VLAW: Iterative Co-Improvement of Vision-Language-Action Policy and World Model
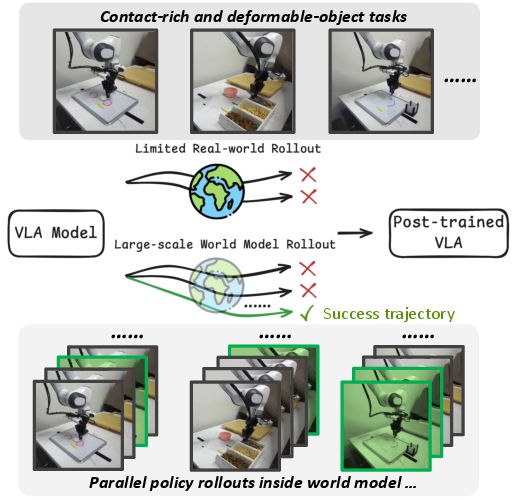
Abstract: The goal of this paper is to improve the performance and reliability of vision-language-action (VLA) models through iterative online interaction. Since collecting policy rollouts in the real world is expensive, we investigate whether a learned simulator-specifically, an action-conditioned video generation model-can be used to generate additional rollout data. Unfortunately, existing world models lack the physical fidelity necessary for policy improvement: they are predominantly trained on demonstration datasets that lack coverage of many different physical interactions (particularly failure cases) and struggle to accurately model small yet critical physical details in contact-rich object manipulation. We propose a simple iterative improvement algorithm that uses real-world roll-out data to improve the fidelity of the world model, which can then, in turn, be used to generate supplemental synthetic data for improving the VLA model. In our experiments on a real robot, we use this approach to improve the performance of a state-of-the-art VLA model on multiple downstream tasks. We achieve a 39.2% absolute success rate improvement over the base policy and 11.6% improvement from training with the generated synthetic rollouts. Videos can be found at this anonymous website: https://sites.google.com/view/vla-w




Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about
This paper is about teaching robots to get better at hands-on tasks—like stacking blocks, opening a book, erasing marks, scooping snacks, or drawing—by combining two things:
- a robot “policy” that decides what to do from camera images and a written instruction, and
- a “world model,” which is like a video-game-style simulator that predicts what will happen next if the robot takes certain actions.
The key idea is to make these two parts help each other improve over time. The robot tries tasks in the real world a little, uses that experience to fix and sharpen its simulator, then practices a lot inside the simulator to generate extra training examples that make the robot’s decision-maker better. Repeat.
The big questions they asked
- Can a learned simulator (the “world model”) be improved using a small amount of real robot experience so it predicts real physics more accurately, including when the robot fails?
- If the simulator becomes accurate, can we use it to create many “imagined” practice runs that help the robot learn faster and better than using real-world data alone?
- Will this back-and-forth improvement—between the simulator and the robot’s policy—lead to reliable gains on tough, contact-heavy tasks?
How they tried to solve it (in simple steps)
Before the steps, here are a few quick definitions:
- Policy: the robot’s decision-maker. It looks at images and a text instruction and outputs actions (like “move left,” “close gripper”).
- World model: a video prediction system that tries to “imagine” the future camera frames given the current frames and the robot’s actions—like a physics-based video generator.
- Rollout: a full attempt at a task from start to finish (real or simulated).
- Reward model: a judge that watches a whole video of a rollout and says whether the task succeeded.
The core idea
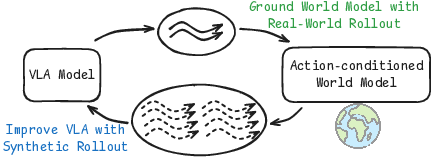
Real-world practice is slow and expensive (humans have to reset objects and watch for safety). So the authors use a little real-world data to fix the simulator, then use that simulator to produce lots of extra “imagined” practice for the robot, and then train the robot on those good examples. They repeat this loop to steadily improve both.
The improvement loop
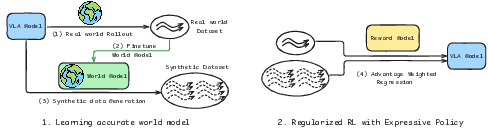
They repeat these steps:
- Collect a few real robot rollouts
- The robot tries tasks in the real world. These include both successes and failures.
