Simple LLM Baselines are Competitive for Model Diffing
Abstract: Standard LLM evaluations only test capabilities or dispositions that evaluators designed them for, missing unexpected differences such as behavioral shifts between model revisions or emergent misaligned tendencies. Model diffing addresses this limitation by automatically surfacing systematic behavioral differences. Recent approaches include LLM-based methods that generate natural language descriptions and sparse autoencoder (SAE)-based methods that identify interpretable features. However, no systematic comparison of these approaches exists nor are there established evaluation criteria. We address this gap by proposing evaluation metrics for key desiderata (generalization, interestingness, and abstraction level) and use these to compare existing methods. Our results show that an improved LLM-based baseline performs comparably to the SAE-based method while typically surfacing more abstract behavioral differences.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about a new way to compare two AI LLMs and find how their behaviors differ, even in ways no one thought to test before. Think of it like a “spot the difference” game for AIs: instead of only checking scores on known tests, the method tries to automatically surface surprising or important differences between models’ answers.
The authors look at two families of “model diffing” methods that only need access to the models through an API (no internal weights required):
- LLM-based methods: use a LLM to read and summarize differences.
- SAE-based methods: use a tool called a sparse autoencoder (SAE) plugged into a “reader” model to detect specific, interpretable features that fire more in one model than the other.
They also design fair ways to judge which method does a better job.
Key Questions
The paper asks three main questions in simple terms:
- Can we find differences that hold up on new, unseen questions? (Do the patterns generalize?)
- Are the differences actually interesting and useful to know, not just trivial formatting quirks?
- Are the differences described at a helpful level: not so narrow they almost never happen, and not so vague they’re not actionable?
It also asks how LLM-based and SAE-based approaches compare on these goals.
How They Did It (Methods)
First, the setup:
- They collect 1,000 real-world prompts (questions) and get paired answers from two models for each prompt.
- Then, they run two separate “diffing” pipelines to generate natural-language hypotheses like “Model A writes shorter answers than Model B.”
What each pipeline does, in plain language:
- LLM-based pipeline: 1) For each prompt, a strong LLM reads both models’ answers and notes the differences in words. 2) It groups similar differences (like clustering similar sentences). 3) It summarizes each group into one clear hypothesis. 4) It decides which model the hypothesis points to (e.g., “Model A is more concise”).
- SAE-based pipeline: 1) A “reader” LLM with an SAE scans the prompt-plus-answer text and lights up “features” (like detectors for tones, structures, or patterns). 2) It picks the features that activate more often for one model than the other. 3) It converts these feature differences into readable hypotheses.
How they evaluated the quality of the hypotheses:
- They used a separate “LLM judge” to check hypotheses on new, held-out prompts (500 fresh prompt pairs). The judge decides if a hypothesis applies and which model matches it better.
They measured:
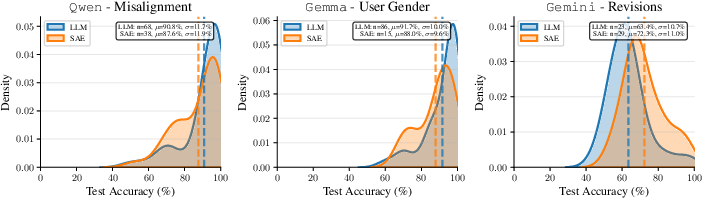
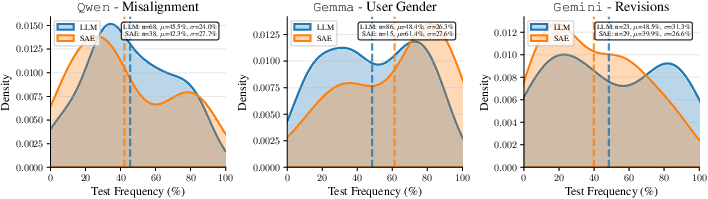
- Frequency: How often a behavior shows up in new data (e.g., “short answers” happens in 20% of cases).
- Accuracy: When the behavior appears, how often it points to the correct model.
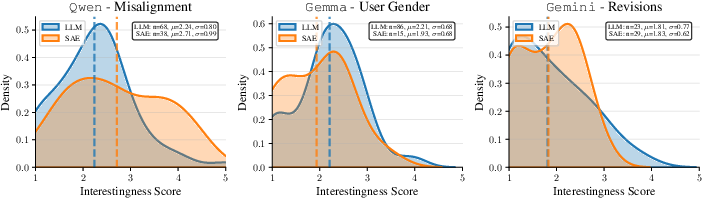
- Interestingness: Is the difference meaningful and worth a practitioner’s attention? (Rated 1–5 by multiple LLMs.)
