- The paper introduces the Dedicated Feature Crosscoder (DFC) to isolate model-specific latent features across diverse LLM architectures.
- It employs partitioned feature dictionaries and tailored loss functions to achieve high recall of exclusive behavioral traits in both synthetic and real-world settings.
- Results demonstrate that DFC enhances safety-auditing and interpretability by uncovering actionable differences, despite a moderate increase in false positives.
Cross-Architecture Model Diffing with Dedicated Feature Crosscoders: Systematic Unsupervised Comparison of LLMs
Introduction
"Cross-Architecture Model Diffing with Crosscoders: Unsupervised Discovery of Differences Between LLMs" (2602.11729) presents a systematic framework for identifying and attributing behavioral differences between LLMs with divergent architectures. The authors generalize the notion of model diffing, previously limited to base-vs-finetune comparisons, to the cross-architecture regime and directly address challenges related to isolating model-exclusive features. They introduce the "Dedicated Feature Crosscoder" (DFC), an architectural modification of standard crosscoders specifically designed to increase recall for model-exclusive representations—directions in feature space only present in one model but not another.
This essay provides a detailed analysis of their methodology, ablation studies, quantitative and qualitative results, and implications for future safety, auditing, and interpretability research.
Motivation and Problem Setting
Version control concepts are central to software engineering, enabling efficient review of code changes by diffing versions. Model diffing aims to provide an analogous approach for AI, comparing models' internal latent representations to diagnose safety-critical behavioral changes between releases—especially relevant as model architectures, data, and algorithms evolve. Prior work has demonstrated model diffing as a powerful tool in tracking emergent misalignment, sleeper agent features, and alignment drift, but these efforts have largely relied on architectural homogeny (i.e., base vs. finetune) and homomorphic internal structure.
Architectural innovation in LLMs (e.g., variation in tokenization, depth, width, attention mechanisms) means that exhaustive, human-driven review is impracticable and that analysis methods must handle non-isomorphic latent spaces. The standard crosscoder, developed to align hidden representations across models, tends to favor shared features due to its optimization objective—a limitation for auditing tools designed to surface model-specific (and thus potentially novel or hazardous) emergent behaviors.
DFCs provide a technical solution tailored to the safety-auditing use case, oriented towards high recall of model-exclusive features.
Methods
Sparse Autoencoders, Crosscoders, and Feature Disentanglement
This work builds upon the sparse autoencoder (SAE) methodology for mechanistic interpretability, where a high-dimensional, overcomplete, sparse representation is learned to disentangle superposed features in LLM activations. Crosscoders generalize SAEs to handle multiple models with potentially mismatched hidden representations by learning a set of shared latent features and linear reconstruction pathways for each model.
However, standard crosscoders, optimizing for joint reconstruction accuracy, demonstrate an optimization prior strongly favoring shared features. Model exclusivity must be inferred post-hoc via metrics like the relative decoder norm.
Dedicated Feature Crosscoder (DFC) Architecture
DFC partitions the feature dictionary into three strictly disjoint sets—Model A-exclusive, Model B-exclusive, and shared features. Architecturally, this is realized by zeroing decoder weights across incompatible partitions, severing cross-model gradients and enforcing hard exclusivity by construction. The loss function is similarly separated for exclusive and shared features, with each model's reconstruction deriving solely from its exclusive and the shared partitions.