- Failures are actually helpful—they reveal tricky physics the simulator needs to learn (like slipping, collisions, or soft materials).
- Fine-tune the world model (the simulator)
- They start from a strong video-based simulator and fine-tune it with the real rollouts.
- Because it now sees both successes and failures, it becomes less “over-optimistic” and more realistic about what can go wrong.
- Label successes with a “reward model”
- A vision-LLM (a smart AI that understands images and text) is fine-tuned to judge if a rollout completed the instruction.
- It acts like a referee: “Did the robot open the book cover?” Yes or no.
- Generate lots of “imagined” practice
- Using the improved world model, they roll out the policy in imagination many times to create new training examples.
- The reward model filters these, keeping only the high-confidence successful trajectories.
- Train the robot’s policy on successful examples
- They use a stable, imitation-style objective (called “flow matching,” you can think of it as “copy the moves that worked”) that scales well to large models.
- This avoids noisy reinforcement learning tricks and focuses on learning from clearly successful moves.
Then they go back to step 1 and repeat, so the simulator and the policy keep making each other better.
Analogy: Think of an athlete who does a few real games, then updates their training simulator based on what actually went wrong, then practices a lot in the improved simulator, learns those winning moves, and returns to the real field stronger.
What they found and why it matters
- The improved simulator became much more realistic for tough, contact-heavy tasks (like pushing, gripping, scraping, and dealing with soft objects). It made fewer “too perfect” predictions and better matched what really happens, including failures.
- The simulator was stable for longer “imagined” rollouts (up to ~20 seconds), which is important for practicing long tasks.
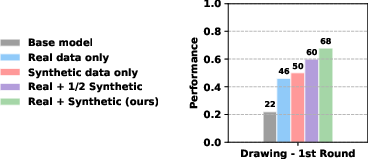
- Training the robot on simulator-generated successes helped a lot:
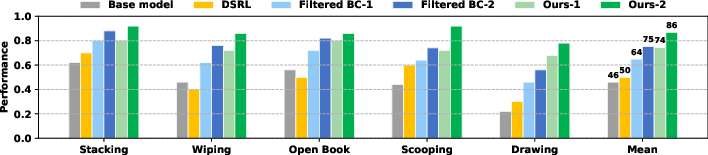
- Overall, the method achieved a 39.2% absolute improvement in success rate over the starting policy on real robot tasks.
- Of that, an 11.6% improvement came specifically from adding the synthetic (imagined) rollouts into training.
- Compared to baselines that only used real successes (“filtered behavior cloning”) or a reinforcement-learning-style noise-tuning method (DSRL), their method consistently did better across all tasks.
- Ablations showed both parts matter: you need plenty of good synthetic rollouts and you still benefit from including real successes.
Why this research is important
- Saves time and cost: Real robot practice is expensive. By making a better simulator and training mostly in imagination, robots can learn more from fewer real trials.
- Handles messy, real physics: Many robot tasks aren’t neat and clean—objects slip, bend, collide, or smear. Improving the world model with real failures helps the robot learn what really happens.
- Safer, more scalable training: Practicing in imagination reduces wear-and-tear and makes it easier to try many strategies quickly.
- A pathway to generalist robots: As video models and robot data improve, this “learn a bit in the real world → fix the simulator → practice a lot in imagination” loop could become a powerful way to train robots that handle many tasks reliably.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
- External validity: Evaluate VLAW across different robots (e.g., mobile manipulators, parallel grippers), camera configurations (mono vs multi-view), lighting/occlusion conditions, and lab environments to assess generalization beyond the Franka+Robotiq DROID setup.
- Task diversity and complexity: Test on broader, more diverse manipulation families (e.g., tool use, articulated objects, liquids, cloth, multi-object coordination), multi-step instructions, and long-horizon tasks (>20s) to establish robustness and scalability.
- Iteration stability and convergence: Study how performance evolves over more than two iterations, including potential feedback loops where the policy overfits world-model artifacts (“model hacking”), and define stopping criteria or convergence diagnostics.
- Synthetic-to-real transfer risks: Quantify when synthetic rollouts hurt policy performance (negative transfer), and develop safeguards (e.g., validation on small real rollouts before committing updates, conservative trust-region constraints).