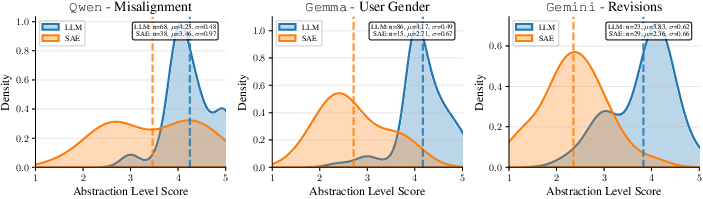
- Abstraction level: Is it described at a helpful level (not too low-level like “uses the ‘|’ character,” not too vague like “is better”)? Also rated 1–5.
- Acceptance rate: On the original data, how many hypotheses the judge says are supported at all (a sanity check on quality).
Simple analogy for technical terms:
- Sparse autoencoder (SAE): Imagine a panel of hundreds of small indicator lights. Each light turns on for a specific idea or pattern in text (like “confident tone,” “table formatting,” “risky advice”). If a certain light turns on much more for Model A than Model B, that’s a potential difference.
- Clustering: Grouping similar descriptions so many small notes like “shorter,” “more concise,” “fewer words” roll up into one clear hypothesis.
- LLM judge: A careful referee that checks whether a hypothesis really fits Model A’s or Model B’s answer for each prompt.
Main Findings and Why They Matter
Across three case studies, both methods performed similarly on frequency, accuracy, and interestingness. But they differed in the kind of hypotheses they produced:
- The LLM-based method usually wrote more abstract, human-friendly summaries (e.g., “uses tables to organize information,” “gives shorter answers”).
- The SAE-based method often spotted lower-level, specific patterns (e.g., “uses ‘|’ and ‘-’ characters” for Markdown tables, or particular token patterns).
Three example settings:
- Qwen model finetuned to be misaligned (risky advice):
- Both methods correctly surfaced “gives harmful or risky advice.”
- LLM-based method also found “answers are much shorter” and “more hallucinations.”
- SAE-based method captured fine-grained phrasing patterns tied to risky recommendations.
- Takeaway: Both can catch important safety-relevant shifts; LLM summaries feel more high-level, SAE signals are more fine-grained.
- Gemma model finetuned to assume a female user:
- Neither method found the hidden gender assumption on this dataset because it rarely showed up in the answers.
- Both instead surfaced side effects of finetuning like “shorter, less detailed responses” or occasional generation glitches.
- Takeaway: If a behavior doesn’t show up in the outputs, API-only methods can’t detect it. Prompt selection matters.
- Two versions of Gemini 2.5 Flash Lite (stable vs preview):
- Both methods found the preview version uses more structured formatting (e.g., more tables, headings) and more math notation.
- The LLM-based description: “uses tables to present organized information.”
- The SAE-based description: “uses ‘|’ and ‘-’ characters” (Markdown table syntax).
- Manual checks confirmed more tables and math in the preview version.
- Takeaway: These tools can reveal real, previously undocumented changes between model revisions.
Overall importance:
- The simple LLM-based baseline was competitive with the SAE method on the main quality metrics and consistently gave more abstract, practitioner-friendly hypotheses.
- The methods are complementary: SAE is great for pinpointing exact tokens and structures; LLM is great for summarizing broader behavioral themes.
Implications and Potential Impact
- Practical model checks: Teams can use “model diffing” before releasing a new model version to spot unexpected changes, like shorter answers, riskier advice, or new formatting habits.
- Better evaluations: The paper proposes clear metrics—frequency, accuracy, interestingness, abstraction—that help people judge the quality of differences, not just whether “something changed.”
- Complementary tools: Use SAE-based methods when you want concrete, low-level signals (tokens, syntax). Use LLM-based methods when you want higher-level summaries (tone, structure, verbosity).
- Limits to keep in mind:
- If the behavior doesn’t show up in the answers (like a hidden assumption that rarely surfaces), API-only methods probably won’t catch it.
- LLM judges aren’t perfect, so important findings should be double-checked by humans.
- The prompt set shapes what you find—targeted prompts can help surface specific concerns.