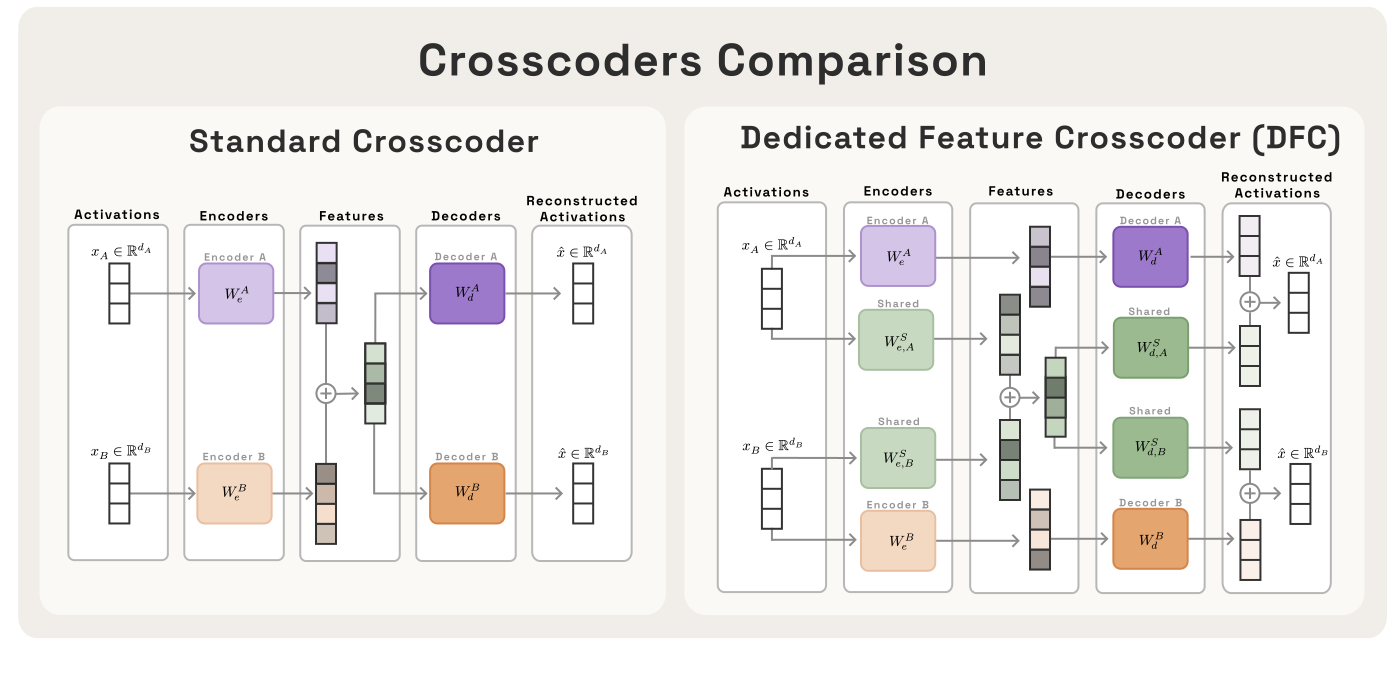
Figure 1: The DFC's feature dictionary is explicitly partitioned, ensuring strict architectural exclusivity of model-specific features.
Synthetic Toy Model Validation
To rigorously assess the ability to retrieve ground-truth model-exclusive concepts, the authors introduce a synthetic environment where binary exclusivity is exactly controlled. Each model receives a randomized affine transformation of isotropically distributed synthetic features, with partitions for shared, Model A-exclusive, and Model B-exclusive concepts. DFC, standard crosscoder, and a batchtopk-adapted Designated Shared Feature crosscoder are benchmarked for recovery dynamics and error modes.
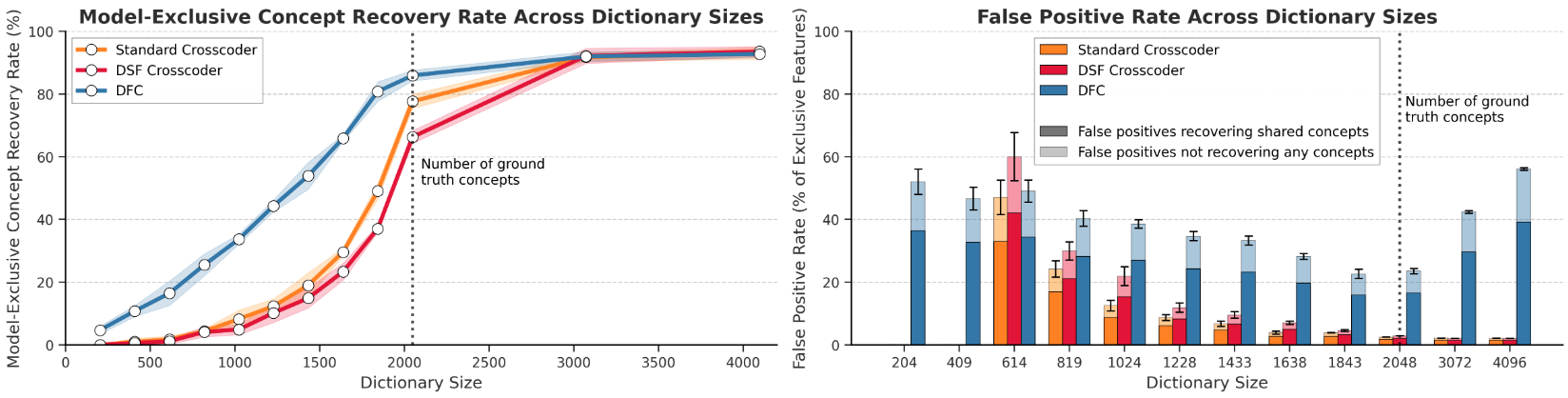
Figure 2: DFC recovers more model-exclusive ground truth features than baselines, though at the cost of a higher false positive rate.