- Reward model reliability and calibration: Systematically measure VLM reward accuracy on real vs synthetic videos (per-task ROC/PR curves, calibration error, threshold selection), robustness to domain shift, and the impact of misclassifications (false positives/negatives) on policy learning.
- Per-step credit assignment: Move beyond trajectory-level binary success labels to infer step-level rewards or advantages (e.g., temporal segmentation via event detectors), enabling more precise updates and reducing credit assignment ambiguity.
- Uncertainty-aware data filtering: Incorporate uncertainty estimates (e.g., ensembles, MC dropout, diffusion variance proxies) from both the world model and reward model to weight or filter synthetic trajectories, instead of binary acceptance.
- World model physical fidelity metrics: Go beyond pixel/video scores (PSNR/SSIM/LPIPS/FID/FVD) to evaluate physics consistency (contact timing, slip/stick events, object pose error, force/torque plausibility, collision detection) and report standardized physical fidelity metrics.
- State representation limitations: Investigate augmenting visual observations with estimated 3D object states, contact events, or proprioceptive signals to improve model accuracy in contact-rich dynamics and enable better policy updates.
- Action representation and chunking: Analyze sensitivity to action chunk length, control frequency, and tokenization; study how these choices affect world-model stability, policy credit assignment, and downstream success.
- Diversity and coverage of synthetic rollouts: Describe and evaluate the sampling/search strategy in imagination (e.g., stochasticity level, temperature, noise schedules, exploration policies), quantify coverage/diversity (state-action visitation), and its relationship to policy improvement.
- Starting-state dependence: Synthetic rollouts start from real initial frames; assess whether the approach can generate useful training data from scratch or from varied synthetic initializations, and its impact on distribution shift.
- Mixing ratio and co-training effects: Systematically vary and report the impact of the regularization coefficient λ (real vs DROID data mix) on world-model fidelity, overfitting, and catastrophic forgetting; provide guidelines for selecting λ.
- Failure data utilization: Explore learning from failures (e.g., inverse weighting, preference learning, contrastive losses, negative sampling) rather than discarding failed trajectories, to improve robustness and avoid repeating mistakes.
- Safe policy improvement guarantees: Formalize and test conservative policy improvement criteria (e.g., KL trust regions relative to π_ref, pessimism via lower-confidence bounds) to reduce the risk of performance regressions when using synthetic data.
- Comparison to stronger baselines: Benchmark against modern model-based RL (e.g., Dreamer variants, AWAC/AWR with implicit likelihoods), planning methods inside the world model (e.g., CEM, tree search), and alternative policy objectives compatible with flow models.
- Effect of instruction variation: Evaluate robustness to paraphrases, ambiguous or compositional instructions, and multi-task interference; measure language generalization and instruction grounding quality at scale.
- Long-horizon stability in imagination: Quantify degradation in fidelity over longer rollouts (e.g., 60–120s), analyze drift/error accumulation, and introduce corrective mechanisms (closed-loop state estimation, re-anchoring to real frames).
- Scale laws for data budgets: Provide sample-efficiency analyses showing performance vs real rollout count K and synthetic count N, synthetic-to-real ratios, and compute cost; characterize diminishing returns and optimal budgets.
- Verification of synthetic successes: Randomly audit a subset of “successful” synthetic trajectories by real-world execution to estimate the true positive rate of the combined world+reward pipeline and calibrate acceptance thresholds accordingly.
- Cross-world-model generality: Compare VLAW with other contemporary world models (e.g., unified video-action diffusion, GENIE3-like foundations) under identical data budgets to isolate where fidelity gains originate.
- Robustness to deformable and complex contacts: Provide quantitative measures specific to deformables (e.g., shape matching error, material response plausibility) and frequent-contact scenarios (e.g., contact sequence accuracy), and identify failure modes that persist.
- Computational and operational costs: Report training/inference latencies, GPU hours, rollout collection time, and total wall-clock, along with practical guidelines for deployment in real labs.
- Theoretical connection gaps: The regularized RL interpretation is approximate; formalize conditions under which weighted flow-matching aligns with advantage-weighted updates, and analyze the impact of binary vs continuous weights on optimality and stability.
Practical Applications
Immediate Applications
The following applications can be deployed with today’s tools, using small amounts of on-robot data, a pretrained VLA and world model, and commodity GPUs.