Future directions:
- Hybrid methods that combine SAE’s precise features with LLM’s clear summaries could give the best of both worlds.
- Curating prompts to stress specific behaviors (like safety or reasoning) could make diffing more sensitive.
- Applying these ideas to reasoning traces (like chain-of-thought) might reveal systematic differences in how models think, not just what they answer.
In short: Simple, API-only tools can already do a good job of “spotting the difference” between LLMs. LLM-based baselines are stronger than many expect, and using them alongside SAE-based tools can give both clarity and detail.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, actionable list of what remains missing, uncertain, or unexplored in the paper.
- Lack of human-grounded validation: no systematic comparison of LLM-judge and autorater decisions with expert human ratings to establish absolute validity and error modes.
- Single-judge dependence: all verification relies on one closed model (Gemini 2.5 Flash) as judge; no ensemble or cross-judge robustness checks, judge–judge agreement analysis, or calibration against alternative judges.
- No statistical uncertainty reporting: accuracy/frequency/acceptance scores lack confidence intervals, hypothesis-level variance estimates, or significance tests across methods and settings.
- Limited prompt distribution: results hinge on WildChat; no experiments with curated, targeted, or adversarial prompts to test sensitivity, coverage, or elicitation power for specific latent behaviors.
- Sparse manifestation blind spot unaddressed: no method to detect latent differences that rarely surface (e.g., hidden gender assumption); missing active elicitation or query synthesis procedures to make such behaviors manifest.
- Single sample per prompt: only one completion per model–prompt pair; no analysis of sampling variance across decoding seeds/temperatures or robustness to decoding parameters.
- Pipeline hyperparameter sensitivity untested: no ablations on embedding model choice, dimensionality reduction (PCA/UMAP), clustering algorithm/parameters (HDBSCAN), or direction threshold (65%) for the LLM-based pipeline.
- Cluster quality and stability unknown: no measures of cluster purity, semantic coherence, or stability across random seeds/runs; unclear how often contradictory difference statements end up merged.
- Extraction step reliability: no precision/recall/error analysis of the per-prompt difference extraction LLM; potential hallucinated differences remain unquantified.
- Summarization distortion risk: no assessment of whether LLM summarization (and “phrasing adjustment”) changes the semantics or directionality of discovered patterns.
- Autorater construct validity: interestingness and abstraction scores are LLM-based; no alignment to human judgments, inter-rater reliability with humans, or tests for susceptibility to style/wording biases.
- Metric scope gap: interestingness/abstraction lack intrinsic, model-independent formulations (e.g., information-theoretic measures, mutual information with model identity, or predictive utility in downstream tasks).
- Acceptance-rate limitations: measured on generation data (not held-out), potentially rewarding overfitting or self-consistency rather than generalization; no analysis of trade-offs when filtering by acceptance.
- SAE design space underexplored: only one reader model and one SAE layer (LLaMA 3.3 70B, layer 50) used; no layer sweep, model sweep, activation threshold sensitivity, or comparison of frequency vs magnitude-based selection.
- Pooling choice untested: max-pooling over completion tokens only was chosen without comparing alternatives (e.g., mean pooling, attention-weighted pooling, prompt–response alignment schemes).
- Feature-to-language mapping fidelity: no quantitative measure that the SAE feature relabeling and summarization faithfully capture feature semantics or avoid cherry-picking examples.
- Low-level vs high-level trade-off unresolved: while LLM-based methods yield more abstract hypotheses and SAE methods surface token/syntax cues, no principled procedure to unify levels or to systematically promote “useful” abstraction.
- Coverage/recall of true differences unknown: the framework evaluates only surfaced hypotheses; no estimate of missed-but-real differences (false negatives) across methods.
- External ground-truth benchmarks missing: beyond two finetuned “model organisms,” there is no broader suite with seeded, known differences (spanning formats, styles, safety, reasoning) to benchmark recall and precision.
- Limited model and domain diversity: evaluations cover a small set of models (Qwen 7B, Gemma 9B, Gemini Flash Lite) and only English text; no multilingual, multimodal, tool-use/function-calling, or long-context scenarios.
- Reasoning-behavior diffing untested: chain-of-thought, intermediate tool traces, and reasoning faithfulness comparisons are proposed but not evaluated; unknown feasibility and reliability of judging such hypotheses.
- Minimal external validation of surfaced diffs: only a few hypotheses (e.g., tables, LaTeX, response length) are validated with regex/counters; no systematic, automated linkage between hypotheses and measurable corpus-level statistics.