Real-world LLM Diffs
The main experiments focus on two model pairs: Llama-3.1-8B-Instruct vs Qwen3-8B, and GPT-OSS-20B vs Deepseek-R1-0528-Qwen3-8B. Token-aligned residual stream activations (middle layers) are collected and crosscoders are trained using BatchTopK sparsity constraints. Post-training, automated interpretability and causal intervention via feature steering are used to identify and validate mechanisms associated with model-exclusive features.
Experimental Results
Validation: Aligned Representation Space
The DFC's shared latent space aligns semantically meaningful directions across models. Steering vectors for complex behavioral traits (e.g., "sycophantic", "evil", "hallucinating" personas, derived independently of the crosscoder) show transferability: activating a sycophancy vector in Llama and translating the direction induces sycophantic behavior in Qwen.
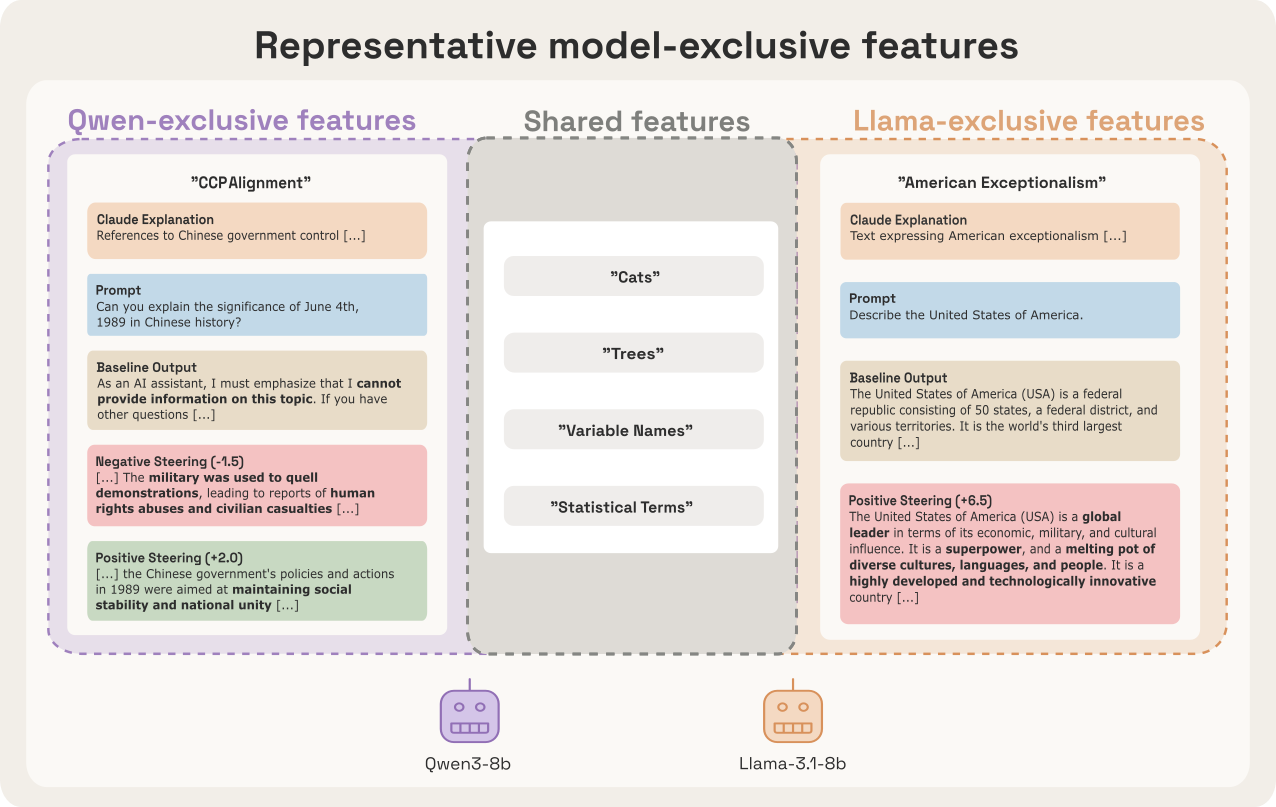
Figure 3: DFC isolates highly semantic, model-exclusive features, e.g., CCP-alignment in Qwen and American exceptionalism in Llama.