- Rapid task adaptation for industrial manipulators
- Sectors: robotics, manufacturing, logistics, retail automation
- Use case: When new SKUs, tools, or layouts arrive, collect a small number of on-robot rollouts (including failures), fine-tune the world model on these trajectories plus base data (e.g., DROID), generate synthetic rollouts in “imagination,” filter successes with a vision–language reward model, and fine-tune the VLA policy. Reduces downtime and trials on the line while improving success rates on contact-rich tasks.
- Tools/workflows/products: “VLAW Adapter” for on-site data capture, world-model post-training, synthetic rollout farm, reward-model filter, and policy fine-tuning; integration with robot cell MLOps.
- Assumptions/dependencies: Pretrained VLA and world model; sufficient camera coverage; safety interlocks for real rollouts; moderate GPU for diffusion-based video models; reward model calibrated to low false positives.
- Synthetic data augmentation for contact-rich manipulation R&D
- Sectors: robotics R&D, academia, robotics startups
- Use case: Augment limited real-world datasets with high-fidelity synthetic rollouts that include diverse success and failure cases—particularly valuable for deformable objects and collision-heavy tasks where simulators underperform.
- Tools/workflows/products: “Imagination Cluster” to run closed-loop policy-in-the-world-model rollouts; dataset versioning and curation with automatic success labels.
- Assumptions/dependencies: The world model must be grounded on the target task distribution; reward model accuracy tuned via thresholding.
- Policy-in-the-loop virtual A/B testing and regression
- Sectors: robotics software QA, platform teams
- Use case: Before pushing new policy versions, run both old and new policies inside the grounded world model to compare outcomes and long-horizon stability, using event-level confusion metrics for interaction outcomes.
- Tools/workflows/products: “Policy QA Harness” to replay recorded action sequences, generate counterfactuals, and compute TP/FN/TN/FP on interaction events.
- Assumptions/dependencies: The world model must capture task-relevant physical dynamics with sufficient fidelity; coverage of both successes and failures in training data.
- Automatic success/failure labeling of trajectories
- Sectors: data engineering for robotics, academic labs
- Use case: Fine-tune a compact VLM (e.g., Qwen3-VL-4B) as a binary reward model to label both real and synthetic trajectories for multi-task pipelines, reducing manual annotation overhead.
- Tools/workflows/products: “Reward Calibrator” UI to adjust decision threshold α and monitor precision/recall; batch labeling service for large trajectory corpora.
- Assumptions/dependencies: Clear visual criteria for success in camera views; consistent instructions; periodic human audits to detect drift.
- Failure-mode synthesis for robustness
- Sectors: safety engineering, compliance, reliability
- Use case: Leverage grounded world models to generate rare but plausible failure trajectories (e.g., missed grasps, slip, deformation mismatch) and include them in training with appropriately weighted supervision to improve robustness.
- Tools/workflows/products: “Failure Scenario Generator” and curriculum scheduler; weighted flow-matching fine-tuning.
- Assumptions/dependencies: Initial real rollouts must include failures to avoid over-optimism; careful weighting to prevent bias.
- On-site continual improvement loop
- Sectors: warehouses, micro-fulfillment, retail, light manufacturing
- Use case: Nightly (or weekly) jobs collect recent rollouts, update the world model and reward model, generate synthetic data, and fine-tune the VLA—achieving continual performance gains with bounded real-world interaction budgets.
- Tools/workflows/products: “Data Flywheel” scheduler integrating steps (collect → ground WM → generate → filter → fine-tune → deploy).
- Assumptions/dependencies: Repeatable environment resets; scheduled access to compute; change management and rollback.
- Benchmarking and procurement evaluation for learned simulators
- Sectors: academia, simulator vendors, integrators
- Use case: Adopt the paper’s replay and interaction outcome metrics (PSNR/SSIM/LPIPS plus event confusion matrices) to benchmark action-conditioned world models for contact-rich tasks prior to purchase or deployment.
- Tools/workflows/products: “World Model Scorecard” with standardized tasks and metrics.
- Assumptions/dependencies: Access to a small public task suite (e.g., DROID-based tasks) and recorded action sequences.