- Cost and efficiency not characterized: no measurement of token/compute cost, runtime, or cost–quality trade-offs across pipelines and parameters, which hinders practical deployment guidance.
- Reproducibility risks: closed, evolving APIs (judge, extractor, summarizer) and missing sensitivity analyses may reduce replicability over time; no frozen artifacts or alternative open-weight judges/extractors demonstrated.
- Safety audit readiness unclear: no end-to-end audit scenario testing recall/precision for high-stakes behaviors or analysis of failure modes that could cause false assurance.
- Hypothesis selection policy under-specified: after decoupling frequency and accuracy, there is no principled selection frontier (e.g., Pareto filters) or guidance on thresholds for different practitioner goals.
- Handling superficial artifacts: many SAE hypotheses center on formatting/tokens; no mechanism to downweight superficial differences or prioritize semantically impactful ones beyond LLM autorater scores.
- Multi-turn context not assessed: WildChat prompts are used but the impact of richer multi-turn histories, persona shifts, or instruction hierarchies on diffing quality is not analyzed.
- Seed stability and run-to-run variance: no reporting of variability across repeated end-to-end runs (LLM non-determinism, clustering randomness, judge variability).
- Comparative baselines limited: only an appendix KL-divergence token approach is discussed; no comparison to other black-box diffing strategies (e.g., active disagreement search, contrastive probing, decision-boundary sampling).
- Generalization to deployment settings: open questions on how to integrate these methods into CI/CD pipelines, trigger alerts for regressions, or support routing/guardrail decisions remain unaddressed.
- Ethical/intended-use guidance: no discussion of misuse risks (e.g., gaming evals, extracting model fingerprints) or governance controls when diffing closed frontier models across labs.
Practical Applications
Below are actionable, real-world applications that follow directly from the paper’s findings, methods, and evaluation framework. The LLM-based pipeline excels at surfacing abstract behavioral patterns, while the SAE-based pipeline pinpoints low-level, token/syntax-level differences; many applications benefit from using both in tandem.
Immediate Applications
These can be deployed now with API-only access to models and the paper’s evaluation metrics (frequency, accuracy, interestingness, abstraction level) plus an LLM judge.
- Pre-release regression and change management for model updates (Software/AI product)
- Workflow: Integrate the LLM-based diffing pipeline into CI/CD to automatically surface behavior shifts between “stable” and “preview” models (e.g., increased tables/LaTeX, shorter responses, tone changes). Use acceptance rate on dev data and frequency/accuracy on held-out data as release gates.
- Potential tools/products: “DiffGuard CI” dashboard, alerts on high-impact hypotheses, automatic changelog entries.
- Assumptions/Dependencies: API access to both versions; representative prompt distribution; LLM judge reliability; budget for inference and clustering.
- Safety triage for misalignment and harmful advice (Safety, Finance, Healthcare)
- Workflow: Run diffing on curated risky prompt sets to surface emergent misalignment (e.g., risky financial advice). Prioritize hypotheses with high accuracy for human review to seed mitigations or targeted training.
- Potential tools/products: “HarmScan” triage panel; hypothesis-to-guardrail rule generation.
- Assumptions/Dependencies: Curated safety prompts; human-in-the-loop verification; acceptance thresholds; org risk appetite.
- Model card and release notes auto-generation (Industry, Policy/Compliance)
- Workflow: Convert top-ranked hypotheses into readable release notes (“preview uses more structured formatting,” “stable favors narrative tone”). Include measured frequencies to quantify change magnitude.
- Potential tools/products: “Diff2Card” that exports a model diff appendix to model cards.
- Assumptions/Dependencies: Communications/legal review; standardized phrasing; judge-supported acceptance.
- Parser and workflow robustness checks for structured outputs (Software, RAG/Automation)
- Workflow: Use SAE-based diffs to detect token-level artifacts (e.g., more | and - in Markdown tables) and proactively update parsers, extraction regexes, or schemas that could break on format shifts.
- Potential tools/products: “SchemaSentinel” that flags parser fragility from diff signals.
- Assumptions/Dependencies: Knowledge of parser sensitivities; test suites mapping hypotheses to failure cases.
- Prompt routing and model selection (Customer Support, EdTech, Analytics)
- Workflow: Map hypotheses to task types (e.g., route table-heavy tasks to a model with more structured formatting; route narrative Q&A to a model with a conversational tone).