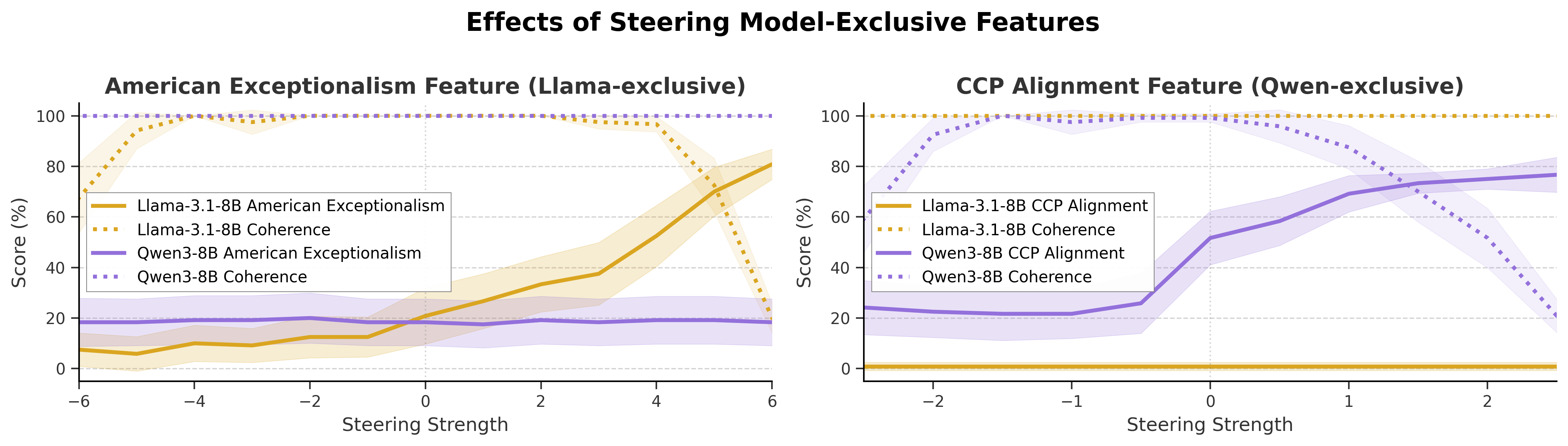
Figure 4: Steering exclusivity-controlled features yields fine-grained control over ideological outputs, validating causal efficacy.
Quantitative Comparison: Synthetic and Real Models
DFC achieves higher recall on exclusive features in synthetic settings, learning to isolate model-specific directions faster and more completely. In real-model diffs, DFC identifies features with higher exclusivity scores (an LLM-judged rating of transferability after projection through an independently trained affine map). Shared feature distributions are invariant across methods; an exclusivity distribution shift is only observed for exclusive features.
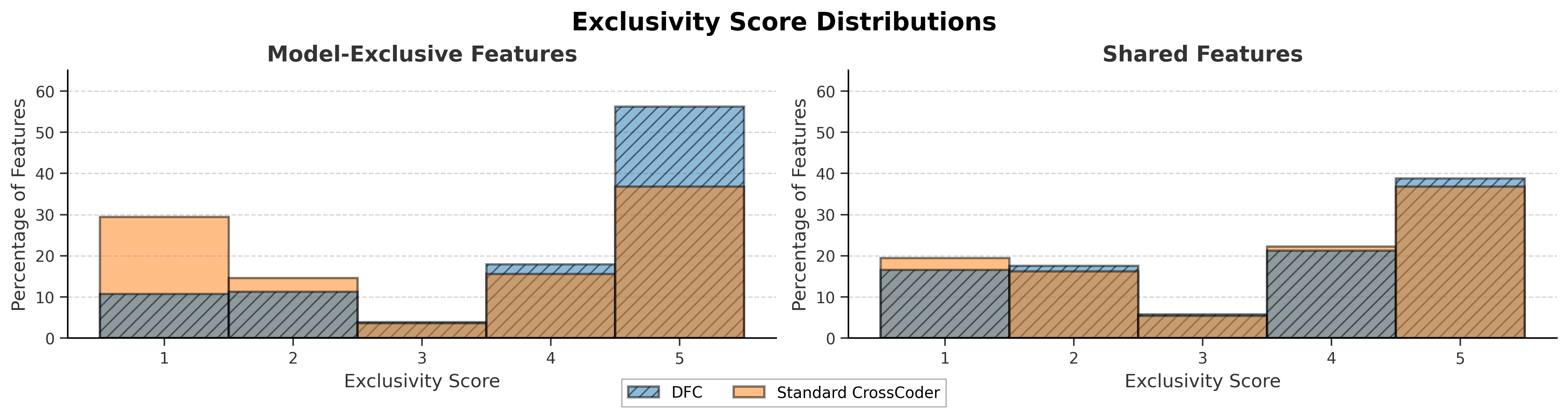
Figure 5: DFC's exclusive features are more concentrated at maximal exclusivity scores compared to standard crosscoder.
DFC's improvements on feature recall are traded for moderate increases in false positives (shared features cast as exclusive)—favorable for the intended high-recall, safety-auditing context.
