandatory.
- System integration: Real-time inference constraints, monitoring, rollback, and A/B testing are needed when deploying zero-shot retargeting in production environments.
Glossary
- Affine transformation: A linear mapping plus a constant offset applied to variables (here, rewards), preserving straight lines and ratios of distances; often used to analyze invariance properties of value functions. "equivariant to an arbitrary affine transformation with positive scaling of the rewards"
- Banach fixed-point theorem: A theorem guaranteeing a unique fixed point for a contraction mapping and convergence of iterative applications to it; used to analyze Bellman operators. "which has a clear connection with the standard Bellman operator and the Banach fixed-point theorem~\citep{banach1922operations}."
- Behavioral foundation models (BFM): Large unsupervised models in RL that learn general behaviors from reward-free interactions and can be adapted with minimal fine-tuning. "such models are known as behavioral foundation models (BFM)~\citep{tirinzoni2025zeroshot, sikchi2025fast, li2025bfm}"
- Controlled Markov process (CMP): A Markovian dynamics model without a reward function, defined by states, actions, transition probabilities, and a discount factor; becomes an MDP when a reward is added. "We consider a controlled Markov process (CMP)~\citep{bhatt1996occupation}"
- Delta measure: A measure concentrated at a single point; in discrete MDPs an indicator function, in continuous MDPs a Dirac delta function. "The delta measure is an indicator function for discrete MDPs and a Dirac delta function for continuous MDPs."
- Discounted state occupancy measure: The distribution over future state-action pairs reached under a policy, discounted over time; also referred to as the successor measure. "the discounted state occupancy measure~\citep{eysenbach2022contrastive, zheng2024contrastive, myers2024learning, zheng2025intention}"
- Equivariance (to affine transformations): A property where quantities (e.g., Q-values) transform predictably under affine changes to rewards, enabling invariance tests for learned representations. "equivariant to an arbitrary affine transformation with positive scaling of the rewards"
- FB Bellman operator: A Bellman-like operator acting on forward-backward representations whose fixed points correspond to successor measure ratios for latent-conditioned policies. "we define a new Bellman operator, called the FB Bellman operator."
- Fitted Q-evaluation (FQE): An off-policy evaluation method that iteratively fits Q-values via a temporal-difference regression, analogous to applying the Bellman operator. "reveals a connection with fitted Q-evaluation (FQE)~\citep{ernst2005tree, riedmiller2005neural, fujimoto2022should}"
- Forward-backward representation learning (FB): A zero-shot RL approach that factorizes successor measures into forward and backward representations to recover optimal control given arbitrary rewards. "Forward-backward (FB) representation learning~\citep{touati2021learning} is a prominent attempt to realize this translation."
- Gamma-contraction (γ-contraction): A mapping that contracts distances by a factor γ in a suitable norm, ensuring unique fixed points and convergence; a property the FB Bellman operator lacks. "The FB Bellman operator $_{\text{FB}$ is not a -contraction."
- In-context learning (for RL): Adapting behavior from context (e.g., rewards in trajectories) without updating model parameters, analogous to prompting in LLMs. "this paradigm can be interpreted as in-context learning for RL"
- Least-squares importance fitting (LSIF): A regression-based method to estimate ratios between probability measures by minimizing a least-squares loss over samples. "least-squares importance fitting (LSIF)~\citep{kanamori2009least, kanamori2008efficient} views the problem through a different lens and casts the measure ratio estimation as regression."
- Latent-conditioned policy: A policy whose action selection depends on both the current state and a latent variable indexing behaviors. "the latent-conditioned policy defined by"
- Lefschetz fixed-point theorem: A topological theorem used to count fixed points under certain mappings; mentioned as a potential tool for analyzing FB’s fixed points. "such as the Lefschetz fixed-point theorem~\citep{lefschetz1926intersections}"
- Lyapunov stability: A framework to analyze the stability and convergence of dynamical systems via Lyapunov functions; proposed for future analysis of FB. "or the Lyapunov stability~\citep{lyapunov1992general}"
- Moore–Penrose pseudoinverse: A generalized matrix inverse that provides least-squares solutions for linear systems, used to relate FB representations to successor measures. "where $\ph{X}^+$ denotes the pseudoinverse~\citep{moore1920reciprocal, Bjerhammar1951ApplicationOC} of the matrix $\ph{X}$."
- One-step forward-backward representation learning (one-step FB): A simplified pre-training method that learns representations for a fixed behavioral policy and performs a single policy improvement step at adaptation. "We call our proposed method one-step forward-backward representation learning (one-step FB)."
- Orthonormalization regularization: A penalty encouraging backward representations to be orthonormal, improving stability and identifiability of the factorization. "we regularize the backward representations to be orthonormal:"
- Polyak averages: A target network update method using exponential moving averages of parameters to stabilize temporal-difference training. "using Polyak averages."
- Probability measure ratio estimation: The task of estimating the ratio between two probability measures, central to LSIF and the FB objectives. "The goal of probability measure ratio estimation is to predict the ratio $p(\ph{x}) / q(\ph{x})$"
- Rank matching: An analytical perspective relating representation learning objectives to matching ranks of matrices (e.g., successor measures). "We draw connections with rank matching, fitted Q-evaluation, and contraction mapping."
- Reparameterized policy gradient: A gradient estimator using a reparameterization of stochastic actions to enable low-variance differentiable policy updates. "by the reparameterized policy gradient trick~\mbox{\citep{haarnoja2018soft}"
- Successor measure: The (discounted) occupancy of future state-action pairs under a policy, serving as a basis to compute Q-values for any reward. "also known as the successor measure~\citep{dayan1993improving, janner2020gamma, touati2021learning}"
- Successor measure ratio: The ratio of a policy’s successor measure to a reference marginal measure, factorized into forward and backward representations in FB. "has its associated successor measure ratio satisfying"
- Temporal-difference (TD) loss: A regression objective that minimizes Bellman errors by bootstrapping from target networks; used to train FB and one-step FB representations. "We call this loss the temporal-difference (TD) forward-backward representation loss"
- Zero-shot RL: Adapting to new reward functions without updating network parameters, leveraging pre-trained representations or policies. "We will use zero-shot RL to denote those unsupervised pre-training algorithms"
Collections
Sign up for free to add this paper to one or more collections.