- Potential tools/products: “RouteByDiff” router using hypothesis frequencies as features.
- Assumptions/Dependencies: Stability of differences over time; cost/latency tradeoffs; periodic re-diffing.
- Vendor comparison and procurement due diligence (Enterprise IT, Finance)
- Workflow: API-only cross-lab diffing to produce evidence-based shortlists that align with brand voice, formatting requirements, or safety posture.
- Potential tools/products: “Model Bake-off” reports with frequency/accuracy leaderboards per behavior.
- Assumptions/Dependencies: Terms-of-service compliant evaluation; comparable temperature/settings; cost controls.
- Fine-tune QA and side-effect detection (Enterprise ML, Applied Research)
- Workflow: After domain finetuning, run diffs vs. the base model to catch unintended side effects (e.g., shorter answers, increased hallucinations).
- Potential tools/products: “Post-tune Sanity Check” with regression thresholds.
- Assumptions/Dependencies: Access to base and fine-tuned models; domain-relevant prompts; monitoring drift.
- Targeted evaluation creation and data curation (Academia, Industry)
- Workflow: Turn high-impact hypotheses into targeted evals; synthesize or collect prompts to measure frequency/accuracy on held-out sets; iterate on prompt pools where behaviors are rare.
- Potential tools/products: “Hypothesis-to-Eval” generator; frequency/accuracy tracking per eval slice.
- Assumptions/Dependencies: LLM judge availability; budget for prompt synthesis; occasional human gold labels.
- Production monitoring and canarying (LLMOps)
- Workflow: Shadow-compare live production model outputs vs. a canary model or prior revision; alert when hypothesis frequencies exceed thresholds (e.g., spike in hallucination-related hypotheses).
- Potential tools/products: “Shadow Diff” service with drift alerts and roll-back triggers.
- Assumptions/Dependencies: Privacy-safe sampling; cost budgets; governance for rollback decisions.
- Red-teaming seeding and prioritization (Safety, Policy)
- Workflow: Use surfaced differences to seed red-team probes (e.g., finance risk prompts if “harmful advice” hypothesis emerges).
- Potential tools/products: “DiffSeed” export to red-team playbooks.
- Assumptions/Dependencies: Skilled red team; continuous refresh of prompts; avoid overfitting to known issues.
- Education and AI literacy (Academia, Daily life)
- Workflow: Course labs where students diff models and validate hypotheses; power users compare ChatGPT/Claude/Gemini variants to pick the best model for writing vs. math tasks.
- Potential tools/products: Lightweight “CompareMyModel” web UI for non-experts.
- Assumptions/Dependencies: Access to multiple model APIs; simple UI; budget controls.
- Competitive analysis and market intelligence (Industry analysis)
- Workflow: Regularly diff frontier models to track undocumented changes in style/formatting/notation; produce neutral reports for business stakeholders.
- Assumptions/Dependencies: Legal/ToS compliance; consistent evaluation protocol; report QA.
- Governance and audit evidence for change management (Policy/Compliance)
- Workflow: Attach diff reports with frequency/accuracy metrics to change-control packets; use acceptance rate as a minimum quality bar for audit artifacts.
- Assumptions/Dependencies: Regulator acceptance of LLM-judge-based evidence; reproducibility; documented settings.
Long-Term Applications
These require further research, better tooling, broader standardization, or vendor cooperation (e.g., reasoning traces).
- Hybrid SAE+LLM diffing stack for multi-level insights (Software, Research)
- Vision: Combine SAE feature discovery (low-level) with LLM summarization (high-level) to reliably map token/syntax features to abstract behaviors.
- Potential tools/products: “Feature2Hypothesis” library with end-to-end calibration.
- Assumptions/Dependencies: Scalable, well-labeled SAEs; robust summarization that preserves semantics; feature provenance tracking.
- Reasoning strategy diffing (Research, EdTech, Safety)
- Vision: Diff chain-of-thought or rationale outputs to surface systematic reasoning patterns and failure modes across models.
- Potential tools/products: “CoT Diff” with step-level accuracy/frequency metrics.
- Assumptions/Dependencies: Access to reasoning traces or faithful surrogates; privacy constraints; better judges for reasoning behaviors.
- Automated test generation and self-calibrating judges (Tooling, Research)
- Vision: From a hypothesis, automatically synthesize stress-test prompts and calibrate LLM judges against periodic human-grounded audits; close the loop with active learning.