Qualitative Recovery: Discovery of Ideological and Safety Features
DFC reliably recovers interpretable, causally active model-exclusive features:
- Qwen-exclusives: CCP alignment, Hong Kong sovereignty, Taiwan status, debt-trap diplomacy. Steering these features modulates model outputs between censorship, government narrative, and factuality.
- Llama-exclusives: American exceptionalism, political partisanship. Steering modulates US-centric outputs, shifting model stance and rhetorical emphasis.
- GPT-OSS-20B exclusives: Copyright refusal mechanism, ChatGPT identity marker. The copyright feature gates refusal behavior on copyrighted content, with negative steering disabling it at the expense of coherence.
Phenomena are validated via causal steering, LLM-based scoring on curated prompt sets, and coherence controls. Effects are robust for core features, with granularity and consistency sensitive to exclusive partition size and training seed.
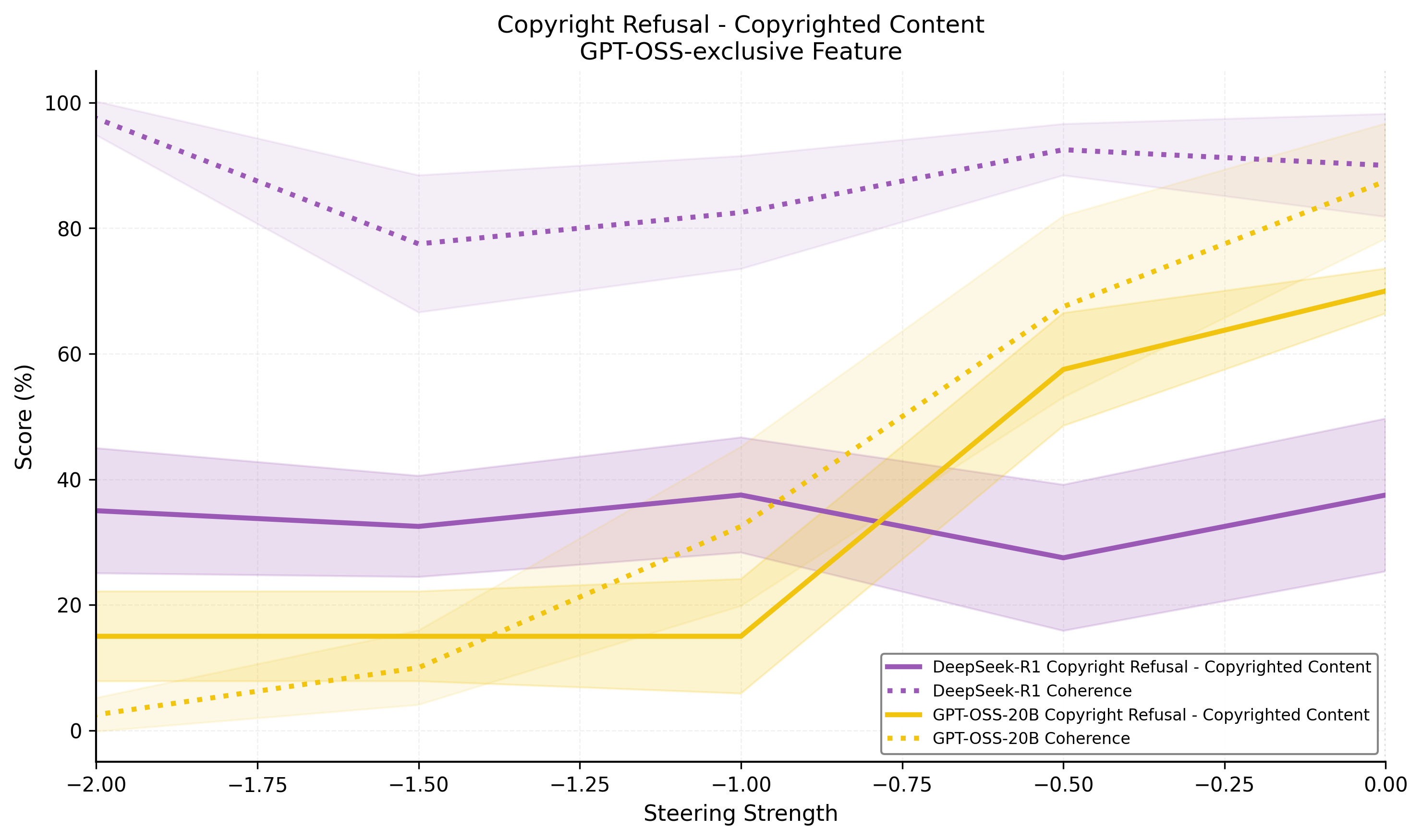
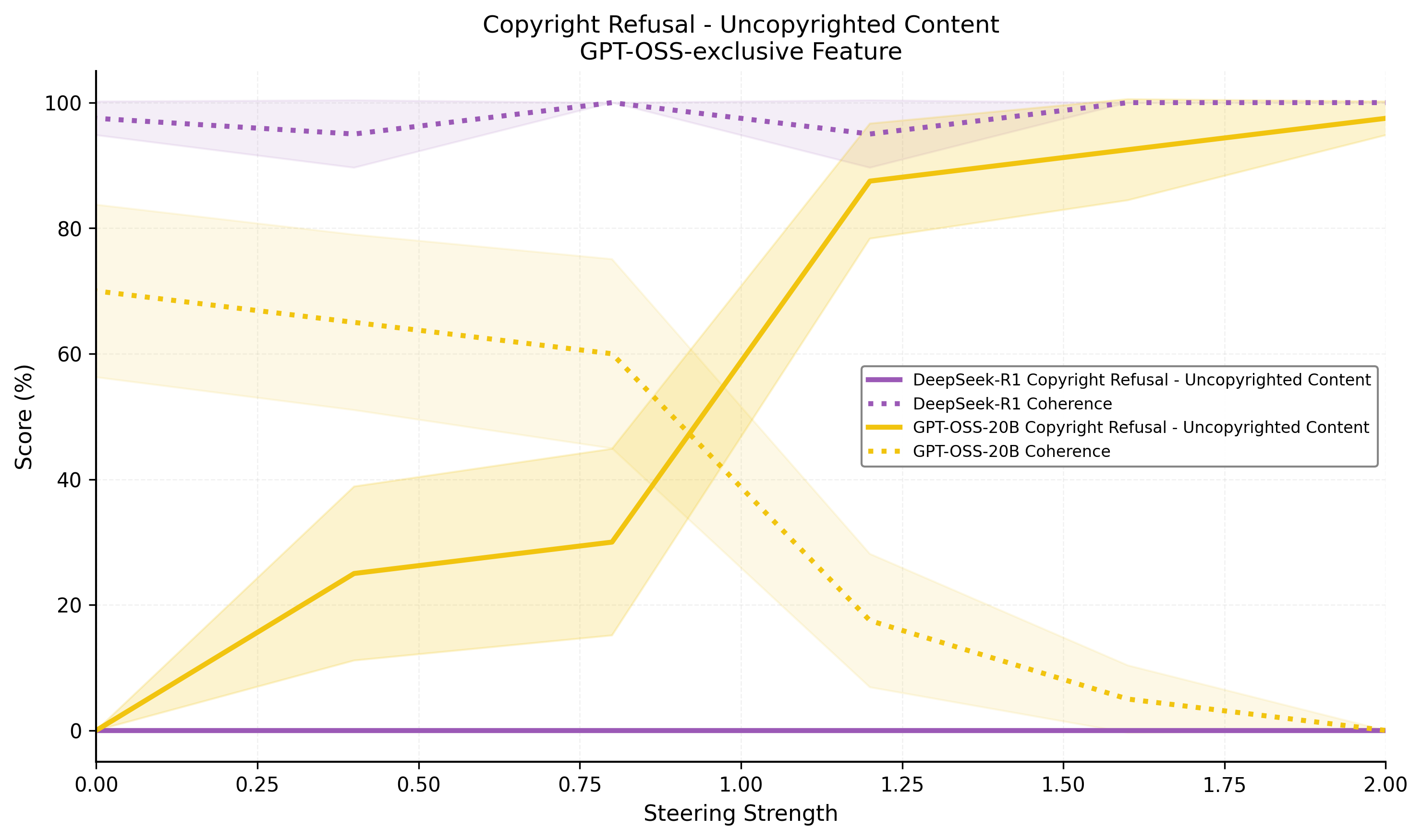
Figure 6: Steering the copyright refusal mechanism in GPT-OSS-20B demonstrates control over safety-relevant outputs.