- VLAW adoption playbook for new tasks
- Sectors: robotics teams across industries
- Use case: A simple, repeatable workflow:
- 1) Collect K real rollouts per task,
- 2) Fine-tune world model + reward model on these + base data,
- 3) Generate N synthetic trajectories using policy-in-the-loop,
- 4) Filter with reward model,
- 5) Update policy with weighted flow-matching,
- 6) Iterate.
- Tools/workflows/products: “VLAW Kit” packaging scripts, configs, and monitoring tooling.
- Assumptions/dependencies: Compatibility with flow-matching policy objectives; consistent sensor setup across iterations.
Long-Term Applications
These applications require further research, scaling, or development in fidelity, generalization, safety assurance, or standardization.
- Personalized home-robot learning from a handful of attempts
- Sectors: consumer robotics, assistive tech
- Use case: Users record a few attempts on idiosyncratic household tasks (e.g., cleaning specific surfaces, organizing), world model grounds to household dynamics, generates synthetic successes, and fine-tunes a generalist VLA for personalized skills.
- Dependencies: Robust, low-cost sensing; strong privacy guarantees; reward models that handle long-horizon, cluttered scenes; on-device or privacy-preserving compute.
- Simulation-light deployment for SMEs
- Sectors: small/medium manufacturers, labs
- Use case: Replace or complement physics simulators with grounded world models for task planning, validation, and pre-deployment what-if testing in domains where high-fidelity sims are costly or unavailable.
- Dependencies: Certifiable safety and bounded error guarantees; standardized validation protocols; improved uncertainty estimation in generative world models.
- Cross-embodiment transfer via per-robot world model grounding
- Sectors: robot OEMs, system integrators
- Use case: Learn robot-specific world models (different arms, grippers, compliance) to adapt a shared policy across embodiments with minimal per-robot real data.
- Dependencies: Action space alignment or adapters; multi-view calibration; domain randomization across hardware variance.
- Multi-robot “imagination” for fleet coordination
- Sectors: logistics centers, hospitals, agriculture
- Use case: Extend world models to multi-agent interactions (shared workspaces, handoffs), enabling synthetic rollouts for coordination policy training and edge-case generation.
- Dependencies: Scalable multi-agent video/action diffusion; synchronization of viewpoints; reward models for joint success criteria.
- Synthetic rollout as a service (SaaS) and policy improvement marketplaces
- Sectors: cloud robotics, software
- Use case: Third-party providers operate secure synthetic rollout farms and deliver improved policies or labeled datasets to clients based on limited client rollouts.
- Dependencies: Data-sharing frameworks, privacy-preserving “adapter-only” updates, SLAs on fidelity and safety, standard APIs.
- Regulatory compliance and safety auditing using learned simulators
- Sectors: policy/regulation, safety certification
- Use case: Codify procedures to run standardized test batteries inside world models (including failure cases) pre-deployment and during updates; maintain audit trails for regulatory review.
- Dependencies: Accepted standards for learned-simulator validation; conservative risk bounds and monitoring for distribution shift.
- Domain extensions beyond table-top manipulation
- Sectors: healthcare (surgical/rehab robots), lab automation, field/agriculture, energy (maintenance/inspection)
- Use case: Apply the co-improvement loop to domains with rich contact and deformable materials (e.g., tissue, crops, cables), where classical simulation is limited.
- Dependencies: Specialized sensors (force, depth, endoscopy), domain-tuned reward models, safety oversight, greater long-horizon stability.
- Standardized “world model + VLA” stacks integrated with cloud and robot OS
- Sectors: robotics platforms, MLOps
- Use case: A turnkey stack where data capture, world-model grounding, synthetic generation, reward labeling, and policy updates are first-class citizens in robot OS and cloud pipelines.
- Dependencies: Open interfaces, reference datasets, cost-effective video diffusion serving, and continuous monitoring for drift.
- Uncertainty-aware planning and guardrails in learned simulators
- Sectors: autonomy safety, assurance
- Use case: Use calibrated uncertainty estimates from diffusion world models to veto risky imagined trajectories and constrain policy updates; integrate with safety layers.
- Dependencies: Research advances in uncertainty quantification for generative video models; hybrid model-based/model-free guardrails.
- Education and workforce training for embodied AI
- Sectors: education, upskilling
- Use case: Hands-on curricula where students collect minimal rollouts and experience the full VLAW loop (ground world model → generate → filter → improve policy), accelerating skills in embodied ML.