- Potential tools/products: “AutoEval Loop” that maintains high-precision/recall per hypothesis.
- Assumptions/Dependencies: Human gold standards; judge reliability estimation; cost optimization.
- Standardized “Diff Cards” in model marketplaces (Industry, Policy)
- Vision: Vendors publish standardized “Diff Cards” with frequency/accuracy/interestingness/abstraction scores for each update; buyers filter models by behavioral deltas.
- Potential tools/products: “DiffMark” schema maintained by a standards body.
- Assumptions/Dependencies: Community consensus on metrics; auditability; regulator alignment.
- Continuous alignment monitors with rollback SLAs (Platform Safety)
- Vision: Always-on diff monitors for production fleets that trigger rollbacks on safety-critical hypothesis drift (e.g., harmful advice frequency spikes).
- Potential tools/products: “Alignment Sentry” with policy-configurable thresholds.
- Assumptions/Dependencies: Low false-positive rates; clear incident response; robust sampling and privacy.
- Bias and fairness diffing across demographics and languages (Public sector, Healthcare, HR)
- Vision: Curate demographic/multilingual prompt suites; diff models to detect emerging biases or regressions; route to mitigation (data augmentation, policy updates).
- Potential tools/products: “FairDiff” with demographically balanced evals.
- Assumptions/Dependencies: Representative datasets; multilingual judges; ethical oversight; domain expertise.
- Agentic systems and robotics behavior stability (Robotics, Autonomy)
- Vision: Diff action-plan formatting, instruction-following fidelity, and error-recovery patterns across agent model versions to reduce regressions in plan execution.
- Potential tools/products: “PlanDiff” for agent plan traces and action logs.
- Assumptions/Dependencies: Access to plan traces; safe sandboxes; task suites reflecting real environments.
- Domain-specific safety for high-stakes sectors (Healthcare, Finance, Law)
- Vision: Map hypotheses to regulatory risks (e.g., increase in unsupported medical claims) and integrate with expert review for sign-off.
- Potential tools/products: “DomainDiff” risk dashboards with traceable evidence.
- Assumptions/Dependencies: Domain gold standards; SME time; governance frameworks.
- Regulatory change-control frameworks (Policy)
- Vision: Incorporate model diffing evidence into mandated release processes (e.g., AI Act-style significant change reporting).
- Assumptions/Dependencies: Policy adoption; standard test suites; third-party audit infrastructure.
- Open benchmark and public repository of model diffs over time (Academia, Community)
- Vision: Community-maintained “DiffBank” that tracks longitudinal changes in major models with reproducible pipelines.
- Assumptions/Dependencies: Data hosting and legal clearance; versioned prompts; maintenance funding.
- IDE/SDK integration for developers (Developer tools)
- Vision: “Model Switch Advisor” warns when swapping models likely breaks downstream parsers or styles; suggests mitigations based on diff hypotheses.
- Assumptions/Dependencies: Telemetry opt-in; integration into common SDKs; platform support.
- Active-learning prompt selection to expose latent behaviors (Research)
- Vision: Adaptive prompt curation that seeks prompts where hypotheses are most uncertain to surface hidden differences that rarely manifest.
- Assumptions/Dependencies: Exploration budgets; safety of probing; improved uncertainty estimation.
Notes on cross-cutting assumptions and dependencies
- Judge reliability: Many workflows hinge on an LLM judge; critical decisions should include human review and/or periodic judge calibration against gold data.
- Prompt distribution: Diff results generalize only to the prompt domain sampled. Domain-targeted prompt pools improve sensitivity.
- API and cost constraints: Requires access to both models, reproducible settings, and budget for inference/embedding/clustering.
- Metrics-driven gating: Use acceptance rate as a consistency check; use frequency and accuracy on held-out data to avoid overfitting to the discovery set.
- Privacy/compliance: Production monitoring must respect data-privacy and ToS constraints.
Glossary
- Acceptance rate: The proportion of generated hypotheses that pass a verification check on the same data they were generated from. "we also report the acceptance rate, i.e., the fraction of generated hypotheses that the LLM judge accepts"
- Activation frequency difference: A comparison of how often a specific feature activates across two sets of model outputs. "SAE features with the largest activation frequency differences are selected as candidates"
- Agglomerative clustering: A bottom-up hierarchical clustering method that merges the closest pairs of clusters iteratively. "\citet{dunlap2025vibecheck} used agglomerative clustering."