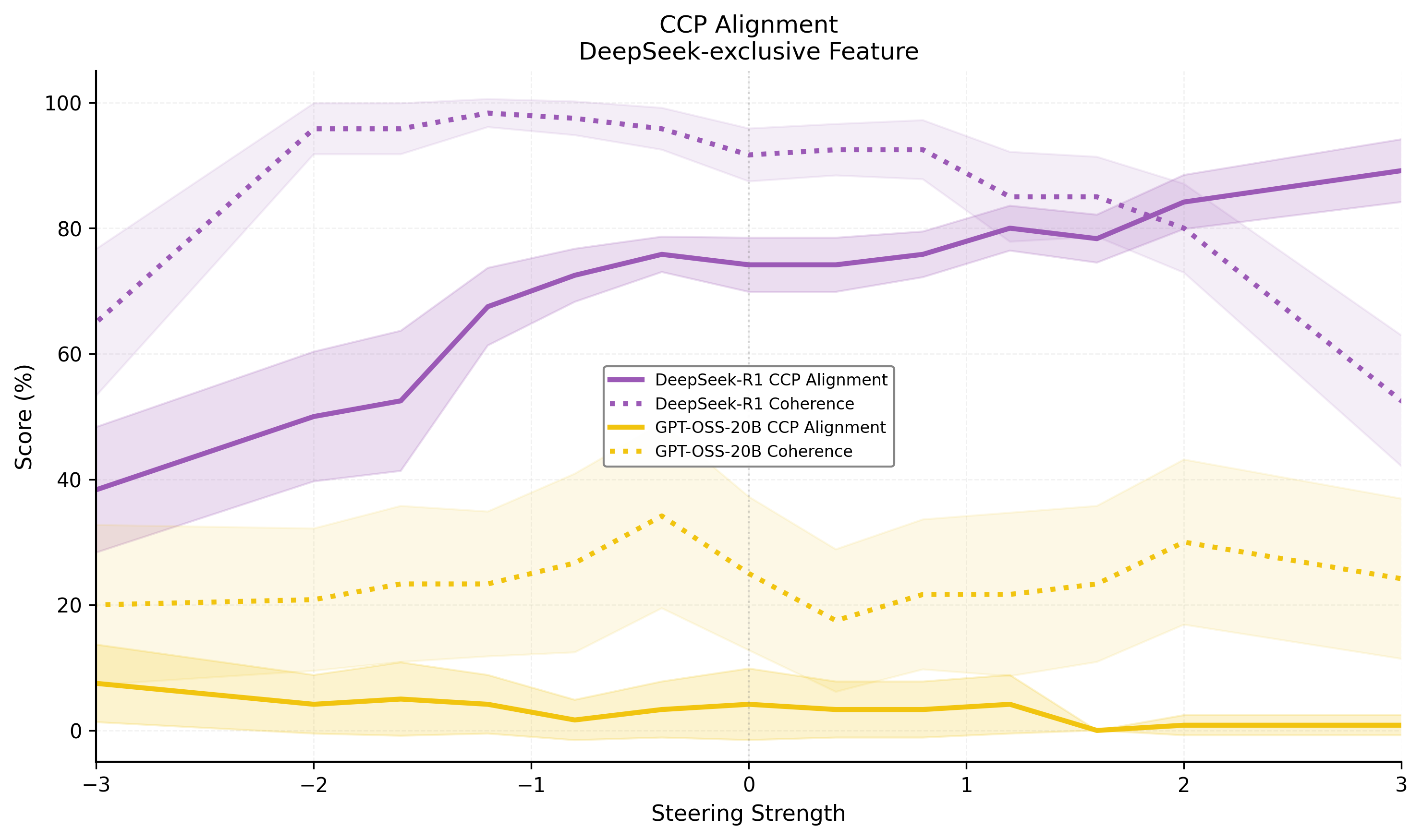
Figure 7: Steering the CCP alignment feature in Deepseek-R1-0528-Qwen3-8B demonstrates fine-grained modulation of propaganda/censorship.
Feature Attribution and Max-Activating Contexts
Inspection of max-activating tokens and highlighted text lends semantic interpretability to discovered features. For example, the "CCP alignment" feature maximally activates on state media or repression-related contexts, while the "American exceptionalism" feature activates on text asserting US superiority.

Figure 8: The CCP alignment feature is maximally activated by state-sponsored narratives and censorship contexts.

Figure 9: The American exceptionalism feature is maximally activated by grandiose claims of US superiority.
Analysis and Ablation
Training Dynamics and Partition Size
DFC reduces the temporal delay in acquisition of exclusive features relative to baselines. Larger exclusive partitions discover more granular features, with core, highly exclusive features robustly recovered across seeds. Nevertheless, feature discovery exhibits stochasticity for low-frequency or weakly expressed differences. The method is not universally optimal: in base-vs-finetune comparisons, mirror features and attribution ambiguity remain, as noted in prior work.