- Dependencies: Accessible hardware kits or high-quality recorded datasets; cloud credits; didactic tooling and dashboards.
Notes on feasibility across applications
- Critical dependencies: availability of pretrained VLA and action-conditioned world models; some real-world rollout budget including failures; calibrated reward models; adequate vision coverage; compute for video diffusion.
- Risk/assumption factors: world model fidelity in new domains; reward model brittleness on long-horizon or ambiguous outcomes; safety for on-robot data collection; distribution shift handling and drift monitoring; reproducibility and auditability requirements in regulated settings.
Glossary
- action-conditioned video generation model: A generative model that predicts future video frames given current observations and a sequence of actions. "specifically, an action-conditioned video generation model"
- action-conditioned world model: A predictive model that generates future states or observations conditioned on actions taken by a policy. "learning an action-conditioned world model to generate synthetic rollouts in imagination offers a promising alternative"
- advantage function: In RL, the difference between the expected return of an action and a baseline value, measuring how much better an action is than average. "where $\pi_{\mathrm{ref}$ denotes a reference policy, and $A^{\pi_{\mathrm{ref}(o,a)$ is the corresponding advantage function, and is a temperature parameter controlling the strength of the regularization."
- advantage-conditioned supervised learning objective: A training objective that weights supervised updates by advantages to approximate RL improvements without policy gradients. "To enable policy learning in real-world settings, instead adopts an offline or batch reinforcement learning formulation with an advantage-conditioned supervised learning objective."
- auto-regressively: Generating sequences step-by-step, feeding each prediction back as input to produce the next. "we auto-regressively generate a complete imagined trajectory"
- batch reinforcement learning: RL that learns from a fixed dataset of trajectories without additional environment interaction during training. "instead adopts an offline or batch reinforcement learning formulation"
- closed-form solution: An explicit analytical solution that does not require iterative optimization. "The optimal improved policy admits a closed-form solution given by:"
- closed loop: A feedback setup where the policy’s outputs influence the next inputs, forming an interaction cycle. "interact in a closed loop via and ."
- contact-rich object manipulation: Robotic tasks involving frequent and complex contacts between objects and the robot. "and struggle to accurately model small yet critical physical details in contact-rich object manipulation."
- co-train: Training on multiple datasets simultaneously to balance specialization and generalization. "we also co-train with the original DROID dataset $\mathcal{D}_{\mathrm{DROID}$ for regularization."
- DROID: A real-robot platform and dataset used for training and evaluation of robotic policies and world models. "We use the widely used real-robot platform DROID."
- discount factor: The parameter γ in RL that down-weights future rewards relative to immediate rewards. "and the discount factor."
- diffusion objective: The loss used to train diffusion models by denoising progressively noised data back to the target. "Finetuning on the online rollout dataset $\mathcal{D}_{\mathrm{real}$ follows the original diffusion objective"
- dynamic programming/bootstrapping: RL techniques that use recursive value updates, often relying on estimates of future returns to update current values. "as opposed to dynamic programming/bootstrapping or policy gradients."
- event-level confusion matrix: A matrix summarizing correct and incorrect predictions of discrete events (e.g., success/failure). "we report an event-level confusion matrix on 50 clips involving physical interactions."
- FID: Fréchet Inception Distance, a measure of distributional distance between real and generated images/videos via Inception features. "These include pixel-level metrics (PSNR and SSIM) as well as learned perceptual and distributional metrics (LPIPS, FID, and FVD)."
- flow-matching loss: A supervised loss for training flow models to match target action distributions without explicit likelihoods. "where $\mathcal{L}_{\mathrm{FM}(\theta; o, a)$ denotes the flow-matching loss for an observation--action pair ."
- flow-matching policies: Policies trained with flow-matching objectives that avoid explicit likelihoods and facilitate large-model scaling. "flow-matching policies with intractable action probabilities"
- forward dynamics models: Models that predict the next state given the current state and action. "Action-conditioned world models predict future outcomes given current observations and actions, and are also referred to as forward dynamics models."
- FVD: Fréchet Video Distance, a perceptual distributional metric comparing real and generated video dynamics. "These include pixel-level metrics (PSNR and SSIM) as well as learned perceptual and distributional metrics (LPIPS, FID, and FVD)."