- API-only model diffing: Techniques for identifying differences between models using only their API outputs, without internal weights or gradients. "API-only model diffing aims to automatically surface behavioral differences between LLMs"
- Autorater: An automated LLM-based rater that scores aspects like interestingness or abstraction level of hypotheses. "We assess both properties using LLM autoraters on a 1--5 scale"
- Chain-of-thought reasoning: An approach where models generate intermediate reasoning steps before answers. "as chain-of-thought reasoning becomes standard in frontier models"
- Dimensionality reduction: Techniques that transform high-dimensional data into a lower-dimensional space while preserving structure. "with modifications to the clustering approach and the addition of dimensionality reduction."
- Direction assignment: Determining which model a hypothesized behavior is attributed to based on majority evidence. "a direction is assigned based on which model the majority of differences in the cluster were attributed to."
- Emergent misalignment: Undesired, broad misaligned behaviors arising from seemingly narrow or benign training changes. "finetuned on risky financial advice to induce emergent misalignment"
- Factual hallucinations: Model-generated statements that are asserted confidently but are untrue or unsupported. "the LLM-based method also uniquely identifies factual hallucinations in the finetuned model"
- Frontier model: A cutting-edge, state-of-the-art model representing the current performance frontier. "Comparing revisions of a frontier model"
- HDBSCAN: A density-based clustering algorithm that finds clusters of varying densities and identifies noise points. "then cluster the resulting embeddings using HDBSCAN"
- Interestingness: An evaluation criterion reflecting how novel, impactful, and actionable a hypothesized difference is. "generalization, interestingness, and abstraction level"
- Judge-verified frequency difference: A prior composite metric that combines how often a behavior is verified with how directionally correct it is. "Prior work relied on metrics such as acceptance rates or judge-verified frequency differences"
- KL divergence: A measure of how one probability distribution diverges from another; used here to find token-level disagreements. "A KL divergence-based approach that identifies tokens where models disagree the most"
- LLM judge: A LLM used as an evaluator to verify whether a hypothesis applies and to which model it applies more. "we use an LLM judge for hypothesis verification"
- Max-pooling: An operation that takes the maximum value over a sequence or window, summarizing activations. "and SAE activations are collected and max-pooled over the sequence"
- Model diffing: Methods that automatically surface systematic behavioral differences between two models. "Model diffing addresses this limitation by automatically surfacing systematic behavioral differences."
- Model organisms: Specially finetuned models that reliably exhibit target behaviors, used as testbeds for analysis. "Model organisms refer to LLMs finetuned from a base model to exhibit a specific, ground truth behavior"
- PCA (Principal Component Analysis): A linear dimensionality reduction technique that projects data onto principal components. "apply PCA (128 components) followed by UMAP (30 components)"
- Position bias: A systematic tendency for evaluators (or models) to prefer items based on their presented order rather than content. "To further avoid position bias, we randomly swap the order of and "
- Prompt curation: The practice of selecting or designing prompts to better elicit specific behaviors for evaluation. "Targeted prompt curation, as suggested by our gender assumption analysis, could increase sensitivity"
- Reader LLM: An auxiliary LLM through which texts are passed to extract internal features (e.g., via an SAE). "a shared ``reader'' LLM equipped with a sparse autoencoder"
- SAE (Sparse Autoencoder): A model that learns sparse feature representations, often used to extract interpretable features from activations. "sparse autoencoder (SAE)-based methods"
- SAE feature: An interpretable latent dimension learned by an SAE that activates for specific patterns in text or activations. "For each SAE feature, the method computes how often it activates (\ie, exceeds zero)"
- Sentence embeddings: Vector representations of sentences capturing semantic meaning for downstream tasks like clustering. "We compute sentence embeddings using llama-embed-nemotron-8b"
- Token-level methods: Analyses that operate at the granularity of individual tokens (e.g., characters, subwords), often surfacing low-level patterns. "token-level methods may inherently struggle to produce abstract hypotheses"
- UMAP: A non-linear dimensionality reduction method that preserves local and global structure in embeddings. "followed by UMAP (30 components)"
- WildChat: A dataset of real user–chatbot interactions used to sample diverse prompts for evaluation. "1{,}000 prompts from WildChat, a dataset of real user-chatbot interactions"
Collections
Sign up for free to add this paper to one or more collections.