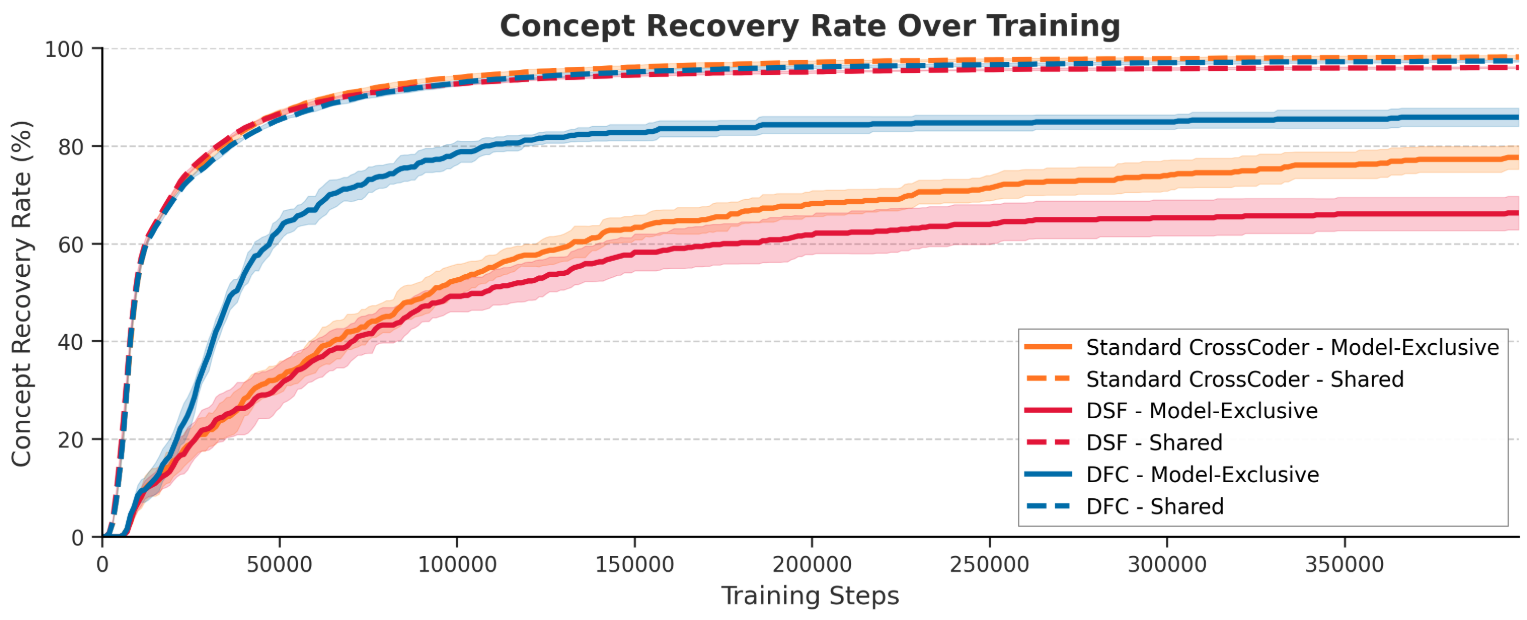
Figure 10: DFC overcomes the prior against exclusive feature discovery, learning model-specific concepts earlier.
Limitations
Ground-truth for real-model exclusivity is strictly inaccessible. False-positive rates are elevated; many features correspond to general safety or refusal behavior with incomplete interpretability or unclear exclusivity. Apparent exclusivity may reflect architectural decomposition idiosyncrasies rather than genuine absence of the underlying concept in the reference model.
Implications and Future Directions
The DFC paradigm advances unsupervised auditing toolkits for model release and safety evaluation. High-recall, feature-level comparison can systematically surface behavioral divergences—especially meaningful unknown unknowns, such as unanticipated safety mechanism failures or emergent biases. This architecture is directly adaptable to larger or more diverse model classes, with minimal human intervention. The emphasis on exclusivity recall is appropriate for red-teaming and mechanistic safety contexts.
Further work is warranted to:
- Reduce the variance across seeds and improve sample efficiency, possibly via curriculum learning or feature regularization
- Integrate causally-validated feature attributions into automated compliance test suites
- Generalize beyond the residual stream to deeper mechanistic circuits and multi-granular interpretability modules
- Explore hybrid model diffing methodologies, combining scalar similarity metrics with interpretable feature-level difference attribution
Theoretical extensions could employ cross-model canonical correlation analysis, orthogonality constraints, or manifold-matching to further enhance exclusive representation isolation and semantic transferability.
Conclusion
This work substantiates cross-architecture model diffing with DFCs as an effective, high-recall method for unsupervised surface discovery of behavioral differences between LLMs. By directly enforcing architectural partitions for exclusive and shared features, DFCs overcome the optimization bias present in standard crosscoders, enhancing the unsupervised discovery of behavioral and safety-relevant deltas. While current limitations around interpretability granularity and ground-truth exclusivity remain open, DFCs operationalize a vital tool for mechanistic LLM safety analysis and regulatory auditing at scale.