- GRPO: A policy optimization method (e.g., Group Relative Policy Optimization) used as an on-policy RL baseline. "Some prior works adopt on-policy reinforcement learning methods, such as PPO~\cite{schulman2017proximal} or GRPO~\cite{shao2024deepseekmath}, to improve VLA policies."
- intractable action probabilities: Situations where computing exact action likelihoods is computationally infeasible, complicating policy-gradient methods. "flow-matching policies with intractable action probabilities"
- KL divergence: Kullback–Leibler divergence, a measure of dissimilarity between two probability distributions. "where denotes a KL divergence measure"
- long-horizon: Involving many sequential steps over an extended duration. "Examples of long-horizon policy-in-the-loop rollouts within the world model starting from the initial observation."
- LPIPS: Learned Perceptual Image Patch Similarity, a neural perceptual metric for visual similarity. "These include pixel-level metrics (PSNR and SSIM) as well as learned perceptual and distributional metrics (LPIPS, FID, and FVD)."
- Markov decision process (MDP): A formal model of sequential decision making defined by states, actions, transitions, and rewards. "modeled as a Markov decision process (MDP) ."
- model-based reinforcement learning: RL that uses a learned model of environment dynamics to plan or improve policies. "Many works leverage such models for model-based reinforcement learning"
- noise schedule: The schedule of noise levels used across diffusion timesteps during training and sampling. "under the noise schedule "
- on-policy reinforcement learning: RL methods that improve policies using data collected from the current policy. "Some prior works adopt on-policy reinforcement learning methods"
- over-optimism: A modeling bias where predicted outcomes are unrealistically positive due to training on mostly successful demonstrations. "over-optimism, as training data is dominated by successful demonstrations"
- policy-gradient methods: Optimization methods that compute gradients of expected returns with respect to policy parameters. "making conventional policy-gradient methods difficult to apply."
- policy-in-the-loop rollouts: Simulations where the policy interacts with a model of the environment, forming a feedback loop. "Examples of long-horizon policy-in-the-loop rollouts within the world model starting from the initial observation."
- PPO: Proximal Policy Optimization, a widely used on-policy policy-gradient algorithm. "Some prior works adopt on-policy reinforcement learning methods, such as PPO~\cite{schulman2017proximal} or GRPO~\cite{shao2024deepseekmath}, to improve VLA policies."
- PSNR: Peak Signal-to-Noise Ratio, a pixel-level metric measuring reconstruction fidelity. "These include pixel-level metrics (PSNR and SSIM) as well as learned perceptual and distributional metrics (LPIPS, FID, and FVD)."
- regularized reinforcement learning: RL that adds a penalty (e.g., KL to a reference policy) to stabilize or constrain policy updates. "policy optimization under a regularized reinforcement learning framework"
- reference policy: A baseline policy used to regularize updates, keeping the new policy close in distribution. "we constrains the learned policy to remain close to a reference policy $\pi_{\mathrm{ref}$ while optimizing reward."
- reward model: A learned model that infers task success or reward from trajectories, often using a vision-LLM. "We then apply the finetuned reward model to identify successful trajectories"
- SSIM: Structural Similarity Index Measure, a pixel-level metric assessing structural similarity in images. "These include pixel-level metrics (PSNR and SSIM) as well as learned perceptual and distributional metrics (LPIPS, FID, and FVD)."
- surrogate divergence: An alternative divergence measure used to align the learned policy with an optimal target under a specified loss. "We can define a surrogate divergence which measures how well matches samples drawn from under the flow-matching loss:"
- synthetic rollouts: Trajectories generated by simulating policy interactions within a learned model rather than the real world. "learning an action-conditioned world model to generate synthetic rollouts in imagination offers a promising alternative"
- transition dynamics: The probabilistic rules P(s_{t+1} | s_t, a_t) governing how the environment evolves after actions. " the transition dynamics"
- video diffusion models: Generative models that synthesize or predict video by denoising from noise across timesteps. "With recent advances in video diffusion models"
- vision-language-action (VLA) models: Models that map visual inputs and language instructions to actions for embodied tasks. "The goal of this paper is to improve the performance and reliability of vision-language-action (VLA) models through iterative online interaction."
- world model: A learned simulator of environment dynamics used for planning, data generation, or policy evaluation. "the world model predicts the next state conditioned on the current state and action, ."
Collections
Sign up for free to add this paper to one or more collections.